Что такое сверточная нейронная сеть?
Сверточная нейронная сеть, также известная как коннет или CNN, является хорошо известным методом в приложениях компьютерного зрения. Этот тип архитектуры является доминирующим для распознавания объектов из изображения или видео.
В этом уроке вы узнаете, как создать коннет и как использовать TensorFlow для решения рукописного набора данных.
В этом уроке вы узнаете
- Сверточная нейронная сеть
- Архитектура сверточной нейронной сети
- Компоненты Convnets
- Поезд CNN с TensorFlow
- Шаг 1: Загрузить набор данных
- Шаг 2: входной слой
- Шаг 3: сверточный слой
- Шаг 4: объединение слоя
- Шаг 5: Второй сверточный слой и объединяющий слой
- Шаг 6: Плотный слой
- Шаг 7: Logit Layer
Архитектура сверточной нейронной сети
Подумайте о Facebook несколько лет назад, после того как вы загрузили фотографию в свой профиль, вас попросили добавить имя к лицу на картинке вручную. В настоящее время Facebook использует convnet для автоматической пометки вашего друга на картинке.
Сверточная нейронная сеть не очень сложна для понимания. Входное изображение обрабатывается на этапе свертки, а затем присваивается метка.
Типичная архитектура Connet может быть обобщена на рисунке ниже. Прежде всего, изображение передается в сеть; это называется входным изображением. Затем входное изображение проходит бесконечное количество шагов; это сверточная часть сети. Наконец, нейронная сеть может предсказать цифру на изображении.
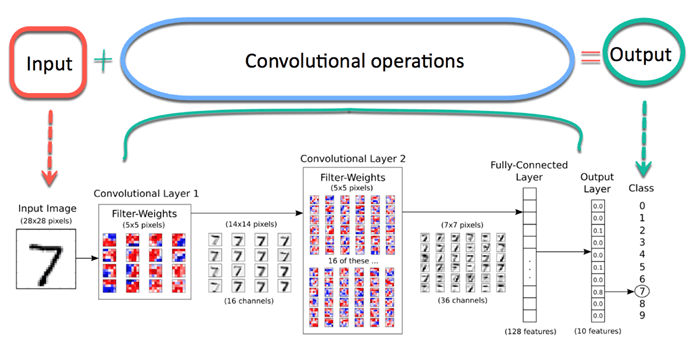
Изображение состоит из массива пикселей с высотой и шириной. Изображение в градациях серого имеет только один канал, в то время как цветное изображение имеет три канала (каждый для красного, зеленого и синего). Канал накладывается друг на друга. В этом уроке вы будете использовать изображение в градациях серого только с одним каналом. Каждый пиксель имеет значение от 0 до 255, чтобы отражать интенсивность цвета. Например, пиксель, равный 0, покажет белый цвет, а пиксель со значением, близким к 255, будет темнее.
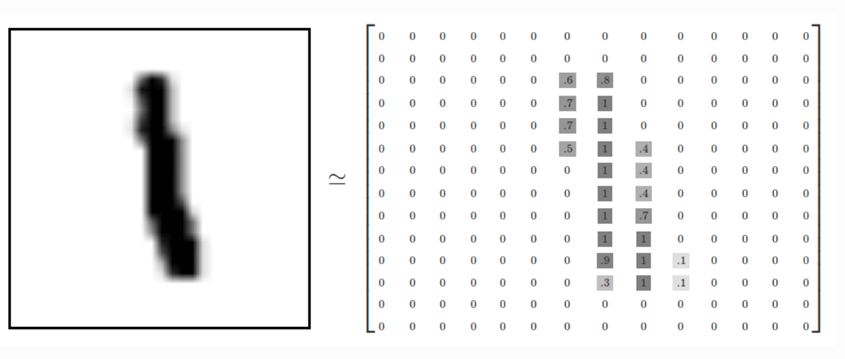
Давайте посмотрим на изображение, хранящееся в наборе данных MNIST . На рисунке ниже показано, как представить изображение слева в матричном формате. Обратите внимание, что исходная матрица была стандартизирована, чтобы быть между 0 и 1. Для более темного цвета значение в матрице составляет приблизительно 0,9, в то время как белые пиксели имеют значение 0.
Сверточная операция
Наиболее важным компонентом в модели является сверточный слой. Эта часть направлена на уменьшение размера изображения для более быстрого вычисления весов и улучшения его обобщения.
Во время сверточной части сеть сохраняет основные характеристики изображения и исключает ненужные шумы. Например, модель учится узнавать слона по картинке с горой на заднем плане. Если вы используете традиционную нейронную сеть, модель назначит вес всем пикселям, включая пиксели с горы, что несущественно и может ввести сеть в заблуждение.
Вместо этого, сверточная нейронная сеть будет использовать математическую технику для извлечения только наиболее релевантных пикселей. Эта математическая операция называется сверткой. Этот метод позволяет сети изучать все более сложные функции на каждом уровне. Свертка делит матрицу на маленькие кусочки, чтобы изучить наиболее важные элементы в каждом кусочке.
Компоненты Convnets
Есть четыре компонента Convnets
- свертка
- Нелинейность (ReLU)
- Объединение или подвыбор
- Классификация (полностью связанный слой)
- свертка
Целью свертки является локальное выделение признаков объекта на изображении. Это означает, что сеть изучит определенные шаблоны в пределах изображения и сможет распознать его повсюду в изображении.
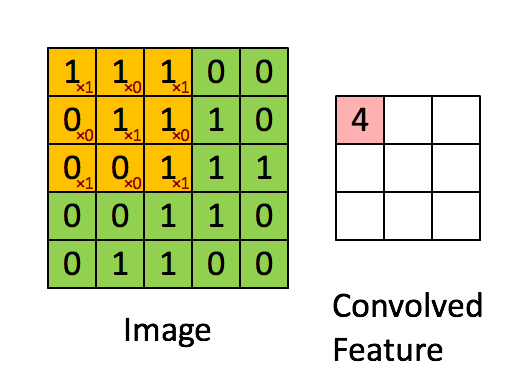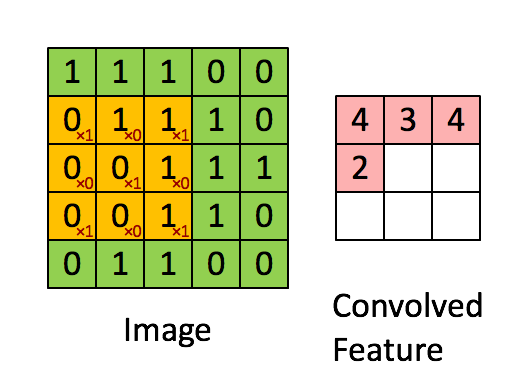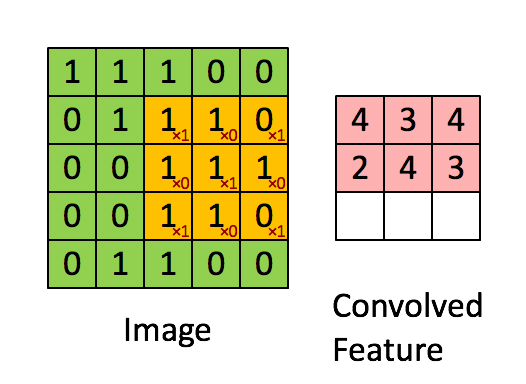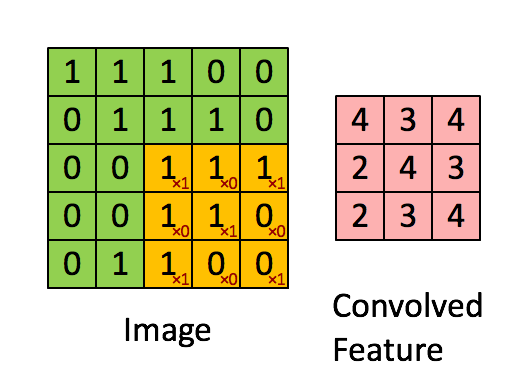
Свертка — это поэлементное умножение. Концепция проста для понимания. Компьютер отсканирует часть изображения, обычно размером 3х3, и умножит его на фильтр. Результат поэлементного умножения называется картой объектов. Этот шаг повторяется до тех пор, пока не будет отсканировано все изображение. Обратите внимание, что после свертки размер изображения уменьшается.
