Что такое линейный классификатор?
Двумя наиболее распространенными контролируемыми учебными задачами являются линейная регрессия и линейный классификатор. Линейная регрессия предсказывает значение, в то время как линейный классификатор предсказывает класс. Этот учебник ориентирован на линейный классификатор.
Проблемы классификации составляют примерно 80 процентов задачи машинного обучения. Целью классификации является прогнозирование вероятности каждого класса с учетом набора входных данных. Метка (т.е. зависимая переменная) представляет собой дискретное значение, называемое классом.
- Если метка имеет только два класса, алгоритм обучения является двоичным классификатором.
- Мультиклассовый классификатор работает с метками более чем с двумя классами.
Например, типичная проблема двоичной классификации заключается в прогнозировании вероятности совершения покупателем второй покупки. Предсказание типа животного, показанного на картинке, является проблемой мультиклассовой классификации, поскольку существует более двух разновидностей животных.
Теоретическая часть этого урока делает основной упор на бинарный класс. Вы узнаете больше о функции вывода мультикласса в следующем уроке.
В этом уроке вы узнаете
- Что такое линейный классификатор?
- Как работает двоичный классификатор?
- Как измерить производительность линейного классификатора?
- точность
- Путаница матрица
- Точность и чувствительность
- Линейный классификатор с TensorFlow
- Шаг 1) Импортируйте данные
- Шаг 2) Преобразование данных
- Шаг 3) Тренируйте классификатор
- Шаг 4) Улучшение модели
- Шаг 5) Гиперпараметр: лассо и хребет
Как работает двоичный классификатор?
В предыдущем уроке вы узнали, что функция состоит из двух типов переменных: зависимой переменной и набора функций (независимых переменных). В линейной регрессии зависимая переменная представляет собой действительное число без диапазона. Основная цель состоит в том, чтобы предсказать его значение путем минимизации среднеквадратичной ошибки.
Для двоичной задачи метка может иметь два возможных целочисленных значения. В большинстве случаев это либо [0,1], либо [1,2]. Например, цель состоит в том, чтобы предсказать, купит ли клиент продукт или нет. Метка определяется следующим образом:
- Y = 1 (покупатель приобрел товар)
- Y = 0 (покупатель не покупает товар)
Модель использует функции X для классификации каждого покупателя по наиболее вероятному классу, к которому он принадлежит, а именно, потенциальный покупатель или нет.
Вероятность успеха рассчитывается с помощью логистической регрессии . Алгоритм вычислит вероятность на основе признака X и прогнозирует успех, когда эта вероятность превышает 50 процентов. Более формально вероятность рассчитывается следующим образом:
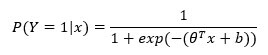
где 0 — набор весов, особенностей и смещения.
Функция может быть разбита на две части:
- Линейная модель
- Логистическая функция
Линейная модель
Вы уже знакомы с тем, как рассчитываются веса. Весовые коэффициенты вычисляются с использованием точечного произведения: 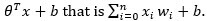 Y — линейная функция всех признаков x i . Если модель не имеет особенностей, прогноз равен смещению, б.
Y — линейная функция всех признаков x i . Если модель не имеет особенностей, прогноз равен смещению, б.
Веса указывают направление корреляции между признаками x i и меткой y. Положительная корреляция увеличивает вероятность положительного класса, в то время как отрицательная корреляция приводит вероятность ближе к 0 (т. Е. Отрицательный класс).
Линейная модель возвращает только действительное число, которое не согласуется с вероятностной мерой диапазона [0,1]. Логистическая функция требуется для преобразования выходной линейной модели в вероятность,
Логистическая функция
Логистическая функция, или сигмовидная функция, имеет S-образную форму, и выход этой функции всегда находится между 0 и 1.
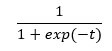
Выход линейной регрессии легко подставить в сигмовидную функцию. В результате получается новое число с вероятностью от 0 до 1.
Классификатор может преобразовать вероятность в класс
- Значения от 0 до 0,49 становятся классом 0
- Значения от 0,5 до 1 становятся классом 1
Как измерить производительность линейного классификатора?
точность
Общая эффективность классификатора измеряется с помощью метрики точности. Точность собирает все правильные значения, деленные на общее количество наблюдений. Например, значение точности 80 процентов означает, что модель верна в 80 процентах случаев.
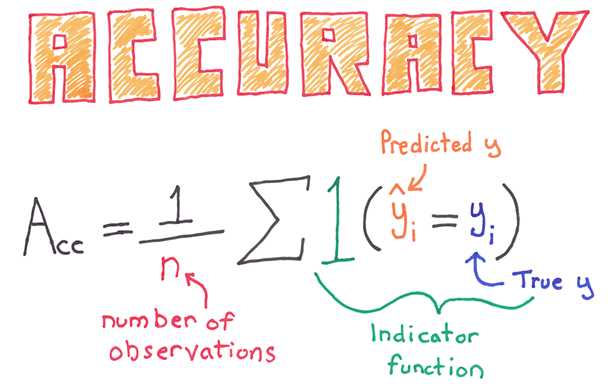
Вы можете отметить недостаток этой метрики, особенно для класса дисбаланса. Набор данных о дисбалансе возникает, когда число наблюдений на группу не равно. Скажем; Вы пытаетесь классифицировать редкое событие с помощью логистической функции. Представьте, что классификатор пытается оценить смерть пациента после заболевания. По данным, 5 процентов пациентов скончались. Вы можете обучить классификатор, чтобы предсказать количество смертей и использовать метрику точности, чтобы оценить показатели. Если классификатор предсказывает 0 смертей для всего набора данных, он будет правильным в 95 процентах случаев.
Путаница матрица
Лучший способ оценить производительность классификатора — взглянуть на матрицу путаницы.
