Цель этого урока — сделать набор данных линейно разделимым. Учебник разделен на две части:
- Преобразование функций
- Обучите классификатор ядра с помощью Tensorflow
В первой части вы поймете идею, лежащую в основе классификатора ядра, а во второй части вы увидите, как обучить классификатор ядра с помощью Tensorflow. Вы будете использовать набор данных для взрослых. Цель этого набора данных — классифицировать доход ниже и выше 50 тыс., Зная поведение каждого домохозяйства.
В этом уроке вы узнаете
- Зачем вам нужны методы ядра?
- Что такое ядро в машинном обучении?
- Тип методов ядра
- Обучите классификатор ядра Гаусса с помощью TensorFlow
Зачем вам нужны методы ядра?
Цель каждого классификатора — правильно прогнозировать классы. Для этого набор данных должен быть отделимым. Посмотрите на сюжет ниже; довольно просто увидеть, что все точки над черной линией принадлежат первому классу, а другие — второму классу. Тем не менее, очень редко иметь такой простой набор данных. В большинстве случаев данные неразделимы. Это дает наивным классификаторам, таким как логистическая регрессия, трудное время.
import numpy as np import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D
x_lin = np.array([1,2,3,4,5,6,7,8,9,10]) y_lin = np.array([2,2,3,2,2,9,6,8,8,9]) label_lin = np.array([0,0,0,0,0,1,1,1,1,1]) fig = plt.figure() ax=fig.add_subplot(111) plt.scatter(x_lin, y_lin, c=label_lin, s=60) plt.plot([-2.5, 10], [12.5, -2.5], 'k-', lw=2) ax.set_xlim([-5,15]) ax.set_ylim([-5,15])plt.show()
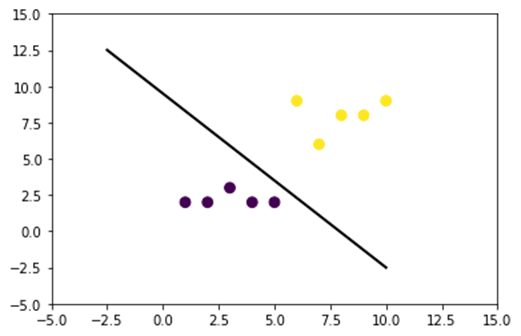
На рисунке ниже мы строим набор данных, который не является линейно разделимым. Если мы нарисуем прямую линию, большинство точек не будут классифицированы в правильном классе.
Один из способов решения этой проблемы — взять набор данных и преобразовать данные в другую карту объектов. Это означает, что вы будете использовать функцию для преобразования данных в другой план, который должен быть линейным.
x = np.array([1,1,2,3,3,6,6,6,9,9,10,11,12,13,16,18]) y = np.array([18,13,9,6,15,11,6,3,5,2,10,5,6,1,3,1]) label = np.array([1,1,1,1,0,0,0,1,0,1,0,0,0,1,0,1])
fig = plt.figure() plt.scatter(x, y, c=label, s=60) plt.show()
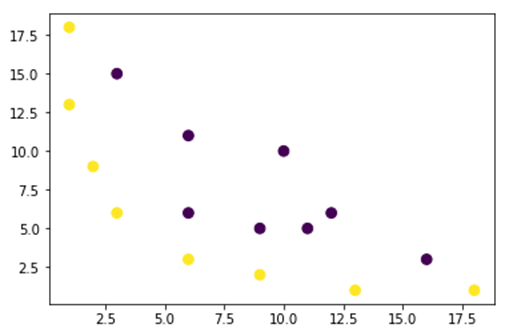
Данные из рисунка выше представлены в двухмерном плане, который не может быть разделен. Вы можете попытаться преобразовать эти данные в трехмерном, это означает, что вы создаете фигуру с 3 осями.
В нашем примере мы применим полиномиальное отображение, чтобы привести наши данные в трехмерное измерение. Формула для преобразования данных выглядит следующим образом.
