Что такое функция в R?
Функция , в среде программирования, представляет собой набор инструкций. Программист создает функцию, чтобы избежать повторения одной и той же задачи или уменьшить сложность.
Функция должна быть
- написано для выполнения указанной задачи
- может включать или не включать аргументы
- содержать тело
- может возвращать или не возвращать одно или несколько значений.
Общий подход к функции состоит в том, чтобы использовать часть аргумента в качестве входных данных , передать часть тела и, наконец, вернуть выходные данные . Синтаксис функции следующий:
function (arglist) {
#Function body
}
В этом уроке мы узнаем
- R важные встроенные функции
- Общие функции
- Математические функции
- Статистические функции
- Написать функцию в R
- Когда мы должны написать функцию?
- Функции с условием
R важные встроенные функции
В R. Есть много встроенных функций в R. R сопоставляет ваши входные параметры с аргументами функции, либо по значению, либо по положению, а затем выполняет тело функции. Аргументы функции могут иметь значения по умолчанию: если вы не укажете эти аргументы, R примет значение по умолчанию.
Примечание . Исходный код функции можно увидеть, запустив имя самой функции в консоли.
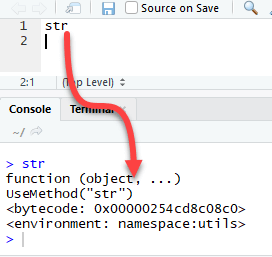
Мы увидим три группы функций в действии
- Общая функция
- Математическая функция
- Статистическая функция
Общие функции
Мы уже знакомы с общими функциями, такими как функции cbind (), rbind (), range (), sort (), order (). Каждая из этих функций имеет определенную задачу, принимает аргументы для возврата вывода. Ниже приведены важные функции, которые нужно знать:
функция diff ()
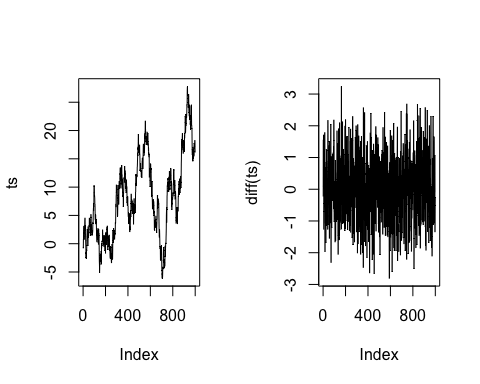
Если вы работаете с временными рядами , вам нужно фиксировать ряды, принимая их значения запаздывания . Стационарный процесс позволяет постоянно среднее значение, дисперсия и автокорреляция с течением времени. Это в основном улучшает прогнозирование временного ряда. Это легко сделать с помощью функции diff (). Мы можем построить случайные данные временных рядов с трендом, а затем использовать функцию diff () для стационарного ряда. Функция diff () принимает один аргумент, вектор и возвращает подходящую задержанную и повторенную разницу.
Примечание : нам часто нужно создавать случайные данные, но для изучения и сравнения мы хотим, чтобы числа были одинаковыми на разных машинах. Чтобы все мы генерировали одни и те же данные, мы используем функцию set.seed () с произвольными значениями 123. Функция set.seed () генерируется в процессе генерации псевдослучайных чисел, которая заставляет все современные компьютеры иметь одинаковую последовательность чисел. Если мы не используем функцию set.seed (), мы все будем иметь разную последовательность чисел.
set.seed(123) ## Create the data x = rnorm(1000) ts <- cumsum(x) ## Stationary the serie diff_ts <- diff(ts) par(mfrow=c(1,2)) ## Plot the series plot(ts, type='l') plot(diff(ts), type='l')
функция length ()
Во многих случаях мы хотим знать длину вектора для вычисления или для использования в цикле for. Функция length () считает количество строк в векторе x. Следующие коды импортируют набор данных автомобилей и возвращают количество строк.