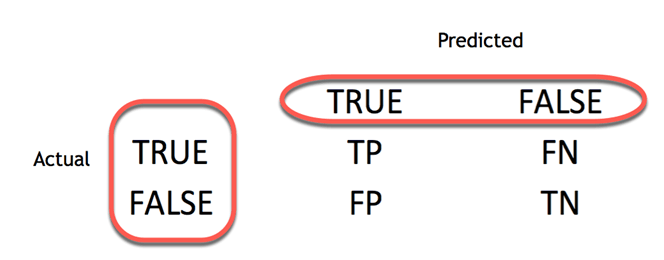
Матрица путаницы визуализирует точность классификатора, сравнивая фактические и прогнозируемые классы. Матрица двоичной путаницы состоит из квадратов:
- TP: True Positive: прогнозируемые значения, правильно прогнозируемые как фактические положительные
- FP: Предсказанные значения неправильно предсказывают фактический положительный результат. т.е. отрицательные значения прогнозируются как положительные
- FN: False Negative: положительные значения прогнозируются как отрицательные
- TN: True Negative: прогнозируемые значения, правильно прогнозируемые как фактические отрицательные
Из матрицы путаницы легко сравнить фактический класс и прогнозируемый класс.
Точность и чувствительность
Матрица путаницы дает хорошее понимание истинного положительного и ложного положительного. В некоторых случаях предпочтительно иметь более сжатую метрику.
точность
Метрика точности показывает точность положительного класса. Он измеряет вероятность того, что прогноз положительного класса верен.
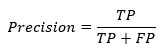
Максимальная оценка равна 1, когда классификатор отлично классифицирует все положительные значения. Одна только точность не очень полезна, потому что она игнорирует отрицательный класс. Метрика обычно сопряжена с метрикой Recall. Напомним, также называется чувствительность или истинно положительный показатель.
чувствительность
Чувствительность вычисляет соотношение положительно обнаруженных классов. Этот показатель показывает, насколько хороша модель для распознавания положительного класса.
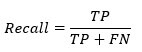
Линейный классификатор с TensorFlow
Для этого урока мы будем использовать набор данных переписи. Цель состоит в том, чтобы использовать переменные в наборе данных переписи для прогнозирования уровня дохода. Обратите внимание, что доход является двоичной переменной
- со значением 1, если доход> 50k
- 0 если доход <50к.
Эта переменная — ваш ярлык
Этот набор данных включает в себя восемь категориальных переменных:
- рабочее место
- образование
- супружеский
- род занятий
- отношения
- гонка
- секс
- родная страна
кроме того, шесть непрерывных переменных:
- возраст
- fnlwgt
- education_num
- прирост капитала
- capital_loss
- hours_week
Из этого примера вы поймете, как обучить линейный классификатор с помощью оценщика TensorFlow и как улучшить показатель точности.
Мы будем действовать следующим образом:
- Шаг 1) Импортируйте данные
- Шаг 2) Преобразование данных
- Шаг 3) Обучить классификатор
- Шаг 4) Улучшение модели
- Шаг 5) Гиперпараметр: лассо и хребет
Шаг 1) Импортируйте данные
Сначала вы импортируете библиотеки, используемые во время урока.
import tensorflow as tf import pandas as pd
Далее вы импортируете данные из архива UCI и определяете имена столбцов. Вы будете использовать КОЛОННЫ для именования столбцов во фрейме данных Pandas.
Обратите внимание, что вы будете обучать классификатор, используя фрейм данных Pandas.
## Define path data
COLUMNS = ['age','workclass', 'fnlwgt', 'education', 'education_num', 'marital',
'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss',
'hours_week', 'native_country', 'label']
PATH = "https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data"
PATH_test = "https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.test"
Данные, хранящиеся в сети, уже поделены между набором поездов и тестовым набором.
df_train = pd.read_csv(PATH, skipinitialspace=True, names = COLUMNS, index_col=False) df_test = pd.read_csv(PATH_test,skiprows = 1, skipinitialspace=True, names = COLUMNS, index_col=False)
Набор поездов содержит 32 561 наблюдений и набор тестов 16 281
print(df_train.shape, df_test.shape) print(df_train.dtypes) (32561, 15) (16281, 15) age int64 workclass object fnlwgt int64 education object education_num int64 marital object occupation object relationship object race object sex object capital_gain int64 capital_loss int64 hours_week int64 native_country object label object dtype: object
Tensorflow требует логического значения для обучения классификатора. Вам нужно привести значения из строки в целое число. Метка хранится как объект, однако вам необходимо преобразовать ее в числовое значение. Приведенный ниже код создает словарь со значениями для преобразования и циклического перемещения по элементу столбца. Обратите внимание, что вы выполняете эту операцию дважды, один для теста поезда, один для набора тестов
label = {'<=50K': 0,'>50K': 1}
df_train.label = [label[item] for item in df_train.label]
label_t = {'<=50K.': 0,'>50K.': 1}
df_test.label = [label_t[item] for item in df_test.label]
В данных поезда есть 24 720 доходов ниже, чем 50k и 7841 выше. Соотношение практически одинаковое для тестового набора. Пожалуйста, обратитесь к этому руководству на Facets для получения дополнительной информации.
print(df_train["label"].value_counts()) ### The model will be correct in atleast 70% of the case print(df_test["label"].value_counts()) ## Unbalanced label print(df_train.dtypes) 0 24720 1 7841 Name: label, dtype: int64 0 12435 1 3846 Name: label, dtype: int64 age int64 workclass object fnlwgt int64 education object education_num int64 marital object occupation object relationship object race object sex object capital_gain int64 capital_loss int64 hours_week int64 native_country object label int64 dtype: object
Шаг 2) Преобразование данных
Для обучения линейного классификатора с помощью Tensorflow необходимо выполнить несколько шагов. Вам необходимо подготовить функции для включения в модель. В регрессионном тесте вы будете использовать исходные данные без каких-либо преобразований.
Оценщик должен иметь список возможностей для обучения модели. Следовательно, данные столбца должны быть преобразованы в тензор.
Хорошей практикой является определение двух списков объектов в зависимости от их типа, а затем передача их в feature_columns блока оценки.
Вы начнете с преобразования непрерывных объектов, а затем определите сегмент с категориальными данными.
Функции набора данных имеют два формата:
- целое число
- объект
Каждая особенность перечислена в следующих двух переменных согласно их типам.
