Резюме переменной важно иметь представление о данных. Хотя суммирование переменных по группам дает лучшую информацию о распределении данных.
В этом руководстве вы узнаете, как суммировать набор данных по группам с помощью библиотеки dplyr.
В этом уроке вы узнаете
- Подводить итоги()
- Group_by против no group_by
- Функция в суммировании ()
- Основная функция
- Подменю
- сумма
- Среднеквадратичное отклонение
- Минимум и максимум
- подсчитывать
- Первый и последний
- n-е наблюдение
- Несколько групп
- Фильтр
- Ungroup
Для этого урока вы будете использовать набор данных ватина. Исходный набор данных содержит 102816 наблюдений и 22 переменных. Вы будете использовать только 20 процентов этого набора данных и использовать следующие переменные:
- playerID: код идентификатора игрока. фактор
- yearID: год. фактор
- teamID: команда. фактор
- lgID: Лига. Фактор: AA AL FL NL PL UA
- АБ: На летучих мышах. числовой
- G: Игры: количество игр игрока. числовой
- R: работает. числовой
- HR: Homeruns. числовой
- SH: Жертвы жертвы. числовой
Перед выполнением сводки вы выполните следующие шаги для подготовки данных:
- Шаг 1: Импортируйте данные
- Шаг 2: Выберите соответствующие переменные
- Шаг 3: Сортировка данных
library(dplyr)
# Step 1
data <- read.csv("https://raw.githubusercontent.com/guru99-edu/R-Programming/master/lahman-batting.csv") % > %
# Step 2
select(c(playerID, yearID, AB, teamID, lgID, G, R, HR, SH)) % > %
# Step 3
arrange(playerID, teamID, yearID)
Хорошей практикой при импорте набора данных является использование функции glimpse (), чтобы иметь представление о структуре набора данных.
# Structure of the data glimpse(data)
Вывод:
Observations: 104,324 Variables: 9 $ playerID <fctr> aardsda01, aardsda01, aardsda01, aardsda01, aardsda01, a... $ yearID <int> 2015, 2008, 2007, 2006, 2012, 2013, 2009, 2010, 2004, 196... $ AB <int> 1, 1, 0, 2, 0, 0, 0, 0, 0, 603, 600, 606, 547, 516, 495, ... $ teamID <fctr> ATL, BOS, CHA, CHN, NYA, NYN, SEA, SEA, SFN, ATL, ATL, A... $ lgID <fctr> NL, AL, AL, NL, AL, NL, AL, AL, NL, NL, NL, NL, NL, NL, ... $ G <int> 33, 47, 25, 45, 1, 43, 73, 53, 11, 158, 155, 160, 147, 15... $ R <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 117, 113, 84, 100, 103, 95, 75... $ HR <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 44, 39, 29, 44, 38, 47, 34, 40... $ SH <int> 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 6, ...
Подводить итоги()
Синтаксис summaze () является базовым и согласуется с другими глаголами, включенными в библиотеку dplyr.
summarise(df, variable_name=condition) arguments: - `df`: Dataset used to construct the summary statistics - `variable_name=condition`: Formula to create the new variable
Посмотрите на код ниже:
summarise(data, mean_run =mean(R))
Код Объяснение
- резюмировать (данные, mean_run = mean (R)): создает переменную с именем mean_run, которая является средним значением столбца, запущенного из данных набора данных.
Вывод:
## mean_run ## 1 19.20114
Вы можете добавить столько переменных, сколько хотите. Вы возвращаете среднее количество сыгранных игр и среднее количество жертв.
summarise(data, mean_games = mean(G),
mean_SH = mean(SH, na.rm = TRUE))
Код Объяснение
- mean_SH = mean (SH, na.rm = TRUE): суммировать вторую переменную. Вы устанавливаете na.rm = TRUE, потому что столбец SH содержит отсутствующие наблюдения.
Вывод:
## mean_games mean_SH ## 1 51.98361 2.340085
Group_by против no group_by
Функция summerise () без group_by () не имеет никакого смысла. Создает сводную статистику по группам. Библиотека dplyr автоматически применяет функцию к группе, которую вы передали внутри глагола group_by.
