Введение в анализ данных
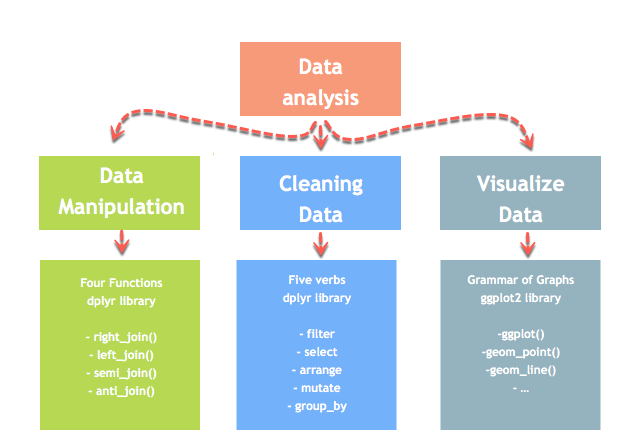
Анализ данных можно разделить на три части
- Извлечение: во-первых, нам нужно собрать данные из многих источников и объединить их.
- Преобразование: этот шаг включает в себя манипулирование данными. После того, как мы объединили все источники данных, мы можем начать очистку данных.
- Визуализация: последний шаг — визуализация наших данных для проверки неправильности.
Одной из наиболее значительных проблем, с которыми сталкивается ученый, является манипулирование данными. Данные никогда не доступны в нужном формате. Специалист по данным должен тратить как минимум половину своего времени на очистку и манипулирование данными. Это одно из самых важных заданий в работе. Если процесс манипулирования данными не является полным, точным и строгим, модель не будет работать правильно.
R имеет библиотеку dplyr, которая помогает в преобразовании данных.
Библиотека dplyr в основном создана из четырех функций для манипулирования данными и пяти глаголов для очистки данных. После этого мы можем использовать библиотеку ggplot для анализа и визуализации данных.
В этом уроке мы узнаем, как использовать библиотеку dplyr для манипулирования фреймом данных.
В этом уроке вы узнаете
- Анализ данных
- Объединить с dplyr ()
- left_join ()
- right_join ()
- внутреннее соединение()
- full_join ()
- Несколько ключей
- Функции очистки данных
- собирать ()
- распространение()
- отдельно ()
- Unite ()
Объединить с dplyr ()
dplyr предоставляет удобный и удобный способ объединения наборов данных. У нас может быть много источников входных данных, и в какой-то момент нам нужно их объединить. Объединение с dplyr добавляет переменные справа от исходного набора данных. Прелесть dplyr в том, что он обрабатывает четыре типа соединений, похожих на SQL
- Left_join ()
- right_join ()
- внутреннее соединение()
- full_join ()
Мы рассмотрим все типы соединений на простом примере.
Прежде всего, мы строим два набора данных. Таблица 1 содержит две переменные, ID и y, тогда как Таблица 2 собирает ID и z. В каждой ситуации нам нужна переменная пары ключей . В нашем случае ID является нашей ключевой переменной. Функция будет искать одинаковые значения в обеих таблицах и связывать возвращаемые значения справа от таблицы 1.
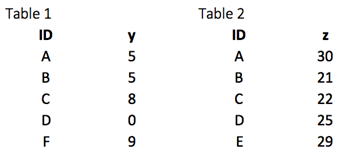
library(dplyr) df_primary <- tribble( ~ID, ~y, "A", 5, "B", 5, "C", 8, "D", 0, "F", 9) df_secondary <- tribble( ~ID, ~y, "A", 30, "B", 21, "C", 22, "D", 25, "E", 29)
left_join ()
Наиболее распространенный способ объединения двух наборов данных — это использование функции left_join (). Из рисунка ниже видно, что пара ключей идеально соответствует строкам A, B, C и D из обоих наборов данных. Тем не менее, E и F остались. Как мы относимся к этим двум наблюдениям? С помощью left_join () мы сохраним все переменные в исходной таблице и не будем рассматривать переменные, у которых нет пары ключей в таблице назначения. В нашем примере переменная E не существует в таблице 1. Поэтому строка будет удалена. Переменная F происходит из исходной таблицы; он будет сохранен после left_join () и вернет NA в столбце z. На рисунке ниже показано, что произойдет с left_join ().