## Add features to the bucket: ### Define continuous list CONTI_FEATURES = ['age', 'fnlwgt','capital_gain', 'education_num', 'capital_loss', 'hours_week'] ### Define the categorical list CATE_FEATURES = ['workclass', 'education', 'marital', 'occupation', 'relationship', 'race', 'sex', 'native_country']
Feature_column снабжен объектом numeric_column, чтобы помочь в преобразовании непрерывных переменных в тензор. В приведенном ниже коде вы конвертируете все переменные из CONTI_FEATURES в тензор с числовым значением. Это обязательно для построения модели. Все независимые переменные должны быть преобразованы в правильный тип тензора.
Ниже мы напишем код, который позволит вам увидеть, что происходит за feature_column.numeric_column. Мы напечатаем преобразованное значение для возраста. Это для пояснительной цели, поэтому нет необходимости понимать код Python. Вы можете обратиться к официальной документации, чтобы понять коды.
def print_transformation(feature = "age", continuous = True, size = 2):
#X = fc.numeric_column(feature)
## Create feature name
feature_names = [
feature]
## Create dict with the data
d = dict(zip(feature_names, [df_train[feature]]))
## Convert age
if continuous == True:
c = tf.feature_column.numeric_column(feature)
feature_columns = [c]
else:
c = tf.feature_column.categorical_column_with_hash_bucket(feature, hash_bucket_size=size)
c_indicator = tf.feature_column.indicator_column(c)
feature_columns = [c_indicator]
## Use input_layer to print the value
input_layer = tf.feature_column.input_layer(
features=d,
feature_columns=feature_columns
)
## Create lookup table
zero = tf.constant(0, dtype=tf.float32)
where = tf.not_equal(input_layer, zero)
## Return lookup tble
indices = tf.where(where)
values = tf.gather_nd(input_layer, indices)
## Initiate graph
sess = tf.Session()
## Print value
print(sess.run(input_layer))
print_transformation(feature = "age", continuous = True)
[[39.]
[50.]
[38.]
...
[58.]
[22.]
[52.]]
Значения точно такие же, как в df_train
continuous_features = [tf.feature_column.numeric_column(k) for k in CONTI_FEATURES]
Согласно документации TensorFlow, существуют разные способы преобразования категориальных данных. Если словарный список функции известен и не имеет большого количества значений, можно создать категориальный столбец с категориальным списком категорий. Он назначит всем уникальным спискам словаря идентификатор.
Например, если состояние переменной имеет три различных значения:
- Муж
- Жена
- Один
Тогда три удостоверения личности будут приписаны. Например, у Мужа будет ID 1, у Wife ID 2 и так далее.
В целях иллюстрации вы можете использовать этот код для преобразования переменной объекта в категориальный столбец в TensorFlow.
Характеристика секса может иметь только два значения: мужское или женское. Когда мы преобразуем функцию пола, Tensorflow создаст 2 новых столбца, один для мужчин и один для женщин. Если пол равен мужскому, то новый столбец мужского пола будет равен 1, а женского — 0. Этот пример показан в таблице ниже:
|
строки |
секс |
после трансформации |
мужчина |
женский пол |
|
1 |
мужчина |
=> |
1 |
0 |
|
2 |
мужчина |
=> |
1 |
0 |
|
3 |
женский пол |
=> |
0 |
1 |
В тензорном потоке:
print_transformation(feature = "sex", continuous = False, size = 2)
[[1. 0.]
[1. 0.]
[1. 0.]
...
[0. 1.]
[1. 0.]
[0. 1.]]
relationship = tf.feature_column.categorical_column_with_vocabulary_list(
'relationship', [
'Husband', 'Not-in-family', 'Wife', 'Own-child', 'Unmarried',
'Other-relative'])
Ниже мы добавили код Python для печати кодировки. Опять же, вам не нужно понимать код, цель состоит в том, чтобы увидеть преобразование
Тем не менее, более быстрый способ преобразования данных заключается в использовании метода categoryorical_column_with_hash_bucket. Изменение строковых переменных в разреженной матрице будет полезно. Разреженная матрица — это матрица с большей частью нуля. Метод заботится обо всем. Вам нужно только указать количество сегментов и ключевой столбец. Количество сегментов — это максимальное количество групп, которое может создать Tensorflow. Ключевой столбец — это просто имя столбца для преобразования.
В приведенном ниже коде вы создаете цикл над всеми категориальными функциями.
categorical_features = [tf.feature_column.categorical_column_with_hash_bucket(k, hash_bucket_size=1000) for k in CATE_FEATURES]
Шаг 3) Тренируйте классификатор
В настоящее время TensorFlow предоставляет оценку для линейной регрессии и линейной классификации.
- Линейная регрессия: LinearRegressor
- Линейная классификация: LinearClassifier
Синтаксис линейного классификатора такой же, как в учебнике по линейной регрессии, за исключением одного аргумента, n_class. Вам необходимо определить столбец объектов, каталог моделей и сравнить с линейным регрессором; у вас есть определение номера класса. Для логит регрессии, это номер класса равен 2.
Модель будет вычислять вес столбцов, содержащихся в Continuous_Features и Категориальных_Features.
model = tf.estimator.LinearClassifier(
n_classes = 2,
model_dir="ongoing/train",
feature_columns=categorical_features+ continuous_features)
ВЫВОД:
INFO:tensorflow:Using default config.
INFO:tensorflow:Using config: {'_model_dir': 'ongoing/train', '_tf_random_seed': None, '_save_summary_steps': 100, '_save_checkpoints_steps': None, '_save_checkpoints_secs': 600, '_session_config': None, '_keep_checkpoint_max': 5, '_keep_checkpoint_every_n_hours': 10000, '_log_step_count_steps': 100, '_train_distribute': None, '_service': None, '_cluster_spec':
<tensorflow.python.training.server_lib.ClusterSpec object at 0x181f24c898>, '_task_type': 'worker', '_task_id': 0, '_global_id_in_cluster': 0, '_master': '', '_evaluation_master': '', '_is_chief': True, '_num_ps_replicas': 0, '_num_worker_replicas': 1}
Теперь, когда классификатор определен, вы можете создать функцию ввода. Метод такой же, как в учебнике по линейному регрессору. Здесь вы используете размер пакета 128 и перемешиваете данные.