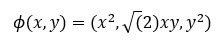
Вы определяете функцию в Python для создания новых карт объектов
Вы можете использовать numpy для кодирования приведенной выше формулы:
| формула | Эквивалентный код Numpy |
| Икс | х [:, 0] ** |
| Y | х [: 1] |
| х 2 | х [: 0] ** 2 |
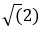 |
np.sqrt (2) * |
| ху | х [: 0] * х [: 1] |
| у 2 | х [: 1] ** 2 |
### illustration purpose
def mapping(x, y):
x = np.c_[(x, y)]
if len(x) > 2:
x_1 = x[:,0]**2
x_2 = np.sqrt(2)*x[:,0]*x[:,1]
x_3 = x[:,1]**2
else:
x_1 = x[0]**2
x_2 = np.sqrt(2)*x[0]*x[1]
x_3 = x[1]**2
trans_x = np.array([x_1, x_2, x_3])
return trans_x
Новое отображение должно быть с 3 измерениями с 16 точками
x_1 = mapping(x, y) x_1.shape
(3, 16)
Давайте создадим новый график с 3 осями, x, y и z соответственно.
# plot
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.scatter(x_1[0], x_1[1], x_1[2], c=label, s=60)
ax.view_init(30, 185)ax.set_xlabel('X Label')
ax.set_ylabel('Y Label')
ax.set_zlabel('Z Label')
plt.show()
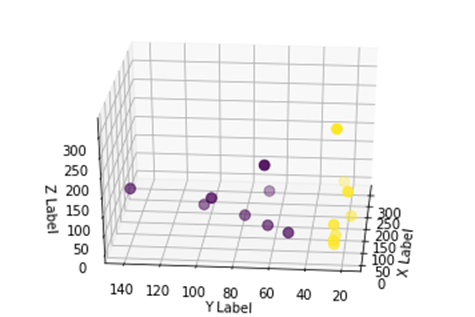
Мы видим улучшение, но если мы изменим ориентацию графика, ясно, что набор данных теперь разделим
# plot
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.scatter(x_1[0], x_1[1], x_1[1], c=label, s=60)
ax.view_init(0, -180)ax.set_ylim([150,-50])
ax.set_zlim([-10000,10000])
ax.set_xlabel('X Label')
ax.set_ylabel('Y Label')
ax.set_zlabel('Z Label')plt.show()
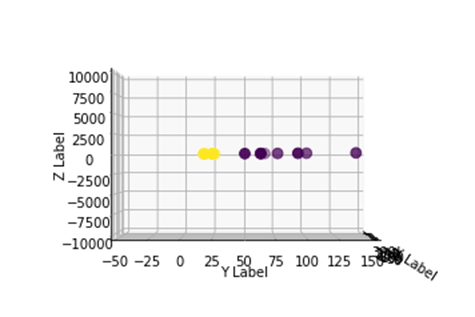
Чтобы манипулировать большим набором данных, и вам может потребоваться создать более двух измерений, вы столкнетесь с большой проблемой, используя описанный выше метод. На самом деле вам необходимо преобразовать все точки данных, что явно не является устойчивым. Это займет у вас много времени, и вашему компьютеру может не хватить памяти.
Наиболее распространенный способ преодолеть эту проблему — использовать ядро .
Что такое ядро в машинном обучении?
Идея состоит в том, чтобы использовать пространство признаков более высокой размерности, чтобы сделать данные почти линейно разделяемыми, как показано на рисунке выше.
Существует множество пространств с более высокой размерностью, чтобы сделать точки данных разделимыми. Например, мы показали, что полиномиальное отображение — отличное начало.
Мы также продемонстрировали, что при большом количестве данных это преобразование неэффективно. Вместо этого вы можете использовать функцию ядра для изменения данных без перехода на новый тарифный план.
Магия ядра заключается в том, чтобы найти функцию, которая позволяет избежать всех проблем, связанных с многомерными вычислениями. Результатом ядра является скаляр или, иначе говоря, мы вернулись в одномерное пространство
После того, как вы нашли эту функцию, вы можете подключить ее к стандартному линейному классификатору.
