Машинное обучение с Python — Основы
Мы живем в «век данных», который обогащен лучшими вычислительными возможностями и большим объемом ресурсов хранения. Эти данные или информация растут день ото дня, но реальная задача состоит в том, чтобы разобраться во всех данных. Предприятия и организации пытаются справиться с этим путем создания интеллектуальных систем с использованием концепций и методологий из Data Science, Data Mining и Machine learning. Среди них машинное обучение — самая захватывающая область информатики. Это не было бы неправильно, если бы мы называли машинное обучение приложением и наукой об алгоритмах, которые дают смысл данным.
Что такое машинное обучение?
Машинное обучение (ML) — это та область компьютерных наук, с помощью которой компьютерные системы могут придавать смысл данным так же, как это делают люди.
Проще говоря, ML — это тип искусственного интеллекта, который извлекает шаблоны из необработанных данных, используя алгоритм или метод. Основная задача ML — позволить компьютерным системам учиться на собственном опыте без явного программирования или вмешательства человека.
Потребность в машинном обучении
В настоящий момент люди являются самыми умными и продвинутыми видами на земле, потому что они могут думать, оценивать и решать сложные проблемы. С другой стороны, ИИ все еще находится на начальной стадии и не превзошел человеческий интеллект во многих аспектах. Тогда вопрос в том, что нужно сделать, чтобы машина училась? Наиболее подходящая причина для этого — «принимать решения, основываясь на данных, с эффективностью и масштабностью».
В последнее время организации вкладывают значительные средства в новые технологии, такие как искусственный интеллект, машинное обучение и глубокое обучение, чтобы получить ключевую информацию из данных для выполнения нескольких реальных задач и решения проблем. Мы можем назвать это решениями, основанными на данных, принимаемыми машинами, особенно для автоматизации процесса. Эти управляемые данными решения могут использоваться вместо использования логики программирования в задачах, которые не могут быть запрограммированы по своей сути. Дело в том, что мы не можем обойтись без человеческого разума, но другой аспект заключается в том, что нам всем нужно эффективно решать реальные проблемы в огромных масштабах. Вот почему возникает необходимость в машинном обучении.
Зачем и когда учить машины?
Мы уже обсуждали необходимость машинного обучения, но возникает другой вопрос: в каких случаях мы должны заставить машину учиться? Может быть несколько обстоятельств, когда нам нужны машины для принятия решений, основанных на данных, с эффективностью и в огромных масштабах. Ниже приведены некоторые из таких обстоятельств, при которых обучение машин было бы более эффективным.
Недостаток человеческого опыта
Самым первым сценарием, в котором мы хотим, чтобы машина обучалась и принимала решения, основанные на данных, может быть область, где не хватает человеческого опыта. Примерами могут быть навигации по неизвестным территориям или пространственным планетам.
Динамические сценарии
Есть несколько сценариев, которые по своей природе динамичны, то есть они со временем меняются. В случае этих сценариев и поведения мы хотим, чтобы машина изучала и принимала решения, основанные на данных. Некоторыми примерами могут быть сетевое подключение и доступность инфраструктуры в организации.
Трудность в переводе экспертизы в вычислительные задачи
Там могут быть различные области, в которых люди имеют свой опыт; однако они не могут перевести этот опыт в вычислительные задачи. В таких условиях мы хотим машинное обучение. Примерами могут быть области распознавания речи, когнитивные задачи и т. Д.
Модель машинного обучения
Прежде чем обсуждать модель машинного обучения, мы должны понять следующее формальное определение ML, данное профессором Митчеллом:
«Говорят, что компьютерная программа извлекает уроки из опыта E в отношении некоторого класса задач T и показателя P производительности, если ее производительность в задачах T, измеряемая P, улучшается с опытом E.»
Вышеприведенное определение в основном сфокусировано на трех параметрах, а также на основных компонентах любого алгоритма обучения, а именно Задаче (T), Производительности (P) и опыте (E). В этом контексте мы можем упростить это определение как —
ML — это область ИИ, состоящая из алгоритмов обучения, которые —
- Улучшить их производительность (P)
- При выполнении некоторого задания (T)
- Со временем с опытом (E)
Исходя из вышеизложенного, следующая диаграмма представляет модель машинного обучения —
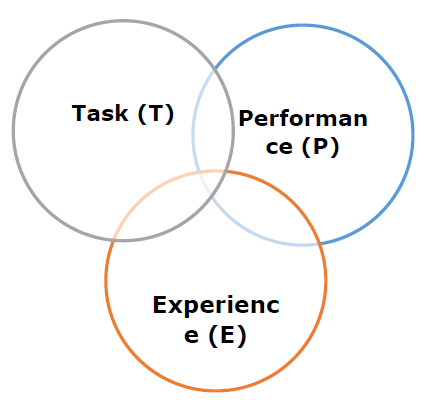
Давайте обсудим их более подробно сейчас —
Задача (Т)
С точки зрения проблемы, мы можем определить задачу T как реальную проблему, которую нужно решить. Проблема может быть любой, например, найти лучшую цену на жилье в определенном месте или найти лучшую маркетинговую стратегию и т. Д. С другой стороны, если мы говорим о машинном обучении, определение задачи будет другим, потому что трудно решить задачи, основанные на ОД, традиционный подход к программированию.
Задача T называется задачей на основе ML, когда она основана на процессе, и система должна следовать для работы с точками данных. Примерами задач на основе ML являются классификация, регрессия, структурированные аннотации, кластеризация, транскрипция и т. Д.
Опыт (E)
Как следует из названия, это знания, полученные из точек данных, предоставленных алгоритму или модели. После предоставления набора данных модель будет работать итеративно и изучать некоторые присущие ей шаблоны. Полученное таким образом обучение называется опытом (E). Проводя аналогию с обучением человека, мы можем представить себе ситуацию, в которой человек учится или приобретает некоторый опыт из различных атрибутов, таких как ситуация, отношения и т. Д. Обучение под наблюдением, без присмотра и подкрепление — это некоторые способы обучения или приобретения опыта. Опыт, полученный нашей моделью или алгоритмом ML, будет использован для решения задачи T.
Производительность (P)
Алгоритм ML должен выполнять задачу и получать опыт с течением времени. Мера, которая показывает, выполняет ли алгоритм ML согласно ожиданиям или нет, это его производительность (P). P — это в основном количественная метрика, которая показывает, как модель выполняет задачу, T, используя свой опыт, E. Есть много метрик, которые помогают понять производительность ML, таких как оценка точности, оценка F1, матрица путаницы, точность, отзыв чувствительность и т. д.
Проблемы в машинном обучении
В то время как машинное обучение стремительно развивается, делая значительные успехи в области кибербезопасности и автономных машин, этому сегменту ИИ в целом еще предстоит пройти долгий путь. Причина заключается в том, что ОД не смог преодолеть ряд проблем. Проблемы, с которыми сталкивается ОД в настоящее время:
Качество данных. Наличие качественных данных для алгоритмов ML является одной из самых больших проблем. Использование данных низкого качества приводит к проблемам, связанным с предварительной обработкой данных и извлечением функций.
Задача, отнимающая много времени. Другая проблема, с которой сталкиваются модели ML, — это трата времени, особенно на сбор данных, извлечение функций и поиск.
Нехватка специалистов — Поскольку технология ML все еще находится на начальной стадии, доступ к экспертным ресурсам — сложная задача.
Нет четкой цели для формулирования бизнес-задач. Отсутствие четкой цели и четко определенной цели для бизнес-задач является еще одной ключевой проблемой для ML, поскольку эта технология еще не настолько развита.
Проблема переоснащения и недостаточного оснащения — если модель переоснащена или недостаточно оснащена, она не может быть хорошо представлена для данной проблемы.
Проклятие размерности — Еще одна сложность, с которой сталкивается модель ML, — это слишком много особенностей точек данных. Это может быть настоящим препятствием.
Сложность в развертывании — Сложность модели ML делает его довольно сложным для развертывания в реальной жизни.
Применение машин обучения
Машинное обучение является наиболее быстро развивающейся технологией, и, по мнению исследователей, мы находимся в золотом году ИИ и МЛ. Он используется для решения многих реальных сложных проблем, которые невозможно решить с помощью традиционного подхода. Ниже приведены некоторые реальные применения ML —
- Эмоциональный анализ
- Анализ настроений
- Обнаружение и предотвращение ошибок
- Прогнозирование погоды и прогнозирование
- Анализ и прогнозирование фондового рынка
- Синтез речи
- Распознавание речи
- Сегментация клиентов
- Распознавание объектов
- Обнаружение мошенничества
- Предотвращение мошенничества
- Рекомендация товара покупателю в интернет-магазине
Машинное обучение с Python — Экосистема
Введение в Python
Python — это популярный объектно-ориентированный язык программирования, обладающий возможностями языка программирования высокого уровня. Его простой в освоении синтаксис и возможность переносимости делают его популярным в наши дни. Следующие факты дают нам введение в Python —
-
Python был разработан Гвидо ван Россумом в Stichting Mathematisch Centrum в Нидерландах.
-
Он был написан как преемник языка программирования под названием «ABC».
-
Его первая версия была выпущена в 1991 году.
-
Название Python было выбрано Гвидо ван Россумом из телешоу «Летающий цирк Монти Пайтона».
-
Это язык программирования с открытым исходным кодом, что означает, что мы можем свободно скачать его и использовать для разработки программ. Его можно скачать с www.python.org. ,
-
Язык программирования Python обладает функциями как Java, так и Си. Он имеет элегантный код C, а с другой стороны, имеет классы и объекты, такие как Java, для объектно-ориентированного программирования.
-
Это интерпретируемый язык, который означает, что исходный код программы Python сначала будет преобразован в байт-код, а затем выполнен виртуальной машиной Python.
Python был разработан Гвидо ван Россумом в Stichting Mathematisch Centrum в Нидерландах.
Он был написан как преемник языка программирования под названием «ABC».
Его первая версия была выпущена в 1991 году.
Название Python было выбрано Гвидо ван Россумом из телешоу «Летающий цирк Монти Пайтона».
Это язык программирования с открытым исходным кодом, что означает, что мы можем свободно скачать его и использовать для разработки программ. Его можно скачать с www.python.org. ,
Язык программирования Python обладает функциями как Java, так и Си. Он имеет элегантный код C, а с другой стороны, имеет классы и объекты, такие как Java, для объектно-ориентированного программирования.
Это интерпретируемый язык, который означает, что исходный код программы Python сначала будет преобразован в байт-код, а затем выполнен виртуальной машиной Python.
Сильные и слабые стороны Python
Каждый язык программирования имеет свои сильные и слабые стороны, как и Python.
Сильные стороны
Согласно исследованиям и опросам, Python является пятым по важности языком, а также самым популярным языком для машинного обучения и науки о данных. Именно из-за следующих сильных сторон, которые имеет Python —
Легко учиться и понимать — синтаксис Python проще; следовательно, даже для начинающих относительно легко выучить и понять язык.
Многоцелевой язык — Python является многоцелевым языком программирования, потому что он поддерживает структурированное программирование, объектно-ориентированное программирование, а также функциональное программирование.
Огромное количество модулей — Python имеет огромное количество модулей для охвата всех аспектов программирования. Эти модули легко доступны для использования, что делает Python расширяемым языком.
Поддержка сообщества с открытым исходным кодом. Будучи языком программирования с открытым исходным кодом, Python поддерживается очень большим сообществом разработчиков. Благодаря этому ошибки легко исправляются сообществом Python. Эта характеристика делает Python очень надежным и адаптивным.
Масштабируемость — Python является масштабируемым языком программирования, потому что он обеспечивает улучшенную структуру для поддержки больших программ, чем shell-скрипты.
Слабость
Хотя Python является популярным и мощным языком программирования, у него есть слабое место — низкая скорость выполнения.
Скорость выполнения Python медленная по сравнению со скомпилированными языками, потому что Python является интерпретируемым языком. Это может быть основной областью улучшения для сообщества Python.
Установка Python
Для работы в Python, мы должны сначала установить его. Вы можете выполнить установку Python любым из следующих двух способов:
- Установка Python индивидуально
- Использование готового дистрибутива Python: Anaconda
Давайте обсудим это каждый в деталях.
Установка Python индивидуально
Если вы хотите установить Python на свой компьютер, вам нужно загрузить только двоичный код, подходящий для вашей платформы. Дистрибутив Python доступен для платформ Windows, Linux и Mac.
Ниже приведен краткий обзор установки Python на вышеупомянутых платформах.
На платформе Unix и Linux
С помощью следующих шагов мы можем установить Python на платформу Unix и Linux —
-
Сначала перейдите на www.python.org/downloads/ .
-
Затем нажмите на ссылку, чтобы скачать сжатый исходный код, доступный для Unix / Linux.
-
Теперь загрузите и распакуйте файлы.
-
Затем мы можем отредактировать файл Modules / Setup, если мы хотим настроить некоторые параметры.
- Далее напишите команду run ./configure script
- делать
- сделать установку
Сначала перейдите на www.python.org/downloads/ .
Затем нажмите на ссылку, чтобы скачать сжатый исходный код, доступный для Unix / Linux.
Теперь загрузите и распакуйте файлы.
Затем мы можем отредактировать файл Modules / Setup, если мы хотим настроить некоторые параметры.
На платформе Windows
С помощью следующих шагов мы можем установить Python на платформу Windows —
-
Сначала перейдите на https://www.python.org/downloads/ .
-
Далее нажмите на ссылку для установщика Windows, файл python-XYZ.msi. Здесь XYZ — версия, которую мы хотим установить.
-
Теперь мы должны запустить загруженный файл. Это приведет нас к мастеру установки Python, который прост в использовании. Теперь примите настройки по умолчанию и дождитесь окончания установки.
Сначала перейдите на https://www.python.org/downloads/ .
Далее нажмите на ссылку для установщика Windows, файл python-XYZ.msi. Здесь XYZ — версия, которую мы хотим установить.
Теперь мы должны запустить загруженный файл. Это приведет нас к мастеру установки Python, который прост в использовании. Теперь примите настройки по умолчанию и дождитесь окончания установки.
На платформе Macintosh
Для Mac OS X, Homebrew, отличный и простой в использовании установщик пакетов рекомендуется установить Python 3. Если у вас нет Homebrew, вы можете установить его с помощью следующей команды —
$ ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
Его можно обновить с помощью команды ниже —
$ brew update
Теперь, чтобы установить Python3 в вашей системе, нам нужно выполнить следующую команду —
$ brew install python3
Использование предварительно упакованного дистрибутива Python: Anaconda
Anaconda — это пакетный сборник Python, в котором есть все библиотеки, широко используемые в науке о данных. Мы можем выполнить следующие шаги для настройки среды Python с использованием Anaconda —
-
Шаг 1 — Во-первых, нам нужно скачать необходимый установочный пакет из дистрибутива Anaconda. Ссылка для того же — www.anaconda.com/distribution/. Вы можете выбрать ОС Windows, Mac и Linux в соответствии с вашими требованиями.
-
Шаг 2 — Затем выберите версию Python, которую вы хотите установить на свой компьютер. Последняя версия Python — 3.7. Там вы получите опции для 64-битного и 32-битного графического инсталлятора.
-
Шаг 3 — После выбора версии ОС и Python он загрузит установщик Anaconda на ваш компьютер. Теперь дважды щелкните файл, и установщик установит пакет Anaconda.
-
Шаг 4 — Чтобы проверить, установлен он или нет, откройте командную строку и введите Python следующим образом
Шаг 1 — Во-первых, нам нужно скачать необходимый установочный пакет из дистрибутива Anaconda. Ссылка для того же — www.anaconda.com/distribution/. Вы можете выбрать ОС Windows, Mac и Linux в соответствии с вашими требованиями.
Шаг 2 — Затем выберите версию Python, которую вы хотите установить на свой компьютер. Последняя версия Python — 3.7. Там вы получите опции для 64-битного и 32-битного графического инсталлятора.
Шаг 3 — После выбора версии ОС и Python он загрузит установщик Anaconda на ваш компьютер. Теперь дважды щелкните файл, и установщик установит пакет Anaconda.
Шаг 4 — Чтобы проверить, установлен он или нет, откройте командную строку и введите Python следующим образом
Вы также можете проверить это в подробном видео-лекции на https://www.tutorialspoint.com/python_essentials_online_training/getting_started_with_anaconda.asp.
Почему Python для Data Science?
Python является пятым по важности языком, а также самым популярным языком для машинного обучения и науки о данных. Ниже приведены особенности Python, которые делают его предпочтительным языком для науки о данных —
Обширный набор пакетов
Python имеет обширный и мощный набор пакетов, которые готовы к использованию в различных областях. Он также имеет пакеты, такие как numpy, scipy, pandas, scikit-learn и т. Д. , Которые необходимы для машинного обучения и науки о данных.
Простое прототипирование
Еще одна важная особенность Python, которая делает выбор языка для науки о данных, простым и быстрым прототипированием. Эта функция полезна для разработки нового алгоритма.
Функция совместной работы
Область науки о данных в основном нуждается в хорошем сотрудничестве, и Python предоставляет множество полезных инструментов, которые делают это чрезвычайно.
Один язык для многих доменов
Типичный проект по науке о данных включает в себя различные области, такие как извлечение данных, манипулирование данными, анализ данных, извлечение функций, моделирование, оценка, развертывание и обновление решения. Поскольку Python является многоцелевым языком, он позволяет специалисту по данным обращаться ко всем этим областям с общей платформы.
Компоненты экосистемы Python ML
В этом разделе давайте обсудим некоторые основные библиотеки Data Science, которые образуют компоненты экосистемы обучения Python Machine. Эти полезные компоненты делают Python важным языком для Data Science. Хотя таких компонентов много, давайте обсудим некоторые важные компоненты экосистемы Python здесь:
-
Блокнот Jupyter — Блокноты Jupyter в основном предоставляют интерактивную вычислительную среду для разработки приложений Data Science на основе Python.
Блокнот Jupyter — Блокноты Jupyter в основном предоставляют интерактивную вычислительную среду для разработки приложений Data Science на основе Python.
Машинное обучение с Python — Методы
Существуют различные алгоритмы ML, методы и методы, которые можно использовать для построения моделей для решения реальных проблем с использованием данных. В этой главе мы собираемся обсудить такие разные методы.
Различные типы методов
Ниже приведены различные методы ML, основанные на некоторых широких категориях:
На основании человеческого контроля
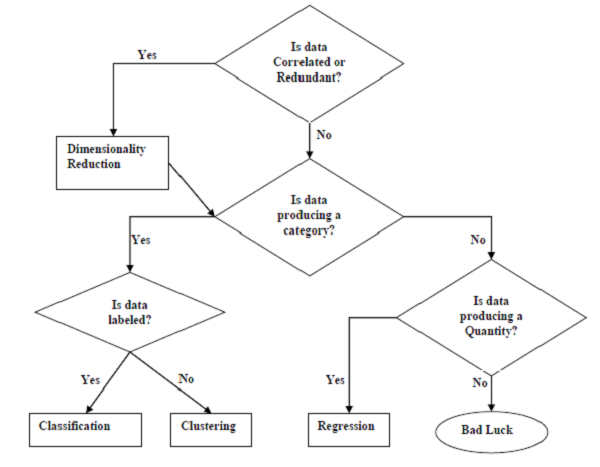
Задачи, подходящие для машинного обучения
Следующая диаграмма показывает, какой тип задачи подходит для различных задач ML —
На основании способности к обучению
В процессе обучения ниже приведены некоторые методы, основанные на способности к обучению.
Пакетное обучение
Во многих случаях у нас есть сквозные системы машинного обучения, в которых нам необходимо обучать модель за один раз, используя все доступные данные обучения. Такой вид метода обучения или алгоритма называется пакетным или автономным обучением . Это называется периодическим или автономным обучением, потому что это однократная процедура, и модель будет обучаться с использованием данных в одной партии. Ниже приведены основные этапы методов пакетного обучения.
-
Шаг 1 — Во-первых, нам нужно собрать все данные обучения для начала обучения модели.
-
Шаг 2 — Теперь начните обучение модели, предоставляя все данные тренировки за один раз.
-
Шаг 3 — Затем прекратите процесс обучения / тренировки, как только вы получите удовлетворительные результаты / результаты.
-
Шаг 4 — Наконец, разверните эту обученную модель в производство. Здесь он будет предсказывать вывод для новой выборки данных.
Шаг 1 — Во-первых, нам нужно собрать все данные обучения для начала обучения модели.
Шаг 2 — Теперь начните обучение модели, предоставляя все данные тренировки за один раз.
Шаг 3 — Затем прекратите процесс обучения / тренировки, как только вы получите удовлетворительные результаты / результаты.
Шаг 4 — Наконец, разверните эту обученную модель в производство. Здесь он будет предсказывать вывод для новой выборки данных.
Онлайн обучение
Это полностью противоположно пакетным или автономным методам обучения. В этих методах обучения данные обучения передаются алгоритму в несколько последовательных пакетов, называемых мини-пакетами. Ниже приведены основные этапы методов онлайн-обучения —
-
Шаг 1 — Во-первых, нам нужно собрать все данные обучения для начала обучения модели.
-
Шаг 2 — Теперь начните обучение модели, предоставив алгоритму мини-пакет обучающих данных.
-
Шаг 3 — Далее нам нужно предоставить мини-пакеты обучающих данных с несколькими приращениями к алгоритму.
-
Шаг 4 — Поскольку он не остановится как пакетное обучение, следовательно, после предоставления целых данных обучения в мини-пакетах, предоставьте новые образцы данных также для него.
-
Шаг 5 — Наконец, он продолжит обучение в течение определенного периода времени на основе новых образцов данных.
Шаг 1 — Во-первых, нам нужно собрать все данные обучения для начала обучения модели.
Шаг 2 — Теперь начните обучение модели, предоставив алгоритму мини-пакет обучающих данных.
Шаг 3 — Далее нам нужно предоставить мини-пакеты обучающих данных с несколькими приращениями к алгоритму.
Шаг 4 — Поскольку он не остановится как пакетное обучение, следовательно, после предоставления целых данных обучения в мини-пакетах, предоставьте новые образцы данных также для него.
Шаг 5 — Наконец, он продолжит обучение в течение определенного периода времени на основе новых образцов данных.
Основан на обобщающем подходе
В процессе обучения ниже приведены некоторые методы, основанные на обобщающих подходах:
Обучение на основе экземпляров
Метод обучения на основе экземпляров является одним из полезных методов, которые создают модели ML путем обобщения на основе входных данных. Он отличается от ранее изученных методов обучения тем, что этот вид обучения включает в себя системы ОД, а также методы, которые используют сами исходные точки данных для получения результатов для более новых выборок данных без построения явной модели обучающих данных.
