Двустороннее отношение описывает отношение — или корреляцию — между двумя переменными, и. В этом руководстве мы обсудим концепцию корреляции и покажем, как ее можно использовать для измерения взаимосвязи между любыми двумя переменными.
Есть два основных метода для вычисления корреляции между двумя переменными.
- Пирсон: Параметрическая корреляция
- Спирмен: Непараметрическая корреляция
В этом уроке вы узнаете
Корреляции Пирсона
Метод корреляции Пирсона обычно используется в качестве первичной проверки взаимосвязи между двумя переменными.
Коэффициент корреляции , является показателем прочности линейной связи между двумя переменными и. Он рассчитывается следующим образом:
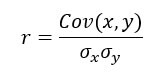
с
 т.е. стандартное отклонение
т.е. стандартное отклонение - т.е. стандартное отклонение
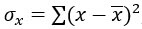
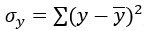
Корреляция колеблется между -1 и 1.
- Значение, близкое или равное 0, подразумевает небольшую или нулевую линейную зависимость между и.
- Напротив, чем ближе значение к 1 или -1, тем сильнее линейная зависимость.
Мы можем вычислить t-критерий следующим образом и проверить таблицу распределения со степенью свободы, равной:
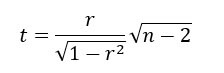
Спирман Ранг Корреляция
Ранговая корреляция сортирует наблюдения по рангу и вычисляет уровень сходства между рангом. Ранговая корреляция имеет то преимущество, что она устойчива к выбросам и не связана с распределением данных. Обратите внимание, что ранг корреляции подходит для порядковой переменной.
Ранговая корреляция Спирмена, всегда между -1 и 1 со значением, близким к конечности, указывает на сильную связь. Он рассчитывается следующим образом:
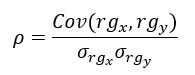
с заявленными ковариациями между рангом и. Знаменатель рассчитывает стандартные отклонения.
В R мы можем использовать функцию cor (). Требуется три аргумента и метод.
cor(x, y, method)
Аргументы :
- х: первый вектор
- у: второй вектор
- Метод: формула, используемая для вычисления корреляции. Три строковых значения:
- «Pearson»
- «Kendall»
- «Копьеносец»
Необязательный аргумент может быть добавлен, если векторы содержат отсутствующее значение: use = «complete.obs»
Мы будем использовать набор данных BudgetUK. Этот набор данных сообщает о распределении бюджета британских домохозяйств в период между 1980 и 1982 годами. Имеется 1519 наблюдений с десятью характеристиками, среди которых:
- wfood: разделить расходы на продукты питания
- wfuel: поделитесь расходами топлива
- wcloth: бюджетная доля расходов на одежду
- Walc: разделите расходы на алкоголь
- wtrans: разделите транспортные расходы
- wother: доля расходов на другие товары
- totexp: общие расходы домохозяйства в фунтах
- общий доход домохозяйства
- возраст: возраст домашнего хозяйства
- дети: количество детей
пример
library(dplyr)
PATH <-"https://raw.githubusercontent.com/guru99-edu/R-Programming/master/british_household.csv"
data <-read.csv(PATH)
filter(income < 500)
mutate(log_income = log(income),
log_totexp = log(totexp),
children_fac = factor(children, order = TRUE, labels = c("No", "Yes")))
select(-c(X,X.1, children, totexp, income))
glimpse(data)
Код Объяснение
- Сначала мы импортируем данные и рассмотрим функцию glimpse () из библиотеки dplyr.
- Три очка выше 500К, поэтому мы решили их исключить.
- Обычной практикой является преобразование денежной переменной в лог. Это помогает уменьшить влияние выбросов и уменьшает асимметрию в наборе данных.
