Данные могут существовать в разных форматах. Для каждого формата R имеет определенную функцию и аргумент. В этом руководстве объясняется, как импортировать данные в R.
В этом уроке вы узнаете
- Читать CSV
- Чтение файлов Excel
- readxl_example ()
- read_excel ()
- excel_sheets ()
- Импорт данных из другого статистического программного обеспечения
- Читать сас
- Читать STATA
- Читать SPSS
- Лучшие практики для импорта данных
Читать CSV
Одним из наиболее распространенных хранилищ данных являются форматы файлов .csv (значения, разделенные запятыми). R загружает массив библиотек во время запуска, включая пакет utils. Этот пакет удобен для открытия CSV-файлов в сочетании с функцией reading.csv (). Вот синтаксис для read.csv
read.csv(file, header = TRUE, sep = ",")
Аргумент :
- file : PATH, где хранится файл
- header : подтвердите, имеет ли файл заголовок или нет, по умолчанию заголовок установлен в TRUE
- sep : символ, используемый для разделения переменной. По умолчанию `,`.
Мы будем читать данные файла с именем mtcats. CSV-файл хранится в Интернете. Если ваш файл .csv хранится локально, вы можете заменить PATH внутри фрагмента кода. Не забудьте обернуть его внутри ». PATH должен быть строковым значением.
Для пользователя Mac путь к папке загрузки:
"/Users/USERNAME/Downloads/FILENAME.csv"
Для пользователей Windows:
"C:\Users\USERNAME\Downloads\FILENAME.csv"
Обратите внимание, что мы всегда должны указывать расширение имени файла.
- .csv
- .xlsx
- .текст
- …
PATH <- 'https://raw.githubusercontent.com/guru99-edu/R-Programming/master/mtcars.csv' df <- read.csv(PATH, header = TRUE, sep = ',') length(df)
Вывод:
## [1] 12
class(df$X)
Вывод:
## [1] "factor"
R по умолчанию возвращает значения символов как фактор. Мы можем отключить этот параметр, добавив stringsAsFactors = FALSE.
PATH <- 'https://raw.githubusercontent.com/guru99-edu/R-Programming/master/mtcars.csv' df <-read.csv(PATH, header =TRUE, sep = ',', stringsAsFactors =FALSE) class(df$X)
Вывод:
## [1] "character"
Класс для переменной X теперь является символом.
Чтение файлов Excel
Файлы Excel очень популярны среди аналитиков данных. Таблицы просты в работе и гибки. R оснащен библиотекой readxl для импорта электронных таблиц Excel.
Используйте этот код
require(readxl)
чтобы проверить, установлен ли readxl на вашем компьютере. Если вы устанавливаете r с помощью r-conda-essential, библиотека уже установлена. Вы должны увидеть в окне команд:
Вывод:
Loading required package: readxl.
Если пакет не выходит, вы можете установить его с библиотекой conda или в терминале, используйте conda install -c mittner r-readxl.
Используйте следующую команду, чтобы загрузить библиотеку для импорта файлов Excel.
library(readxl)
readxl_example ()
Мы используем примеры, включенные в пакет readxl во время этого урока.
Используйте код
readxl_example()
чтобы увидеть все доступные таблицы в библиотеке.
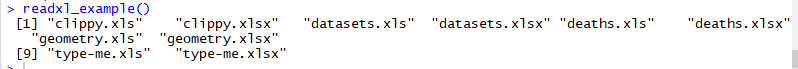
Чтобы проверить расположение таблицы с именем clippy.xls, просто используйте
readxl_example("geometry.xls")

Если вы устанавливаете R с помощью conda, электронные таблицы находятся в Anaconda3 / lib / R / library / readxl / extdata / filename.xls
read_excel ()
Функция read_excel () отлично подходит для открытия расширений xls и xlsx.
Синтаксис:
read_excel(PATH, sheet = NULL, range= NULL, col_names = TRUE) arguments: -PATH: Path where the excel is located -sheet: Select the sheet to import. By default, all -range: Select the range to import. By default, all non-null cells -col_names: Select the columns to import. By default, all non-null columns
Мы можем импортировать электронные таблицы из библиотеки readxl и посчитать количество столбцов на первом листе.