Проще говоря, обучение на основе экземпляров в основном начинает работать с просмотра точек входных данных, а затем с использованием метрики подобия, которое будет обобщать и прогнозировать новые точки данных.
Модель на основе обучения
В методах обучения, основанных на моделях, итеративный процесс происходит на моделях ML, которые построены на основе различных параметров модели, называемых гиперпараметрами, и в которых входные данные используются для извлечения функций. В этом обучении гиперпараметры оптимизируются на основе различных методов проверки моделей. Вот почему мы можем сказать, что методы обучения, основанные на моделях, используют более традиционный подход ML к обобщению.
Загрузка данных для проектов ML
Предположим, что если вы хотите начать проект ML, то, что вам понадобится в первую очередь? Это данные, которые нам нужно загрузить для запуска любого проекта ML. Что касается данных, наиболее распространенным форматом данных для проектов ОД является CSV (значения, разделенные запятыми).
По сути, CSV — это простой формат файла, который используется для хранения табличных данных (числа и текста), таких как электронная таблица, в виде простого текста. В Python мы можем загружать данные CSV различными способами, но перед загрузкой данных CSV мы должны позаботиться о некоторых соображениях.
Рассмотрение при загрузке данных CSV
Формат данных CSV является наиболее распространенным форматом для данных ML, но мы должны позаботиться о том, чтобы следовать основным соображениям, загружая их в наши проекты ML.
Заголовок файла
В файлах данных CSV заголовок содержит информацию для каждого поля. Мы должны использовать один и тот же разделитель для файла заголовка и для файла данных, потому что это файл заголовка, который определяет, как следует интерпретировать поля данных.
Ниже приведены два случая, связанные с заголовком файла CSV, которые необходимо учитывать:
-
Случай I: Когда файл данных имеет заголовок файла — он автоматически присваивает имена каждому столбцу данных, если файл данных имеет заголовок файла.
-
Случай II: Когда файл данных не имеет заголовка файла — нам нужно назначить имена для каждого столбца данных вручную, если файл данных не имеет заголовка файла.
Случай I: Когда файл данных имеет заголовок файла — он автоматически присваивает имена каждому столбцу данных, если файл данных имеет заголовок файла.
Случай II: Когда файл данных не имеет заголовка файла — нам нужно назначить имена для каждого столбца данных вручную, если файл данных не имеет заголовка файла.
В обоих случаях мы должны явно указать, содержит ли наш CSV-файл заголовок или нет.
Комментарии
Комментарии в любом файле данных имеют свое значение. В файле данных CSV комментарии обозначаются хешем (#) в начале строки. Нам нужно учитывать комментарии при загрузке данных CSV в проекты ML, потому что, если у нас есть комментарии в файле, нам, возможно, потребуется указать, зависит от выбранного нами способа загрузки, ожидать ли эти комментарии или нет.
Разделитель
В файлах данных CSV символ запятой (,) является стандартным разделителем. Роль разделителя заключается в разделении значений в полях. Важно учитывать роль разделителя при загрузке файла CSV в проекты ML, поскольку мы также можем использовать другой разделитель, такой как табуляция или пробел. Но в случае использования разделителя, отличного от стандартного, мы должны указать его явно.
Цитаты
В файлах данных CSV знак двойной кавычки («») является символом кавычки по умолчанию. Важно учитывать роль кавычек при загрузке файла CSV в проекты ML, потому что мы также можем использовать другой символ кавычки, кроме двойной кавычки. Но в случае использования символа кавычки, отличного от стандартного, мы должны указать его явно.
Методы для загрузки файла данных CSV
При работе с проектами ML наиболее важной задачей является правильная загрузка данных в него. Наиболее распространенным форматом данных для проектов ML является CSV, и он имеет различные разновидности и разные трудности для анализа. В этом разделе мы собираемся обсудить три распространенных подхода в Python для загрузки файла данных CSV —
Загрузите CSV со стандартной библиотекой Python
Первый и наиболее используемый подход для загрузки файла данных CSV — это использование стандартной библиотеки Python, которая предоставляет нам множество встроенных модулей, а именно модуль csv и функцию reader () . Ниже приведен пример загрузки файла данных CSV с его помощью —
пример
В этом примере мы используем набор данных радужной оболочки, который можно загрузить в наш локальный каталог. После загрузки файла данных мы можем преобразовать его в
NumPy
массив и использовать его для проектов ML. Ниже приведен скрипт Python для загрузки файла данных CSV —
Во-первых, нам нужно импортировать модуль csv, предоставляемый стандартной библиотекой Python, следующим образом:
import csv
Далее нам нужно импортировать модуль Numpy для преобразования загруженных данных в массив NumPy.
import numpy as np
Теперь укажите полный путь к файлу, хранящемуся в нашем локальном каталоге, с файлом данных CSV —
path = r"c:\iris.csv"
Затем используйте функцию csv.reader () для чтения данных из файла CSV —
with open(path,'r') as f: reader = csv.reader(f,delimiter = ',') headers = next(reader) data = list(reader) data = np.array(data).astype(float)
Мы можем напечатать имена заголовков с помощью следующей строки скрипта —
print(headers)
Следующая строка скрипта напечатает форму данных, т.е. количество строк и столбцов в файле —
print(data.shape)
Следующая строка скрипта даст первые три строки файла данных —
print(data[:3])
Выход
['sepal_length', 'sepal_width', 'petal_length', 'petal_width'] (150, 4) [[5.1 3.5 1.4 0.2] [4.9 3. 1.4 0.2] [4.7 3.2 1.3 0.2]]
Загрузите CSV с NumPy
Другой подход к загрузке файла данных CSV — это функции NumPy и numpy.loadtxt () . Ниже приведен пример загрузки файла данных CSV с его помощью —
пример
В этом примере мы используем набор данных индейцев Pima, содержащий данные пациентов с диабетом. Этот набор данных является числовым набором данных без заголовка. Его также можно загрузить в наш локальный каталог. После загрузки файла данных мы можем преобразовать его в массив NumPy и использовать его для проектов ML. Ниже приведен скрипт Python для загрузки файла данных CSV —
from numpy import loadtxt path = r"C:\pima-indians-diabetes.csv" datapath= open(path, 'r') data = loadtxt(datapath, delimiter=",") print(data.shape) print(data[:3])
Выход
(768, 9) [[ 6. 148. 72. 35. 0. 33.6 0.627 50. 1.] [ 1. 85. 66. 29. 0. 26.6 0.351 31. 0.] [ 8. 183. 64. 0. 0. 23.3 0.672 32. 1.]]
Загрузить CSV с пандами
Другой подход к загрузке файла данных CSV — использование функций Pandas и pandas.read_csv () . Это очень гибкая функция, которая возвращает pandas.DataFrame, которую можно сразу использовать для построения графиков. Ниже приведен пример загрузки файла данных CSV с его помощью —
пример
Здесь мы будем реализовывать два скрипта Python, первый — с набором данных Iris, имеющим заголовки, а другой — с использованием набора данных индейцев Pima, который представляет собой числовой набор данных без заголовка. Оба набора данных могут быть загружены в локальный каталог.
Script-1
Ниже приведен скрипт Python для загрузки файла данных CSV с использованием набора данных Pandas на Iris —
from pandas import read_csv path = r"C:\iris.csv" data = read_csv(path) print(data.shape) print(data[:3])
Выход
(150, 4) sepal_length sepal_width petal_length petal_width 0 5.1 3.5 1.4 0.2 1 4.9 3.0 1.4 0.2 2 4.7 3.2 1.3 0.2
Script-2
Ниже приведен скрипт Python для загрузки файла данных CSV, а также указание имен заголовков с использованием Pandas в наборе данных диабета индейцев Pima.
from pandas import read_csv path = r"C:\pima-indians-diabetes.csv" headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(path, names=headernames) print(data.shape) print(data[:3])
Выход
(768, 9) preg plas pres skin test mass pedi age class 0 6 148 72 35 0 33.6 0.627 50 1 1 1 85 66 29 0 26.6 0.351 31 0 2 8 183 64 0 0 23.3 0.672 32 1
Различие между тремя вышеупомянутыми подходами для загрузки файла данных CSV легко понять с помощью приведенных примеров.
ML — Понимание данных со статистикой
Вступление
Работая с проектами машинного обучения, мы обычно игнорируем две самые важные части, называемые математикой и данными . Это потому, что мы знаем, что ML — это подход, основанный на данных, и наша модель ML даст только такие же хорошие или плохие результаты, как и данные, которые мы ей предоставили.
В предыдущей главе мы обсуждали, как мы можем загрузить данные CSV в наш проект ML, но было бы хорошо понять данные перед их загрузкой. Мы можем понять данные двумя способами: с помощью статистики и визуализации.
В этой главе, с помощью следующих рецептов Python, мы разберем данные ML со статистикой.
Глядя на необработанные данные
Самый первый рецепт для просмотра ваших необработанных данных. Важно смотреть на необработанные данные, потому что понимание, которое мы получим после просмотра необработанных данных, повысит наши шансы на лучшую предварительную обработку, а также обработку данных для проектов ML.
Ниже приведен сценарий Python, реализованный с использованием функции head () Pandas DataFrame в наборе данных диабета индейцев Пима для просмотра первых 50 строк, чтобы лучше понять его.
пример
from pandas import read_csv path = r"C:\pima-indians-diabetes.csv" headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(path, names=headernames) print(data.head(50))
Выход
preg plas pres skin test mass pedi age class 0 6 148 72 35 0 33.6 0.627 50 1 1 1 85 66 29 0 26.6 0.351 31 0 2 8 183 64 0 0 23.3 0.672 32 1 3 1 89 66 23 94 28.1 0.167 21 0 4 0 137 40 35 168 43.1 2.288 33 1 5 5 116 74 0 0 25.6 0.201 30 0 6 3 78 50 32 88 31.0 0.248 26 1 7 10 115 0 0 0 35.3 0.134 29 0 8 2 197 70 45 543 30.5 0.158 53 1 9 8 125 96 0 0 0.0 0.232 54 1 10 4 110 92 0 0 37.6 0.191 30 0 11 10 168 74 0 0 38.0 0.537 34 1 12 10 139 80 0 0 27.1 1.441 57 0 13 1 189 60 23 846 30.1 0.398 59 1 14 5 166 72 19 175 25.8 0.587 51 1 15 7 100 0 0 0 30.0 0.484 32 1 16 0 118 84 47 230 45.8 0.551 31 1 17 7 107 74 0 0 29.6 0.254 31 1 18 1 103 30 38 83 43.3 0.183 33 0 19 1 115 70 30 96 34.6 0.529 32 1 20 3 126 88 41 235 39.3 0.704 27 0 21 8 99 84 0 0 35.4 0.388 50 0 22 7 196 90 0 0 39.8 0.451 41 1 23 9 119 80 35 0 29.0 0.263 29 1 24 11 143 94 33 146 36.6 0.254 51 1 25 10 125 70 26 115 31.1 0.205 41 1 26 7 147 76 0 0 39.4 0.257 43 1 27 1 97 66 15 140 23.2 0.487 22 0 28 13 145 82 19 110 22.2 0.245 57 0 29 5 117 92 0 0 34.1 0.337 38 0 30 5 109 75 26 0 36.0 0.546 60 0 31 3 158 76 36 245 31.6 0.851 28 1 32 3 88 58 11 54 24.8 0.267 22 0 33 6 92 92 0 0 19.9 0.188 28 0 34 10 122 78 31 0 27.6 0.512 45 0 35 4 103 60 33 192 24.0 0.966 33 0 36 11 138 76 0 0 33.2 0.420 35 0 37 9 102 76 37 0 32.9 0.665 46 1 38 2 90 68 42 0 38.2 0.503 27 1 39 4 111 72 47 207 37.1 1.390 56 1 40 3 180 64 25 70 34.0 0.271 26 0 41 7 133 84 0 0 40.2 0.696 37 0 42 7 106 92 18 0 22.7 0.235 48 0 43 9 171 110 24 240 45.4 0.721 54 1 44 7 159 64 0 0 27.4 0.294 40 0 45 0 180 66 39 0 42.0 1.893 25 1 46 1 146 56 0 0 29.7 0.564 29 0 47 2 71 70 27 0 28.0 0.586 22 0 48 7 103 66 32 0 39.1 0.344 31 1 49 7 105 0 0 0 0.0 0.305 24 0
Из вышеприведенного вывода мы можем наблюдать, что в первом столбце указан номер строки, который может быть очень полезен для ссылки на конкретное наблюдение.
Проверка размеров данных
Полезно всегда знать, сколько данных, с точки зрения строк и столбцов, у нас есть для нашего проекта ML. Причины этого —
-
Предположим, что если у нас слишком много строк и столбцов, тогда потребуется много времени для запуска алгоритма и обучения модели.
-
Предположим, что если у нас слишком мало строк и столбцов, тогда у нас не будет достаточно данных, чтобы хорошо обучить модель.
Предположим, что если у нас слишком много строк и столбцов, тогда потребуется много времени для запуска алгоритма и обучения модели.
Предположим, что если у нас слишком мало строк и столбцов, тогда у нас не будет достаточно данных, чтобы хорошо обучить модель.
Ниже приведен скрипт Python, реализованный путем печати свойства shape в Pandas Data Frame. Мы собираемся реализовать его на наборе данных радужной оболочки для получения общего количества строк и столбцов в нем.
пример
from pandas import read_csv path = r"C:\iris.csv" data = read_csv(path) print(data.shape)
Выход
(150, 4)
Из результатов мы можем легко заметить, что набор данных iris, который мы будем использовать, имеет 150 строк и 4 столбца.
Получение типа данных каждого атрибута
Еще одна полезная практика — знать тип данных каждого атрибута. Причина в том, что согласно требованию иногда нам может потребоваться преобразовать один тип данных в другой. Например, нам может потребоваться преобразовать строку в число с плавающей запятой или int для представления категориальных или порядковых значений. Мы можем получить представление о типе данных атрибута, посмотрев на необработанные данные, но другой способ — использовать свойство dtypes в Pandas DataFrame. С помощью свойства dtypes мы можем классифицировать каждый тип данных атрибутов. Это можно понять с помощью следующего скрипта Python —
пример
from pandas import read_csv path = r"C:\iris.csv" data = read_csv(path) print(data.dtypes)
Выход
sepal_length float64 sepal_width float64 petal_length float64 petal_width float64 dtype: object
Исходя из вышеприведенного вывода, мы можем легко получить типы данных каждого атрибута.
Статистическая сводка данных
Мы обсудили рецепт Python, чтобы получить форму, то есть количество строк и столбцов данных, но много раз нам нужно было просматривать сводки по этой форме данных. Это можно сделать с помощью функции description () Pandas DataFrame, которая дополнительно предоставляет следующие 8 статистических свойств каждого атрибута данных —
- подсчитывать
- Имею в виду
- Стандартное отклонение
- Минимальное значение
- Максимальное значение
- 25%
- Медиана то есть 50%
- 75%
пример
from pandas import read_csv from pandas import set_option path = r"C:\pima-indians-diabetes.csv" names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(path, names=names) set_option('display.width', 100) set_option('precision', 2) print(data.shape) print(data.describe())
Выход
(768, 9)
preg plas pres skin test mass pedi age class
count 768.00 768.00 768.00 768.00 768.00 768.00 768.00 768.00 768.00
mean 3.85 120.89 69.11 20.54 79.80 31.99 0.47 33.24 0.35
std 3.37 31.97 19.36 15.95 115.24 7.88 0.33 11.76 0.48
min 0.00 0.00 0.00 0.00 0.00 0.00 0.08 21.00 0.00
25% 1.00 99.00 62.00 0.00 0.00 27.30 0.24 24.00 0.00
50% 3.00 117.00 72.00 23.00 30.50 32.00 0.37 29.00 0.00
75% 6.00 140.25 80.00 32.00 127.25 36.60 0.63 41.00 1.00
max 17.00 199.00 122.00 99.00 846.00 67.10 2.42 81.00 1.00
Исходя из вышеприведенного вывода, мы можем наблюдать статистическую сводку данных набора данных Pima Indian Diabetes вместе с формой данных.
Просмотр распределения классов
Статистика распределения классов полезна в задачах классификации, где нам нужно знать баланс значений классов. Важно знать распределение значений классов, потому что если у нас очень несбалансированное распределение классов, то есть один класс имеет намного больше наблюдений, чем другой класс, то он может нуждаться в специальной обработке на этапе подготовки данных нашего проекта ML. Мы можем легко получить распределение классов в Python с помощью Pandas DataFrame.
пример
from pandas import read_csv path = r"C:\pima-indians-diabetes.csv" names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(path, names=names) count_class = data.groupby('class').size() print(count_class)
Выход
Class 0 500 1 268 dtype: int64
Из вышеприведенного вывода ясно видно, что количество наблюдений с классом 0 почти вдвое превышает количество наблюдений с классом 1.
Проверка корреляции между атрибутами
Связь между двумя переменными называется корреляцией. В статистике наиболее распространенным методом расчета корреляции является коэффициент корреляции Пирсона. Может иметь три значения следующим образом:
-
Значение коэффициента = 1 — представляет полную положительную корреляцию между переменными.
-
Значение коэффициента = -1 — представляет полную отрицательную корреляцию между переменными.
-
Значение коэффициента = 0 — не представляет никакой корреляции между переменными.
Значение коэффициента = 1 — представляет полную положительную корреляцию между переменными.
Значение коэффициента = -1 — представляет полную отрицательную корреляцию между переменными.
Значение коэффициента = 0 — не представляет никакой корреляции между переменными.
Для нас всегда полезно проанализировать попарные корреляции атрибутов в нашем наборе данных, прежде чем использовать его в проекте ML, потому что некоторые алгоритмы машинного обучения, такие как линейная регрессия и логистическая регрессия, будут работать плохо, если у нас будут сильно коррелированные атрибуты. В Python мы можем легко рассчитать корреляционную матрицу атрибутов набора данных с помощью функции corr () в Pandas DataFrame.
пример
from pandas import read_csv from pandas import set_option path = r"C:\pima-indians-diabetes.csv" names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(path, names=names) set_option('display.width', 100) set_option('precision', 2) correlations = data.corr(method='pearson') print(correlations)
Выход
preg plas pres skin test mass pedi age class preg 1.00 0.13 0.14 -0.08 -0.07 0.02 -0.03 0.54 0.22 plas 0.13 1.00 0.15 0.06 0.33 0.22 0.14 0.26 0.47 pres 0.14 0.15 1.00 0.21 0.09 0.28 0.04 0.24 0.07 skin -0.08 0.06 0.21 1.00 0.44 0.39 0.18 -0.11 0.07 test -0.07 0.33 0.09 0.44 1.00 0.20 0.19 -0.04 0.13 mass 0.02 0.22 0.28 0.39 0.20 1.00 0.14 0.04 0.29 pedi -0.03 0.14 0.04 0.18 0.19 0.14 1.00 0.03 0.17 age 0.54 0.26 0.24 -0.11 -0.04 0.04 0.03 1.00 0.24 class 0.22 0.47 0.07 0.07 0.13 0.29 0.17 0.24 1.00
Матрица в вышеприведенном выводе дает корреляцию между всеми парами атрибута в наборе данных.
Обзор перекоса распределения атрибутов
Асимметрия может быть определена как распределение, которое предполагается гауссовым, но выглядит искаженным или смещенным в том или ином направлении или либо влево, либо вправо. Проверка асимметрии атрибутов является одной из важных задач по следующим причинам:
-
Наличие асимметрии в данных требует корректировки на этапе подготовки данных, чтобы мы могли получить больше точности из нашей модели.
-
В большинстве алгоритмов ML предполагается, что данные имеют гауссово распределение, т.е. либо нормаль данных изогнутого колокола.
Наличие асимметрии в данных требует корректировки на этапе подготовки данных, чтобы мы могли получить больше точности из нашей модели.
В большинстве алгоритмов ML предполагается, что данные имеют гауссово распределение, т.е. либо нормаль данных изогнутого колокола.
В Python мы можем легко рассчитать перекос каждого атрибута с помощью функции skew () в DataFrame Pandas.
пример
from pandas import read_csv path = r"C:\pima-indians-diabetes.csv" names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(path, names=names) print(data.skew())
Выход
preg 0.90 plas 0.17 pres -1.84 skin 0.11 test 2.27 mass -0.43 pedi 1.92 age 1.13 class 0.64 dtype: float64
Из вышеприведенного вывода можно наблюдать положительный или отрицательный перекос. Если значение ближе к нулю, то оно показывает меньший перекос.
ML — понимание данных с помощью визуализации
Вступление
В предыдущей главе мы обсудили важность данных для алгоритмов машинного обучения, а также некоторые рецепты Python для понимания данных со статистикой. Существует еще один способ, называемый визуализация, для понимания данных.
С помощью визуализации данных мы можем увидеть, как выглядят данные и какая корреляция содержится в атрибутах данных. Это самый быстрый способ узнать, соответствуют ли функции выводу. С помощью следующих рецептов Python мы можем понять данные ML со статистикой.
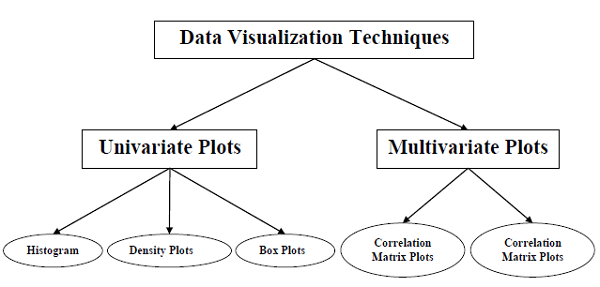
Одномерные графики: независимое понимание атрибутов
Самый простой тип визуализации — визуализация с одной переменной или «одномерная». С помощью одномерной визуализации мы можем понять каждый атрибут нашего набора данных независимо. Ниже приведены некоторые приемы в Python для реализации одномерной визуализации:
| Sr.No | Одномерные графики и описание |
|---|---|
| 1 | Гистограммы
Гистограммы группируют данные в бункерах и это самый быстрый способ получить представление о распределении каждого атрибута в наборе данных. |
| 2 | Графики плотности
Еще одним быстрым и простым способом получения распределения каждого атрибута является график плотности. |
| 3 | Коробка и Вискерские участки
Графики Бокса и Вискера, которые также называются боксплотами, являются еще одним полезным методом для анализа распределения распределения каждого атрибута. |
Гистограммы группируют данные в бункерах и это самый быстрый способ получить представление о распределении каждого атрибута в наборе данных.
