В этом руководстве вы узнаете, как проверить данные и подготовить их к созданию простой задачи линейной регрессии.
Этот урок разделен на две части:
- Ищите взаимодействия
- Протестируйте модель
В предыдущем уроке вы использовали набор данных из Бостона, чтобы оценить среднюю цену дома. Бостонский набор данных имеет небольшой размер, всего 506 наблюдений. Этот набор данных считается эталоном для тестирования новых алгоритмов линейной регрессии.
Набор данных состоит из:
| переменная | Описание |
| гп | Доля жилой земли зонирована под участки более 25 000 кв. Футов. |
| промышл | Доля неторгового бизнеса в акрах города. |
| NOx | концентрация окислов азота |
| комната | среднее количество комнат в доме |
| возраст | доля домовладельцев, построенных до 1940 года |
| дис | взвешенные расстояния до пяти бостонских центров занятости |
| налог | ставка налога на имущество на полную стоимость за доллары 10000 |
| ptratio | соотношение ученик-учитель по городу |
| MEDV | Средняя стоимость домов, занимаемых владельцами, в тысячах долларов |
| CRIM | уровень преступности на душу населения по городам |
| Чес | Фиктивная переменная Чарльза (1, если ограничивает реку; 0 в противном случае) |
| В | доля негров по городу |
В этом уроке мы оценим среднюю цену с помощью линейного регрессора, но основное внимание уделяется одному конкретному процессу машинного обучения: «подготовке данных».
Модель обобщает образец в данных. Чтобы запечатлеть такой паттерн, сначала нужно его найти. Хорошей практикой является выполнение анализа данных перед запуском любого алгоритма машинного обучения.
Выбор правильных функций влияет на успех вашей модели. Представьте, что вы пытаетесь оценить заработную плату людей, если вы не включите пол как ковариату, у вас получится плохая оценка.
Другой способ улучшить модель — посмотреть на корреляцию между независимой переменной. Возвращаясь к примеру, вы можете рассматривать образование как превосходного кандидата для прогнозирования заработной платы, а также профессии. Справедливо сказать, что профессия зависит от уровня образования, а именно высшее образование часто приводит к лучшей профессии. Если мы обобщим эту идею, мы можем сказать, что корреляция между зависимой переменной и объясняющей переменной может быть увеличена еще одной объясняющей переменной.
Чтобы зафиксировать ограниченное влияние образования на профессию, мы можем использовать термин взаимодействия.

Если вы посмотрите на уравнение заработной платы, оно становится:
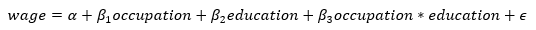
Если 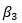 оно положительное, то это означает, что дополнительный уровень образования приводит к более высокому увеличению средней стоимости дома для высокого уровня занятости. Другими словами, существует эффект взаимодействия между образованием и профессией.
оно положительное, то это означает, что дополнительный уровень образования приводит к более высокому увеличению средней стоимости дома для высокого уровня занятости. Другими словами, существует эффект взаимодействия между образованием и профессией.
В этом уроке мы попытаемся увидеть, какие переменные могут быть хорошим кандидатом для терминов взаимодействия. Мы проверим, приведет ли добавление такого рода информации к лучшему прогнозированию цен.
В этом уроке вы узнаете
- Сводные статистические данные
- Обзор аспектов
- Facets Deep Dive
- Установить Facet
- обзор
- график
- Facets Deep Dive
- TensorFlow
- Подготовка данных
- Основная регрессия: контрольный ориентир
- Улучшение модели: термин взаимодействия
Сводные статистические данные
Есть несколько шагов, которые вы можете выполнить, прежде чем приступить к модели. Как упоминалось ранее, модель является обобщением данных. Лучшая практика — это понять данные и сделать прогноз. Если вы не знаете своих данных, у вас мало шансов улучшить свою модель.
В качестве первого шага загрузите данные в виде фрейма данных Pandas и создайте обучающий набор и набор для тестирования.
Советы: для этого урока вам нужно установить matplotlit и seaborn в Python. Вы можете установить пакет Python на лету с помощью Jupyter. Вы не должны делать это
!conda install -- yes matplotlib
но
import sys
!{sys.executable} -m pip install matplotlib # Already installed
!{sys.executable} -m pip install seaborn
Обратите внимание, что этот шаг не требуется, если у вас установлены matplotlib и seaborn.
Matplotlib — это библиотека для создания графа в Python. Seaborn — это статистическая библиотека визуализации, построенная на основе matplotlib. Это обеспечивает привлекательные и красивые участки.
Код ниже импортирует необходимые библиотеки.
import pandas as pd from sklearn import datasets import tensorflow as tf from sklearn.datasets import load_boston import numpy as np
Библиотека sklearn включает в себя набор данных Бостона. Вы можете вызвать его API для импорта данных.
boston = load_boston() df = pd.DataFrame(boston.data)
Имя объекта хранится в объекте feature_names в массиве.
boston.feature_names
Вывод
array(['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD','TAX', 'PTRATIO', 'B', 'LSTAT'], dtype='<U7')
Вы можете переименовать столбцы.
df.columns = boston.feature_names df['PRICE'] = boston.target df.head(2)

Вы преобразуете переменную CHAS в строковую переменную и помечаете ее как да, если CHAS = 1, и нет, если CHAS = 0
df['CHAS'] = df['CHAS'].map({1:'yes', 0:'no'})
df['CHAS'].head(5)
0 no
1 no
2 no
3 no
4 no
Name: CHAS, dtype: object
С пандами легко разбить набор данных. Вы случайным образом делите набор данных с 80-процентным обучающим набором и 20-процентным набором тестирования. У Pandas есть встроенная функция стоимости для разделения выборки фрейма данных.