Обратите внимание, что group_by отлично работает со всеми другими глаголами (например, mutate (), filter () ,range (), …).
Удобно пользоваться оператором конвейера, когда у вас более одного шага. Вы можете рассчитать средний homerun по бейсбольной лиге.
data % > % group_by(lgID) % > % summarise(mean_run = mean(HR))
Код Объяснение
- данные: набор данных, используемый для построения сводной статистики
- group_by (lgID): вычислить сводку, сгруппировав переменную `lgID
- суммировать (mean_run = mean (HR)): вычислить среднее значение homerun
Вывод:
## # A tibble: 7 x 2 ## lgID mean_run ## <fctr> <dbl> ## 1 AA 0.9166667 ## 2 AL 3.1270988 ## 3 FL 1.3131313 ## 4 NL 2.8595953 ## 5 PL 2.5789474 ## 6 UA 0.6216216 ## 7 <NA> 0.2867133
Трубный оператор также работает с ggplot (). Вы можете легко показать сводную статистику с графиком. Все шаги проталкиваются внутри конвейера до тех пор, пока захват не будет построен. Кажется более наглядным увидеть среднего homerun по лиге с символом бара. Приведенный ниже код демонстрирует мощь объединения group_by (), summaze () и ggplot ().
Вы сделаете следующий шаг:
- Шаг 1: Выберите фрейм данных
- Шаг 2: Группировка данных
- Шаг 3: Суммируйте данные
- Шаг 4. Составьте сводную статистику
library(ggplot2)
# Step 1
data % > %
#Step 2
group_by(lgID) % > %
#Step 3
summarise(mean_home_run = mean(HR)) % > %
#Step 4
ggplot(aes(x = lgID, y = mean_home_run, fill = lgID)) +
geom_bar(stat = "identity") +
theme_classic() +
labs(
x = "baseball league",
y = "Average home run",
title = paste(
"Example group_by() with summarise()"
)
)
Вывод:
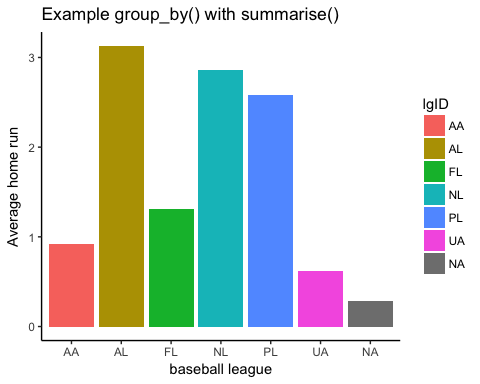
Функция в суммировании ()
Глагол sumrize () совместим практически со всеми функциями в R. Вот краткий список полезных функций, которые вы можете использовать вместе с sumrize ():
| Задача | функция | Описание |
|---|---|---|
| основной | жадный() | Среднее вектора х |
| медиана () | Медиана вектора х | |
| сумма () | Сумма вектора х | |
| изменение | SD () | стандартное отклонение вектора х |
| МКР () | Интерквартиль вектора х | |
| Спектр | мин () | Минимум вектора х |
| Максимум() | Максимум вектора х | |
| квантиль () | Квантиль вектора х | |
| Должность | первый() | Использовать с group_by () Первое наблюдение за группой |
| прошлой() | Используйте с group_by (). Последнее наблюдение группы | |
| п-й () | Используйте с group_by (). n-е наблюдение за группой | |
| подсчитывать | п () | Используйте с group_by (). Подсчитайте количество строк |
| n_distinct () | Используйте с group_by (). Подсчитайте количество разных наблюдений |
Мы увидим примеры для каждой функции таблицы 1.
Основная функция
В предыдущем примере вы не сохранили сводную статистику во фрейме данных.