Еще одним быстрым и простым способом получения распределения каждого атрибута является график плотности.
Графики Бокса и Вискера, которые также называются боксплотами, являются еще одним полезным методом для анализа распределения распределения каждого атрибута.
Многомерные графики: взаимодействие между несколькими переменными
Другим типом визуализации является многопараметрическая или «многомерная» визуализация. С помощью многовариантной визуализации мы можем понять взаимодействие между несколькими атрибутами нашего набора данных. Ниже приведены некоторые приемы в Python для реализации многомерной визуализации.
| Sr.No | Многовариантные участки и описание |
|---|---|
| 1 | Матрица корреляции
Корреляция является показателем изменений между двумя переменными. |
| 2 | Scatter Matrix Plot
Диаграммы разброса показывают, насколько одна переменная подвержена влиянию другой или отношения между ними с помощью точек в двух измерениях. |
Корреляция является показателем изменений между двумя переменными.
Диаграммы разброса показывают, насколько одна переменная подвержена влиянию другой или отношения между ними с помощью точек в двух измерениях.
Машинное обучение — подготовка данных
Вступление
Алгоритмы машинного обучения полностью зависят от данных, потому что это наиболее важный аспект, который делает возможным обучение модели. С другой стороны, если мы не сможем разобраться в этих данных, прежде чем передавать их в алгоритмы ML, машина будет бесполезна. Проще говоря, нам всегда нужно предоставлять правильные данные, то есть данные в правильном масштабе, формате и содержащие значимые функции, для решения проблемы, которую мы хотим решить машиной.
Это делает подготовку данных наиболее важным шагом в процессе ОД. Подготовка данных может быть определена как процедура, которая делает наш набор данных более подходящим для процесса ML.
Почему предварительная обработка данных?
После выбора необработанных данных для обучения ОД наиболее важной задачей является предварительная обработка данных. В широком смысле, предварительная обработка данных преобразует выбранные данные в форму, с которой мы можем работать или можем передавать алгоритмы ML. Нам всегда нужно предварительно обрабатывать наши данные, чтобы они могли соответствовать алгоритму машинного обучения.
Методы предварительной обработки данных
У нас есть следующие методы предварительной обработки данных, которые можно применять к набору данных для получения данных для алгоритмов ML —
пересчет
Скорее всего, наш набор данных состоит из атрибутов с различным масштабом, но мы не можем предоставить такие данные алгоритму ML, поэтому он требует масштабирования. Масштабирование данных гарантирует, что атрибуты имеют одинаковый масштаб. Обычно атрибуты масштабируются в диапазоне от 0 до 1. Алгоритмы ML, такие как градиентный спуск и k-ближайших соседей, требуют масштабированных данных. Мы можем изменить масштаб данных с помощью класса Python библиотеки Scikit-Learn MinMaxScaler .
пример
В этом примере мы будем масштабировать данные набора данных диабета индейцев Пима, которые мы использовали ранее. Сначала будут загружены данные CSV (как это делалось в предыдущих главах), а затем с помощью класса MinMaxScaler они будут масштабироваться в диапазоне от 0 до 1.
Первые несколько строк следующего скрипта такие же, как мы писали в предыдущих главах при загрузке данных CSV.
from pandas import read_csv from numpy import set_printoptions from sklearn import preprocessing path = r'C:\pima-indians-diabetes.csv' names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] dataframe = read_csv(path, names=names) array = dataframe.values
Теперь мы можем использовать класс MinMaxScaler для изменения масштаба данных в диапазоне от 0 до 1.
data_scaler = preprocessing.MinMaxScaler(feature_range=(0,1)) data_rescaled = data_scaler.fit_transform(array)
Мы также можем суммировать данные для вывода по нашему выбору. Здесь мы устанавливаем точность в 1 и показываем первые 10 строк в выводе.
set_printoptions(precision=1)
print ("\nScaled data:\n", data_rescaled[0:10])
Выход
Scaled data: [[0.4 0.7 0.6 0.4 0. 0.5 0.2 0.5 1. ] [0.1 0.4 0.5 0.3 0. 0.4 0.1 0.2 0. ] [0.5 0.9 0.5 0. 0. 0.3 0.3 0.2 1. ] [0.1 0.4 0.5 0.2 0.1 0.4 0. 0. 0. ] [0. 0.7 0.3 0.4 0.2 0.6 0.9 0.2 1. ] [0.3 0.6 0.6 0. 0. 0.4 0.1 0.2 0. ] [0.2 0.4 0.4 0.3 0.1 0.5 0.1 0.1 1. ] [0.6 0.6 0. 0. 0. 0.5 0. 0.1 0. ] [0.1 1. 0.6 0.5 0.6 0.5 0. 0.5 1. ] [0.5 0.6 0.8 0. 0. 0. 0.1 0.6 1. ]]
Из вышеприведенного вывода все данные были перераспределены в диапазоне от 0 до 1.
нормализация
Еще одним полезным методом предварительной обработки данных является нормализация. Это используется для изменения масштаба каждой строки данных, чтобы иметь длину 1. Это в основном полезно в наборе разреженных данных, где у нас много нулей. Мы можем изменить масштаб данных с помощью класса Normalizer библиотеки Python scikit-learn .
Типы нормализации
В машинном обучении существует два типа методов предварительной обработки нормализации:
бинаризации
Как следует из названия, это метод, с помощью которого мы можем сделать наши данные двоичными. Мы можем использовать двоичный порог для того, чтобы сделать наши данные двоичными. Значения выше этого порогового значения будут преобразованы в 1, а ниже этого порогового значения будут преобразованы в 0.
Например, если мы выберем пороговое значение = 0,5, то значение набора данных выше этого станет 1, а ниже этого станет 0. Поэтому мы можем назвать его бинаризацией данных или пороговым значением данных. Этот метод полезен, когда у нас есть вероятности в нашем наборе данных и мы хотим преобразовать их в четкие значения.
Мы можем преобразовать данные в двоичную форму с помощью класса Python библиотеки Scinit-learn Binarizer.
пример
В этом примере мы будем масштабировать данные набора данных диабета индейцев Пима, которые мы использовали ранее. Сначала будут загружены данные CSV, а затем с помощью класса Binarizer они будут преобразованы в двоичные значения, то есть 0 и 1, в зависимости от порогового значения. Мы берем 0,5 в качестве порогового значения.
Первые несколько строк следующего скрипта такие же, как мы писали в предыдущих главах при загрузке данных CSV.
from pandas import read_csv from sklearn.preprocessing import Binarizer path = r'C:\pima-indians-diabetes.csv' names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] dataframe = read_csv(path, names=names) array = dataframe.values
Теперь мы можем использовать класс Binarize для преобразования данных в двоичные значения.
binarizer = Binarizer(threshold=0.5).fit(array) Data_binarized = binarizer.transform(array)
Здесь мы показываем первые 5 строк в выводе.
print ("\nBinary data:\n", Data_binarized [0:5])
Выход
Binary data: [[1. 1. 1. 1. 0. 1. 1. 1. 1.] [1. 1. 1. 1. 0. 1. 0. 1. 0.] [1. 1. 1. 0. 0. 1. 1. 1. 1.] [1. 1. 1. 1. 1. 1. 0. 1. 0.] [0. 1. 1. 1. 1. 1. 1. 1. 1.]]
Стандартизация
Еще один полезный метод предварительной обработки данных, который в основном используется для преобразования атрибутов данных с гауссовым распределением. Он отличает среднее значение и SD (стандартное отклонение) от стандартного гауссовского распределения со средним значением 0 и SD от 1. Этот метод полезен в алгоритмах ML, таких как линейная регрессия, логистическая регрессия, которая предполагает гауссовское распределение во входном наборе данных и производит лучше результаты с измененными данными. Мы можем стандартизировать данные (среднее = 0 и SD = 1) с помощью StandardScaler класса библиотеки Python scikit-learn .
пример
В этом примере мы будем масштабировать данные набора данных диабета индейцев Пима, которые мы использовали ранее. Сначала будут загружены данные CSV, а затем с помощью класса StandardScaler они будут преобразованы в гауссово распределение со средним значением = 0 и SD = 1.
Первые несколько строк следующего скрипта такие же, как мы писали в предыдущих главах при загрузке данных CSV.
from sklearn.preprocessing import StandardScaler from pandas import read_csv from numpy import set_printoptions path = r'C:\pima-indians-diabetes.csv' names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] dataframe = read_csv(path, names=names) array = dataframe.values
Теперь мы можем использовать класс StandardScaler для изменения масштаба данных.
data_scaler = StandardScaler().fit(array) data_rescaled = data_scaler.transform(array)
Мы также можем суммировать данные для вывода по нашему выбору. Здесь мы устанавливаем точность до 2 и показываем первые 5 строк в выводе.
set_printoptions(precision=2)
print ("\nRescaled data:\n", data_rescaled [0:5])
Выход
Rescaled data: [[ 0.64 0.85 0.15 0.91 -0.69 0.2 0.47 1.43 1.37] [-0.84 -1.12 -0.16 0.53 -0.69 -0.68 -0.37 -0.19 -0.73] [ 1.23 1.94 -0.26 -1.29 -0.69 -1.1 0.6 -0.11 1.37] [-0.84 -1. -0.16 0.15 0.12 -0.49 -0.92 -1.04 -0.73] [-1.14 0.5 -1.5 0.91 0.77 1.41 5.48 -0.02 1.37]]
Маркировка данных
Мы обсудили важность хороших данных для алгоритмов ML, а также некоторые методы предварительной обработки данных перед их отправкой в алгоритмы ML. Еще один аспект в этом отношении — маркировка данных. Также очень важно отправлять данные в алгоритмы ML с надлежащей маркировкой. Например, в случае проблем с классификацией в данных имеется множество меток в виде слов, цифр и т. Д.
Что такое кодирование меток?
Большинство функций sklearn ожидают, что данные с числовыми метками, а не надписями слов. Следовательно, нам необходимо преобразовать такие метки в числовые метки. Этот процесс называется кодированием меток. Мы можем выполнить кодирование меток данных с помощью функции LabelEncoder () библиотеки Python scikit-learn .
пример
В следующем примере скрипт Python выполнит кодирование метки.
Сначала импортируйте необходимые библиотеки Python следующим образом:
import numpy as np from sklearn import preprocessing
Теперь нам нужно указать следующие метки ввода:
input_labels = ['red','black','red','green','black','yellow','white']
Следующая строка кода создаст кодировщик меток и обучит его.
encoder = preprocessing.LabelEncoder() encoder.fit(input_labels)
Следующие строки скрипта будут проверять производительность путем кодирования случайного упорядоченного списка —
test_labels = ['green','red','black'] encoded_values = encoder.transform(test_labels) print("\nLabels =", test_labels) print("Encoded values =", list(encoded_values)) encoded_values = [3,0,4,1] decoded_list = encoder.inverse_transform(encoded_values)
Мы можем получить список закодированных значений с помощью следующего скрипта Python —
print("\nEncoded values =", encoded_values)
print("\nDecoded labels =", list(decoded_list))
Выход
Labels = ['green', 'red', 'black'] Encoded values = [1, 2, 0] Encoded values = [3, 0, 4, 1] Decoded labels = ['white', 'black', 'yellow', 'green']
Машинное обучение — выбор характеристик данных
В предыдущей главе мы подробно рассмотрели, как предварительно обрабатывать и подготавливать данные для машинного обучения. В этой главе давайте подробно разберемся с выбором функции данных и различными аспектами, связанными с ней.
Важность выбора функции данных
Производительность модели машинного обучения прямо пропорциональна характеристикам данных, используемым для ее обучения. На производительность модели ML будет оказано негативное влияние, если предоставляемые ей функции данных не будут иметь значения. С другой стороны, использование соответствующих функций данных может повысить точность модели ML, особенно линейной и логистической регрессии.
Теперь возникает вопрос, что такое автоматический выбор функции? Он может быть определен как процесс, с помощью которого мы выбираем те функции в наших данных, которые наиболее актуальны для выходной или прогнозной переменной, в которой мы заинтересованы. Это также называется выбором атрибутов.
Ниже приведены некоторые преимущества автоматического выбора функций перед моделированием данных.
-
Выполнение выбора функции перед моделированием данных уменьшит перенастройку.
-
Выбор функции перед моделированием данных повысит точность модели ML.
-
Выбор функций перед моделированием данных сократит время обучения
Выполнение выбора функции перед моделированием данных уменьшит перенастройку.
Выбор функции перед моделированием данных повысит точность модели ML.
Выбор функций перед моделированием данных сократит время обучения
Методы выбора функций
Ниже приведены методы автоматического выбора функций, которые мы можем использовать для моделирования данных ML в Python.
Одномерный выбор
Этот метод выбора функций очень полезен при выборе этих функций с помощью статистического тестирования, которые наиболее тесно связаны с переменными прогнозирования. Мы можем реализовать метод выбора одномерного объекта с помощью SelectKBest0class библиотеки Python scikit-learn.
пример
В этом примере мы будем использовать набор данных Pima Indians Diabetes, чтобы выбрать 4 из атрибутов, имеющих лучшие характеристики, с помощью статистического критерия хи-квадрат.
from pandas import read_csv from numpy import set_printoptions from sklearn.feature_selection import SelectKBest from sklearn.feature_selection import chi2 path = r'C:\pima-indians-diabetes.csv' names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] dataframe = read_csv(path, names=names) array = dataframe.values
Далее мы разделим массив на компоненты ввода и вывода —
X = array[:,0:8] Y = array[:,8]
Следующие строки кода выберут лучшие функции из набора данных —
test = SelectKBest(score_func=chi2, k=4) fit = test.fit(X,Y)
Мы также можем суммировать данные для вывода по нашему выбору. Здесь мы устанавливаем точность до 2 и показываем 4 атрибута данных с лучшими характеристиками вместе с лучшим показателем каждого атрибута —
set_printoptions(precision=2)
print(fit.scores_)
featured_data = fit.transform(X)
print ("\nFeatured data:\n", featured_data[0:4])
Выход
[ 111.52 1411.89 17.61 53.11 2175.57 127.67 5.39 181.3 ] Featured data: [[148. 0. 33.6 50. ] [ 85. 0. 26.6 31. ] [ 183. 0. 23.3 32. ] [ 89. 94. 28.1 21. ]]
Удаление рекурсивных функций
Как следует из названия, метод выбора функций RFE (рекурсивное исключение объектов) рекурсивно удаляет атрибуты и строит модель с оставшимися атрибутами. Мы можем реализовать метод выбора функций RFE с помощью класса RFE библиотеки Python scikit-learn .
пример
В этом примере мы будем использовать RFE с алгоритмом логистической регрессии, чтобы выбрать 3 лучших атрибута с лучшими характеристиками из набора данных диабета индейцев Пима.
from pandas import read_csv from sklearn.feature_selection import RFE from sklearn.linear_model import LogisticRegression path = r'C:\pima-indians-diabetes.csv' names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] dataframe = read_csv(path, names=names) array = dataframe.values
Далее мы разделим массив на входные и выходные компоненты —
X = array[:,0:8] Y = array[:,8]
Следующие строки кода выберут лучшие функции из набора данных —
model = LogisticRegression() rfe = RFE(model, 3) fit = rfe.fit(X, Y) print("Number of Features: %d") print("Selected Features: %s") print("Feature Ranking: %s")
Выход
Number of Features: 3 Selected Features: [ True False False False False True True False] Feature Ranking: [1 2 3 5 6 1 1 4]
В приведенном выше выводе видно, что RFE выбирает preg, mass и pedi в качестве первых 3 лучших функций. Они отмечены как 1 на выходе.
Анализ основных компонентов (PCA)
PCA, обычно называемая техникой сокращения данных, является очень полезной техникой выбора признаков, поскольку она использует линейную алгебру для преобразования набора данных в сжатую форму. Мы можем реализовать метод выбора функций PCA с помощью класса PCA библиотеки Python scikit-learn. Мы можем выбрать количество основных компонентов в выводе.
пример
В этом примере мы будем использовать PCA, чтобы выбрать 3 лучших компонента из набора данных диабета индейцев Pima.
from pandas import read_csv from sklearn.decomposition import PCA path = r'C:\pima-indians-diabetes.csv' names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] dataframe = read_csv(path, names=names) array = dataframe.values
Далее мы разделим массив на компоненты ввода и вывода —
X = array[:,0:8] Y = array[:,8]
Следующие строки кода извлекут функции из набора данных —
pca = PCA(n_components = 3) fit = pca.fit(X) print("Explained Variance: %s") % fit.explained_variance_ratio_ print(fit.components_)
Выход
Explained Variance: [ 0.88854663 0.06159078 0.02579012] [[ -2.02176587e-03 9.78115765e-02 1.60930503e-02 6.07566861e-02 9.93110844e-01 1.40108085e-02 5.37167919e-04 -3.56474430e-03] [ 2.26488861e-02 9.72210040e-01 1.41909330e-01 -5.78614699e-02 -9.46266913e-02 4.69729766e-02 8.16804621e-04 1.40168181e-01] [ -2.24649003e-02 1.43428710e-01 -9.22467192e-01 -3.07013055e-01 2.09773019e-02 -1.32444542e-01 -6.39983017e-04 -1.25454310e-01]]
Из вышеприведенного вывода мы можем наблюдать, что 3 главных компонента мало похожи на исходные данные.
Важность функции
Как следует из названия, техника важности функций используется для выбора важных функций. Он в основном использует обученный контролируемый классификатор для выбора функций. Мы можем реализовать эту технику выбора функций с помощью класса ExtraTreeClassifier библиотеки Python scikit-learn.
пример
В этом примере мы будем использовать ExtraTreeClassifier для выбора функций из набора данных диабета индейцев Pima.
from pandas import read_csv from sklearn.ensemble import ExtraTreesClassifier path = r'C:\Desktop\pima-indians-diabetes.csv' names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] dataframe = read_csv(data, names=names) array = dataframe.values
Далее мы разделим массив на компоненты ввода и вывода —
X = array[:,0:8] Y = array[:,8]
Следующие строки кода извлекут функции из набора данных —
model = ExtraTreesClassifier() model.fit(X, Y) print(model.feature_importances_)
Выход
[ 0.11070069 0.2213717 0.08824115 0.08068703 0.07281761 0.14548537 0.12654214 0.15415431]
Из результатов мы можем наблюдать, что есть оценки для каждого атрибута. Чем выше оценка, тем выше важность этого атрибута.
Алгоритмы классификации — Введение
Введение в классификацию
Классификация может быть определена как процесс прогнозирования класса или категории по наблюдаемым значениям или заданным точкам данных. Категоризованный вывод может иметь форму, такую как «Черный» или «Белый» или «Спам» или «Нет спама».
Математически классификация — это задача приближения функции отображения (f) от входных переменных (X) к выходным переменным (Y). Это в основном относится к контролируемому машинному обучению, в котором цели также предоставляются вместе с набором входных данных.
Примером проблемы классификации может быть обнаружение спама в электронных письмах. Может быть только две категории вывода: «спам» и «нет спама»; следовательно, это двоичная классификация типов.
Чтобы реализовать эту классификацию, нам сначала нужно обучить классификатор. В этом примере электронные письма «спам» и «не спам» будут использоваться в качестве обучающих данных. После успешного обучения классификатора его можно использовать для обнаружения неизвестного электронного письма.
Типы учащихся в классификации
У нас есть два типа учащихся в соответствии с проблемами классификации —
Ленивые ученики
Как следует из названия, такие ученики ждут появления данных тестирования после сохранения данных обучения. Классификация проводится только после получения данных тестирования. Они тратят меньше времени на обучение, но больше времени на прогнозирование. Примерами ленивых учеников являются K-ближайший сосед и рассуждения на основе случая.
Нетерпеливые ученики
В отличие от ленивых учеников, нетерпеливые ученики строят классификационную модель, не дожидаясь появления данных тестирования после сохранения обучающих данных. Они тратят больше времени на тренировки, но меньше на прогнозирование. Примерами усердных учеников являются деревья решений, наивные байесовские и искусственные нейронные сети (ANN).
Создание классификатора в Python
Scikit-learn, библиотека Python для машинного обучения может использоваться для построения классификатора в Python. Шаги для создания классификатора в Python следующие:
Шаг 1: Импорт необходимого пакета Python
Для построения классификатора с помощью scikit-learn нам нужно его импортировать. Мы можем импортировать его, используя следующий скрипт —
import sklearn
Шаг 2: Импорт набора данных
После импорта необходимого пакета нам понадобится набор данных для построения модели прогнозирования классификации. Мы можем импортировать его из набора данных sklearn или использовать другой согласно нашему требованию. Мы собираемся использовать диагностическую базу данных Sklearn по раку молочной железы в Висконсине. Мы можем импортировать его с помощью следующего скрипта —
from sklearn.datasets import load_breast_cancer
Следующий скрипт загрузит набор данных;
data = load_breast_cancer()
Нам также необходимо организовать данные, и это можно сделать с помощью следующих сценариев:
label_names = data['target_names'] labels = data['target'] feature_names = data['feature_names'] features = data['data']
Следующая команда напечатает названия меток, «злокачественные» и «доброкачественные» в случае нашей базы данных.
print(label_names)
Результатом вышеприведенной команды являются имена меток —
['malignant' 'benign']
Эти метки отображаются в двоичные значения 0 и 1. Злокачественный рак представлен 0, а доброкачественный рак представлен 1.
