Что такое Data Mining?
Data Mining ищет скрытые, допустимые и потенциально полезные шаблоны в огромных наборах данных. Data Mining — это обнаружение неожиданных / ранее неизвестных связей между данными.
Это междисциплинарный навык, который использует машинное обучение, статистику, искусственный интеллект и технологии баз данных.
Выводы, полученные с помощью Data Mining, могут быть использованы для маркетинга, выявления мошенничества, научных открытий и т. Д.
Интеллектуальный анализ данных также называется обнаружением знаний, извлечением знаний, анализом данных / шаблонов, сбором информации и т. Д.
В этом уроке вы узнаете
- Что такое Data Mining?
- Типы данных
- Процесс внедрения Data Mining
- Понимание бизнеса:
- Понимание данных:
- Подготовка данных:
- Преобразование данных:
- Моделирование:
- Методы добычи данных
- Проблемы внедрения Data Mine:
- Примеры интеллектуального анализа данных:
- Инструменты интеллектуального анализа данных
- Преимущества Data Mining:
- Недостатки Data Mining
- Приложения для интеллектуального анализа данных
Типы данных
Интеллектуальный анализ данных может быть выполнен на следующих типах данных
- Реляционные базы данных
- Хранилища данных
- Усовершенствованные БД и информационные хранилища
- Объектно-ориентированные и объектно-реляционные базы данных
- Транзакционные и пространственные базы данных
- Гетерогенные и унаследованные базы данных
- Мультимедийная и потоковая база данных
- Текстовые базы данных
- Текстовый майнинг и веб майнинг
Процесс внедрения Data Mining

Давайте подробно изучим процесс внедрения Data Mining
Понимание бизнеса:
На этом этапе устанавливаются цели бизнеса и добычи данных.
- Во-первых, вы должны понимать цели бизнеса и клиента. Вы должны определить, что хочет ваш клиент (что часто даже они сами не знают)
- Подведите итоги текущего сценария добычи данных. Фактор ресурсов, предположения, ограничения и другие существенные факторы в вашей оценке.
- Используя бизнес-цели и текущий сценарий, определите свои цели интеллектуального анализа данных.
- Хороший план интеллектуального анализа данных очень подробный и должен быть разработан для достижения целей как бизнеса, так и данных.
Понимание данных:
На этом этапе выполняется проверка работоспособности данных, чтобы проверить, подходит ли она для целей интеллектуального анализа данных.
- Во-первых, данные собираются из нескольких источников данных, доступных в организации.
- Эти источники данных могут включать в себя несколько баз данных, плоский файл или кубы данных. Существуют такие проблемы, как сопоставление объектов и интеграция схем, которые могут возникнуть в процессе интеграции данных. Это довольно сложный и сложный процесс, так как данные из разных источников вряд ли легко сопоставимы. Например, таблица A содержит сущность с именем cust_no, тогда как другая таблица B содержит сущность с именем cust-id.
- Следовательно, довольно трудно гарантировать, что оба эти заданных объекта ссылаются на одно и то же значение или нет. Здесь метаданные должны использоваться для уменьшения ошибок в процессе интеграции данных.
- Далее необходимо выполнить поиск свойств полученных данных. Хороший способ исследовать данные — это ответить на вопросы интеллектуального анализа данных (решенные в бизнес-фазе), используя инструменты запросов, отчетов и визуализации.
- На основании результатов запроса должно быть установлено качество данных. Отсутствующие данные, если таковые имеются, должны быть получены.
Подготовка данных:
На этом этапе данные готовятся к производству.
Процесс подготовки данных занимает около 90% времени проекта.
Данные из разных источников должны быть отобраны, очищены, преобразованы, отформатированы, анонимны и построены (если требуется).
Очистка данных — это процесс «очистки» данных путем сглаживания зашумленных данных и заполнения пропущенных значений.