Примечание : length () возвращает количество элементов в векторе. Если функция передается в матрицу или фрейм данных, возвращается число столбцов.
dt <- cars ## number columns length(dt)
Вывод:
## [1] 1
## number rows length(dt[,1])
Вывод:
## [1] 50
Математические функции
R имеет массив математических функций.
| оператор | Описание |
|---|---|
| абс (х) | Принимает абсолютное значение х |
| Журнал (х, база = у) | Принимает логарифм x с основанием y; если база не указана, возвращает натуральный логарифм |
| ехр (х) | Возвращает экспоненту х |
| SQRT (х) | Возвращает квадратный корень из х |
| факториала (х) | Возвращает факториал x (x!) |
# sequence of number from 44 to 55 both including incremented by 1 x_vector <- seq(45,55, by = 1) #logarithm log(x_vector)
Вывод:
## [1] 3.806662 3.828641 3.850148 3.871201 3.891820 3.912023 3.931826 ## [8] 3.951244 3.970292 3.988984 4.007333
#exponential exp(x_vector)
#squared root sqrt(x_vector)
Вывод:
## [1] 6.708204 6.782330 6.855655 6.928203 7.000000 7.071068 7.141428 ## [8] 7.211103 7.280110 7.348469 7.416198
#factorial factorial(x_vector)
Вывод:
## [1] 1.196222e+56 5.502622e+57 2.586232e+59 1.241392e+61 6.082819e+62 ## [6] 3.041409e+64 1.551119e+66 8.065818e+67 4.274883e+69 2.308437e+71 ## [11] 1.269640e+73
Статистические функции
Стандартная установка R содержит широкий спектр статистических функций. В этом уроке мы кратко рассмотрим наиболее важную функцию.
Основные статистические функции
|
оператор |
Описание |
|---|---|
|
Среднее (х) |
Среднее значение х |
|
медиана (х) |
Медиана х |
|
вар (х) |
Дисперсия х |
|
сд (х) |
Стандартное отклонение х |
|
шкала (х) |
Стандартные оценки (Z-оценки) х |
|
квантиль (х) |
Квартили х |
|
Резюме (х) |
Резюме x: среднее, минимальное, максимальное и т. Д. |
speed <- dt$speed speed # Mean speed of cars dataset mean(speed)
Вывод:
## [1] 15.4
# Median speed of cars dataset median(speed)
Вывод:
## [1] 15
# Variance speed of cars dataset var(speed)
Вывод:
## [1] 27.95918
# Standard deviation speed of cars dataset sd(speed)
Вывод:
## [1] 5.287644
# Standardize vector speed of cars dataset head(scale(speed), 5)
Вывод:
## [,1] ## [1,] -2.155969 ## [2,] -2.155969 ## [3,] -1.588609 ## [4,] -1.588609 ## [5,] -1.399489
# Quantile speed of cars dataset quantile(speed)
Вывод:
## 0% 25% 50% 75% 100% ## 4 12 15 19 25
# Summary speed of cars dataset summary(speed)
Вывод:
## Min. 1st Qu. Median Mean 3rd Qu. Max. ## 4.0 12.0 15.0 15.4 19.0 25.0
До этого момента мы узнали много встроенных функций R.
Примечание : будьте осторожны с классом аргумента, то есть с числовым, логическим или строковым. Например, если нам нужно передать строковое значение, нам нужно заключить строку в кавычку: «ABC».
Написать функцию в R
В некоторых случаях нам нужно написать собственную функцию, потому что мы должны выполнить определенную задачу, а готовой функции не существует. Пользовательская функция включает в себя имя , аргументы и тело .
function.name <- function(arguments)
{
computations on the arguments
some other code
}
Примечание . Рекомендуется называть пользовательскую функцию отличной от встроенной функции. Это позволяет избежать путаницы.
Функция с одним аргументом
В следующем фрагменте мы определяем простую квадратную функцию. Функция принимает значение и возвращает квадрат значения.
square_function<- function(n)
{
# compute the square of integer `n`
n^2
}
# calling the function and passing value 4
square_function(4)
Объяснение кода:
- Функция называется square_function; это можно назвать как мы хотим.
- Он получает аргумент «n». Мы не указали тип переменной, чтобы пользователь мог передать целое число, вектор или матрицу
- Функция принимает вход «n» и возвращает квадрат ввода.
Когда вы закончите использовать функцию, мы можем удалить ее с помощью функции rm ().