Имена и значения функций этих меток можно увидеть с помощью следующих команд:
print(feature_names[0])
Результатом вышеприведенной команды являются имена признаков для метки 0, т.е. злокачественный рак —
mean radius
Точно так же названия функций для метки могут быть получены следующим образом —
print(feature_names[1])
Результатом вышеприведенной команды являются имена признаков для метки 1, т. Е. Доброкачественного рака —
mean texture
Мы можем распечатать функции для этих этикеток с помощью следующей команды —
print(features[0])
Это даст следующий вывод —
[1.799e+01 1.038e+01 1.228e+02 1.001e+03 1.184e-01 2.776e-01 3.001e-01 1.471e-01 2.419e-01 7.871e-02 1.095e+00 9.053e-01 8.589e+00 1.534e+02 6.399e-03 4.904e-02 5.373e-02 1.587e-02 3.003e-02 6.193e-03 2.538e+01 1.733e+01 1.846e+02 2.019e+03 1.622e-01 6.656e-01 7.119e-01 2.654e-01 4.601e-01 1.189e-01]
Мы можем распечатать функции для этих этикеток с помощью следующей команды —
print(features[1])
Это даст следующий вывод —
[2.057e+01 1.777e+01 1.329e+02 1.326e+03 8.474e-02 7.864e-02 8.690e-02 7.017e-02 1.812e-01 5.667e-02 5.435e-01 7.339e-01 3.398e+00 7.408e+01 5.225e-03 1.308e-02 1.860e-02 1.340e-02 1.389e-02 3.532e-03 2.499e+01 2.341e+01 1.588e+02 1.956e+03 1.238e-01 1.866e-01 2.416e-01 1.860e-01 2.750e-01 8.902e-02]
Шаг 3: Организация данных в наборы для обучения и тестирования
Поскольку нам нужно протестировать нашу модель на невидимых данных, мы разделим наш набор данных на две части: обучающий набор и тестовый набор. Мы можем использовать функцию train_test_split () пакета python sklearn для разделения данных на наборы. Следующая команда импортирует функцию —
from sklearn.model_selection import train_test_split
Теперь следующая команда разделит данные на данные обучения и тестирования. В этом примере мы используем 40 процентов данных для целей тестирования и 60 процентов данных для целей обучения —
train, test, train_labels, test_labels = train_test_split(features,labels,test_size = 0.40, random_state = 42)
Шаг 4: Оценка модели
После разделения данных на обучение и тестирование нам нужно построить модель. Для этой цели мы будем использовать наивный байесовский алгоритм. Следующие команды импортируют модуль GaussianNB —
from sklearn.naive_bayes import GaussianNB
Теперь, инициализируйте модель следующим образом —
gnb = GaussianNB()
Далее с помощью следующей команды мы можем обучить модель —
model = gnb.fit(train, train_labels)
Теперь для целей оценки нам нужно сделать прогнозы. Это можно сделать с помощью функции предиката () следующим образом:
preds = gnb.predict(test) print(preds)
Это даст следующий вывод —
[1 0 0 1 1 0 0 0 1 1 1 0 1 0 1 0 1 1 1 0 1 1 0 1 1 1 1 1 1 0 1 1 1 1 1 1 0 1 0 1 1 0 1 1 1 1 1 1 1 1 0 0 1 1 1 1 1 0 0 1 1 0 0 1 1 1 0 0 1 1 0 0 1 0 1 1 1 1 1 1 0 1 1 0 0 0 0 0 1 1 1 1 1 1 1 1 0 0 1 0 0 1 0 0 1 1 1 0 1 1 0 1 1 0 0 0 1 1 1 0 0 1 1 0 1 0 0 1 1 0 0 0 1 1 1 0 1 1 0 0 1 0 1 1 0 1 0 0 1 1 1 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 0 1 1 0 1 1 1 1 1 1 0 0 0 1 1 0 1 0 1 1 1 1 0 1 1 0 1 1 1 0 1 0 0 1 1 1 1 1 1 1 1 0 1 1 1 1 1 0 1 0 0 1 1 0 1]
Приведенные выше серии 0 и 1 в выходных данных являются прогнозируемыми значениями для классов злокачественных и доброкачественных опухолей.
Шаг 5: Нахождение точности
Мы можем найти точность построения модели на предыдущем шаге, сравнив два массива, а именно test_labels и preds . Мы будем использовать функцию precision_score () для определения точности.
from sklearn.metrics import accuracy_score print(accuracy_score(test_labels,preds)) 0.951754385965
Приведенные выше результаты показывают, что классификатор NaïveBayes имеет точность 95,17%.
Метрики оценки классификации
Работа не выполнена, даже если вы завершили реализацию своего приложения или модели машинного обучения. Мы должны выяснить, насколько эффективна наша модель? Могут быть разные метрики оценки, но мы должны тщательно их выбирать, потому что выбор метрик влияет на то, как измеряется и сравнивается производительность алгоритма машинного обучения.
Ниже приведены некоторые важные метрики оценки классификации, среди которых вы можете выбирать, основываясь на наборе данных и типе проблемы.
Матрица путаницы
-
Матрица путаницы — это самый простой способ измерить производительность задачи классификации, когда выходные данные могут быть двух или более типов классов.
Матрица путаницы — это самый простой способ измерить производительность задачи классификации, когда выходные данные могут быть двух или более типов классов.
Различные алгоритмы классификации ML
Ниже приведены некоторые важные алгоритмы классификации ML —
- Логистическая регрессия
- Машина опорных векторов (SVM)
- Древо решений
- Наивный Байес
- Случайный Лес
Мы будем подробно обсуждать все эти алгоритмы классификации в следующих главах.
Приложения
Некоторые из наиболее важных приложений алгоритмов классификации следующие:
- Распознавание речи
- Распознавание почерка
- Биометрическая идентификация
- Классификация документов
Машинное обучение — логистическая регрессия
Введение в логистическую регрессию
Логистическая регрессия представляет собой контролируемый алгоритм классификации обучения, используемый для прогнозирования вероятности целевой переменной. Природа целевой или зависимой переменной дихотомична, что означает, что будет только два возможных класса.
Проще говоря, зависимая переменная имеет двоичную природу и имеет данные, закодированные как 1 (означает успех / да) или 0 (означает отказ / нет).
Математически, модель логистической регрессии предсказывает P (Y = 1) как функцию X. Это один из самых простых алгоритмов ML, который можно использовать для различных задач классификации, таких как обнаружение спама, прогнозирование диабета, обнаружение рака и т. Д.
Типы логистической регрессии
Как правило, логистическая регрессия означает бинарную логистическую регрессию, имеющую двоичные целевые переменные, но она может быть предсказана еще двумя категориями целевых переменных. Исходя из этого количества категорий, Логистическая регрессия может быть разделена на следующие типы —
Бинарный или Биномиальный
В такого рода классификации зависимая переменная будет иметь только два возможных типа: 1 и 0. Например, эти переменные могут представлять успех или неудачу, да или нет, выигрыш или проигрыш и т. Д.
полиномиальной
В таком виде классификации зависимая переменная может иметь 3 или более возможных неупорядоченных типов или типов, не имеющих количественного значения. Например, эти переменные могут представлять «тип A» или «тип B» или «тип C».
порядковый
В таком виде классификации зависимая переменная может иметь 3 или более возможных упорядоченных типов или типов, имеющих количественное значение. Например, эти переменные могут представлять «плохо» или «хорошо», «очень хорошо», «отлично», и каждая категория может иметь баллы, такие как 0,1,2,3.
Допущения логистической регрессии
Прежде чем углубляться в реализацию логистической регрессии, мы должны знать о следующих предположениях об одном и том же:
-
В случае бинарной логистической регрессии целевые переменные всегда должны быть бинарными, а желаемый результат представлен уровнем факторов 1.
-
В модели не должно быть мультиколлинеарности, что означает, что независимые переменные должны быть независимы друг от друга.
-
Мы должны включить значимые переменные в нашу модель.
-
Мы должны выбрать большой размер выборки для логистической регрессии.
В случае бинарной логистической регрессии целевые переменные всегда должны быть бинарными, а желаемый результат представлен уровнем факторов 1.
В модели не должно быть мультиколлинеарности, что означает, что независимые переменные должны быть независимы друг от друга.
Мы должны включить значимые переменные в нашу модель.
Мы должны выбрать большой размер выборки для логистической регрессии.
Модели регрессии
-
Модель бинарной логистической регрессии. Самой простой формой логистической регрессии является бинарная или биномиальная логистическая регрессия, в которой целевая или зависимая переменная может иметь только 2 возможных типа: 1 или 0.
-
Модель полиномиальной логистической регрессии. Другой полезной формой логистической регрессии является полиномиальная логистическая регрессия, в которой целевая или зависимая переменная может иметь 3 или более возможных неупорядоченных типов, то есть типы, не имеющие количественной значимости.
Модель бинарной логистической регрессии. Самой простой формой логистической регрессии является бинарная или биномиальная логистическая регрессия, в которой целевая или зависимая переменная может иметь только 2 возможных типа: 1 или 0.
Модель полиномиальной логистической регрессии. Другой полезной формой логистической регрессии является полиномиальная логистическая регрессия, в которой целевая или зависимая переменная может иметь 3 или более возможных неупорядоченных типов, то есть типы, не имеющие количественной значимости.
ML — Машина опорных векторов (SVM)
Введение в SVM
Машины опорных векторов (SVM) — это мощные, но гибкие алгоритмы машинного обучения под наблюдением, которые используются как для классификации, так и для регрессии. Но, как правило, они используются в задачах классификации. В 1960-х годах SVM были впервые представлены, но позже они были усовершенствованы в 1990 году. SVM имеют свой уникальный способ реализации по сравнению с другими алгоритмами машинного обучения. В последнее время они чрезвычайно популярны из-за их способности обрабатывать несколько непрерывных и категориальных переменных.
Работа СВМ
Модель SVM — это в основном представление разных классов на гиперплоскости в многомерном пространстве. Гиперплоскость будет сгенерирована SVM итеративным способом, так что ошибка может быть минимизирована. Цель SVM — разделить наборы данных на классы, чтобы найти максимальную предельную гиперплоскость (MMH).
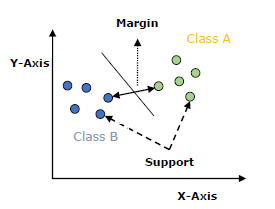
Следующие важные понятия в SVM —
-
Векторы поддержки — Точки данных, которые находятся ближе всего к гиперплоскости, называются векторами поддержки. Разделительная линия будет определяться с помощью этих точек данных.
-
Гиперплоскость — как мы видим на приведенной выше диаграмме, это плоскость принятия решений или пространство, которое разделено между набором объектов, имеющих разные классы.
-
Маржа — это может быть определено как разрыв между двумя линиями в точках данных шкафа разных классов. Его можно рассчитать как перпендикулярное расстояние от линии до опорных векторов. Большая маржа считается хорошей маржей, а маленькая маржа считается плохой маржей.
Векторы поддержки — Точки данных, которые находятся ближе всего к гиперплоскости, называются векторами поддержки. Разделительная линия будет определяться с помощью этих точек данных.
Гиперплоскость — как мы видим на приведенной выше диаграмме, это плоскость принятия решений или пространство, которое разделено между набором объектов, имеющих разные классы.
Маржа — это может быть определено как разрыв между двумя линиями в точках данных шкафа разных классов. Его можно рассчитать как перпендикулярное расстояние от линии до опорных векторов. Большая маржа считается хорошей маржей, а маленькая маржа считается плохой маржей.
Основная цель SVM — разделить наборы данных на классы, чтобы найти максимальную предельную гиперплоскость (MMH), и это можно сделать в следующие два шага:
-
Во-первых, SVM итеративно генерирует гиперплоскости, которые наилучшим образом разделяют классы.
-
Затем он выберет гиперплоскость, которая правильно разделяет классы.
Во-первых, SVM итеративно генерирует гиперплоскости, которые наилучшим образом разделяют классы.
Затем он выберет гиперплоскость, которая правильно разделяет классы.
Реализация SVM в Python
-
Для реализации SVM в Python — мы начнем со импорта стандартных библиотек следующим образом —
Для реализации SVM в Python — мы начнем со импорта стандартных библиотек следующим образом —
Ядра SVM
На практике алгоритм SVM реализуется с помощью ядра, которое преобразует пространство входных данных в требуемую форму. SVM использует технику, называемую уловкой ядра, в которой ядро занимает низкоразмерное пространство ввода и преобразует его в пространство более высокого измерения. Проще говоря, ядро преобразует неразделимые задачи в отдельные, добавляя в него больше измерений. Это делает SVM более мощным, гибким и точным. Ниже приведены некоторые из типов ядер, используемых SVM.
Линейное ядро
Его можно использовать как произведение точек между любыми двумя наблюдениями. Формула линейного ядра выглядит следующим образом:
К(х,Xя)=сумма(х∗XI)
Из приведенной выше формулы видно, что произведение между двумя векторами говорит ð ‘¥ & ð’ ¥ ð ‘- это сумма умножения каждой пары входных значений.
Полиномиальное Ядро
Это более обобщенная форма линейного ядра и различение искривленного или нелинейного входного пространства. Ниже приведена формула для полиномиального ядра —
к(Х,Х)=1+сумма(Х∗Xг) шапкуd
Здесь d — степень полинома, которую мы должны указать вручную в алгоритме обучения.
Ядро радиальной базовой функции (RBF)
Ядро RBF, чаще всего используемое в классификации SVM, отображает входное пространство в неопределенное пространство измерений. Следующая формула объясняет это математически —
K(X,XI)=ехр(−gamma∗сумма(X−XI Шляпа2))
Здесь гамма колеблется от 0 до 1. Нам нужно вручную указать это в алгоритме обучения. Хорошее значение гаммы по умолчанию — 0,1.
Поскольку мы реализовали SVM для линейно разделимых данных, мы можем реализовать его в Python для данных, которые не являются линейно разделимыми. Это можно сделать с помощью ядра.
пример
Ниже приведен пример создания классификатора SVM с использованием ядер. Мы будем использовать набор данных iris из scikit-learn —
Мы начнем с импорта следующих пакетов —
import pandas as pd import numpy as np from sklearn import svm, datasets import matplotlib.pyplot as plt
Теперь нам нужно загрузить входные данные —
iris = datasets.load_iris()
Из этого набора данных мы берем первые две особенности следующим образом:
X = iris.data[:, :2] y = iris.target
Далее мы построим границы SVM с исходными данными следующим образом:
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1 y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1 h = (x_max / x_min)/100 xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h)) X_plot = np.c_[xx.ravel(), yy.ravel()]
Теперь нам нужно указать значение параметра регуляризации следующим образом:
C = 1.0
Далее, объект классификатора SVM может быть создан следующим образом:
Svc_classifier = svm.SVC (ядро = ‘линейный’, C = C) .fit (X, y)
Z = svc_classifier.predict(X_plot) Z = Z.reshape(xx.shape) plt.figure(figsize=(15, 5)) plt.subplot(121) plt.contourf(xx, yy, Z, cmap=plt.cm.tab10, alpha=0.3) plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Set1) plt.xlabel('Sepal length') plt.ylabel('Sepal width') plt.xlim(xx.min(), xx.max()) plt.title('Support Vector Classifier with linear kernel')
Выход
Text(0.5, 1.0, 'Support Vector Classifier with linear kernel')
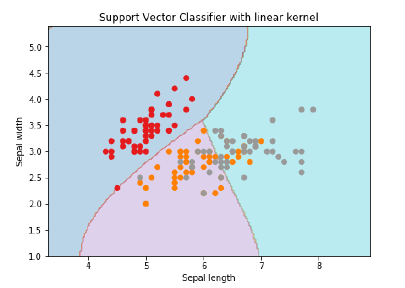
Для создания классификатора SVM с ядром rbf мы можем изменить ядро на rbf следующим образом:
Svc_classifier = svm.SVC(kernel = 'rbf', gamma =‘auto’,C = C).fit(X, y) Z = svc_classifier.predict(X_plot) Z = Z.reshape(xx.shape) plt.figure(figsize=(15, 5)) plt.subplot(121) plt.contourf(xx, yy, Z, cmap = plt.cm.tab10, alpha = 0.3) plt.scatter(X[:, 0], X[:, 1], c = y, cmap = plt.cm.Set1) plt.xlabel('Sepal length') plt.ylabel('Sepal width') plt.xlim(xx.min(), xx.max()) plt.title('Support Vector Classifier with rbf kernel')
Выход
Text(0.5, 1.0, 'Support Vector Classifier with rbf kernel')
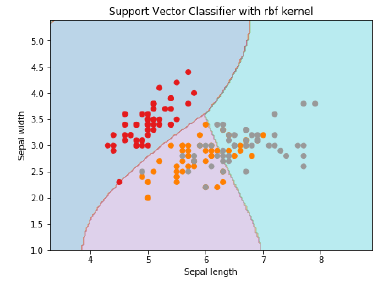
Мы устанавливаем значение гаммы равным «авто», но вы также можете указать его значение от 0 до 1.
Плюсы и минусы классификаторов SVM
Плюсы классификатора SVM
Классификаторы SVM предлагают высокую точность и хорошо работают с пространством большого размера. Классификаторы SVM в основном используют подмножество обучающих точек, следовательно, в результате используется очень меньше памяти.
Минусы SVM классификаторов
Они имеют большое время обучения, поэтому на практике не подходят для больших наборов данных. Другим недостатком является то, что классификаторы SVM плохо работают с перекрывающимися классами.
Алгоритмы классификации — Дерево решений
Введение в дерево решений
В целом, анализ дерева решений — это инструмент прогнозного моделирования, который можно применять во многих областях. Деревья решений могут быть построены с помощью алгоритмического подхода, который может разбить набор данных по-разному в зависимости от условий. Решения Tress являются наиболее мощными алгоритмами, которые подпадают под категорию контролируемых алгоритмов.
Их можно использовать как для задач классификации, так и для регрессии. Две основные сущности дерева — это узлы принятия решений, где данные разделяются и удаляются, где мы получаем результат. Пример бинарного дерева для предсказания, подходит ли человек или нет, предоставляя различную информацию, такую как возраст, пищевые привычки и физические упражнения, приведен ниже —
В приведенном выше дереве решений вопрос — это узлы решения, а конечные результаты — это листья. У нас есть следующие два типа деревьев решений.
-
Деревья решений классификации — В деревьях такого типа переменная решения является категориальной. Приведенное выше дерево решений является примером дерева решений классификации.
-
Деревья решений регрессии. В деревьях решений такого типа переменная решения является непрерывной.
Деревья решений классификации — В деревьях такого типа переменная решения является категориальной. Приведенное выше дерево решений является примером дерева решений классификации.
Деревья решений регрессии. В деревьях решений такого типа переменная решения является непрерывной.
Реализация алгоритма дерева решений
Индекс Джини
Это имя функции стоимости, которая используется для оценки двоичных разбиений в наборе данных и работает с целевой категориальной переменной «Успех» или «Сбой».
Чем выше значение индекса Джини, тем выше однородность. Идеальное значение индекса Джини равно 0, а худшее — 0,5 (для задачи 2 класса). Индекс Джини для разделения можно рассчитать с помощью следующих шагов —
-
Сначала вычислите индекс Джини для подузлов, используя формулу p ^ 2 + q ^ 2 , которая является суммой квадрата вероятности успеха и неудачи.
-
Затем вычислите индекс Джини для разделения, используя взвешенную оценку Джини для каждого узла этого разделения.
Сначала вычислите индекс Джини для подузлов, используя формулу p ^ 2 + q ^ 2 , которая является суммой квадрата вероятности успеха и неудачи.
Затем вычислите индекс Джини для разделения, используя взвешенную оценку Джини для каждого узла этого разделения.
Алгоритм дерева классификации и регрессии (CART) использует метод Джини для генерации двоичных разбиений.
Сплит Создание
Разделение в основном включает в себя атрибут в наборе данных и значение. Мы можем создать разделение в наборе данных с помощью следующих трех частей —
-
Часть 1: Расчет баллов Джини. Мы только что обсудили эту часть в предыдущем разделе.
-
Часть 2. Разделение набора данных. Его можно определить как разделение набора данных на два списка строк, имеющих индекс атрибута и значение разделения этого атрибута. Получив две группы — правую и левую, из набора данных, мы можем вычислить значение разделения, используя показатель Джини, рассчитанный в первой части. Значение разделения будет определять, в какой группе будет находиться атрибут.
-
Часть 3: Оценка всех расщеплений. Следующая часть после нахождения оценки Джини и набора данных расщепления — это оценка всех расщеплений. Для этого, во-первых, мы должны проверить каждое значение, связанное с каждым атрибутом, как разделение кандидатов. Затем нам нужно найти наилучшее возможное разделение, оценив стоимость разделения. Наилучшее разделение будет использоваться в качестве узла в дереве решений.
Часть 1: Расчет баллов Джини. Мы только что обсудили эту часть в предыдущем разделе.
Часть 2. Разделение набора данных. Его можно определить как разделение набора данных на два списка строк, имеющих индекс атрибута и значение разделения этого атрибута. Получив две группы — правую и левую, из набора данных, мы можем вычислить значение разделения, используя показатель Джини, рассчитанный в первой части. Значение разделения будет определять, в какой группе будет находиться атрибут.
Часть 3: Оценка всех расщеплений. Следующая часть после нахождения оценки Джини и набора данных расщепления — это оценка всех расщеплений. Для этого, во-первых, мы должны проверить каждое значение, связанное с каждым атрибутом, как разделение кандидатов. Затем нам нужно найти наилучшее возможное разделение, оценив стоимость разделения. Наилучшее разделение будет использоваться в качестве узла в дереве решений.
Строим дерево
Как известно, у дерева есть корневой узел и конечные узлы. После создания корневого узла мы можем построить дерево, выполнив две части:
Часть 1: Создание терминального узла
При создании терминальных узлов дерева решений одним из важных моментов является решение о том, когда прекратить выращивание дерева или создать дополнительные терминальные узлы. Это может быть сделано с использованием двух критериев, а именно: максимальная глубина дерева и минимальная запись узла следующим образом:
-
Максимальная глубина дерева — как следует из названия, это максимальное количество узлов в дереве после корневого узла. Мы должны прекратить добавлять терминальные узлы, как только дерево достигнет максимальной глубины, т.е. как только дерево получит максимальное количество терминальных узлов.
-
Записи минимального узла — его можно определить как минимальное количество шаблонов обучения, за которое отвечает данный узел. Мы должны прекратить добавлять терминальные узлы, когда дерево достигнет этих минимальных записей узлов или ниже этого минимума.
Максимальная глубина дерева — как следует из названия, это максимальное количество узлов в дереве после корневого узла. Мы должны прекратить добавлять терминальные узлы, как только дерево достигнет максимальной глубины, т.е. как только дерево получит максимальное количество терминальных узлов.
Записи минимального узла — его можно определить как минимальное количество шаблонов обучения, за которое отвечает данный узел. Мы должны прекратить добавлять терминальные узлы, когда дерево достигнет этих минимальных записей узлов или ниже этого минимума.
Терминальный узел используется для окончательного прогноза.
Часть 2: Рекурсивное расщепление
Как мы поняли, когда создавать терминальные узлы, теперь мы можем начать строить наше дерево. Рекурсивное расщепление — это метод построения дерева. В этом методе после создания узла мы можем рекурсивно создавать дочерние узлы (узлы, добавленные к существующему узлу) для каждой группы данных, сгенерированной путем разделения набора данных, вызывая ту же функцию снова и снова.
прогнозирование
После построения дерева решений нам нужно сделать прогноз об этом. По сути, прогнозирование предполагает навигацию по дереву решений с помощью специально предоставленной строки данных.