Давайте рассмотрим пример, чтобы понять концепцию ядра. У вас есть два вектора, х1 и х2. Цель состоит в том, чтобы создать более высокое измерение с использованием полиномиального отображения. Результат равен точечному произведению новой карты объектов. Из вышеописанного метода вам необходимо:
- Преобразуйте x1 и x2 в новое измерение
- Вычислить скалярное произведение: общее для всех ядер
- Преобразуйте x1 и x2 в новое измерение
Вы можете использовать созданную выше функцию для вычисления более высокого измерения.
## Kernel x1 = np.array([3,6]) x2 = np.array([10,10]) x_1 = mapping(x1, x2) print(x_1)
Вывод
[[ 9. 100. ]
[ 25.45584412 141.42135624]
[ 36. 100. ]]
Вычислить скалярное произведение
Вы можете использовать точку объекта из numpy, чтобы вычислить произведение точек между первым и вторым вектором, хранящимся в x_1.
print(np.dot(x_1[:,0], x_1[:,1])) 8100.0
Выходное значение равно 8100. Вы видите проблему, вам нужно сохранить в памяти новую карту объектов для вычисления точечного произведения. Если у вас есть набор данных с миллионами записей, он неэффективен в вычислительном отношении.
Вместо этого вы можете использовать ядро полинома для вычисления точечного произведения без преобразования вектора. Эта функция вычисляет произведение точек x1 и x2, как если бы эти два вектора были преобразованы в более высокое измерение. Иными словами, функция ядра вычисляет результаты скалярного произведения из другого пространства функций.
Вы можете написать функцию ядра полинома в Python следующим образом.
def polynomial_kernel(x, y, p=2): return (np.dot(x, y)) ** p
Это сила точечного произведения двух векторов. Ниже вы возвращаете вторую степень ядра полинома. Выход равен другому методу. Это магия ядра.
polynomial_kernel(x1, x2, p=2) 8100
Тип методов ядра
Доступно много разных ядер. Самое простое — это линейное ядро. Эта функция работает очень хорошо для классификации текста. Другое ядро:
- Полиномиальное ядро
- Гауссово ядро
В примере с TensorFlow мы будем использовать Случайный Фурье. TensorFlow имеет встроенную систему оценки для вычисления пространства новых функций. Эта функция является приближением функции ядра Гаусса.
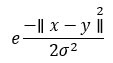
Эта функция вычисляет сходство между точками данных в пространстве гораздо более высокого измерения.
Обучите классификатор ядра Гаусса с помощью TensorFlow
Целью алгоритма является классификация доходов домохозяйств более или менее 50 тыс.
Вы оцените логистическую регрессию, чтобы иметь эталонную модель. После этого вы будете обучать классификатор ядра, чтобы увидеть, сможете ли вы добиться лучших результатов.
Вы используете следующие переменные из набора данных для взрослых:
- возраст
- workclass
- fnlwgt
- education
- education_num
- marital
- occupation
- relationship
- race
- sex
- capital_gain
- capital_loss
- hours_week
- native_country
- label
You will proceed as follow before you train and evaluate the model:
- Step 1) Import the libraries
- Step 2) Import the data
- Step 3) Prepare the data
- Step 4) Construct the input_fn
- Step 5) Construct the logistic model: Baseline model
- Step 6) Evaluate the model
- Step 7) Construct the Kernel classifier
- Step 8) Evaluate the Kernel classifier
Step 1) Import the libraries
To import and train the model, you need to import tensorflow, pandas and numpy
#import numpy as np from sklearn.model_selection import train_test_split import tensorflow as tf import pandas as pd import numpy as np
Step 2) Import the data
You download the data from the following website and you import it as a panda dataframe.
