Что такое деревья решений?
РЕШЕНИЯ — это универсальный алгоритм машинного обучения, который может выполнять как задачи классификации, так и регрессии. Это очень мощные алгоритмы, способные подгонять сложные наборы данных. Кроме того, деревья решений являются фундаментальными компонентами случайных лесов, которые являются одними из самых мощных алгоритмов машинного обучения, доступных сегодня.
Обучение и визуализация деревьев решений
Чтобы построить ваши первые деревья решений, мы будем действовать следующим образом:
- Шаг 1: Импортируйте данные
- Шаг 2: Очистите набор данных
- Шаг 3: Создайте поезд / тестовый набор
- Шаг 4: Постройте модель
- Шаг 5: Сделайте прогноз
- Шаг 6: Измерение производительности
- Шаг 7: Настройте гиперпараметры
Шаг 1) Импортируйте данные
Если вам интересно узнать о судьбе Титаника, вы можете посмотреть это видео на Youtube . Цель этого набора данных — предсказать, какие люди с большей вероятностью выживут после столкновения с айсбергом. Набор данных содержит 13 переменных и 1309 наблюдений. Набор данных упорядочен по переменной X.
set.seed(678) path <- 'https://raw.githubusercontent.com/guru99-edu/R-Programming/master/titanic_data.csv' titanic <-read.csv(path) head(titanic)
Вывод:
## X pclass survived name sex ## 1 1 1 1 Allen, Miss. Elisabeth Walton female ## 2 2 1 1 Allison, Master. Hudson Trevor male ## 3 3 1 0 Allison, Miss. Helen Loraine female ## 4 4 1 0 Allison, Mr. Hudson Joshua Creighton male ## 5 5 1 0 Allison, Mrs. Hudson J C (Bessie Waldo Daniels) female ## 6 6 1 1 Anderson, Mr. Harry male ## age sibsp parch ticket fare cabin embarked ## 1 29.0000 0 0 24160 211.3375 B5 S ## 2 0.9167 1 2 113781 151.5500 C22 C26 S ## 3 2.0000 1 2 113781 151.5500 C22 C26 S ## 4 30.0000 1 2 113781 151.5500 C22 C26 S ## 5 25.0000 1 2 113781 151.5500 C22 C26 S ## 6 48.0000 0 0 19952 26.5500 E12 S ## home.dest ## 1 St Louis, MO ## 2 Montreal, PQ / Chesterville, ON ## 3 Montreal, PQ / Chesterville, ON ## 4 Montreal, PQ / Chesterville, ON ## 5 Montreal, PQ / Chesterville, ON ## 6 New York, NY
tail(titanic)
Вывод:
## X pclass survived name sex age sibsp ## 1304 1304 3 0 Yousseff, Mr. Gerious male NA 0 ## 1305 1305 3 0 Zabour, Miss. Hileni female 14.5 1 ## 1306 1306 3 0 Zabour, Miss. Thamine female NA 1 ## 1307 1307 3 0 Zakarian, Mr. Mapriededer male 26.5 0 ## 1308 1308 3 0 Zakarian, Mr. Ortin male 27.0 0 ## 1309 1309 3 0 Zimmerman, Mr. Leo male 29.0 0 ## parch ticket fare cabin embarked home.dest ## 1304 0 2627 14.4583 C ## 1305 0 2665 14.4542 C ## 1306 0 2665 14.4542 C ## 1307 0 2656 7.2250 C ## 1308 0 2670 7.2250 C ## 1309 0 315082 7.8750 S
Из вывода головы и хвоста вы можете заметить, что данные не перемешаны. Это большая проблема! Когда вы разделите свои данные между набором поездов и тестовым набором, вы выберете только пассажира из классов 1 и 2 (ни один пассажир из класса 3 не входит в верхние 80 процентов наблюдений), что означает, что алгоритм никогда не увидит Особенности пассажира класса 3. Эта ошибка приведет к плохому прогнозу.
Чтобы преодолеть эту проблему, вы можете использовать функцию sample ().
shuffle_index <- sample(1:nrow(titanic)) head(shuffle_index)
Код Объяснение
- sample (1: nrow (titanic)): создать случайный список индексов от 1 до 1309 (т. е. максимальное количество строк).