Вы можете выполнить два шага, чтобы сгенерировать рамку даты из сводки:
- Шаг 1: Сохраните фрейм данных для дальнейшего использования
- Шаг 2: Используйте набор данных для создания линейного графика
Шаг 1) Вы вычисляете среднее количество игр, сыгранных за год.
## Mean ex1 <- data % > % group_by(yearID) % > % summarise(mean_game_year = mean(G)) head(ex1)
Код Объяснение
- Сводная статистика набора данных ватина сохраняется во фрейме данных ex1.
Вывод:
## # A tibble: 6 x 2 ## yearID mean_game_year ## <int> <dbl> ## 1 1871 23.42308 ## 2 1872 18.37931 ## 3 1873 25.61538 ## 4 1874 39.05263 ## 5 1875 28.39535 ## 6 1876 35.90625
Шаг 2) Вы показываете сводную статистику с линейным графиком и видите тренд.
# Plot the graph
ggplot(ex1, aes(x = yearID, y = mean_game_year)) +
geom_line() +
theme_classic() +
labs(
x = "Year",
y = "Average games played",
title = paste(
"Average games played from 1871 to 2016"
)
)
Вывод:

Подменю
Функция summaze () совместима с поднабором.
## Subsetting + Median data % > % group_by(lgID) % > % summarise(median_at_bat_league = median(AB), #Compute the median without the zero median_at_bat_league_no_zero = median(AB[AB > 0]))
Код Объяснение
- median_at_bat_league_no_zero = median (AB [AB> 0]): переменная AB содержит множество 0. Вы можете сравнить медиану переменной at bat с и без 0.
Вывод:
## # A tibble: 7 x 3 ## lgID median_at_bat_league median_at_bat_league_no_zero ## <fctr> <dbl> <dbl> ## 1 AA 130 131 ## 2 AL 38 85 ## 3 FL 88 97 ## 4 NL 56 67 ## 5 PL 238 238 ## 6 UA 35 35 ## 7 <NA> 101 101
сумма
Еще одна полезная функция для агрегирования переменной — это sum ().
Вы можете проверить, какие лиги имеют больше homeruns.
## Sum data % > % group_by(lgID) % > % summarise(sum_homerun_league = sum(HR))
Вывод:
## # A tibble: 7 x 2 ## lgID sum_homerun_league ## <fctr> <int> ## 1 AA 341 ## 2 AL 29426 ## 3 FL 130 ## 4 NL 29817 ## 5 PL 98 ## 6 UA 46 ## 7 <NA> 41
Среднеквадратичное отклонение
Разброс данных рассчитывается со стандартным отклонением или sd () в R.
# Spread data % > % group_by(teamID) % > % summarise(sd_at_bat_league = sd(HR))
Вывод:
## # A tibble: 148 x 2 ## teamID sd_at_bat_league ## <fctr> <dbl> ## 1 ALT NA ## 2 ANA 8.7816395 ## 3 ARI 6.0765503 ## 4 ATL 8.5363863 ## 5 BAL 7.7350173 ## 6 BFN 1.3645163 ## 7 BFP 0.4472136 ## 8 BL1 0.6992059 ## 9 BL2 1.7106757 ## 10 BL3 1.0000000 ## # ... with 138 more rows
Есть много неравенства в количестве homerun, сделанном каждой командой.
Минимум и максимум
Вы можете получить доступ к минимуму и максимуму вектора с помощью функций min () и max ().
Приведенный ниже код возвращает наименьшее и наибольшее количество игр за сезон, в которые играл игрок.
# Min and max
data % > %
group_by(playerID) % > %
summarise(min_G = min(G),
max_G = max(G))
Вывод:
## # A tibble: 10,395 x 3 ## playerID min_G max_G ## <fctr> <int> ## 1 aardsda01 53 73 ## 2 aaronha01 120 156 ## 3 aasedo01 24 66 ## 4 abadfe01 18 18 ## 5 abadijo01 11 11 ## 6 abbated01 3 153 ## 7 abbeybe01 11 11 ## 8 abbeych01 80 132 ## 9 abbotgl01 5 23 ## 10 abbotji01 13 29 ## # ... with 10,385 more rows
подсчитывать
Подсчет наблюдений по группам — это всегда хорошая идея. С помощью R вы можете агрегировать число вхождений с помощью n ().