## Define path data COLUMNS = ['age','workclass', 'fnlwgt', 'education', 'education_num', 'marital', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_week', 'native_country', 'label'] PATH = "https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data" PATH_test ="https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.test "## Import df_train = pd.read_csv(PATH, skipinitialspace=True, names = COLUMNS, index_col=False) df_test = pd.read_csv(PATH_test,skiprows = 1, skipinitialspace=True, names = COLUMNS, index_col=False)
Now that the train and test set are defined, you can change the column label from string to integer. tensorflow does not accept string value for the label.
label = {'<=50K': 0,'>50K': 1}
df_train.label = [label[item] for item in df_train.label]
label_t = {'<=50K.': 0,'>50K.': 1}
df_test.label = [label_t[item] for item in df_test.label]
df_train.shape
(32561, 15)
Step 3) Prepare the data
The dataset contains both continuous and categorical features. A good practice is to standardize the values of the continuous variables. You can use the function StandardScaler from sci-kit learn. You create a user-defined function as well to make it easier to convert the train and test set. Note that, you concatenate the continuous and categorical variables to a common dataset and the array should be of the type: float32
COLUMNS_INT = ['age','fnlwgt','education_num','capital_gain', 'capital_loss', 'hours_week']
CATE_FEATURES = ['workclass', 'education', 'marital', 'occupation', 'relationship', 'race', 'sex', 'native_country']
from sklearn.preprocessing import StandardScaler
from sklearn import preprocessing
def prep_data_str(df):
scaler = StandardScaler()
le = preprocessing.LabelEncoder()
df_toscale = df[COLUMNS_INT]
df_scaled = scaler.fit_transform(df_toscale.astype(np.float64))
X_1 = df[CATE_FEATURES].apply(le.fit_transform)
y = df['label'].astype(np.int32)
X_conc = np.c_[df_scaled, X_1].astype(np.float32)
return X_conc, y
The transformer function is ready, you can convert the dataset and create the input_fn function.
X_train, y_train = prep_data_str(df_train) X_test, y_test = prep_data_str(df_test) print(X_train.shape) (32561, 14)
In the next step, you will train a logistic regression. It will give you a baseline accuracy. The objective is to beat the baseline with a different algorithm, namely a Kernel classifier.
Шаг 4) Построить логистическую модель: базовая модель
Вы создаете столбец объекта с помощью объекта real_valued_column. Это гарантирует, что все переменные являются плотными числовыми данными.
feat_column = tf.contrib.layers.real_valued_column('features', dimension=14)
Оценщик определяется с помощью Оценщика TensorFlow, вы указываете столбцы объектов и где сохранять график.
estimator = tf.estimator.LinearClassifier(feature_columns=[feat_column],
n_classes=2,
model_dir = "kernel_log"
)
INFO:tensorflow:Using default config.INFO:tensorflow:Using config: {'_model_dir': 'kernel_log', '_tf_random_seed': None, '_save_summary_steps': 100, '_save_checkpoints_steps': None, '_save_checkpoints_secs': 600, '_session_config': None, '_keep_checkpoint_max': 5, '_keep_checkpoint_every_n_hours': 10000, '_log_step_count_steps': 100, '_train_distribute': None, '_service': None, '_cluster_spec': <tensorflow.python.training.server_lib.ClusterSpec object at 0x1a2003f780>, '_task_type': 'worker', '_task_id': 0, '_global_id_in_cluster': 0, '_master': '', '_evaluation_master': '', '_is_chief': True, '_num_ps_replicas': 0, '_num_worker_replicas': 1}
Вы будете тренировать логистическую регрессию, используя мини-партии размером 200.