# Store the path of `datasets.xlsx`
example <- readxl_example("datasets.xlsx")
# Import the spreadsheet
df <- read_excel(example)
# Count the number of columns
length(df)
Вывод:
## [1] 5
excel_sheets ()
Файл datasets.xlsx состоит из 4 листов. Мы можем узнать, какие листы доступны в книге, используя функцию excel_sheets ()
example <- readxl_example("datasets.xlsx")
excel_sheets(example)
Вывод:
[1] "iris" "mtcars" "chickwts" "quakes"
Если рабочий лист включает в себя много листов, легко выбрать конкретный лист, используя аргументы листа. Мы можем указать название листа или индекс листа. Мы можем проверить, возвращает ли обе функции один и тот же вывод с помощью метода unique ().
example <- readxl_example("datasets.xlsx")
quake <- read_excel(example, sheet = "quakes")
quake_1 <-read_excel(example, sheet = 4)
identical(quake, quake_1)
Вывод:
## [1] TRUE
Мы можем контролировать, какие ячейки читать 2 способами
- Используйте аргумент n_max для возврата n строк
- Используйте аргумент диапазона в сочетании с cell_rows или cell_cols
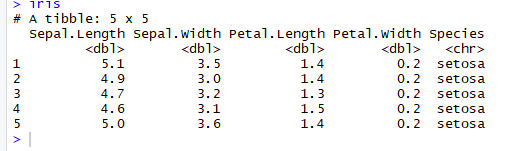
Например, мы устанавливаем n_max равным 5, чтобы импортировать первые пять строк.
# Read the first five row: with header iris <-read_excel(example, n_max =5, col_names =TRUE)
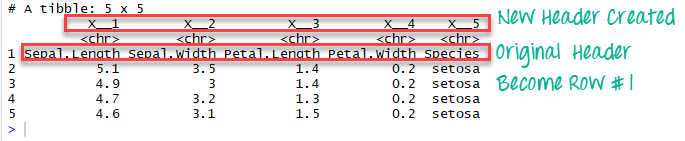
Если мы изменим col_names на FALSE, R автоматически создаст заголовки.
# Read the first five row: without header iris_no_header <-read_excel(example, n_max =5, col_names =FALSE)
iris_no_header
В фрейме данных iris_no_header R создал пять новых переменных с именами X__1, X__2, X__3, X__4 и X__5
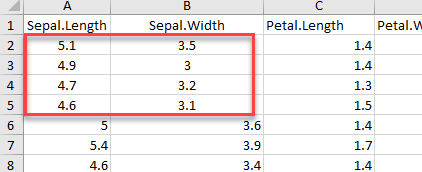
Мы также можем использовать диапазон аргументов для выбора строк и столбцов в электронной таблице. В приведенном ниже коде мы используем стиль Excel, чтобы выбрать диапазон от A1 до B5.
# Read rows A1 to B5 example_1 <-read_excel(example, range = "A1:B5", col_names =TRUE) dim(example_1)
Вывод:
## [1] 4 2
Мы видим, что example_1 возвращает 4 строки с 2 столбцами. У набора данных есть заголовок, поэтому размер равен 4×2.
Во втором примере мы используем функцию cell_rows (), которая управляет диапазоном возвращаемых строк. Если мы хотим импортировать строки с 1 по 5, мы можем установить cell_rows (1: 5). Обратите внимание, что cell_rows (1: 5) возвращает тот же вывод, что и cell_rows (5: 1).
# Read rows 1 to 5 example_2 <-read_excel(example, range =cell_rows(1:5),col_names =TRUE) dim(example_2)
Вывод:
## [1] 4 5
Однако example_2 представляет собой матрицу 4×5. Набор данных iris имеет 5 столбцов с заголовком. Мы возвращаем первые четыре строки с заголовком всех столбцов
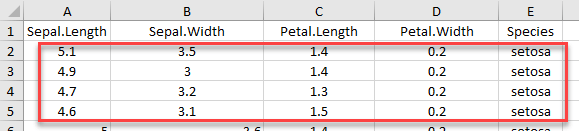
Если мы хотим импортировать строки, которые не начинаются с первой строки, мы должны включить col_names = FALSE. Если мы используем range = cell_rows (2: 5), становится очевидно, что наш фрейм данных больше не имеет заголовка.
iris_row_with_header <-read_excel(example, range =cell_rows(2:3), col_names=TRUE) iris_row_no_header <-read_excel(example, range =cell_rows(2:3),col_names =FALSE)
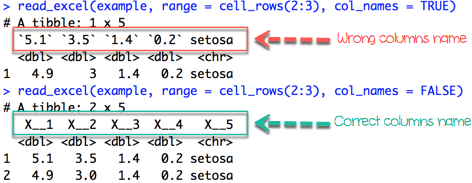
We can select the columns with the letter, like in Excel.
# Select columns A and B
col <-read_excel(example, range =cell_cols("A:B"))
dim(col)
Вывод:
## [1] 150 2
Примечание: range = cell_cols («A: B»), возвращает выходные данные всех ячеек с ненулевым значением. Набор данных содержит 150 строк, поэтому read_excel () возвращает строки до 150. Это проверяется с помощью функции dim ().
read_excel () возвращает NA, когда в ячейке появляется символ без числового значения. Мы можем посчитать количество пропущенных значений с помощью комбинации двух функций
- сумма
- is.na
Вот код
iris_na <-read_excel(example, na ="setosa") sum(is.na(iris_na))
Вывод:
## [1] 50
У нас пропущено 50 значений, которые являются строками, принадлежащими видам сетоз.
