Иерархическая кластеризация является еще одним алгоритмом обучения без контроля, который используется для группировки непомеченных точек данных, имеющих сходные характеристики. Алгоритмы иерархической кластеризации делятся на две категории.
Агломерационные иерархические алгоритмы. В агломерационных иерархических алгоритмах каждая точка данных обрабатывается как один кластер, а затем последовательно объединяется или агломерирует (подход снизу вверх) пары кластеров. Иерархия кластеров представлена в виде дендрограммы или древовидной структуры.
Разделительные иерархические алгоритмы. С другой стороны, в разделительных иерархических алгоритмах все точки данных обрабатываются как один большой кластер, а процесс кластеризации включает в себя разделение (нисходящий подход) одного большого кластера на различные маленькие кластеры.
Шаги по выполнению агломерационной иерархической кластеризации
Мы собираемся объяснить наиболее используемую и важную иерархическую кластеризацию, т.е. агломерацию. Шаги, чтобы выполнить то же самое, следующие:
-
Шаг 1 — Обработайте каждую точку данных как один кластер. Следовательно, мы будем иметь, скажем, K кластеров в начале. Количество точек данных также будет K при запуске.
-
Шаг 2 — Теперь на этом шаге нам нужно сформировать большой кластер, объединив две точки данных шкафа. Это приведет к общему количеству кластеров K-1.
-
Шаг 3 — Теперь, чтобы сформировать больше кластеров, нам нужно объединить два закрытых кластера. Это приведет к общему количеству кластеров K-2.
-
Шаг 4 — Теперь, чтобы сформировать один большой кластер, повторите описанные выше три шага, пока K не станет равным 0, то есть больше не осталось точек данных для соединения.
-
Шаг 5 — Наконец, после создания одного большого кластера, дендрограммы будут использоваться для разделения на несколько кластеров в зависимости от проблемы.
Шаг 1 — Обработайте каждую точку данных как один кластер. Следовательно, мы будем иметь, скажем, K кластеров в начале. Количество точек данных также будет K при запуске.
Шаг 2 — Теперь на этом шаге нам нужно сформировать большой кластер, объединив две точки данных шкафа. Это приведет к общему количеству кластеров K-1.
Шаг 3 — Теперь, чтобы сформировать больше кластеров, нам нужно объединить два закрытых кластера. Это приведет к общему количеству кластеров K-2.
Шаг 4 — Теперь, чтобы сформировать один большой кластер, повторите описанные выше три шага, пока K не станет равным 0, то есть больше не осталось точек данных для соединения.
Шаг 5 — Наконец, после создания одного большого кластера, дендрограммы будут использоваться для разделения на несколько кластеров в зависимости от проблемы.
Роль дендрограмм в агломерационной иерархической кластеризации
Как мы уже говорили на последнем шаге, роль дендрограммы начинается после формирования большого кластера. Дендрограмма будет использоваться для разделения кластеров на несколько кластеров связанных точек данных в зависимости от нашей проблемы. Это можно понять с помощью следующего примера —
Пример 1
Чтобы понять, давайте начнем с импорта необходимых библиотек следующим образом:
%matplotlib inline import matplotlib.pyplot as plt import numpy as np
Далее мы будем строить точки данных, которые мы взяли для этого примера —
X = np.array( [[7,8],[12,20],[17,19],[26,15],[32,37],[87,75],[73,85], [62,80],[73,60],[87,96],]) labels = range(1, 11) plt.figure(figsize = (10, 7)) plt.subplots_adjust(bottom = 0.1) plt.scatter(X[:,0],X[:,1], label = 'True Position') for label, x, y in zip(labels, X[:, 0], X[:, 1]): plt.annotate( label,xy = (x, y), xytext = (-3, 3),textcoords = 'offset points', ha = 'right', va = 'bottom') plt.show()
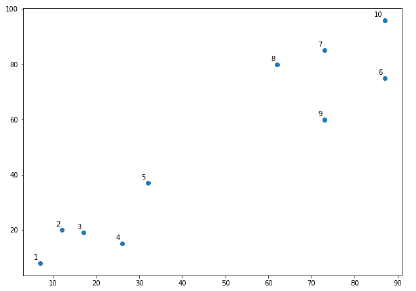
Из приведенной выше диаграммы очень легко увидеть, что у нас есть два кластера в выходных точках данных, но в данных реального мира могут быть тысячи кластеров. Далее мы будем строить дендрограммы наших точек данных с помощью библиотеки Scipy —
from scipy.cluster.hierarchy import dendrogram, linkage from matplotlib import pyplot as plt linked = linkage(X, 'single') labelList = range(1, 11) plt.figure(figsize = (10, 7)) dendrogram(linked, orientation = 'top',labels = labelList, distance_sort ='descending',show_leaf_counts = True) plt.show()
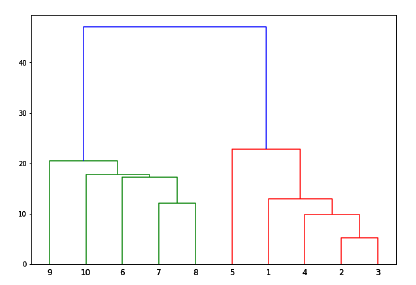
Теперь, когда сформирован большой кластер, выбирается самое длинное вертикальное расстояние. Затем через него проводится вертикальная линия, как показано на следующем рисунке. Поскольку горизонтальная линия пересекает синюю линию в двух точках, число кластеров будет равно двум.
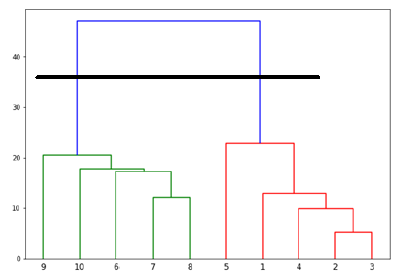
Далее нам нужно импортировать класс для кластеризации и вызвать его метод fit_predict для прогнозирования кластера. Мы импортируем класс AgglomerativeClustering библиотеки sklearn.cluster —
from sklearn.cluster import AgglomerativeClustering cluster = AgglomerativeClustering(n_clusters = 2, affinity = 'euclidean', linkage = 'ward') cluster.fit_predict(X)
Затем постройте кластер с помощью следующего кода —
plt.scatter(X[:,0],X[:,1], c = cluster.labels_, cmap = 'rainbow')
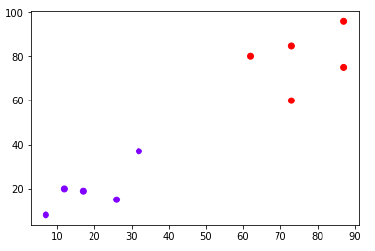
Диаграмма выше показывает два кластера из наших точек данных.
Пример 2
Как мы поняли концепцию дендрограмм из простого примера, рассмотренного выше, давайте перейдем к другому примеру, в котором мы создаем кластеры точки данных в наборе данных диабета индейцев Pima с помощью иерархической кластеризации.
import matplotlib.pyplot as plt import pandas as pd %matplotlib inline import numpy as np from pandas import read_csv path = r"C:\pima-indians-diabetes.csv" headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(path, names = headernames) array = data.values X = array[:,0:8] Y = array[:,8] data.shape (768, 9) data.head()