Что такое неработающие ссылки?
Нерабочие ссылки — это ссылки или URL-адреса, которые недоступны. Они могут быть недоступны или не работают из-за какой-либо ошибки сервера
URL всегда будет иметь статус 2xx, который действителен. Существуют разные коды состояния HTTP, которые имеют разные цели. Для недействительного запроса статус HTTP 4xx и 5xx.
Класс кодов состояния 4xx в основном предназначен для ошибок на стороне клиента, а класс кодов состояния 5xx главным образом для ошибок ответа сервера.
Скорее всего, мы не сможем подтвердить, работает ли эта ссылка или нет, пока мы не щелкнем и не подтвердим ее.
Зачем вам проверять неработающие ссылки?
Вы должны всегда следить за тем, чтобы на сайте не было неработающих ссылок, поскольку пользователь не должен попадать на страницу с ошибкой.
Ошибка происходит, если правила не обновлены правильно, или запрошенные ресурсы не существуют на сервере.
Ручная проверка ссылок является утомительной задачей, поскольку каждая веб-страница может содержать большое количество ссылок, и ручной процесс должен повторяться для всех страниц.
Сценарий автоматизации, использующий Selenium, который автоматизирует процесс, является более подходящим решением.
Как проверить неработающие ссылки и изображения
Для проверки неработающих ссылок вам необходимо выполнить следующие шаги.
- Соберите все ссылки на веб-странице на основе тега <a>.
- Отправьте HTTP-запрос на ссылку и прочитайте HTTP-код ответа.
- Узнайте, является ли ссылка действительной или неработающей, основываясь на коде ответа HTTP.
- Повторите это для всех захваченных ссылок.
Код для поиска неработающих ссылок на веб-странице
Ниже приведен код веб-драйвера, который тестирует наш вариант использования:
package automationPractice;
import java.io.IOException;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.Iterator;
import java.util.List;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
public class BrokenLinks {
private static WebDriver driver = null;
public static void main(String[] args) {
// TODO Auto-generated method stub
String homePage = "http://www.zlti.com";
String url = "";
HttpURLConnection huc = null;
int respCode = 200;
driver = new ChromeDriver();
driver.manage().window().maximize();
driver.get(homePage);
List<WebElement> links = driver.findElements(By.tagName("a"));
Iterator<WebElement> it = links.iterator();
while(it.hasNext()){
url = it.next().getAttribute("href");
System.out.println(url);
if(url == null || url.isEmpty()){
System.out.println("URL is either not configured for anchor tag or it is empty");
continue;
}
if(!url.startsWith(homePage)){
System.out.println("URL belongs to another domain, skipping it.");
continue;
}
try {
huc = (HttpURLConnection)(new URL(url).openConnection());
huc.setRequestMethod("HEAD");
huc.connect();
respCode = huc.getResponseCode();
if(respCode >= 400){
System.out.println(url+" is a broken link");
}
else{
System.out.println(url+" is a valid link");
}
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
driver.quit();
}
}
Объяснение кода Пример
Шаг 1: Импорт пакетов
Импортируйте пакет ниже, в дополнение к пакетам по умолчанию:
import java.net.HttpURLConnection;
Используя методы этого пакета, мы можем отправлять HTTP-запросы и захватывать HTTP-коды ответов из ответа.
Шаг 2: собрать все ссылки на веб-странице
Определите все ссылки на веб-странице и сохраните их в списке.
List<WebElement> links = driver.findElements(By.tagName("a"));
Получите Iterator, чтобы пройти через Список.
Iterator<WebElement> it = links.iterator();
Шаг 3. Идентификация и проверка URL
В этой части мы проверим, принадлежит ли URL-адрес стороннему домену или пустой или пустой.