Вывод:
## [1] 288 874 1078 633 887 992
Вы будете использовать этот индекс для перетасовки титанового набора данных.
titanic <- titanic[shuffle_index, ] head(titanic)
Вывод:
## X pclass survived ## 288 288 1 0 ## 874 874 3 0 ## 1078 1078 3 1 ## 633 633 3 0 ## 887 887 3 1 ## 992 992 3 1 ## name sex age ## 288 Sutton, Mr. Frederick male 61 ## 874 Humblen, Mr. Adolf Mathias Nicolai Olsen male 42 ## 1078 O'Driscoll, Miss. Bridget female NA ## 633 Andersson, Mrs. Anders Johan (Alfrida Konstantia Brogren) female 39 ## 887 Jermyn, Miss. Annie female NA ## 992 Mamee, Mr. Hanna male NA ## sibsp parch ticket fare cabin embarked home.dest## 288 0 0 36963 32.3208 D50 S Haddenfield, NJ ## 874 0 0 348121 7.6500 F G63 S ## 1078 0 0 14311 7.7500 Q ## 633 1 5 347082 31.2750 S Sweden Winnipeg, MN ## 887 0 0 14313 7.7500 Q ## 992 0 0 2677 7.2292 C
Шаг 2) Очистите набор данных
Структура данных показывает, что некоторые переменные имеют NA. Очистка данных должна быть сделана следующим образом
- Сбросить переменные home.dest, каюта, имя, X и билет
- Создайте факторные переменные для pclass и выжили
- Брось АН
library(dplyr)
# Drop variables
clean_titanic <- titanic % > %
select(-c(home.dest, cabin, name, X, ticket)) % > %
#Convert to factor level
mutate(pclass = factor(pclass, levels = c(1, 2, 3), labels = c('Upper', 'Middle', 'Lower')),
survived = factor(survived, levels = c(0, 1), labels = c('No', 'Yes'))) % > %
na.omit()
glimpse(clean_titanic)
Код Объяснение
- выберите (-c (home.dest, каюта, имя, X, билет)): удалить ненужные переменные
- pclass = factor (pclass, level = c (1,2,3), label = c («Upper», «Middle», «Lower»)): добавить метку в переменную pclass. 1 становится верхним, 2 становится простым, а 3 становится ниже
- фактор (выжил, уровни = c (0,1), метки = c («нет», «да»)): добавить метку к выжившей переменной. 1 становится нет, а 2 становится да
- na.omit (): удалить наблюдения NA
Вывод:
## Observations: 1,045 ## Variables: 8 ## $ pclass <fctr> Upper, Lower, Lower, Upper, Middle, Upper, Middle, U... ## $ survived <fctr> No, No, No, Yes, No, Yes, Yes, No, No, No, No, No, Y... ## $ sex <fctr> male, male, female, female, male, male, female, male... ## $ age <dbl> 61.0, 42.0, 39.0, 49.0, 29.0, 37.0, 20.0, 54.0, 2.0, ... ## $ sibsp <int> 0, 0, 1, 0, 0, 1, 0, 0, 4, 0, 0, 1, 1, 0, 0, 0, 1, 1,... ## $ parch <int> 0, 0, 5, 0, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 2, 0, 4, 0,... ## $ fare <dbl> 32.3208, 7.6500, 31.2750, 25.9292, 10.5000, 52.5542, ... ## $ embarked <fctr> S, S, S, S, S, S, S, S, S, C, S, S, S, Q, C, S, S, C...