Первый параметр frac — это значение от 0 до 1. Вы устанавливаете его на 0,8, чтобы случайным образом выбрать 80 процентов фрейма данных.
Random_state позволяет получить один и тот же кадр данных для всех.
### Create train/test set df_train=df.sample(frac=0.8,random_state=200) df_test=df.drop(df_train.index)
Вы можете получить форму данных. Должен быть:
- Набор поездов: 506 * 0,8 = 405
- Тестовый набор: 506 * 0,2 = 101
print(df_train.shape, df_test.shape)
Вывод
(405, 14) (101, 14)
df_test.head(5)
Вывод
| CRIM | ZN | INDUS | ЧАС | NOX | RM | ВОЗРАСТ | ДИС | РАД | НАЛОГОВЫЙ | PTRATIO | В | LSTAT | ЦЕНА | |
| 0 | 0,00632 | 18,0 | 2,31 | нет | 0,538 | 6,575 | 65,2 | 4,0900 | 1,0 | 296,0 | 15,3 | 396,90 | 4,98 | 24,0 |
| 1 | 0,02731 | 0.0 | 7,07 | нет | 0,469 | 6,421 | 78,9 | 4,9671 | 2,0 | 242,0 | 17,8 | 396,90 | 9,14 | 21,6 |
| 3 | 0,03237 | 0.0 | 2,18 | нет | 0,458 | 6,998 | 45,8 | 6,0622 | 3.0 | 222,0 | 18,7 | 394,63 | 2,94 | 33,4 |
| 6 | 0,08829 | 12,5 | 7,87 | нет | 0,524 | 6,012 | 66,6 | 5,5605 | 5.0 | 311,0 | 15,2 | 395,60 | 12,43 | 22,9 |
| 7 | 0,14455 | 12,5 | 7,87 | нет | 0,524 | 6,172 | 96,1 | 5,9505 | 5.0 | 311,0 | 15,2 | 396,90 | 19,15 | 27,1 |
Данные грязные; он часто разбалансирован и усеян внешними значениями, которые отбрасывают анализ и обучение машинному обучению.
Первым шагом к очистке набора данных является понимание того, где он нуждается в очистке. Очистка набора данных может быть сложной задачей, особенно любым обобщенным способом
Команда Google Research разработала инструмент для этой работы, который называется Facets, который помогает визуализировать данные и разбивать их по-разному. Это хорошая отправная точка для понимания того, как устроен набор данных.
Грани позволяют вам найти, где данные не совсем так, как вы думаете.
За исключением их веб-приложения, Google позволяет легко встраивать инструментарий в блокнот Jupyter.
В Facets есть две части:
- Обзор аспектов
- Facets Deep Dive
Обзор аспектов
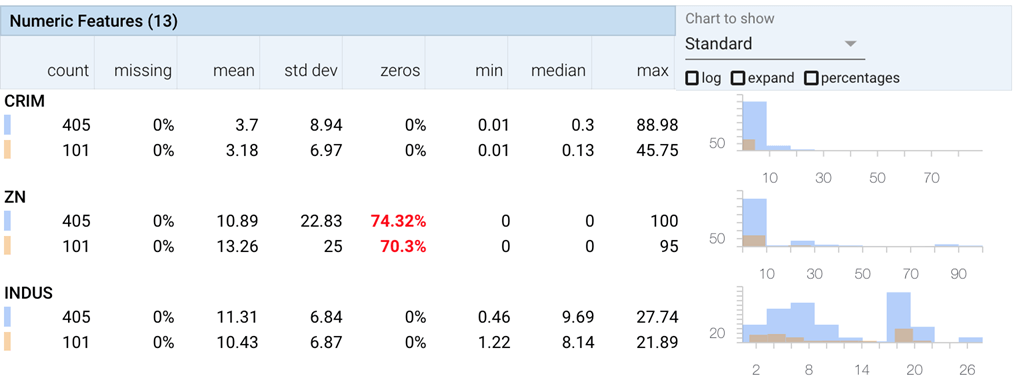
Обзор аспектов дает обзор набора данных. Обзор фасетов разбивает столбцы данных на строки существенной информации, показывающей
- процент пропущенных наблюдений
- минимальное и максимальное значения
- статистические данные, такие как среднее значение, медиана и стандартное отклонение.
- Он также добавляет столбец, который показывает процент значений, которые являются нулями, что полезно, когда большинство значений являются нулями.
- Эти распределения можно увидеть в наборе тестовых данных, а также в обучающем наборе для каждой функции. Это означает, что вы можете дважды проверить, что тест имеет распределение, аналогичное данным обучения.
Это как минимум минимум того, что нужно сделать перед любой задачей машинного обучения. С помощью этого инструмента вы не пропустите этот важный шаг, и он подчеркивает некоторые отклонения.
Facets Deep Dive
Facets Deep Dive — классный инструмент. Это позволяет вам иметь некоторую ясность в вашем наборе данных и полностью увеличивать масштаб, чтобы увидеть отдельный фрагмент данных. Это означает, что вы можете фасетировать данные по строкам и столбцам для любых функций набора данных.
Мы будем использовать эти два инструмента с набором данных Бостона.
Примечание . Вы не можете одновременно использовать Обзор аспектов и Глубокое погружение. Вы должны очистить блокнот, чтобы сменить инструмент.
Установить Facet
Вы можете использовать веб-приложение Facet для большей части анализа. В этом руководстве вы увидите, как использовать его в блокноте Jupyter.