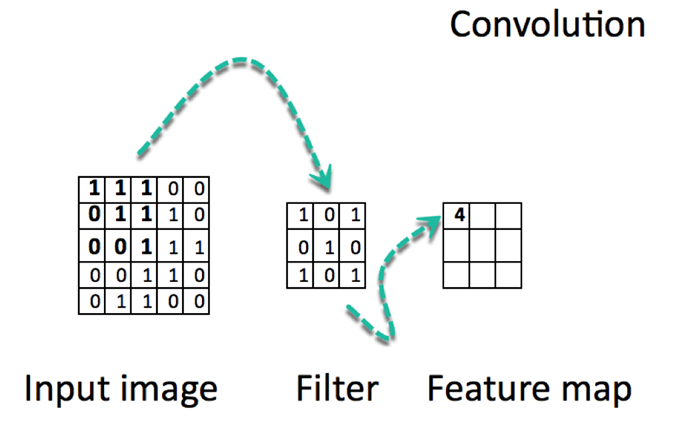
Ниже приведен URL-адрес, чтобы увидеть, как работает свертка.
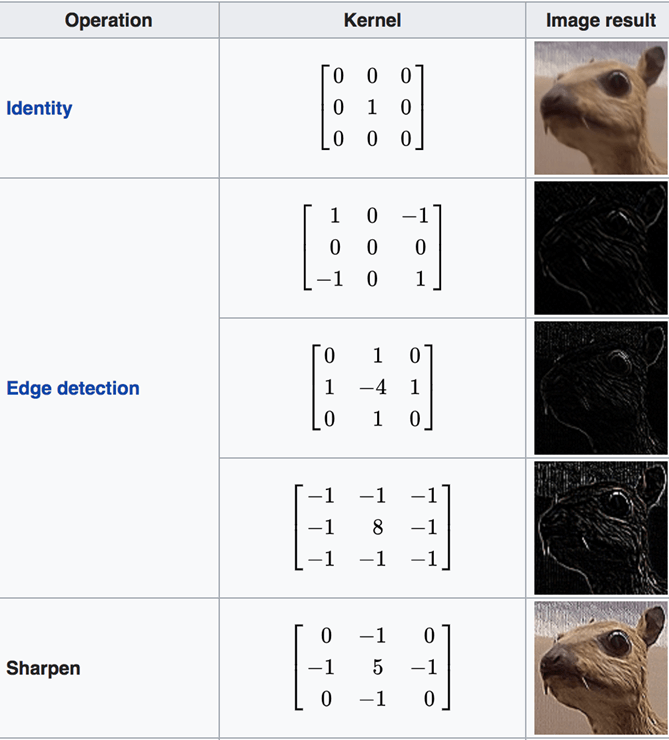
Есть множество доступных каналов. Ниже мы перечислили некоторые каналы. Вы можете видеть, что каждый фильтр имеет определенную цель. Обратите внимание, на рисунке ниже; Ядро — это синоним фильтра.
Арифметика за сверткой
Фаза свертки будет применять фильтр к небольшому массиву пикселей в пределах изображения. Фильтр будет двигаться вдоль входного изображения с общей формой 3×3 или 5×5. Это означает, что сеть будет скользить этими окнами по всему входному изображению и вычислять