Что такое TensorFlow?
В настоящее время самой известной библиотекой глубокого обучения в мире является Google TensorFlow. Продукт Google использует машинное обучение во всех своих продуктах для улучшения поисковой системы, перевода, подписи к изображениям или рекомендаций.
Чтобы привести конкретный пример, пользователи Google могут ускорить и улучшить поиск с помощью AI. Если пользователь вводит ключевое слово в строке поиска, Google дает рекомендацию о том, что может быть следующим словом.

Google хочет использовать машинное обучение, чтобы использовать преимущества своих массивных наборов данных, чтобы предоставить пользователям лучший опыт. Три разные группы используют машинное обучение:
- Исследователи
- Ученые данных
- Программисты.
Все они могут использовать один и тот же набор инструментов для совместной работы и повышения эффективности.
Google не просто имеет какие-либо данные; у них самый массивный компьютер в мире, поэтому Tensor Flow был построен в масштабе. TensorFlow — это библиотека, разработанная Google Brain Team для ускорения машинного обучения и глубоких исследований нейронных сетей.
Он был создан для работы на нескольких процессорах или графических процессорах и даже в мобильных операционных системах и имеет несколько оболочек на нескольких языках, таких как Python, C ++ или Java.
В этом уроке вы узнаете
- Что такое TensorFlow?
- История ТензорФлоу
- TensorFlow Architecture
- Где может работать Tensorflow?
- Введение в компоненты TensorFlow
- Почему TensorFlow популярен?
- Список известных алгоритмов, поддерживаемых TensorFlow
- Простой пример TensorFlow
- Опции для загрузки данных в TensorFlow
- Создать конвейер Tensorflow
История ТензорФлоу
Пару лет назад, глубокое обучение начало превосходить все другие алгоритмы машинного обучения, предоставляя огромное количество данных. Google увидел, что может использовать эти глубокие нейронные сети для улучшения своих услуг:
- Gmail
- Фото
- Поисковая система Google
Они создают среду под названием Tensorflow, чтобы позволить исследователям и разработчикам совместно работать над моделью ИИ. После разработки и масштабирования он позволяет многим людям использовать его.
Впервые он был опубликован в конце 2015 года, а первая стабильная версия появилась в 2017 году. Это открытый исходный код под лицензией Apache Open Source. Вы можете использовать его, изменять его и распространять измененную версию за плату, ничего не платя Google.
TensorFlow Architecture
Архитектура Tensorflow работает в трех частях:
- Предварительная обработка данных
- Построить модель
- Обучите и оцените модель
Он называется Tensorflow, потому что он принимает входные данные в виде многомерного массива, также известного как тензоры . Вы можете создать своего рода блок-схему операций (называемую «График»), которую вы хотите выполнить с этим вводом. Вход вводится на одном конце, а затем он проходит через эту систему множества операций и выходит на другом конце в качестве вывода.
Вот почему он называется TensorFlow, потому что входящий в него тензор проходит через список операций, а затем выходит на другую сторону.
Где может работать Tensorflow?
Требования к оборудованию и программному обеспечению TensorFlow можно разделить на
Этап разработки: это когда вы тренируете режим. Обучение обычно проводится на вашем рабочем столе или ноутбуке.
Фаза запуска или фаза вывода: после завершения обучения Tensorflow можно запускать на разных платформах. Вы можете запустить его на
- Рабочий стол под управлением Windows, MacOS или Linux
- Облако как веб-сервис
- Мобильные устройства, такие как iOS и Android
Вы можете обучить его на нескольких машинах, затем вы можете запустить его на другой машине, как только у вас будет обученная модель.
Модель можно обучать и использовать как на GPU, так и на CPU. Графические процессоры изначально были предназначены для видеоигр. В конце 2010 года исследователи из Стэнфорда обнаружили, что GPU также очень хорош в матричных операциях и алгебре, что делает их очень быстрыми для выполнения подобных вычислений. Глубокое обучение основано на умножении матриц. TensorFlow очень быстро вычисляет умножение матриц, потому что оно написано на C ++. Хотя он реализован на C ++, TensorFlow может быть доступен и управляться в основном другими языками, Python.
Наконец, важной особенностью TensorFlow является TensorBoard. TensorBoard позволяет графически и визуально отслеживать, что делает TensorFlow.