Прежде всего, вам необходимо установить nbextensions. Это сделано с этим кодом. Вы копируете и вставляете следующий код в терминал вашей машины.
pip install jupyter_contrib_nbextensions
Сразу после этого вам нужно клонировать репозитории на вашем компьютере. У вас есть два варианта:
Вариант 1) Скопируйте и вставьте этот код в терминал (рекомендуется)
Если на вашем компьютере не установлен Git, перейдите по этому адресу https://git-scm.com/download/win и следуйте инструкциям. Когда вы закончите, вы можете использовать команду git в терминале для пользователя Mac или приглашение Anaconda для пользователя Windows
git clone https://github.com/PAIR-code/facets
Вариант 2) Перейдите на https://github.com/PAIR-code/facets и загрузите репозитории.
Если вы выберете первый вариант, файл окажется в вашем загружаемом файле. Вы можете либо разрешить загрузку файла, либо перетащить его по другому пути.
Вы можете проверить, где Facets хранится с этой командной строкой:
echo `pwd`/`ls facets`
Теперь, когда вы нашли Facets, вам нужно установить его в Jupyter Notebook. Вам необходимо установить в рабочем каталоге путь, по которому расположены фасеты.
Ваш текущий рабочий каталог и расположение ZIP-архива Facets должны быть одинаковыми.
Вам нужно указать рабочий каталог на Facet:
cd facets
Чтобы установить Facets в Jupyter, у вас есть два варианта. Если вы установили Jupyter с Conda для всех пользователей, скопируйте этот код:
можно использовать jupyter nbextension install facets-dist /
jupyter nbextension install facets-dist/
В противном случае используйте:
jupyter nbextension install facets-dist/ --user
Хорошо, все готово. Давайте откроем обзор аспектов.
обзор
Обзор использует скрипт Python для вычисления статистики. Вам нужно импортировать скрипт с именем generic_feature_statistics_generator в Jupyter. Не волнуйся; скрипт находится в фацетных файлах.
Вам нужно найти его путь. Это легко сделать. Вы открываете фасеты, открываете файл facets_overview и затем python. Скопируйте путь
После этого вернитесь к Jupyter и напишите следующий код. Измените путь ‘/ Users / Thomas / facets / facets_overview / python’ на ваш путь.
# Add the facets overview python code to the python path# Add t
import sys
sys.path.append('/Users/Thomas/facets/facets_overview/python')
Вы можете импортировать скрипт с кодом ниже.
from generic_feature_statistics_generator import GenericFeatureStatisticsGenerator
В Windows тот же код становится
import sys sys.path.append(r"C:\Users\Admin\Anaconda3\facets-master\facets_overview\python") from generic_feature_statistics_generator import GenericFeatureStatisticsGenerator
Чтобы вычислить статистику объекта, вам нужно использовать функцию GenericFeatureStatisticsGenerator () и использовать объект ProtoFromDataFrames. Вы можете передать фрейм данных в словаре. Например, если мы хотим создать сводную статистику для набора поездов, мы можем сохранить информацию в словаре и использовать ее в объекте `ProtoFromDataFrames«
-
'name': 'train', 'table': df_train
Имя — это имя отображаемой таблицы, и вы используете имя таблицы, для которой вы хотите рассчитать сводку. В вашем примере таблица, содержащая данные: df_train
# Calculate the feature statistics proto from the datasets and stringify it for use in facets overview
import base64
gfsg = GenericFeatureStatisticsGenerator()
proto = gfsg.ProtoFromDataFrames([{'name': 'train', 'table': df_train},
{'name': 'test', 'table': df_test}])
#proto = gfsg.ProtoFromDataFrames([{'name': 'train', 'table': df_train}])
protostr = base64.b64encode(proto.SerializeToString()).decode("utf-8")
Наконец, вы просто скопируйте и вставьте код ниже. Код приходит прямо с GitHub. Вы должны быть в состоянии увидеть это:
# Display the facets overview visualization for this data# Displ
from IPython.core.display import display, HTML
HTML_TEMPLATE = """<link rel="import" href="/nbextensions/facets-dist/facets-jupyter.html" >
<facets-overview id="elem"></facets-overview>
<script>
document.querySelector("#elem").protoInput = "{protostr}";
</script>"""
html = HTML_TEMPLATE.format(protostr=protostr)
display(HTML(html))
график
После проверки данных и их распределения вы можете построить матрицу корреляции. Корреляционная матрица вычисляет коэффициент Пирсона. Этот коэффициент связан между -1 и 1, причем положительное значение указывает на положительную корреляцию, а отрицательное значение — на отрицательную корреляцию.
Вам интересно посмотреть, какие переменные могут быть хорошим кандидатом для условий взаимодействия.
