Чтение HTML-таблицы
Есть моменты, когда нам нужно получить доступ к элементам (обычно текстам), которые находятся в таблицах HTML. Тем не менее, веб-дизайнер редко предоставляет атрибут id или name для определенной ячейки в таблице. Поэтому мы не можем использовать обычные методы, такие как «By.id ()», «By.name ()» или «By.cssSelector ()». В этом случае наиболее надежным вариантом является доступ к ним с помощью метода «By.xpath ()».
В этом уроке вы узнаете
- Как написать XPath для таблицы
- Доступ к вложенным таблицам
- Использование атрибутов в качестве предикатов
- Ярлык: используйте элемент проверки для доступа к таблицам в Selenium
Как написать XPath для таблицы
Рассмотрим код HTML ниже.

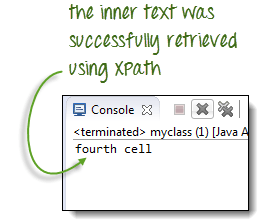
Мы будем использовать XPath для получения внутреннего текста ячейки, содержащей текст «четвертая ячейка».
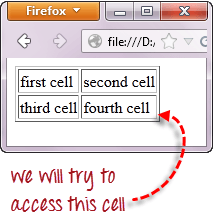
Шаг 1 — Установите родительский элемент (таблица)
Локаторы XPath в WebDriver всегда начинаются с двойной косой черты «//» и затем сопровождаются родительским элементом . Поскольку мы имеем дело с таблицами, родительским элементом всегда должен быть тег <table>. Поэтому первая часть нашего локатора XPath должна начинаться с «// table».
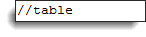
Шаг 2 — Добавьте дочерние элементы
Элемент, находящийся непосредственно под <table>, является <tbody>, поэтому мы можем сказать, что <tbody> является «потомком» <table>. А также <table> является «родителем» <tbody>. Все дочерние элементы в XPath размещаются справа от их родительского элемента, разделенных одной косой чертой «/», как показано в коде ниже.
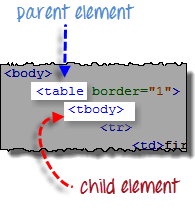

Шаг 3 — Добавить предикаты
Элемент <tbody> содержит два тега <tr>. Теперь мы можем сказать, что эти два тега <tr> являются «потомками» <tbody>. Следовательно, мы можем сказать, что <tbody> является родителем обоих элементов <tr>.
Мы также можем сделать вывод, что два элемента <tr> являются родственными. Братья и сестры относятся к дочерним элементам, имеющим одного и того же родителя .
Чтобы добраться до <td>, к которому мы хотим получить доступ (тот, что с текстом «четвертая ячейка»), мы должны сначала получить доступ ко второму <tr>, а не к первому. Если мы просто напишем «// table / tbody / tr», то мы будем обращаться к первому тегу <tr>.
Итак, как нам получить доступ ко второму <tr> тогда? Ответ на это заключается в использовании предикатов .
Предикаты — это числа или атрибуты HTML, заключенные в пару квадратных скобок «[]», которые отличают дочерний элемент от его родных элементов . Поскольку <tr> нам нужен доступ, является вторым, мы будем использовать «[2]» в качестве предиката.

Если мы не будем использовать какой-либо предикат, XPath получит доступ к первому брату. Следовательно, мы можем получить доступ к первому <tr>, используя любой из этих кодов XPath.

Шаг 4 — Добавьте последующие дочерние элементы, используя соответствующие предикаты
Следующий элемент, к которому нам нужно получить доступ, это второй <td>. Применяя принципы, которые мы узнали из шагов 2 и 3, мы завершим наш код XPath так, как показано ниже.

Теперь, когда у нас есть правильный локатор XPath, мы уже можем получить доступ к ячейке, которую мы хотели, и получить ее внутренний текст, используя код ниже. Предполагается, что вы сохранили приведенный выше HTML-код как «newhtml.html» на диске C.
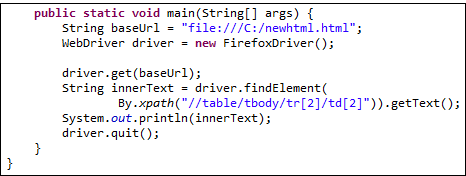
public static void main(String[] args) {
String baseUrl = "http://demo.guru99.com/test/write-xpath-table.html";
WebDriver driver = new FirefoxDriver();
driver.get(baseUrl);
String innerText = driver.findElement(
By.xpath("//table/tbody/tr[2]/td[2]")).getText();
System.out.println(innerText);
driver.quit();
}
}
Доступ к вложенным таблицам
Те же самые принципы, которые обсуждались выше, применяются к вложенным таблицам. Вложенные таблицы — это таблицы, расположенные в другой таблице . Пример показан ниже.

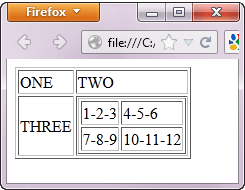
Чтобы получить доступ к ячейке с текстом «4-5-6» с помощью «// parent / child» и предикатных концепций из предыдущего раздела, мы должны быть в состоянии найти код XPath ниже.

Приведенный ниже код WebDriver должен быть в состоянии извлечь внутренний текст ячейки, к которой мы обращаемся.

public static void main(String[] args) {
String baseUrl = "http://demo.guru99.com/test/accessing-nested-table.html";
WebDriver driver = new FirefoxDriver();
driver.get(baseUrl);
String innerText = driver.findElement(
By.xpath("//table/tbody/tr[2]/td[2]/table/tbody/tr/td[2]")).getText();
System.out.println(innerText);
driver.quit();
}
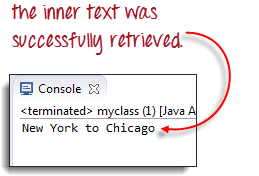
Вывод ниже подтверждает, что внутренняя таблица была успешно доступна.

