Что такое искусственная нейронная сеть?
Искусственная нейронная сеть (ANN) состоит из четырех основных объектов:
- Слои: все обучение происходит в слоях. Есть 3 слоя 1) Вход 2) Скрытый и 3) Выход
- функция и метка: ввод данных в сеть (функции) и вывод из сети (метки)
- функция потерь: метрика, используемая для оценки эффективности фазы обучения
- оптимизатор: улучшить обучение, обновляя знания в сети
Нейронная сеть будет принимать входные данные и помещать их в ансамбль слоев. Сеть должна оценить свою производительность с функцией потерь. Функция потерь дает сети представление о пути, который необходимо пройти, прежде чем овладеть знаниями. Сеть должна улучшить свои знания с помощью оптимизатора.
Если вы посмотрите на рисунок ниже, вы поймете основной механизм.
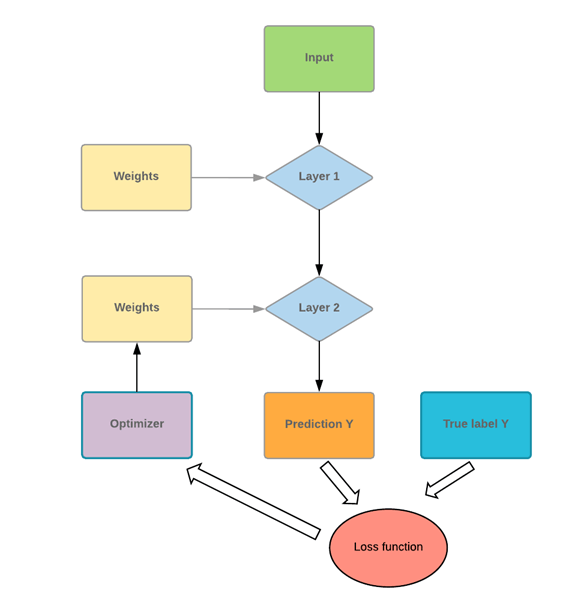
The program takes some input values and pushes them into two fully connected layers. Imagine you have a math problem, the first thing you do is to read the corresponding chapter to solve the problem. You apply your new knowledge to solve the problem. There is a high chance you will not score very well. It is the same for a network. The first time it sees the data and makes a prediction, it will not match perfectly with the actual data.
To improve its knowledge, the network uses an optimizer. In our analogy, an optimizer can be thought of as rereading the chapter. You gain new insights/lesson by reading again. Similarly, the network uses the optimizer, updates its knowledge, and tests its new knowledge to check how much it still needs to learn. The program will repeat this step until it makes the lowest error possible.
In our math problem analogy, it means you read the textbook chapter many times until you thoroughly understand the course content. Even after reading multiple times, if you keep making an error, it means you reached the knowledge capacity with the current material. You need to use different textbook or test different method to improve your score. For a neural network, it is the same process. If the error is far from 100%, but the curve is flat, it means with the current architecture; it cannot learn anything else. The network has to be better optimized to improve the knowledge.
In this tutorial, you will learn-
- What is Artificial Neural Network?
- Neural Network Architecture
- Loss function
- Optimizer
- Limitations of Neural Network
- Network size
- Weight Regularization
- Dropout
- Example Neural Network in TensorFlow
- Train a neural network with TensorFlow
- Step 1) Import the data
- Step 2) Transform the data
- Step 3) Construct the tensor
- Step 4) Build the model
- Step 5) Train and evaluate the model
- Step 6) Improve the model
Neural Network Architecture
Layers
A layer is where all the learning takes place. Inside a layer, there are an infinite amount of weights (neurons). A typical neural network is often processed by densely connected layers (also called fully connected layers). It means all the inputs are connected to the output.
A typical neural network takes a vector of input and a scalar that contains the labels. The most comfortable set up is a binary classification with only two classes: 0 and 1.
The network takes an input, sends it to all connected nodes and computes the signal with an activation function.