свертку. Изображение ниже показывает, как работает свертка. Размер исправления составляет 3х3, а выходная матрица является результатом поэлементной операции между матрицей изображения и фильтром.
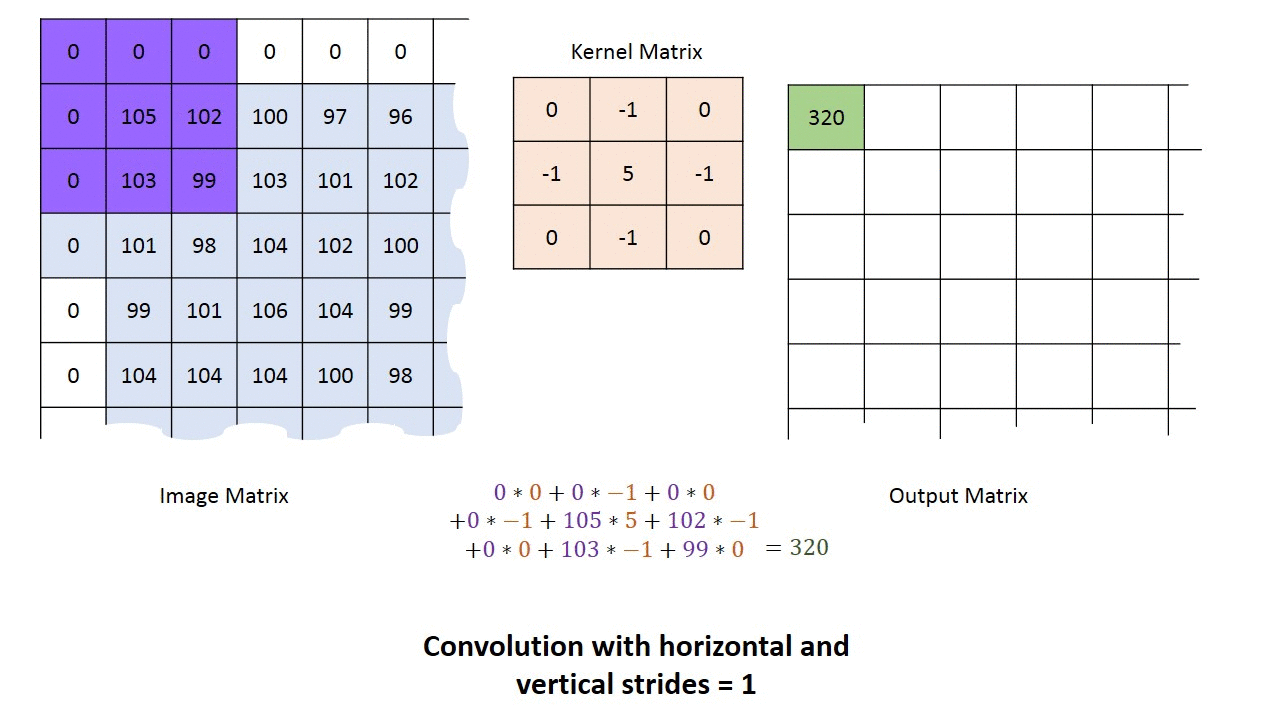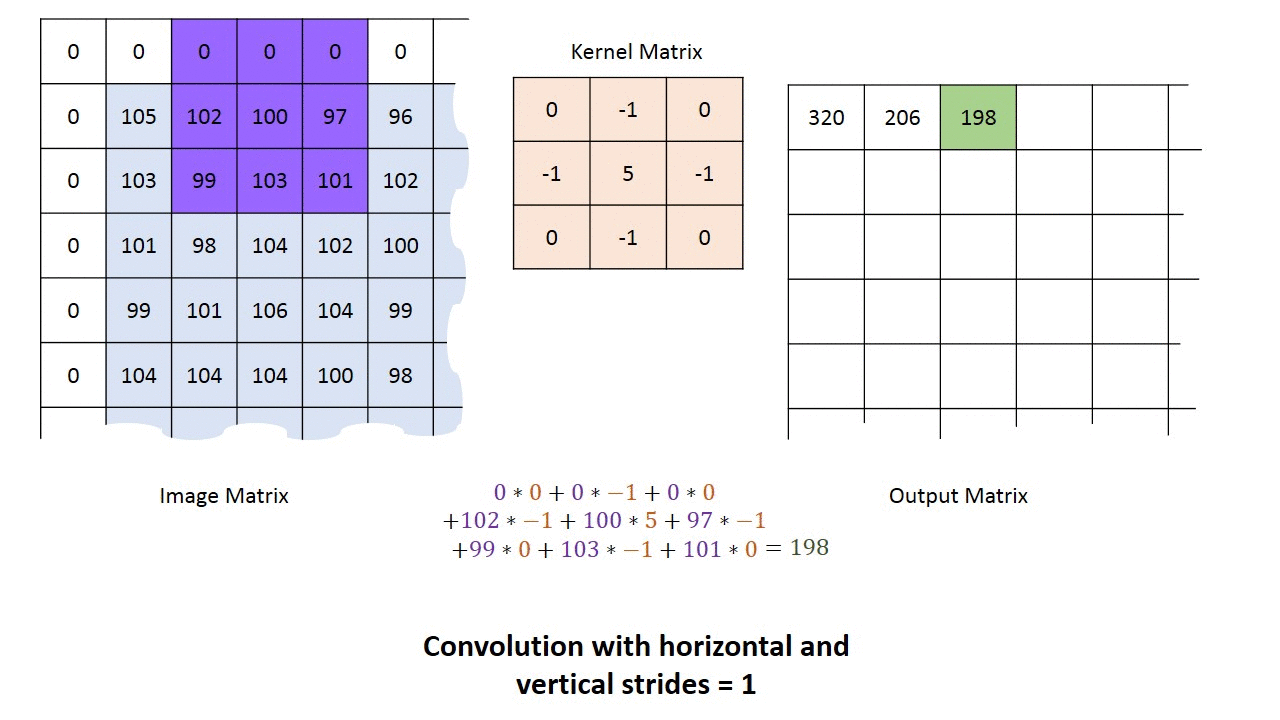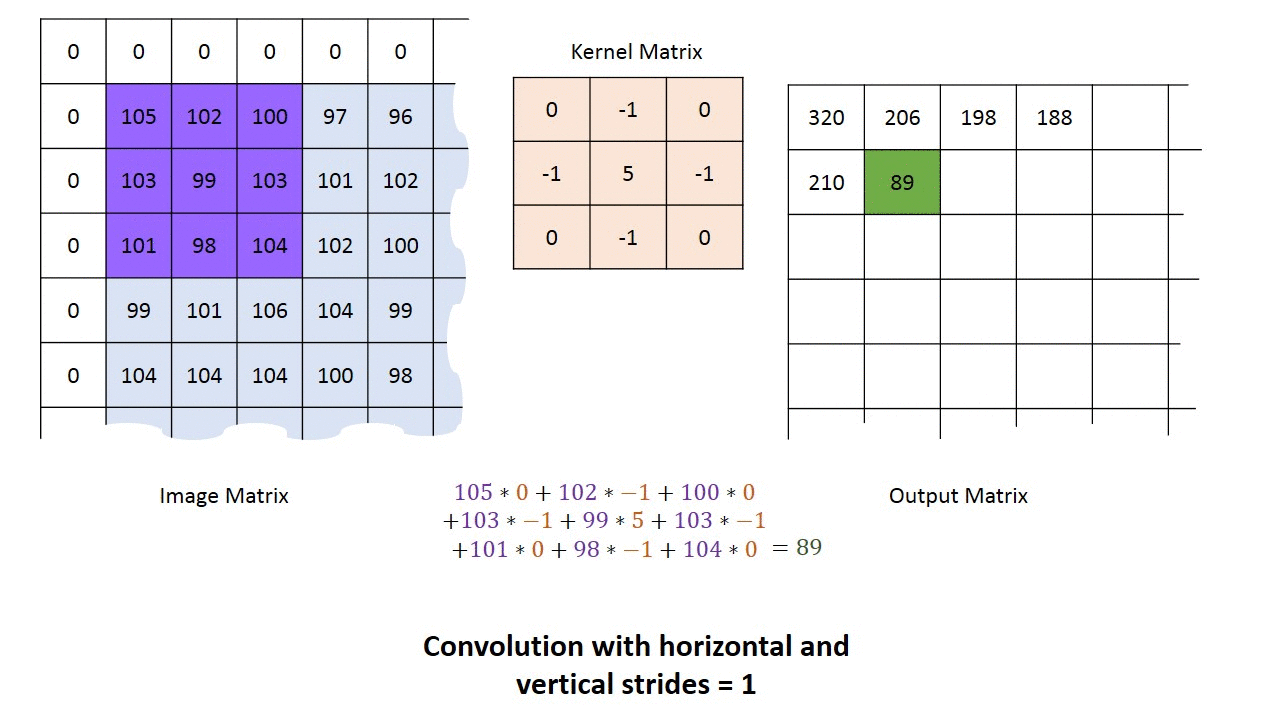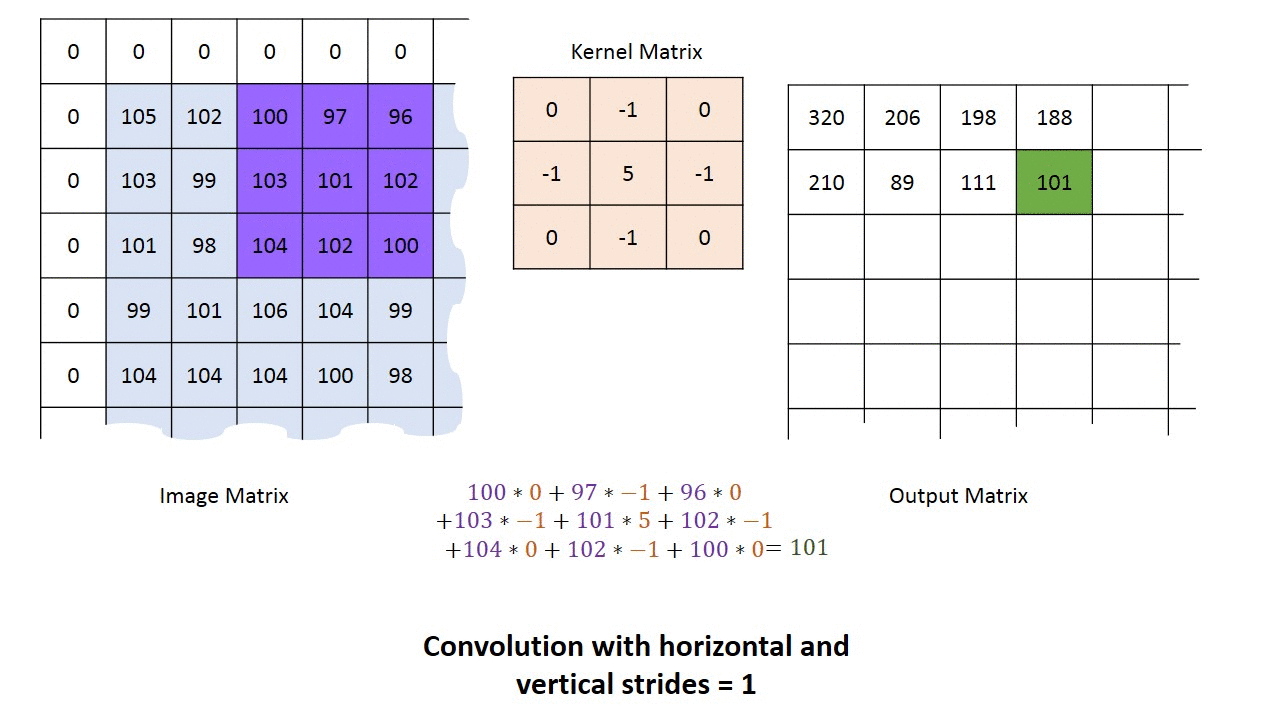
Вы заметите, что ширина и высота вывода могут отличаться от ширины и высоты ввода. Это происходит из-за эффекта границы.
Пограничный эффект
Изображение имеет карту возможностей 5х5 и фильтр 3х3. В центре есть только одно окно, где фильтр может экранировать сетку 3х3. Выходная карта объектов будет уменьшена на две плитки вместе с размером 3х3.
