Очень часто у нас есть данные из нескольких источников. Чтобы выполнить анализ, нам нужно объединить два кадра данных вместе с одной или несколькими общими ключевыми переменными .
В этом уроке вы узнаете
Полное совпадение
Полное совпадение возвращает значения, которые имеют аналог в таблице назначения. Значения, которые не совпадают, не будут возвращены в новом фрейме данных. Частичное совпадение, однако, возвращает отсутствующие значения как NA.
Мы увидим простое внутреннее соединение . Ключевое слово inner join выбирает записи, которые имеют совпадающие значения в обеих таблицах. Чтобы объединить два набора данных, мы можем использовать функцию merge (). Мы будем использовать три аргумента:
merge(x, y, by.x = x, by.y = y)Arguments: -x: The origin data frame -y: The data frame to merge -by.x: The column used for merging in x data frame. Column x to merge on -by.y: The column used for merging in y data frame. Column y to merge on
Пример:
Создать первый набор данных с переменными
- фамилия
- Национальность
Создать второй набор данных с переменными
- фамилия
- фильмы
Общей ключевой переменной является фамилия. Мы можем объединить обе данные и проверить, равна ли размерность 7х3.
Мы добавляем stringsAsFactors = FALSE во фрейм данных, потому что мы не хотим, чтобы R преобразовывала строку как фактор, мы хотим, чтобы переменная рассматривалась как символ.
# Create origin dataframe(
producers <- data.frame(
surname = c("Spielberg","Scorsese","Hitchcock","Tarantino","Polanski"),
nationality = c("US","US","UK","US","Poland"),
stringsAsFactors=FALSE)
# Create destination dataframe
movies <- data.frame(
surname = c("Spielberg",
"Scorsese",
"Hitchcock",
"Hitchcock",
"Spielberg",
"Tarantino",
"Polanski"),
title = c("Super 8",
"Taxi Driver",
"Psycho",
"North by Northwest",
"Catch Me If You Can",
"Reservoir Dogs","Chinatown"),
stringsAsFactors=FALSE)
# Merge two datasets
m1 <- merge(producers, movies, by.x = "surname")
m1
dim(m1)
Вывод:
surname nationality title 1 Hitchcock UK Psycho 2 Hitchcock UK North by Northwest 3 Polanski Poland Chinatown 4 Scorsese US Taxi Driver 5 Spielberg US Super 8 6 Spielberg US Catch Me If You Can 7 Tarantino US Reservoir Dogs
Давайте объединяем фреймы данных, когда переменные общего ключа имеют разные имена.
Мы меняем фамилию на имя в кадре данных фильмов. Мы используем функцию identifier (x1, x2), чтобы проверить, идентичны ли оба кадра данных.
# Change name of ` movies ` dataframe colnames(movies)[colnames(movies) == 'surname'] <- 'name' # Merge with different key value m2 <- merge(producers, movies, by.x = "surname", by.y = "name") # Print head of the data head(m2)
Вывод:
##surname nationality title ## 1 Hitchcock UK Psycho ## 2 Hitchcock UK North by Northwest ## 3 Polanski Poland Chinatown ## 4 Scorsese US Taxi Driver ## 5 Spielberg US Super 8 ## 6 Spielberg US Catch Me If You Can
# Check if data are identical identical(m1, m2)
Вывод:
## [1] TRUE
Это показывает, что операция объединения выполняется, даже если имена столбцов отличаются.
Частичное совпадение
Неудивительно, что два кадра данных не имеют одинаковых общих ключевых переменных. При полном совпадении фрейм данных возвращает только строки, найденные во фрейме данных x и y. При частичном объединении можно сохранить строки без совпадающих строк в другом фрейме данных. Эти строки будут иметь NA в тех столбцах, которые обычно заполняются значениями от y. Мы можем сделать это, установив all.x = TRUE.
Например, мы можем добавить нового производителя, Лукаса, во фрейм данных производителя без ссылок на фильмы в фрейме данных фильмов. Если мы установим all.x = FALSE, R объединит только совпадающие значения в обоих наборах данных. В нашем случае продюсер Лукас не присоединится к слиянию, так как оно отсутствует в одном наборе данных.
Давайте посмотрим размерность каждого вывода, когда мы указываем all.x = TRUE, а когда нет.
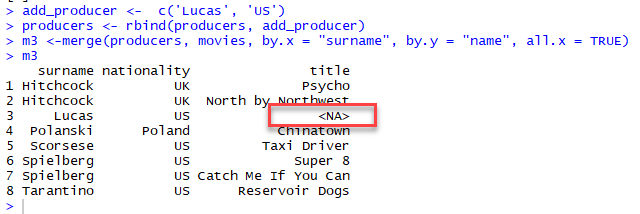
# Create a new producer
add_producer <- c('Lucas', 'US')
# Append it to the ` producer` dataframe
producers <- rbind(producers, add_producer)
# Use a partial merge
m3 <-merge(producers, movies, by.x = "surname", by.y = "name", all.x = TRUE)
m3
Вывод:
# Compare the dimension of each data frame dim(m1)
Вывод:
## [1] 7 3
dim(m2)
Вывод:
## [1] 7 3
dim(m3)
Вывод:
## [1] 8 3
Как мы видим, размерность нового фрейма данных 8×3 по сравнению с 7×3 для m1 и m2. R включает NA для пропавшего автора во фрейме данных книг.