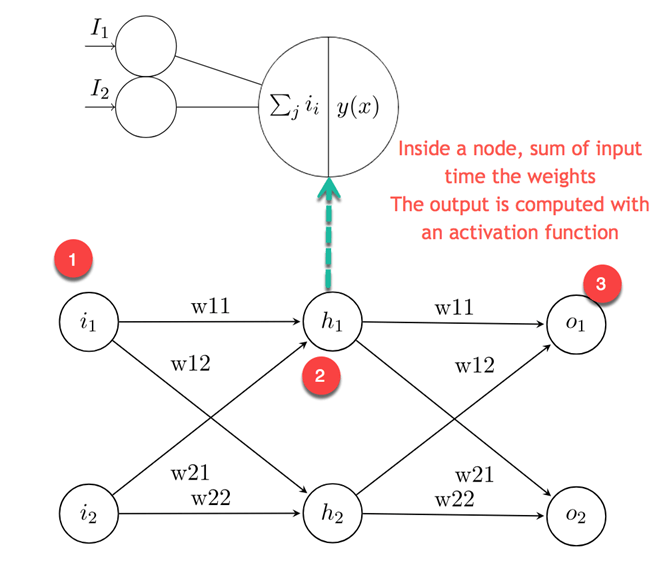
На рисунке выше изображена эта идея. Первый слой представляет собой входные значения для второго слоя, называемого скрытым слоем, получает взвешенные входные данные от предыдущего слоя
- Первый узел — это входные значения
- Нейрон разлагается на входную часть и функцию активации. Левая часть получает все входные данные от предыдущего слоя. Правая часть представляет собой сумму входных переходов в функцию активации.
- Выходное значение вычисляется из скрытых слоев и используется для прогнозирования. Для классификации он равен номеру класса. Для регрессии прогнозируется только одно значение.
Функция активации
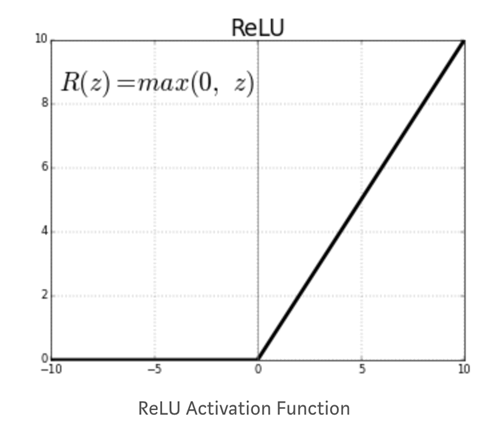
Функция активации узла определяет выходные данные с учетом набора входных данных. Вам нужна функция активации, чтобы позволить сети изучать нелинейный шаблон. Распространенной функцией активации является Relu, выпрямленная линейная единица. Функция дает ноль для всех отрицательных значений.
Другие функции активации:
- Кусочно-линейный
- сигмоид
- Tanh
- Leaky Relu
Критическое решение, которое необходимо принять при построении нейронной сети:
- Сколько слоев в нейронной сети
- Сколько скрытых единиц для каждого слоя
Нейронная сеть с большим количеством слоев и скрытых единиц может выучить сложное представление данных, но это делает вычисления в сети очень дорогими.
Функция потери
После того, как вы определили скрытые слои и функцию активации, вам нужно указать функцию потерь и оптимизатор.
Для бинарной классификации обычной практикой является использование бинарной функции кросс-энтропийной потери. В линейной регрессии вы используете среднеквадратичную ошибку.
Функция потерь является важной метрикой для оценки производительности оптимизатора. Во время обучения этот показатель будет минимизирован. Вам нужно тщательно выбирать это количество в зависимости от типа проблемы, с которой вы имеете дело.
оптимизатор
Функция потерь является мерой производительности модели. Оптимизатор поможет улучшить вес сети, чтобы уменьшить потери. Доступны разные оптимизаторы, но наиболее распространенным является Stochastic Gradient Descent.