Шаг 3) Создайте поезд / тестовый набор
Прежде чем тренировать свою модель, вам нужно выполнить два шага:
- Создание поезда и набора тестов: вы тренируете модель на наборе поездов и тестируете прогноз на наборе тестов (то есть невидимых данных)
- Установите rpart.plot из консоли
Обычной практикой является разделение данных на 80/20, 80 процентов данных служат для обучения модели, а 20 процентов — для прогнозирования. Вам необходимо создать два отдельных фрейма данных. Вы не хотите трогать тестовый набор, пока не закончите сборку модели. Вы можете создать имя функции create_train_test (), которое принимает три аргумента.
create_train_test(df, size = 0.8, train = TRUE) arguments: -df: Dataset used to train the model. -size: Size of the split. By default, 0.8. Numerical value -train: If set to `TRUE`, the function creates the train set, otherwise the test set. Default value sets to `TRUE`. Boolean value.You need to add a Boolean parameter because R does not allow to return two data frames simultaneously.
create_train_test <- function(data, size = 0.8, train = TRUE) {
n_row = nrow(data)
total_row = size * n_row
train_sample < - 1: total_row
if (train == TRUE) {
return (data[train_sample, ])
} else {
return (data[-train_sample, ])
}
}
Код Объяснение
- функция (данные, размер = 0,8, поезд = ИСТИНА): добавить аргументы в функцию
- n_row = nrow (data): подсчитать количество строк в наборе данных
- total_row = size * n_row: вернуть n-ую строку для построения набора поездов
- train_sample <- 1: total_row: выберите от первой строки до n-й строки
- if (train == TRUE) {} else {}: если условие имеет значение true, вернуть набор поездов, иначе набор тестов.
Вы можете проверить свою функцию и проверить размерность.
data_train <- create_train_test(clean_titanic, 0.8, train = TRUE) data_test <- create_train_test(clean_titanic, 0.8, train = FALSE) dim(data_train)
Вывод:
## [1] 836 8
dim(data_test)
Вывод:
## [1] 209 8
Набор данных поезда имеет 1046 строк, а набор тестовых данных — 262 строки.
Вы используете функцию prop.table () в сочетании с table () для проверки правильности процесса рандомизации.
prop.table(table(data_train$survived))
Вывод:
## ## No Yes ## 0.5944976 0.4055024
prop.table(table(data_test$survived))
Вывод:
## ## No Yes ## 0.5789474 0.4210526
В обоих наборах данных число выживших одинаково — около 40 процентов.
Установите rpart.plot
rpart.plot недоступен в библиотеках conda. Вы можете установить его из консоли:
install.packages("rpart.plot")
Шаг 4) Постройте модель
Вы готовы построить модель. Синтаксис для функции Rpart ():
rpart(formula, data=, method='') arguments: - formula: The function to predict - data: Specifies the data frame- method: - "class" for a classification tree - "anova" for a regression tree
Вы используете метод класса, потому что вы предсказываете класс.
library(rpart) library(rpart.plot) fit <- rpart(survived~., data = data_train, method = 'class') rpart.plot(fit, extra = 106
Код Объяснение
- rpart (): функция для соответствия модели. Аргументы:
- выжил ~ .: Формула деревьев решений
- data = data_train: набор данных
- method = ‘class’: подходит бинарная модель
- rpart.plot (fit, extra = 106): построить дерево. Дополнительные функции установлены на 101 для отображения вероятности 2-го класса (полезно для двоичных ответов). Вы можете обратиться к виньетке для получения дополнительной информации о других вариантах.
Вывод:
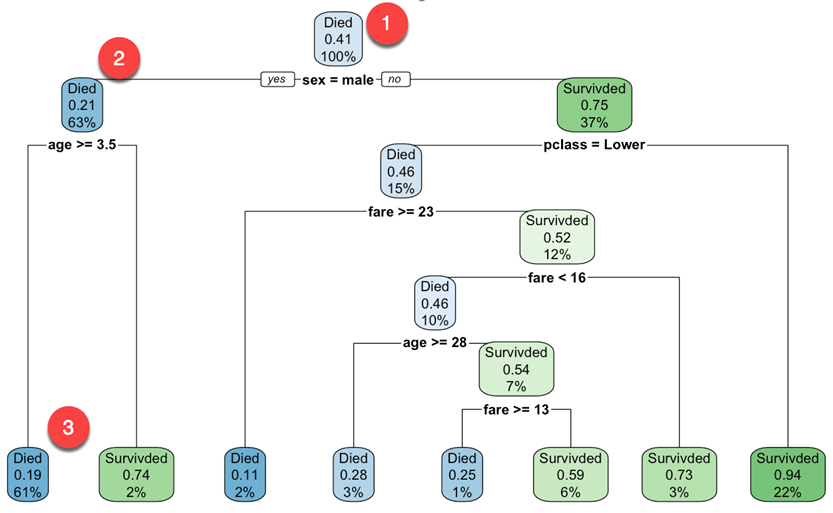
Вы начинаете с корневого узла (глубина от 0 до 3, верхняя часть графика):
- Вверху это общая вероятность выживания. Он показывает долю пассажиров, переживших аварию. 41 процент пассажиров выжил.