Введение в компоненты TensorFlow
Тензор
Название Tensorflow напрямую связано с его основной структурой: Tensor . В Tensorflow все вычисления включают тензоры. Тензор — это вектор или матрица n-измерений, представляющая все типы данных. Все значения в тензоре содержат идентичный тип данных с известной (или частично известной) формой . Форма данных — это размерность матрицы или массива.
Тензор может быть получен из входных данных или результатов вычислений. В TensorFlow все операции проводятся внутри графика . График представляет собой набор вычислений, которые происходят последовательно. Каждая операция называется операционным узлом и связана друг с другом.
На графике показаны операции и связи между узлами. Тем не менее, он не отображает значения. Край узлов — это тензор, т. Е. Способ заполнения операции данными.
диаграммы
TensorFlow использует каркас графа. График собирает и описывает все вычисления серии, сделанные во время обучения. Граф имеет много преимуществ:
- Это было сделано для запуска на нескольких процессорах или графических процессорах и даже мобильной операционной системе
- Переносимость графика позволяет сохранить вычисления для немедленного или последующего использования. График может быть сохранен для выполнения в будущем.
- Все вычисления в графе выполняются путем соединения тензоров
- Тензор имеет узел и ребро. Узел выполняет математическую операцию и производит выходные данные конечных точек. Ребра ребра объясняют отношения ввода / вывода между узлами.
Почему TensorFlow популярен?
TensorFlow — лучшая библиотека из всех, потому что она создана для того, чтобы она была доступна каждому. Библиотека Tensorflow включает в себя различные API для построения в масштабе архитектуры глубокого обучения, таких как CNN или RNN. TensorFlow основан на вычислении графа; это позволяет разработчику визуализировать построение нейронной сети с помощью Tensorboad. Этот инструмент полезен для отладки программы. Наконец, Tensorflow создан для развертывания в масштабе. Он работает на процессоре и графическом процессоре.
Tensorflow привлекает наибольшую популярность на GitHub по сравнению с другими системами глубокого обучения.
Список известных алгоритмов, поддерживаемых TensorFlow
В настоящее время TensorFlow 1.10 имеет встроенный API для:
- Линейная регрессия: tf.estimator.LinearRegressor
- Классификация: tf.estimator.LinearClassifier
- Классификация глубокого обучения: tf.estimator.DNNClassifier
- Глубокое изучение стереть и углубить: tf.estimator.DNNLinearCombinedClassifier
- Ускорение регрессии дерева: tf.estimator.BoostedTreesRegressor
- Усиленная классификация дерева: tf.estimator.BoostedTreesClassifier
Простой пример TensorFlow
import numpy as np import tensorflow as tf
В первых двух строках кода мы импортировали тензорный поток как tf. В Python обычной практикой является использование короткого имени для библиотеки. Преимущество состоит в том, чтобы не вводить полное имя библиотеки, когда нам нужно ее использовать. Например, мы можем импортировать тензор потока как tf и вызывать tf, когда мы хотим использовать функцию тензор потока
Давайте попрактикуемся в простейшем рабочем процессе Tensorflow на простом примере. Давайте создадим вычислительный граф, который умножает два числа вместе.
Во время примера мы умножим X_1 и X_2 вместе. Tensorflow создаст узел для подключения операции. В нашем примере это называется умножение. Когда график определен, вычислительные движки Tensorflow умножатся вместе на X_1 и X_2.
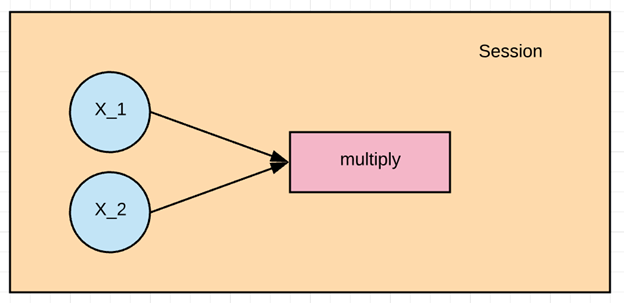
Наконец, мы запустим сеанс TensorFlow, который запустит вычислительный граф со значениями X_1 и X_2 и выведет результат умножения.
Давайте определим входные узлы X_1 и X_2. Когда мы создаем узел в Tensorflow, мы должны выбрать, какой тип узла создать. Узлы X1 и X2 будут узлами-заполнителями. Заполнитель присваивает новое значение каждый раз, когда мы делаем расчет. Мы создадим их как местозаполнитель узла TF.