Обычные оптимизаторы:
- Оптимизация импульса,
- Нестеров Ускоренный Градиент,
- AdaGrad,
- Адам оптимизация
Ограничения нейронной сети
переобучения
Общая проблема со сложной нейронной сетью — трудности в обобщении невидимых данных. Нейронная сеть с большим количеством весов может очень хорошо идентифицировать конкретные детали в наборе поездов, но часто приводит к переоснащению. Если данные не сбалансированы внутри групп (т. Е. Недостаточно данных, доступных в некоторых группах), сеть будет очень хорошо учиться во время обучения, но не сможет обобщить такой шаблон для данных, которые раньше никогда не видели.
В машинном обучении существует компромисс между оптимизацией и обобщением.
Оптимизация модели требует поиска наилучших параметров, минимизирующих потери тренировочного набора.
Обобщение, однако, говорит о том, как ведет себя модель для невидимых данных.
Чтобы модель не могла фиксировать определенные детали или нежелательные образцы данных обучения, вы можете использовать различные методы. Лучший способ — это иметь сбалансированный набор данных с достаточным количеством данных. Искусство уменьшения переоснащения называется регуляризацией . Давайте рассмотрим некоторые традиционные методы.
Размер сети
Известно, что нейронная сеть со слишком большим количеством слоев и скрытых единиц очень сложна. Простой способ уменьшить сложность модели — уменьшить ее размер. Не существует наилучшей практики для определения количества слоев. Вы должны начать с небольшого количества слоя и увеличивать его размер, пока не найдете подходящую модель.
Регуляризация веса
Стандартный метод предотвращения переоснащения заключается в добавлении ограничений к весам сети. Ограничение заставляет размер сети принимать только небольшие значения. Ограничение добавляется к функции потери ошибки. Существует два вида регуляризации:
L1: лассо: стоимость пропорциональна абсолютному значению весовых коэффициентов
L2: Хребет: Стоимость пропорциональна квадрату значения весовых коэффициентов.
Выбывать
Dropout — странная, но полезная техника. Сеть с выпадением означает, что некоторые веса будут случайно установлены на ноль. Представьте, что у вас есть массив весов [0,1, 1,7, 0,7, -0,9]. Если в нейронной сети есть выпадение, оно станет [0,1, 0, 0, -0,9] со случайным распределением 0. Параметр, который управляет выпадением, — это коэффициент отсева. Скорость определяет, сколько весов будет установлено на ноль. Частота от 0,2 до 0,5 распространена.
Пример нейронной сети в TensorFlow
Давайте посмотрим, как работает нейронная сеть для типичной задачи классификации. Есть два входа, x1 и x2 со случайным значением. Вывод является двоичным классом. Цель состоит в том, чтобы классифицировать метку на основе двух функций. Для выполнения этой задачи архитектура нейронной сети определяется следующим образом:
- Два скрытых слоя
- Первый слой имеет четыре полностью связанных нейрона
- Второй слой имеет два полностью связанных нейрона
- Функция активации является Relu
- Добавьте Регуляризацию L2 со скоростью обучения 0,003
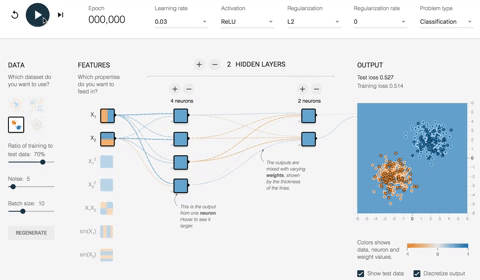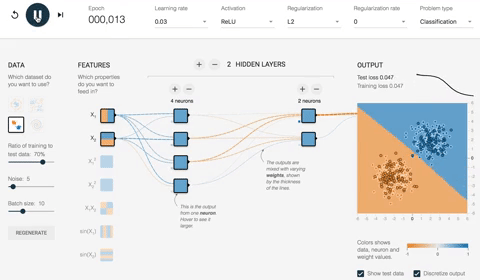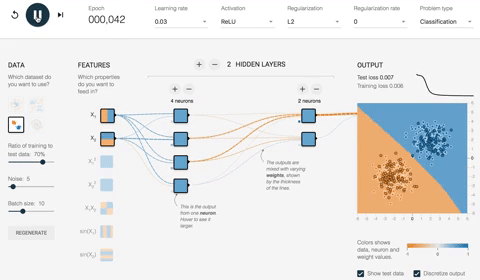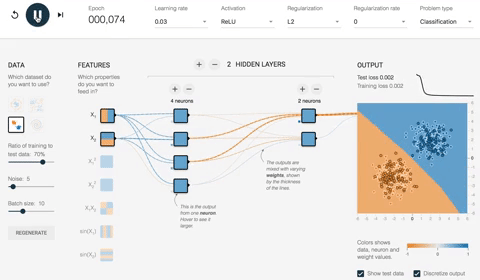
Сеть будет оптимизировать вес в течение 180 эпох с размером пакета 10. В видео ниже вы можете увидеть, как весы эволюционируют и как сеть улучшает отображение классификации.