FEATURES = ['age','workclass', 'fnlwgt', 'education', 'education_num', 'marital', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_week', 'native_country']
LABEL= 'label'
def get_input_fn(data_set, num_epochs=None, n_batch = 128, shuffle=True):
return tf.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({k: data_set[k].values for k in FEATURES}),
y = pd.Series(data_set[LABEL].values),
batch_size=n_batch,
num_epochs=num_epochs,
shuffle=shuffle)
Вы создаете функцию с аргументами, необходимыми для линейной оценки, т. Е. Числом эпох, количеством партий и перемешиванием набора данных или заметки. Поскольку вы используете метод Pandas для передачи данных в модель, вам необходимо определить переменные X как фрейм данных Pandas. Обратите внимание, что вы перебираете все данные, хранящиеся в FEATURES.
Давайте обучим модель с объектом model.train. Вы используете функцию, определенную ранее, чтобы снабдить модель соответствующими значениями. Обратите внимание, что вы установили размер пакета равным 128, а количество эпох — Нет. Модель будет обучена более тысячи шагов.
model.train(input_fn=get_input_fn(df_train,
num_epochs=None,
n_batch = 128,
shuffle=False),
steps=1000)
INFO:tensorflow:Calling model_fn. INFO:tensorflow:Done calling model_fn. INFO:tensorflow:Create CheckpointSaverHook. INFO:tensorflow: Graph was finalized. INFO:tensorflow:Running local_init_op. INFO:tensorflow:Done running local_init_op. INFO:tensorflow:Saving checkpoints for 1 into ongoing/train/model.ckpt. INFO:tensorflow:loss = 88.722855, step = 1 INFO:tensorflow:global_step/sec: 65.8282 INFO:tensorflow:loss = 52583.64, step = 101 (1.528 sec) INFO:tensorflow:global_step/sec: 118.386 INFO:tensorflow:loss = 25203.816, step = 201 (0.837 sec) INFO:tensorflow:global_step/sec: 110.542 INFO:tensorflow:loss = 54924.312, step = 301 (0.905 sec) INFO:tensorflow:global_step/sec: 199.03 INFO:tensorflow:loss = 68509.31, step = 401 (0.502 sec) INFO:tensorflow:global_step/sec: 167.488 INFO:tensorflow:loss = 9151.754, step = 501 (0.599 sec) INFO:tensorflow:global_step/sec: 220.155 INFO:tensorflow:loss = 34576.06, step = 601 (0.453 sec) INFO:tensorflow:global_step/sec: 199.016 INFO:tensorflow:loss = 36047.117, step = 701 (0.503 sec) INFO:tensorflow:global_step/sec: 197.531 INFO:tensorflow:loss = 22608.148, step = 801 (0.505 sec) INFO:tensorflow:global_step/sec: 208.479 INFO:tensorflow:loss = 22201.918, step = 901 (0.479 sec) INFO:tensorflow:Saving checkpoints for 1000 into ongoing/train/model.ckpt. INFO:tensorflow:Loss for final step: 5444.363. <tensorflow.python.estimator.canned.linear.LinearClassifier at 0x181f223630>
Обратите внимание, что впоследствии потери уменьшились в течение последних 100 шагов, то есть с 901 до 1000.
Окончательная потеря после тысячи итераций составляет 5444. Вы можете оценить свою модель на тестовом наборе и увидеть производительность. Чтобы оценить производительность вашей модели, вам нужно использовать объект оценки. Вы наполняете модель тестовым набором и устанавливаете количество эпох на 1, т. Е. Данные будут поступать в модель только один раз.
model.evaluate(input_fn=get_input_fn(df_test,
num_epochs=1,
n_batch = 128,
shuffle=False),
steps=1000)
INFO:tensorflow:Calling model_fn.
WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead.
WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead.
INFO:tensorflow:Done calling model_fn.
INFO:tensorflow:Starting evaluation at 2018-06-02-08:28:22
INFO:tensorflow:Graph was finalized.
INFO:tensorflow:Restoring parameters from ongoing/train/model.ckpt-1000
INFO:tensorflow:Running local_init_op.
INFO:tensorflow:Done running local_init_op.
INFO:tensorflow:Evaluation [100/1000]
INFO:tensorflow:Finished evaluation at 2018-06-02-08:28:23
INFO:tensorflow:Saving dict for global step 1000: accuracy = 0.7615626, accuracy_baseline = 0.76377374, auc = 0.63300294, auc_precision_recall = 0.50891197, average_loss = 47.12155, global_step = 1000, label/mean = 0.23622628, loss = 5993.6406, precision = 0.49401596, prediction/mean = 0.18454961, recall = 0.38637546
{'accuracy': 0.7615626,
'accuracy_baseline': 0.76377374,
'auc': 0.63300294,
'auc_precision_recall': 0.50891197,
'average_loss': 47.12155,
'global_step': 1000,
'label/mean': 0.23622628,
'loss': 5993.6406,
'precision': 0.49401596,
'prediction/mean': 0.18454961,
'recall': 0.38637546}
TensorFlow возвращает все метрики, которые вы узнали в теоретической части. Не удивительно, что точность большая из-за несбалансированной этикетки. На самом деле модель работает немного лучше, чем случайное предположение. Представьте, что модель предсказывает все домохозяйства с доходом ниже 50К, тогда модель имеет точность 70 процентов. При ближайшем анализе вы можете увидеть прогноз и отзыв довольно низок.
Шаг 4) Улучшение модели
Теперь, когда у вас есть эталонная модель, вы можете попытаться улучшить ее, то есть повысить точность. В предыдущем уроке вы узнали, как улучшить силу предсказания с помощью термина взаимодействия. В этом руководстве вы вернетесь к этой идее, добавив полиномиальный термин в регрессию.
Полиномиальная регрессия полезна, когда в данных присутствует нелинейность. Есть два способа уловить нелинейность данных.