# после создания функции
rm(square_function) square_function
На консоли мы видим сообщение об ошибке: Ошибка: объект ‘square_function’ не найден, сообщая, что функция не существует.
Окружающая среда
В R среда представляет собой набор объектов, таких как функции, переменные, фрейм данных и т. Д.
R открывает окружение каждый раз, когда запрашивается Rstudio.
Доступной средой верхнего уровня является глобальная среда , называемая R_GlobalEnv. И у нас есть местная среда.
Мы можем перечислить содержимое текущей среды.
ls(environment())
Вывод
## [1] "diff_ts" "dt" "speed" "square_function" ## [5] "ts" "x" "x_vector"
Вы можете увидеть все переменные и функции, созданные в R_GlobalEnv.
Приведенный выше список будет отличаться для вас в зависимости от исторического кода, который вы выполняете в R Studio.
Обратите внимание, что аргумент функции square_function n не находится в этой глобальной среде .
Новая среда создается для каждой функции. В приведенном выше примере функция square_function () создает новую среду внутри глобальной среды.
Чтобы прояснить разницу между глобальной и локальной средой , давайте изучим следующий пример
Эти функции принимают значение x в качестве аргумента и добавляют его к y, определяемому снаружи и внутри функции.
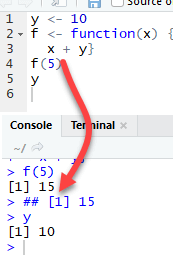
Функция f возвращает результат 15. Это потому, что у определяется в глобальной среде. Любая переменная, определенная в глобальной среде, может использоваться локально. Переменная y имеет значение 10 во время всех вызовов функций и доступна в любое время.
Посмотрим, что произойдет, если переменная y определена внутри функции.
Нам нужно сбросить `y` перед запуском этого кода, используя rm r
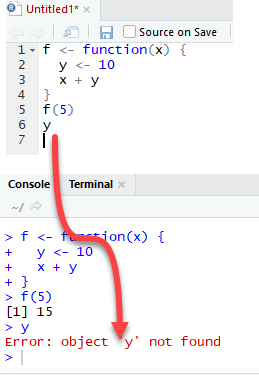
Выход также равен 15, когда мы вызываем f (5), но возвращает ошибку, когда мы пытаемся вывести значение y. Переменная y не находится в глобальной среде.
Наконец, R использует самое последнее определение переменной для передачи внутри тела функции. Давайте рассмотрим следующий пример:
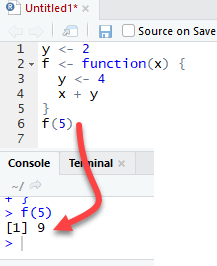
R игнорирует значения y, определенные вне функции, потому что мы явно создали переменную y внутри тела функции.
Функция нескольких аргументов
Мы можем написать функцию с более чем одним аргументом. Рассмотрим функцию под названием «раз». Это простая функция, умножающая две переменные.
times <- function(x,y) {
x*y
}
times(2,4)
Вывод:
## [1] 8
Когда мы должны написать функцию?
Специалист по данным должен сделать много повторяющихся задач. Большую часть времени мы копируем и вставляем куски кода многократно. Например, нормализация переменной настоятельно рекомендуется, прежде чем мы запустим алгоритм машинного обучения. Формула для нормализации переменной:
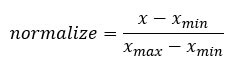
Мы уже знаем, как использовать функции min () и max () в R. Мы используем библиотеку tibble для создания фрейма данных. Tibble — пока самая удобная функция для создания набора данных с нуля.
library(tibble) # Create a data frame data_frame <- tibble( c1 = rnorm(50, 5, 1.5), c2 = rnorm(50, 5, 1.5), c3 = rnorm(50, 5, 1.5), )
Мы продолжим в два шага, чтобы вычислить функцию, описанную выше. На первом шаге мы создадим переменную с именем c1_norm, которая будет масштабировать c1. На втором шаге мы просто копируем и вставляем код c1_norm и меняем его на c2 и c3.