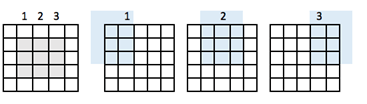
Чтобы получить то же выходное измерение, что и входное измерение, необходимо добавить заполнение. Заполнение состоит из добавления правильного количества строк и столбцов на каждой стороне матрицы. Это позволит свертке центрироваться в каждой клетке ввода. На изображении ниже матрица ввода / вывода имеет одинаковый размер 5×5
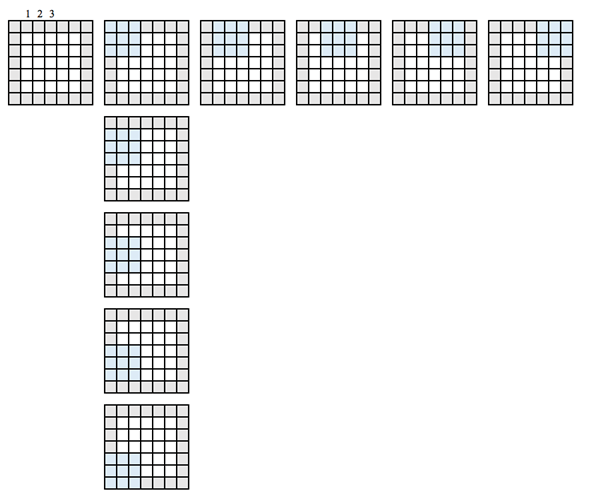
Когда вы определяете сеть, свернутые функции управляются тремя параметрами:
- Глубина: определяет количество фильтров, применяемых во время свертки. В предыдущем примере вы видели глубину 1, что означает, что используется только один фильтр. В большинстве случаев существует более одного фильтра. На рисунке ниже показаны операции, выполненные в ситуации с тремя фильтрами
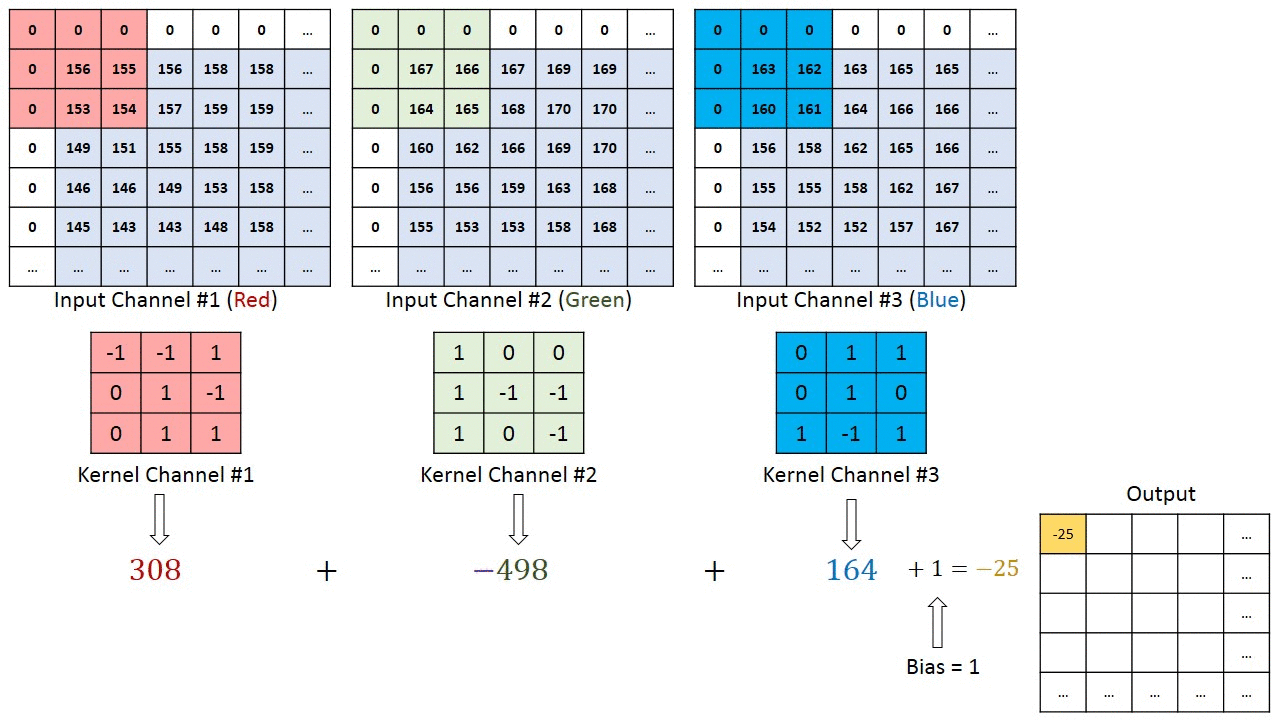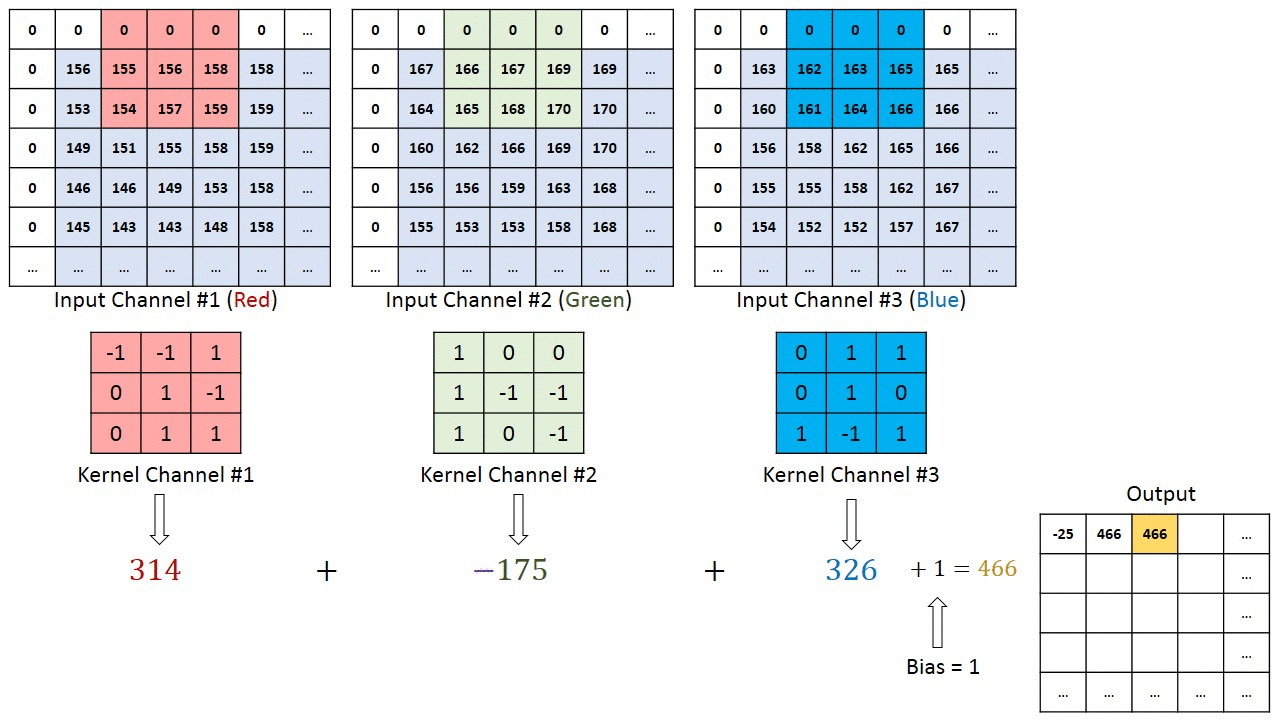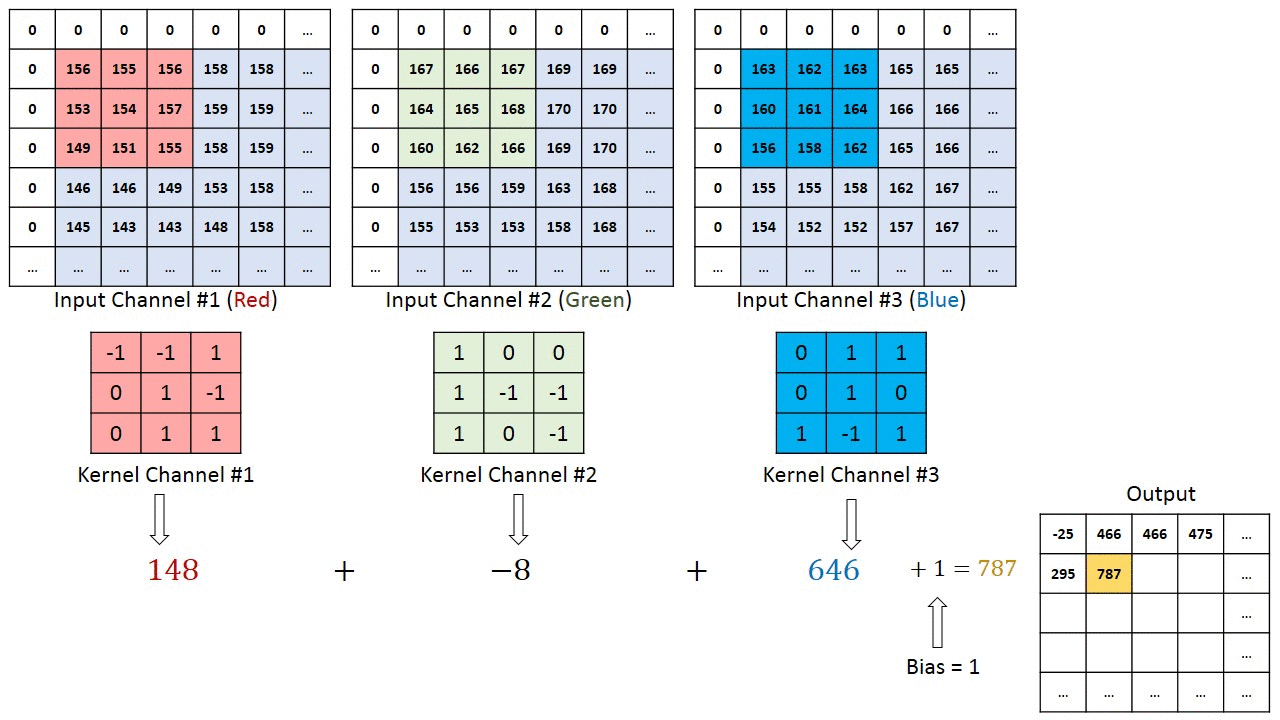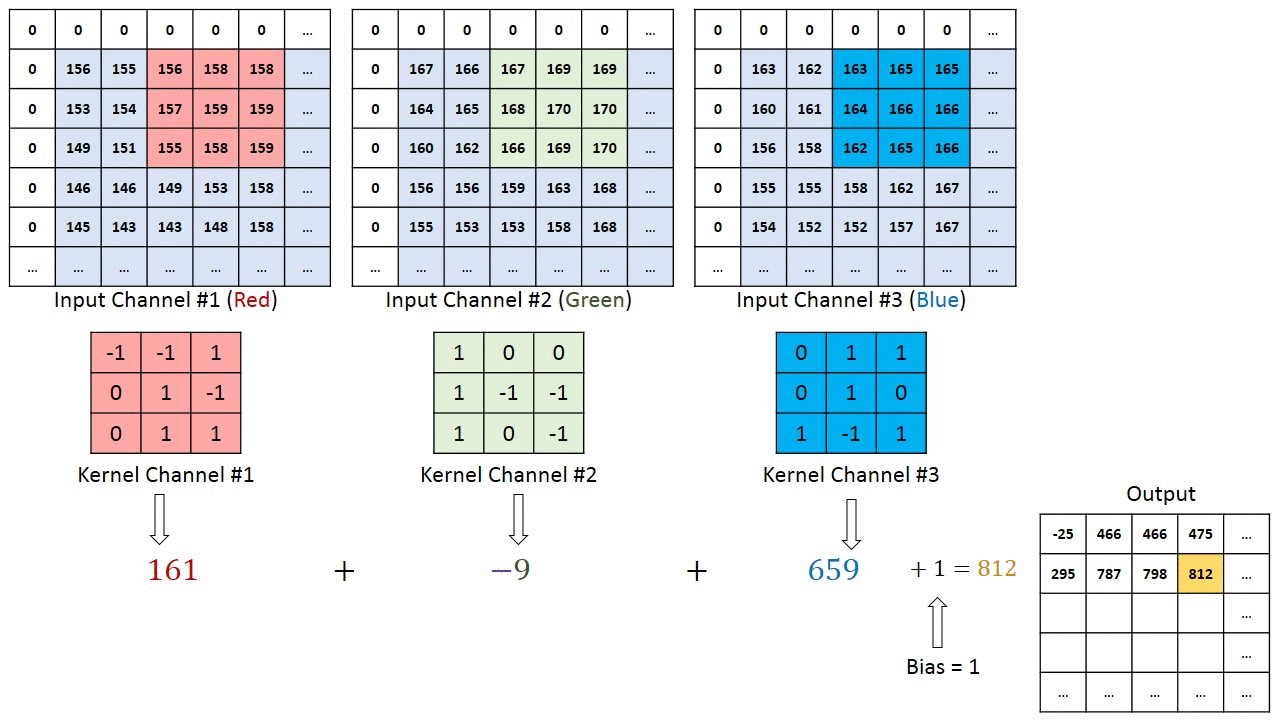
- Stride: определяет количество «прыжков пикселя» между двумя срезами. Если шаг равен 1, окна будут двигаться с разбросом по пикселям, равным единице. Если шаг равен двум, окна будут прыгать на 2 пикселя. Если вы увеличите шаг, у вас будут карты меньшего размера.
