Что такое Scikit-Learn?
Scikit-learn — это библиотека Python с открытым исходным кодом для машинного обучения. Библиотека поддерживает современные алгоритмы, такие как KNN, XGBoost, случайный лес, SVM и другие. Он построен на вершине Numpy. Scikit-learn широко используется в соревнованиях по борьбе, а также в известных технологических компаниях. Scikit-learn помогает в предварительной обработке, уменьшении размерности (выбор параметров), классификации, регрессии, кластеризации и выборе моделей.
Scikit-learn имеет лучшую документацию из всех библиотек с открытым исходным кодом. Он предоставляет вам интерактивную диаграмму по адресу https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html .
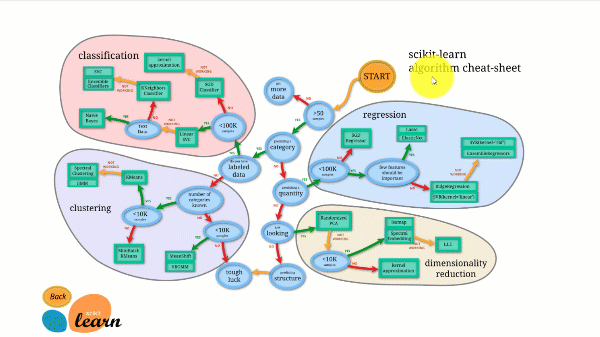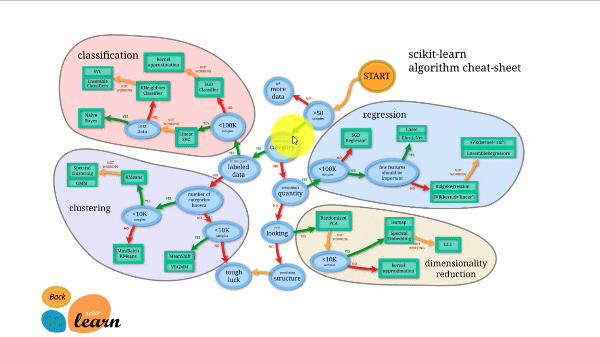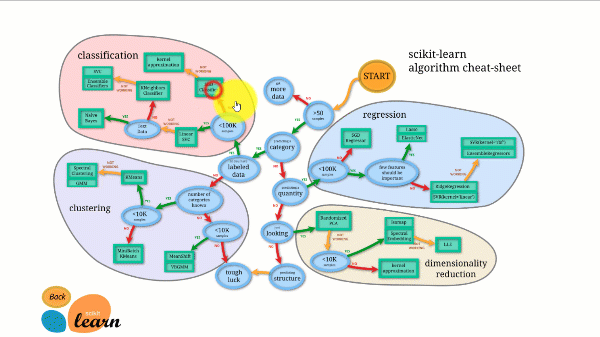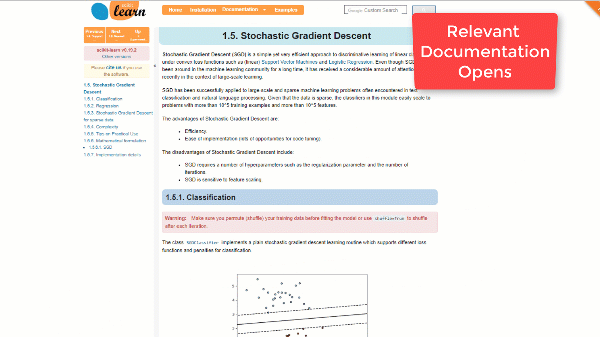
Scikit-learn не очень сложен в использовании и дает отличные результаты. Тем не менее, Scikit Learn не поддерживает параллельные вычисления. С ним можно запустить алгоритм глубокого обучения, но это не оптимальное решение, особенно если вы знаете, как использовать TensorFlow.
В этом уроке вы узнаете.
- Что такое Scikit-Learn?
- Скачать и установить scikit-learn
- Машинное обучение с scikit-learn
- Импортировать данные
- Создать поезд / тестовый набор
- Построить трубопровод
- Используя наш конвейер в сетке поиска
- Модель XGBoost с scikit-learn
- Создать DNN с MLPClassifier в scikit-learn
- ЛАЙМ: доверяй своей модели
Скачать и установить scikit-learn
Вариант 1: AWS
scikit-learn можно использовать поверх AWS. Пожалуйста, обратитесь к образу Docker с предустановленным scikit-learn.
Чтобы использовать версию разработчика, используйте команду в Jupyter
import sys
!{sys.executable} -m pip install git+git://github.com/scikit-learn/scikit-learn.git
Вариант 2: Mac или Windows с использованием Anaconda
Чтобы узнать об установке Anaconda, см. Https://www.guru99.com/download-install-tensorflow.html.
Недавно разработчики Scikit выпустили версию для разработчиков, которая решает общую проблему, с которой сталкивается текущая версия. Мы посчитали более удобным использовать версию разработчика вместо текущей версии.
Если вы установили scikit-learn в среде conda, пожалуйста, следуйте инструкциям по обновлению до версии 0.20.
Шаг 1) Активировать среду tenorflow
source activate hello-tf
Шаг 2) Удалите scikit lean с помощью команды conda
conda remove scikit-learn
Шаг 3) Установите версию Scikit Learn для разработчиков вместе с необходимыми библиотеками.
conda install -c anaconda git pip install Cython pip install h5py pip install git+git://github.com/scikit-learn/scikit-learn.git
ПРИМЕЧАНИЕ. Для использования Windows потребуется установить Microsoft Visual C ++ 14. Вы можете получить его здесь
Машинное обучение с scikit-learn
Этот урок разделен на две части:
- Машинное обучение с scikit-learn
- Как доверять вашей модели с LIME
В первой части подробно рассказывается, как построить конвейер, создать модель и настроить гиперпараметры, а во второй части представлено современное состояние с точки зрения выбора модели.
