Что такое автоэнкодер?
Автоэнкодер — отличный инструмент для воссоздания ввода. Одним словом, машина снимает, скажем, изображение и может создавать тесно связанную картину. Вклад в этот тип нейронной сети немечен, что означает, что сеть способна обучаться без присмотра. Точнее, вход кодируется сетью, чтобы сосредоточиться только на наиболее важной функции. Это одна из причин, почему автоэнкодер популярен для уменьшения размерности. Кроме того, автоэнкодеры могут быть использованы для создания генеративных моделей обучения . Например, нейронная сеть может быть обучена с набором граней, а затем может создавать новые лица.
В этом уроке вы узнаете:
- Что такое автоэнкодер?
- Как работает автоэнкодер?
- Пример Stacked Autoencoder
- Создайте автоэнкодер с TensorFlow
- Предварительная обработка изображения
- Оценка набора данных
- Постройте сеть
Как работает автоэнкодер?
Цель автоэнкодера — произвести аппроксимацию входных данных, сосредоточив внимание только на основных функциях. Вы можете подумать, почему бы просто не научиться копировать и вставлять входные данные для создания выходных данных. Фактически, автоэнкодер — это набор ограничений, которые заставляют сеть изучать новые способы представления данных, отличные от простого копирования выходных данных.
Типичный автоэнкодер определяется с помощью ввода, внутреннего представления и вывода (аппроксимация ввода). Обучение происходит в слоях, прикрепленных к внутреннему представлению. На самом деле, есть два основных блока слоев, которые выглядят как традиционная нейронная сеть. Небольшая разница в том, что слой, содержащий выходные данные, должен быть равен входным данным. На рисунке ниже исходный вход переходит в первый блок, называемый кодером . Это внутреннее представление сжимает (уменьшает) размер ввода. Во втором блоке происходит реконструкция ввода. Это фаза декодирования.
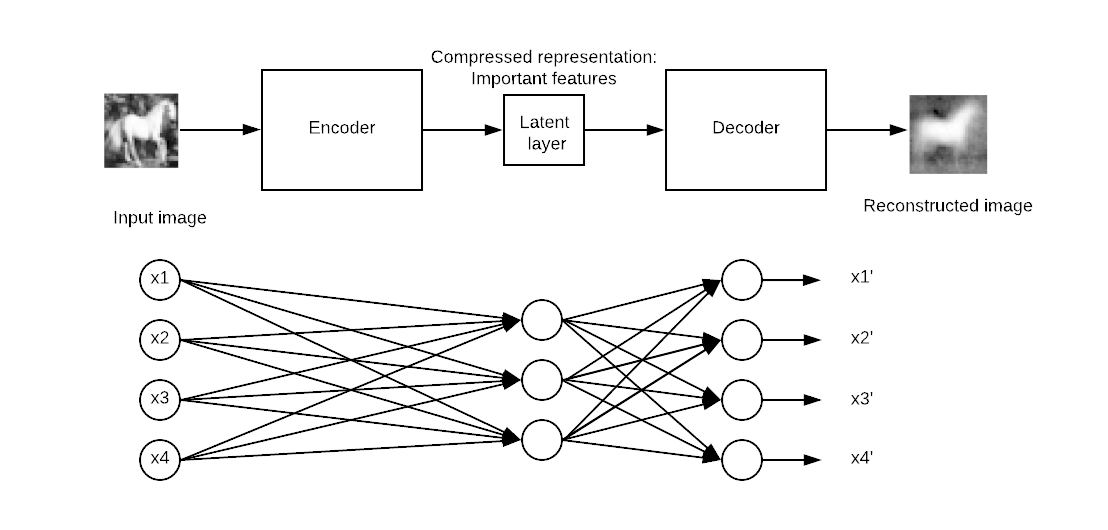
Модель будет обновлять веса путем минимизации функции потерь. Модель оштрафована, если выходные данные реконструкции отличаются от входных данных.
Конкретно, представьте картинку размером 50х50 (то есть 250 пикселей) и нейронную сеть с одним скрытым слоем, состоящим из ста нейронов. Обучение осуществляется на карте объектов, которая в два раза меньше входных данных. Это означает, что сети необходимо найти способ восстановить 250 пикселей только с вектором нейронов, равным 100.
Пример Stacked Autoencoder
В этом уроке вы узнаете, как использовать сложный автоэнкодер. Архитектура похожа на традиционную нейронную сеть. Ввод идет в скрытый слой для сжатия или уменьшения его размера, а затем достигает слоев восстановления. Цель состоит в том, чтобы получить выходное изображение как можно ближе к оригиналу. Модель должна научиться выполнять свою задачу в рамках набора ограничений, то есть с меньшим измерением.
