Что такое панды?
Pandas — это библиотека с открытым исходным кодом, позволяющая вам манипулировать данными в Python. Библиотека Pandas построена поверх Numpy, а это значит, что Pandas для работы нужен Numpy. Панды предоставляют простой способ создавать, обрабатывать и обрабатывать данные. Pandas также является элегантным решением для данных временных рядов.
В этом руководстве вы узнаете:
- Что такое панды?
- Зачем использовать панды?
- Как установить панды?
- Что такое фрейм данных?
- Что такое серия?
- Создать фрейм данных
- Диапазон данных
- Проверка данных
- Данные среза
- Оставить столбец
- конкатенация
Зачем использовать панды?
Исследователи данных используют Pandas для следующих преимуществ:
- Легко обрабатывает недостающие данные
- Он использует Series для одномерной структуры данных и DataFrame для многомерной структуры данных
- Это обеспечивает эффективный способ нарезки данных
- Он предоставляет гибкий способ объединения, объединения или изменения формы данных.
- Он включает в себя мощный инструмент для работы с временными рядами
В двух словах, Pandas — полезная библиотека для анализа данных. Может использоваться для обработки и анализа данных. Pandas предоставляют мощные и простые в использовании структуры данных, а также средства для быстрого выполнения операций над этими структурами.
Как установить панды?
Чтобы установить библиотеку Pandas, пожалуйста, обратитесь к нашему руководству Как установить TensorFlow . Панды установлены по умолчанию. В удаленном случае, панды не установлены
Вы можете установить Pandas используя:
- Анаконда: Конда установить -c Анаконда Панды
- В ноутбуке Jupyter:
import sys
!conda install --yes --prefix {sys.prefix} pandas
Что такое фрейм данных?
Фрейм данных — это двумерный массив с помеченными осями (строки и столбцы). Фрейм данных — это стандартный способ хранения данных.
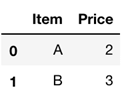
Фрейм данных хорошо известен специалистам по статистике и другим специалистам. Фрейм данных — это табличные данные со строками для хранения информации и столбцами для присвоения информации. Например, цена может быть именем столбца и 2,3,4 значениями цены.
Ниже изображение фрейма данных Pandas:
Что такое серия?
Серия — это одномерная структура данных. Он может иметь любую структуру данных, например, integer, float и string. Это полезно, когда вы хотите выполнить вычисление или вернуть одномерный массив. Ряд по определению не может иметь несколько столбцов. В последнем случае, пожалуйста, используйте структуру фрейма данных.
Серия имеет один параметр:
- Данные: может быть списком, словарем или скалярным значением
pd.Series([1., 2., 3.])
0 1.0 1 2.0 2 3.0 dtype: float64
Вы можете добавить индекс с индексом. Это помогает назвать строки. Длина должна быть равна размеру столбца
pd.Series([1., 2., 3.], index=['a', 'b', 'c'])
Ниже вы создаете серию Pandas с отсутствующим значением для третьих строк. Обратите внимание, что пропущенные значения в Python помечены как «NaN». Вы можете использовать numpy для создания недостающего значения: np.nan искусственно
pd.Series([1,2,np.nan])
Вывод
0 1.0 1 2.0 2 NaN dtype: float64
Создать фрейм данных
Вы можете преобразовать пустой массив во фрейм данных pandas с помощью pd.Data frame (). Возможно и обратное. Чтобы преобразовать фрейм данных pandas в массив, вы можете использовать np.array ()
## Numpy to pandas
import numpy as np
h = [[1,2],[3,4]]
df_h = pd.DataFrame(h)
print('Data Frame:', df_h)
## Pandas to numpy
df_h_n = np.array(df_h)
print('Numpy array:', df_h_n)
Data Frame: 0 1
0 1 2
1 3 4
Numpy array: [[1 2]
[3 4]]
Вы также можете использовать словарь для создания фрейма данных Pandas.
dic = {'Name': ["John", "Smith"], 'Age': [30, 40]}
pd.DataFrame(data=dic)
| Возраст | имя | |
| 0 | 30 | Джон |
| 1 | 40 | кузнец |
Диапазон данных
Панды имеют удобный API для создания диапазона дат
pd.data_range (дата, период, частота):
- Первый параметр — дата начала
- Второй параметр — это число периодов (необязательно, если указана дата окончания)
- Последний параметр — это частота: день: «D», месяц: «M» и год: «Y».