Получите href тега привязки и сохраните его в переменной url.
url = it.next().getAttribute("href");
Проверьте, является ли URL-адрес пустым или пустым, и пропустите оставшиеся шаги, если условие выполнено.
if(url == null || url.isEmpty()){
System.out.println("URL is either not configured for anchor tag or it is empty");
continue;
}
Проверьте, принадлежит ли URL-адрес основному домену или третьей стороне. Пропустите оставшиеся шаги, если он принадлежит стороннему домену.
if(!url.startsWith(homePage)){
System.out.println("URL belongs to another domain, skipping it.");
continue;
}
Шаг 4: Отправить http запрос
Класс HttpURLConnection имеет методы для отправки HTTP-запроса и захвата HTTP-кода ответа. Таким образом, вывод метода openConnection () (URLConnection) имеет тип, приведенный к HttpURLConnection.
huc = (HttpURLConnection)(new URL(url).openConnection());
Мы можем установить тип запроса как «HEAD» вместо «GET». Так что возвращаются только заголовки, а не тело документа.
huc.setRequestMethod("HEAD");
При вызове метода connect () устанавливается фактическое соединение с URL и отправляется запрос.
huc.connect();
Шаг 5: Проверка ссылок
Используя метод getResponseCode (), мы можем получить код ответа на запрос
respCode = huc.getResponseCode();
На основании кода ответа мы попытаемся проверить статус ссылки.
if(respCode >= 400){
System.out.println(url+" is a broken link");
}
else{
System.out.println(url+" is a valid link");
}
Таким образом, мы можем получить все ссылки с веб-страницы и распечатать, являются ли ссылки действительными или неработающими.
Надеюсь, что этот учебник поможет вам в проверке битых ссылок с помощью селена.
Как получить ВСЕ ссылки на веб-странице
Одна из распространенных процедур веб- тестирования — проверка работоспособности всех ссылок, представленных на странице. Это может быть удобно сделано с использованием комбинации цикла Java for-each , findElements () и By.tagName («a») .
Метод findElements () возвращает список веб-элементов с тегом a. Используя цикл for-each, осуществляется доступ к каждому элементу.
Приведенный ниже код WebDriver проверяет каждую ссылку на домашней странице Mercury Tours, чтобы определить, какие из них работают, а какие еще находятся в разработке.
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
import java.util.List;
import java.util.concurrent.TimeUnit;
import org.openqa.selenium.*;
public class P1 {
public static void main(String[] args) {
String baseUrl = "http://demo.guru99.com/test/newtours/";
System.setProperty("webdriver.chrome.driver","G:\\chromedriver.exe");
WebDriver driver = new ChromeDriver();
String underConsTitle = "Under Construction: Mercury Tours";
driver.manage().timeouts().implicitlyWait(5, TimeUnit.SECONDS);
driver.get(baseUrl);
List<WebElement> linkElements = driver.findElements(By.tagName("a"));
String[] linkTexts = new String[linkElements.size()];
int i = 0;
//extract the link texts of each link element
for (WebElement e : linkElements) {
linkTexts[i] = e.getText();
i++;
}
//test each link
for (String t : linkTexts) {
driver.findElement(By.linkText(t)).click();
if (driver.getTitle().equals(underConsTitle)) {
System.out.println("\"" + t + "\""
+ " is under construction.");
} else {
System.out.println("\"" + t + "\""
+ " is working.");
}
driver.navigate().back();
}
driver.quit();
}
}
Вывод должен быть аналогичен указанному ниже.
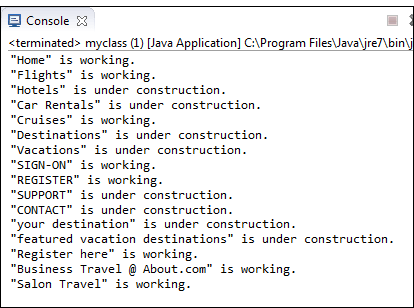
Поиск проблемы
В единичном случае первой ссылкой, к которой обращается код, может быть ссылка «Домашняя страница». В этом случае действие driver.navigate.back () покажет пустую страницу, так как 1-е действие открывает браузер. Драйвер не сможет найти все остальные ссылки в пустом браузере. Поэтому IDE сгенерирует исключение, а остальная часть кода не будет выполнена. Это можно легко сделать с помощью цикла If.