Вывод:
## Observations: 1,516## Variables: 10 ## $ wfood <dbl> 0.4272, 0.3739, 0.1941, 0.4438, 0.3331, 0.3752, 0... ## $ wfuel <dbl> 0.1342, 0.1686, 0.4056, 0.1258, 0.0824, 0.0481, 0... ## $ wcloth <dbl> 0.0000, 0.0091, 0.0012, 0.0539, 0.0399, 0.1170, 0... ## $ walc <dbl> 0.0106, 0.0825, 0.0513, 0.0397, 0.1571, 0.0210, 0... ## $ wtrans <dbl> 0.1458, 0.1215, 0.2063, 0.0652, 0.2403, 0.0955, 0... ## $ wother <dbl> 0.2822, 0.2444, 0.1415, 0.2716, 0.1473, 0.3431, 0... ## $ age <int> 25, 39, 47, 33, 31, 24, 46, 25, 30, 41, 48, 24, 2... ## $ log_income <dbl> 4.867534, 5.010635, 5.438079, 4.605170, 4.605170,... ## $ log_totexp <dbl> 3.912023, 4.499810, 5.192957, 4.382027, 4.499810,... ## $ children_fac <ord> Yes, Yes, Yes, Yes, No, No, No, No, No, No, Yes, ...
Мы можем вычислить коэффициент корреляции между доходом и переменными wfood с помощью методов «Pearson» и «Spearman».
cor(data$log_income, data$wfood, method = "pearson")
вывод:
## [1] -0.2466986
cor(data$log_income, data$wfood, method = "spearman")
Вывод:
## [1] -0.2501252
Матрица корреляции
Двусторонняя корреляция — хорошее начало, но мы можем получить более широкую картину с помощью многомерного анализа. Корреляция со многими переменными изображена внутри корреляционной матрицы . Корреляционная матрица — это матрица, которая представляет корреляцию пар всех переменных.
Функция cor () возвращает корреляционную матрицу. Единственная разница с двумерной корреляцией заключается в том, что нам не нужно указывать, какие переменные. По умолчанию R вычисляет корреляцию между всеми переменными.
Обратите внимание, что корреляция не может быть вычислена для факторной переменной. Нам нужно убедиться, что мы отбрасываем категориальную особенность, прежде чем передать фрейм данных в cor ().
Матрица корреляции является симметричной, что означает, что значения выше диагонали имеют те же значения, что и ниже. Более наглядно показать половину матрицы.
Мы исключаем children_fac, потому что это переменная факторного уровня. cor не выполняет корреляцию по категориальной переменной.
# the last column of data is a factor level. We don't include it in the code mat_1 <-as.dist(round(cor(data[,1:9]),2)) mat_1
Код Объяснение
- cor (data): отобразить матрицу корреляции
- round (data, 2): округлить корреляционную матрицу с двумя десятичными знаками
- as.dist (): показывает только вторую половину
Вывод:
## wfood wfuel wcloth walc wtrans wother age log_income ## wfuel 0.11 ## wcloth -0.33 -0.25 ## walc -0.12 -0.13 -0.09 ## wtrans -0.34 -0.16 -0.19 -0.22 ## wother -0.35 -0.14 -0.22 -0.12 -0.29 ## age 0.02 -0.05 0.04 -0.14 0.03 0.02 ## log_income -0.25 -0.12 0.10 0.04 0.06 0.13 0.23 ## log_totexp -0.50 -0.36 0.34 0.12 0.15 0.15 0.21 0.49
Уровень значимости
Уровень значимости полезен в некоторых ситуациях, когда мы используем метод Пирсона или Спирмена. Функция rcorr () из библиотеки Hmisc вычисляет для нас значение p. Мы можем скачать библиотеку из conda и скопировать код, чтобы вставить ее в терминал:
conda install -c r r-hmisc
Функция rcorr () требует, чтобы кадр данных был сохранен в виде матрицы. Мы можем преобразовать наши данные в матрицу, прежде чем вычислять матрицу корреляции с p-значением.