left_join(df_primary, df_secondary, by ='ID')
Вывод:
## # A tibble: 5 x 3 ## ID y.x y.y ## <chr> <dbl> <dbl> ## 1 A 5 30 ## 2 B 5 21 ## 3 C 8 22 ## 4 D 0 25 ## 5 F 9 NA
right_join ()
Функция right_join () работает точно так же, как left_join (). Разница лишь в том, что ряд отброшен. Значение E, доступное в целевом фрейме данных, существует в новой таблице и принимает значение NA для столбца y.
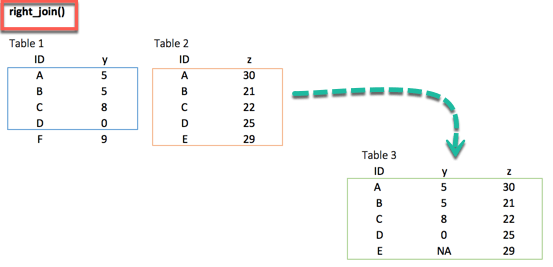
right_join(df_primary, df_secondary, by = 'ID')
Вывод:
## # A tibble: 5 x 3 ## ID y.x y.y ## <chr> <dbl> <dbl> ## 1 A 5 30 ## 2 B 5 21 ## 3 C 8 22 ## 4 D 0 25 ## 5 E NA 29
внутреннее соединение()
Когда мы на 100% уверены, что два набора данных не будут совпадать, мы можем рассмотреть возможность возврата только тех строк, которые существуют в обоих наборах данных. Это возможно, когда нам нужен чистый набор данных или когда мы не хотим вменять пропущенные значения в среднее значение или медиану.
Inner_join () приходит на помощь. Эта функция исключает несопоставленные строки.
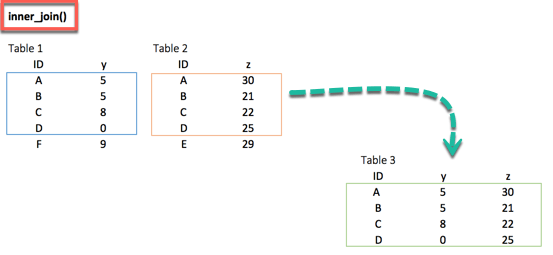
inner_join(df_primary, df_secondary, by ='ID')
вывод:
## # A tibble: 4 x 3 ## ID y.x y.y ## <chr> <dbl> <dbl> ## 1 A 5 30 ## 2 B 5 21 ## 3 C 8 22 ## 4 D 0 25
full_join ()
Наконец, функция full_join () сохраняет все наблюдения и заменяет отсутствующие значения на NA.
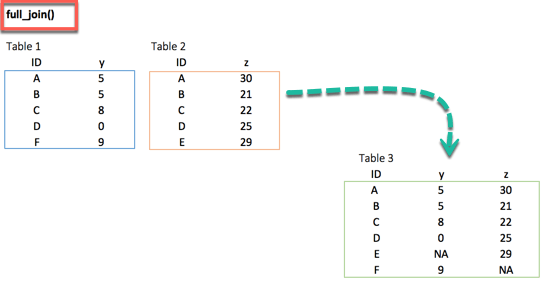
full_join(df_primary, df_secondary, by = 'ID')
Вывод:
## # A tibble: 6 x 3 ## ID y.x y.y ## <chr> <dbl> <dbl> ## 1 A 5 30 ## 2 B 5 21 ## 3 C 8 22 ## 4 D 0 25 ## 5 F 9 NA ## 6 E NA 29
Несколько пар ключей
И последнее, но не менее важное: в нашем наборе данных может быть несколько ключей. Рассмотрим следующий набор данных, где у нас есть годы или список продуктов, купленных клиентом.