Использование атрибутов в качестве предикатов
Если элемент написан глубоко внутри HTML-кода, так что число, используемое для предиката, определить очень сложно, мы можем использовать вместо этого уникальный атрибут этого элемента.
В приведенном ниже примере ячейка «Нью-Йорк-Чикаго» расположена глубоко в HTML-коде домашней страницы Mercury Tours.
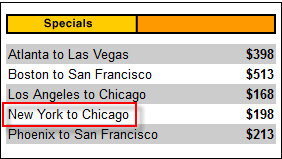

В этом случае мы можем использовать уникальный атрибут таблицы (width = «270») в качестве предиката. Атрибуты используются в качестве предикатов, добавляя к ним префикс @ . В приведенном выше примере ячейка «от Нью-Йорка до Чикаго» расположена в первом <td> четвертом <tr>, поэтому наш XPath должен быть таким, как показано ниже.

Помните, что когда мы помещаем код XPath в Java, мы должны использовать обратную косую черту «\» для двойных кавычек по обе стороны от «270», чтобы строковый аргумент By.xpath () не завершался преждевременно. ,

Теперь мы готовы получить доступ к этой ячейке, используя код ниже.

public static void main(String[] args) {
String baseUrl = "http://demo.guru99.com/test/newtours/";
WebDriver driver = new FirefoxDriver();
driver.get(baseUrl);
String innerText = driver.findElement(By
.xpath("//table[@width=\"270\"]/tbody/tr[4]/td"))
.getText();
System.out.println(innerText);
driver.quit();
}
Ярлык: используйте элемент проверки для доступа к таблицам в Selenium
Если число или атрибут элемента получить чрезвычайно сложно или невозможно получить, самый быстрый способ создания кода XPath — использовать Inspect Element.
Рассмотрите пример ниже с домашней страницы Mercury Tours.

Шаг 1
Используйте Firebug для получения кода XPath.
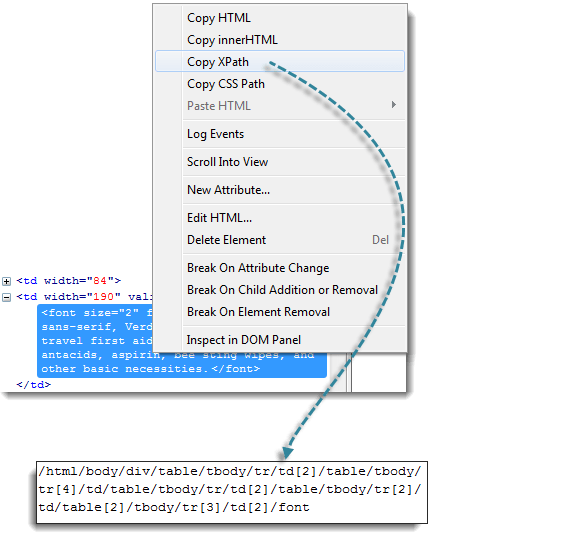
Шаг 2
Найдите первый родительский элемент «таблица» и удалите все слева от него.
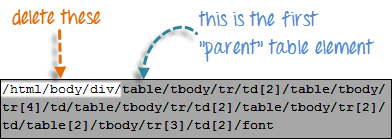
Шаг 3
Добавьте к оставшейся части кода двойную косую черту «//» и скопируйте ее в свой код WebDriver.
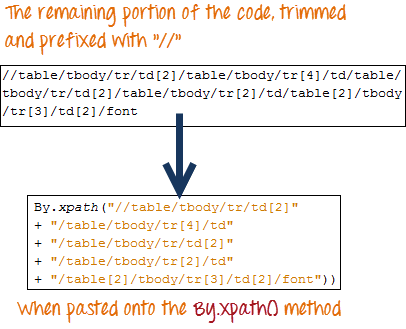
Приведенный ниже код WebDriver сможет успешно извлечь внутренний текст элемента, к которому мы обращаемся.
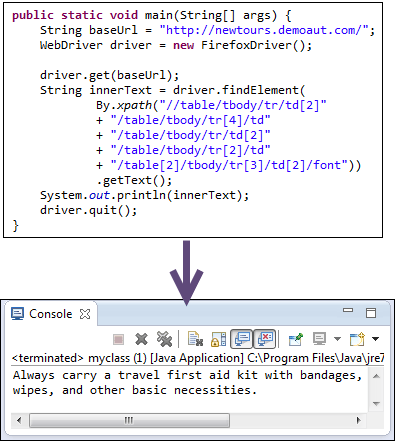
public static void main(String[] args) {
String baseUrl = "http://demo.guru99.com/test/newtours/";
WebDriver driver = new FirefoxDriver();
driver.get(baseUrl);
String innerText = driver.findElement(By
.xpath("//table/tbody/tr/td[2]"
+ "//table/tbody/tr[4]/td/"
+ "table/tbody/tr/td[2]/"
+ "table/tbody/tr[2]/td[1]/"
+ "table[2]/tbody/tr[3]/td[2]/font"))
.getText();
System.out.println(innerText);
driver.quit();
}
Резюме
- By.xpath () обычно используется для доступа к элементам таблицы.
- Если элемент написан глубоко внутри HTML-кода, так что число, используемое для предиката, определить очень сложно, мы можем использовать вместо этого уникальный атрибут этого элемента.
- Атрибуты используются в качестве предикатов, добавляя к ним префикс @.
- Используйте элемент контроля для доступа к таблицам в Selenium