Шаг 1) Импортируйте данные
В этом уроке вы будете использовать набор данных для взрослых. Если вы хотите узнать больше об описательной статистике, пожалуйста, используйте инструменты Dive и Overview. Обратитесь к этому руководству, чтобы узнать больше о погружении и обзоре.
Вы импортируете набор данных с помощью Pandas. Обратите внимание, что вам необходимо преобразовать тип непрерывных переменных в формат с плавающей точкой.
Этот набор данных включает в себя восемь категориальных переменных:
Категориальные переменные перечислены в CATE_FEATURES
- workclass
- образование
- супружеский
- род занятий
- отношения
- гонка
- секс
- родная страна
кроме того, шесть непрерывных переменных:
Непрерывные переменные перечислены в CONTI_FEATURES
- возраст
- fnlwgt
- education_num
- прирост капитала
- capital_loss
- hours_week
Обратите внимание, что мы заполняем список вручную, чтобы вы лучше понимали, какие столбцы мы используем. Более быстрый способ составить список категориальных или непрерывных списков — использовать:
## List Categorical
CATE_FEATURES = df_train.iloc[:,:-1].select_dtypes('object').columns
print(CATE_FEATURES)
## List continuous
CONTI_FEATURES = df_train._get_numeric_data()
print(CONTI_FEATURES)
Вот код для импорта данных:
# Import dataset
import pandas as pd
## Define path data
COLUMNS = ['age','workclass', 'fnlwgt', 'education', 'education_num', 'marital',
'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss',
'hours_week', 'native_country', 'label']
### Define continuous list
CONTI_FEATURES = ['age', 'fnlwgt','capital_gain', 'education_num', 'capital_loss', 'hours_week']
### Define categorical list
CATE_FEATURES = ['workclass', 'education', 'marital', 'occupation', 'relationship', 'race', 'sex', 'native_country']
## Prepare the data
features = ['age','workclass', 'fnlwgt', 'education', 'education_num', 'marital',
'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss',
'hours_week', 'native_country']
PATH = "https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data"
df_train = pd.read_csv(PATH, skipinitialspace=True, names = COLUMNS, index_col=False)
df_train[CONTI_FEATURES] =df_train[CONTI_FEATURES].astype('float64')
df_train.describe()
| возраст | fnlwgt | education_num | прирост капитала | capital_loss | hours_week | |
| подсчитывать | 32561.000000 | 3.256100e + 04 | 32561.000000 | 32561.000000 | 32561.000000 | 32561.000000 |
| жадный | 38.581647 | 1.897784e + 05 | 10.080679 | 1077.648844 | 87.303830 | 40.437456 |
| станд | 13.640433 | 1.055500e + 05 | 2.572720 | 7385.292085 | 402.960219 | 12.347429 |
| мин | 17.000000 | 1.228500e + 04 | 1.000000 | 0.000000 | 0.000000 | 1.000000 |
| 25% | 28.000000 | 1.178270e + 05 | 9.000000 | 0.000000 | 0.000000 | 40.000000 |
| 50% | 37.000000 | 1.783560e + 05 | 10.000000 | 0.000000 | 0.000000 | 40.000000 |
| 75% | 48.000000 | 2.370510e + 05 | 12.000000 | 0.000000 | 0.000000 | 45.000000 |
| Максимум | 90.000000 | 1.484705e + 06 | 16.000000 | 99999.000000 | 4356.000000 | 99.000000 |
Вы можете проверить количество уникальных значений функций native_country. Вы можете видеть, что только одно домохозяйство происходит из Голландии-Нидерландов. Это домашнее хозяйство не принесет нам никакой информации, но из-за ошибки во время обучения.
df_train.native_country.value_counts()
United-States 29170 Mexico 643 ? 583 Philippines 198 Germany 137 Canada 121 Puerto-Rico 114 El-Salvador 106 India 100 Cuba 95 England 90 Jamaica 81 South 80 China 75 Italy 73 Dominican-Republic 70 Vietnam 67 Guatemala 64 Japan 62 Poland 60 Columbia 59 Taiwan 51 Haiti 44 Iran 43 Portugal 37 Nicaragua 34 Peru 31 France 29 Greece 29 Ecuador 28 Ireland 24 Hong 20 Cambodia 19 Trinadad&Tobago 19 Thailand 18 Laos 18 Yugoslavia 16 Outlying-US(Guam-USVI-etc) 14 Honduras 13 Hungary 13 Scotland 12 Holand-Netherlands 1 Name: native_country, dtype: int64
Вы можете исключить эту неинформативную строку из набора данных
## Drop Netherland, because only one row df_train = df_train[df_train.native_country != "Holand-Netherlands"]
Далее вы сохраняете положение непрерывных объектов в списке. Он понадобится вам на следующем этапе, чтобы построить конвейер.
Приведенный ниже код будет перебирать все имена столбцов в CONTI_FEATURES и получать его местоположение (т.е. его номер), а затем добавлять его в список с именем conti_features.
## Get the column index of the categorical features
conti_features = []
for i in CONTI_FEATURES:
position = df_train.columns.get_loc(i)
conti_features.append(position)
print(conti_features)
[0, 2, 10, 4, 11, 12]
Код ниже выполняет ту же работу, что и выше, но для категориальной переменной. Код ниже повторяет то, что вы делали ранее, за исключением категориальных функций.