# Train the model
train_input_fn = tf.estimator.inputs.numpy_input_fn(
x={"features": X_train},
y=y_train,
batch_size=200,
num_epochs=None,
shuffle=True)
Вы можете обучить модель с 1000 итераций
estimator.train(input_fn=train_input_fn, steps=1000)
INFO:tensorflow:Calling model_fn. INFO:tensorflow:Done calling model_fn. INFO:tensorflow:Create CheckpointSaverHook. INFO:tensorflow:Graph was finalized. INFO:tensorflow:Running local_init_op. INFO:tensorflow:Done running local_init_op. INFO:tensorflow:Saving checkpoints for 1 into kernel_log/model.ckpt. INFO:tensorflow:loss = 138.62949, step = 1 INFO:tensorflow:global_step/sec: 324.16 INFO:tensorflow:loss = 87.16762, step = 101 (0.310 sec) INFO:tensorflow:global_step/sec: 267.092 INFO:tensorflow:loss = 71.53657, step = 201 (0.376 sec) INFO:tensorflow:global_step/sec: 292.679 INFO:tensorflow:loss = 69.56703, step = 301 (0.340 sec) INFO:tensorflow:global_step/sec: 225.582 INFO:tensorflow:loss = 74.615875, step = 401 (0.445 sec) INFO:tensorflow:global_step/sec: 209.975 INFO:tensorflow:loss = 76.49044, step = 501 (0.475 sec) INFO:tensorflow:global_step/sec: 241.648 INFO:tensorflow:loss = 66.38373, step = 601 (0.419 sec) INFO:tensorflow:global_step/sec: 305.193 INFO:tensorflow:loss = 87.93341, step = 701 (0.327 sec) INFO:tensorflow:global_step/sec: 396.295 INFO:tensorflow:loss = 76.61518, step = 801 (0.249 sec) INFO:tensorflow:global_step/sec: 359.857 INFO:tensorflow:loss = 78.54885, step = 901 (0.277 sec) INFO:tensorflow:Saving checkpoints for 1000 into kernel_log/model.ckpt. INFO:tensorflow:Loss for final step: 67.79706. <tensorflow.python.estimator.canned.linear.LinearClassifier at 0x1a1fa3cbe0>
Шаг 6) Оцените модель
Вы определяете оценку NumPy для оценки модели. Вы используете весь набор данных для оценки
# Evaluation
test_input_fn = tf.estimator.inputs.numpy_input_fn(
x={"features": X_test},
y=y_test,
batch_size=16281,
num_epochs=1,
shuffle=False)
estimator.evaluate(input_fn=test_input_fn, steps=1)
INFO:tensorflow:Calling model_fn. WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead. WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead. INFO:tensorflow:Done calling model_fn. INFO:tensorflow:Starting evaluation at 2018-07-12-15:58:22 INFO:tensorflow:Graph was finalized. INFO:tensorflow:Restoring parameters from kernel_log/model.ckpt-1000 INFO:tensorflow:Running local_init_op. INFO:tensorflow:Done running local_init_op. INFO:tensorflow:Evaluation [1/1] INFO:tensorflow:Finished evaluation at 2018-07-12-15:58:23 INFO:tensorflow:Saving dict for global step 1000: accuracy = 0.82353663, accuracy_baseline = 0.76377374, auc = 0.84898686, auc_precision_recall = 0.67214864, average_loss = 0.3877216, global_step = 1000, label/mean = 0.23622628, loss = 6312.495, precision = 0.7362797, prediction/mean = 0.21208474, recall = 0.39417577
{'accuracy': 0.82353663,
'accuracy_baseline': 0.76377374,
'auc': 0.84898686,
'auc_precision_recall': 0.67214864,
'average_loss': 0.3877216,
'global_step': 1000,
'label/mean': 0.23622628,
'loss': 6312.495,
'precision': 0.7362797,
'prediction/mean': 0.21208474,
'recall': 0.39417577}
У вас точность 82 процента. В следующем разделе вы попытаетесь превзойти логистический классификатор с помощью классификатора ядра.
Шаг 7) Построить классификатор ядра
Оценка ядра не так сильно отличается от традиционного линейного классификатора, по крайней мере, с точки зрения построения. Идея заключается в том, чтобы использовать возможности явного ядра с линейным классификатором.
Для обучения классификатора ядра вам понадобятся два предварительно определенных оценщика, доступных в TensorFlow:
- RandomFourierFeatureMapper
- KernelLinearClassifier
В первом разделе вы узнали, что вам нужно преобразовать низкое измерение в высокое, используя функцию ядра. Точнее, вы будете использовать Случайный Фурье, который является приближением функции Гаусса. К счастью, Tensorflow имеет функцию в своей библиотеке: RandomFourierFeatureMapper. Модель может быть обучена с использованием оценщика KernelLinearClassifier.