В настоящее время автоэнкодеры в основном используются для шумоподавления изображения. Представьте себе изображение с царапинами; человек все еще может распознать содержание. Идея шумоподавления автоэнкодера состоит в том, чтобы добавить шум к изображению, чтобы заставить сеть изучать схему, лежащую в основе данных.
Другое полезное семейство автоэнкодеров — это вариационные автоэнкодеры. Этот тип сети может генерировать новые изображения. Представьте, что вы тренируете сеть с изображением человека; такая сеть может произвести новые лица.
Создайте автоэнкодер с TensorFlow
В этом уроке вы узнаете, как создать сложный авто-кодер для восстановления изображения.
Вы будете использовать набор данных CIFAR-10, который содержит 60000 цветных изображений 32×32. Набор данных уже разделен между 50000 изображениями для обучения и 10000 для тестирования. Есть до десяти классов:
- самолет
- автомобильный
- птица
- Кошка
- олень
- Собака
- Лягушка
- Horse
- Ship
- Truck
You need download the images in this URL https://www.cs.toronto.edu/~kriz/cifar.html and unzip it. The folder for-10-batches-py contains five batches of data with 10000 images each in a random order.
Before you build and train your model, you need to apply some data processing. You will proceed as follow:
- Import the data
- Convert the data to black and white format
- Append all the batches
- Construct the training dataset
- Construct an image visualizer
Image preprocessing
Step 1) Import the data.
According to the official website, you can upload the data with the following code. The code will load the data in a dictionary with the data and the label. Note that the code is a function.
import numpy as np
import tensorflow as tf
import pickle
def unpickle(file):
import pickle
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='latin1')
return dict
Step 2) Convert the data to black and white format
For simplicity, you will convert the data to a grayscale. That is, with only one dimension against three for colors image. Most of the neural network works only with one dimension input.
def grayscale(im):
return im.reshape(im.shape[0], 3, 32, 32).mean(1).reshape(im.shape[0], -1)
Step 3) Append all the batches
Now that both functions are created and the dataset loaded, you can write a loop to append the data in memory. If you check carefully, the unzip file with the data is named data_batch_ with a number from 1 to 5. You can loop over the files and append it to data.
When this step is done, you convert the colours data to a gray scale format. As you can see, the shape of the data is 50000 and 1024. The 32*32 pixels are now flatten to 2014.
# Load the data into memory
data, labels = [], []
## Loop over the b
for i in range(1, 6):
filename = './cifar-10-batches-py/data_batch_' + str(i)
open_data = unpickle(filename)
if len(data) > 0:
data = np.vstack((data, open_data['data']))
labels = np.hstack((labels, open_data['labels']))
else:
data = open_data['data']
labels = open_data['labels']
data = grayscale(data)
x = np.matrix(data)
y = np.array(labels)
print(x.shape)
(50000, 1024)
Note: Change ‘./cifar-10-batches-py/data_batch_’ to the actual location of your file. For instance for Windows machine, the path could be filename = ‘E:\cifar-10-batches-py\data_batch_’ + str(i)
Step 4) Construct the training dataset
To make the training faster and easier, you will train a model on the horse images only. The horses are the seventh class in the label data. As mentioned in the documentation of the CIFAR-10 dataset, each class contains 5000 images. You can print the shape of the data to confirm there are 5.000 images with 1024 columns.
horse_i = np.where(y == 7)[0] horse_x = x[horse_i] print(np.shape(horse_x)) (5000, 1024)
Step 5) Construct an image visualizer
Наконец, вы создаете функцию для построения изображений. Эта функция понадобится вам для печати восстановленного изображения из автоэнкодера.
Простой способ печати изображений — использовать объект imshow из библиотеки matplotlib. Обратите внимание, что вам нужно преобразовать форму данных из 1024 в 32 * 32 (то есть формат изображения).
# To plot pretty figures
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
def plot_image(image, shape=[32, 32], cmap = "Greys_r"):
plt.imshow(image.reshape(shape), cmap=cmap,interpolation="nearest")
plt.axis("off")
Функция принимает 3 аргумента:
- Изображение: вход
- Форма: список, размерность изображения
- Cmap: выберите карту цветов. По умолчанию серый
Вы можете попробовать построить первое изображение в наборе данных. Вы должны увидеть человека на лошади.
plot_image(horse_x[1], shape=[32, 32], cmap = "Greys_r")

Оценка набора данных
Хорошо, теперь, когда набор данных готов к использованию, вы можете начать использовать Tensorflow. Прежде чем строить модель, давайте использовать оценщик данных из Tensorflow для подачи в сеть.