## Get the column index of the categorical features
categorical_features = []
for i in CATE_FEATURES:
position = df_train.columns.get_loc(i)
categorical_features.append(position)
print(categorical_features)
[1, 3, 5, 6, 7, 8, 9, 13]
Вы можете взглянуть на набор данных. Обратите внимание, что каждая категориальная особенность является строкой. Вы не можете кормить модель строковым значением. Вам необходимо преобразовать набор данных, используя фиктивную переменную.
df_train.head(5)
Фактически вам нужно создать один столбец для каждой группы в объекте. Во-первых, вы можете запустить приведенный ниже код, чтобы вычислить общее количество необходимых столбцов.
print(df_train[CATE_FEATURES].nunique(),
'There are',sum(df_train[CATE_FEATURES].nunique()), 'groups in the whole dataset')
workclass 9 education 16 marital 7 occupation 15 relationship 6 race 5 sex 2 native_country 41 dtype: int64 There are 101 groups in the whole dataset
Весь набор данных содержит 101 группу, как показано выше. Например, функции рабочего класса имеют девять групп. Вы можете визуализировать названия групп с помощью следующих кодов
unique () возвращает уникальные значения категориальных функций.
for i in CATE_FEATURES:
print(df_train[i].unique())
['State-gov' 'Self-emp-not-inc' 'Private' 'Federal-gov' 'Local-gov' '?' 'Self-emp-inc' 'Without-pay' 'Never-worked'] ['Bachelors' 'HS-grad' '11th' 'Masters' '9th' 'Some-college' 'Assoc-acdm' 'Assoc-voc' '7th-8th' 'Doctorate' 'Prof-school' '5th-6th' '10th' '1st-4th' 'Preschool' '12th'] ['Never-married' 'Married-civ-spouse' 'Divorced' 'Married-spouse-absent' 'Separated' 'Married-AF-spouse' 'Widowed'] ['Adm-clerical' 'Exec-managerial' 'Handlers-cleaners' 'Prof-specialty' 'Other-service' 'Sales' 'Craft-repair' 'Transport-moving' 'Farming-fishing' 'Machine-op-inspct' 'Tech-support' '?' 'Protective-serv' 'Armed-Forces' 'Priv-house-serv'] ['Not-in-family' 'Husband' 'Wife' 'Own-child' 'Unmarried' 'Other-relative'] ['White' 'Black' 'Asian-Pac-Islander' 'Amer-Indian-Eskimo' 'Other'] ['Male' 'Female'] ['United-States' 'Cuba' 'Jamaica' 'India' '?' 'Mexico' 'South' 'Puerto-Rico' 'Honduras' 'England' 'Canada' 'Germany' 'Iran' 'Philippines' 'Italy' 'Poland' 'Columbia' 'Cambodia' 'Thailand' 'Ecuador' 'Laos' 'Taiwan' 'Haiti' 'Portugal' 'Dominican-Republic' 'El-Salvador' 'France' 'Guatemala' 'China' 'Japan' 'Yugoslavia' 'Peru' 'Outlying-US(Guam-USVI-etc)' 'Scotland' 'Trinadad&Tobago' 'Greece' 'Nicaragua' 'Vietnam' 'Hong' 'Ireland' 'Hungary']
Поэтому обучающий набор данных будет содержать 101 + 7 столбцов. Последние семь столбцов являются непрерывными элементами.
Scikit-Learn может позаботиться о преобразовании. Это делается в два этапа:
- Во-первых, вам нужно преобразовать строку в ID. Например, State-gov будет иметь ID 1, Self-emp-not-inc ID 2 и так далее. Функция LabelEncoder делает это для вас
- Переместите каждый идентификатор в новый столбец. Как упоминалось ранее, набор данных имеет 101 идентификатор группы. Поэтому будет 101 столбец, содержащий все группы объектов категорий. Scikit-learn имеет функцию OneHotEncoder, которая выполняет эту операцию
Шаг 2) Создайте поезд / тестовый набор
Теперь, когда набор данных готов, мы можем разделить его на 80/20. 80 процентов для тренировочного набора и 20 процентов для тестового набора.
Вы можете использовать train_test_split. Первый аргумент — это dataframe — это особенности, а второй аргумент — это метка dataframe. Вы можете указать размер набора тестов с помощью test_size.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(df_train[features],
df_train.label,
test_size = 0.2,
random_state=0)
X_train.head(5)
print(X_train.shape, X_test.shape)
(26048, 14) (6512, 14)
Шаг 3) Постройте трубопровод
Конвейер облегчает снабжение модели согласованными данными. Идея заключается в том, чтобы поместить необработанные данные в «конвейер» для выполнения операций. Например, в текущем наборе данных вам необходимо стандартизировать непрерывные переменные и преобразовать категориальные данные. Обратите внимание, что вы можете выполнять любые операции внутри конвейера. Например, если у вас есть «NA» в наборе данных, вы можете заменить их средним или медианным. Вы также можете создавать новые переменные.
У вас есть выбор; Жесткий код двух процессов или создать конвейер. Первый выбор может привести к утечке данных и создать несоответствия во времени. Лучшим вариантом является использование конвейера.
from sklearn.preprocessing import StandardScaler, OneHotEncoder, LabelEncoder from sklearn.compose import ColumnTransformer, make_column_transformer from sklearn.pipeline import make_pipeline from sklearn.linear_model import LogisticRegression
Перед подачей в логистический классификатор конвейер выполнит две операции:
- Стандартизируйте переменную: `StandardScaler ()` `
- Преобразование категориальных функций: OneHotEncoder (sparse = False)
Вы можете выполнить два шага, используя make_column_transformer. Эта функция недоступна в текущей версии scikit-learn (0.19). В текущей версии невозможно выполнить кодировщик меток и один горячий кодировщик в конвейере. Это одна из причин, по которой мы решили использовать версию для разработчиков.
make_column_transformer прост в использовании. Вам необходимо определить, какие столбцы применить преобразование и какое преобразование использовать. Например, чтобы стандартизировать непрерывную функцию, вы можете сделать:
- conti_features, StandardScaler () внутри make_column_transformer.
