В этом уроке вы узнаете:
Импортировать CSV
Во время обучения TensorFlow вы будете использовать набор данных для взрослых. Это часто используется с задачей классификации. Он доступен по этому адресу https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data.
Данные хранятся в формате CSV. Этот набор данных включает в себя восемь категориальных переменных:
Этот набор данных включает в себя восемь категориальных переменных:
- workclass
- образование
- супружеский
- род занятий
- отношения
- гонка
- секс
- родная страна
кроме того, шесть непрерывных переменных:
- возраст
- fnlwgt
- education_num
- прирост капитала
- capital_loss
hours_week
Чтобы импортировать набор данных CSV, вы можете использовать объект pd.read_csv (). Основной аргумент внутри:
Синтаксис:
pandas.read_csv(filepath_or_buffer,sep=', ',`names=None`,`index_col=None`,`skipinitialspace=False`)
- filepath_or_buffer: путь или URL с данными
- sep = ‘,’: определить разделитель для использования
- `names = None`: назовите столбцы. Если набор данных имеет десять столбцов, вам нужно передать десять имен
- `index_col = None`: если да, первый столбец используется как индекс строки
- `skipinitialspace = False`: пропустить пробелы после разделителя.
Для получения дополнительной информации о readcsv (), пожалуйста, проверьте официальную документацию
https://pandas.pydata.org/pandas-docs/stable/generated/pandas.read_csv.html .
Рассмотрим следующий пример
## Import csv
import pandas as pd
## Define path data
COLUMNS = ['age','workclass', 'fnlwgt', 'education', 'education_num', 'marital',
'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss',
'hours_week', 'native_country', 'label']
PATH = "https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data"
df_train = pd.read_csv(PATH,
skipinitialspace=True,
names = COLUMNS,
index_col=False)
df_train.shape
Вывод:
(32561, 15)
Группа по
Простой способ просмотреть данные — использовать метод groupby. Этот метод может помочь вам обобщить данные по группам. Ниже приведен список методов, доступных с groupby:
- считать: считать
- мин: мин
- max: max
- значит: значит
- медиана: медиана
- стандартное отклонение: SDT
- так далее
Внутри groupby () вы можете использовать столбец, к которому хотите применить метод.
Давайте посмотрим на одну группу с набором данных для взрослых. Вы получите среднее значение всех непрерывных переменных по типу дохода, т.е. выше 50 тыс. Или ниже 50 тыс.
df_train.groupby(['label']).mean()
| возраст | fnlwgt | education_num | прирост капитала | capital_loss | hours_week | |
| метка | ||||||
| <= 50K | 36.783738 | +190340,86517 | 9.595065 | 148.752468 | 53.142921 | 38.840210 |
| > 50K | 44.249841 | +188005,00000 | 11.611657 | 4006.142456 | 195.001530 | 45.473026 |
Вы можете получить минимальный возраст по типу домашнего хозяйства
df_train.groupby ([ ‘этикетка’]) [ ‘возраст’]. мин ()
label <=50K 17 >50K 19 Name: age, dtype: int64
Вы также можете группировать по нескольким столбцам. Например, вы можете получить максимальный прирост капитала в зависимости от типа домохозяйства и семейного положения.
df_train.groupby(['label', 'marital'])['capital_gain'].max()
label marital
<=50K Divorced 34095
Married-AF-spouse 2653
Married-civ-spouse 41310
Married-spouse-absent 6849
Never-married 34095
Separated 7443
Widowed 6849
>50K Divorced 99999
Married-AF-spouse 7298
Married-civ-spouse 99999
Married-spouse-absent 99999
Never-married 99999
Separated 99999
Widowed 99999
Name: capital_gain, dtype: int64
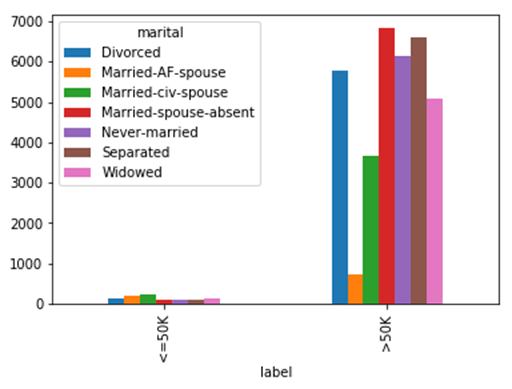
Вы можете создать сюжет по группам. Один из способов сделать это — использовать график после группировки.
Чтобы создать более превосходный график, вы будете использовать unstack () после mean (), чтобы у вас был такой же многоуровневый индекс, или вы объединяете значения с доходом ниже 50 тыс. И выше 50 тыс. В этом случае сюжет будет иметь две группы вместо 14 (2 * 7).
Если вы используете Jupyter Notebook, обязательно добавьте% matplotlib inline, иначе график не будет отображаться
%matplotlib inline df_plot = df_train.groupby(['label', 'marital'])['capital_gain'].mean().unstack() df_plot