Чтобы построить модель, вы выполните следующие действия:
- Установите функцию ядра высокой размерности
- Установить гиперпараметр L2
- Построить модель
- Тренируй модель
- Оценить модель
Шаг А) Установите функцию ядра высокой размерности
Текущий набор данных содержит 14 объектов, которые вы преобразуете в новый большой размер 5000-мерного вектора. Вы используете случайные функции Фурье для достижения преобразования. Если вы вспомните формулу ядра Гаусса, вы заметите, что для определения есть параметр стандартного отклонения. Этот параметр управляет мерой сходства, используемой во время классификации.
Вы можете настроить все параметры в RandomFourierFeatureMapper с помощью:
- input_dim = 14
- output_dim = 5000
- StdDev = 4
### Prep Kernel kernel_mapper = tf.contrib.kernel_methods.RandomFourierFeatureMapper(input_dim=14, output_dim=5000, stddev=4, name='rffm')
Вам необходимо создать модуль отображения ядра, используя ранее созданные столбцы функций: feat_column
### Map Kernel
kernel_mappers = {feat_column: [kernel_mapper]}
Шаг Б) Установите гиперпараметр L2
Чтобы предотвратить переоснащение, вы штрафуете функцию потерь с регуляризатором L2. Вы устанавливаете гиперпараметр L2 на 0,1, а скорость обучения на 5
optimizer = tf.train.FtrlOptimizer(learning_rate=5, l2_regularization_strength=0.1)
Шаг С) Построить модель
Следующий шаг похож на линейную классификацию. Вы используете встроенный оценщик KernelLinearClassifier. Обратите внимание, что вы добавили определитель ядра, определенный ранее, и изменили каталог модели.
### Prep estimator
estimator_kernel = tf.contrib.kernel_methods.KernelLinearClassifier(
n_classes=2,
optimizer=optimizer,
kernel_mappers=kernel_mappers,
model_dir="kernel_train")
WARNING:tensorflow:From /Users/Thomas/anaconda3/envs/hello-tf/lib/python3.6/site-packages/tensorflow/contrib/kernel_methods/python/kernel_estimators.py:305: multi_class_head (from tensorflow.contrib.learn.python.learn.estimators.head) is deprecated and will be removed in a future version.
Instructions for updating:
Please switch to tf.contrib.estimator.*_head.
WARNING:tensorflow:From /Users/Thomas/anaconda3/envs/hello-tf/lib/python3.6/site-packages/tensorflow/contrib/learn/python/learn/estimators/estimator.py:1179: BaseEstimator.__init__ (from tensorflow.contrib.learn.python.learn.estimators.estimator) is deprecated and will be removed in a future version.
Instructions for updating:
Please replace uses of any Estimator from tf.contrib.learn with an Estimator from tf.estimator.*
WARNING:tensorflow:From /Users/Thomas/anaconda3/envs/hello-tf/lib/python3.6/site-packages/tensorflow/contrib/learn/python/learn/estimators/estimator.py:427: RunConfig.__init__ (from tensorflow.contrib.learn.python.learn.estimators.run_config) is deprecated and will be removed in a future version.
Instructions for updating:
When switching to tf.estimator.Estimator, use tf.estimator.RunConfig instead.
INFO:tensorflow:Using default config.
INFO:tensorflow:Using config: {'_task_type': None, '_task_id': 0, '_cluster_spec': <tensorflow.python.training.server_lib.ClusterSpec object at 0x1a200ae550>, '_master': '', '_num_ps_replicas': 0, '_num_worker_replicas': 0, '_environment': 'local', '_is_chief': True, '_evaluation_master': '', '_train_distribute': None, '_tf_config': gpu_options {
per_process_gpu_memory_fraction: 1.0
}
, '_tf_random_seed': None, '_save_summary_steps': 100, '_save_checkpoints_secs': 600, '_log_step_count_steps': 100, '_session_config': None, '_save_checkpoints_steps': None, '_keep_checkpoint_max': 5, '_keep_checkpoint_every_n_hours': 10000, '_model_dir': 'kernel_train'}
Шаг D) Обучаем модель
Теперь, когда классификатор Kernel создан, вы готовы обучать его. Вы решили повторить модель 2000 раз
### estimate estimator_kernel.fit(input_fn=train_input_fn, steps=2000)
WARNING:tensorflow:Casting <dtype: 'int32'> labels to bool.