Пример шага 1

Изображение шаг 2

- Заполнение нулями. Заполнение — это операция добавления соответствующего числа строк и столбцов на каждой стороне карт входных объектов. В этом случае выход имеет тот же размер, что и вход.
- Нелинейность (ReLU)
В конце операции свертки выходной сигнал подвергается функции активации для обеспечения нелинейности. Обычная функция активации для Connet — это Relu. Все пиксели с отрицательным значением будут заменены на ноль.
- Макс пул операция
Этот шаг легко понять. Целью объединения является уменьшение размерности входного изображения. Шаги сделаны, чтобы уменьшить вычислительную сложность операции. Уменьшая размерность, сеть вычисляет меньшие веса, что предотвращает переоснащение.
На этом этапе вам нужно определить размер и шаг. Стандартный способ объединения входного изображения — использовать максимальное значение карты объектов. Посмотрите на картинку ниже. «Объединение» отобразит четыре подматрицы карты объектов 4×4 и вернет максимальное значение. Пул принимает максимальное значение массива 2×2 и затем перемещает это окно на два пикселя Например, первая подматрица — [3,1,3,2], объединение вернет максимум, который равен 3.
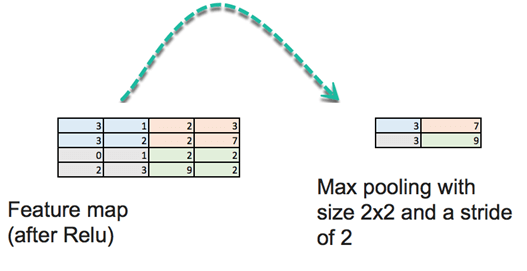
Существует еще одна операция объединения, такая как среднее.
Эта операция агрессивно уменьшает размер карты объектов
- Полностью связанные слои
Последний шаг состоит в создании традиционной искусственной нейронной сети, как вы делали в предыдущем уроке. Вы подключаете все нейроны из предыдущего слоя к следующему слою. Вы используете функцию активации softmax для классификации числа на входном изображении.
Резюме:
Сверточная нейронная сеть компилирует разные слои, прежде чем делать прогноз. Нейронная сеть имеет:
- Сверточный слой
- Функция активации Relu
- Пул слой
- Плотно связанный слой
Сверточные слои применяют различные фильтры к подобласти изображения. Функция активации Relu добавляет нелинейность, а объединяющие слои уменьшают размерность карт объектов.
Все эти слои извлекают важную информацию из изображений. Наконец, карта объектов подается на первичный полностью связанный слой с функцией softmax для прогнозирования.
Поезд CNN с TensorFlow
Теперь, когда вы знакомы со строительным блоком Convnet, вы готовы построить его с TensorFlow. Мы будем использовать набор данных MNIST для классификации изображений.
Подготовка данных такая же, как и в предыдущем уроке. Вы можете запустить коды и перейти непосредственно к архитектуре CNN.
Вы будете следовать инструкциям ниже:
Шаг 1: Загрузить набор данных
Шаг 2: входной слой
Шаг 3: сверточный слой
Шаг 4: объединение слоя
Шаг 5: Второй сверточный слой и объединяющий слой
Шаг 6: Плотный слой
Шаг 7: Logit Layer
Шаг 1: Загрузить набор данных
Набор данных MNIST доступен в Scikit для изучения по этому URL . Пожалуйста, загрузите его и сохраните в разделе «Загрузки». Вы можете загрузить его с fetch_mldata («MNIST оригинал»).
Создать поезд / тестовый набор
Вам нужно разделить набор данных с помощью train_test_split
Масштабировать функции
Наконец, вы можете масштабировать функцию с MinMaxScaler
import numpy as np
import tensorflow as tf
from sklearn.datasets import fetch_mldata
#Change USERNAME by the username of your machine
## Windows USER
mnist = fetch_mldata('C:\\Users\\USERNAME\\Downloads\\MNIST original')
## Mac User
mnist = fetch_mldata('/Users/USERNAME/Downloads/MNIST original')
print(mnist.data.shape)
print(mnist.target.shape)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(mnist.data, mnist.target, test_size=0.2, random_state=42)
y_train = y_train.astype(int)
y_test = y_test.astype(int)
batch_size =len(X_train)
print(X_train.shape, y_train.shape,y_test.shape )
## resclae
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
# Train
X_train_scaled = scaler.fit_transform(X_train.astype(np.float64))
# test
X_test_scaled = scaler.fit_transform(X_test.astype(np.float64))
feature_columns = [tf.feature_column.numeric_column('x', shape=X_train_scaled.shape[1:])]
X_train_scaled.shape[1:]
Определить CNN
CNN использует фильтры на необработанном пикселе изображения, чтобы изучить шаблон деталей по сравнению с глобальным шаблоном с традиционной нейронной сетью. Чтобы построить CNN, вам нужно определить:
- Сверточный слой: примените n фильтров к карте объектов. После свертки вам нужно использовать функцию активации Relu, чтобы добавить нелинейность в сеть.
- Слой пула: следующий шаг после свертки — уменьшить частоту макс. Цель состоит в том, чтобы уменьшить размерность карты объектов, чтобы предотвратить переоснащение и повысить скорость вычислений. Максимальное объединение — это обычный метод, который разделяет карты объектов на субрегионы (обычно с размером 2×2) и сохраняет только максимальные значения.