## Choose important feature and further check with Dive
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(style="ticks")
# Compute the correlation matrix
corr = df.corr('pearson')
# Generate a mask for the upper triangle
mask = np.zeros_like(corr, dtype=np.bool)
mask[np.triu_indices_from(mask)] = True
# Set up the matplotlib figure
f, ax = plt.subplots(figsize=(11, 9))
# Generate a custom diverging colormap
cmap = sns.diverging_palette(220, 10, as_cmap=True)
# Draw the heatmap with the mask and correct aspect ratio
sns.heatmap(corr, mask=mask, cmap=cmap, vmax=.3, center=0,annot=True,
square=True, linewidths=.5, cbar_kws={"shrink": .5})
Вывод
<matplotlib.axes._subplots.AxesSubplot at 0x1a184d6518>
PNG
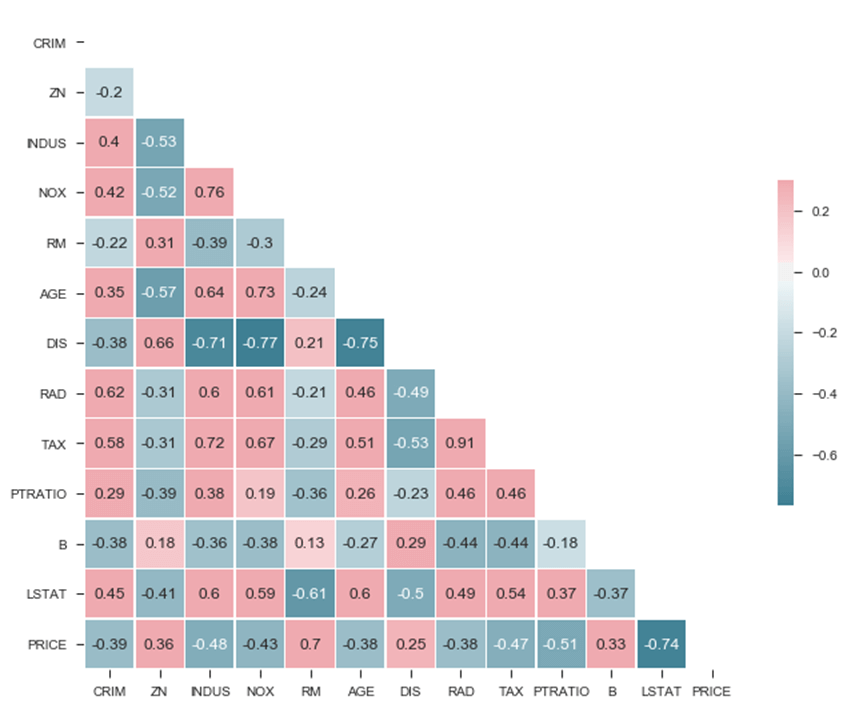
Из матрицы вы можете увидеть:
- LSTAT
- RM
Сильно связаны с ценой. Еще одна интересная особенность — это сильная положительная корреляция между NOX и INDUS, что означает, что эти две переменные движутся в одном направлении. Кроме того, есть также соотносятся с ценой. DIS также сильно коррелирует с IND и NOX.
У вас есть первый намек на то, что IND и NOX могут быть хорошими кандидатами для термина перехвата, и DIS также может быть интересным, чтобы сосредоточиться.
Вы можете пойти немного глубже, построив сетку для пары. Он более подробно проиллюстрирует карту корреляции, которую вы построили ранее.
Сетка пары мы составляем следующим образом:
- Верхняя часть: точечная диаграмма со встроенной линией
- Диагональ: график плотности ядра
- Нижняя часть: многомерный график плотности ядра
Вы выбираете фокус на четырех независимых переменных. Выбор соответствует переменным с сильной корреляцией с ценой
- INDUS
- NOX
- RM
- LSTAT
Более того, ЦЕНА.
Обратите внимание, что стандартная ошибка добавляется по умолчанию к точечной диаграмме.
attributes = ["PRICE", "INDUS", "NOX", "RM", "LSTAT"] g = sns.PairGrid(df[attributes]) g = g.map_upper(sns.regplot, color="g") g = g.map_lower(sns.kdeplot,cmap="Reds", shade=True, shade_lowest=False) g = g.map_diag(sns.kdeplot)
Вывод
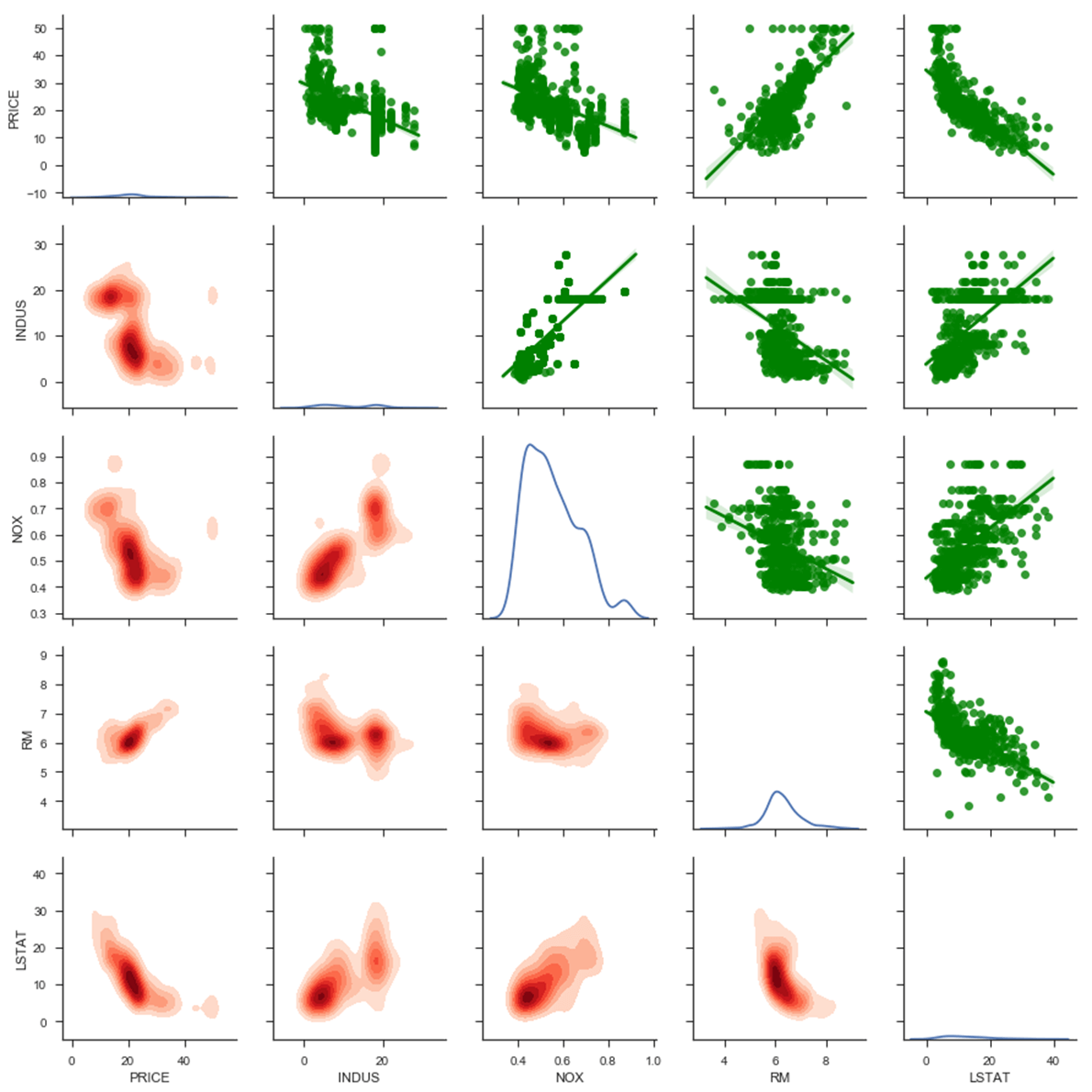
Начнем с верхней части:
- Цена отрицательно коррелирует с INDUS, NOX и LSTAT; положительно коррелирует с РМ.