Мы можем сделать прогноз с помощью рекурсивной функции, как это было сделано выше. Та же самая процедура предсказания вызывается снова с левыми или дочерними правыми узлами.
Предположения
Ниже приведены некоторые предположения, которые мы делаем при создании дерева решений:
-
При подготовке деревьев решений обучающий набор является корневым узлом.
-
Классификатор дерева решений предпочитает, чтобы значения признаков были категориальными. В случае, если вы хотите использовать непрерывные значения, они должны быть дискретизированы до построения модели.
-
На основе значений атрибута записи распределяются рекурсивно.
-
Статистический подход будет использоваться для размещения атрибутов в любом положении узла, то есть в качестве корневого узла или внутреннего узла.
При подготовке деревьев решений обучающий набор является корневым узлом.
Классификатор дерева решений предпочитает, чтобы значения признаков были категориальными. В случае, если вы хотите использовать непрерывные значения, они должны быть дискретизированы до построения модели.
На основе значений атрибута записи распределяются рекурсивно.
Статистический подход будет использоваться для размещения атрибутов в любом положении узла, то есть в качестве корневого узла или внутреннего узла.
Реализация в Python
пример
В следующем примере мы собираемся реализовать классификатор дерева решений для индийского диабета Пима —
Во-первых, начните с импорта необходимых пакетов Python —
import pandas as pd from sklearn.tree import DecisionTreeClassifier from sklearn.model_selection import train_test_split
Затем загрузите набор данных iris с веб-ссылки следующим образом:
col_names = ['pregnant', 'glucose', 'bp', 'skin', 'insulin', 'bmi', 'pedigree', 'age', 'label'] pima = pd.read_csv(r"C:\pima-indians-diabetes.csv", header = None, names = col_names) pima.head()
| беременная | глюкоза | BP | кожа | инсулин | индекс массы тела | Родословная | Возраст | этикетка | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 6 | 148 | 72 | 35 | 0 | 33,6 | 0,627 | 50 | 1 |
| 1 | 1 | 85 | 66 | 29 | 0 | 33,6 | 0,627 | 50 | 1 |
| 2 | 8 | 183 | 64 | 0 | 0 | 23,3 | 0,672 | 32 | 1 |
| 3 | 1 | 89 | 66 | 23 | 94 | 28,1 | 0,167 | 21 | 0 |
| 4 | 0 | 137 | 40 | 35 | 168 | 43,1 | 2,288 | 33 | 1 |
Теперь разделите набор данных на объекты и целевую переменную следующим образом:
feature_cols = ['pregnant', 'insulin', 'bmi', 'age','glucose','bp','pedigree'] X = pima[feature_cols] # Features y = pima.label # Target variable
Далее, мы разделим данные на разделение на поезда и тесты. Следующий код разделит набор данных на 70% данных обучения и 30% данных тестирования.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 1)
Затем обучаем модель с помощью класса sklearn класса DecisionTreeClassifier следующим образом —
clf = DecisionTreeClassifier() clf = clf.fit(X_train,y_train)
Наконец нам нужно сделать прогноз. Это можно сделать с помощью следующего скрипта —
y_pred = clf.predict(X_test)
Далее мы можем получить оценку точности, матрицу путаницы и отчет о классификации следующим образом:
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score result = confusion_matrix(y_test, y_pred) print("Confusion Matrix:") print(result) result1 = classification_report(y_test, y_pred) print("Classification Report:",) print (result1) result2 = accuracy_score(y_test,y_pred) print("Accuracy:",result2)
Выход
Confusion Matrix:
[[116 30]
[ 46 39]]
Classification Report:
precision recall f1-score support
0 0.72 0.79 0.75 146
1 0.57 0.46 0.51 85
micro avg 0.67 0.67 0.67 231
macro avg 0.64 0.63 0.63 231
weighted avg 0.66 0.67 0.66 231
Accuracy: 0.670995670995671
Визуализация дерева решений
Приведенное выше дерево решений можно визуализировать с помощью следующего кода:
from sklearn.tree import export_graphviz
from sklearn.externals.six import StringIO
from IPython.display import Image
import pydotplus
dot_data = StringIO()
export_graphviz(clf, out_file=dot_data, filled=True, rounded=True,
special_characters=True,feature_names = feature_cols,class_names=['0','1'])
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_png('Pima_diabetes_Tree.png')
Image(graph.create_png())
Алгоритмы классификации — Наивный Байес
Введение в наивный байесовский алгоритм
Наивные байесовские алгоритмы — это метод классификации, основанный на применении теоремы Байеса с сильным предположением, что все предикторы независимы друг от друга. Проще говоря, предполагается, что наличие функции в классе не зависит от присутствия любой другой функции в том же классе. Например, телефон может считаться умным, если у него есть сенсорный экран, интернет, хорошая камера и т. Д. Хотя все эти функции зависят друг от друга, они независимо влияют на вероятность того, что телефон является смартфоном.
В байесовской классификации основной интерес заключается в том, чтобы найти апостериорные вероятности, то есть вероятность метки с учетом некоторых наблюдаемых признаков,, (? | ????????). С помощью теоремы Байеса мы можем выразить это в количественной форме следующим образом:
P(L|функция)= гидроразрывP(L)P(функции|L)P(функция)
Здесь (? | ????????) — апостериорная вероятность класса.
? (?) — априорная вероятность класса.
? (???????? | ?) — это вероятность, которая является вероятностью предиктора данного класса.
? (????????) — априорная вероятность предиктора.
Построение модели с использованием Наивного Байеса в Python
Библиотека Python, Scikit learn — самая полезная библиотека, которая помогает нам построить наивный байесовскую модель в Python. У нас есть следующие три типа наивной модели Байеса в Scikit learn Python library —
Гауссовский наивный байесовский
Это самый простой наивный байесовский классификатор, предполагающий, что данные из каждой метки взяты из простого распределения Гаусса.
Полиномиальный Наивный Байес
Другим полезным наивным байесовским классификатором является многочленный наивный байесовский, в котором предполагается, что признаки взяты из простого мультиномиального распределения. Такие наивные байесовские модели наиболее подходят для функций, представляющих дискретные значения.
Бернулли Наивный Байес
Другая важная модель — это наивный байесовский метод Бернулли, в котором предполагается, что особенности являются бинарными (0 и 1). Классификация текста с помощью модели «мешка слов» может быть применена Бернулли Наивным Байесом.
пример
В зависимости от нашего набора данных мы можем выбрать любую из наивных байесовских моделей, описанных выше. Здесь мы реализуем гауссовскую наивную байесовскую модель в Python —
Начнем с необходимого импорта следующим образом:
import numpy as np import matplotlib.pyplot as plt import seaborn as sns; sns.set()
Теперь, используя функцию make_blobs () Scikit learn , мы можем генерировать капли точек с гауссовым распределением следующим образом:
from sklearn.datasets import make_blobs X, y = make_blobs(300, 2, centers = 2, random_state = 2, cluster_std = 1.5) plt.scatter(X[:, 0], X[:, 1], c = y, s = 50, cmap = 'summer');
Далее, для использования модели GaussianNB нам нужно импортировать и сделать ее объект следующим образом:
from sklearn.naive_bayes import GaussianNB model_GBN = GaussianNB() model_GNB.fit(X, y);
Теперь мы должны сделать прогноз. Это можно сделать после генерации некоторых новых данных следующим образом:
rng = np.random.RandomState(0) Xnew = [-6, -14] + [14, 18] * rng.rand(2000, 2) ynew = model_GNB.predict(Xnew)
Далее мы строим новые данные, чтобы найти их границы —
plt.scatter(X[:, 0], X[:, 1], c = y, s = 50, cmap = 'summer') lim = plt.axis() plt.scatter(Xnew[:, 0], Xnew[:, 1], c = ynew, s = 20, cmap = 'summer', alpha = 0.1) plt.axis(lim);
Теперь с помощью следующей строки кодов мы можем найти апостериорные вероятности первой и второй метки —
yprob = model_GNB.predict_proba(Xnew) yprob[-10:].round(3)
Выход
array([[0.998, 0.002], [1. , 0. ], [0.987, 0.013], [1. , 0. ], [1. , 0. ], [1. , 0. ], [1. , 0. ], [1. , 0. ], [0. , 1. ], [0.986, 0.014]])
За и против
Pros
Ниже приведены некоторые преимущества использования наивных байесовских классификаторов —
-
Наивная байесовская классификация легко реализуема и быстра.
-
Он будет сходиться быстрее, чем дискриминационные модели, такие как логистическая регрессия.
-
Это требует меньше тренировочных данных.
-
Это очень масштабируемый характер, или они масштабируются линейно с количеством предикторов и точек данных.
-
Он может делать вероятностные прогнозы и может обрабатывать как непрерывные, так и дискретные данные.
-
Наивный байесовский алгоритм классификации можно использовать как для бинарных, так и для мультиклассовых задач классификации.
Наивная байесовская классификация легко реализуема и быстра.
Он будет сходиться быстрее, чем дискриминационные модели, такие как логистическая регрессия.
Это требует меньше тренировочных данных.
Это очень масштабируемый характер, или они масштабируются линейно с количеством предикторов и точек данных.
Он может делать вероятностные прогнозы и может обрабатывать как непрерывные, так и дискретные данные.
Наивный байесовский алгоритм классификации можно использовать как для бинарных, так и для мультиклассовых задач классификации.
Cons
Ниже приведены некоторые недостатки использования наивных байесовских классификаторов —
-
Одним из наиболее важных минусов наивной байесовской классификации является ее сильная независимость признаков, поскольку в реальной жизни практически невозможно иметь набор функций, которые полностью независимы друг от друга.
-
Еще одна проблема, связанная с наивной байесовской классификацией, заключается в ее «нулевой частоте», которая означает, что если у категориальной переменной есть категория, но она не наблюдается в наборе обучающих данных, то наивная байесовская модель присвоит ей нулевую вероятность, и она не сможет прогнозирование.
Одним из наиболее важных минусов наивной байесовской классификации является ее сильная независимость признаков, поскольку в реальной жизни практически невозможно иметь набор функций, которые полностью независимы друг от друга.
Еще одна проблема, связанная с наивной байесовской классификацией, заключается в ее «нулевой частоте», которая означает, что если у категориальной переменной есть категория, но она не наблюдается в наборе обучающих данных, то наивная байесовская модель присвоит ей нулевую вероятность, и она не сможет прогнозирование.
Применение наивной байесовской классификации
Ниже приведены некоторые общие применения классификации наивного байесовского
-
Прогнозирование в реальном времени. Благодаря простоте реализации и быстрым вычислениям его можно использовать для прогнозирования в режиме реального времени.
-
Предсказание нескольких классов — Наивный байесовский алгоритм классификации можно использовать для прогнозирования апостериорной вероятности нескольких классов целевой переменной.
-
Классификация текста. Благодаря многоуровневому прогнозированию, наивные байесовские алгоритмы классификации хорошо подходят для классификации текста. Вот почему он также используется для решения таких проблем, как фильтрация спама и анализ настроений.
-
Система рекомендаций — наряду с такими алгоритмами, как совместная фильтрация, Наив Байес создает систему рекомендаций, которую можно использовать для фильтрации невидимой информации и прогнозирования погоды, которой пользователь захочет получить данный ресурс или нет.
Прогнозирование в реальном времени. Благодаря простоте реализации и быстрым вычислениям его можно использовать для прогнозирования в режиме реального времени.
Предсказание нескольких классов — Наивный байесовский алгоритм классификации можно использовать для прогнозирования апостериорной вероятности нескольких классов целевой переменной.
Классификация текста. Благодаря многоуровневому прогнозированию, наивные байесовские алгоритмы классификации хорошо подходят для классификации текста. Вот почему он также используется для решения таких проблем, как фильтрация спама и анализ настроений.
Система рекомендаций — наряду с такими алгоритмами, как совместная фильтрация, Наив Байес создает систему рекомендаций, которую можно использовать для фильтрации невидимой информации и прогнозирования погоды, которой пользователь захочет получить данный ресурс или нет.
Алгоритмы классификации — случайный лес
Вступление
Случайный лес — это контролируемый алгоритм обучения, который используется как для классификации, так и для регрессии. Но, тем не менее, он в основном используется для задач классификации. Поскольку мы знаем, что лес составлен из деревьев, и больше деревьев означает более устойчивый лес. Точно так же алгоритм случайного леса создает деревья решений для выборок данных, а затем получает прогноз по каждой из них и, наконец, выбирает лучшее решение посредством голосования. Это метод ансамбля, который лучше, чем единое дерево решений, потому что он уменьшает переобучение путем усреднения результата.
Работа алгоритма случайного леса
Мы можем понять работу алгоритма Random Forest с помощью следующих шагов:
-
Шаг 1 — Сначала начните с выбора случайных выборок из заданного набора данных.
-
Шаг 2 — Далее этот алгоритм построит дерево решений для каждой выборки. Затем он получит результат прогнозирования из каждого дерева решений.
-
Шаг 3 — На этом этапе голосование будет проводиться для каждого прогнозируемого результата.
-
Шаг 4 — Наконец, выберите результат прогноза с наибольшим количеством голосов в качестве окончательного результата прогноза.
Шаг 1 — Сначала начните с выбора случайных выборок из заданного набора данных.
Шаг 2 — Далее этот алгоритм построит дерево решений для каждой выборки. Затем он получит результат прогнозирования из каждого дерева решений.
Шаг 3 — На этом этапе голосование будет проводиться для каждого прогнозируемого результата.
Шаг 4 — Наконец, выберите результат прогноза с наибольшим количеством голосов в качестве окончательного результата прогноза.
Следующая диаграмма проиллюстрирует его работу —
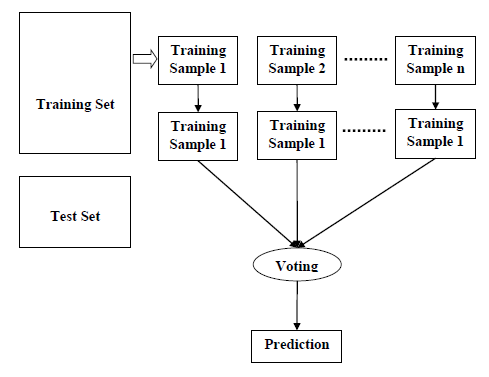
Реализация в Python
Во-первых, начните с импорта необходимых пакетов Python —
import numpy as np import matplotlib.pyplot as plt import pandas as pd
Затем загрузите набор данных iris с веб-ссылки следующим образом:
path = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
Далее нам нужно назначить имена столбцов для набора данных следующим образом:
headernames = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'Class']
Теперь нам нужно прочитать набор данных в pandas dataframe следующим образом:
dataset = pd.read_csv(path, names = headernames) dataset.head()
| чашелистник длины | чашелистник ширины | Лепесток длина | Лепесток ширины | Учебный класс | |
|---|---|---|---|---|---|
| 0 | 5,1 | 3,5 | 1.4 | 0.2 | Iris-setosa |
| 1 | 4,9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| 2 | 4,7 | 3,2 | 1,3 | 0.2 | Iris-setosa |
| 3 | 4,6 | 3,1 | 1,5 | 0.2 | Iris-setosa |
| 4 | 5.0 | 3,6 | 1.4 | 0.2 | Iris-setosa |
Предварительная обработка данных будет выполняться с помощью следующих строк сценария.
X = dataset.iloc[:, :-1].values y = dataset.iloc[:, 4].values
Далее, мы разделим данные на разделение на поезда и тесты. Следующий код разделит набор данных на 70% данных обучения и 30% данных тестирования.
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.30)
Затем обучаем модель с помощью класса sklearn класса RandomForestClassifier следующим образом —
from sklearn.ensemble import RandomForestClassifier classifier = RandomForestClassifier(n_estimators = 50) classifier.fit(X_train, y_train)
Наконец, нам нужно сделать прогноз. Это можно сделать с помощью следующего скрипта —
y_pred = classifier.predict(X_test)
Затем распечатайте результаты следующим образом —
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score result = confusion_matrix(y_test, y_pred) print("Confusion Matrix:") print(result) result1 = classification_report(y_test, y_pred) print("Classification Report:",) print (result1) result2 = accuracy_score(y_test,y_pred) print("Accuracy:",result2)
Выход
Confusion Matrix:
[[14 0 0]
[ 0 18 1]
[ 0 0 12]]
Classification Report:
precision recall f1-score support
Iris-setosa 1.00 1.00 1.00 14
Iris-versicolor 1.00 0.95 0.97 19
Iris-virginica 0.92 1.00 0.96 12
micro avg 0.98 0.98 0.98 45
macro avg 0.97 0.98 0.98 45
weighted avg 0.98 0.98 0.98 45
Accuracy: 0.9777777777777777
Плюсы и минусы случайного леса
Pros
Ниже приведены преимущества алгоритма Random Forest —
-
Он преодолевает проблему переоснащения путем усреднения или объединения результатов различных деревьев решений.
-
Случайные леса хорошо работают с большим количеством элементов данных, чем одно дерево решений.
-
Случайный лес имеет меньшую дисперсию, чем одно дерево решений.
-
Случайные леса очень гибки и обладают очень высокой точностью.
-
Масштабирование данных не требует в алгоритме случайного леса. Он сохраняет хорошую точность даже после предоставления данных без масштабирования.
-
Алгоритмы Random Forest поддерживают хорошую точность даже при отсутствии значительной части данных.
Он преодолевает проблему переоснащения путем усреднения или объединения результатов различных деревьев решений.
Случайные леса хорошо работают с большим количеством элементов данных, чем одно дерево решений.
Случайный лес имеет меньшую дисперсию, чем одно дерево решений.
Случайные леса очень гибки и обладают очень высокой точностью.
Масштабирование данных не требует в алгоритме случайного леса. Он сохраняет хорошую точность даже после предоставления данных без масштабирования.
Алгоритмы Random Forest поддерживают хорошую точность даже при отсутствии значительной части данных.
Cons
Ниже приведены недостатки алгоритма Random Forest —
-
Сложность является основным недостатком алгоритмов случайного леса.
-
Построение Случайных лесов намного сложнее и отнимает больше времени, чем деревья решений.
-
Для реализации алгоритма Random Forest требуется больше вычислительных ресурсов.
-
Это менее интуитивно понятно в случае, когда у нас есть большая коллекция деревьев решений.
-
Процесс прогнозирования с использованием случайных лесов очень трудоемкий по сравнению с другими алгоритмами.
Сложность является основным недостатком алгоритмов случайного леса.
Построение Случайных лесов намного сложнее и отнимает больше времени, чем деревья решений.
Для реализации алгоритма Random Forest требуется больше вычислительных ресурсов.
Это менее интуитивно понятно в случае, когда у нас есть большая коллекция деревьев решений.
Процесс прогнозирования с использованием случайных лесов очень трудоемкий по сравнению с другими алгоритмами.
Регрессионные алгоритмы — обзор
Введение в регрессию
Регрессия является еще одним важным и широко используемым инструментом статистического и машинного обучения. Основная цель задач на основе регрессии — предсказать выходные метки или ответы, которые являются продолженными числовыми значениями, для заданных входных данных. Результат будет основан на том, что модель выучила на этапе обучения. В основном, регрессионные модели используют функции входных данных (независимые переменные) и соответствующие им непрерывные числовые выходные значения (зависимые или выходные переменные), чтобы узнать конкретную связь между входными данными и соответствующими выходными данными.
Типы регрессионных моделей
Модели регрессии бывают двух типов:
Простая регрессионная модель — это самая базовая регрессионная модель, в которой прогнозы формируются из единой, одномерной особенности данных.
Модель множественной регрессии. Как следует из названия, в этой модели регрессии прогнозы формируются из множества характеристик данных.
Построение регрессора в Python
Модель регрессора в Python может быть построена так же, как мы построили классификатор. Scikit-learn, библиотека Python для машинного обучения также может быть использована для создания регрессора в Python.
В следующем примере мы будем строить базовую регрессионную модель, которая будет соответствовать линии данных, то есть линейному регрессору. Необходимые шаги для построения регрессора в Python следующие:
Шаг 1: Импорт необходимого пакета Python
Для построения регрессора с помощью scikit-learn нам нужно импортировать его вместе с другими необходимыми пакетами. Мы можем импортировать, используя следующий скрипт —
import numpy as np from sklearn import linear_model import sklearn.metrics as sm import matplotlib.pyplot as plt
Шаг 2: Импорт набора данных
После импорта необходимого пакета нам понадобится набор данных для построения модели прогнозирования регрессии. Мы можем импортировать его из набора данных sklearn или использовать другой согласно нашему требованию. Мы собираемся использовать наши сохраненные входные данные. Мы можем импортировать его с помощью следующего скрипта —
input = r'C:\linear.txt'
Далее нам нужно загрузить эти данные. Мы используем функцию np.loadtxt для загрузки.
input_data = np.loadtxt(input, delimiter=',') X, y = input_data[:, :-1], input_data[:, -1]
Шаг 3: Организация данных в наборы для обучения и тестирования
Следовательно, поскольку нам необходимо протестировать нашу модель на невидимых данных, мы разделим наш набор данных на две части: обучающий набор и тестовый набор. Следующая команда выполнит это —
training_samples = int(0.6 * len(X)) testing_samples = len(X) - num_training X_train, y_train = X[:training_samples], y[:training_samples] X_test, y_test = X[training_samples:], y[training_samples:]
Шаг 4: Оценка модели и прогноз
После разделения данных на обучение и тестирование нам нужно построить модель. Для этой цели мы будем использовать функцию LineaRegression () Scikit-learn. Следующая команда создаст объект линейного регрессора.
reg_linear = linear_model.LinearRegression()
Затем, обучите эту модель с обучающими образцами следующим образом —
reg_linear.fit(X_train, y_train)
Теперь, наконец, нам нужно сделать прогноз с данными тестирования.
y_test_pred = reg_linear.predict(X_test)
Шаг 5: Сюжет и визуализация
После прогноза мы можем построить и визуализировать его с помощью следующего скрипта —
plt.scatter(X_test, y_test, color = 'red') plt.plot(X_test, y_test_pred, color = 'black', linewidth = 2) plt.xticks(()) plt.yticks(()) plt.show()
Выход
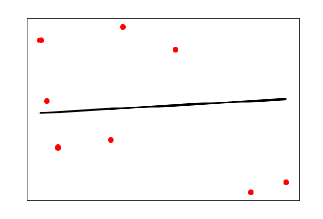
В приведенном выше выводе мы видим линию регрессии между точками данных.