- Добавить полиномиальный термин
- Bucketize непрерывной переменной в категориальную переменную
Полиномиальный термин
Из рисунка ниже вы можете увидеть, что такое полиномиальная регрессия. Это уравнение с X переменными с различной степенью. Полиномиальная регрессия второй степени имеет две переменные, X и X в квадрате. Третья степень имеет три переменные, X, X 2 и X 3
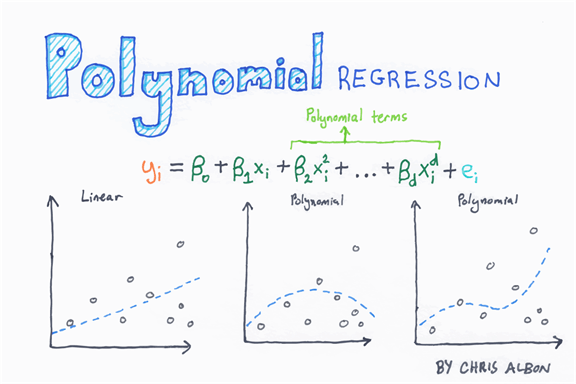
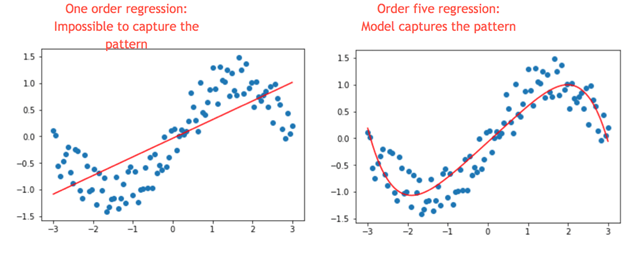
Ниже мы построили график с двумя переменными, X и Y. Очевидно, что связь не является линейной. Если мы добавим линейную регрессию, мы увидим, что модель не может захватить образец (левая картинка).
Теперь, посмотрите на левую картинку на картинке ниже, мы добавили пятичлен к регрессии (то есть y = x + x 2 + x 3 + x 4 + x 5. Модель теперь лучше отражает модель. Это сила полиномиальной регрессии.
Давайте вернемся к нашему примеру. Возраст не находится в линейной связи с доходом. Ранний возраст может иметь плоский доход, близкий к нулю, потому что дети или молодые люди не работают. Затем оно увеличивается в трудоспособном возрасте и уменьшается при выходе на пенсию. Обычно это фигура с перевернутой буквой U Один из способов уловить этот паттерн — прибавить степень два к регрессии.
Посмотрим, повысит ли это точность.
Вам необходимо добавить эту новую функцию в набор данных и в список непрерывных функций.
Вы добавляете новую переменную в набор данных train и test, чтобы было удобнее написать функцию.
def square_var(df_t, df_te, var_name = 'age'):
df_t['new'] = df_t[var_name].pow(2)
df_te['new'] = df_te[var_name].pow(2)
return df_t, df_te
Функция имеет 3 аргумента:
- df_t: определить тренировочный набор
- df_te: определить тестовый набор
- var_name = ‘age’: определить переменную для преобразования
Вы можете использовать объект pow (2) для возведения в квадрат переменной возраста. Обратите внимание, что новая переменная называется «новая»
Теперь, когда написана функция square_var, вы можете создавать новые наборы данных.
df_train_new, df_test_new = square_var(df_train, df_test, var_name = 'age')
Как вы можете видеть, новый набор данных имеет еще одну особенность.
print(df_train_new.shape, df_test_new.shape) (32561, 16) (16281, 16)
Квадратная переменная называется новой в наборе данных. Вам необходимо добавить его в список непрерывных функций.
CONTI_FEATURES_NEW = ['age', 'fnlwgt','capital_gain', 'education_num', 'capital_loss', 'hours_week', 'new'] continuous_features_new = [tf.feature_column.numeric_column(k) for k in CONTI_FEATURES_NEW]
Обратите внимание, что вы изменили каталог Graph. Вы не можете тренировать разные модели в одном каталоге. Это означает, что вам нужно изменить путь аргумента model_dir. Если вы этого не сделаете, TensorFlow выдаст ошибку.
model_1 = tf.estimator.LinearClassifier(
model_dir="ongoing/train1",
feature_columns=categorical_features+ continuous_features_new)
INFO:tensorflow:Using default config.
INFO:tensorflow:Using config: {'_model_dir': 'ongoing/train1', '_tf_random_seed': None, '_save_summary_steps': 100, '_save_checkpoints_steps': None, '_save_checkpoints_secs': 600, '_session_config': None, '_keep_checkpoint_max': 5, '_keep_checkpoint_every_n_hours': 10000, '_log_step_count_steps': 100, '_train_distribute': None, '_service': None, '_cluster_spec':
<tensorflow.python.training.server_lib.ClusterSpec object at 0x1820f04b70>, '_task_type': 'worker', '_task_id': 0, '_global_id_in_cluster': 0, '_master': '', '_evaluation_master': '', '_is_chief': True, '_num_ps_replicas': 0, '_num_worker_replicas': 1}
FEATURES_NEW = ['age','workclass', 'fnlwgt', 'education', 'education_num', 'marital', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_week', 'native_country', 'new']
def get_input_fn(data_set, num_epochs=None, n_batch = 128, shuffle=True):
return tf.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({k: data_set[k].values for k in FEATURES_NEW}),
y = pd.Series(data_set[LABEL].values),
batch_size=n_batch,
num_epochs=num_epochs,
shuffle=shuffle)
Теперь, когда классификатор разработан с использованием нового набора данных, вы можете обучать и оценивать модель.