WARNING:tensorflow:Casting <dtype: 'int32'> labels to bool.
WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead.
WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead.
WARNING:tensorflow:From /Users/Thomas/anaconda3/envs/hello-tf/lib/python3.6/site-packages/tensorflow/contrib/learn/python/learn/estimators/head.py:678: ModelFnOps.__new__ (from tensorflow.contrib.learn.python.learn.estimators.model_fn) is deprecated and will be removed in a future version.
Instructions for updating:
When switching to tf.estimator.Estimator, use tf.estimator.EstimatorSpec. You can use the `estimator_spec` method to create an equivalent one.
INFO:tensorflow:Create CheckpointSaverHook.
INFO:tensorflow:Graph was finalized.
INFO:tensorflow:Running local_init_op.
INFO:tensorflow:Done running local_init_op.
INFO:tensorflow:Saving checkpoints for 1 into kernel_train/model.ckpt.
INFO:tensorflow:loss = 0.6931474, step = 1
INFO:tensorflow:global_step/sec: 86.6365
INFO:tensorflow:loss = 0.39374447, step = 101 (1.155 sec)
INFO:tensorflow:global_step/sec: 80.1986
INFO:tensorflow:loss = 0.3797774, step = 201 (1.247 sec)
INFO:tensorflow:global_step/sec: 79.6376
INFO:tensorflow:loss = 0.3908726, step = 301 (1.256 sec)
INFO:tensorflow:global_step/sec: 95.8442
INFO:tensorflow:loss = 0.41890752, step = 401 (1.043 sec)
INFO:tensorflow:global_step/sec: 93.7799
INFO:tensorflow:loss = 0.35700393, step = 501 (1.066 sec)
INFO:tensorflow:global_step/sec: 94.7071
INFO:tensorflow:loss = 0.35535482, step = 601 (1.056 sec)
INFO:tensorflow:global_step/sec: 90.7402
INFO:tensorflow:loss = 0.3692882, step = 701 (1.102 sec)
INFO:tensorflow:global_step/sec: 94.4924
INFO:tensorflow:loss = 0.34746957, step = 801 (1.058 sec)
INFO:tensorflow:global_step/sec: 95.3472
INFO:tensorflow:loss = 0.33655524, step = 901 (1.049 sec)
INFO:tensorflow:global_step/sec: 97.2928
INFO:tensorflow:loss = 0.35966292, step = 1001 (1.028 sec)
INFO:tensorflow:global_step/sec: 85.6761
INFO:tensorflow:loss = 0.31254214, step = 1101 (1.167 sec)
INFO:tensorflow:global_step/sec: 91.4194
INFO:tensorflow:loss = 0.33247527, step = 1201 (1.094 sec)
INFO:tensorflow:global_step/sec: 82.5954
INFO:tensorflow:loss = 0.29305756, step = 1301 (1.211 sec)
INFO:tensorflow:global_step/sec: 89.8748
INFO:tensorflow:loss = 0.37943482, step = 1401 (1.113 sec)
INFO:tensorflow:global_step/sec: 76.9761
INFO:tensorflow:loss = 0.34204718, step = 1501 (1.300 sec)
INFO:tensorflow:global_step/sec: 73.7192
INFO:tensorflow:loss = 0.34614792, step = 1601 (1.356 sec)
INFO:tensorflow:global_step/sec: 83.0573
INFO:tensorflow:loss = 0.38911164, step = 1701 (1.204 sec)
INFO:tensorflow:global_step/sec: 71.7029
INFO:tensorflow:loss = 0.35255936, step = 1801 (1.394 sec)
INFO:tensorflow:global_step/sec: 73.2663
INFO:tensorflow:loss = 0.31130585, step = 1901 (1.365 sec)
INFO:tensorflow:Saving checkpoints for 2000 into kernel_train/model.ckpt.