Шаг 6: Расчет производительности. Мы также можем вычислить производительность нашей регрессионной модели с помощью различных метрик производительности следующим образом.
print("Regressor model performance:") print("Mean absolute error(MAE) =", round(sm.mean_absolute_error(y_test, y_test_pred), 2)) print("Mean squared error(MSE) =", round(sm.mean_squared_error(y_test, y_test_pred), 2)) print("Median absolute error =", round(sm.median_absolute_error(y_test, y_test_pred), 2)) print("Explain variance score =", round(sm.explained_variance_score(y_test, y_test_pred), 2)) print("R2 score =", round(sm.r2_score(y_test, y_test_pred), 2))
Выход
Regressor model performance: Mean absolute error(MAE) = 1.78 Mean squared error(MSE) = 3.89 Median absolute error = 2.01 Explain variance score = -0.09 R2 score = -0.09
Типы алгоритмов регрессии ML
Наиболее полезным и популярным алгоритмом регрессии ML является алгоритм линейной регрессии, который далее делится на два типа, а именно:
- Алгоритм простой линейной регрессии
- Алгоритм множественной линейной регрессии.
Мы обсудим это и реализуем на Python в следующей главе.
Приложения
Применения алгоритмов регрессии ML следующие:
Прогнозирование или прогнозный анализ. Одним из важных применений регрессии является прогнозирование или прогнозный анализ. Например, мы можем прогнозировать ВВП, цены на нефть или, проще говоря, количественные данные, которые меняются с течением времени.
Оптимизация — мы можем оптимизировать бизнес-процессы с помощью регрессии. Например, менеджер магазина может создать статистическую модель, чтобы понять время прихода покупателей.
Исправление ошибок — В бизнесе принятие правильного решения не менее важно, чем оптимизация бизнес-процесса. Регрессия может помочь нам принять правильное решение, а также исправить уже выполненное решение.
Экономика — это наиболее используемый инструмент в экономике. Мы можем использовать регрессию для прогнозирования спроса, предложения, потребления, инвестиций в запасы и т. Д.
Финансы — финансовая компания всегда заинтересована в минимизации портфеля рисков и хочет знать факторы, влияющие на клиентов. Все это можно предсказать с помощью регрессионной модели.
Алгоритмы регрессии — линейная регрессия
Введение в линейную регрессию
Линейная регрессия может быть определена как статистическая модель, которая анализирует линейные отношения между зависимой переменной с заданным набором независимых переменных. Линейная связь между переменными означает, что когда значение одной или нескольких независимых переменных будет изменяться (увеличиваться или уменьшаться), значение зависимой переменной также будет изменяться соответственно (увеличиваться или уменьшаться).
Математически связь может быть представлена с помощью следующего уравнения —
Y= МХ+Ь
Здесь Y — это зависимая переменная, которую мы пытаемся предсказать.
X — это зависимая переменная, которую мы используем для прогнозирования.
m — наклон линии регрессии, который представляет влияние X на Y
b является константой, известной как ?Y-перехват. Если X = 0, Y будет равен ?b.
Кроме того, линейные отношения могут быть положительными или отрицательными по природе, как объяснено ниже —
Положительные Линейные Отношения
Линейные отношения будут называться положительными, если возрастает как независимая, так и зависимая переменная. Это можно понять с помощью следующего графика —
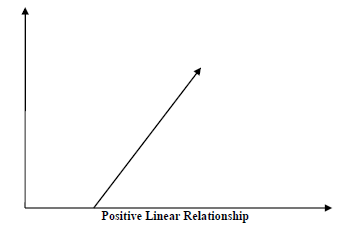
Отрицательные линейные отношения
Линейные отношения будут называться положительными, если независимые возрастают, а зависимые переменные уменьшаются. Это можно понять с помощью следующего графика —
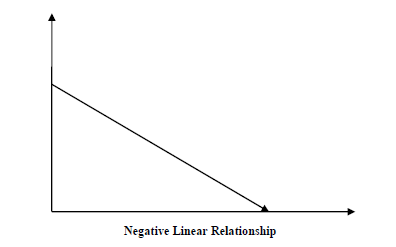
Типы линейной регрессии
Линейная регрессия бывает следующих двух типов:
Множественная линейная регрессия
Предположения
Ниже приведены некоторые предположения о наборе данных, которые сделаны моделью линейной регрессии.
Мультиколлинеарность. Модель линейной регрессии предполагает, что мультиколлинеарность данных очень мала или отсутствует. По сути, мультиколлинеарность возникает, когда независимые переменные или свойства имеют зависимость от них.
Автокорреляция. Другое допущение, которое предполагает модель линейной регрессии, заключается в том, что в данных очень мало или вообще нет автокорреляции. По сути, автокорреляция происходит, когда существует зависимость между остаточными ошибками.
Взаимосвязь между переменными. Модель линейной регрессии предполагает, что взаимосвязь между откликом и характеристическими переменными должна быть линейной.
Алгоритмы кластеризации — обзор
Введение в кластеризацию
Методы кластеризации являются одним из наиболее полезных неконтролируемых методов ML. Эти методы используются для нахождения сходства, а также моделей взаимосвязи между выборками данных, а затем группируют эти выборки в группы, имеющие сходство на основе признаков.
Кластеризация важна, потому что она определяет внутреннюю группировку среди текущих немеченых данных. Они в основном делают некоторые предположения о точках данных, чтобы составить их сходство. Каждое предположение будет создавать разные, но одинаково действительные кластеры.
Например, ниже приведена схема, на которой показана кластерная система, сгруппированная в один и тот же тип данных в разных кластерах.
Методы формирования кластеров
Нет необходимости, чтобы кластеры формировались в сферической форме. Ниже приведены некоторые другие методы формирования кластеров —
Плотность на основе
В этих методах кластеры образуются в виде плотной области. Преимущество этих методов заключается в том, что они имеют хорошую точность, а также хорошую способность объединять два кластера. Ex. Основанная на плотности пространственная кластеризация приложений с шумом (DBSCAN), точек упорядочения для определения структуры кластеризации (OPTICS) и т. Д.
Иерархическая основе
В этих методах кластеры формируются в виде древовидной структуры на основе иерархии. У них есть две категории, а именно: агломерация (подход «снизу вверх») и дивизия (подход «сверху вниз»). Ex. Кластеризация с использованием представителей (CURE), Сбалансированная итеративная редукционная кластеризация с использованием иерархий (BIRCH) и т. Д.
Разметка
В этих методах кластеры формируются путем разбиения объектов на k кластеров. Количество кластеров будет равно количеству разделов. Ex. K-означает, кластеризация больших приложений на основе рандомизированного поиска (CLARANS).
сетка
В этих методах кластеры формируются как сетчатая структура. Преимущество этих методов заключается в том, что все операции кластеризации, выполняемые в этих сетках, выполняются быстро и не зависят от количества объектов данных. Ex. Статистическая информационная сетка (STING), кластеризация в квесте (CLIQUE).
Измерение производительности кластеризации
Одним из наиболее важных соображений, касающихся модели ML, является оценка ее характеристик, или, можно сказать, качество модели. В случае контролируемых алгоритмов обучения оценить качество нашей модели легко, потому что у нас уже есть ярлыки для каждого примера.
С другой стороны, в случае неконтролируемых алгоритмов обучения мы не так счастливы, потому что имеем дело с немаркированными данными. Но все же у нас есть некоторые метрики, которые дают практикующему специалисту представление о происходящих изменениях в кластерах в зависимости от алгоритма.
Прежде чем мы углубимся в такие метрики, мы должны понять, что эти метрики только оценивают сравнительные характеристики моделей друг против друга, а не измеряют достоверность прогноза модели. Ниже приведены некоторые из метрик, которые мы можем использовать в алгоритмах кластеризации для измерения качества модели.
Анализ силуэта
Анализ силуэта используется для проверки качества кластерной модели путем измерения расстояния между кластерами. По сути, это дает нам возможность оценить параметры, такие как количество кластеров, с помощью показателя Silhouette . Эта оценка показывает, насколько близко каждая точка в одном кластере к точкам в соседних кластерах.
Анализ силуэта баллов
-
Анализ баллов силуэта — диапазон баллов силуэта [-1, 1].
Анализ баллов силуэта — диапазон баллов силуэта [-1, 1].
Типы алгоритмов кластеризации ML
Ниже приведены наиболее важные и полезные алгоритмы кластеризации ML.
K-означает кластеризацию
Этот алгоритм кластеризации вычисляет центроиды и выполняет итерации, пока мы не найдем оптимальный центроид. Предполагается, что количество кластеров уже известно. Это также называется алгоритм плоской кластеризации . Количество кластеров, идентифицированных по данным алгоритмом, обозначается буквой «K» в K-средних.
Алгоритм среднего смещения
Это еще один мощный алгоритм кластеризации, используемый в обучении без учителя. В отличие от кластеризации K-средних, она не делает никаких предположений, следовательно, это непараметрический алгоритм.
Иерархическая кластеризация
Это еще один неконтролируемый алгоритм обучения, который используется для группировки немаркированных точек данных, имеющих сходные характеристики.
Мы будем подробно обсуждать все эти алгоритмы в следующих главах.
Приложения кластеризации
Мы можем найти кластеризацию полезной в следующих областях:
Суммирование и сжатие данных. Кластеризация широко используется в областях, где нам требуется также суммирование, сжатие и сокращение данных. Примерами являются обработка изображений и векторное квантование.
Системы совместной работы и сегментация клиентов. Поскольку кластеризацию можно использовать для поиска аналогичных продуктов или пользователей того же типа, ее можно использовать в области систем совместной работы и сегментации клиентов.
Служить в качестве ключевого промежуточного шага для других задач интеллектуального анализа данных — кластерный анализ может генерировать компактную сводку данных для классификации, тестирования, генерации гипотез; следовательно, он служит ключевым промежуточным этапом и для других задач интеллектуального анализа данных.
Обнаружение трендов в динамических данных. Кластеризация также может использоваться для обнаружения трендов в динамических данных путем создания различных кластеров схожих трендов.
Анализ социальных сетей — кластеризация может использоваться в анализе социальных сетей. Примеры генерируют последовательности в изображениях, видео или аудио.
Анализ биологических данных — кластеризация также может использоваться для создания кластеров изображений, видео, следовательно, она может успешно использоваться для анализа биологических данных.
ML — Алгоритм кластеризации K-средних
Введение в алгоритм K-средних
Алгоритм кластеризации K-средних вычисляет центроиды и выполняет итерации, пока мы не найдем оптимальный центроид. Предполагается, что количество кластеров уже известно. Это также называется алгоритм плоской кластеризации . Количество кластеров, идентифицированных по данным алгоритмом, обозначается буквой «K» в K-средних.
В этом алгоритме точки данных назначаются кластеру таким образом, чтобы сумма квадратов расстояния между точками данных и центроидом была бы минимальной. Следует понимать, что меньшее отклонение в кластерах приведет к большему количеству сходных точек данных в одном кластере.
Работа алгоритма K-средних
Мы можем понять работу алгоритма кластеризации K-Means с помощью следующих шагов:
Шаг 1 — Во-первых, нам нужно указать количество кластеров, K, которые должны быть сгенерированы этим алгоритмом.
Шаг 2 — Затем случайным образом выберите K точек данных и назначьте каждую точку данных кластеру. Проще говоря, классифицировать данные на основе количества точек данных.
Шаг 3 — Теперь он будет вычислять кластерные центроиды.
Шаг 4 — Далее, продолжайте повторять следующее до тех пор, пока мы не найдем оптимальный центроид, который является назначением точек данных кластерам, которые больше не меняются
-
4.1 — Сначала будет вычислена сумма квадратов расстояния между точками данных и центроидами.
-
4.2 — Теперь мы должны назначить каждую точку данных кластеру, который находится ближе, чем другой кластер (центроид).
-
4.3 — Наконец, вычислите центроиды для кластеров, взяв среднее значение всех точек данных этого кластера.
4.1 — Сначала будет вычислена сумма квадратов расстояния между точками данных и центроидами.
4.2 — Теперь мы должны назначить каждую точку данных кластеру, который находится ближе, чем другой кластер (центроид).
4.3 — Наконец, вычислите центроиды для кластеров, взяв среднее значение всех точек данных этого кластера.
K-означает следовать подходу ожидания-максимизации для решения проблемы. Шаг ожидания используется для назначения точек данных ближайшему кластеру, а шаг максимизации используется для вычисления центроида каждого кластера.
При работе с алгоритмом K-means мы должны позаботиться о следующих вещах:
-
При работе с алгоритмами кластеризации, включая K-Means, рекомендуется стандартизировать данные, поскольку такие алгоритмы используют измерения на основе расстояний для определения сходства между точками данных.
-
Из-за итеративной природы K-средних и случайной инициализации центроидов K-средние могут придерживаться локального оптимума и могут не сходиться к глобальному оптимуму. Вот почему рекомендуется использовать разные инициализации центроидов.
При работе с алгоритмами кластеризации, включая K-Means, рекомендуется стандартизировать данные, поскольку такие алгоритмы используют измерения на основе расстояний для определения сходства между точками данных.
Из-за итеративной природы K-средних и случайной инициализации центроидов K-средние могут придерживаться локального оптимума и могут не сходиться к глобальному оптимуму. Вот почему рекомендуется использовать разные инициализации центроидов.
Реализация в Python
Следующие два примера реализации алгоритма кластеризации K-Means помогут нам в его лучшем понимании:
Пример 1
Это простой пример, чтобы понять, как работает k-means. В этом примере мы сначала сгенерируем 2D-набор данных, содержащий 4 разных больших объекта, а затем применим алгоритм k-средних, чтобы увидеть результат.
Сначала мы начнем с импорта необходимых пакетов —
%matplotlib inline import matplotlib.pyplot as plt import seaborn as sns; sns.set() import numpy as np from sklearn.cluster import KMeans
Следующий код сгенерирует 2D, содержащий четыре капли:
from sklearn.datasets.samples_generator import make_blobs X, y_true = make_blobs(n_samples = 400, centers = 4, cluster_std = 0.60, random_state = 0)
Далее, следующий код поможет нам визуализировать набор данных —
plt.scatter(X[:, 0], X[:, 1], s = 20); plt.show()
Затем создайте объект KMeans вместе с указанием количества кластеров, обучите модель и сделайте прогноз следующим образом:
kmeans = KMeans(n_clusters = 4) kmeans.fit(X) y_kmeans = kmeans.predict(X)
Теперь с помощью следующего кода мы можем построить и визуализировать центры кластера, выбранные с помощью k-средних оценки Python —
from sklearn.datasets.samples_generator import make_blobs X, y_true = make_blobs(n_samples = 400, centers = 4, cluster_std = 0.60, random_state = 0)
Далее, следующий код поможет нам визуализировать набор данных —
plt.scatter(X[:, 0], X[:, 1], c = y_kmeans, s = 20, cmap = 'summer') centers = kmeans.cluster_centers_ plt.scatter(centers[:, 0], centers[:, 1], c = 'blue', s = 100, alpha = 0.9); plt.show()
Пример 2
Давайте перейдем к другому примеру, в котором мы собираемся применить кластеризацию K-средних к набору простых цифр. K-means попытается идентифицировать похожие цифры, не используя информацию оригинальной этикетки.
Сначала мы начнем с импорта необходимых пакетов —
%matplotlib inline import matplotlib.pyplot as plt import seaborn as sns; sns.set() import numpy as np from sklearn.cluster import KMeans
Затем загрузите набор цифр из sklearn и создайте из него объект. Мы также можем найти количество строк и столбцов в этом наборе данных следующим образом:
from sklearn.datasets import load_digits digits = load_digits() digits.data.shape
Выход
(1797, 64)
Приведенный выше вывод показывает, что этот набор данных имеет 1797 выборок с 64 признаками.
Мы можем выполнить кластеризацию, как в примере 1 выше —
kmeans = KMeans(n_clusters = 10, random_state = 0) clusters = kmeans.fit_predict(digits.data) kmeans.cluster_centers_.shape
Выход
(10, 64)
Приведенный выше вывод показывает, что K-means создал 10 кластеров с 64 функциями.
fig, ax = plt.subplots(2, 5, figsize=(8, 3)) centers = kmeans.cluster_centers_.reshape(10, 8, 8) for axi, center in zip(ax.flat, centers): axi.set(xticks=[], yticks=[]) axi.imshow(center, interpolation='nearest', cmap=plt.cm.binary)
Выход
В качестве результата мы получим следующее изображение, показывающее центры кластеров, изученные с помощью k-средних.
Следующие строки кода будут сопоставлять изученные метки кластера с истинными метками, найденными в них:
from scipy.stats import mode labels = np.zeros_like(clusters) for i in range(10): mask = (clusters == i) labels[mask] = mode(digits.target[mask])[0]
Далее мы можем проверить точность следующим образом:
from sklearn.metrics import accuracy_score accuracy_score(digits.target, labels)
Выход
0.7935447968836951
Приведенный выше вывод показывает, что точность составляет около 80%.
Преимущества и недостатки
преимущества
Ниже приведены некоторые преимущества алгоритмов кластеризации K-Means:
-
Это очень легко понять и реализовать.
-
Если у нас будет большое количество переменных, тогда K-means будет быстрее, чем иерархическая кластеризация.
-
При повторном вычислении центроидов экземпляр может изменить кластер.
-
Более плотные кластеры формируются с помощью K-средних по сравнению с иерархической кластеризацией.
Это очень легко понять и реализовать.
Если у нас будет большое количество переменных, тогда K-means будет быстрее, чем иерархическая кластеризация.
При повторном вычислении центроидов экземпляр может изменить кластер.
Более плотные кластеры формируются с помощью K-средних по сравнению с иерархической кластеризацией.
Недостатки
Ниже приведены некоторые недостатки алгоритмов кластеризации K-Means:
-
Немного сложно предсказать количество кластеров, то есть значение k.
-
На выход сильно влияют исходные данные, такие как количество кластеров (значение k)
-
Порядок данных будет иметь сильное влияние на конечный результат.
-
Это очень чувствительно к масштабированию. Если мы будем масштабировать наши данные с помощью нормализации или стандартизации, то вывод полностью изменится.
-
В кластеризации плохо работать, если кластеры имеют сложную геометрическую форму.
Немного сложно предсказать количество кластеров, то есть значение k.
На выход сильно влияют исходные данные, такие как количество кластеров (значение k)
Порядок данных будет иметь сильное влияние на конечный результат.
Это очень чувствительно к масштабированию. Если мы будем масштабировать наши данные с помощью нормализации или стандартизации, то вывод полностью изменится.
В кластеризации плохо работать, если кластеры имеют сложную геометрическую форму.
Применение алгоритма кластеризации K-средних
Основными целями кластерного анализа являются —
-
Чтобы получить значимую интуицию от данных, с которыми мы работаем.
-
Cluster-then-предсказывать, где будут построены разные модели для разных подгрупп.
Чтобы получить значимую интуицию от данных, с которыми мы работаем.
Cluster-then-предсказывать, где будут построены разные модели для разных подгрупп.
Для достижения вышеупомянутых целей кластеризация K-средних достаточно эффективна. Может использоваться в следующих приложениях —
- Сегментация рынка
- Кластеризация документов
- Сегментация изображения
- Сжатие изображения
- Сегментация клиентов
- Анализ тренда на динамических данных
ML — Алгоритм среднего сдвига кластеризации
Введение в алгоритм среднего смещения
Как обсуждалось ранее, это еще один мощный алгоритм кластеризации, используемый в обучении без учителя. В отличие от кластеризации K-средних, она не делает никаких предположений; следовательно, это непараметрический алгоритм.
Алгоритм среднего сдвига в основном назначает точки данных кластерам итеративно, смещая точки в направлении наивысшей плотности точек данных, то есть центроида кластера.
Разница между алгоритмом K-Means и Mean-Shift заключается в том, что позже не нужно заранее указывать количество кластеров, поскольку количество кластеров будет определяться алгоритмом по данным.
Работа алгоритма среднего сдвига
Мы можем понять работу алгоритма кластеризации Mean-Shift с помощью следующих шагов:
-
Шаг 1 — Сначала начните с точек данных, назначенных их кластеру.
-
Шаг 2 — Далее этот алгоритм будет вычислять центроиды.
-
Шаг 3 — На этом шаге местоположение новых центроидов будет обновлено.
-
Шаг 4 — Теперь процесс будет повторен и перемещен в область более высокой плотности.
-
Шаг 5 — Наконец, он будет остановлен, как только центроиды достигнут позиции, из которой он не сможет двигаться дальше.
Шаг 1 — Сначала начните с точек данных, назначенных их кластеру.
Шаг 2 — Далее этот алгоритм будет вычислять центроиды.
Шаг 3 — На этом шаге местоположение новых центроидов будет обновлено.
Шаг 4 — Теперь процесс будет повторен и перемещен в область более высокой плотности.
Шаг 5 — Наконец, он будет остановлен, как только центроиды достигнут позиции, из которой он не сможет двигаться дальше.
Реализация в Python
Это простой пример, чтобы понять, как работает алгоритм Mean-Shift. В этом примере мы сначала сгенерируем 2D-набор данных, содержащий 4 разных больших объекта, а затем применим алгоритм Mean-Shift, чтобы увидеть результат.
%matplotlib inline import numpy as np from sklearn.cluster import MeanShift import matplotlib.pyplot as plt from matplotlib import style style.use("ggplot") from sklearn.datasets.samples_generator import make_blobs centers = [[3,3,3],[4,5,5],[3,10,10]] X, _ = make_blobs(n_samples = 700, centers = centers, cluster_std = 0.5) plt.scatter(X[:,0],X[:,1]) plt.show()
ms = MeanShift() ms.fit(X) labels = ms.labels_ cluster_centers = ms.cluster_centers_ print(cluster_centers) n_clusters_ = len(np.unique(labels)) print("Estimated clusters:", n_clusters_) colors = 10*['r.','g.','b.','c.','k.','y.','m.'] for i in range(len(X)): plt.plot(X[i][0], X[i][1], colors[labels[i]], markersize = 3) plt.scatter(cluster_centers[:,0],cluster_centers[:,1], marker = ".",color = 'k', s = 20, linewidths = 5, zorder = 10) plt.show()
Выход
[[ 2.98462798 9.9733794 10.02629344] [ 3.94758484 4.99122771 4.99349433] [ 3.00788996 3.03851268 2.99183033]] Estimated clusters: 3
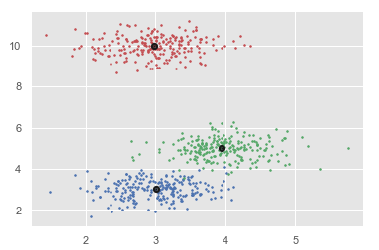
Преимущества и недостатки
преимущества
Ниже приведены некоторые преимущества алгоритма кластеризации Mean-Shift:
-
Не нужно делать какие-либо модельные допущения, как в случае K-средних или гауссовой смеси.