Например, для демографического профиля клиента отсутствуют данные о возрасте. Данные являются неполными и должны быть заполнены. В некоторых случаях могут быть выбросы данных. Например, возраст имеет значение 300. Данные могут быть противоречивыми. Например, имя клиента отличается в разных таблицах.
Операции преобразования данных изменяют данные, чтобы сделать их полезными для интеллектуального анализа данных. Следующее преобразование может быть применено
Преобразование данных:
Операции преобразования данных будут способствовать успеху процесса майнинга.
Сглаживание: помогает удалить шум из данных.
Агрегация. Сводные или агрегирующие операции применяются к данным. То есть еженедельные данные о продажах агрегируются для расчета месячной и годовой суммы.
Обобщение: На этом этапе данные низкого уровня заменяются концепциями более высокого уровня с помощью иерархий концепций. Например, город заменяется графством.
Нормализация: Нормализация выполняется, когда данные атрибута увеличиваются или уменьшаются. Пример: данные должны находиться в диапазоне от -2,0 до 2,0 после нормализации.
Построение атрибута : эти атрибуты создаются и включают в себя заданный набор атрибутов, полезных для интеллектуального анализа данных.
Результатом этого процесса является окончательный набор данных, который можно использовать при моделировании.
моделирование
На этом этапе математические модели используются для определения структуры данных.
- Исходя из бизнес-целей, подходящие методы моделирования должны быть выбраны для подготовленного набора данных.
- Создайте сценарий для проверки качества и валидности модели.
- Запустите модель на подготовленном наборе данных.
- Результаты должны оцениваться всеми заинтересованными сторонами, чтобы убедиться, что модель может соответствовать целям сбора данных.
Оценка:
На этом этапе идентифицированные шаблоны оцениваются в соответствии с бизнес-целями.
- Результаты, полученные с помощью модели интеллектуального анализа данных, должны оцениваться в соответствии с бизнес-целями.
- Получение понимания бизнеса является итеративным процессом. Фактически, при понимании, новые бизнес-требования могут быть повышены из-за интеллектуального анализа данных
- Принято решение о переходе модели на этап развертывания.
Развертывание:
На этапе развертывания вы отправляете свои открытия для интеллектуального анализа данных в повседневные бизнес-операции.
- Знания или информация, обнаруженные в процессе извлечения данных, должны быть понятны для нетехнических заинтересованных сторон.
- Создан подробный план развертывания для доставки, обслуживания и мониторинга обнаружений интеллектуального анализа данных.
- Окончательный отчет по проекту создается с учетом извлеченных уроков и ключевых событий в ходе проекта. Это помогает улучшить деловую политику организации.
Методы добычи данных
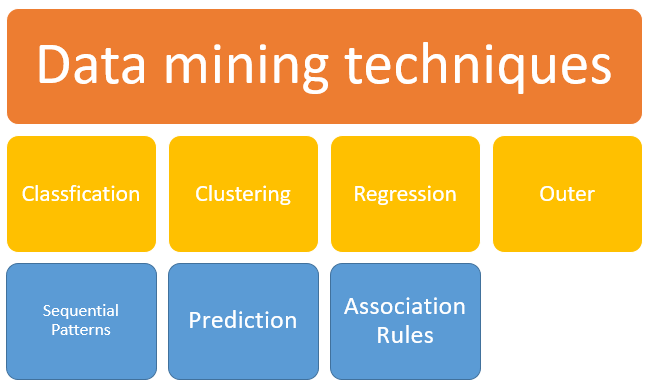
1.Classification:
Этот анализ используется для получения важной и актуальной информации о данных и метаданных. Этот метод анализа данных помогает классифицировать данные в разных классах.
2. Кластеризация:
Кластерный анализ — это метод анализа данных, позволяющий идентифицировать данные, которые похожи друг на друга. Этот процесс помогает понять различия и сходства между данными.
3. Регрессия:
Регрессионный анализ — это метод интеллектуального анализа данных для выявления и анализа взаимосвязи между переменными. Он используется для определения вероятности конкретной переменной, учитывая наличие других переменных.
