Что такое ETL?
ETL — это процесс, который извлекает данные из разных исходных систем, затем преобразует их (например, применяет вычисления, объединения и т. Д.) И, наконец, загружает данные в систему хранилища данных. Полная форма ETL — Извлечение, Преобразование и Загрузка.
Соблазнительно думать, что создание хранилища данных — это просто извлечение данных из нескольких источников и загрузка в базу данных хранилища данных. Это далеко от истины и требует сложного процесса ETL. Процесс ETL требует активного участия различных заинтересованных сторон, включая разработчиков, аналитиков, тестировщиков, руководителей и технически сложен.
Чтобы сохранить свою ценность в качестве инструмента для лиц, принимающих решения, система хранилищ данных должна меняться с изменениями в бизнесе. ETL — это периодическое действие (ежедневно, еженедельно, ежемесячно) системы хранилища данных, которое должно быть гибким, автоматизированным и хорошо документированным.
В этом уроке вы узнаете
- Что такое ETL?
- Зачем вам ETL?
- Процесс ETL в хранилищах данных
- Шаг 1) Извлечение
- Шаг 2) Преобразование
- Шаг 3) Загрузка
- Инструменты ETL
- Лучшие практики ETL процесса
Зачем вам ETL?
Есть много причин для принятия ETL в организации:
- Это помогает компаниям анализировать свои бизнес-данные для принятия важных бизнес-решений.
- Транзакционные базы данных не могут ответить на сложные бизнес-вопросы, на которые может ответить ETL.
- Хранилище данных предоставляет общий репозиторий данных
- ETL предоставляет метод перемещения данных из различных источников в хранилище данных.
- При изменении источников данных хранилище данных будет автоматически обновляться.
- Хорошо разработанная и документированная система ETL практически необходима для успеха проекта хранилища данных.
- Разрешить проверку правил преобразования, агрегирования и расчета данных.
- Процесс ETL позволяет сравнивать выборочные данные между исходной и целевой системами.
- Процесс ETL может выполнять сложные преобразования и требует дополнительной области для хранения данных.
- ETL помогает переносить данные в хранилище данных. Преобразование в различные форматы и типы, чтобы придерживаться одной последовательной системы.
- ETL — это предопределенный процесс для доступа к исходным данным и управления ими в целевой базе данных.
- ETL предлагает глубокий исторический контекст для бизнеса.
- Это помогает повысить производительность, поскольку кодирует и повторно использует без необходимости технических навыков.
Процесс ETL в хранилищах данных
ETL — это трехэтапный процесс
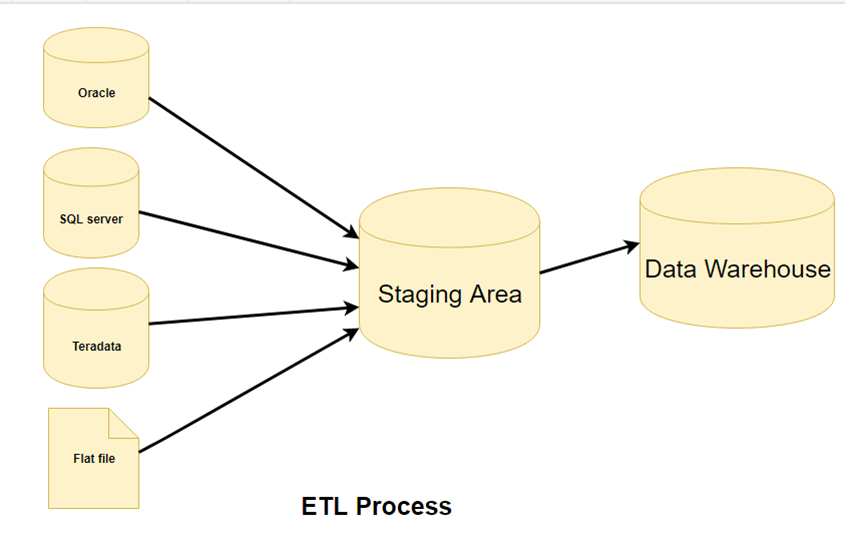
Шаг 1) Извлечение
На этом этапе данные извлекаются из исходной системы в промежуточную область. Преобразования, если таковые имеются, выполняются в области подготовки, так что производительность исходной системы не ухудшается. Кроме того, если поврежденные данные копируются непосредственно из источника в базу данных хранилища данных, откат будет затруднен. Промежуточная область дает возможность проверить извлеченные данные перед их перемещением в хранилище данных.