library("Hmisc")
data_rcorr <-as.matrix(data[, 1: 9])
mat_2 <-rcorr(data_rcorr)
# mat_2 <-rcorr(as.matrix(data)) returns the same output
Объект списка mat_2 содержит три элемента:
- r: вывод корреляционной матрицы
- n: номер наблюдения
- P: p-значение
Нас интересует третий элемент, значение p. Распространено показывать матрицу корреляции с p-значением вместо коэффициента корреляции.
p_value <-round(mat_2[["P"]], 3) p_value
Код Объяснение
- mat_2 [[«P»]]: значения p хранятся в элементе с именем P
- round (mat_2 [[«P»]], 3): округлить элементы тремя цифрами
Вывод:
wfood wfuel wcloth walc wtrans wother age log_income log_totexp wfood NA 0.000 0.000 0.000 0.000 0.000 0.365 0.000 0 wfuel 0.000 NA 0.000 0.000 0.000 0.000 0.076 0.000 0 wcloth 0.000 0.000 NA 0.001 0.000 0.000 0.160 0.000 0 walc 0.000 0.000 0.001 NA 0.000 0.000 0.000 0.105 0 wtrans 0.000 0.000 0.000 0.000 NA 0.000 0.259 0.020 0 wother 0.000 0.000 0.000 0.000 0.000 NA 0.355 0.000 0 age 0.365 0.076 0.160 0.000 0.259 0.355 NA 0.000 0 log_income 0.000 0.000 0.000 0.105 0.020 0.000 0.000 NA 0 log_totexp 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 NA
Визуализировать матрицу корреляции
Тепловая карта — это еще один способ показать корреляционную матрицу. Библиотека GGally является расширением ggplot2. В настоящее время он не доступен в библиотеке conda. Мы можем установить прямо в консоли.
install.packages("GGally")
Библиотека включает в себя различные функции для отображения сводной статистики, такой как корреляция и распределение всех переменных в матрице.
Функция ggcorr () имеет множество аргументов. Мы представим только те аргументы, которые мы будем использовать в руководстве:
Функция ggcorr
ggcorr(df, method = c("pairwise", "pearson"),
nbreaks = NULL, digits = 2, low = "#3B9AB2",
mid = "#EEEEEE", high = "#F21A00",
geom = "tile", label = FALSE,
label_alpha = FALSE)
Аргументы:
- df : набор данных используется
- Метод : Формула для расчета корреляции. По умолчанию попарно и Пирсон вычисляются
- nbreaks : возвращает категориальный диапазон для окрашивания коэффициентов. По умолчанию нет перерывов и цветовой градиент непрерывен
- цифры : округлить коэффициент корреляции. По умолчанию установлено значение 2
- низкий : контролировать нижний уровень окраски
- средний : контроль среднего уровня окраски
- высокий : контролировать высокий уровень окраски
- geom : управление формой геометрического аргумента. По умолчанию «тайл»
- label : логическое значение. Показать или нет метку. По умолчанию установлено значение «ЛОЖЬ»
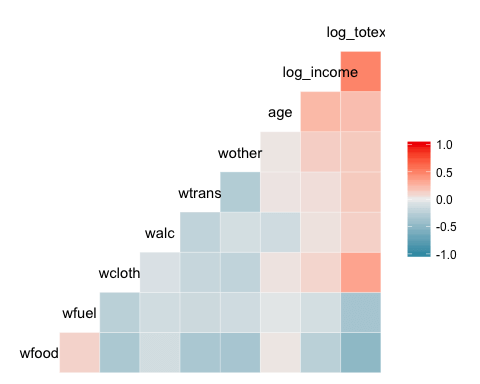
Основная тепловая карта
Самым основным сюжетом пакета является тепловая карта. Легенда графика показывает цвет градиента от — 1 до 1, причем горячий цвет указывает на сильную положительную корреляцию, а холодный цвет — на отрицательную корреляцию.
library(GGally) ggcorr(data)
Код Объяснение
- ggcorr (данные): необходим только один аргумент, который является именем фрейма данных. Переменные уровня фактора не включены в график.