-
Он также может моделировать сложные кластеры, которые имеют невыпуклую форму.
-
Требуется только один параметр с именем bandwidth, который автоматически определяет количество кластеров.
-
Там нет вопроса локальных минимумов, как в K-средних.
-
Нет проблем, генерируемых выбросами.
Не нужно делать какие-либо модельные допущения, как в случае K-средних или гауссовой смеси.
Он также может моделировать сложные кластеры, которые имеют невыпуклую форму.
Требуется только один параметр с именем bandwidth, который автоматически определяет количество кластеров.
Там нет вопроса локальных минимумов, как в K-средних.
Нет проблем, генерируемых выбросами.
Недостатки
Ниже приведены некоторые недостатки алгоритма кластеризации Mean-Shift:
-
Алгоритм среднего сдвига не работает хорошо в случае большой размерности, где количество кластеров резко меняется.
-
У нас нет прямого контроля над количеством кластеров, но в некоторых приложениях нам нужно определенное количество кластеров.
-
Он не может различить осмысленные и бессмысленные способы.
Алгоритм среднего сдвига не работает хорошо в случае большой размерности, где количество кластеров резко меняется.
У нас нет прямого контроля над количеством кластеров, но в некоторых приложениях нам нужно определенное количество кластеров.
Он не может различить осмысленные и бессмысленные способы.
Машинное обучение — иерархическая кластеризация
Введение в иерархическую кластеризацию
Иерархическая кластеризация является еще одним алгоритмом обучения без контроля, который используется для группировки непомеченных точек данных, имеющих сходные характеристики. Алгоритмы иерархической кластеризации делятся на две категории.
Агломерационные иерархические алгоритмы. В агломерационных иерархических алгоритмах каждая точка данных обрабатывается как один кластер, а затем последовательно объединяется или агломерирует (подход снизу вверх) пары кластеров. Иерархия кластеров представлена в виде дендрограммы или древовидной структуры.
Разделительные иерархические алгоритмы. С другой стороны, в разделительных иерархических алгоритмах все точки данных обрабатываются как один большой кластер, а процесс кластеризации включает в себя разделение (нисходящий подход) одного большого кластера на различные маленькие кластеры.
Шаги по выполнению агломерационной иерархической кластеризации
Мы собираемся объяснить наиболее используемую и важную иерархическую кластеризацию, т.е. агломерацию. Шаги, чтобы выполнить то же самое, следующие:
-
Шаг 1 — Обработайте каждую точку данных как один кластер. Следовательно, мы будем иметь, скажем, K кластеров в начале. Количество точек данных также будет K при запуске.
-
Шаг 2 — Теперь на этом шаге нам нужно сформировать большой кластер, объединив две точки данных шкафа. Это приведет к общему количеству кластеров K-1.
-
Шаг 3 — Теперь, чтобы сформировать больше кластеров, нам нужно объединить два закрытых кластера. Это приведет к общему количеству кластеров K-2.
-
Шаг 4 — Теперь, чтобы сформировать один большой кластер, повторите описанные выше три шага, пока K не станет равным 0, то есть больше не осталось точек данных для соединения.
-
Шаг 5 — Наконец, после создания одного большого кластера, дендрограммы будут использоваться для разделения на несколько кластеров в зависимости от проблемы.
Шаг 1 — Обработайте каждую точку данных как один кластер. Следовательно, мы будем иметь, скажем, K кластеров в начале. Количество точек данных также будет K при запуске.
Шаг 2 — Теперь на этом шаге нам нужно сформировать большой кластер, объединив две точки данных шкафа. Это приведет к общему количеству кластеров K-1.
Шаг 3 — Теперь, чтобы сформировать больше кластеров, нам нужно объединить два закрытых кластера. Это приведет к общему количеству кластеров K-2.
Шаг 4 — Теперь, чтобы сформировать один большой кластер, повторите описанные выше три шага, пока K не станет равным 0, то есть больше не осталось точек данных для соединения.
Шаг 5 — Наконец, после создания одного большого кластера, дендрограммы будут использоваться для разделения на несколько кластеров в зависимости от проблемы.
Роль дендрограмм в агломерационной иерархической кластеризации
Как мы уже говорили на последнем шаге, роль дендрограммы начинается после формирования большого кластера. Дендрограмма будет использоваться для разделения кластеров на несколько кластеров связанных точек данных в зависимости от нашей проблемы. Это можно понять с помощью следующего примера —
Пример 1
Чтобы понять, давайте начнем с импорта необходимых библиотек следующим образом:
%matplotlib inline import matplotlib.pyplot as plt import numpy as np
Далее мы будем строить точки данных, которые мы взяли для этого примера —
X = np.array( [[7,8],[12,20],[17,19],[26,15],[32,37],[87,75],[73,85], [62,80],[73,60],[87,96],]) labels = range(1, 11) plt.figure(figsize = (10, 7)) plt.subplots_adjust(bottom = 0.1) plt.scatter(X[:,0],X[:,1], label = 'True Position') for label, x, y in zip(labels, X[:, 0], X[:, 1]): plt.annotate( label,xy = (x, y), xytext = (-3, 3),textcoords = 'offset points', ha = 'right', va = 'bottom') plt.show()
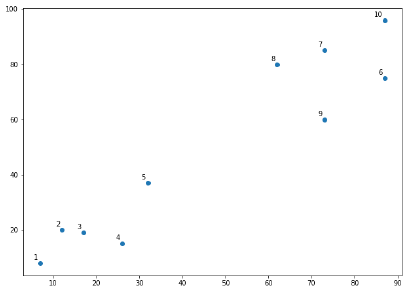
Из приведенной выше диаграммы очень легко увидеть, что у нас есть два кластера в выходных точках данных, но в данных реального мира могут быть тысячи кластеров. Далее мы будем строить дендрограммы наших точек данных с помощью библиотеки Scipy —
from scipy.cluster.hierarchy import dendrogram, linkage from matplotlib import pyplot as plt linked = linkage(X, 'single') labelList = range(1, 11) plt.figure(figsize = (10, 7)) dendrogram(linked, orientation = 'top',labels = labelList, distance_sort ='descending',show_leaf_counts = True) plt.show()
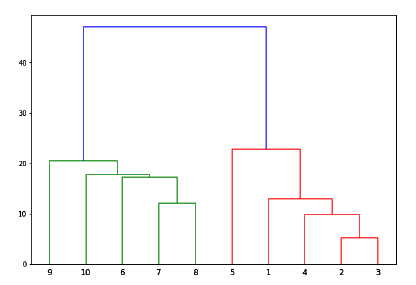
Теперь, когда сформирован большой кластер, выбирается самое длинное вертикальное расстояние. Затем через него проводится вертикальная линия, как показано на следующем рисунке. Поскольку горизонтальная линия пересекает синюю линию в двух точках, число кластеров будет равно двум.
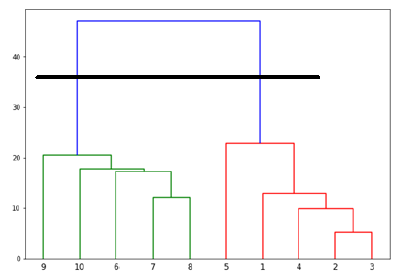
Далее нам нужно импортировать класс для кластеризации и вызвать его метод fit_predict для прогнозирования кластера. Мы импортируем класс AgglomerativeClustering библиотеки sklearn.cluster —
from sklearn.cluster import AgglomerativeClustering cluster = AgglomerativeClustering(n_clusters = 2, affinity = 'euclidean', linkage = 'ward') cluster.fit_predict(X)
Затем постройте кластер с помощью следующего кода —
plt.scatter(X[:,0],X[:,1], c = cluster.labels_, cmap = 'rainbow')
Диаграмма выше показывает два кластера из наших точек данных.
Пример 2
Как мы поняли концепцию дендрограмм из простого примера, рассмотренного выше, давайте перейдем к другому примеру, в котором мы создаем кластеры точки данных в наборе данных диабета индейцев Pima с помощью иерархической кластеризации.
import matplotlib.pyplot as plt import pandas as pd %matplotlib inline import numpy as np from pandas import read_csv path = r"C:\pima-indians-diabetes.csv" headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(path, names = headernames) array = data.values X = array[:,0:8] Y = array[:,8] data.shape (768, 9) data.head()
| PREG | Плас | Pres | кожа | Тестовое задание | масса | Педи | Возраст | Учебный класс | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 6 | 148 | 72 | 35 | 0 | 33,6 | 0,627 | 50 | 1 |
| 1 | 1 | 85 | 66 | 29 | 0 | 26,6 | 0,351 | 31 | 0 |
| 2 | 8 | 183 | 64 | 0 | 0 | 23,3 | 0,672 | 32 | 1 |
| 3 | 1 | 89 | 66 | 23 | 94 | 28,1 | 0,167 | 21 | 0 |
| 4 | 0 | 137 | 40 | 35 | 168 | 43,1 | 2,288 | 33 | 1 |
patient_data = data.iloc[:, 3:5].values import scipy.cluster.hierarchy as shc plt.figure(figsize = (10, 7)) plt.title("Patient Dendograms") dend = shc.dendrogram(shc.linkage(data, method = 'ward'))
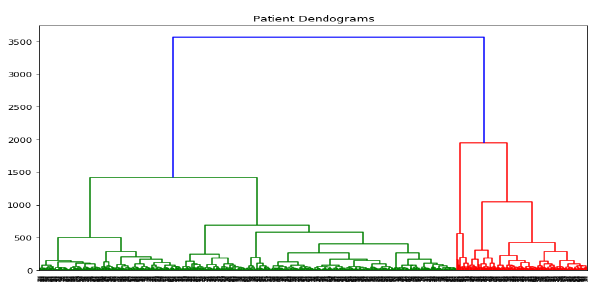
from sklearn.cluster import AgglomerativeClustering cluster = AgglomerativeClustering(n_clusters = 4, affinity = 'euclidean', linkage = 'ward') cluster.fit_predict(patient_data) plt.figure(figsize = (10, 7)) plt.scatter(patient_data[:,0], patient_data[:,1], c = cluster.labels_, cmap = 'rainbow')
Алгоритм КНН — поиск ближайших соседей
Вступление
Алгоритм K-ближайших соседей (KNN) — это тип управляемого алгоритма ML, который может использоваться как для классификации, так и для задач прогнозирования регрессии. Тем не менее, он в основном используется для классификации прогнозирующих проблем в промышленности. Следующие два свойства будут определять KNN хорошо —
-
Алгоритм ленивого обучения — KNN — это алгоритм ленивого обучения, потому что он не имеет специальной фазы обучения и использует все данные для обучения во время классификации.
-
Непараметрический алгоритм обучения — KNN также является непараметрическим алгоритмом обучения, потому что он не предполагает ничего о базовых данных.
Алгоритм ленивого обучения — KNN — это алгоритм ленивого обучения, потому что он не имеет специальной фазы обучения и использует все данные для обучения во время классификации.
Непараметрический алгоритм обучения — KNN также является непараметрическим алгоритмом обучения, потому что он не предполагает ничего о базовых данных.
Работа алгоритма КНН
Алгоритм K-ближайших соседей (KNN) использует «сходство признаков» для прогнозирования значений новых точек данных, что также означает, что новой точке данных будет присвоено значение на основе того, насколько близко он соответствует точкам в обучающем наборе. Мы можем понять его работу с помощью следующих шагов —
Шаг 1 — Для реализации любого алгоритма нам нужен набор данных. Таким образом, во время первого шага KNN мы должны загрузить данные обучения, а также данные испытаний.
Шаг 2 — Далее нам нужно выбрать значение K, то есть ближайшие точки данных. K может быть любым целым числом.
Шаг 3 — Для каждой точки в тестовых данных сделайте следующее —
-
3.1 — Рассчитайте расстояние между данными испытаний и каждой строкой данных тренировки с помощью любого из методов, а именно: Евклидово, Манхэттенское или Хэмминговское расстояние. Наиболее часто используемый метод расчета расстояния — евклидов.
-
3.2 — Теперь, основываясь на значении расстояния, отсортируйте их в порядке возрастания.
-
3.3 — Далее он выберет верхние K строк из отсортированного массива.
-
3.4 — Теперь он назначит класс контрольной точке на основе наиболее часто встречающегося класса этих строк.
3.1 — Рассчитайте расстояние между данными испытаний и каждой строкой данных тренировки с помощью любого из методов, а именно: Евклидово, Манхэттенское или Хэмминговское расстояние. Наиболее часто используемый метод расчета расстояния — евклидов.
3.2 — Теперь, основываясь на значении расстояния, отсортируйте их в порядке возрастания.
3.3 — Далее он выберет верхние K строк из отсортированного массива.
3.4 — Теперь он назначит класс контрольной точке на основе наиболее часто встречающегося класса этих строк.
Шаг 4 — Конец
пример
Ниже приведен пример для понимания концепции K и работы алгоритма KNN.
Предположим, у нас есть набор данных, который можно построить следующим образом:
Теперь нам нужно классифицировать новую точку данных с черной точкой (в точке 60, 60) в синий или красный класс. Мы предполагаем, что K = 3, то есть он найдет три ближайшие точки данных. Это показано на следующей диаграмме —
На приведенной выше диаграмме мы видим трех ближайших соседей точки данных с черной точкой. Среди этих трех два из них принадлежат к Красному классу, поэтому черная точка также будет назначена в Красном классе.
Реализация в Python
Как мы знаем, алгоритм K-ближайших соседей (KNN) может использоваться как для классификации, так и для регрессии. Ниже приведены рецепты использования Python в качестве классификатора и регрессора в Python:
КНН как классификатор
Во-первых, начните с импорта необходимых пакетов Python —
import numpy as np import matplotlib.pyplot as plt import pandas as pd
Затем загрузите набор данных iris с веб-ссылки следующим образом:
path = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
Далее нам нужно назначить имена столбцов для набора данных следующим образом:
headernames = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'Class']
Теперь нам нужно прочитать набор данных в pandas dataframe следующим образом:
dataset = pd.read_csv(path, names = headernames) dataset.head()
| чашелистник длины | чашелистник ширины | Лепесток длина | Лепесток ширины | Учебный класс | |
|---|---|---|---|---|---|
| 0 | 5,1 | 3,5 | 1.4 | 0.2 | Iris-setosa |
| 1 | 4,9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| 2 | 4,7 | 3,2 | 1,3 | 0.2 | Iris-setosa |
| 3 | 4,6 | 3,1 | 1,5 | 0.2 | Iris-setosa |
| 4 | 5.0 | 3,6 | 1.4 | 0.2 | Iris-setosa |
Предварительная обработка данных будет выполняться с помощью следующих строк сценария.
X = dataset.iloc[:, :-1].values y = dataset.iloc[:, 4].values
Далее, мы разделим данные на разделение на поезда и тесты. Следующий код разделит набор данных на 60% данных обучения и 40% данных тестирования —
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.40)
Далее, масштабирование данных будет сделано следующим образом —
from sklearn.preprocessing import StandardScaler scaler = StandardScaler() scaler.fit(X_train) X_train = scaler.transform(X_train) X_test = scaler.transform(X_test)
Далее обучаем модель с помощью класса sklearn класса KNeighborsClassifier следующим образом —
from sklearn.neighbors import KNeighborsClassifier classifier = KNeighborsClassifier(n_neighbors = 8) classifier.fit(X_train, y_train)
Наконец нам нужно сделать прогноз. Это можно сделать с помощью следующего скрипта —
y_pred = classifier.predict(X_test)
Затем распечатайте результаты следующим образом —
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score result = confusion_matrix(y_test, y_pred) print("Confusion Matrix:") print(result) result1 = classification_report(y_test, y_pred) print("Classification Report:",) print (result1) result2 = accuracy_score(y_test,y_pred) print("Accuracy:",result2)
Выход
Confusion Matrix:
[[21 0 0]
[ 0 16 0]
[ 0 7 16]]
Classification Report:
precision recall f1-score support
Iris-setosa 1.00 1.00 1.00 21
Iris-versicolor 0.70 1.00 0.82 16
Iris-virginica 1.00 0.70 0.82 23
micro avg 0.88 0.88 0.88 60
macro avg 0.90 0.90 0.88 60
weighted avg 0.92 0.88 0.88 60
Accuracy: 0.8833333333333333
КНН в качестве регрессора
Во-первых, начните с импорта необходимых пакетов Python —
import numpy as np import pandas as pd
Затем загрузите набор данных iris с веб-ссылки следующим образом:
path = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
Далее нам нужно назначить имена столбцов для набора данных следующим образом:
headernames = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'Class']
Теперь нам нужно прочитать набор данных в pandas dataframe следующим образом:
data = pd.read_csv(url, names = headernames) array = data.values X = array[:,:2] Y = array[:,2] data.shape output🙁150, 5)
Затем импортируйте KNeighborsRegressor из sklearn, чтобы соответствовать модели —
from sklearn.neighbors import KNeighborsRegressor knnr = KNeighborsRegressor(n_neighbors = 10) knnr.fit(X, y)
Наконец, мы можем найти MSE следующим образом —
print ("The MSE is:",format(np.power(y-knnr.predict(X),2).mean()))
Выход
The MSE is: 0.12226666666666669
Плюсы и минусы КНН
Pros
-
Это очень простой алгоритм для понимания и интерпретации.
-
Это очень полезно для нелинейных данных, потому что в этом алгоритме нет предположения о данных.
-
Это универсальный алгоритм, поскольку мы можем использовать его как для классификации, так и для регрессии.
-
Он имеет относительно высокую точность, но есть гораздо лучшие контролируемые модели обучения, чем KNN.
Это очень простой алгоритм для понимания и интерпретации.
Это очень полезно для нелинейных данных, потому что в этом алгоритме нет предположения о данных.
Это универсальный алгоритм, поскольку мы можем использовать его как для классификации, так и для регрессии.
Он имеет относительно высокую точность, но есть гораздо лучшие контролируемые модели обучения, чем KNN.
Cons
-
Это вычислительно немного дорогой алгоритм, потому что он хранит все данные обучения.
-
Требуется большой объем памяти по сравнению с другими контролируемыми алгоритмами обучения.
-
Прогнозирование медленное в случае большого N.
-
Он очень чувствителен к масштабу данных, а также к несущественным функциям.
Это вычислительно немного дорогой алгоритм, потому что он хранит все данные обучения.
Требуется большой объем памяти по сравнению с другими контролируемыми алгоритмами обучения.
Прогнозирование медленное в случае большого N.
Он очень чувствителен к масштабу данных, а также к несущественным функциям.
Применение КНН
Ниже приведены некоторые из областей, в которых KNN может быть успешно применен:
Банковская система
KNN может использоваться в банковской системе, чтобы предсказать, подходит ли человек для утверждения кредита? Есть ли у этого человека характеристики, аналогичные неплательщикам?
Расчет кредитных рейтингов
Алгоритмы KNN могут быть использованы для определения кредитного рейтинга человека по сравнению с людьми, имеющими сходные черты.
Политика
С помощью алгоритмов KNN мы можем классифицировать потенциального избирателя по разным классам, таким как «Буду голосовать», «Не буду голосовать», «Буду голосовать за партию« Конгресс »,« Буду голосовать за партию «BJP».
Другими областями, в которых может использоваться алгоритм KNN, являются распознавание речи, обнаружение почерка, распознавание изображений и распознавание видео.
Машинное обучение — показатели производительности
Существуют различные метрики, которые мы можем использовать для оценки производительности алгоритмов ML, классификации, а также алгоритмов регрессии. Мы должны тщательно выбирать метрики для оценки эффективности ОД, потому что —
-
То, как производительность алгоритмов ML измеряется и сравнивается, будет полностью зависеть от выбранного вами показателя.
-
То, как вы оцениваете важность различных характеристик в результате, будет полностью зависеть от выбранной вами метрики.
То, как производительность алгоритмов ML измеряется и сравнивается, будет полностью зависеть от выбранного вами показателя.
То, как вы оцениваете важность различных характеристик в результате, будет полностью зависеть от выбранной вами метрики.
Метрики производительности для задач классификации
Мы обсуждали классификацию и ее алгоритмы в предыдущих главах. Здесь мы собираемся обсудить различные метрики производительности, которые можно использовать для оценки прогнозов для задач классификации.
Матрица путаницы
Это самый простой способ измерить производительность задачи классификации, когда выходные данные могут быть двух или более типов классов. Матрица путаницы — это не что иное, как таблица с двумя измерениями, а именно. «Фактические» и «Предсказанные», и, кроме того, оба измерения имеют «Истинные позитивы (TP)», «Истинные негативы (TN)», «Ложные позитивы (FP)», «Ложные негативы (FN)», как показано ниже —
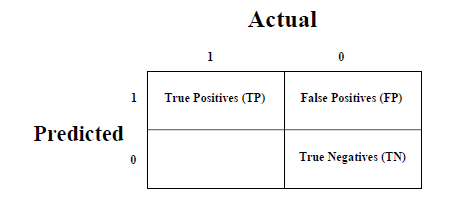
Пояснения терминов, связанных с матрицей путаницы, следующие:
-
True Positives (TP) — это тот случай, когда фактический класс и прогнозируемый класс точки данных равны 1.
-
True Negatives (TN) — это тот случай, когда фактический класс и прогнозируемый класс точки данных равны 0.
-
Ложные срабатывания (FP) — это тот случай, когда фактический класс точки данных равен 0, а прогнозируемый класс точки данных равен 1.
-
False Negatives (FN) — это тот случай, когда фактический класс точки данных равен 1, а прогнозируемый класс точки данных равен 0.
True Positives (TP) — это тот случай, когда фактический класс и прогнозируемый класс точки данных равны 1.
True Negatives (TN) — это тот случай, когда фактический класс и прогнозируемый класс точки данных равны 0.
Ложные срабатывания (FP) — это тот случай, когда фактический класс точки данных равен 0, а прогнозируемый класс точки данных равен 1.
False Negatives (FN) — это тот случай, когда фактический класс точки данных равен 1, а прогнозируемый класс точки данных равен 0.
Мы можем использовать функцию confusion_matrix в sklearn.metrics для вычисления Confusion Matrix нашей модели классификации.
Точность классификации
Это наиболее распространенная метрика производительности для алгоритмов классификации. Это может быть определено как число правильных прогнозов, сделанных как отношение всех сделанных прогнозов. Мы можем легко рассчитать его по матрице путаницы с помощью следующей формулы —
Точность= гидроразрываTP+TNTP+FP+FN+TN
Мы можем использовать функцию precision_score sklearn.metrics, чтобы вычислить точность нашей модели классификации.