- conti_features: список с непрерывной переменной
- StandardScaler: стандартизировать переменную
Объект OneHotEncoder внутри make_column_transformer автоматически кодирует метку.
preprocess = make_column_transformer(
(conti_features, StandardScaler()),
### Need to be numeric not string to specify columns name
(categorical_features, OneHotEncoder(sparse=False))
)
Вы можете проверить, работает ли конвейер с помощью fit_transform. Набор данных должен иметь следующую форму: 26048, 107
preprocess.fit_transform(X_train).shape
(26048, 107)
Преобразователь данных готов к использованию. Вы можете создать конвейер с помощью make_pipeline. Как только данные преобразованы, вы можете кормить логистическую регрессию.
model = make_pipeline(
preprocess,
LogisticRegression())
Обучение модели с scikit-learn является тривиальным. Вам нужно использовать соответствие объекта, которому предшествует конвейер, то есть модель. Вы можете напечатать точность с помощью объекта Score из библиотеки scikit-learn.
model.fit(X_train, y_train)
print("logistic regression score: %f" % model.score(X_test, y_test))
logistic regression score: 0.850891
Наконец, вы можете предсказать классы с помощьюgnast_proba. Возвращает вероятность для каждого класса. Обратите внимание, что это сумма к одному.
model.predict_proba(X_test)
array([[0.83576663, 0.16423337],
[0.94582765, 0.05417235],
[0.64760587, 0.35239413],
...,
[0.99639252, 0.00360748],
[0.02072181, 0.97927819],
[0.56781353, 0.43218647]])
Шаг 4) Использование нашего конвейера в сетке поиска
Настроить гиперпараметр (переменные, которые определяют структуру сети, например скрытые блоки) может быть утомительно и утомительно. Одним из способов оценки модели может быть изменение размера тренировочного комплекта и оценка характеристик. Вы можете повторить этот метод десять раз, чтобы увидеть показатели оценки. Тем не менее, это слишком много работы.
Вместо этого scikit-learn предоставляет функцию для настройки параметров и перекрестной проверки.
Перекрестная проверка
Под перекрестной проверкой подразумевается, что во время обучения тренировочный набор проскальзывает n раз, а затем оценивает модель n раз. Например, если cv установлено в 10, обучающий набор обучается и оценивается десять раз. В каждом раунде классификатор выбирает случайным образом девять раз для обучения модели, а десятый — для оценки.
Поиск по сетке Каждый классификатор имеет гиперпараметры для настройки. Вы можете попробовать разные значения или установить сетку параметров. Если вы зайдете на официальный сайт scikit-learn, вы увидите, что классификатор логистики имеет различные параметры для настройки. Чтобы ускорить обучение, вы выбираете настройку параметра C. Он контролирует параметр регуляризации. Это должно быть позитивно. Небольшое значение придает больший вес регуляризатору.
Вы можете использовать объект GridSearchCV. Вам нужно создать словарь, содержащий гиперпараметры для настройки.
Вы перечисляете гиперпараметры, за которыми следуют значения, которые вы хотите попробовать. Например, чтобы настроить параметр C, вы используете:
- ‘logisticregression__C’: [0.1, 1.0, 1.0]: параметру предшествует имя в нижнем регистре классификатора и два подчеркивания.
Модель будет использовать четыре разных значения: 0,001, 0,01, 0,1 и 1.
Вы тренируете модель, используя 10 сгибов: cv = 10
from sklearn.model_selection import GridSearchCV
# Construct the parameter grid
param_grid = {
'logisticregression__C': [0.001, 0.01,0.1, 1.0],
}
Вы можете обучить модель, используя GridSearchCV с параметрами gri и cv.
# Train the model
grid_clf = GridSearchCV(model,
param_grid,
cv=10,
iid=False)
grid_clf.fit(X_train, y_train)
ВЫВОД
GridSearchCV(cv=10, error_score='raise-deprecating',
estimator=Pipeline(memory=None,
steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None,
transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,...ty='l2', random_state=None, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False))]),
fit_params=None, iid=False, n_jobs=1,
param_grid={'logisticregression__C': [0.001, 0.01, 0.1, 1.0]},
pre_dispatch='2*n_jobs', refit=True, return_train_score='warn',
scoring=None, verbose=0)
Чтобы получить доступ к лучшим параметрам, вы используете best_params_
grid_clf.best_params_
ВЫВОД
{'logisticregression__C': 1.0}
После обучения модели с четырьмя различными значениями регуляризации, оптимальный параметр
print("best logistic regression from grid search: %f" % grid_clf.best_estimator_.score(X_test, y_test))
лучшая логистическая регрессия из сетки поиска: 0,850891
Чтобы получить доступ к прогнозируемым вероятностям:
grid_clf.best_estimator_.predict_proba(X_test)
array([[0.83576677, 0.16423323],
[0.9458291 , 0.0541709 ],
[0.64760416, 0.35239584],
...,
[0.99639224, 0.00360776],
[0.02072033, 0.97927967],
[0.56782222, 0.43217778]])
Модель XGBoost с scikit-learn
Попробуем подготовить один из лучших классификаторов на рынке. XGBoost — это улучшение по сравнению со случайным лесом. Теоретические основы классификатора выходят за рамки этого урока. Имейте в виду, что XGBoost выиграл множество соревнований по борьбе. При среднем размере набора данных он может работать так же хорошо, как алгоритм глубокого обучения или даже лучше.
Классификатор сложно обучать, потому что он имеет большое количество параметров для настройки. Вы можете, конечно, использовать GridSearchCV, чтобы выбрать параметр для вас.