## Create date
# Days
dates_d = pd.date_range('20300101', periods=6, freq='D')
print('Day:', dates_d)
Вывод
Day: DatetimeIndex(['2030-01-01', '2030-01-02', '2030-01-03', '2030-01-04', '2030-01-05', '2030-01-06'], dtype='datetime64[ns]', freq='D')
# Months
dates_m = pd.date_range('20300101', periods=6, freq='M')
print('Month:', dates_m)
Вывод
Month: DatetimeIndex(['2030-01-31', '2030-02-28', '2030-03-31', '2030-04-30','2030-05-31', '2030-06-30'], dtype='datetime64[ns]', freq='M')
Проверка данных
Вы можете проверить заголовок или хвост набора данных с помощью head () или tail (), которому предшествует имя фрейма данных панды
Шаг 1) Создайте случайную последовательность с NumPy. Последовательность имеет 4 столбца и 6 строк
random = np.random.randn(6,4)
Шаг 2) Затем вы создаете фрейм данных, используя панд.
Используйте date_m в качестве индекса для фрейма данных. Это означает, что каждой строке будет присвоено «имя» или индекс, соответствующий дате.
Наконец, вы даете имя 4 столбцам с аргументами столбцов
# Create data with date
df = pd.DataFrame(random,
index=dates_m,
columns=list('ABCD'))
Шаг 3) Использование функции головы
df.head(3)
| A | В | С | D | |
| 2030-01-31 | 1.139433 | 1.318510 | -0,181334 | 1.615822 |
| 2030-02-28 | -0,081995 | -0,063582 | 0.857751 | -0,527374 |
| 2030-03-31 | -0,519179 | 0.080984 | -1,454334 | 1.314947 |
Шаг 4) Использование функции хвоста
df.tail(3)
| A | В | С | D | |
| 2030-04-30 | -0,685448 | -0,011736 | 0.622172 | 0.104993 |
| 2030-05-31 | -0,935888 | -0,731787 | -0,558729 | 0.768774 |
| 2030-06-30 | 1.096981 | 0.949180 | -0,196901 | -0,471556 |
Шаг 5) Отличная практика, чтобы получить представление о данных, — это использовать description (). Он обеспечивает количество, среднее, стандартное, минимальное, максимальное и процентиль набора данных.
df.describe()
| A | В | С | D | |
| подсчитывать | 6.000000 | 6.000000 | 6.000000 | 6.000000 |
| жадный | 0.002317 | 0.256928 | -0,151896 | 0.467601 |
| станд | 0.908145 | 0.746939 | 0.834664 | 0.908910 |
| мин | -0,935888 | -0,731787 | -1,454334 | -0,527374 |
| 25% | -0,643880 | -0,050621 | -0,468272 | -0,327419 |
| 50% | -0,300587 | 0.034624 | -0,189118 | 0.436883 |
| 75% | 0.802237 | 0.732131 | 0.421296 | 1.178404 |
| Максимум | 1.139433 | 1.318510 | 0.857751 | 1.615822 |
Данные среза
Последний пункт этого урока о том, как нарезать фрейм данных Pandas.
Вы можете использовать имя столбца для извлечения данных в определенном столбце.
## Slice ### Using name df['A'] 2030-01-31 -0.168655 2030-02-28 0.689585 2030-03-31 0.767534 2030-04-30 0.557299 2030-05-31 -1.547836 2030-06-30 0.511551 Freq: M, Name: A, dtype: float64
Чтобы выбрать несколько столбцов, вам нужно использовать двойную скобку, [[.., ..]]
Первая пара скобок означает, что вы хотите выбрать столбцы, вторая пара скобок указывает, какие столбцы вы хотите вернуть.
df[['A', 'B']].
| A | В | |
| 2030-01-31 | -0,168655 | 0.587590 |
| 2030-02-28 | 0.689585 | 0.998266 |
| 2030-03-31 | 0.767534 | -0,940617 |
| 2030-04-30 | 0.557299 | 0.507350 |
| 2030-05-31 | -1,547836 | 1.276558 |
| 2030-06-30 | 0.511551 | 1.572085 |
Вы можете нарезать строки с помощью:
Код ниже возвращает первые три строки
### using a slice for row df[0:3]
| A | В | С | D | |
| 2030-01-31 | -0,168655 | 0.587590 | 0.572301 | -0,031827 |
| 2030-02-28 | 0.689585 | 0.998266 | 1.164690 | 0.475975 |
| 2030-03-31 | 0.767534 | -0,940617 | 0.227255 | -0,341532 |
Функция loc используется для выбора столбцов по именам. Как обычно, значения до комы обозначают строки, а после относятся к столбцу. Вам нужно использовать скобки, чтобы выбрать более одного столбца.
