Что такое Data Lake?
Data Lake — это хранилище данных, которое может хранить большое количество структурированных, полуструктурированных и неструктурированных данных. Это место для хранения всех типов данных в собственном формате без фиксированных ограничений на размер учетной записи или файл. Он предлагает большое количество данных для повышения аналитической производительности и встроенной интеграции.
Data Lake похожа на большой контейнер, который очень похож на настоящее озеро и реки. Точно так же, как в озере есть несколько притоков, озеро данных содержит структурированные данные, неструктурированные данные, от машины к машине, журналы, проходящие в режиме реального времени.
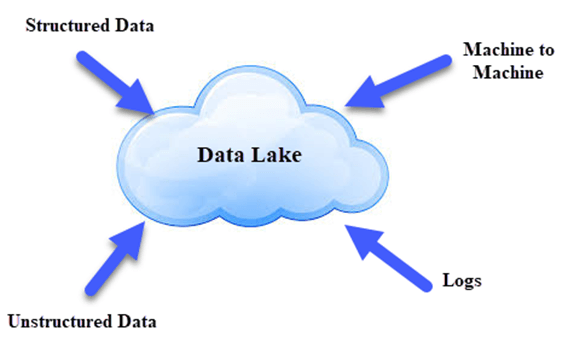
Data Lake демократизирует данные и является экономически эффективным способом хранения всех данных организации для последующей обработки. Аналитик может сосредоточиться на поиске шаблонов значений в данных, а не на самих данных.
В отличие от иерархического хранилища данных, в котором данные хранятся в папках и файлах, озеро данных имеет плоскую архитектуру. Каждым элементам данных в озере данных присваивается уникальный идентификатор, и они помечаются набором метаданных.
В этом уроке вы узнаете
- Что такое Data Lake?
- Почему Data Lake?
- Архитектура озера данных
- Основные понятия озера данных
- Этапы зрелости озера данных
- Лучшие практики для внедрения озера данных:
- Разница между озерами данных и хранилищем данных
- Преимущества и риски использования Data Lake:
Почему Data Lake?
Основная цель построения озера данных — предложить ученым, работающим с данными, неопределяемое представление данных.
Причины использования Data Lake:
- С появлением таких механизмов хранения, как Hadoop, хранение разрозненной информации стало простым делом. Нет необходимости моделировать данные в корпоративную схему с озером данных.
- С увеличением объема данных, качества данных и метаданных качество анализа также увеличивается.
- Data Lake предлагает гибкость бизнеса
- Машинное обучение и искусственный интеллект могут использоваться, чтобы делать прибыльные прогнозы.
- Он предлагает конкурентное преимущество внедряющей организации.
- Структура хранилища данных отсутствует. Data Lake дает 360-градусный обзор клиентов и делает анализ более надежным.
Архитектура озера данных
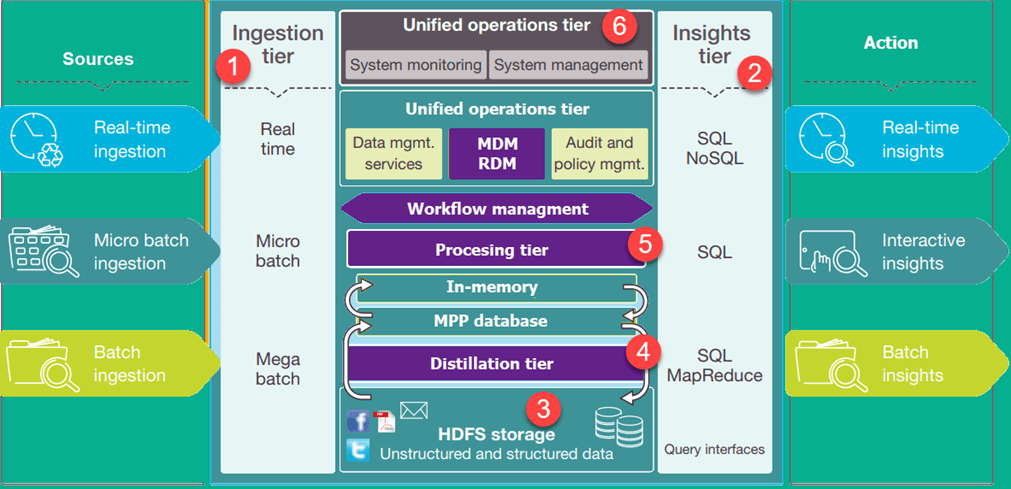
На рисунке показана архитектура озера бизнес-данных. Нижние уровни представляют данные, которые в основном находятся в состоянии покоя, а верхние уровни показывают данные транзакций в реальном времени. Эти данные проходят через систему без задержки или с небольшой задержкой. Ниже перечислены важные уровни архитектуры озера данных.