Вместо этого, давайте посмотрим, как использовать лучший способ найти оптимальные параметры. GridSearchCV может быть утомительным и очень долго тренироваться, если вы передадите много значений. Пространство поиска растет вместе с количеством параметров. Предпочтительным решением является использование RandomizedSearchCV. Этот метод состоит из случайного выбора значений каждого гиперпараметра после каждой итерации. Например, если классификатор обучен за 1000 итераций, то оцениваются 1000 комбинаций. Это работает более или менее как. GridSearchCV
Вам нужно импортировать xgboost. Если библиотека не установлена, используйте pip3 install xgboost или
use import sys
!{sys.executable} -m pip install xgboost
В среде Jupyter
Следующий,
import xgboost from sklearn.model_selection import RandomizedSearchCV from sklearn.model_selection import StratifiedKFold
Следующий шаг включает в себя указание параметров для настройки. Вы можете обратиться к официальной документации, чтобы увидеть все параметры для настройки. Ради учебника вы выбираете только два гиперпараметра с двумя значениями каждый. XGBoost требует много времени для обучения, чем больше гиперпараметров в сетке, тем дольше вам нужно ждать.
params = {
'xgbclassifier__gamma': [0.5, 1],
'xgbclassifier__max_depth': [3, 4]
}
Вы создаете новый конвейер с классификатором XGBoost. Вы выбираете, чтобы определить 600 оценщиков. Обратите внимание, что n_estimators — это параметр, который вы можете настроить. Высокое значение может привести к переоснащению. Вы можете попробовать разные значения, но помните, что это может занять несколько часов. Вы используете значение по умолчанию для других параметров
model_xgb = make_pipeline(
preprocess,
xgboost.XGBClassifier(
n_estimators=600,
objective='binary:logistic',
silent=True,
nthread=1)
)
Вы можете улучшить перекрестную проверку с помощью перекрестного средства проверки Straified K-Folds. Здесь вы строите только три раза, чтобы ускорить вычисления, но при этом снизить качество. Увеличьте это значение до 5 или 10 дома, чтобы улучшить результаты.
Вы выбираете тренировать модель в течение четырех итераций.
skf = StratifiedKFold(n_splits=3,
shuffle = True,
random_state = 1001)
random_search = RandomizedSearchCV(model_xgb,
param_distributions=params,
n_iter=4,
scoring='accuracy',
n_jobs=4,
cv=skf.split(X_train, y_train),
verbose=3,
random_state=1001)
Рандомизированный поиск готов к использованию, вы можете обучить модель
#grid_xgb = GridSearchCV(model_xgb, params, cv=10, iid=False) random_search.fit(X_train, y_train)
Fitting 3 folds for each of 4 candidates, totalling 12 fits [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............ [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............ [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............ [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............ [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8759645283888057, total= 1.0min [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............ [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8729701715996775, total= 1.0min [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8706519235199263, total= 1.0min [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............ [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 .............. [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8735460094437406, total= 1.3min [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 .............. [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8722791661868018, total= 57.7s [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 .............. [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8753886905447426, total= 1.0min [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 .............. [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8697304768486523, total= 1.3min [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 .............. [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8740066797189912, total= 1.4min [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 .............. [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8707671043538355, total= 1.0min [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8729701715996775, total= 1.2min [Parallel(n_jobs=4)]: Done 10 out of 12 | elapsed: 3.6min remaining: 43.5s [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8736611770125533, total= 1.2min [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8692697535130154, total= 1.2min
[Parallel(n_jobs=4)]: Done 12 out of 12 | elapsed: 3.6min finished /Users/Thomas/anaconda3/envs/hello-tf/lib/python3.6/site-packages/sklearn/model_selection/_search.py:737: DeprecationWarning: The default of the `iid` parameter will change from True to False in version 0.22 and will be removed in 0.24. This will change numeric results when test-set sizes are unequal. DeprecationWarning)
RandomizedSearchCV(cv=<generator object _BaseKFold.split at 0x1101eb830>,
error_score='raise-deprecating',
estimator=Pipeline(memory=None,
steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None,
transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,...
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None,
silent=True, subsample=1))]),
fit_params=None, iid='warn', n_iter=4, n_jobs=4,
param_distributions={'xgbclassifier__gamma': [0.5, 1], 'xgbclassifier__max_depth': [3, 4]},
pre_dispatch='2*n_jobs', random_state=1001, refit=True,
return_train_score='warn', scoring='accuracy', verbose=3)
Как вы можете видеть, XGBoost имеет лучший результат, чем предыдущая регрессия логистики.
print("Best parameter", random_search.best_params_)
print("best logistic regression from grid search: %f" % random_search.best_estimator_.score(X_test, y_test))
Best parameter {'xgbclassifier__max_depth': 3, 'xgbclassifier__gamma': 0.5}
best logistic regression from grid search: 0.873157
random_search.best_estimator_.predict(X_test)
array(['<=50K', '<=50K', '<=50K', ..., '<=50K', '>50K', '<=50K'], dtype=object)
Создать DNN с MLPClassifier в scikit-learn
Наконец, вы можете обучить алгоритму глубокого обучения с помощью scikit-learn. Метод такой же, как и у другого классификатора. Классификатор доступен на MLPClassifier.
from sklearn.neural_network import MLPClassifier
Вы определяете следующий алгоритм глубокого обучения:
- Адам Солвер
- Функция активации Relu
- Альфа = 0,0001
- размер партии 150
- Два скрытых слоя с 100 и 50 нейронами соответственно
model_dnn = make_pipeline(
preprocess,
MLPClassifier(solver='adam',
alpha=0.0001,
activation='relu',
batch_size=150,
hidden_layer_sizes=(200, 100),
random_state=1))
Вы можете изменить количество слоев, чтобы улучшить модель
model_dnn.fit(X_train, y_train)
print("DNN regression score: %f" % model_dnn.score(X_test, y_test))
Оценка регрессии DNN: 0,821253
ЛАЙМ: доверяй своей модели
Now that you have a good model, you need a tool to trust it. Machine learning algorithm, especially random forest and neural network, are known to be blax-box algorithm. Say differently, it works but no one knows why.