Хранилище данных должно интегрировать системы, которые имеют разные
СУБД, оборудование, операционные системы и протоколы связи. Источники могут включать в себя унаследованные приложения, такие как мейнфреймы, специализированные приложения, устройства точки контакта, такие как ATM, переключатели вызовов, текстовые файлы, электронные таблицы, ERP, данные от поставщиков, партнеров и других.
Следовательно, перед извлечением и загрузкой данных физически необходима логическая карта данных. Эта карта данных описывает отношения между источниками и целевыми данными.
Три метода извлечения данных:
- Полная добыча
- Частичное извлечение — без уведомления об обновлении.
- Частичное извлечение — с уведомлением об обновлении
Независимо от используемого метода извлечение не должно влиять на производительность и время отклика исходных систем. Эти исходные системы являются живыми производственными базами данных. Любое замедление или блокировка могут повлиять на прибыль компании.
Некоторые проверки выполняются во время извлечения:
- Согласовать записи с исходными данными
- Убедитесь, что спам / нежелательные данные не загружены
- Проверка типа данных
- Удалить все типы дубликатов / фрагментированных данных
- Проверьте, все ли ключи на месте или нет
Шаг 2) Преобразование
Данные, извлеченные с исходного сервера, являются необработанными и не могут использоваться в исходном виде. Поэтому он должен быть очищен, нанесен на карту и преобразован. Фактически, это ключевой шаг, когда процесс ETL добавляет ценность и изменяет данные таким образом, чтобы можно было создавать проницательные отчеты BI.
На этом этапе вы применяете набор функций к извлеченным данным. Данные, которые не требуют какого-либо преобразования, называются прямым перемещением или передачей данных .
На этапе преобразования вы можете выполнять настраиваемые операции с данными. Например, если пользователь хочет получить доход от суммы продаж, которого нет в базе данных. Или, если имя и фамилия в таблице находятся в разных столбцах. Их можно объединить перед загрузкой.
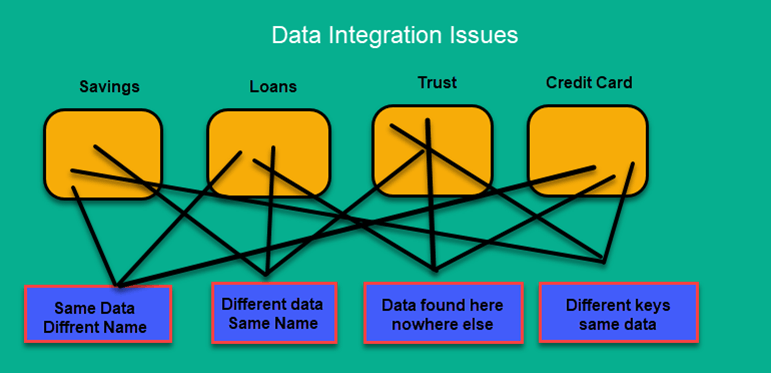
Ниже приведены проблемы целостности данных:
- Разное написание одного и того же человека, как Джон, Джон и т. Д.
- Есть несколько способов обозначить название компании, как Google, Google Inc.
- Использование разных имен, таких как Кливленд, Кливленд.
- Может случиться так, что разные приложения генерируют разные номера счетов для одного и того же клиента.
- В некоторых данных обязательные файлы остаются пустыми
- Недопустимый продукт, собранный в POS при ручном вводе, может привести к ошибкам.
Проверки проводятся на этом этапе
- Фильтрация — выберите только определенные столбцы для загрузки
- Использование правил и справочных таблиц для стандартизации данных
- Набор символов Преобразование и обработка кодировки
- Преобразование единиц измерения, таких как преобразование даты и времени, преобразование валют, числовые преобразования и т. Д.