4. Правила ассоциации:
Этот метод анализа данных помогает найти связь между двумя или более Предметами. Он обнаруживает скрытый шаблон в наборе данных.
5. Наружное обнаружение:
Этот тип метода интеллектуального анализа данных относится к наблюдению за элементами данных в наборе данных, которые не соответствуют ожидаемому образцу или ожидаемому поведению. Этот метод может использоваться в различных областях, таких как вторжение, обнаружение, мошенничество или обнаружение ошибок и т. Д. Наружное обнаружение также называется анализом выбросов или добычей выбросов.
6. Последовательные паттерны:
Этот метод анализа данных помогает обнаруживать или идентифицировать аналогичные модели или тенденции в данных транзакций за определенный период.
7. Прогноз:
Прогнозирование использует комбинацию других методов анализа данных, таких как тренды, последовательные шаблоны, кластеризация, классификация и т. Д. Он анализирует прошлые события или экземпляры в правильной последовательности для прогнозирования будущего события.
Проблемы внедрения Data mine:
- Квалифицированные специалисты необходимы для формулирования запросов на интеллектуальный анализ данных.
- Переоснащение: из-за небольшой базы данных обучения модель может не соответствовать будущим состояниям.
- Для интеллектуального анализа данных необходимы большие базы данных, которыми иногда сложно управлять
- Деловую практику, возможно, придется изменить, чтобы определить, использовать ли информацию, не раскрытую.
- Если набор данных не разнообразен, результаты анализа данных могут быть неточными.
- Информация об интеграции, необходимая из разнородных баз данных и глобальных информационных систем, может быть сложной
Примеры добычи данных:
Пример 1:
Consider a marketing head of telecom service provides who wants to increase revenues of long distance services. For high ROI on his sales and marketing efforts customer profiling is important. He has a vast data pool of customer information like age, gender, income, credit history, etc. But its impossible to determine characteristics of people who prefer long distance calls with manual analysis. Using data mining techniques, he may uncover patterns between high long distance call users and their characteristics.
For example, he might learn that his best customers are married females between the age of 45 and 54 who make more than $80,000 per year. Marketing efforts can be targeted to such demographic.
Example 2:
A bank wants to search new ways to increase revenues from its credit card operations. They want to check whether usage would double if fees were halved.
Bank has multiple years of record on average credit card balances, payment amounts, credit limit usage, and other key parameters. They create a model to check the impact of the proposed new business policy. The data results show that cutting fees in half for a targetted customer base could increase revenues by $10 million.
Data Mining Tools
Following are 2 popular Data Mining Tools widely used in Industry
R-language:
R language is an open source tool for statistical computing and graphics. R has a wide variety of statistical, classical statistical tests, time-series analysis, classification and graphical techniques. It offers effective data handing and storage facility.
Oracle Data Mining:
Oracle Data Mining popularly knowns as ODM is a module of the Oracle Advanced Analytics Database. This Data mining tool allows data analysts to generate detailed insights and makes predictions. It helps predict customer behavior, develops customer profiles, identifies cross-selling opportunities.
Benefits of Data Mining:
- Data mining technique helps companies to get knowledge-based information.
- Data mining helps organizations to make the profitable adjustments in operation and production.
- The data mining is a cost-effective and efficient solution compared to other statistical data applications.
- Data mining helps with the decision-making process.
- Facilitates automated prediction of trends and behaviors as well as automated discovery of hidden patterns.
- It can be implemented in new systems as well as existing platforms
- It is the speedy process which makes it easy for the users to analyze huge amount of data in less time.
Disadvantages of Data Mining
- There are chances of companies may sell useful information of their customers to other companies for money. For example, American Express has sold credit card purchases of their customers to the other companies.
- Many data mining analytics software is difficult to operate and requires advance training to work on.