Шаг 1: Определите переменную
X_1 = tf.placeholder(tf.float32, name = "X_1") X_2 = tf.placeholder(tf.float32, name = "X_2")
Когда мы создаем узел-заполнитель, мы должны передать, что тип данных будет добавлять числа здесь, чтобы мы могли использовать тип данных с плавающей точкой, давайте использовать tf.float32. Нам также нужно дать этому узлу имя. Это имя появится, когда мы посмотрим на графические визуализации нашей модели. Давайте назовем этот узел X_1, передав параметр name со значением X_1, и теперь давайте определим X_2 таким же образом. X_2.
Шаг 2: Определите вычисление
multiply = tf.multiply(X_1, X_2, name = "multiply")
Теперь мы можем определить узел, который выполняет операцию умножения. В Tensorflow мы можем сделать это, создав узел tf.multiply.
Мы передадим узлы X_1 и X_2 узлу умножения. Он указывает тензорному потоку связать эти узлы в вычислительном графе, поэтому мы просим его извлечь значения из x и y и умножить результат. Давайте также дадим узлу умножения имя умножения. Это полное определение нашего простого вычислительного графа.
Шаг 3: Выполнить операцию
Чтобы выполнить операции в графе, мы должны создать сеанс. В Tensorflow это делается с помощью tf.Session (). Теперь, когда у нас есть сеанс, мы можем попросить сеанс запустить операции на нашем вычислительном графе, вызвав сеанс. Чтобы запустить вычисление, нам нужно использовать run.
Когда операция сложения будет запущена, она увидит, что ей нужно получить значения узлов X_1 и X_2, поэтому нам также необходимо ввести значения для X_1 и X_2. Мы можем сделать это, предоставив параметр с именем feed_dict. Мы передаем значение 1,2,3 для X_1 и 4,5,6 для X_2.
Мы печатаем результаты с печатью (результат). Мы должны видеть 4, 10 и 18 для 1×4, 2×5 и 3×6
X_1 = tf.placeholder(tf.float32, name = "X_1")
X_2 = tf.placeholder(tf.float32, name = "X_2")
multiply = tf.multiply(X_1, X_2, name = "multiply")
with tf.Session() as session:
result = session.run(multiply, feed_dict={X_1:[1,2,3], X_2:[4,5,6]})
print(result)
[ 4. 10. 18.]
Опции для загрузки данных в TensorFlow
Первым шагом перед обучением алгоритму машинного обучения является загрузка данных. Существует два способа загрузки данных:
1. Загрузите данные в память: это самый простой способ. Вы загружаете все свои данные в память как единый массив. Вы можете написать код Python. Эти строки кода не связаны с Tensorflow.
2. Тензор потока данных. Tensorflow имеет встроенный API, который помогает загружать данные, выполнять операции и легко подавать алгоритм машинного обучения. Этот метод работает очень хорошо, особенно если у вас большой набор данных. Например, известно, что записи изображений огромны и не помещаются в память. Конвейер данных управляет памятью сам
Какое решение использовать?
Загрузить данные в память
Если ваш набор данных не слишком большой, то есть менее 10 гигабайт, вы можете использовать первый метод. Данные могут поместиться в память. Вы можете использовать знаменитую библиотеку Pandas для импорта файлов CSV. Вы узнаете больше о пандах в следующем уроке.
Загрузка данных с конвейером Tensorflow
Второй метод работает лучше всего, если у вас большой набор данных. Например, если у вас есть набор данных в 50 гигабайт, а на вашем компьютере только 16 гигабайт памяти, то произойдет сбой компьютера.
В этой ситуации вам нужно построить конвейер Tensorflow. Конвейер будет загружать данные в пакетном режиме или небольшими порциями. Каждая партия будет вытеснена на конвейер и будет готова к обучению. Построение конвейера является отличным решением, поскольку позволяет использовать параллельные вычисления. Это означает, что Tensorflow будет обучать модель на нескольких процессорах. Это способствует вычислениям и позволяет тренировать мощную нейронную сеть.
В следующих уроках вы увидите, как построить значительный конвейер для питания вашей нейронной сети.
Одним словом, если у вас небольшой набор данных, вы можете загрузить данные в память с помощью библиотеки Pandas.