Three researchers have come up with a great tool to see how the computer makes a prediction. The paper is called Why Should I Trust You?
They developed an algorithm named Local Interpretable Model-Agnostic Explanations (LIME).
Take an example:
sometimes you do not know if you can trust a machine-learning prediction:
A doctor, for example, cannot trust a diagnosis just because a computer said so. You also need to know if you can trust the model before putting it into production.
Imagine we can understand why any classifier is making a prediction even incredibly complicated models such as neural networks, random forests or svms with any kernel
will become more accessible to trust a prediction if we can understand the reasons behind it. From the example with the doctor, if the model told him which symptoms are essential you would trust it, it is also easier to figure out if you should not trust the model.
Lime can tell you what features affect the decisions of the classifier
Data Preparation
They are a couple of things you need to change to run LIME with python. First of all, you need to install lime in the terminal. You can use pip install lime
Lime makes use of LimeTabularExplainer object to approximate the model locally. This object requires:
- a dataset in numpy format
- The name of the features: feature_names
- The name of the classes: class_names
- The index of the column of the categorical features: categorical_features
- The name of the group for each categorical features: categorical_names
Create numpy train set
You can copy and convert df_train from pandas to numpy very easily
df_train.head(5) # Create numpy data df_lime = df_train df_lime.head(3)
Get the class name The label is accessible with the object unique(). You should see:
- ‘<=50K’
- ‘>50K’
# Get the class name class_names = df_lime.label.unique() class_names
array(['<=50K', '>50K'], dtype=object)
index of the column of the categorical features
You can use the method you lean before to get the name of the group. You encode the label with LabelEncoder. You repeat the operation on all the categorical features.
##
import sklearn.preprocessing as preprocessing
categorical_names = {}
for feature in CATE_FEATURES:
le = preprocessing.LabelEncoder()
le.fit(df_lime[feature])
df_lime[feature] = le.transform(df_lime[feature])
categorical_names[feature] = le.classes_
print(categorical_names)
{'workclass': array(['?', 'Federal-gov', 'Local-gov', 'Never-worked', 'Private',
'Self-emp-inc', 'Self-emp-not-inc', 'State-gov', 'Without-pay'],
dtype=object), 'education': array(['10th', '11th', '12th', '1st-4th', '5th-6th', '7th-8th', '9th',
'Assoc-acdm', 'Assoc-voc', 'Bachelors', 'Doctorate', 'HS-grad',
'Masters', 'Preschool', 'Prof-school', 'Some-college'],
dtype=object), 'marital': array(['Divorced', 'Married-AF-spouse', 'Married-civ-spouse',
'Married-spouse-absent', 'Never-married', 'Separated', 'Widowed'],
dtype=object), 'occupation': array(['?', 'Adm-clerical', 'Armed-Forces', 'Craft-repair',
'Exec-managerial', 'Farming-fishing', 'Handlers-cleaners',
'Machine-op-inspct', 'Other-service', 'Priv-house-serv',
'Prof-specialty', 'Protective-serv', 'Sales', 'Tech-support',
'Transport-moving'], dtype=object), 'relationship': array(['Husband', 'Not-in-family', 'Other-relative', 'Own-child',
'Unmarried', 'Wife'], dtype=object), 'race': array(['Amer-Indian-Eskimo', 'Asian-Pac-Islander', 'Black', 'Other',
'White'], dtype=object), 'sex': array(['Female', 'Male'], dtype=object), 'native_country': array(['?', 'Cambodia', 'Canada', 'China', 'Columbia', 'Cuba',
'Dominican-Republic', 'Ecuador', 'El-Salvador', 'England',
'France', 'Germany', 'Greece', 'Guatemala', 'Haiti', 'Honduras',
'Hong', 'Hungary', 'India', 'Iran', 'Ireland', 'Italy', 'Jamaica',
'Japan', 'Laos', 'Mexico', 'Nicaragua',
'Outlying-US(Guam-USVI-etc)', 'Peru', 'Philippines', 'Poland',
'Portugal', 'Puerto-Rico', 'Scotland', 'South', 'Taiwan',
'Thailand', 'Trinadad&Tobago', 'United-States', 'Vietnam',
'Yugoslavia'], dtype=object)}
df_lime.dtypes
age float64 workclass int64 fnlwgt float64 education int64 education_num float64 marital int64 occupation int64 relationship int64 race int64 sex int64 capital_gain float64 capital_loss float64 hours_week float64 native_country int64 label object dtype: object
Теперь, когда набор данных готов, вы можете создать другой набор данных. Вы фактически трансформируете данные вне конвейера, чтобы избежать ошибок с LIME. Обучающий набор в LimeTabularExplainer должен быть пустым массивом без строки. При использовании описанного выше метода у вас уже есть конвертированный тренировочный набор данных.
from sklearn.model_selection import train_test_split
X_train_lime, X_test_lime, y_train_lime, y_test_lime = train_test_split(df_lime[features],
df_lime.label,
test_size = 0.2,
random_state=0)
X_train_lime.head(5)
Вы можете сделать конвейер с оптимальными параметрами из XGBoost
model_xgb = make_pipeline(
preprocess,
xgboost.XGBClassifier(max_depth = 3,
gamma = 0.5,
n_estimators=600,
objective='binary:logistic',
silent=True,
nthread=1))
model_xgb.fit(X_train_lime, y_train_lime)
/Users/Thomas/anaconda3/envs/hello-tf/lib/python3.6/site-packages/sklearn/preprocessing/_encoders.py:351: FutureWarning: The handling of integer data will change in version 0.22. Currently, the categories are determined based on the range [0, max(values)], while in the future they will be determined based on the unique values. If you want the future behavior and silence this warning, you can specify "categories='auto'."In case you used a LabelEncoder before this OneHotEncoder to convert the categories to integers, then you can now use the OneHotEncoder directly. warnings.warn(msg, FutureWarning)
Pipeline(memory=None,
steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None,
transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,...