Прежде всего, сеть назначает случайные значения всем весам.
- При случайных весах, т. Е. Без оптимизации, потери на выходе составляют 0,453. На рисунке ниже представлена сеть с разными цветами.
- Как правило, оранжевый цвет представляет отрицательные значения, в то время как синий цвет показывает положительные значения.
- Точки данных имеют одинаковое представление; синие — положительные, а оранжевые — отрицательные.
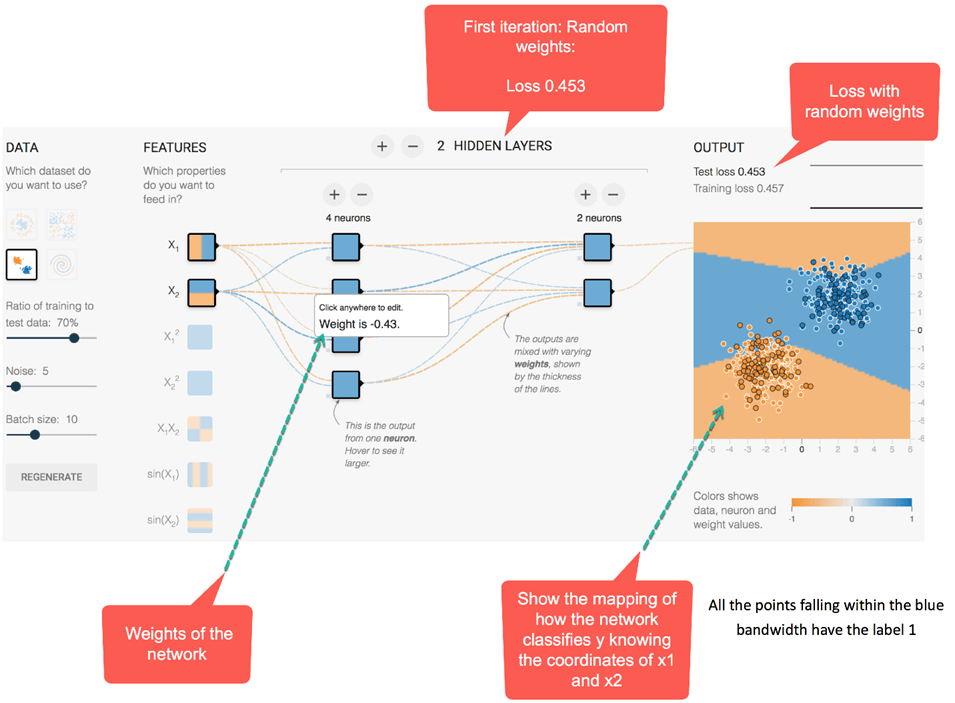
Внутри второго скрытого слоя линии окрашены в соответствии со знаком весов. Оранжевые линии обозначают отрицательные веса, а синие — положительные.
Как вы можете видеть, при отображении выходных данных сеть допускает много ошибок. Посмотрим, как ведет себя сеть после оптимизации.
На рисунке ниже показаны результаты оптимизированной сети. Прежде всего, вы заметили, что сеть успешно научилась классифицировать точку данных. Вы можете видеть на картинке раньше; начальный вес был -0,43, тогда как после оптимизации он весит -0,95.