- Уровень проглатывания : Уровни на левой стороне отображают источники данных. Данные могут быть загружены в озеро данных в пакетном режиме или в режиме реального времени
- Уровень понимания: уровни справа представляют исследовательскую сторону, где используются выводы из системы. Для анализа данных могут использоваться запросы SQL, NoSQL или даже Excel.
- HDFS — это экономичное решение для структурированных и неструктурированных данных. Это посадочная зона для всех данных, которые находятся в состоянии покоя в системе.
- Уровень дистилляции берет данные из шины хранения и преобразует их в структурированные данные для более легкого анализа.
- На уровне обработки выполняются аналитические алгоритмы и пользовательские запросы с изменяющимся интерактивным пакетным режимом в реальном времени для создания структурированных данных для более удобного анализа.
- Уровень унифицированных операций управляет управлением и мониторингом системы. Он включает в себя аудит и управление навыками, управление данными, управление рабочим процессом.
Основные понятия озера данных
Ниже приведены ключевые концепции озера данных, которые необходимо понять, чтобы полностью понять архитектуру озера данных.
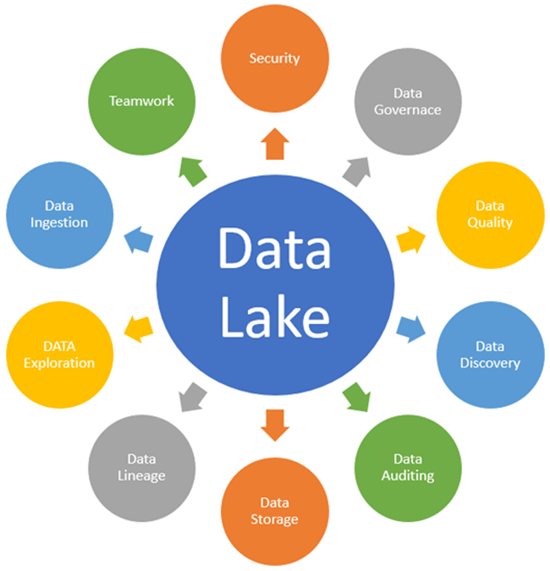
Попадание данных
Загрузка данных позволяет соединителям получать данные из разных источников данных и загружать их в озеро данных.
Загрузка данных поддерживает:
- Все типы структурированных, полуструктурированных и неструктурированных данных.
- Несколько приемов пищи, таких как пакетная, в режиме реального времени, разовая загрузка.
- Многие типы источников данных, такие как базы данных, веб-серверы, электронные письма, IoT и FTP.
Хранилище данных
Хранение данных должно быть масштабируемым, предлагать экономичное хранилище и обеспечивать быстрый доступ к исследованию данных. Он должен поддерживать различные форматы данных.
Управление данными
Управление данными — это процесс управления доступностью, удобством использования, безопасностью и целостностью данных, используемых в организации.