- Проверка пороговых значений данных. Например, возраст не может быть более двух цифр.
- Проверка потока данных из промежуточной области в промежуточные таблицы.
- Обязательные поля не следует оставлять пустыми.
- Очистка (например, отображение NULL в 0 или пол мужчины в «M» и женщина в «F» и т. Д.)
- Разбить столбец на несколько и объединить несколько столбцов в один столбец.
- Транспонирование строк и столбцов,
- Используйте поиск для объединения данных
- Использование любой сложной проверки данных (например, если первые два столбца в строке пустые, строка автоматически отклоняет обработку)
Шаг 3) Загрузка
Загрузка данных в целевую базу данных хранилища данных является последним этапом процесса ETL. В типичном хранилище данных огромный объем данных необходимо загружать за относительно короткий период (ночи). Следовательно, процесс загрузки должен быть оптимизирован для производительности.
В случае сбоя загрузки механизмы восстановления должны быть настроены на перезапуск с точки сбоя без потери целостности данных. Администраторы хранилища данных должны отслеживать, возобновлять, отменять нагрузки в соответствии с преобладающей производительностью сервера.
Типы погрузки:
- Начальная загрузка — заполнение всех таблиц хранилища данных
- Инкрементная нагрузка — применение текущих изменений по мере необходимости периодически.
- Полное обновление — стирание содержимого одной или нескольких таблиц и перезагрузка со свежими данными.
Загрузить подтверждение
- Убедитесь, что данные ключевого поля не являются ни отсутствующими, ни нулевыми.
- Тестирование видов моделирования на основе целевых таблиц.
- Проверьте, что объединенные значения и рассчитанные меры.
- Проверка данных в таблице измерений, а также в таблице истории.
- Проверьте отчеты BI по загруженной таблице фактов и измерений.
Инструменты ETL
На рынке доступно много инструментов для хранения данных. Вот некоторые из наиболее выдающихся:
1. MarkLogic:
MarkLogic — это решение для хранения данных, которое делает интеграцию данных более простой и быстрой, используя множество корпоративных функций. Он может запрашивать различные типы данных, такие как документы, отношения и метаданные.
https://developer.marklogic.com/products/
2. Оракул:
Oracle является лидирующей в отрасли базой данных. Он предлагает широкий выбор решений для хранилищ данных как для локальных, так и для облачных вычислений. Это помогает оптимизировать качество обслуживания клиентов за счет повышения операционной эффективности.
https://www.oracle.com/index.html
3. Amazon RedShift:
Amazon Redshift — это инструмент Datawarehouse. Это простой и экономичный инструмент для анализа всех типов данных с использованием стандартного SQL и существующих инструментов BI. Это также позволяет выполнять сложные запросы к петабайтам структурированных данных.
https://aws.amazon.com/redshift/?nc2=h_m1
Вот полный список полезных инструментов хранилища данных.
Лучшие практики ETL процесса
Никогда не пытайтесь очистить все данные:
Каждая организация хотела бы, чтобы все данные были чистыми, но большинство из них не готовы платить за ожидание или не готовы ждать. Очистка всего этого займет слишком много времени, поэтому лучше не пытаться очистить все данные.
Никогда ничего не очищайте:
Всегда планируйте что-то чистить, потому что главная причина создания хранилища данных — предлагать более чистые и надежные данные.
Определите стоимость очистки данных:
Перед очисткой всех «грязных» данных важно определить стоимость очистки для каждого «грязного» элемента данных.
Чтобы ускорить обработку запросов, имейте вспомогательные представления и индексы:
Чтобы сократить расходы на хранение, храните обобщенные данные на дисках. Также требуется компромисс между объемом хранимых данных и их подробным использованием. Компромисс на уровне детализации данных для снижения затрат на хранение.
Резюме:
- ETLstands для извлечения, преобразования и загрузки.
- ETL предоставляет метод перемещения данных из различных источников в хранилище данных.
- На первом этапе извлечения данные извлекаются из исходной системы в область подготовки.
- На этапе преобразования данные, извлеченные из источника, очищаются и преобразуются.
- Загрузка данных в целевое хранилище данных является последним этапом процесса ETL.