- Different data mining tools work in different manners due to different algorithms employed in their design. Therefore, the selection of correct data mining tool is a very difficult task.
- The data mining techniques are not accurate, and so it can cause serious consequences in certain conditions.
Data Mining Applications
| Applications | Usage |
| связи | Методы интеллектуального анализа данных используются в секторе коммуникаций для прогнозирования поведения клиентов, чтобы предлагать целевые и релевантные кампании. |
| страхование | Data mining помогает страховым компаниям выгодно оценивать свои продукты и продвигать новые предложения для своих новых или существующих клиентов. |
| образование | Интеллектуальный анализ данных помогает преподавателям получать доступ к данным учащихся, прогнозировать уровни успеваемости и находить учащихся или группы учащихся, которым требуется дополнительное внимание. Например, студенты, которые слабы по математике. |
| Производство | С помощью Data Mining производители могут прогнозировать износ производственных активов. Они могут рассчитывать на техническое обслуживание, которое помогает им уменьшить их, чтобы минимизировать время простоя. |
| Банковское дело | Интеллектуальный анализ данных помогает финансовому сектору получать представление о рыночных рисках и управлять соблюдением нормативных требований. Это помогает банкам выявлять возможных неплательщиков, чтобы решить, выпускать ли кредитные карты, кредиты и т. Д. |
| Розничная торговля | Методы Data Mining помогают розничным торговым центрам и продуктовым магазинам выявлять и размещать наиболее продаваемые товары в наиболее внимательных местах. Это помогает владельцам магазинов придумать предложение, которое стимулирует покупателей увеличивать свои расходы. |
| Поставщики услуг | Поставщики услуг, такие как мобильные телефоны и коммунальные предприятия, используют Data Mining для прогнозирования причин ухода клиента из своей компании. Они анализируют детали выставления счетов, взаимодействия с клиентами, жалобы, поданные в компанию, чтобы назначить каждому клиенту оценку вероятности и предлагают стимулы. |
| Электронная коммерция | Сайты электронной коммерции используют Data Mining, чтобы предлагать перекрестные продажи и продажи через свои веб-сайты. Одним из самых известных имен является Amazon, который использует методы интеллектуального анализа данных, чтобы привлечь больше клиентов в свой магазин электронной коммерции. |
| Супер Маркетс | Data Mining позволяет правилам разработки супермаркетов прогнозировать, ожидают ли их покупатели. Оценив их модель покупок, они могли бы найти женщин-клиентов, которые, скорее всего, беременны. Они могут начать нацеливаться на такие продукты, как детская присыпка, детский магазин, подгузники и так далее. |
| Расследование преступления | Data Mining помогает органам по расследованию преступлений задействовать сотрудников полиции (где преступление наиболее вероятно и когда?), Кого искать на пограничном переходе и т. Д. |
| Биоинформатика | Data Mining помогает добывать биологические данные из массивных наборов данных, собранных в биологии и медицине. |
Резюме:
- Data Mining — это объяснение прошлого и предсказание будущего для анализа.
- Интеллектуальный анализ данных помогает извлекать информацию из огромных массивов данных. Это процедура извлечения знаний из данных.
- Процесс интеллектуального анализа данных включает в себя понимание бизнеса, понимание данных, подготовку данных, моделирование, развитие, развертывание.
- Важные методы интеллектуального анализа данных: классификация, кластеризация, регрессия, правила ассоциации, внешнее обнаружение, последовательные шаблоны и прогнозирование.
- R-язык и Oracle Data Mining являются известными инструментами интеллектуального анализа данных.
- Техника добычи данных помогает компаниям получать основанную на знаниях информацию.
- Основным недостатком интеллектуального анализа данных является то, что многие аналитические программы сложны в управлении и требуют прохождения предварительной подготовки.
- Интеллектуальный анализ данных используется в различных отраслях, таких как связь, страхование, образование, производство, банковское дело, розничная торговля, поставщики услуг, электронная коммерция, супермаркеты, биоинформатика.