Безопасность
Безопасность должна быть реализована на каждом уровне озера данных. Все начинается с хранения, отсоединения и потребления. Основная необходимость — прекратить доступ для неавторизованных пользователей. Он должен поддерживать различные инструменты для доступа к данным с удобной навигацией по GUI и инструментальным панелям.
Аутентификация, учет, авторизация и защита данных являются важными функциями защиты озера данных.
Качество данных:
Качество данных является важным компонентом архитектуры озера данных. Данные используются для точного определения стоимости бизнеса. Извлечение информации из данных низкого качества приведет к снижению качества информации.
Обнаружение данных
Обнаружение данных является еще одним важным этапом, прежде чем вы сможете начать подготовку данных или анализа. На этом этапе техника тегирования используется для выражения понимания данных путем организации и интерпретации данных, введенных в озеро данных.
Аудит данных
Двумя основными задачами аудита данных являются отслеживание изменений в наборе ключевых данных.
- Отслеживание изменений в важных элементах набора данных
- Захватывает, как / когда / и кто меняет эти элементы.
Аудит данных помогает оценить риск и соответствие.
Линия данных
Этот компонент имеет дело с происхождением данных. В основном это касается того, где он движется с течением времени и что с ним происходит. Это облегчает исправление ошибок в процессе анализа данных от источника до места назначения.
Исследование данных
Это начальный этап анализа данных. Это помогает определить правильный набор данных жизненно важно перед началом исследования данных.
Все данные компоненты должны работать вместе, чтобы играть важную роль в построении озера данных, легко развиваться и исследовать окружающую среду.
Этапы зрелости озера данных
Определение этапов зрелости озера данных отличается от учебника к другому. Хотя суть остается прежней. После зрелости, определение стадии с точки зрения непрофессионала.

Этап 1: обработка и получение данных в масштабе
Эта первая стадия зрелости данных включает в себя улучшение способности преобразовывать и анализировать данные. Здесь владельцы бизнеса должны найти инструменты в соответствии со своими навыками для получения дополнительных данных и создания аналитических приложений.
Этап 2: Наращивание аналитической мускулатуры
Это второй этап, который включает в себя улучшение способности преобразовывать и анализировать данные. На этом этапе компании используют инструмент, наиболее соответствующий их навыкам. Они начинают получать больше данных и создавать приложения. Здесь возможности хранилища данных предприятия и озера данных используются совместно.
Этап 3: EDW и Data Lake работают в унисон
Этот шаг включает передачу данных и аналитики в руки как можно большего числа людей. На этом этапе озеро данных и корпоративное хранилище данных начинают работать в объединении. Оба играют свою роль в аналитике
Этап 4: Возможности предприятия на озере
На этой стадии зрелости озера данных к озеру данных добавляются корпоративные возможности. Принятие управления информацией, возможностей управления жизненным циклом информации и управления метаданными. Тем не менее, очень немногие организации могут достичь такого уровня зрелости, но в будущем этот показатель увеличится.
Лучшие практики для внедрения озера данных:
- Архитектурные компоненты, их взаимодействие и идентифицированные продукты должны поддерживать собственные типы данных.
- Проектирование Data Lake должно основываться на том, что доступно, а не на том, что требуется. Схема и требования к данным не определены, пока не будет запрошен
- При проектировании следует руководствоваться одноразовыми компонентами, интегрированными с сервисным API.
- Обнаружение, прием, хранение, администрирование, качество, преобразование и визуализация данных должны управляться независимо.