Вы создадите набор данных с помощью оценщика TensorFlow. Чтобы освежить свой разум, вам нужно использовать:
- from_tensor_slices
- повторение
- партия
Полный код для построения набора данных:
dataset = tf.data.Dataset.from_tensor_slices(x).repeat().batch(batch_size)
Обратите внимание, что x — это заполнитель со следующей формой:
- [Нет, n_inputs]: установите значение «Нет», поскольку число каналов передачи изображений в сеть равно размеру пакета.
подробности см. в руководстве по линейной регрессии.
После этого вам нужно создать итератор. Без этой строки кода никакие данные не будут проходить через конвейер.
iter = dataset.make_initializable_iterator() # create the iteratorfeatures = iter.get_next()
Теперь, когда конвейер готов, вы можете проверить, является ли первое изображение таким же, как раньше (т. Е. Человек на лошади).
Вы устанавливаете размер пакета равным 1, потому что вы хотите передать только один набор данных. Вы можете увидеть размерность данных с помощью print (sess.run (features) .shape). Он равен (1, 1024). 1 означает, что подается только одно изображение с 1024. Если размер пакета установлен на два, то два изображения будут проходить через конвейер. (Не изменяйте размер пакета. В противном случае он выдаст ошибку. Только одно изображение за раз может перейти к функции plot_image ().
## Parameters
n_inputs = 32 * 32
BATCH_SIZE = 1
batch_size = tf.placeholder(tf.int64)
# using a placeholder
x = tf.placeholder(tf.float32, shape=[None,n_inputs])
## Dataset
dataset = tf.data.Dataset.from_tensor_slices(x).repeat().batch(batch_size)
iter = dataset.make_initializable_iterator() # create the iterator
features = iter.get_next()
## Print the image
with tf.Session() as sess:
# feed the placeholder with data
sess.run(iter.initializer, feed_dict={x: horse_x,
batch_size: BATCH_SIZE})
print(sess.run(features).shape)
plot_image(sess.run(features), shape=[32, 32], cmap = "Greys_r")
(1, 1024)

Постройте сеть
Настало время построить сеть. Вы будете обучать сложенный автоэнкодер, то есть сеть с несколькими скрытыми слоями.
Ваша сеть будет иметь один входной слой с 1024 точками, то есть 32×32, форма изображения.
Блок кодера будет иметь один верхний скрытый слой с 300 нейронами, центральный слой с 150 нейронами. Блок декодера симметричен кодеру. Вы можете визуализировать сеть на картинке ниже. Обратите внимание, что вы можете изменить значения скрытого и центрального слоев.
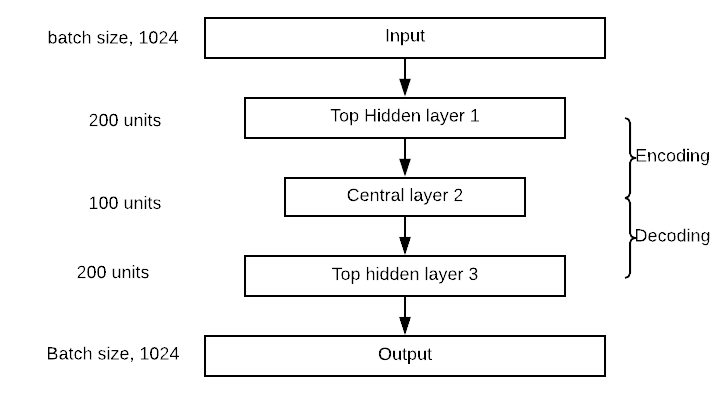
Создание автоэнкодера очень похоже на любую другую модель глубокого обучения.
Вы построите модель, выполнив следующие действия:
- Определите параметры
- Определите слои
- Определить архитектуру
- Определите оптимизацию
- Запустить модель
- Оценить модель
В предыдущем разделе вы узнали, как создать конвейер для подачи модели, поэтому нет необходимости еще раз создавать набор данных. Вы построите автоэнкодер с четырьмя слоями. Вы используете инициализацию Xavier. Это методика установки начальных весов, равных дисперсии входных и выходных данных. Наконец, вы используете функцию активации elu. Вы регуляризируете функцию потерь с помощью регулятора L2.