Классификационный отчет
Этот отчет состоит из оценок Точности, Напомним, F1 и Поддержки. Они объясняются следующим образом —
точность
Точность, используемая при поиске документов, может быть определена как количество правильных документов, возвращаемых нашей моделью ML. Мы можем легко рассчитать его по матрице путаницы с помощью следующей формулы —
Точность= гидроразрываTPTP+FN
Напомним или Чувствительность
Отзыв может быть определен как число положительных результатов, возвращаемых нашей моделью ML. Мы можем легко вычислить его по матрице смешения с помощью следующей формулы.
Напомним= гидроразрываTPTP+FN
специфичность
Специфичность, в отличие от напоминания, может быть определена как количество негативов, возвращаемых нашей моделью ML. Мы можем легко рассчитать его по матрице путаницы с помощью следующей формулы —
Специфичность= гидроразрываTNTN+FP
Служба поддержки
Поддержка может быть определена как количество выборок истинного ответа, который лежит в каждом классе целевых значений.
Счет F1
Эта оценка даст нам гармоничное среднее точность и отзыв. Математически, оценка F1 — средневзвешенное значение точности и отзыва. Наилучшее значение F1 будет равно 1, а худшее — 0. Мы можем рассчитать показатель F1 с помощью следующей формулы:
F1=2∗(точность∗вызов)/(точность+отзыв)
Счет F1 имеет равный относительный вклад точности и отзыва.
Мы можем использовать функциюification_report в sklearn.metrics, чтобы получить отчет о классификации нашей модели классификации.
AUC (площадь под кривой ROC)
AUC (область под кривой) -ROC (рабочая характеристика приемника) — это показатель производительности, основанный на различных пороговых значениях, для задач классификации. Как следует из названия, ROC — это кривая вероятности, а AUC измеряет отделимость. Проще говоря, метрика AUC-ROC расскажет нам о способности модели различать классы. Чем выше AUC, тем лучше модель.
Математически это может быть создано путем построения графика TPR (True Positive Rate), т. Е. Чувствительности или отзыва по сравнению с FPR (False Positive Rate), т.е. 1-специфичность, при различных пороговых значениях. Ниже приведен график, показывающий ROC, AUC, имеющий TPR на оси Y и FPR на оси X —
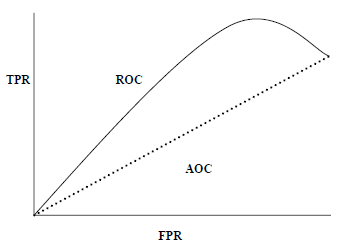
Мы можем использовать функцию roc_auc_score sklearn.metrics для вычисления AUC-ROC.
LOGLOSS (логарифмическая потеря)
Это также называется потерей логистической регрессии или потерей перекрестной энтропии. Он в основном определяется по оценкам вероятности и измеряет эффективность модели классификации, где входными данными является значение вероятности в диапазоне от 0 до 1. Это можно понять более четко, дифференцируя его с точностью. Поскольку мы знаем, что точность — это количество прогнозов (прогнозируемое значение = фактическое значение) в нашей модели, тогда как Log Loss — это количество неопределенности нашего прогноза, основанное на том, насколько оно отличается от фактической метки. С помощью значения Log Loss мы можем получить более точное представление о производительности нашей модели. Мы можем использовать функцию log_loss sklearn.metrics, чтобы вычислить Log Loss.
пример
Ниже приведен простой рецепт в Python, который даст нам представление о том, как мы можем использовать вышеописанные метрики производительности в бинарной модели классификации.
from sklearn.metrics import confusion_matrix from sklearn.metrics import accuracy_score from sklearn.metrics import classification_report from sklearn.metrics import roc_auc_score from sklearn.metrics import log_loss X_actual = [1, 1, 0, 1, 0, 0, 1, 0, 0, 0] Y_predic = [1, 0, 1, 1, 1, 0, 1, 1, 0, 0] results = confusion_matrix(X_actual, Y_predic) print ('Confusion Matrix :') print(results) print ('Accuracy Score is',accuracy_score(X_actual, Y_predic)) print ('Classification Report : ') print (classification_report(X_actual, Y_predic)) print('AUC-ROC:',roc_auc_score(X_actual, Y_predic)) print('LOGLOSS Value is',log_loss(X_actual, Y_predic))
Выход
Confusion Matrix :
[[3 3]
[1 3]]
Accuracy Score is 0.6
Classification Report :
precision recall f1-score support
0 0.75 0.50 0.60 6
1 0.50 0.75 0.60 4
micro avg 0.60 0.60 0.60 10
macro avg 0.62 0.62 0.60 10
weighted avg 0.65 0.60 0.60 10
AUC-ROC: 0.625
LOGLOSS Value is 13.815750437193334
Метрики производительности для задач регрессии
Мы обсуждали регрессию и ее алгоритмы в предыдущих главах. Здесь мы собираемся обсудить различные показатели производительности, которые можно использовать для оценки прогнозов для проблем регрессии.
Средняя абсолютная ошибка (MAE)
Это самый простой показатель ошибки, используемый в задачах регрессии. Это в основном сумма среднего абсолютной разницы между прогнозируемыми и фактическими значениями. Проще говоря, с помощью MAE мы можем получить представление о том, насколько неправильными были прогнозы. MAE не указывает направление модели, то есть не указывает на недостаточную или недостаточную производительность модели. Ниже приведена формула для расчета MAE —
MAE= frac1n sum midY− hatY mid
Здесь y = фактические выходные значения
И hatY = прогнозируемые выходные значения.
Мы можем использовать функцию mean_absolute_error в sklearn.metrics для вычисления MAE.
Среднеквадратичная ошибка (MSE)
MSE похож на MAE, но единственное отличие состоит в том, что он возводит в квадрат разницу фактических и прогнозируемых выходных значений перед суммированием их всех вместо использования абсолютного значения. Разницу можно заметить в следующем уравнении —
СКО= гидроразрыва1N сумма(Y− шлемY)
Здесь Y = фактические выходные значения
И hatY = прогнозируемые выходные значения.
Мы можем использовать функцию mean_squared_error в sklearn.metrics для вычисления MSE.
R в квадрате (R 2 )
R Квадратная метрика обычно используется для пояснительных целей и обеспечивает индикацию достоверности или соответствия набора прогнозируемых выходных значений фактическим выходным значениям. Следующая формула поможет нам понять это —
R2=1− frac frac1n sumni=1(Yi− hatYi)2 frac1n sumni=1(Yi− hatYi)2
В приведенном выше уравнении числитель — это MSE, а знаменатель — это дисперсия значений Y.
Мы можем использовать функцию r2_score sklearn.metrics для вычисления значения R в квадрате.
пример
Ниже приведен простой рецепт в Python, который даст нам представление о том, как мы можем использовать вышеописанные метрики производительности в регрессионной модели:
from sklearn.metrics import r2_score from sklearn.metrics import mean_absolute_error from sklearn.metrics import mean_squared_error X_actual = [5, -1, 2, 10] Y_predic = [3.5, -0.9, 2, 9.9] print ('R Squared =',r2_score(X_actual, Y_predic)) print ('MAE =',mean_absolute_error(X_actual, Y_predic)) print ('MSE =',mean_squared_error(X_actual, Y_predic))
Выход
R Squared = 0.9656060606060606 MAE = 0.42499999999999993 MSE = 0.5674999999999999
Машинное обучение — автоматические рабочие процессы
Вступление
Для успешного выполнения и получения результатов модель машинного обучения должна автоматизировать некоторые стандартные рабочие процессы. Процесс автоматизации этих стандартных рабочих процессов может быть выполнен с помощью Scikit-learn Pipelines. С точки зрения ученого, конвейер является обобщенной, но очень важной концепцией. Это в основном позволяет поток данных из своего необработанного формата к некоторой полезной информации. Работу трубопроводов можно понять с помощью следующей диаграммы —
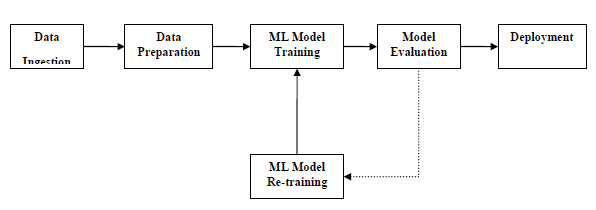
Блоки трубопроводов ML расположены следующим образом:
Прием данных. Как следует из названия, это процесс импорта данных для использования в проекте ML. Данные могут быть извлечены в режиме реального времени или партиями из одной или нескольких систем. Это один из самых сложных шагов, потому что качество данных может повлиять на всю модель ML.
Подготовка данных — после импорта данных нам необходимо подготовить данные для использования в нашей модели ML. Предварительная обработка данных является одним из важнейших методов подготовки данных.
Обучение модели ML — следующий шаг — тренировка нашей модели ML. У нас есть различные алгоритмы ML, такие как контролируемый, неконтролируемый, усиление для извлечения характеристик из данных и прогнозирования.
Оценка модели — Далее нам нужно оценить модель ML. В случае конвейера AutoML модель ML может быть оценена с помощью различных статистических методов и бизнес-правил.
Переподготовка модели ML — В случае конвейера AutoML необязательно, чтобы первая модель была лучшей. Первая модель рассматривается как базовая модель, и мы можем повторно обучить ее, чтобы повысить точность модели.
Развертывание — наконец, нам нужно развернуть модель. Этот шаг включает в себя применение и перенос модели в бизнес-операции для их использования.
Проблемы, сопровождающие трубопроводы ML
Чтобы создать конвейеры ML, исследователи данных сталкиваются со многими проблемами. Эти проблемы делятся на следующие три категории —
Качество данных
Успех любой модели ML во многом зависит от качества данных. Если данные, которые мы предоставляем модели ML, не являются точными, надежными и надежными, то мы закончим с неправильным или вводящим в заблуждение выводом.
Надежность данных
Еще одной проблемой, связанной с конвейерами ML, является надежность данных, которые мы предоставляем модели ML. Как мы знаем, могут быть различные источники, из которых ученый может получать данные, но для получения наилучших результатов необходимо убедиться, что источники данных являются надежными и надежными.
Доступность данных
Чтобы получить наилучшие результаты от конвейеров ML, сами данные должны быть доступны, что требует консолидации, очистки и обработки данных. В результате свойства доступности данных метаданные будут обновлены новыми тегами.
Моделирование ML Pipeline и подготовка данных
Утечка данных, происходящая от обучающего набора данных к тестирующему набору данных, является важной проблемой для исследователя данных при подготовке данных для модели ML. Как правило, во время подготовки данных ученый использует методы, такие как стандартизация или нормализация всего набора данных перед обучением. Но эти методы не могут помочь нам от утечки данных, потому что на тренировочный набор данных повлиял бы масштаб данных в тестовом наборе данных.
Используя конвейеры ML, мы можем предотвратить эту утечку данных, потому что конвейеры гарантируют, что подготовка данных, такая как стандартизация, ограничена каждой процедурой перекрестной проверки.
пример
Ниже приведен пример в Python, который демонстрирует процесс подготовки данных и оценки модели. Для этой цели мы используем набор данных Pima Indian Diabetes от Sklearn. Во-первых, мы будем создавать конвейер, который стандартизировал данные. Затем будет создана модель линейного дискриминационного анализа и, наконец, конвейер будет оценен с использованием 10-кратной перекрестной проверки.
Сначала импортируйте необходимые пакеты следующим образом:
from pandas import read_csv from sklearn.model_selection import KFold from sklearn.model_selection import cross_val_score from sklearn.preprocessing import StandardScaler from sklearn.pipeline import Pipeline from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
Теперь нам нужно загрузить набор данных диабета Pima, как это делалось в предыдущих примерах —
path = r"C:\pima-indians-diabetes.csv" headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(path, names = headernames) array = data.values
Далее мы создадим конвейер с помощью следующего кода —
estimators = [] estimators.append(('standardize', StandardScaler())) estimators.append(('lda', LinearDiscriminantAnalysis())) model = Pipeline(estimators)
Наконец, мы собираемся оценить этот конвейер и вывести его точность следующим образом:
kfold = KFold(n_splits = 20, random_state = 7) results = cross_val_score(model, X, Y, cv = kfold) print(results.mean())
Выход
0.7790148448043184
Приведенный выше вывод представляет собой сводную информацию о точности настройки набора данных.
Моделирование ML Pipeline и извлечение функций
Утечка данных также может произойти на этапе извлечения признаков модели ML. Вот почему процедуры извлечения признаков также должны быть ограничены, чтобы остановить утечку данных в нашем обучающем наборе данных. Как и в случае подготовки данных, используя конвейеры ML, мы также можем предотвратить утечку данных. FeatureUnion, инструмент, предоставляемый конвейерами ML, может быть использован для этой цели.
пример
Ниже приведен пример в Python, который демонстрирует рабочий процесс извлечения функций и оценки модели. Для этой цели мы используем набор данных Pima Indian Diabetes от Sklearn.
Во-первых, 3 функции будут извлечены с помощью PCA (Анализ основных компонентов). Затем 6 объектов будут извлечены с помощью статистического анализа. После извлечения признаков результат нескольких процедур выбора и извлечения будет объединен с помощью
Инструмент FeatureUnion. Наконец, будет создана модель логистической регрессии, и конвейер будет оценен с использованием 10-кратной перекрестной проверки.
Сначала импортируйте необходимые пакеты следующим образом:
from pandas import read_csv from sklearn.model_selection import KFold from sklearn.model_selection import cross_val_score from sklearn.pipeline import Pipeline from sklearn.pipeline import FeatureUnion from sklearn.linear_model import LogisticRegression from sklearn.decomposition import PCA from sklearn.feature_selection import SelectKBest
Теперь нам нужно загрузить набор данных диабета Pima, как это делалось в предыдущих примерах —
path = r"C:\pima-indians-diabetes.csv" headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(path, names = headernames) array = data.values
Далее объединение объектов будет создано следующим образом:
features = [] features.append(('pca', PCA(n_components=3))) features.append(('select_best', SelectKBest(k=6))) feature_union = FeatureUnion(features)
Далее будет создан конвейер с помощью следующих строк скрипта —
estimators = [] estimators.append(('feature_union', feature_union)) estimators.append(('logistic', LogisticRegression())) model = Pipeline(estimators)
Наконец, мы собираемся оценить этот конвейер и вывести его точность следующим образом:
kfold = KFold(n_splits = 20, random_state = 7) results = cross_val_score(model, X, Y, cv = kfold) print(results.mean())
Выход
0.7789811066126855
Приведенный выше вывод представляет собой сводную информацию о точности настройки набора данных.
Улучшение производительности моделей ML
Улучшение производительности с ансамблями
Ансамбли могут дать нам результат в машинном обучении, объединив несколько моделей. По сути, ансамблевые модели состоят из нескольких индивидуально обученных контролируемых моделей обучения, и их результаты объединяются различными способами для достижения лучшей прогностической эффективности по сравнению с одной моделью. Методы ансамбля можно разделить на следующие две группы:
Последовательные методы ансамбля
Как следует из названия, в таких методах ансамбля базовые учащиеся генерируются последовательно. Мотивация таких методов заключается в использовании зависимости среди базовых учащихся.
Параллельные методы ансамбля
Как следует из названия, в таких методах ансамбля базовые учащиеся генерируются параллельно. Мотивация таких методов заключается в использовании независимости среди базовых учащихся.
Методы обучения ансамблю
Ниже приведены наиболее популярные методы ансамблевого обучения, то есть методы комбинирования прогнозов из разных моделей.
мешковина
Термин пакетирование также известен как агрегация начальной загрузки. В методах пакетирования ансамблевая модель пытается улучшить точность прогнозирования и уменьшить дисперсию модели, комбинируя прогнозы отдельных моделей, обученных по случайно сгенерированным обучающим выборкам. Окончательный прогноз модели ансамбля будет дан путем расчета среднего значения всех прогнозов по отдельным оценщикам. Одним из лучших примеров методов упаковки в мешки являются случайные леса.
стимулирование
В методе повышения, основной принцип построения ансамблевой модели состоит в том, чтобы строить ее постепенно, последовательно обучая каждый оценщик базовой модели. Как следует из названия, он в основном объединяет несколько недельных базовых учащихся, обученных последовательно в течение нескольких итераций обучающих данных, для создания мощного ансамбля. Во время обучения недельных базовых учеников более высокие веса присваиваются тем ученикам, которые были ошибочно классифицированы ранее. Примером метода повышения является AdaBoost.
голосование
В этой модели обучения ансамбля построено несколько моделей разных типов, и для комбинирования предсказаний используется некоторая простая статистика, такая как вычисление среднего или медианы и т. Д. Этот прогноз будет служить дополнительным входом для обучения, чтобы сделать окончательный прогноз.
Алгоритмы объединения в пакеты
Ниже приведены три алгоритма объединения в пакеты.
Усиление ансамблевых алгоритмов
Ниже приведены два наиболее распространенных алгоритма усиления ансамбля —
Стохастический градиент повышения
Алгоритмы голосования ансамбля
Как уже говорилось, голосование сначала создает две или более автономных моделей из обучающего набора данных, а затем классификатор голосования обернет модель вместе со средним значением прогнозов подмодели всякий раз, когда понадобятся новые данные.
В следующем рецепте Python мы собираемся построить модель ансамбля Voting для классификации с использованием класса sklearn VotingClassifier для набора данных диабета индейцев Pima. Мы объединяем прогнозы логистической регрессии, классификатора дерева решений и SVM вместе для задачи классификации следующим образом:
Сначала импортируйте необходимые пакеты следующим образом:
from pandas import read_csv from sklearn.model_selection import KFold from sklearn.model_selection import cross_val_score from sklearn.linear_model import LogisticRegression from sklearn.tree import DecisionTreeClassifier from sklearn.svm import SVC from sklearn.ensemble import VotingClassifier
Теперь нам нужно загрузить набор данных диабета Pima, как это делалось в предыдущих примерах —
path = r"C:\pima-indians-diabetes.csv" headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(path, names = headernames) array = data.values X = array[:,0:8] Y = array[:,8]
Затем введите 10-кратную перекрестную проверку следующим образом:
kfold = KFold(n_splits = 10, random_state = 7)
Далее нам нужно создать подмодели следующим образом:
estimators = [] model1 = LogisticRegression() estimators.append(('logistic', model1)) model2 = DecisionTreeClassifier() estimators.append(('cart', model2)) model3 = SVC() estimators.append(('svm', model3))
Теперь создайте модель ансамбля голосования, комбинируя предсказания созданных выше подмоделей.
ensemble = VotingClassifier(estimators) results = cross_val_score(ensemble, X, Y, cv = kfold) print(results.mean())
Выход
0.7382262474367738
Вывод выше показывает, что мы получили точность 74% нашей модели ансамбля классификатора голосования.
Улучшение производительности модели ML (продолжение)
Улучшение производительности с помощью настройки алгоритма
Поскольку мы знаем, что модели ML параметризованы таким образом, что их поведение может быть скорректировано для конкретной проблемы. Настройка алгоритма означает поиск наилучшей комбинации этих параметров, чтобы можно было улучшить производительность модели ML. Этот процесс иногда называют оптимизацией гиперпараметров, а параметры самого алгоритма называют гиперпараметрами, а коэффициенты, найденные алгоритмом ML, называют параметрами.
Улучшение производительности с помощью настройки алгоритма
Здесь мы собираемся обсудить некоторые методы настройки параметров алгоритма, предоставляемые Python Scikit-learn.
Настройка параметров поиска в сетке
Это подход настройки параметров. Ключевым моментом работы этого метода является то, что он методично строит и оценивает модель для каждой возможной комбинации параметров алгоритма, указанных в сетке. Следовательно, можно сказать, что этот алгоритм имеет поисковый характер.
пример
В следующем рецепте Python мы собираемся выполнить поиск по сетке, используя класс sklearn GridSearchCV для оценки различных альфа-значений для алгоритма регрессии Риджа в наборе данных диабета индейцев Пима.
Сначала импортируйте необходимые пакеты следующим образом:
import numpy from pandas import read_csv from sklearn.linear_model import Ridge from sklearn.model_selection import GridSearchCV
Теперь нам нужно загрузить набор данных диабета Pima, как это делалось в предыдущих примерах —
path = r"C:\pima-indians-diabetes.csv" headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(path, names = headernames) array = data.values X = array[:,0:8] Y = array[:,8]
Затем оцените различные значения альфа следующим образом;
alphas = numpy.array([1,0.1,0.01,0.001,0.0001,0]) param_grid = dict(alpha = alphas)
Теперь нам нужно применить поиск по сетке к нашей модели —
model = Ridge() grid = GridSearchCV(estimator = model, param_grid = param_grid) grid.fit(X, Y)
Выведите результат с помощью следующей строки сценария —
print(grid.best_score_) print(grid.best_estimator_.alpha)
Выход
0.2796175593129722 1.0
Приведенный выше вывод дает нам оптимальную оценку и набор параметров в сетке, которая достигла этой оценки. Значение альфа в этом случае составляет 1,0.
Настройка параметров случайного поиска
Это подход настройки параметров. Ключевым моментом работы этого метода является то, что он выбирает параметры алгоритма из случайного распределения для фиксированного числа итераций.
пример
В следующем рецепте Python мы собираемся выполнить случайный поиск, используя класс sklearn RandomizedSearchCV для оценки различных значений альфа-канала между 0 и 1 для алгоритма регрессии хребта для набора данных диабета индейцев пима.
Сначала импортируйте необходимые пакеты следующим образом:
import numpy from pandas import read_csv from scipy.stats import uniform from sklearn.linear_model import Ridge from sklearn.model_selection import RandomizedSearchCV
Теперь нам нужно загрузить набор данных диабета Pima, как это делалось в предыдущих примерах —
path = r"C:\pima-indians-diabetes.csv" headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(path, names=headernames) array = data.values X = array[:,0:8] Y = array[:,8]
Затем оцените различные альфа-значения в алгоритме регрессии Риджа следующим образом:
param_grid = {'alpha': uniform()} model = Ridge() random_search = RandomizedSearchCV( estimator = model, param_distributions = param_grid, n_iter = 50, random_state=7) random_search.fit(X, Y)
Выведите результат с помощью следующей строки сценария —
print(random_search.best_score_) print(random_search.best_estimator_.alpha)
Выход
0.27961712703051084 0.9779895119966027
Приведенный выше вывод дает нам оптимальную оценку, аналогичную поиску по сетке.