- Архитектура озера данных должна быть адаптирована к конкретной отрасли. Он должен гарантировать, что возможности, необходимые для этой области, являются неотъемлемой частью проекта
- Важно ускорить адаптацию недавно открытых источников данных
- Data Lake помогает настраиваемому управлению извлекать максимальную выгоду
- Озеро данных должно поддерживать существующие методы и методы управления данными предприятия
Проблемы построения озера данных:
- В Data Lake объем данных выше, поэтому процесс должен в большей степени зависеть от программного администрирования
- Трудно иметь дело с редкими, неполными, изменчивыми данными
- Более широкий набор данных и источник нуждаются в большем управлении данными и поддержке
Разница между озерами данных и хранилищем данных
| параметры | Озера данных | Хранилище данных |
| Данные | Озера данных хранят все. | Хранилище данных ориентировано только на бизнес-процессы. |
| обработка | Данные в основном не обрабатываются | Сильно обработанные данные. |
| Тип данных | Он может быть неструктурированным, полуструктурированным и структурированным. | Это в основном в табличной форме и структуре. |
| задача | Поделиться данными руководства | Оптимизирован для поиска данных |
| проворство | Высокая гибкость, настройка и перенастройка по мере необходимости. | По сравнению с озером данных он менее гибок и имеет фиксированную конфигурацию. |
| пользователей | Data Lake в основном используется Data Scientist | Профессионалы бизнеса широко используют хранилище данных |
| Место хранения | Дизайн озер данных для недорогого хранения. | Используются дорогие хранилища, обеспечивающие быстрое время отклика. |
| Безопасность | Предлагает меньший контроль. | Позволяет лучше контролировать данные. |
| Замена EDW | Озеро данных может быть источником для EDW | В дополнение к EDW (не замена) |
| схема | Схема на чтение (без предопределенных схем) | Схема при записи (предопределенные схемы) |
| Обработка данных | Помогает для быстрого приема новых данных. | Требуется много времени для внедрения нового контента. |
| Гранулярность данных | Данные на низком уровне детализации или детализации. | Данные на сводном или агрегированном уровне детализации. |
| инструменты | Можно использовать с открытым исходным кодом / инструменты, такие как Hadoop / Map Reduce | В основном коммерческие инструменты. |
Преимущества и риски использования Data Lake:
Вот несколько основных преимуществ использования озера данных:
- Полностью помогает с ионизацией продукта и передовой аналитикой
- Обеспечивает экономичную масштабируемость и гибкость
- Предлагает ценность от неограниченных типов данных
- Уменьшает долгосрочную стоимость владения
- Позволяет экономичное хранение файлов
- Быстро адаптируется к изменениям
- Основным преимуществом озера данных является централизация различных источников контента.
- Пользователи из разных отделов могут быть разбросаны по всему земному шару и могут иметь гибкий доступ к данным.
Риск использования озера данных:
- Через некоторое время Data Lake может потерять актуальность и импульс
- При проектировании озера данных существует больший риск
- Неструктурированные данные могут привести к неуправляемому Chao, неиспользуемым данным, отдельным и сложным инструментам, совместной работе в масштабах предприятия, унифицированной, последовательной и общей
- Это также увеличивает стоимость хранения и вычисляет
- Невозможно получить информацию от других, которые работали с данными, потому что нет данных о происхождении результатов предыдущих аналитиков.
- Самый большой риск озер данных — это безопасность и контроль доступа. Иногда данные могут быть помещены в озеро без какого-либо надзора, так как некоторые данные могут иметь конфиденциальность и нормативные требования
Резюме:
- Data Lake — это хранилище данных, которое может хранить большое количество структурированных, полуструктурированных и неструктурированных данных.
- Основная цель построения озера данных — предложить ученым, работающим с данными, неопределяемое представление данных.
- Уровень унифицированных операций, уровень обработки, уровень дистилляции и HDFS являются важными уровнями архитектуры озера данных.
- Прием данных, хранение данных, качество данных, аудит данных, исследование данных, обнаружение данных — вот некоторые важные компоненты архитектуры озера данных.
- Проектирование Data Lake должно основываться на том, что доступно, а не на том, что требуется.
- Data Lake снижает долгосрочную стоимость владения и позволяет экономично хранить файлы
- Самый большой риск озер данных — это безопасность и контроль доступа. Иногда данные могут быть помещены в озеро без какого-либо надзора, так как некоторые данные могут нуждаться в конфиденциальности и нормативных требованиях.