- Полностью связанные слои: все нейроны из предыдущих слоев связаны со следующими слоями. CNN классифицирует метку в соответствии с особенностями сверточных слоев и сокращается с помощью пула.
Архитектура CNN
- Сверточный слой: применяет 14 фильтров 5×5 (извлекает 5×5-пиксельные субрегионы) с функцией активации ReLU
- Уровень пула: выполняет максимальное объединение с фильтром 2×2 и шагом 2 (который указывает, что объединенные области не перекрываются)
- Сверточный слой: применяет 36 фильтров 5×5 с функцией активации ReLU
- Уровень пула № 2: Опять же, максимальный пул выполняется с фильтром 2х2 и шагом 2
- 1764 нейрона, с коэффициентом регуляризации отсева 0,4 (вероятность 0,4, что любой данный элемент будет отброшен во время обучения)
- Плотный слой (Logits Layer): 10 нейронов, по одному на каждый разряд целевого класса (0–9).
Есть три важных модуля, чтобы использовать для создания CNN:
- conv2d (). Создает двумерный сверточный слой с количеством фильтров, размером ядра фильтра, заполнением и функцией активации в качестве аргументов.
- max_pooling2d (). Создает слой двумерного пула с использованием алгоритма максимального пула.
- плотный(). Создает плотный слой со скрытыми слоями и единицами
Вы определите функцию для построения CNN. Давайте посмотрим подробно, как создать каждый строительный блок, прежде чем обернуть все вместе в функцию.
Шаг 2: входной слой
def cnn_model_fn(features, labels, mode):
input_layer = tf.reshape(tensor = features["x"],shape =[-1, 28, 28, 1])
Вам нужно определить тензор с формой данных. Для этого вы можете использовать модуль tf.reshape. В этом модуле необходимо объявить тензор для изменения формы и форму тензора. Первый аргумент — это особенности данных, которые определены в аргументе функции.
Картинка имеет высоту, ширину и канал. Набор данных MNIST — это монохронное изображение размером 28×28. Мы устанавливаем размер пакета в -1 в аргументе shape, чтобы он принял форму объектов [«x»]. Преимущество заключается в настройке гиперпараметров размера партии. Если размер партии установлен в 7, то тензор подаст 5488 значений (28 * 28 * 7).
Step 3: Convolutional layer
# first Convolutional Layer
conv1 = tf.layers.conv2d(
inputs=input_layer,
filters=14,
kernel_size=[5, 5],
padding="same",
activation=tf.nn.relu)
Первый сверточный слой имеет 14 фильтров с размером ядра 5×5 с одинаковым заполнением. Одинаковое заполнение означает, что и выходной тензор, и входной тензор должны иметь одинаковую высоту и ширину. Tensorflow добавит нули к строкам и столбцам, чтобы обеспечить одинаковый размер.
Вы используете функцию активации Relu. Размер вывода будет [28, 28, 14].
Шаг 4: объединение слоя
Следующим шагом после свертки является вычисление пула. Вычисление пула уменьшит размерность данных. Вы можете использовать модуль max_pooling2d размером 2х2 и шагом 2. Вы используете предыдущий слой в качестве входных данных. Размер вывода будет [batch_size, 14, 14, 14]
# first Pooling Layer pool1 = tf.layers.max_pooling2d(inputs=conv1, pool_size=[2, 2], strides=2)
Шаг 5: Второй сверточный слой и объединяющий слой
Второй сверточный слой имеет 32 фильтра с выходным размером [batch_size, 14, 14, 32]. Слой пула имеет тот же размер, что и раньше, а выходная форма — [batch_size, 14, 14, 18].
conv2 = tf.layers.conv2d(
inputs=pool1,
filters=36,
kernel_size=[5, 5],
padding="same",
activation=tf.nn.relu)
pool2 = tf.layers.max_pooling2d(inputs=conv2, pool_size=[2, 2], strides=2)
Шаг 6: Плотный слой
Затем вам нужно определить полностью связанный слой. Карта объектов должна быть сплющена, прежде чем она будет связана с плотным слоем. Вы можете использовать модуль reshape размером 7 * 7 * 36.
Плотный слой соединит 1764 нейрона. Вы добавляете функцию активации Relu. Кроме того, вы добавляете термин регуляризации отсева с коэффициентом 0,3, что означает, что 30 процентов весов будут установлены на 0. Обратите внимание, что отсев происходит только на этапе обучения. Функция cnn_model_fn имеет режим аргумента, чтобы объявить, нужно ли обучать модель или оценивать.
pool2_flat = tf.reshape(pool2, [-1, 7 * 7 * 36])
dense = tf.layers.dense(inputs=pool2_flat, units=7 * 7 * 36, activation=tf.nn.relu)
dropout = tf.layers.dropout(
inputs=dense, rate=0.3, training=mode == tf.estimator.ModeKeys.TRAIN)
Шаг 7: Logit Layer
Наконец, вы можете определить последний слой с предсказанием модели. Форма вывода равна размеру пакета и 10, общее количество изображений.
# Logits Layer logits = tf.layers.dense(inputs=dropout, units=10)
Вы можете создать словарь, содержащий классы и вероятность каждого класса. Модуль tf.argmax () с возвращает наибольшее значение, если слои логита. Функция softmax возвращает вероятность каждого класса.
predictions = {
# Generate predictions
"classes": tf.argmax(input=logits, axis=1),
"probabilities": tf.nn.softmax(logits, name="softmax_tensor") }
Вы хотите возвращать словарный прогноз только тогда, когда режим установлен на прогнозирование. Вы добавляете эти коды, чтобы опровергнуть прогнозы
if mode == tf.estimator.ModeKeys.PREDICT:
return tf.estimator.EstimatorSpec(mode=mode, predictions=predictions)
Следующий шаг состоит в том, чтобы вычислить потерю модели. В последнем уроке вы узнали, что функция потерь для мультиклассовой модели является кросс-энтропией. Потери легко вычисляются с помощью следующего кода:
# Calculate Loss (for both TRAIN and EVAL modes) loss = tf.losses.sparse_softmax_cross_entropy(labels=labels, logits=logits)
Последний шаг — оптимизация модели, то есть поиск наилучших значений весов. Для этого вы используете оптимизатор градиентного спуска со скоростью обучения 0,001. Цель состоит в том, чтобы минимизировать потери
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.001)
train_op = optimizer.minimize(
loss=loss,
global_step=tf.train.get_global_step())
Вы сделали с CNN. Однако вы хотите отобразить показатели производительности в режиме оценки. Метрики производительности для мультиклассовой модели — это метрики точности. Tensorflow оснащен модулем точности с двумя аргументами, метками и прогнозируемыми значениями.
eval_metric_ops = {
"accuracy": tf.metrics.accuracy(labels=labels, predictions=predictions["classes"])}
return tf.estimator.EstimatorSpec(mode=mode, loss=loss, eval_metric_ops=eval_metric_ops)
Вот и все. Вы создали свой первый CNN, и вы готовы обернуть все в функцию, чтобы использовать ее для обучения и оценки модели.
def cnn_model_fn(features, labels, mode):
"""Model function for CNN."""