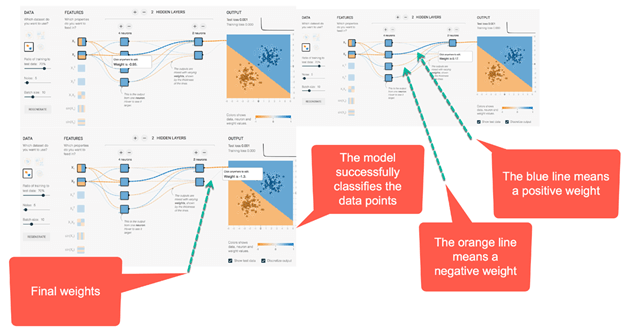
Идея может быть обобщена для сетей с большим количеством скрытых слоев и нейронов. Вы можете поиграть в ссылку .
Обучаем нейронную сеть с TensorFlow
В этой части руководства вы узнаете, как обучать нейронную сеть с помощью TensorFlow, используя оценщик API DNNClassifier.
Мы будем использовать набор данных MNIST для обучения вашей первой нейронной сети. Обучение нейронной сети с Tensorflow не очень сложно. Шаг предварительной обработки выглядит точно так же, как и в предыдущих уроках. Вы будете действовать следующим образом:
- Шаг 1: Импортируйте данные
- Шаг 2. Преобразование данных
- Шаг 3: Построить тензор
- Шаг 4: Постройте модель
- Шаг 5: Обучите и оцените модель
- Шаг 6: улучшить модель
Шаг 1) Импортируйте данные
Прежде всего, вам необходимо импортировать необходимую библиотеку. Вы можете импортировать набор данных MNIST, используя scikit learn.
Набор данных MNIST является обычно используемым набором данных для тестирования новых методов или алгоритмов. Этот набор данных представляет собой набор изображений размером 28×28 пикселей с рукописными цифрами от 0 до 9. В настоящее время самая низкая ошибка в тесте составляет 0,27 процента при комитете из 7 сверточных нейронных сетей.
import numpy as np import tensorflow as tf np.random.seed(1337)
Вы можете скачать scikit learn временно по этому адресу. Скопируйте и вставьте набор данных в удобную папку. Чтобы импортировать данные в python, вы можете использовать fetch_mldata из scikit learn. Вставьте путь к файлу внутри fetch_mldata, чтобы получить данные.
from sklearn.datasets import fetch_mldata
mnist = fetch_mldata(' /Users/Thomas/Dropbox/Learning/Upwork/tuto_TF/data/mldata/MNIST original')
print(mnist.data.shape)
print(mnist.target.shape)
После этого вы импортируете данные и получите форму обоих наборов данных.
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(mnist.data, mnist.target, test_size=0.2, random_state=42) y_train = y_train.astype(int) y_test = y_test.astype(int) batch_size =len(X_train) print(X_train.shape, y_train.shape,y_test.shape )
Шаг 2) Преобразование данных
В предыдущем уроке вы узнали, что вам необходимо преобразовать данные, чтобы ограничить влияние выбросов. В этом уроке вы преобразуете данные с помощью скейлера min-max. Формула:
(X-min_x)/(max_x - min_x)
Scikit узнает, что уже имеет функцию для этого: MinMaxScaler ()
## resclae from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler() # Train X_train_scaled = scaler.fit_transform(X_train.astype(np.float64)) # test X_test_scaled = scaler.fit_transform(X_test.astype(np.float64))
Шаг 3) Построить тензор
Теперь вы знакомы с тем, как создать тензор в Tensorflow. Вы можете преобразовать набор поездов в числовой столбец.
feature_columns = [tf.feature_column.numeric_column('x', shape=X_train_scaled.shape[1:])]
Шаг 4) Постройте модель
Архитектура нейронной сети содержит 2 скрытых слоя с 300 единицами для первого уровня и 100 единицами для второго. Мы используем эти значения на основе нашего собственного опыта. Вы можете настроить значения этих тезисов и посмотреть, как это влияет на точность работы сети.