model_1.train(input_fn=get_input_fn(df_train,
num_epochs=None,
n_batch = 128,
shuffle=False),
steps=1000)
INFO:tensorflow:Calling model_fn. INFO:tensorflow:Done calling model_fn. INFO:tensorflow:Create CheckpointSaverHook. INFO:tensorflow:Graph was finalized. INFO:tensorflow:Running local_init_op. INFO:tensorflow:Done running local_init_op. INFO:tensorflow:Saving checkpoints for 1 into ongoing/train1/model.ckpt. INFO:tensorflow:loss = 88.722855, step = 1 INFO:tensorflow:global_step/sec: 81.487 INFO:tensorflow:loss = 70077.66, step = 101 (1.228 sec) INFO:tensorflow:global_step/sec: 111.169 INFO:tensorflow:loss = 49522.082, step = 201 (0.899 sec) INFO:tensorflow:global_step/sec: 128.91 INFO:tensorflow:loss = 107120.57, step = 301 (0.776 sec) INFO:tensorflow:global_step/sec: 132.546 INFO:tensorflow:loss = 12814.152, step = 401 (0.755 sec) INFO:tensorflow:global_step/sec: 162.194 INFO:tensorflow:loss = 19573.898, step = 501 (0.617 sec) INFO:tensorflow:global_step/sec: 204.852 INFO:tensorflow:loss = 26381.986, step = 601 (0.488 sec) INFO:tensorflow:global_step/sec: 188.923 INFO:tensorflow:loss = 23417.719, step = 701 (0.529 sec) INFO:tensorflow:global_step/sec: 192.041 INFO:tensorflow:loss = 23946.049, step = 801 (0.521 sec) INFO:tensorflow:global_step/sec: 197.025 INFO:tensorflow:loss = 3309.5786, step = 901 (0.507 sec) INFO:tensorflow:Saving checkpoints for 1000 into ongoing/train1/model.ckpt. INFO:tensorflow:Loss for final step: 28861.898. <tensorflow.python.estimator.canned.linear.LinearClassifier at 0x1820f04c88>
model_1.evaluate(input_fn=get_input_fn(df_test_new,
num_epochs=1,
n_batch = 128,
shuffle=False),
steps=1000)
INFO:tensorflow:Calling model_fn.
WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead.
WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead.
INFO:tensorflow:Done calling model_fn.
INFO:tensorflow:Starting evaluation at 2018-06-02-08:28:37
INFO:tensorflow:Graph was finalized.
INFO:tensorflow:Restoring parameters from ongoing/train1/model.ckpt-1000
INFO:tensorflow:Running local_init_op.
INFO:tensorflow:Done running local_init_op.
INFO:tensorflow:Evaluation [100/1000]
INFO:tensorflow:Finished evaluation at 2018-06-02-08:28:39
INFO:tensorflow:Saving dict for global step 1000: accuracy = 0.7944229, accuracy_baseline = 0.76377374, auc = 0.6093755, auc_precision_recall = 0.54885805, average_loss = 111.0046, global_step = 1000, label/mean = 0.23622628, loss = 14119.265, precision = 0.6682401, prediction/mean = 0.09116262, recall = 0.2576703
{'accuracy': 0.7944229,
'accuracy_baseline': 0.76377374,
'auc': 0.6093755,
'auc_precision_recall': 0.54885805,
'average_loss': 111.0046,
'global_step': 1000,
'label/mean': 0.23622628,
'loss': 14119.265,
'precision': 0.6682401,
'prediction/mean': 0.09116262,
'recall': 0.2576703}
Переменная в квадрате улучшила точность с 0,76 до 0,79. Давайте посмотрим, сможете ли вы добиться большего успеха, объединив термин «бакетизация» и термин «взаимодействие».
Бакетизация и взаимодействие
Как вы видели ранее, линейный классификатор не может правильно отразить структуру возраста и дохода. Это потому, что он изучает один вес для каждой функции. Чтобы упростить работу классификатора, вы можете использовать одну из функций. Группировка преобразует числовую функцию в несколько определенных в зависимости от диапазона, в который она попадает, и каждая из этих новых функций указывает, попадает ли возраст человека в этот диапазон.
Благодаря этим новым функциям линейная модель может фиксировать отношения, изучая различные веса для каждого сегмента.
В TensorFlow это делается с помощью bucketized_column. Вам нужно добавить диапазон значений в границы.
age = tf.feature_column.numeric_column('age')
age_buckets = tf.feature_column.bucketized_column(
age, boundaries=[18, 25, 30, 35, 40, 45, 50, 55, 60, 65])
Вы уже знаете, что возраст нелинейен с доходом. Еще один способ улучшить модель — это взаимодействие. По словам TensorFlow, это пересечение функций. Пересечение объектов — это способ создания новых объектов, представляющих собой комбинации существующих, которые могут быть полезны для линейного классификатора, который не может моделировать взаимодействия между объектами.
Вы можете разбить возраст с другой функцией, такой как образование. То есть, некоторые группы могут иметь высокий доход, а другие — низкий (подумайте о докторанте).
education_x_occupation = [tf.feature_column.crossed_column(
['education', 'occupation'], hash_bucket_size=1000)]
age_buckets_x_education_x_occupation = [tf.feature_column.crossed_column(
[age_buckets, 'education', 'occupation'], hash_bucket_size=1000)]
Чтобы создать столбец с перекрестными объектами, вы используете перекрещенный столбец с переменными, чтобы пересечь скобку. Hash_bucket_size указывает максимальные возможности пересечения. Чтобы создать взаимодействие между переменными (по крайней мере, одна переменная должна быть категориальной), вы можете использовать tf.feature_column.crossed_column. Чтобы использовать этот объект, вам нужно добавить в квадратную скобку переменную для взаимодействия и второй аргумент, размер корзины. Размер сегмента — это максимально возможное количество групп в переменной. Здесь вы устанавливаете его на 1000, так как вы не знаете точное количество групп
age_buckets должен быть в квадрате, прежде чем добавить его в столбцы объектов. Вы также добавляете новые функции в столбцы функций и подготавливаете оценку
base_columns = [
age_buckets,
]
model_imp = tf.estimator.LinearClassifier(
model_dir="ongoing/train3",
feature_columns=categorical_features+base_columns+education_x_occupation+age_buckets_x_education_x_occupation)
ВЫВОД
INFO:tensorflow:Using default config.