- Этот узел спрашивает, является ли пол пассажира мужским. Если да, то вы переходите к левому дочернему узлу корня (глубина 2). 63 процента составляют мужчины с вероятностью выживания 21 процент.
- Во втором узле вы спрашиваете, является ли пассажир мужского пола старше 3,5 лет. Если да, то шанс на выживание составляет 19 процентов.
- Вы продолжаете в том же духе, чтобы понять, какие особенности влияют на вероятность выживания.
Обратите внимание, что одним из многих качеств деревьев решений является то, что они требуют очень мало подготовки данных. В частности, они не требуют масштабирования или центрирования объектов.
По умолчанию функция rpart () использует меру примеси Джини для разделения заметки. Чем выше коэффициент Джини, тем больше разных экземпляров в узле.
Шаг 5) Сделайте прогноз
Вы можете предсказать ваш тестовый набор данных. Чтобы сделать прогноз, вы можете использовать функцию предиката (). Основной синтаксис прогнозирования для деревьев решений:
predict(fitted_model, df, type = 'class')
arguments:
- fitted_model: This is the object stored after model estimation.
- df: Data frame used to make the prediction
- type: Type of prediction
- 'class': for classification
- 'prob': to compute the probability of each class
- 'vector': Predict the mean response at the node level
Вы хотите предсказать, какие пассажиры с большей вероятностью выживут после столкновения из тестового набора. Это значит, вы будете знать среди тех 209 пассажиров, кто из них выживет или нет.
predict_unseen <-predict(fit, data_test, type = 'class')
Код Объяснение
- предикат (fit, data_test, type = ‘class’): прогнозирование класса (0/1) тестового набора
Тестирование пассажира, который не сделал это и тех, кто сделал.
table_mat <- table(data_test$survived, predict_unseen) table_mat
Код Объяснение
- таблица (data_test $ выжил, предикат_unseen): создайте таблицу, чтобы подсчитать, сколько пассажиров классифицировано как выжившие и скончались, сравнить с правильной классификацией
Вывод:
## predict_unseen ## No Yes ## No 106 15 ## Yes 30 58
Модель правильно предсказала 106 погибших пассажиров, но 15 оставшихся в живых погибших. По аналогии, модель неправильно классифицировала 30 пассажиров как выживших, в то время как они оказались мертвыми.
Шаг 6) Измерьте производительность
Вы можете вычислить меру точности для задачи классификации с помощью матрицы путаницы :
Матрица неточностей является лучшим выбором для оценки эффективности классификации. Общая идея состоит в том, чтобы подсчитать, сколько раз Истинные экземпляры классифицируются как Ложные.
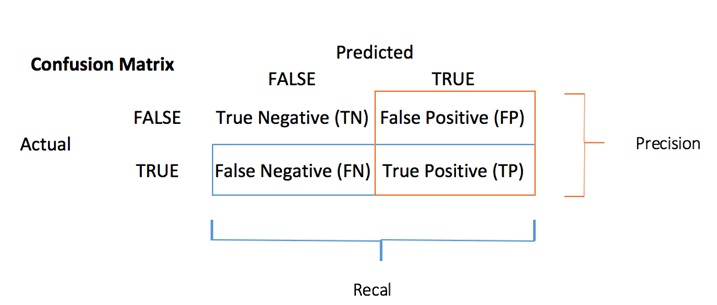
Каждая строка в матрице путаницы представляет фактическую цель, в то время как каждый столбец представляет прогнозируемую цель. В первом ряду этой матрицы рассматриваются мертвые пассажиры (класс False): 106 были правильно классифицированы как мертвые ( истинно отрицательный ), а оставшийся был ошибочно классифицирован как выживший ( ложно положительный ). Во втором ряду рассматриваются выжившие, положительный класс был 58 ( истинно положительный ), в то время как истинный отрицательный был 30.