Деталь функции со столбцом c1:
Номинатор:: data_frame $ c1 -min (data_frame $ c1))
Знаменатель: max (data_frame $ c1) -min (data_frame $ c1))
Следовательно, мы можем разделить их, чтобы получить нормализованное значение столбца c1:
(data_frame$c1 -min(data_frame$c1))/(max(data_frame$c1)-min(data_frame$c1))
Мы можем создать c1_norm, c2_norm и c3_norm:
Create c1_norm: rescaling of c1 data_frame$c1_norm <- (data_frame$c1 -min(data_frame$c1))/(max(data_frame$c1)-min(data_frame$c1)) # show the first five values head(data_frame$c1_norm, 5)
Вывод:
## [1] 0.3400113 0.4198788 0.8524394 0.4925860 0.5067991
Оно работает. Мы можем скопировать и вставить
data_frame$c1_norm <- (data_frame$c1 -min(data_frame$c1))/(max(data_frame$c1)-min(data_frame$c1))
затем измените c1_norm на c2_norm и c1 на c2. Мы делаем то же самое, чтобы создать c3_norm
data_frame$c2_norm <- (data_frame$c2 - min(data_frame$c2))/(max(data_frame$c2)-min(data_frame$c2)) data_frame$c3_norm <- (data_frame$c3 - min(data_frame$c3))/(max(data_frame$c3)-min(data_frame$c3))
Мы отлично перемасштабировали переменные c1, c2 и c3.
Однако этот метод подвержен ошибкам. Мы могли бы скопировать и забыть изменить имя столбца после вставки. Поэтому рекомендуется писать функцию каждый раз, когда вам нужно вставить один и тот же код более двух раз. Мы можем преобразовать код в формулу и вызывать его всякий раз, когда это необходимо. Чтобы написать нашу собственную функцию, нам нужно дать:
- Название: нормализовать.
- количество аргументов: нам нужен только один аргумент, который является столбцом, который мы используем в наших вычислениях.
- Тело: это просто формула, которую мы хотим вернуть.
Мы продолжим шаг за шагом, чтобы создать функцию нормализации.
Шаг 1) Создаем номинатор , который есть. В R мы можем хранить знаменатель в переменной следующим образом:
nominator <- x-min(x)
Шаг 2) Вычислим знаменатель: . Мы можем повторить идею шага 1 и сохранить вычисления в переменной:
denominator <- max(x)-min(x)
Шаг 3) Мы выполняем разделение между знаменателем и знаменателем.
normalize <- nominator/denominator
Шаг 4) Чтобы вернуть значение вызывающей функции, нам нужно передать нормализацию внутри return (), чтобы получить выходные данные функции.
return(normalize)
Шаг 5) Мы готовы использовать функцию, завернув все в скобки.
normalize <- function(x){
# step 1: create the nominator
nominator <- x-min(x)
# step 2: create the denominator
denominator <- max(x)-min(x)
# step 3: divide nominator by denominator
normalize <- nominator/denominator
# return the value
return(normalize)
}
Давайте проверим нашу функцию с переменной c1:
normalize(data_frame$c1)
Работает отлично. Мы создали нашу первую функцию.
Функции являются более всеобъемлющим способом выполнения повторяющихся задач. Мы можем использовать формулу нормализации для разных столбцов, как показано ниже:
data_frame$c1_norm_function <- normalize (data_frame$c1) data_frame$c2_norm_function <- normalize (data_frame$c2) data_frame$c3_norm_function <- normalize (data_frame$c3)
Хотя пример прост, мы можем вывести силу формулы. Приведенный выше код легче читается и особенно позволяет избежать ошибок при вставке кодов.
Функции с условием
Иногда нам нужно включить условия в функцию, чтобы код мог возвращать разные выходные данные.
В задачах машинного обучения нам нужно разделить набор данных между набором поездов и тестовым набором. Набор поездов позволяет алгоритму учиться на данных. Чтобы протестировать производительность нашей модели, мы можем использовать тестовый набор для возврата показателя производительности. R не имеет функции для создания двух наборов данных. Мы можем написать нашу собственную функцию для этого. Наша функция принимает два аргумента и называется split_data (). Идея проста: мы умножаем длину набора данных (т.е. количество наблюдений) на 0,8. Например, если мы хотим разделить набор данных 80/20, а наш набор данных содержит 100 строк, тогда наша функция умножит 0,8 * 100 = 80. 80 строк будут выбраны, чтобы стать нашими данными обучения.