- Есть небольшая нелинейность с LSTAT и PRICE
- Существует прямая линия, когда цена равна 50. Из описания набора данных, ЦЕНА была усечена до значения 50
Диагональ
- Кажется, что у NOX есть два кластера, один около 0,5 и один около 0,85.
Чтобы узнать больше об этом, вы можете посмотреть в нижней части. Многовариантная плотность ядра интересна в том смысле, что она окрашивает большинство точек. Разница с диаграммой рассеяния рисует плотность вероятности, даже если в наборе данных нет точки для данной координаты. Когда цвет сильнее, это указывает на высокую концентрацию точки вокруг этой области.
Если вы проверите многомерную плотность для INDUS и NOX, вы увидите положительную корреляцию и два кластера. Когда доля промышленности превышает 18, концентрация оксидов азота выше 0,6.
Вы можете подумать о добавлении взаимодействия между INDUS и NOX в линейные отношения.
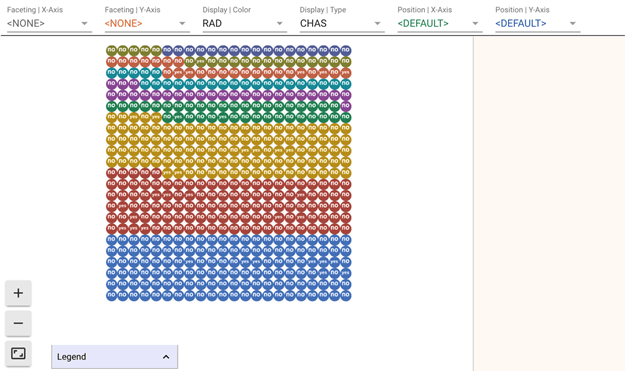
Наконец, вы можете использовать второй инструмент, созданный Google, Facets Deep Dive. Интерфейс разделен на четыре основных раздела. Центральная область в центре — это масштабируемое отображение данных. В верхней части панели находится раскрывающееся меню, в котором можно изменить расположение данных для управления фасеткой, позиционированием и цветом. Справа показан подробный вид определенной строки данных. Это означает, что вы можете нажать на любую точку данных в центре визуализации, чтобы увидеть подробности об этой конкретной точке данных.
На этапе визуализации данных вас интересует поиск парной корреляции между независимой переменной и ценой дома. Тем не менее, он включает как минимум три переменные, и трехмерные графики сложны для работы.
Одним из способов решения этой проблемы является создание категориальной переменной. То есть мы можем создать 2D-график цветом точки. Вы можете разделить переменную ЦЕНА на четыре категории, при этом каждая категория является квартилем (т. Е. 0,25, 0,5, 0,75). Вы называете эту новую переменную Q_PRICE.
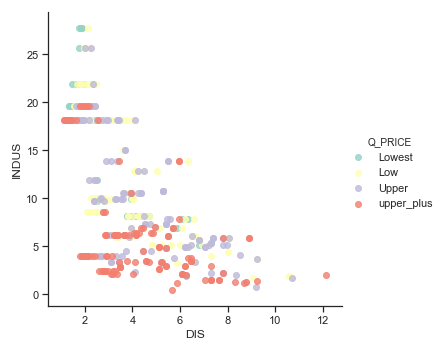
## Check non linearity with important features df['Q_PRICE'] = pd.qcut(df['PRICE'], 4, labels=["Lowest", "Low", "Upper", "upper_plus"]) ## Show non linearity between RM and LSTAT ax = sns.lmplot(x="DIS", y="INDUS", hue="Q_PRICE", data=df, fit_reg = False,palette="Set3")
Facets Deep Dive
Чтобы открыть Deep Dive, вам нужно преобразовать данные в формат json. Панды как объект для этого. Вы можете использовать to_json после набора данных Pandas.
Первая строка кода обрабатывает размер набора данных.
df['Q_PRICE'] = pd.qcut(df['PRICE'], 4, labels=["Lowest", "Low", "Upper", "upper_plus"]) sprite_size = 32 if len(df.index)>50000 else 64 jsonstr = df.to_json(orient='records')
Код ниже взят из Google GitHub. После того, как вы запустите код, вы сможете увидеть это:
# Display thde Dive visualization for this data
from IPython.core.display import display, HTML
# Create Facets template
HTML_TEMPLATE = """<link rel="import" href="/nbextensions/facets-dist/facets-jupyter.html">
<facets-dive sprite-image-width="{sprite_size}" sprite-image-height="{sprite_size}" id="elem" height="600"></facets-dive>
<script>
document.querySelector("#elem").data = {jsonstr};
</script>"""
# Load the json dataset and the sprite_size into the template
html = HTML_TEMPLATE.format(jsonstr=jsonstr, sprite_size=sprite_size)
# Display the template
display(HTML(html))
Вам интересно узнать, существует ли связь между отраслевым тарифом, концентрацией оксида, расстоянием до центра занятости и ценой дома.