Шаг 1) Определите параметры
Первый шаг предполагает определение количества нейронов в каждом слое, скорости обучения и гиперпараметра регуляризатора.
Перед этим вы импортируете функцию частично. Это лучший метод для определения параметров плотных слоев. Код ниже определяет значения архитектуры автоэнкодера. Как указано выше, автоэнкодер имеет два слоя, с 300 нейронами в первых слоях и 150 во вторых слоях. Их значения хранятся в n_hidden_1 и n_hidden_2.
Вам необходимо определить скорость обучения и гиперпараметр L2. Значения хранятся в learning_rate и l2_reg
from functools import partial ## Encoder n_hidden_1 = 300 n_hidden_2 = 150 # codings ## Decoder n_hidden_3 = n_hidden_1 n_outputs = n_inputs learning_rate = 0.01 l2_reg = 0.0001
Техника инициализации Xavier вызывается с объектом xavier_initializer из вклада оценщика. В том же оценщике вы можете добавить регуляризатор с помощью l2_regularizer
## Define the Xavier initialization xav_init = tf.contrib.layers.xavier_initializer() ## Define the L2 regularizer l2_regularizer = tf.contrib.layers.l2_regularizer(l2_reg)
Шаг 2) Определите слои
Все параметры плотных слоев установлены; Вы можете упаковать все в переменную dens_layer, используя частичный объект. density_layer, который использует активацию ELU, инициализацию Xavier и регуляризацию L2.
## Create the dense layer
dense_layer = partial(tf.layers.dense,
activation=tf.nn.elu,
kernel_initializer=xav_init,
kernel_regularizer=l2_regularizer)
Шаг 3) Определите архитектуру
Если вы посмотрите на картину архитектуры, вы заметите, что сеть складывает три слоя с выходным слоем. В приведенном ниже коде вы подключаете соответствующие слои. Например, первый слой вычисляет точечное произведение между входными матричными элементами и матрицами, содержащими 300 весов. После вычисления точечного произведения выход переходит к функции активации Elu. Выходные данные становятся входными данными следующего слоя, поэтому вы используете его для вычисления hidden_2 и так далее. Умножение матриц одинаково для каждого слоя, потому что вы используете одну и ту же функцию активации. Обратите внимание, что последний уровень, выходы, не применяет функцию активации. Это имеет смысл, потому что это восстановленный вход
## Make the mat mul hidden_1 = dense_layer(features, n_hidden_1) hidden_2 = dense_layer(hidden_1, n_hidden_2) hidden_3 = dense_layer(hidden_2, n_hidden_3) outputs = dense_layer(hidden_3, n_outputs, activation=None)
Шаг 4) Определите оптимизацию
Последний шаг заключается в создании оптимизатора. Вы используете среднеквадратическую ошибку в качестве функции потерь. Если вы вспомните учебник по линейной регрессии, вы знаете, что MSE рассчитывается с разницей между прогнозируемым выходным значением и реальной меткой. Здесь метка — это особенность, потому что модель пытается восстановить входные данные. Следовательно, вы хотите получить среднее значение суммы разности квадрата между прогнозируемым выходным значением и входным значением. С TensorFlow вы можете кодировать функцию потерь следующим образом:
loss = tf.reduce_mean(tf.square(outputs - features))
Затем вам нужно оптимизировать функцию потерь. Вы используете оптимизатор Adam для вычисления градиентов. Задача состоит в том, чтобы минимизировать потери.
## Optimize loss = tf.reduce_mean(tf.square(outputs - features)) optimizer = tf.train.AdamOptimizer(learning_rate) train = optimizer.minimize(loss)
Еще одна настройка перед тренировкой модели. Вы хотите использовать размер пакета 150, то есть загружать в конвейер 150 изображений в каждой итерации. Вам нужно вычислить количество итераций вручную. Это тривиально сделать:
Если вы хотите передать 150 изображений каждый раз и знаете, что в наборе данных 5000 изображений, число итераций равно. В python вы можете запустить следующие коды и убедиться, что результат равен 33:
BATCH_SIZE = 150 ### Number of batches : length dataset / batch size n_batches = horse_x.shape[0] // BATCH_SIZE print(n_batches) 33
Шаг 5) Запустите модель
И последнее, но не менее важное: тренируйте модель. Вы тренируете модель со 100 эпохами. То есть модель будет в 100 раз видеть изображения до оптимизированных весов.
Вы уже знакомы с кодами для обучения модели в Tensorflow. Небольшая разница заключается в передаче данных перед запуском тренировки. Таким образом, модель тренируется быстрее.