Импорт данных из другого статистического программного обеспечения
Мы будем импортировать различные файлы формата с пакетом небес. Этот пакет поддерживает программное обеспечение SAS, STATA и SPSS. Мы можем использовать следующую функцию для открытия различных типов наборов данных в соответствии с расширением файла:
- SAS: read_sas ()
- STATA: read_dta () (или read_stata (), которые идентичны)
- SPSS: read_sav () или read_por (). Нам нужно проверить расширение
В этой функции требуется только один аргумент. Нам нужно знать ПУТЬ, где хранится файл. Вот и все, мы готовы открыть все файлы из SAS, STATA и SPSS. Эти три функции также принимают URL.
library(haven)
В гавань входит conda r-essential, в противном случае перейдите по ссылке или в терминале. conda установите -c conda-forge r-haven
Читать сас
Для нашего примера мы собираемся использовать набор входных данных из IDRE.
PATH_sas <- 'https://github.com/guru99-edu/R-Programming/blob/master/binary.sas7bdat?raw=true' df <- read_sas(PATH_sas) head(df)
Вывод:
## # A tibble: 6 x 4 ## ADMIT GRE GPA RANK ## <dbl> <dbl> <dbl> <dbl> ## 1 0 380 3.61 3 ## 2 1 660 3.67 3 ## 3 1 800 4.00 1 ## 4 1 640 3.19 4 ## 5 0 520 2.93 4 ## 6 1 760 3.00 2
Читать STATA
Для файлов данных STATA вы можете использовать read_dta (). Мы используем точно такой же набор данных, но храним его в файле .dta.
PATH_stata <- 'https://github.com/guru99-edu/R-Programming/blob/master/binary.dta?raw=true' df <- read_dta(PATH_stata) head(df)
Вывод:
## # A tibble: 6 x 4 ## admit gre gpa rank ## <dbl> <dbl> <dbl> <dbl> ## 1 0 380 3.61 3 ## 2 1 660 3.67 3 ## 3 1 800 4.00 1 ## 4 1 640 3.19 4 ## 5 0 520 2.93 4 ## 6 1 760 3.00 2
Читать SPSS
Мы используем функцию read_sav (), чтобы открыть файл SPSS. Расширение файла «.sav»
PATH_spss <- 'https://github.com/guru99-edu/R-Programming/blob/master/binary.sav?raw=true' df <- read_sav(PATH_spss) head(df)
Вывод:
## # A tibble: 6 x 4 ## admit gre gpa rank ## <dbl> <dbl> <dbl> <dbl> ## 1 0 380 3.61 3 ## 2 1 660 3.67 3 ## 3 1 800 4.00 1 ## 4 1 640 3.19 4 ## 5 0 520 2.93 4 ## 6 1 760 3.00 2
Лучшие практики для импорта данных
Когда мы хотим импортировать данные в R, полезно реализовать следующий контрольный список. Это позволит легко импортировать данные в R:
- Типичным форматом электронной таблицы является использование первых строк в качестве заголовка (обычно это имя переменной).
- Избегайте именовать набор данных с пробелами; это может привести к интерпретации как отдельной переменной. В качестве альтернативы, предпочтите использовать «_» или «-».
- Короткие имена являются предпочтительными
- Не включайте символ в имя: то есть: exchange_rate _ $ _ € не правильно. Предпочитаю называть это: exchange_rate_dollar_euro
- В противном случае используйте NA для пропущенных значений; нам нужно очистить формат позже.
Резюме
В следующей таблице приведены функции, которые необходимо использовать для импорта файлов различных типов в R. В первом столбце указана библиотека, связанная с этой функцией. Последний столбец ссылается на аргумент по умолчанию.
|
Библиотека |
Задача |
функция |
Аргументы по умолчанию |
|---|---|---|---|
|
Utils |
Читать файл CSV |
read.csv () |
file, header =, TRUE, sep = «,» |
|
readxl |
Прочитать EXCEL файл |
read_excel () |
путь, диапазон = NULL, col_names = TRUE |
|
убежище |
Прочитать файл SAS |
read_sas () |
дорожка |
|
убежище |
Читать файл STATA |
read_stata () |
дорожка |
|
убежище |
Читать SPSS Филе |
read_sav () |
дорожка |
В следующей таблице показаны различные способы импорта выбора с помощью функции read_excel ().
|
функция |
Цели |
аргументы |
|---|---|---|
|
read_excel () |
Прочитать количество строк |
n_max = 10 |
|
Выберите строки и столбцы, как в Excel |
диапазон = «A1: D10» |
|
|
Выберите строки с индексами |
range = cell_rows (1: 3) |
|
|
Выберите столбцы с буквами |
range = cell_cols («A: C») |