Для этого вы сначала разбиваете данные по отраслевому диапазону и цвету на квартиль цен:
- Выберите грань X и выберите INDUS.
- Выберите Display и выберите DIS. Это закрасит точки квартилем цены дома
здесь более темные цвета означают, что расстояние до первого рабочего места далеко.
Пока что это еще раз показывает, что вы знаете, более низкий уровень отрасли, более высокую цену. Теперь вы можете посмотреть на разбивку по INDUX, по NOX.
- Выберите огранку Y и выберите NOX.
Теперь вы можете видеть, что дом далеко от первого центра занятости имеет самую низкую долю промышленности и, следовательно, самую низкую концентрацию оксида. Если вы решите отобразить тип с помощью Q_PRICE и увеличить левый нижний угол, вы сможете увидеть, какая это цена.
У вас есть еще один намек на то, что взаимодействие между IND, NOX и DIS может быть хорошим кандидатом для улучшения модели.
TensorFlow
В этом разделе вы оцените линейный классификатор с помощью API оценки TensorFlow. Вы будете действовать следующим образом:
- Подготовьте данные
- Оценка эталонной модели: нет взаимодействия
- Оцените модель с взаимодействием
Помните, что целью машинного обучения является минимизация ошибки. В этом случае победит модель с наименьшей среднеквадратичной ошибкой. Оценщик TensorFlow автоматически вычисляет этот показатель.
Подготовка данных
В большинстве случаев вам необходимо преобразовать свои данные. Вот почему Обзор Facets является захватывающим. Из сводной статистики вы видели, что есть выбросы. Эти значения влияют на оценки, потому что они не похожи на население, которое вы анализируете. Выбросы обычно смещают результаты. Например, положительный выброс имеет тенденцию переоценивать коэффициент.
Хорошим решением для решения этой проблемы является стандартизация переменной. Стандартизация означает стандартное отклонение единицы и означает ноль. Процесс стандартизации включает в себя два этапа. Прежде всего, это вычитает среднее значение переменной. Во-вторых, он делится на дисперсию, так что распределение имеет единичную дисперсию
Библиотека sklearn полезна для стандартизации переменных. Для этого вы можете использовать модуль предварительной обработки с масштабом объекта.
Вы можете использовать функцию ниже для масштабирования набора данных. Обратите внимание, что вы не масштабируете столбец метки и категориальные переменные.
from sklearn import preprocessing
def standardize_data(df):
X_scaled = preprocessing.scale(df[['CRIM', 'ZN', 'INDUS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD',
'TAX', 'PTRATIO', 'B', 'LSTAT']])
X_scaled_df = pd.DataFrame(X_scaled, columns = ['CRIM', 'ZN', 'INDUS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD',
'TAX', 'PTRATIO', 'B', 'LSTAT'])
df_scale = pd.concat([X_scaled_df,
df['CHAS'],
df['PRICE']],axis=1, join='inner')
return df_scale
Вы можете использовать функцию для построения масштабированного поезда / тестового набора.
df_train_scale = standardize_data(df_train) df_test_scale = standardize_data(df_test)
Основная регрессия: контрольный ориентир
Прежде всего, вы тренируетесь и тестируете модель без взаимодействия. Цель состоит в том, чтобы увидеть метрику производительности модели.
Способ обучения модели в точности как учебник по API высокого уровня . Вы будете использовать оценщик TensorFlow LinearRegressor.
В качестве напоминания вам необходимо выбрать:
- особенности, чтобы положить в модель
- преобразовать функции
- построить линейный регрессор
- построить функцию input_fn
- тренировать модель
- проверить модель
Вы используете все переменные в наборе данных для обучения модели. Всего существует одиннадцать непрерывных переменных и одна категориальная переменная
## Add features to the bucket: ### Define continuous list CONTI_FEATURES = ['CRIM', 'ZN', 'INDUS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD','TAX', 'PTRATIO', 'B', 'LSTAT'] CATE_FEATURES = ['CHAS']
Вы конвертируете объекты в числовой или категориальный столбец.
continuous_features = [tf.feature_column.numeric_column(k) for k in CONTI_FEATURES]
#categorical_features = tf.feature_column.categorical_column_with_hash_bucket(CATE_FEATURES, hash_bucket_size=1000)
categorical_features = [tf.feature_column.categorical_column_with_vocabulary_list('CHAS', ['yes','no'])]
Вы создаете модель с помощью linearRegressor. Вы храните модель в папке train_Boston
model = tf.estimator.LinearRegressor(
model_dir="train_Boston",
feature_columns=categorical_features + continuous_features)
Вывод
INFO:tensorflow:Using default config.