Если мы попытаемся объединить обе таблицы, R выдаст ошибку. Чтобы исправить ситуацию, мы можем передать две пары ключей. То есть ID и год, которые появляются в обоих наборах данных. Мы можем использовать следующий код для объединения таблиц 1 и 2
df_primary <- tribble(
~ID, ~year, ~items,
"A", 2015,3,
"A", 2016,7,
"A", 2017,6,
"B", 2015,4,
"B", 2016,8,
"B", 2017,7,
"C", 2015,4,
"C", 2016,6,
"C", 2017,6)
df_secondary <- tribble(
~ID, ~year, ~prices,
"A", 2015,9,
"A", 2016,8,
"A", 2017,12,
"B", 2015,13,
"B", 2016,14,
"B", 2017,6,
"C", 2015,15,
"C", 2016,15,
"C", 2017,13)
left_join(df_primary, df_secondary, by = c('ID', 'year'))
Вывод:
## # A tibble: 9 x 4 ## ID year items prices ## <chr> <dbl> <dbl> <dbl> ## 1 A 2015 3 9 ## 2 A 2016 7 8 ## 3 A 2017 6 12 ## 4 B 2015 4 13 ## 5 B 2016 8 14 ## 6 B 2017 7 6 ## 7 C 2015 4 15 ## 8 C 2016 6 15 ## 9 C 2017 6 13
Функции очистки данных
Ниже приведены четыре важные функции для очистки данных:
- collect (): преобразование данных из широких в длинные
- spread (): преобразование данных из длинного в широкое
- отделить (): разделить одну переменную на две
- unit (): объединить две переменные в одну
Мы используем библиотеку Tidyr. Эта библиотека принадлежит к коллекции библиотеки для манипулирования, очистки и визуализации данных. Если мы устанавливаем R с помощью anaconda, библиотека уже установлена. Мы можем найти библиотеку здесь, https://anaconda.org/r/r-tidyr .
Если еще не установлен, введите следующую команду
установить tidyr: install.packages («tidyr»)
установить тидыр
собирать ()
Задача функции collect () — преобразовать данные из широких в длинные.
gather(data, key, value, na.rm = FALSE) Arguments: -data: The data frame used to reshape the dataset -key: Name of the new column created -value: Select the columns used to fill the key column -na.rm: Remove missing values. FALSE by default
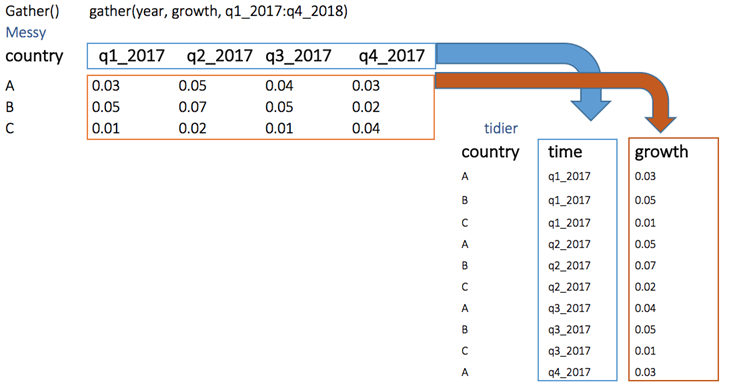
Ниже мы можем визуализировать концепцию изменения формы с широкого на длинный. Мы хотим создать один столбец с именем рост, заполненный строками переменных квартала.
library(tidyr)
# Create a messy dataset
messy <- data.frame(
country = c("A", "B", "C"),
q1_2017 = c(0.03, 0.05, 0.01),
q2_2017 = c(0.05, 0.07, 0.02),
q3_2017 = c(0.04, 0.05, 0.01),
q4_2017 = c(0.03, 0.02, 0.04))
messy
Вывод:
## country q1_2017 q2_2017 q3_2017 q4_2017 ## 1 A 0.03 0.05 0.04 0.03 ## 2 B 0.05 0.07 0.05 0.02 ## 3 C 0.01 0.02 0.01 0.04
# Reshape the data tidier <-messy %>% gather(quarter, growth, q1_2017:q4_2017) tidier
Вывод:
## country quarter growth ## 1 A q1_2017 0.03 ## 2 B q1_2017 0.05 ## 3 C q1_2017 0.01 ## 4 A q2_2017 0.05 ## 5 B q2_2017 0.07 ## 6 C q2_2017 0.02 ## 7 A q3_2017 0.04 ## 8 B q3_2017 0.05 ## 9 C q3_2017 0.01 ## 10 A q4_2017 0.03 ## 11 B q4_2017 0.02 ## 12 C q4_2017 0.04
В функции collect () мы создаем две новые переменные квартал и рост, потому что в нашем исходном наборе данных есть одна групповая переменная: т.е. страна и пары ключ-значение.