Например, приведенный ниже код вычисляет количество лет, проведенных каждым игроком.
# count observations data % > % group_by(playerID) % > % summarise(number_year = n()) % > % arrange(desc(number_year))
Вывод:
## # A tibble: 10,395 x 2 ## playerID number_year ## <fctr> <int> ## 1 pennohe01 11 ## 2 joosted01 10 ## 3 mcguide01 10 ## 4 rosepe01 10 ## 5 davisha01 9 ## 6 johnssi01 9 ## 7 kaatji01 9 ## 8 keelewi01 9 ## 9 marshmi01 9 ## 10 quirkja01 9 ## # ... with 10,385 more rows
Первый и последний
Вы можете выбрать первую, последнюю или n-ю позицию группы.
Например, вы можете найти первый и последний год каждого игрока.
# first and last data % > % group_by(playerID) % > % summarise(first_appearance = first(yearID), last_appearance = last(yearID))
Вывод:
## # A tibble: 10,395 x 3 ## playerID first_appearance last_appearance ## <fctr> <int> <int> ## 1 aardsda01 2009 2010 ## 2 aaronha01 1973 1975 ## 3 aasedo01 1986 1990 ## 4 abadfe01 2016 2016 ## 5 abadijo01 1875 1875 ## 6 abbated01 1905 1897 ## 7 abbeybe01 1894 1894 ## 8 abbeych01 1895 1897 ## 9 abbotgl01 1973 1979 ## 10 abbotji01 1992 1996 ## # ... with 10,385 more rows
n-е наблюдение
Функция nth () дополняет first () и last (). Вы можете получить доступ к n-му наблюдению в группе с индексом для возврата.
Например, вы можете отфильтровать только второй год, в котором играла команда.
# nth data % > % group_by(teamID) % > % summarise(second_game = nth(yearID, 2)) % > % arrange(second_game)
Вывод:
## # A tibble: 148 x 2 ## teamID second_game ## <fctr> <int> ## 1 BS1 1871 ## 2 CH1 1871 ## 3 FW1 1871 ## 4 NY2 1871 ## 5 RC1 1871 ## 6 BR1 1872 ## 7 BR2 1872 ## 8 CL1 1872 ## 9 MID 1872 ## 10 TRO 1872 ## # ... with 138 more rows
Различное количество наблюдений
Функция n () возвращает количество наблюдений в текущей группе. Закрытой функцией для n () является n_distinct (), которая считает количество уникальных значений.
В следующем примере вы складываете общее количество игроков, набранных командой за все периоды.
# distinct values data % > % group_by(teamID) % > % summarise(number_player = n_distinct(playerID)) % > % arrange(desc(number_player))
Код Объяснение
- group_by (teamID): группа по годам и командам
- суммировать (number_player = n_distinct (playerID)): подсчитать различное количество игроков по команде
- упорядочить (desc (number_player)): отсортировать данные по количеству игроков
Вывод:
## # A tibble: 148 x 2 ## teamID number_player ## <fctr> <int> ## 1 CHN 751 ## 2 SLN 729 ## 3 PHI 699 ## 4 PIT 683 ## 5 CIN 679 ## 6 BOS 647 ## 7 CLE 646 ## 8 CHA 636 ## 9 DET 623 ## 10 NYA 612 ## # ... with 138 more rows
Несколько групп
Сводная статистика может быть реализована среди нескольких групп.