INFO:tensorflow:Using config: {'_model_dir': 'train_Boston', '_tf_random_seed': None, '_save_summary_steps': 100, '_save_checkpoints_steps': None, '_save_checkpoints_secs': 600, '_session_config': None, '_keep_checkpoint_max': 5, '_keep_checkpoint_every_n_hours': 10000, '_log_step_count_steps': 100, '_train_distribute': None, '_service': None, '_cluster_spec': <tensorflow.python.training.server_lib.ClusterSpec object at 0x1a19e76ac8>, '_task_type': 'worker', '_task_id': 0, '_global_id_in_cluster': 0, '_master': '', '_evaluation_master': '', '_is_chief': True, '_num_ps_replicas': 0, '_num_worker_replicas': 1}
Каждый столбец в данных поезда или теста преобразуется в тензор с помощью функции get_input_fn
FEATURES = ['CRIM', 'ZN', 'INDUS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD','TAX', 'PTRATIO', 'B', 'LSTAT', 'CHAS']
LABEL= 'PRICE'
def get_input_fn(data_set, num_epochs=None, n_batch = 128, shuffle=True):
return tf.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({k: data_set[k].values for k in FEATURES}),
y = pd.Series(data_set[LABEL].values),
batch_size=n_batch,
num_epochs=num_epochs,
shuffle=shuffle)
Вы оцениваете модель по данным поезда.
model.train(input_fn=get_input_fn(df_train_scale,
num_epochs=None,
n_batch = 128,
shuffle=False),
steps=1000)
Вывод
INFO:tensorflow:Calling model_fn. INFO:tensorflow:Done calling model_fn. INFO:tensorflow:Create CheckpointSaverHook. INFO:tensorflow:Graph was finalized. INFO:tensorflow:Running local_init_op. INFO:tensorflow:Done running local_init_op. INFO:tensorflow:Saving checkpoints for 1 into train_Boston/model.ckpt. INFO:tensorflow:loss = 56417.703, step = 1 INFO:tensorflow:global_step/sec: 144.457 INFO:tensorflow:loss = 76982.734, step = 101 (0.697 sec) INFO:tensorflow:global_step/sec: 258.392 INFO:tensorflow:loss = 21246.334, step = 201 (0.383 sec) INFO:tensorflow:global_step/sec: 227.998 INFO:tensorflow:loss = 30534.78, step = 301 (0.439 sec) INFO:tensorflow:global_step/sec: 210.739 INFO:tensorflow:loss = 36794.5, step = 401 (0.477 sec) INFO:tensorflow:global_step/sec: 234.237 INFO:tensorflow:loss = 8562.981, step = 501 (0.425 sec) INFO:tensorflow:global_step/sec: 238.1 INFO:tensorflow:loss = 34465.08, step = 601 (0.420 sec) INFO:tensorflow:global_step/sec: 237.934 INFO:tensorflow:loss = 12241.709, step = 701 (0.420 sec) INFO:tensorflow:global_step/sec: 220.687 INFO:tensorflow:loss = 11019.228, step = 801 (0.453 sec) INFO:tensorflow:global_step/sec: 232.702 INFO:tensorflow:loss = 24049.678, step = 901 (0.432 sec) INFO:tensorflow:Saving checkpoints for 1000 into train_Boston/model.ckpt. INFO:tensorflow:Loss for final step: 23228.568. <tensorflow.python.estimator.canned.linear.LinearRegressor at 0x1a19e76320>
Наконец, вы оцениваете характеристики модели на тестовом наборе
model.evaluate(input_fn=get_input_fn(df_test_scale,
num_epochs=1,
n_batch = 128,
shuffle=False),
steps=1000)
Вывод
INFO:tensorflow:Calling model_fn.
INFO:tensorflow:Done calling model_fn.
INFO:tensorflow:Starting evaluation at 2018-05-29-02:40:43
INFO:tensorflow:Graph was finalized.
INFO:tensorflow:Restoring parameters from train_Boston/model.ckpt-1000
INFO:tensorflow:Running local_init_op.
INFO:tensorflow:Done running local_init_op.
INFO:tensorflow:Finished evaluation at 2018-05-29-02:40:43
INFO:tensorflow:Saving dict for global step 1000: average_loss = 86.89361, global_step = 1000, loss = 1650.9785
{'average_loss': 86.89361, 'global_step': 1000, 'loss': 1650.9785}
Потеря модели — 1650. Это показатель, который будет побит в следующем разделе.
Улучшение модели: термин взаимодействия
В первой части урока вы увидели интересную связь между переменными. Различные методы визуализации показали, что INDUS и NOS связаны друг с другом и увеличивают влияние на цену. Не только взаимодействие между INDUS и NOS влияет на цену, но и этот эффект сильнее, когда он взаимодействует с DIS.
Настало время обобщить эту идею и посмотреть, сможете ли вы улучшить прогнозируемую модель.
Вам нужно добавить два новых столбца в каждый набор данных: train + test. Для этого вы создаете одну функцию для вычисления члена взаимодействия и другую для вычисления члена тройного взаимодействия. Каждая функция создает один столбец. После создания новых переменных вы можете объединить их с набором обучающих данных и набором тестовых данных.
Прежде всего, вам нужно создать новую переменную для взаимодействия между INDUS и NOX.
Приведенная ниже функция возвращает два кадра данных: train и test с взаимодействием между var_1 и var_2, в вашем случае INDUS и NOX.
def interaction_term(var_1, var_2, name):
t_train = df_train_scale[var_1]*df_train_scale[var_2]
train = t_train.rename(name)
t_test = df_test_scale[var_1]*df_test_scale[var_2]
test = t_test.rename(name)
return train, test
Вы храните две новые колонки
interation_ind_ns_train, interation_ind_ns_test= interaction_term('INDUS', 'NOX', 'INDUS_NOS')
interation_ind_ns_train.shape
(325,)
Во-вторых, вы создаете вторую функцию для вычисления члена тройного взаимодействия.
def triple_interaction_term(var_1, var_2,var_3, name):
t_train = df_train_scale[var_1]*df_train_scale[var_2]*df_train_scale[var_3]
train = t_train.rename(name)
t_test = df_test_scale[var_1]*df_test_scale[var_2]*df_test_scale[var_3]
test = t_test.rename(name)
return train, test
interation_ind_ns_dis_train, interation_ind_ns_dis_test= triple_interaction_term('INDUS', 'NOX', 'DIS','INDUS_NOS_DIS')
Теперь, когда у вас есть все необходимые столбцы, вы можете добавить их для обучения и тестирования набора данных. Вы называете эти два новых кадра данных:
- df_train_new
- df_test_new
df_train_new = pd.concat([df_train_scale,
interation_ind_ns_train,
interation_ind_ns_dis_train],
axis=1, join='inner')
df_test_new = pd.concat([df_test_scale,
interation_ind_ns_test,
interation_ind_ns_dis_test],
axis=1, join='inner')
df_train_new.head(5)
Вывод

Вот и все; Вы можете оценить новую модель с условиями взаимодействия и посмотреть, как метрика производительности.