Вы можете вычислить тест точности из матрицы путаницы:
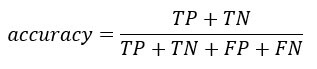
Это доля истинно положительного и истинно отрицательного значения в сумме матрицы. С помощью R вы можете кодировать следующим образом:
accuracy_Test <- sum(diag(table_mat)) / sum(table_mat)
Код Объяснение
- сумма (diag (table_mat)): сумма диагонали
- sum (table_mat): сумма матрицы.
Вы можете распечатать точность тестового набора:
print(paste('Accuracy for test', accuracy_Test))
Вывод:
## [1] "Accuracy for test 0.784688995215311"
У вас есть 78 процентов за тестовый набор. Вы можете повторить то же упражнение с набором тренировочных данных.
Шаг 7) Настройте гиперпараметры
Дерево решений имеет различные параметры, которые управляют аспектами подгонки. В библиотеке rpart вы можете управлять параметрами, используя функцию rpart.control (). В следующем коде вы вводите параметры для настройки. Вы можете обратиться к виньетке для других параметров.
rpart.control(minsplit = 20, minbucket = round(minsplit/3), maxdepth = 30) Arguments: -minsplit: Set the minimum number of observations in the node before the algorithm perform a split -minbucket: Set the minimum number of observations in the final note i.e. the leaf -maxdepth: Set the maximum depth of any node of the final tree. The root node is treated a depth 0
We will proceed as follow:
- Construct function to return accuracy
- Tune the maximum depth
- Tune the minimum number of sample a node must have before it can split
- Tune the minimum number of sample a leaf node must have
You can write a function to display the accuracy. You simply wrap the code you used before:
- predict: predict_unseen <- predict(fit, data_test, type = ‘class’)
- Produce table: table_mat <- table(data_test$survived, predict_unseen)
- Compute accuracy: accuracy_Test <- sum(diag(table_mat))/sum(table_mat)
accuracy_tune <- function(fit) {
predict_unseen <- predict(fit, data_test, type = 'class')
table_mat <- table(data_test$survived, predict_unseen)
accuracy_Test <- sum(diag(table_mat)) / sum(table_mat)
accuracy_Test
}
You can try to tune the parameters and see if you can improve the model over the default value. As a reminder, you need to get an accuracy higher than 0.78
control <- rpart.control(minsplit = 4,
minbucket = round(5 / 3),
maxdepth = 3,
cp = 0)
tune_fit <- rpart(survived~., data = data_train, method = 'class', control = control)
accuracy_tune(tune_fit)
Output:
## [1] 0.7990431
With the following parameter:
minsplit = 4 minbucket= round(5/3) maxdepth = 3cp=0
You get a higher performance than the previous model. Congratulation!
Summary
We can summarize the functions to train a decision trees algorithm.
|
Library |
Objective |
function |
class |
parameters |
details |
|---|---|---|---|---|---|
|
rpart |
Train classification trees |
rpart() |
class |
formula, df, method |
|
|
rpart |
Train regression tree |
rpart() |
anova |
formula, df, method |
|
|
rpart |
Plot the trees |
rpart.plot() |
fitted model |
||
|
base |
predict |
predict() |
class |
fitted model, type |
|
|
base |
predict |
predict() |
prob |
fitted model, type |
|
|
base |
predict |
predict() |
vector |
fitted model, type |
|
|
rpart |
Control parameters |
rpart.control() |
minsplit |
Set the minimum number of observations in the node before the algorithm perform a split |
|
|
minbucket |
Set the minimum number of observations in the final note i.e. the leaf |
||||
|
maxdepth |
Set the maximum depth of any node of the final tree. The root node is treated a depth 0 |
||||
|
rpart |
Train model with control parameter |
rpart() |
formula, df, method, control |
Note : Train the model on a training data and test the performance on an unseen dataset, i.e. test set.