Вывод:
Добавить контроль на карту тепла
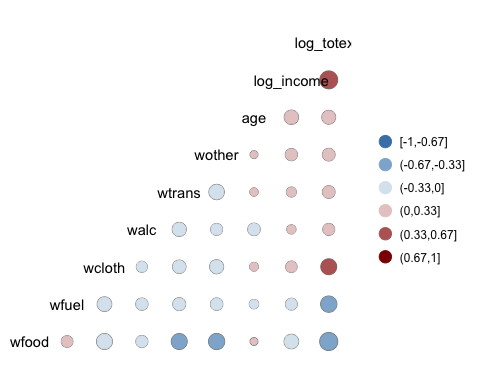
Мы можем добавить больше элементов управления на график.
ggcorr(data,
nbreaks = 6,
low = "steelblue",
mid = "white",
high = "darkred",
geom = "circle")
Код Объяснение
- nbreaks = 6: разбить легенду с 6 рангами.
- low = «steelblue»: используйте более светлые цвета для отрицательной корреляции
- mid = «white»: использовать белые цвета для корреляции средних диапазонов
- high = «darkred»: использовать темные цвета для положительной корреляции
- geom = «circle»: используйте круг в качестве формы окон на тепловой карте. Размер круга пропорционален абсолютному значению корреляции.
Вывод:
Добавьте ярлык на карту тепла
GGally позволяет нам добавлять метки внутри окон.
ggcorr(data,
nbreaks = 6,
label = TRUE,
label_size = 3,
color = "grey50")
Код Объяснение
- label = TRUE: добавить значения коэффициентов корреляции внутри тепловой карты.
- color = «grey50»: выберите цвет, т.е. серый
- label_size = 3: установить размер метки равным 3
Вывод:
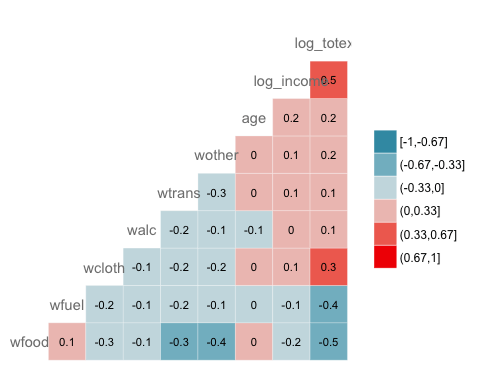
ggpairs
Наконец, мы представляем еще одну функцию из библиотеки GGaly. Ggpair. Он создает график в матричном формате. Мы можем отобразить три вида вычислений в одном графике. Матрица является измерением, равным количеству наблюдений. Верхняя / нижняя часть отображает окна и по диагонали. Мы можем контролировать, какую информацию мы хотим показать в каждой части матрицы. Формула для ggpair:
ggpair(df, columns = 1: ncol(df), title = NULL,
upper = list(continuous = "cor"),
lower = list(continuous = "smooth"),
mapping = NULL)
Аргументы :
- df : набор данных используется
- столбцы : выберите столбцы, чтобы нарисовать график
- title : Включить заголовок
- верхний : Управляйте прямоугольниками выше диагонали графика. Необходимо указать тип вычислений или график для возврата. Если непрерывный = «cor», мы просим R вычислить корреляцию. Обратите внимание, что аргумент должен быть списком. Другие аргументы могут быть использованы, см. [Vignette] («http://ggobi.github.io/ggally/#custom_functions») для получения дополнительной информации.
- Ниже : установите флажки ниже диагонали.
- Отображение : указывает на эстетику графика. Например, мы можем вычислить график для разных групп.