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None,
silent=True, subsample=1))])
Вы получаете предупреждение. Предупреждение объясняет, что вам не нужно создавать кодировщик меток перед конвейером. Если вы не хотите использовать LIME, вы можете использовать метод из первой части урока. В противном случае вы можете использовать этот метод, сначала создать набор закодированных данных, настроить получение горячего кодировщика внутри конвейера.
print("best logistic regression from grid search: %f" % model_xgb.score(X_test_lime, y_test_lime))
best logistic regression from grid search: 0.873157
model_xgb.predict_proba(X_test_lime)
array([[7.9646105e-01, 2.0353897e-01],
[9.5173013e-01, 4.8269872e-02],
[7.9344827e-01, 2.0655173e-01],
...,
[9.9031430e-01, 9.6856682e-03],
[6.4581633e-04, 9.9935418e-01],
[9.7104281e-01, 2.8957171e-02]], dtype=float32)
Прежде чем использовать LIME в действии, давайте создадим пустой массив с функциями неправильной классификации. Вы можете использовать этот список позже, чтобы понять, что вводит в заблуждение классификатор.
temp = pd.concat([X_test_lime, y_test_lime], axis= 1)
temp['predicted'] = model_xgb.predict(X_test_lime)
temp['wrong']= temp['label'] != temp['predicted']
temp = temp.query('wrong==True').drop('wrong', axis=1)
temp= temp.sort_values(by=['label'])
temp.shape
(826, 16)
Вы создаете лямбда-функцию для извлечения прогноза из модели с новыми данными. Вам это понадобится в ближайшее время.
predict_fn = lambda x: model_xgb.predict_proba(x).astype(float) X_test_lime.dtypes
age float64 workclass int64 fnlwgt float64 education int64 education_num float64 marital int64 occupation int64 relationship int64 race int64 sex int64 capital_gain float64 capital_loss float64 hours_week float64 native_country int64 dtype: object
predict_fn(X_test_lime)
array([[7.96461046e-01, 2.03538969e-01],
[9.51730132e-01, 4.82698716e-02],
[7.93448269e-01, 2.06551731e-01],
...,
[9.90314305e-01, 9.68566816e-03],
[6.45816326e-04, 9.99354184e-01],
[9.71042812e-01, 2.89571714e-02]])
Вы конвертируете информационный фрейм панд в массив numpy
X_train_lime = X_train_lime.values X_test_lime = X_test_lime.values X_test_lime
array([[4.00000e+01, 5.00000e+00, 1.93524e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
[2.70000e+01, 4.00000e+00, 2.16481e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
[2.50000e+01, 4.00000e+00, 2.56263e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
...,
[2.80000e+01, 6.00000e+00, 2.11032e+05, ..., 0.00000e+00,
4.00000e+01, 2.50000e+01],
[4.40000e+01, 4.00000e+00, 1.67005e+05, ..., 0.00000e+00,
6.00000e+01, 3.80000e+01],
[5.30000e+01, 4.00000e+00, 2.57940e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01]])
model_xgb.predict_proba(X_test_lime)
array([[7.9646105e-01, 2.0353897e-01],
[9.5173013e-01, 4.8269872e-02],
[7.9344827e-01, 2.0655173e-01],
...,
[9.9031430e-01, 9.6856682e-03],
[6.4581633e-04, 9.9935418e-01],
[9.7104281e-01, 2.8957171e-02]], dtype=float32)
print(features,
class_names,
categorical_features,
categorical_names)
['age', 'workclass', 'fnlwgt', 'education', 'education_num', 'marital', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_week', 'native_country'] ['<=50K' '>50K'] [1, 3, 5, 6, 7, 8, 9, 13] {'workclass': array(['?', 'Federal-gov', 'Local-gov', 'Never-worked', 'Private',
'Self-emp-inc', 'Self-emp-not-inc', 'State-gov', 'Without-pay'],
dtype=object), 'education': array(['10th', '11th', '12th', '1st-4th', '5th-6th', '7th-8th', '9th',
'Assoc-acdm', 'Assoc-voc', 'Bachelors', 'Doctorate', 'HS-grad',
'Masters', 'Preschool', 'Prof-school', 'Some-college'],
dtype=object), 'marital': array(['Divorced', 'Married-AF-spouse', 'Married-civ-spouse',
'Married-spouse-absent', 'Never-married', 'Separated', 'Widowed'],
dtype=object), 'occupation': array(['?', 'Adm-clerical', 'Armed-Forces', 'Craft-repair',
'Exec-managerial', 'Farming-fishing', 'Handlers-cleaners',
'Machine-op-inspct', 'Other-service', 'Priv-house-serv',
'Prof-specialty', 'Protective-serv', 'Sales', 'Tech-support',
'Transport-moving'], dtype=object), 'relationship': array(['Husband', 'Not-in-family', 'Other-relative', 'Own-child',
'Unmarried', 'Wife'], dtype=object), 'race': array(['Amer-Indian-Eskimo', 'Asian-Pac-Islander', 'Black', 'Other',
'White'], dtype=object), 'sex': array(['Female', 'Male'], dtype=object), 'native_country': array(['?', 'Cambodia', 'Canada', 'China', 'Columbia', 'Cuba',
'Dominican-Republic', 'Ecuador', 'El-Salvador', 'England',
'France', 'Germany', 'Greece', 'Guatemala', 'Haiti', 'Honduras',
'Hong', 'Hungary', 'India', 'Iran', 'Ireland', 'Italy', 'Jamaica',
'Japan', 'Laos', 'Mexico', 'Nicaragua',
'Outlying-US(Guam-USVI-etc)', 'Peru', 'Philippines', 'Poland',
'Portugal', 'Puerto-Rico', 'Scotland', 'South', 'Taiwan',
'Thailand', 'Trinadad&Tobago', 'United-States', 'Vietnam',
'Yugoslavia'], dtype=object)}
import lime
import lime.lime_tabular
### Train should be label encoded not one hot encoded
explainer = lime.lime_tabular.LimeTabularExplainer(X_train_lime ,
feature_names = features,
class_names=class_names,
categorical_features=categorical_features,
categorical_names=categorical_names,
kernel_width=3)
Давайте выберем случайное домашнее хозяйство из набора тестов и посмотрим прогноз модели и то, как компьютер сделал свой выбор.