# Input Layer
input_layer = tf.reshape(features["x"], [-1, 28, 28, 1])
# Convolutional Layer
conv1 = tf.layers.conv2d(
inputs=input_layer,
filters=32,
kernel_size=[5, 5],
padding="same",
activation=tf.nn.relu)
# Pooling Layer
pool1 = tf.layers.max_pooling2d(inputs=conv1, pool_size=[2, 2], strides=2)
# Convolutional Layer #2 and Pooling Layer
conv2 = tf.layers.conv2d(
inputs=pool1,
filters=36,
kernel_size=[5, 5],
padding="same",
activation=tf.nn.relu)
pool2 = tf.layers.max_pooling2d(inputs=conv2, pool_size=[2, 2], strides=2)
# Dense Layer
pool2_flat = tf.reshape(pool2, [-1, 7 * 7 * 36])
dense = tf.layers.dense(inputs=pool2_flat, units=7 * 7 * 36, activation=tf.nn.relu)
dropout = tf.layers.dropout(
inputs=dense, rate=0.4, training=mode == tf.estimator.ModeKeys.TRAIN)
# Logits Layer
logits = tf.layers.dense(inputs=dropout, units=10)
predictions = {
# Generate predictions (for PREDICT and EVAL mode)
"classes": tf.argmax(input=logits, axis=1),
"probabilities": tf.nn.softmax(logits, name="softmax_tensor")
}
if mode == tf.estimator.ModeKeys.PREDICT:
return tf.estimator.EstimatorSpec(mode=mode, predictions=predictions)
# Calculate Loss
loss = tf.losses.sparse_softmax_cross_entropy(labels=labels, logits=logits)
# Configure the Training Op (for TRAIN mode)
if mode == tf.estimator.ModeKeys.TRAIN:
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.001)
train_op = optimizer.minimize(
loss=loss,
global_step=tf.train.get_global_step())
return tf.estimator.EstimatorSpec(mode=mode, loss=loss, train_op=train_op)
# Add evaluation metrics Evaluation mode
eval_metric_ops = {
"accuracy": tf.metrics.accuracy(
labels=labels, predictions=predictions["classes"])}
return tf.estimator.EstimatorSpec(
mode=mode, loss=loss, eval_metric_ops=eval_metric_ops)
Шаги ниже такие же, как в предыдущих уроках.
Прежде всего, вы определяете оценщик с моделью CNN.
# Create the Estimator
mnist_classifier = tf.estimator.Estimator(
model_fn=cnn_model_fn, model_dir="train/mnist_convnet_model")
CNN обучается много раз, поэтому вы создаете ловушку Logging для сохранения значений слоев softmax каждые 50 итераций.
# Set up logging for predictions
tensors_to_log = {"probabilities": "softmax_tensor"}
logging_hook = tf.train.LoggingTensorHook(tensors=tensors_to_log, every_n_iter=50)
Вы готовы оценить модель. Вы устанавливаете размер партии 100 и перемешиваете данные. Обратите внимание, что мы установили шаги обучения в 16.000, обучение может занять много времени. Потерпи.
# Train the model
train_input_fn = tf.estimator.inputs.numpy_input_fn(
x={"x": X_train_scaled},
y=y_train,
batch_size=100,
num_epochs=None,
shuffle=True)
mnist_classifier.train(
input_fn=train_input_fn,
steps=16000,
hooks=[logging_hook])
Теперь, когда модель обучена, вы можете оценить ее и распечатать результаты.
# Evaluate the model and print results
eval_input_fn = tf.estimator.inputs.numpy_input_fn(
x={"x": X_test_scaled},
y=y_test,
num_epochs=1,
shuffle=False)
eval_results = mnist_classifier.evaluate(input_fn=eval_input_fn)
print(eval_results)
INFO:tensorflow:Calling model_fn.
INFO:tensorflow:Done calling model_fn.
INFO:tensorflow:Starting evaluation at 2018-08-05-12:52:41
INFO:tensorflow:Graph was finalized.
INFO:tensorflow:Restoring parameters from train/mnist_convnet_model/model.ckpt-15652
INFO:tensorflow:Running local_init_op.
INFO:tensorflow:Done running local_init_op.
INFO:tensorflow:Finished evaluation at 2018-08-05-12:52:56
INFO:tensorflow:Saving dict for global step 15652: accuracy = 0.9589286, global_step = 15652, loss = 0.13894269
{'accuracy': 0.9689286, 'loss': 0.13894269, 'global_step': 15652}
С текущей архитектурой вы получаете точность 97%. Вы можете изменить архитектуру, размер пакета и количество итераций, чтобы повысить точность. Нейронная сеть CNN работает намного лучше, чем ANN или логистическая регрессия. В уроке по искусственной нейронной сети у вас была точность 96%, что ниже CNN. Производительность CNN впечатляет с большим набором изображений , как с точки зрения скорости расчета и точности.
Резюме
Сверточная нейронная сеть работает очень хорошо, чтобы оценить картину. Этот тип архитектуры является доминирующим для распознавания объектов из изображения или видео.
Чтобы построить CNN, вам нужно выполнить шесть шагов:
Шаг 1: Входной слой:
Этот шаг изменяет данные. Форма равна корню квадратному из числа пикселей. Например, если изображение имеет 156 пикселей, то форма будет 26×26. Вам необходимо указать, имеет ли картинка цвет или нет. Если да, то у вас было 3 к форме — 3 для RGB-, иначе 1.
input_layer = tf.reshape(tensor = features["x"],shape =[-1, 28, 28, 1])
Шаг 2: сверточный слой
Далее необходимо создать сверточные слои. Вы применяете различные фильтры, чтобы позволить сети изучить важную функцию. Вы указываете размер ядра и количество фильтров.
conv1 = tf.layers.conv2d(
inputs=input_layer,
filters=14,
kernel_size=[5, 5],
padding="same",
activation=tf.nn.relu)
Шаг 3: объединение слоя
На третьем шаге вы добавляете слой пула. Этот слой уменьшает размер ввода. Это достигается путем взятия максимального значения субматрицы. Например, если субматрица равна [3,1,3,2], объединение вернет максимум, который равен 3.
pool1 = tf.layers.max_pooling2d(inputs=conv1, pool_size=[2, 2], strides=2)
Шаг 4: Добавить сверточный слой и объединяющий слой
На этом шаге вы можете добавить столько слоев, сколько вам нужно, и слои объединения. Google использует архитектуру с более чем 20 конвекс-слоями.
Шаг 5: Плотный слой
Шаг 5 выравнивает предыдущий, чтобы создать полностью связанные слои. На этом этапе вы можете использовать другую функцию активации и добавить эффект отсева.
pool2_flat = tf.reshape(pool2, [-1, 7 * 7 * 36])
dense = tf.layers.dense(inputs=pool2_flat, units=7 * 7 * 36, activation=tf.nn.relu)
dropout = tf.layers.dropout(
inputs=dense, rate=0.3, training=mode == tf.estimator.ModeKeys.TRAIN)
Шаг 6: Logit Layer
Последний шаг — это прогноз.
logits = tf.layers.dense(inputs=dropout, units=10)