INFO:tensorflow:Loss for final step: 0.37795097.
KernelLinearClassifier(params={'head': <tensorflow.contrib.learn.python.learn.estimators.head._BinaryLogisticHead object at 0x1a2054cd30>, 'feature_columns': {_RealValuedColumn(column_name='features_MAPPED', dimension=5000, default_value=None, dtype=tf.float32, normalizer=None)}, 'optimizer': <tensorflow.python.training.ftrl.FtrlOptimizer object at 0x1a200aec18>, 'kernel_mappers': {_RealValuedColumn(column_name='features', dimension=14, default_value=None, dtype=tf.float32, normalizer=None): [<tensorflow.contrib.kernel_methods.python.mappers.random_fourier_features.RandomFourierFeatureMapper object at 0x1a200ae400>]}})
Шаг Е) Оценить модель
И последнее, но не менее важное: вы оцениваете производительность своей модели. Вы должны быть в состоянии победить логистическую регрессию.
# Evaluate and report metrics. eval_metrics = estimator_kernel.evaluate(input_fn=test_input_fn, steps=1)
WARNING:tensorflow:Casting <dtype: 'int32'> labels to bool. WARNING:tensorflow:Casting <dtype: 'int32'> labels to bool. WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead. WARNING:tensorflow:Trapezoidal rule is known to produce incorrect PR-AUCs; please switch to "careful_interpolation" instead. INFO:tensorflow:Starting evaluation at 2018-07-12-15:58:50 INFO:tensorflow:Graph was finalized. INFO:tensorflow:Restoring parameters from kernel_train/model.ckpt-2000 INFO:tensorflow:Running local_init_op. INFO:tensorflow:Done running local_init_op. INFO:tensorflow:Evaluation [1/1] INFO:tensorflow:Finished evaluation at 2018-07-12-15:58:51 INFO:tensorflow:Saving dict for global step 2000: accuracy = 0.83975184, accuracy/baseline_label_mean = 0.23622628, accuracy/threshold_0.500000_mean = 0.83975184, auc = 0.8904007, auc_precision_recall = 0.72722375, global_step = 2000, labels/actual_label_mean = 0.23622628, labels/prediction_mean = 0.23786618, loss = 0.34277728, precision/positive_threshold_0.500000_mean = 0.73001117, recall/positive_threshold_0.500000_mean = 0.5104004
Окончательная точность составляет 84%, это улучшение на 2% по сравнению с логистической регрессией. Существует компромисс между повышением точности и вычислительными затратами. Вам нужно подумать, стоит ли улучшение в 2% времени, затрачиваемого другим классификатором, и оказывает ли это существенное влияние на ваш бизнес.
Резюме
Ядро — отличный инструмент для преобразования нелинейных данных в (почти) линейные. Недостатком этого метода является то, что он требует больших затрат времени и средств.
Ниже вы можете найти самый важный код для обучения классификатора ядра
Установите функцию ядра высокой размерности
- input_dim = 14
- output_dim = 5000
- StdDev = 4
### Prep Kernelkernel_mapper = tf.contrib.kernel_methods.RandomFourierFeatureMapper(input_dim=14, output_dim=5000, stddev=4, name='rffm')
Установить гиперпараметр L2
optimizer = tf.train.FtrlOptimizer(learning_rate=5, l2_regularization_strength=0.1)
Построить модель
estimator_kernel = tf.contrib.kernel_methods.KernelLinearClassifier( n_classes=2,
optimizer=optimizer,
kernel_mappers=kernel_mappers,
model_dir="kernel_train")
Тренируй модель
estimator_kernel.fit(input_fn=train_input_fn, steps=2000)
Оценить модель
eval_metrics = estimator_kernel.evaluate(input_fn=test_input_fn, steps=1)