INFO:tensorflow:Using config: {'_model_dir': 'ongoing/train3', '_tf_random_seed': None, '_save_summary_steps': 100, '_save_checkpoints_steps': None, '_save_checkpoints_secs': 600, '_session_config': None, '_keep_checkpoint_max': 5, '_keep_checkpoint_every_n_hours': 10000, '_log_step_count_steps': 100, '_train_distribute': None, '_service': None, '_cluster_spec': <tensorflow.python.training.server_lib.ClusterSpec object at 0x1823021be0>, '_task_type': 'worker', '_task_id': 0, '_global_id_in_cluster': 0, '_master': '', '_evaluation_master': '', '_is_chief': True, '_num_ps_replicas': 0, '_num_worker_replicas': 1}
FEATURES_imp = ['age','workclass', 'education', 'education_num', 'marital',
'occupation', 'relationship', 'race', 'sex', 'native_country', 'new']
def get_input_fn(data_set, num_epochs=None, n_batch = 128, shuffle=True):
return tf.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({k: data_set[k].values for k in FEATURES_imp}),
y = pd.Series(data_set[LABEL].values),
batch_size=n_batch,
num_epochs=num_epochs,
shuffle=shuffle)
Вы готовы оценить новую модель и посмотреть, повысит ли она точность.
model_imp.train(input_fn=get_input_fn(df_train_new,
num_epochs=None,
n_batch = 128,
shuffle=False),
steps=1000)
INFO:tensorflow:Calling model_fn. INFO:tensorflow:Done calling model_fn. INFO:tensorflow:Create CheckpointSaverHook. INFO:tensorflow:Graph was finalized. INFO:tensorflow:Running local_init_op. INFO:tensorflow:Done running local_init_op. INFO:tensorflow:Saving checkpoints for 1 into ongoing/train3/model.ckpt. INFO:tensorflow:loss = 88.722855, step = 1 INFO:tensorflow:global_step/sec: 94.969 INFO:tensorflow:loss = 50.334488, step = 101 (1.054 sec) INFO:tensorflow:global_step/sec: 242.342 INFO:tensorflow:loss = 56.153225, step = 201 (0.414 sec) INFO:tensorflow:global_step/sec: 213.686 INFO:tensorflow:loss = 45.792007, step = 301 (0.470 sec) INFO:tensorflow:global_step/sec: 174.084 INFO:tensorflow:loss = 37.485672, step = 401 (0.572 sec) INFO:tensorflow:global_step/sec: 191.78 INFO:tensorflow:loss = 56.48449, step = 501 (0.524 sec) INFO:tensorflow:global_step/sec: 163.436 INFO:tensorflow:loss = 32.528934, step = 601 (0.612 sec) INFO:tensorflow:global_step/sec: 164.347 INFO:tensorflow:loss = 37.438057, step = 701 (0.607 sec) INFO:tensorflow:global_step/sec: 154.274 INFO:tensorflow:loss = 61.1075, step = 801 (0.647 sec) INFO:tensorflow:global_step/sec: 189.14 INFO:tensorflow:loss = 44.69645, step = 901 (0.531 sec) INFO:tensorflow:Saving checkpoints for 1000 into ongoing/train3/model.ckpt. INFO:tensorflow:Loss for final step: 44.18133. <tensorflow.python.estimator.canned.linear.LinearClassifier at 0x1823021cf8>
model_imp.evaluate(input_fn=get_input_fn(df_test_new,
num_epochs=1,
n_batch = 128,
shuffle=False),
steps=1000)
INFO:tensorflow:Calling model_fn.
WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead.
WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead.
INFO:tensorflow:Done calling model_fn.
INFO:tensorflow:Starting evaluation at 2018-06-02-08:28:52
INFO:tensorflow:Graph was finalized.
INFO:tensorflow:Restoring parameters from ongoing/train3/model.ckpt-1000
INFO:tensorflow:Running local_init_op.
INFO:tensorflow:Done running local_init_op.
INFO:tensorflow:Evaluation [100/1000]
INFO:tensorflow:Finished evaluation at 2018-06-02-08:28:54
INFO:tensorflow:Saving dict for global step 1000: accuracy = 0.8358209, accuracy_baseline = 0.76377374, auc = 0.88401634, auc_precision_recall = 0.69599575, average_loss = 0.35122654, global_step = 1000, label/mean = 0.23622628, loss = 44.67437, precision = 0.68986726, prediction/mean = 0.23320661, recall = 0.55408216
{'accuracy': 0.8358209,
'accuracy_baseline': 0.76377374,
'auc': 0.88401634,
'auc_precision_recall': 0.69599575,
'average_loss': 0.35122654,
'global_step': 1000,
'label/mean': 0.23622628,
'loss': 44.67437,
'precision': 0.68986726,
'prediction/mean': 0.23320661,
'recall': 0.55408216}
Новый уровень точности составляет 83,58 процента. Это на четыре процента выше, чем у предыдущей модели.
Наконец, вы можете добавить термин регуляризации, чтобы избежать переобучения.
Шаг 5) Гиперпараметр: лассо и хребет
Ваша модель может пострадать от переобучения или underfitting .
- Переоснащение: модель не может обобщить прогноз на новые данные
- Недостаточное оснащение: модель не может захватить структуру данных. т.е. линейная регрессия, когда данные нелинейны
Когда модель имеет много параметров и относительно небольшое количество данных, это приводит к плохим прогнозам. Представьте себе, у одной группы есть только три наблюдения; модель рассчитает вес для этой группы. Вес используется, чтобы сделать прогноз; если наблюдения за тестовым набором для этой конкретной группы полностью отличаются от обучающего набора, то модель сделает неправильный прогноз. Во время оценки с обучающим набором точность хорошая, но не хорошая с тестовым набором, потому что вычисленные веса не являются правильными для обобщения модели. В этом случае он не делает разумного прогноза по невидимым данным.
Чтобы предотвратить переоснащение, регуляризация дает вам возможность управлять такой сложностью и делать ее более обобщенной. Есть два метода регуляризации:
- L1: Лассо
- L2: Хребет
В TensorFlow вы можете добавить эти два гиперпараметра в оптимизаторе. Например, чем выше гиперпараметр L2, вес имеет тенденцию быть очень низким и близким к нулю. Соответствующая линия будет очень плоской, в то время как L2, близкий к нулю, подразумевает, что веса близки к регулярной линейной регрессии.
Вы можете сами попробовать другое значение гиперпараметров и посмотреть, сможете ли вы повысить уровень точности.