Если у вас большой набор данных и вы хотите использовать несколько процессоров, вам будет удобнее работать с конвейером Tensorflow.
Создать конвейер Tensorflow
В предыдущем примере мы вручную добавляем три значения для X_1 и X_2. Теперь посмотрим, как загрузить данные в Tensorflow.
Шаг 1) Создайте данные
Прежде всего, давайте использовать библиотеку numpy для генерации двух случайных значений.
import numpy as np x_input = np.random.sample((1,2)) print(x_input)
[[0.8835775 0.23766977]]
Шаг 2. Создайте заполнитель
Как и в предыдущем примере, мы создаем заполнитель с именем X. Нам нужно явно указать форму тензора. В случае, если мы загрузим массив только с двумя значениями. Мы можем написать форму как shape = [1,2]
# using a placeholder x = tf.placeholder(tf.float32, shape=[1,2], name = 'X')
Шаг 3: Определите метод набора данных
Далее нам нужно определить набор данных, в котором мы можем заполнить значение заполнителя x. Нам нужно использовать метод tf.data.Dataset.from_tensor_slices
dataset = tf.data.Dataset.from_tensor_slices(x)
Шаг 4: Создать конвейер
На четвертом шаге нам нужно инициализировать конвейер, куда будут поступать данные. Нам нужно создать итератор с make_initializable_iterator. Мы называем это итератором. Затем нам нужно вызвать этот итератор для подачи следующей партии данных, get_next. Мы называем этот шаг get_next. Обратите внимание, что в нашем примере есть только один пакет данных только с двумя значениями.
iterator = dataset.make_initializable_iterator() get_next = iterator.get_next()
Шаг 5: Выполнить операцию
Последний шаг похож на предыдущий пример. Мы инициируем сеанс и запускаем итератор операции. Мы подаем feed_dict значением, сгенерированным numpy. Эти два значения будут заполнять заполнитель х. Затем мы запускаем get_next, чтобы напечатать результат.
with tf.Session() as sess:
# feed the placeholder with data
sess.run(iterator.initializer, feed_dict={ x: x_input })
print(sess.run(get_next)) # output [ 0.52374458 0.71968478]
[0.8835775 0.23766978]
Резюме
TensorFlow — самая известная библиотека глубокого обучения за последние годы. Практик, использующий TensorFlow, может построить любую структуру глубокого обучения, такую как CNN, RNN или простая искусственная нейронная сеть.
TensorFlow в основном используется учеными, стартапами и крупными компаниями. Google использует TensorFlow практически во всех ежедневных продуктах Google, включая Gmail, Фото и поисковую систему Google.
TensorFlow команды Google Brain разработали, чтобы заполнить пробел между исследователями и разработчиками продуктов. В 2015 году они обнародовали TensorFlow; это быстро растет в популярности. В настоящее время TensorFlow — это библиотека глубокого обучения с большим количеством репозиториев на GitHub.
Практики используют Tensorflow, потому что его легко развернуть в масштабе. Он предназначен для работы в облаке или на мобильных устройствах, таких как iOs и Android.
Tensorflow работает в сеансе. Каждый сеанс определяется графиком с различными вычислениями. Простым примером может быть умножение на число. В Tensorflow требуется три шага:
- Определите переменную
X_1 = tf.placeholder(tf.float32, name = "X_1") X_2 = tf.placeholder(tf.float32, name = "X_2")
- Определите вычисление
multiply = tf.multiply(X_1, X_2, name = "multiply")
- Выполнить операцию
with tf.Session() as session:
result = session.run(multiply, feed_dict={X_1:[1,2,3], X_2:[4,5,6]})
print(result)
Обычной практикой в Tensorflow является создание конвейера для загрузки данных. Если вы выполните эти пять шагов, вы сможете загрузить данные в TensorFLow
- Создать данные
import numpy as np x_input = np.random.sample((1,2)) print(x_input)
- Создать заполнитель
x = tf.placeholder(tf.float32, shape=[1,2], name = 'X')
- Определите метод набора данных
dataset = tf.data.Dataset.from_tensor_slices(x)
- Создать конвейер
iterator = dataset.make_initializable_iterator() get_next = iterator.get_next()
- Выполнить программу
with tf.Session() as sess:
sess.run(iterator.initializer, feed_dict={ x: x_input })
print(sess.run(get_next))