# Multiple groups data % > % group_by(yearID, teamID) % > % summarise(mean_games = mean(G)) % > % arrange(desc(teamID, yearID))
Код Объяснение
- group_by (yearID, teamID): группа по годам и командам
- суммировать (mean_games = mean (G)): суммировать количество игроков
- упорядочить (desc (teamID, yearID)): отсортировать данные по команде и году
Вывод:
## # A tibble: 2,829 x 3 ## # Groups: yearID [146] ## yearID teamID mean_games ## <int> <fctr> <dbl> ## 1 1884 WSU 20.41667 ## 2 1891 WS9 46.33333 ## 3 1886 WS8 22.00000 ## 4 1887 WS8 51.00000 ## 5 1888 WS8 27.00000 ## 6 1889 WS8 52.42857 ## 7 1884 WS7 8.00000 ## 8 1875 WS6 14.80000 ## 9 1873 WS5 16.62500 ## 10 1872 WS4 4.20000 ## # ... with 2,819 more rows
Фильтр
Прежде чем вы собираетесь выполнить операцию, вы можете отфильтровать набор данных. Набор данных начинается в 1871 году, и анализ не нуждается в годах до 1980 года.
# Filter data % > % filter(yearID > 1980) % > % group_by(yearID) % > % summarise(mean_game_year = mean(G))
Код Объяснение
- фильтр (yearID> 1980): отфильтруйте данные, чтобы показать только соответствующие годы (т.е. после 1980 года)
- group_by (yearID): группа по годам
- суммировать (mean_game_year = mean (G)): суммировать данные
Вывод:
## # A tibble: 36 x 2 ## yearID mean_game_year ## <int> <dbl> ## 1 1981 40.64583 ## 2 1982 56.97790 ## 3 1983 60.25128 ## 4 1984 62.97436 ## 5 1985 57.82828 ## 6 1986 58.55340 ## 7 1987 48.74752 ## 8 1988 52.57282 ## 9 1989 58.16425 ## 10 1990 52.91556 ## # ... with 26 more rows
Ungroup
И последнее, но не менее важное: вам нужно удалить группировку, прежде чем вы захотите изменить уровень вычислений.
# Ungroup the data data % > % filter(HR > 0) % > % group_by(playerID) % > % summarise(average_HR_game = sum(HR) / sum(G)) % > % ungroup() % > % summarise(total_average_homerun = mean(average_HR_game))
Код Объяснение
- фильтр (HR> 0): исключить ноль homerun
- group_by (playerID): группировка по игроку
- суммировать (среднее_ч_игра = сумма (HR) / сумма (G)): вычислить средний запуск по игроку
- ungroup (): удалить группировку
- суммировать (total_average_homerun = среднее (среднее_HR_game)): суммировать данные
Вывод:
## # A tibble: 1 x 1 ## total_average_homerun ## <dbl> ## 1 0.06882226
Резюме
Если вы хотите вернуть резюме по группам, вы можете использовать:
# group by X1, X2, X3 group(df, X1, X2, X3)
вам нужно разгруппировать данные с помощью:
ungroup(df)
В таблице ниже приведены функции, которые вы изучили с помощью функции summaze ().
|
метод |
функция |
код |
|---|---|---|
|
жадный |
жадный |
summarise(df,mean_x1 = mean(x1)) |
|
медиана |
медиана |
summarise(df,median_x1 = median(x1)) |
|
сумма |
сумма |
summarise(df,sum_x1 = sum(x1)) |
|
среднеквадратичное отклонение |
SD |
summarise(df,sd_x1 = sd(x1)) |
|
межквартильный |
IQR |
summarise(df,interquartile_x1 = IQR(x1)) |
|
минимальный |
мин |
summarise(df,minimum_x1 = min(x1)) |
|
максимальная |
Максимум |
summarise(df,maximum_x1 = max(x1)) |
|
квантиль |
квантиль |
summarise(df,quantile_x1 = quantile(x1)) |
|
первое наблюдение |
первый |
summarise(df,first_x1 = first(x1)) |
|
последнее наблюдение |
прошлой |
summarise(df,last_x1 = last(x1)) |
|
n-е наблюдение |
энный |
summarise(df,nth_x1 = nth(x1, 2)) |
|
номер вхождения |
N |
summarise(df,n_x1 = n(x1)) |
|
количество различных случаев |
n_distinct |
summarise(df,n_distinct _x1 = n_distinct(x1)) |