Обратите внимание, что если вы измените гиперпараметр, вам нужно удалить папку продолжается / train4, иначе модель запустится с ранее обученной моделью.
Давайте посмотрим, как это точность с обманом
model_regu = tf.estimator.LinearClassifier(
model_dir="ongoing/train4", feature_columns=categorical_features+base_columns+education_x_occupation+age_buckets_x_education_x_occupation,
optimizer=tf.train.FtrlOptimizer(
learning_rate=0.1,
l1_regularization_strength=0.9,
l2_regularization_strength=5))
Ouput
INFO:tensorflow:Using default config.
INFO:tensorflow:Using config: {'_model_dir': 'ongoing/train4', '_tf_random_seed': None, '_save_summary_steps': 100, '_save_checkpoints_steps': None, '_save_checkpoints_secs': 600, '_session_config': None, '_keep_checkpoint_max': 5, '_keep_checkpoint_every_n_hours': 10000, '_log_step_count_steps': 100, '_train_distribute': None, '_service': None, '_cluster_spec': <tensorflow.python.training.server_lib.ClusterSpec object at 0x1820d9c128>, '_task_type': 'worker', '_task_id': 0, '_global_id_in_cluster': 0, '_master': '', '_evaluation_master': '', '_is_chief': True, '_num_ps_replicas': 0, '_num_worker_replicas': 1}
model_regu.train(input_fn=get_input_fn(df_train_new,
num_epochs=None,
n_batch = 128,
shuffle=False),
steps=1000)
Ouput
INFO:tensorflow:Calling model_fn. INFO:tensorflow:Done calling model_fn. INFO:tensorflow:Create CheckpointSaverHook. INFO:tensorflow:Graph was finalized. INFO:tensorflow:Running local_init_op. INFO:tensorflow:Done running local_init_op. INFO:tensorflow:Saving checkpoints for 1 into ongoing/train4/model.ckpt. INFO:tensorflow:loss = 88.722855, step = 1 INFO:tensorflow:global_step/sec: 77.4165 INFO:tensorflow:loss = 50.38778, step = 101 (1.294 sec) INFO:tensorflow:global_step/sec: 187.889 INFO:tensorflow:loss = 55.38014, step = 201 (0.535 sec) INFO:tensorflow:global_step/sec: 201.895 INFO:tensorflow:loss = 46.806694, step = 301 (0.491 sec) INFO:tensorflow:global_step/sec: 217.992 INFO:tensorflow:loss = 38.68271, step = 401 (0.460 sec) INFO:tensorflow:global_step/sec: 193.676 INFO:tensorflow:loss = 56.99398, step = 501 (0.516 sec) INFO:tensorflow:global_step/sec: 202.195 INFO:tensorflow:loss = 33.263622, step = 601 (0.497 sec) INFO:tensorflow:global_step/sec: 216.756 INFO:tensorflow:loss = 37.7902, step = 701 (0.459 sec) INFO:tensorflow:global_step/sec: 240.215 INFO:tensorflow:loss = 61.732605, step = 801 (0.416 sec) INFO:tensorflow:global_step/sec: 220.336 INFO:tensorflow:loss = 46.938225, step = 901 (0.456 sec) INFO:tensorflow:Saving checkpoints for 1000 into ongoing/train4/model.ckpt. INFO:tensorflow:Loss for final step: 43.4942. <tensorflow.python.estimator.canned.linear.LinearClassifier at 0x181ff39e48>
model_regu.evaluate(input_fn=get_input_fn(df_test_new,
num_epochs=1,
n_batch = 128,
shuffle=False),
steps=1000)
ВЫВОД
INFO:tensorflow:Calling model_fn.
WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead.
WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead.
INFO:tensorflow:Done calling model_fn.
INFO:tensorflow:Starting evaluation at 2018-06-02-08:29:07
INFO:tensorflow:Graph was finalized.
INFO:tensorflow:Restoring parameters from ongoing/train4/model.ckpt-1000
INFO:tensorflow:Running local_init_op.
INFO:tensorflow:Done running local_init_op.
INFO:tensorflow:Evaluation [100/1000]
INFO:tensorflow:Finished evaluation at 2018-06-02-08:29:09
INFO:tensorflow:Saving dict for global step 1000: accuracy = 0.83833915, accuracy_baseline = 0.76377374, auc = 0.8869794, auc_precision_recall = 0.7014905, average_loss = 0.34691378, global_step = 1000, label/mean = 0.23622628, loss = 44.12581, precision = 0.69720596, prediction/mean = 0.23662092, recall = 0.5579823
{'accuracy': 0.83833915,
'accuracy_baseline': 0.76377374,
'auc': 0.8869794,
'auc_precision_recall': 0.7014905,
'average_loss': 0.34691378,
'global_step': 1000,
'label/mean': 0.23622628,
'loss': 44.12581,
'precision': 0.69720596,
'prediction/mean': 0.23662092,
'recall': 0.5579823}
С этим гиперпараметром вы немного увеличите метрики точности. В следующем уроке вы узнаете, как улучшить линейный классификатор с помощью метода ядра.
Резюме
Чтобы обучить модель, вам необходимо:
- Определите функции: Независимые переменные: X
- Определите метку: зависимая переменная: y
- Построить поезд / испытательный комплекс
- Определите начальный вес
- Определить функцию потерь: MSE
- Оптимизация модели: градиентный спуск
- Определение:
- Скорость обучения
- Количество эпох
- Размер партии
- Номер класса
В этом руководстве вы узнали, как использовать API высокого уровня для классификатора линейной регрессии. Вам необходимо определить:
- Особые столбцы. Если непрерывно: tf.feature_column.numeric_column (). Вы можете заполнить список с пониманием списка Python
- Оценщик: tf.estimator.LinearClassifier (feature_columns, model_dir, n_classes = 2)
- Функция для импорта данных, размера пакета и эпохи: input_fn ()
После этого вы готовы тренироваться, оценивать и делать прогнозы с помощью train (), оценивать () и прогнозировать ()
Для повышения производительности модели вы можете:
- Используйте полиномиальную регрессию
- Термин взаимодействия: tf.feature_column.crossed_column
- Добавить параметр регуляризации