распространение()
Функция распространения () делает противоположность сбора.
spread(data, key, value) arguments:
- данные: фрейм данных, используемый для изменения набора данных
- ключ: столбец, чтобы изменить форму от длинного до широкого
- значение: строки, используемые для заполнения нового столбца
Мы можем изменить набор данных Tidier обратно в беспорядок с распространением ()
# Reshape the data messy_1 <- tidier %>% spread(quarter, growth) messy_1
Вывод:
## country q1_2017 q2_2017 q3_2017 q4_2017 ## 1 A 0.03 0.05 0.04 0.03 ## 2 B 0.05 0.07 0.05 0.02 ## 3 C 0.01 0.02 0.01 0.04
отдельно ()
Функция Отделение () разбивает столбец на два в соответствии с разделителем. Эта функция полезна в некоторых ситуациях, когда переменная является датой. Наш анализ может потребовать фокусировки на месяце и году, и мы хотим разделить столбец на две новые переменные.
Синтаксис :
separate(data, col, into, sep= "", remove = TRUE) arguments: -data: The data frame used to reshape the dataset -col: The column to split -into: The name of the new variables -sep: Indicates the symbol used that separates the variable, i.e.: "-", "_", "&" -remove: Remove the old column. By default sets to TRUE.
Мы можем отделить квартал от года в наборе данных tidier, применив функцию Отдельные ().
separate_tidier <-tidier %>%
separate(quarter, c("Qrt", "year"), sep ="_")
head(separate_tidier)
Output:
## country Qrt year growth ## 1 A q1 2017 0.03 ## 2 B q1 2017 0.05 ## 3 C q1 2017 0.01 ## 4 A q2 2017 0.05 ## 5 B q2 2017 0.07 ## 6 C q2 2017 0.02
unite()
The unite() function concanates two columns into one.
Syntax:
unit(data, col, conc ,sep= "", remove = TRUE) arguments: -data: The data frame used to reshape the dataset -col: Name of the new column -conc: Name of the columns to concatenate -sep: Indicates the symbol used that unites the variable, i.e: "-", "_", "&" -remove: Remove the old columns. By default, sets to TRUE
In the above example, we separated quarter from year. What if we want to merge them. We use the following code:
unit_tidier <- separate_tidier %>% unite(Quarter, Qrt, year, sep ="_") head(unit_tidier)
output:
## country Quarter growth ## 1 A q1_2017 0.03 ## 2 B q1_2017 0.05 ## 3 C q1_2017 0.01 ## 4 A q2_2017 0.05 ## 5 B q2_2017 0.07 ## 6 C q2_2017 0.02
Summary
Following are four important functions used in dplyr to merge two datasets.
| Function | Objectives | Arguments | Multiple keys |
|---|---|---|---|
| left_join() | Merge two datasets. Keep all observations from the origin table | data, origin, destination, by = «ID» | origin, destination, by = c(«ID», «ID2») |
| right_join() | Merge two datasets. Keep all observations from the destination table | data, origin, destination, by = «ID» | origin, destination, by = c(«ID», «ID2») |
| inner_join() | Объединить два набора данных. Исключает все несопоставленные строки | данные, источник, пункт назначения, by = «ID» | источник, пункт назначения, by = c («ID», «ID2») |
| full_join () | Объединить два набора данных. Сохраняет все наблюдения | данные, источник, пункт назначения, by = «ID» | источник, пункт назначения, by = c («ID», «ID2») |
Используя библиотеку tidyr, вы можете преобразовать набор данных с помощью функций собирать (), распространить (), разделить () и объединить ().
|
функция |
Цели |
аргументы |
|---|---|---|
|
собирать () |
Преобразование данных из широкого в длинный |
(данные, ключ, значение, na.rm = FALSE) |
|
распространение() |
Преобразуйте данные из длинных в широкие |
(данные, ключ, значение) |
|
отдельно () |
Разделить одну переменную на две |
(data, col, into, sep = «», remove = TRUE) |
|
единица измерения() |
Объединить две переменные в одну |
(data, col, conc, sep = «», remove = TRUE) |