Мы будем использовать набор данных airquality для проверки нашей пользовательской функции. Набор данных airquality состоит из 153 строк. Мы можем видеть это с кодом ниже:
nrow(airquality)
Вывод:
## [1] 153
Мы будем действовать следующим образом:
split_data <- function(df, train = TRUE) Arguments: -df: Define the dataset -train: Specify if the function returns the train set or test set. By default, set to TRUE
Наша функция имеет два аргумента. Поезд аргументов является логическим параметром. Если установлено значение TRUE, наша функция создает набор данных train, в противном случае создает тестовый набор данных.
Мы можем действовать так же, как и в случае с функцией normalize (). Мы пишем код, как если бы это был только одноразовый код, а затем помещаем все с условием в тело для создания функции.
Шаг 1:
Нам нужно вычислить длину набора данных. Это делается с помощью функции nrow (). Nrow возвращает общее количество строк в наборе данных. Мы называем переменную длину.
length<- nrow(airquality) length
Вывод:
## [1] 153
Шаг 2:
Умножаем длину на 0,8. Он вернет количество строк для выбора. Должно быть 153 * 0,8 = 122,4
total_row <- length*0.8 total_row
Вывод:
## [1] 122.4
Мы хотим выбрать 122 строки среди 153 строк в наборе данных качества воздуха. Мы создаем список, содержащий значения от 1 до total_row. Мы сохраняем результат в переменной с именем split
split <- 1:total_row split[1:5]
Вывод:
## [1] 1 2 3 4 5
split выбирает первые 122 строки из набора данных. Например, мы можем видеть, что наша переменная split собирает значения 1, 2, 3, 4, 5 и так далее. Эти значения будут индексом, когда мы выберем строки для возврата.
Шаг 3:
Нам нужно выбрать строки в наборе данных airquality на основе значений, хранящихся в переменной split. Это делается так:
train_df <- airquality[split, ] head(train_df)
Вывод:
##[1] Ozone Solar.R Wind Temp Month Day ##[2] 51 13 137 10.3 76 6 20 ##[3] 15 18 65 13.2 58 5 15 ##[4] 64 32 236 9.2 81 7 3 ##[5] 27 NA NA 8.0 57 5 27 ##[6] 58 NA 47 10.3 73 6 27 ##[7] 44 23 148 8.0 82 6 13
Шаг 4:
Мы можем создать тестовый набор данных, используя оставшиеся строки, 123: 153. Это делается с помощью — перед разделением.
test_df <- airquality[-split, ] head(test_df)
Вывод:
##[1] Ozone Solar.R Wind Temp Month Day ##[2] 123 85 188 6.3 94 8 31 ##[3] 124 96 167 6.9 91 9 1 ##[4] 125 78 197 5.1 92 9 2 ##[5] 126 73 183 2.8 93 9 3 ##[6] 127 91 189 4.6 93 9 4 ##[7] 128 47 95 7.4 87 9 5
Шаг 5:
Мы можем создать условие внутри тела функции. Помните, у нас есть последовательность аргументов, которая по умолчанию имеет логическое значение TRUE для возврата набора поездов. Чтобы создать условие, мы используем синтаксис if:
if (train ==TRUE){
train_df <- airquality[split, ]
return(train)
} else {
test_df <- airquality[-split, ]
return(test)
}
Вот и все, мы можем написать функцию. Нам нужно только изменить airquality на df, потому что мы хотим попробовать нашу функцию для любого фрейма данных, а не только для airquality:
split_data <- function(df, train = TRUE){
length<- nrow(df)
total_row <- length *0.8
split <- 1:total_row
if (train ==TRUE){
train_df <- df[split, ]
return(train_df)
} else {
test_df <- df[-split, ]
return(test_df)
}
}
Давайте попробуем нашу функцию для набора данных airquality. у нас должен быть один поезд с 122 рядами и тестовый набор с 31 строкой.
train <- split_data(airquality, train = TRUE) dim(train)
Вывод:
## [1] 122 6
test <- split_data(airquality, train = FALSE) dim(test)
Вывод:
## [1] 31 6