Вы заинтересованы в том, чтобы напечатать потерю после десяти эпох, чтобы увидеть, изучает ли модель что-то (т.е. потеря уменьшается). Обучение занимает от 2 до 5 минут, в зависимости от аппаратного обеспечения вашего компьютера.
## Set params
n_epochs = 100
## Call Saver to save the model and re-use it later during evaluation
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
# initialise iterator with train data
sess.run(iter.initializer, feed_dict={x: horse_x,
batch_size: BATCH_SIZE})
print('Training...')
print(sess.run(features).shape)
for epoch in range(n_epochs):
for iteration in range(n_batches):
sess.run(train)
if epoch % 10 == 0:
loss_train = loss.eval() # not shown
print("\r{}".format(epoch), "Train MSE:", loss_train)
#saver.save(sess, "./my_model_all_layers.ckpt")
save_path = saver.save(sess, "./model.ckpt")
print("Model saved in path: %s" % save_path)
Training...
(150, 1024)
0 Train MSE: 2934.455
10 Train MSE: 1672.676
20 Train MSE: 1514.709
30 Train MSE: 1404.3118
40 Train MSE: 1425.058
50 Train MSE: 1479.0631
60 Train MSE: 1609.5259
70 Train MSE: 1482.3223
80 Train MSE: 1445.7035
90 Train MSE: 1453.8597
Model saved in path: ./model.ckpt
Шаг 6) Оцените модель
Теперь, когда вы обучили свою модель, пришло время ее оценить. Вам необходимо импортировать тестовый файл из файла / cifar-10-batches-py /.
test_data = unpickle('./cifar-10-batches-py/test_batch')
test_x = grayscale(test_data['data'])
#test_labels = np.array(test_data['labels'])
ПРИМЕЧАНИЕ. Для компьютера с Windows код становится test_data = unpickle (r «E: \ cifar-10-batches-py \ test_batch»)
Вы можете попробовать распечатать изображения 13, который является лошадью
plot_image(test_x[13], shape=[32, 32], cmap = "Greys_r")

To evaluate the model, you will use the pixel value of this image and see if the encoder can reconstruct the same image after shrinking 1024 pixels. Note that, you define a function to evaluate the model on different pictures. The model should work better only on horses.
The function takes two arguments:
- df: Import the test data
- image_number: indicate what image to import
The function is divided into three parts:
- Reshape the image to the correct dimension i.e 1, 1024
- Feed the model with the unseen image, encode/decode the image
- Print the real and reconstructed image
def reconstruct_image(df, image_number = 1):
## Part 1: Reshape the image to the correct dimension i.e 1, 1024
x_test = df[image_number]
x_test_1 = x_test.reshape((1, 32*32))
## Part 2: Feed the model with the unseen image, encode/decode the image
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
sess.run(iter.initializer, feed_dict={x: x_test_1,
batch_size: 1})
## Part 3: Print the real and reconstructed image
# Restore variables from disk.
saver.restore(sess, "./model.ckpt")
print("Model restored.")
# Reconstruct image
outputs_val = outputs.eval()
print(outputs_val.shape)
fig = plt.figure()
# Plot real
ax1 = fig.add_subplot(121)
plot_image(x_test_1, shape=[32, 32], cmap = "Greys_r")
# Plot estimated
ax2 = fig.add_subplot(122)
plot_image(outputs_val, shape=[32, 32], cmap = "Greys_r")
plt.tight_layout()
fig = plt.gcf()
Теперь, когда функция оценки определена, вы можете взглянуть на восстановленное изображение с номером тринадцать
reconstruct_image(df =test_x, image_number = 13)
INFO:tensorflow:Restoring parameters from ./model.ckpt Model restored. (1, 1024)

Резюме
Основная цель автоэнкодера состоит в том, чтобы сжать входные данные, а затем распаковать их в выходные данные, которые очень похожи на исходные данные.
Архитектура автоэнкодера симметрична с центральным слоем, называемым центральным слоем.
Вы можете создать автоэнкодер используя:
- Частично: создать плотные слои с типичной настройкой:
-
tf.layers.dense, activation=tf.nn.elu, kernel_initializer=xav_init, kernel_regularizer=l2_regularizer
- dens_layer (): сделать умножение матрицы
Вы можете определить функцию потерь и оптимизацию с помощью:
loss = tf.reduce_mean(tf.square(outputs - features)) optimizer = tf.train.AdamOptimizer(learning_rate) train = optimizer.minimize(loss)
Последний сеанс для тренировки модели.