## Multi col df.loc[:,['A','B']]
| A | В | |
| 2030-01-31 | -0,168655 | 0.587590 |
| 2030-02-28 | 0.689585 | 0.998266 |
| 2030-03-31 | 0.767534 | -0,940617 |
| 2030-04-30 | 0.557299 | 0.507350 |
| 2030-05-31 | -1,547836 | 1.276558 |
| 2030-06-30 | 0.511551 | 1.572085 |
Есть еще один способ выбрать несколько строк и столбцов в Pandas. Вы можете использовать iloc []. Этот метод использует индекс вместо имени столбца. Код ниже возвращает тот же кадр данных, что и выше
df.iloc[:, :2]
| A | В | |
| 2030-01-31 | -0,168655 | 0.587590 |
| 2030-02-28 | 0.689585 | 0.998266 |
| 2030-03-31 | 0.767534 | -0,940617 |
| 2030-04-30 | 0.557299 | 0.507350 |
| 2030-05-31 | -1,547836 | 1.276558 |
| 2030-06-30 | 0.511551 | 1.572085 |
Оставить столбец
Вы можете удалить столбцы, используя pd.drop ()
df.drop(columns=['A', 'C'])
| В | D | |
| 2030-01-31 | 0.587590 | -0,031827 |
| 2030-02-28 | 0.998266 | 0.475975 |
| 2030-03-31 | -0,940617 | -0,341532 |
| 2030-04-30 | 0.507350 | -0,296035 |
| 2030-05-31 | 1.276558 | 0.523017 |
| 2030-06-30 | 1.572085 | -0,594772 |
конкатенация
Вы можете объединить два DataFrame в Pandas. Вы можете использовать pd.concat ()
Прежде всего, вам нужно создать два DataFrames. Пока все хорошо, вы уже знакомы с созданием dataframe
import numpy as np
df1 = pd.DataFrame({'name': ['John', 'Smith','Paul'],
'Age': ['25', '30', '50']},
index=[0, 1, 2])
df2 = pd.DataFrame({'name': ['Adam', 'Smith' ],
'Age': ['26', '11']},
index=[3, 4])
Наконец, вы объединяете два DataFrame
df_concat = pd.concat([df1,df2]) df_concat
| Возраст | имя | |
| 0 | 25 | Джон |
| 1 | 30 | кузнец |
| 2 | 50 | Павел |
| 3 | 26 | Адам |
| 4 | 11 | кузнец |
Drop_duplicates
Если набор данных может содержать дубликаты информации, `drop_duplicates` легко исключить дубликаты строк. Вы можете видеть, что `df_concat` имеет дублирующее наблюдение,` Smith` дважды появляется в столбце `name`.
df_concat.drop_duplicates('name')
| Возраст | имя | |
| 0 | 25 | Джон |
| 1 | 30 | кузнец |
| 2 | 50 | Павел |
| 3 | 26 | Адам |
Сортировать значения
Вы можете отсортировать значение с помощью sort_values
df_concat.sort_values('Age')
| Возраст | имя | |
| 4 | 11 | кузнец |
| 0 | 25 | Джон |
| 3 | 26 | Адам |
| 1 | 30 | кузнец |
| 2 | 50 | Павел |
Переименовать: изменение индекса
Вы можете использовать переименование, чтобы переименовать столбец в Pandas. Первое значение — это имя текущего столбца, а второе — имя нового столбца.
df_concat.rename(columns={"name": "Surname", "Age": "Age_ppl"})
| Age_ppl | Фамилия | |
| 0 | 25 | Джон |
| 1 | 30 | кузнец |
| 2 | 50 | Павел |
| 3 | 26 | Адам |
| 4 | 11 | кузнец |
Резюме
Ниже приводится краткое изложение наиболее полезного метода для науки о данных с Pandas
| импортировать данные | read_csv |
| создать серию | Серии |
| Создать Dataframe | DataFrame |
| Создать диапазон дат | диапазон дат |
| вернуть голову | глава |
| возвратный хвост | хвост |
| описывать | описывать |
| срез, используя имя | dataname [ ‘имя_столбец’] |
| Срез с использованием строк | имя_данный [0: 5] |