import numpy as np np.random.seed(1) i = 100 print(y_test_lime.iloc[i]) >50K
X_test_lime[i]
array([4.20000e+01, 4.00000e+00, 1.76286e+05, 7.00000e+00, 1.20000e+01,
2.00000e+00, 4.00000e+00, 0.00000e+00, 4.00000e+00, 1.00000e+00,
0.00000e+00, 0.00000e+00, 4.00000e+01, 3.80000e+01])
Вы можете использовать объяснитель с объяснением объяснения за моделью.
exp = explainer.explain_instance(X_test_lime[i], predict_fn, num_features=6) exp.show_in_notebook(show_all=False)
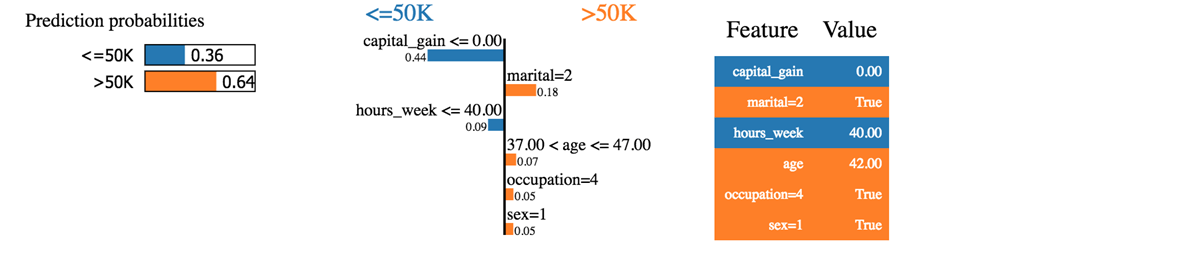
Мы видим, что классификатор правильно предсказал домохозяйство. Доход действительно выше 50 тысяч.
Первое, что мы можем сказать, это то, что классификатор не уверен в предсказанных вероятностях. Машина предсказывает, что доход семьи превышает 50 тыс. С вероятностью 64%. Эти 64% состоят из прироста капитала и брачных отношений. Синий цвет отрицательно влияет на положительный класс, а оранжевая линия — положительно.
Классификатор сбит с толку, потому что прирост капитала этого домохозяйства равен нулю, в то время как прирост капитала обычно является хорошим показателем благосостояния. Кроме того, домохозяйство работает менее 40 часов в неделю. Возраст, род занятий и пол положительно влияют на классификатор.
Если бы семейное положение было одиноким, классификатор прогнозировал бы доход ниже 50 тыс. (0,64-0,18 = 0,46).
Мы можем попробовать с другим домохозяйством, которое было ошибочно классифицировано
temp.head(3) temp.iloc[1,:-2]
age 58 workclass 4 fnlwgt 68624 education 11 education_num 9 marital 2 occupation 4 relationship 0 race 4 sex 1 capital_gain 0 capital_loss 0 hours_week 45 native_country 38 Name: 20931, dtype: object
i = 1
print('This observation is', temp.iloc[i,-2:])
This observation is label <=50K predicted >50K Name: 20931, dtype: object
exp = explainer.explain_instance(temp.iloc[1,:-2], predict_fn, num_features=6) exp.show_in_notebook(show_all=False)

Классификатор предсказал доход ниже 50 тыс., Хотя это не соответствует действительности. Это домашнее хозяйство кажется странным. У него нет ни прироста капитала, ни потери капитала. Он в разводе и ему 60 лет, и это образованные люди, то есть education_num> 12. Согласно общей схеме, это домашнее хозяйство должно, как объяснено классификатором, получать доход ниже 50 тыс.
Вы пытаетесь поиграть с LIME. Вы заметите грубые ошибки из классификатора.
Вы можете проверить GitHub владельца библиотеки. Они предоставляют дополнительную документацию для классификации изображений и текста.
Резюме
Ниже приведен список некоторых полезных команд с scikit learn version> = 0.20
|
создать набор данных поезда / теста |
ученики разделились |
|
Построить трубопровод |
|
|
выберите столбец и примените преобразование |
makecolumntransformer |
|
тип трансформации |
|
|
гостирован |
StandardScaler |
|
мин Макс |
MinMaxScaler |
|
Нормализовать |
Normalizer |
|
Вменяйте недостающее значение |
Imputer |
|
Преобразовать категоричный |
OneHotEncoder |
|
Подгонка и преобразование данных |
fit_transform |
|
Сделать трубопровод |
make_pipeline |
|
Базовая модель |
|
|
логистическая регрессия |
Логистическая регрессия |
|
XGBoost |
XGBClassifier |
|
Нейронная сеть |
MLPClassifier |
|
Сетка поиска |
GridSearchCV |
|
Рандомизированный поиск |
RandomizedSearchCV |