Двусторонний анализ с ggpair с группировкой
Следующий график отображает три информации:
- Матрица корреляции между log_totexp, log_income, возрастом и переменным wtrans сгруппирована по тому, есть ли в семье ребенок или нет.
- График распределения каждой переменной по группам
- Показать график рассеяния с трендом по группам
library(ggplot2)
ggpairs(data, columns = c("log_totexp", "log_income", "age", "wtrans"), title = "Bivariate analysis of revenue expenditure by the British household", upper = list(continuous = wrap("cor",
size = 3)),
lower = list(continuous = wrap("smooth",
alpha = 0.3,
size = 0.1)),
mapping = aes(color = children_fac))
Код Объяснение
- columns = c («log_totexp», «log_income», «age», «wtrans»): выберите переменные для отображения на графике
- title = «Двусторонний анализ расходов доходов британской семьи»: Добавить заголовок
- upper = list (): Управление верхней частью графика. Т.е. над диагональю
- непрерывный = обтекание («cor», размер = 3)): вычислить коэффициент корреляции. Мы оборачиваем аргумент непрерывным внутри функции wrap (), чтобы контролировать эстетику графа (то есть size = 3) -lower = list (): управлять нижней частью графа. Т.е. ниже диагонали.
- непрерывный = обтекание («гладкий», альфа = 0,3, размер = 0,1): добавить график рассеяния с линейным трендом. Мы обертываем непрерывный аргумент внутри функции wrap (), чтобы контролировать эстетику графа (то есть размер = 0,1, альфа = 0,3)
- mapping = aes (color = children_fac): мы хотим, чтобы каждая часть графика была сгруппирована с помощью переменной children_fac, которая является категориальной переменной, принимающей значение 1, если в семье нет детей, и 2 в противном случае
Вывод:
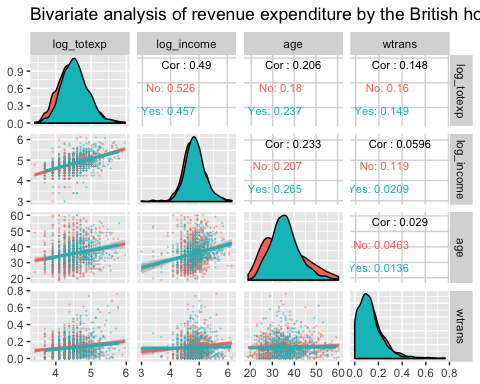
Двусторонний анализ с ggpair с частичной группировкой
График ниже немного отличается. Мы меняем положение отображения внутри верхнего аргумента.
ggpairs(data, columns = c("log_totexp", "log_income", "age", "wtrans"),
title = "Bivariate analysis of revenue expenditure by the British household",
upper = list(continuous = wrap("cor",
size = 3),
mapping = aes(color = children_fac)),
lower = list(
continuous = wrap("smooth",
alpha = 0.3,
size = 0.1))
)
Код Объяснение
- Точно такой же код, как и в предыдущем примере, за исключением:
- mapping = aes (color = children_fac): переместить список в верхний = list (). Мы только хотим, чтобы вычисления складывались по группам в верхней части графика.
Вывод:

Резюме
Мы можем суммировать функцию в таблице ниже:
|
библиотека |
Задача |
метод |
код |
|---|---|---|---|
|
База |
двумерная корреляция |
Pearson |
cor(dfx2, method = "pearson") |
|
База |
двумерная корреляция |
копьеносец |
cor(dfx2, method = "spearman") |
|
База |
Многомерная корреляция |
пирсон |
cor(df, method = "pearson") |
|
База |
Многомерная корреляция |
копьеносец |
cor(df, method = "spearman") |
|
Hmisc |
Значение P |
rcorr(as.matrix(data[,1:9]))[["P"]] |
|
|
Ggally |
Тепловая карта |
ggcorr(df) |
|
|
Многомерные участки |
cf code below |