CONTI_FEATURES_NEW = ['CRIM', 'ZN', 'INDUS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD','TAX', 'PTRATIO', 'B', 'LSTAT',
'INDUS_NOS', 'INDUS_NOS_DIS']
### Define categorical list
continuous_features_new = [tf.feature_column.numeric_column(k) for k in CONTI_FEATURES_NEW]
model = tf.estimator.LinearRegressor(
model_dir="train_Boston_1",
feature_columns= categorical_features + continuous_features_new)
Вывод
INFO:tensorflow:Using default config.
INFO:tensorflow:Using config: {'_model_dir': 'train_Boston_1', '_tf_random_seed': None, '_save_summary_steps': 100, '_save_checkpoints_steps': None, '_save_checkpoints_secs': 600, '_session_config': None, '_keep_checkpoint_max': 5, '_keep_checkpoint_every_n_hours': 10000, '_log_step_count_steps': 100, '_train_distribute': None, '_service': None, '_cluster_spec': <tensorflow.python.training.server_lib.ClusterSpec object at 0x1a1a5d5860>, '_task_type': 'worker', '_task_id': 0, '_global_id_in_cluster': 0, '_master': '', '_evaluation_master': '', '_is_chief': True, '_num_ps_replicas': 0, '_num_worker_replicas': 1}
КОД
FEATURES = ['CRIM', 'ZN', 'INDUS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD','TAX', 'PTRATIO', 'B', 'LSTAT','INDUS_NOS', 'INDUS_NOS_DIS','CHAS']
LABEL= 'PRICE'
def get_input_fn(data_set, num_epochs=None, n_batch = 128, shuffle=True):
return tf.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({k: data_set[k].values for k in FEATURES}),
y = pd.Series(data_set[LABEL].values),
batch_size=n_batch,
num_epochs=num_epochs,
shuffle=shuffle)
model.train(input_fn=get_input_fn(df_train_new,
num_epochs=None,
n_batch = 128,
shuffle=False),
steps=1000)
Вывод
INFO:tensorflow:Calling model_fn. INFO:tensorflow:Done calling model_fn. INFO:tensorflow:Create CheckpointSaverHook. INFO:tensorflow:Graph was finalized. INFO:tensorflow:Running local_init_op. INFO:tensorflow:Done running local_init_op. INFO:tensorflow:Saving checkpoints for 1 into train_Boston_1/model.ckpt. INFO:tensorflow:loss = 56417.703, step = 1 INFO:tensorflow:global_step/sec: 124.844 INFO:tensorflow:loss = 65522.3, step = 101 (0.803 sec) INFO:tensorflow:global_step/sec: 182.704 INFO:tensorflow:loss = 15384.148, step = 201 (0.549 sec) INFO:tensorflow:global_step/sec: 208.189 INFO:tensorflow:loss = 22020.305, step = 301 (0.482 sec) INFO:tensorflow:global_step/sec: 213.855 INFO:tensorflow:loss = 28208.812, step = 401 (0.468 sec) INFO:tensorflow:global_step/sec: 209.758 INFO:tensorflow:loss = 7606.877, step = 501 (0.473 sec) INFO:tensorflow:global_step/sec: 196.618 INFO:tensorflow:loss = 26679.76, step = 601 (0.514 sec) INFO:tensorflow:global_step/sec: 196.472 INFO:tensorflow:loss = 11377.163, step = 701 (0.504 sec) INFO:tensorflow:global_step/sec: 172.82 INFO:tensorflow:loss = 8592.07, step = 801 (0.578 sec) INFO:tensorflow:global_step/sec: 168.916 INFO:tensorflow:loss = 19878.56, step = 901 (0.592 sec) INFO:tensorflow:Saving checkpoints for 1000 into train_Boston_1/model.ckpt. INFO:tensorflow:Loss for final step: 19598.387. <tensorflow.python.estimator.canned.linear.LinearRegressor at 0x1a1a5d5e10>
model.evaluate(input_fn=get_input_fn(df_test_new,
num_epochs=1,
n_batch = 128,
shuffle=False),
steps=1000)
Вывод
INFO:tensorflow:Calling model_fn.
INFO:tensorflow:Done calling model_fn.
INFO:tensorflow:Starting evaluation at 2018-05-29-02:41:14
INFO:tensorflow:Graph was finalized.
INFO:tensorflow:Restoring parameters from train_Boston_1/model.ckpt-1000
INFO:tensorflow:Running local_init_op.
INFO:tensorflow:Done running local_init_op.
INFO:tensorflow:Finished evaluation at 2018-05-29-02:41:14
INFO:tensorflow:Saving dict for global step 1000: average_loss = 79.78876, global_step = 1000, loss = 1515.9863
{'average_loss': 79.78876, 'global_step': 1000, 'loss': 1515.9863}
Новая потеря — 1515. Просто добавив две новые переменные, вы смогли уменьшить потери. Это означает, что вы можете сделать лучший прогноз, чем с эталонной моделью.