Для построения модели вы используете оценщик DNNClassifier. Вы можете добавить количество слоев к аргументу feature_columns. Вам нужно установить количество классов до 10, так как в тренировочном наборе десять классов. Вы уже знакомы с синтаксисом объекта оценки. Аргументы функции столбцы, количество классов и model_dir точно такие же, как в предыдущем уроке. Новый аргумент hidden_unit управляет количеством слоев и количеством узлов для подключения к нейронной сети. В приведенном ниже коде есть два скрытых слоя, первый из которых соединяет 300 узлов, а второй — 100 узлов.
Чтобы построить оценщик, используйте tf.estimator.DNNClassifier со следующими параметрами:
- feature_columns: определить столбцы для использования в сети
- hidden_units: определить количество скрытых нейронов
- n_classes: определить количество классов для прогнозирования
- model_dir: определить путь TensorBoard
estimator = tf.estimator.DNNClassifier(
feature_columns=feature_columns,
hidden_units=[300, 100],
n_classes=10,
model_dir = '/train/DNN')
Шаг 5) Обучите и оцените модель
Вы можете использовать метод NumPy, чтобы обучить модель и оценить ее
# Train the estimator
train_input = tf.estimator.inputs.numpy_input_fn(
x={"x": X_train_scaled},
y=y_train,
batch_size=50,
shuffle=False,
num_epochs=None)
estimator.train(input_fn = train_input,steps=1000)
eval_input = tf.estimator.inputs.numpy_input_fn(
x={"x": X_test_scaled},
y=y_test,
shuffle=False,
batch_size=X_test_scaled.shape[0],
num_epochs=1)
estimator.evaluate(eval_input,steps=None)
Вывод:
{'accuracy': 0.9637143,
'average_loss': 0.12014342,
'loss': 1682.0079,
'global_step': 1000}
Нынешняя архитектура приводит к точности оценки 96%.
Шаг 6) Улучшение модели
Вы можете попытаться улучшить модель, добавив параметры регуляризации.
Мы будем использовать оптимизатор Adam с коэффициентом отсева 0,3, L1 из X и L2 из y. В TensorFlow вы можете управлять оптимизатором с помощью последовательности объектов, следующей за именем оптимизатора. TensorFlow — это встроенный API для оптимизатора Proximal AdaGrad.
Чтобы добавить регуляризацию в глубокую нейронную сеть, вы можете использовать tf.train.ProximalAdagradOptimizer со следующим параметром
- Скорость обучения: learning_rate
- Регуляризация L1: l1_regularization_strength
- Регуляризация L2: l2_regularization_strength
estimator_imp = tf.estimator.DNNClassifier(
feature_columns=feature_columns,
hidden_units=[300, 100],
dropout=0.3,
n_classes = 10,
optimizer=tf.train.ProximalAdagradOptimizer(
learning_rate=0.01,
l1_regularization_strength=0.01,
l2_regularization_strength=0.01
),
model_dir = '/train/DNN1')
estimator_imp.train(input_fn = train_input,steps=1000)
estimator_imp.evaluate(eval_input,steps=None)
Вывод:
{'accuracy': 0.95057142,
'average_loss': 0.17318928,
'loss': 2424.6499,
'global_step': 2000}
Значения, выбранные для уменьшения переоснащения, не улучшили точность модели. Ваша первая модель имела точность 96%, в то время как модель с регуляризатором L2 имеет точность 95%. Вы можете попробовать разные значения и посмотреть, как это влияет на точность.
Резюме
Из этого урока вы узнаете, как построить нейронную сеть. Нейронная сеть требует:
- Number of hidden layers
- Number of fully connected node
- Activation function
- Optimizer
- Number of classes
In TensorFlow, you can train a neural network for classification problem with:
- tf.estimator.DNNClassifier
The estimator requires to specify:
- feature_columns=feature_columns,
- hidden_units=[300, 100]
- n_classes=10
- model_dir
You can improve the model by using different optimizers. In this tutorial, you learned how to use Adam Grad optimizer with a learning rate and add a control to prevent overfitting.