Для успешного выполнения и получения результатов модель машинного обучения должна автоматизировать некоторые стандартные рабочие процессы. Процесс автоматизации этих стандартных рабочих процессов может быть выполнен с помощью Scikit-learn Pipelines. С точки зрения ученого, конвейер является обобщенной, но очень важной концепцией. Это в основном позволяет поток данных из своего необработанного формата к некоторой полезной информации. Работу трубопроводов можно понять с помощью следующей диаграммы —
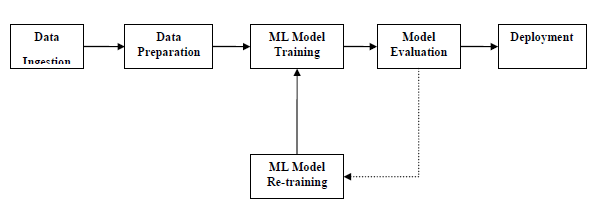
Блоки трубопроводов ML расположены следующим образом:
Прием данных. Как следует из названия, это процесс импорта данных для использования в проекте ML. Данные могут быть извлечены в режиме реального времени или партиями из одной или нескольких систем. Это один из самых сложных шагов, потому что качество данных может повлиять на всю модель ML.
Подготовка данных — после импорта данных нам необходимо подготовить данные для использования в нашей модели ML. Предварительная обработка данных является одним из важнейших методов подготовки данных.
Обучение модели ML — следующий шаг — тренировка нашей модели ML. У нас есть различные алгоритмы ML, такие как контролируемый, неконтролируемый, усиление для извлечения характеристик из данных и прогнозирования.
Оценка модели — Далее нам нужно оценить модель ML. В случае конвейера AutoML модель ML может быть оценена с помощью различных статистических методов и бизнес-правил.
Переподготовка модели ML — В случае конвейера AutoML необязательно, чтобы первая модель была лучшей. Первая модель рассматривается как базовая модель, и мы можем повторно обучить ее, чтобы повысить точность модели.
Развертывание — наконец, нам нужно развернуть модель. Этот шаг включает в себя применение и перенос модели в бизнес-операции для их использования.
Проблемы, сопровождающие трубопроводы ML
Чтобы создать конвейеры ML, исследователи данных сталкиваются со многими проблемами. Эти проблемы делятся на следующие три категории —
Качество данных
Успех любой модели ML во многом зависит от качества данных. Если данные, которые мы предоставляем модели ML, не являются точными, надежными и надежными, то мы закончим с неправильным или вводящим в заблуждение выводом.
Надежность данных
Еще одной проблемой, связанной с конвейерами ML, является надежность данных, которые мы предоставляем модели ML. Как мы знаем, могут быть различные источники, из которых ученый может получать данные, но для получения наилучших результатов необходимо убедиться, что источники данных являются надежными и надежными.
Доступность данных
Чтобы получить наилучшие результаты от конвейеров ML, сами данные должны быть доступны, что требует консолидации, очистки и обработки данных. В результате свойства доступности данных метаданные будут обновлены новыми тегами.
Моделирование ML Pipeline и подготовка данных
Утечка данных, происходящая от обучающего набора данных к тестирующему набору данных, является важной проблемой для исследователя данных при подготовке данных для модели ML. Как правило, во время подготовки данных ученый использует методы, такие как стандартизация или нормализация всего набора данных перед обучением. Но эти методы не могут помочь нам от утечки данных, потому что на тренировочный набор данных повлиял бы масштаб данных в тестовом наборе данных.
Используя конвейеры ML, мы можем предотвратить эту утечку данных, потому что конвейеры гарантируют, что подготовка данных, такая как стандартизация, ограничена каждой процедурой перекрестной проверки.
пример
Ниже приведен пример в Python, который демонстрирует процесс подготовки данных и оценки модели. Для этой цели мы используем набор данных Pima Indian Diabetes от Sklearn. Во-первых, мы будем создавать конвейер, который стандартизировал данные. Затем будет создана модель линейного дискриминационного анализа и, наконец, конвейер будет оценен с использованием 10-кратной перекрестной проверки.
Сначала импортируйте необходимые пакеты следующим образом:
from pandas import read_csv from sklearn.model_selection import KFold from sklearn.model_selection import cross_val_score from sklearn.preprocessing import StandardScaler from sklearn.pipeline import Pipeline from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
Теперь нам нужно загрузить набор данных диабета Pima, как это делалось в предыдущих примерах —
path = r"C:\pima-indians-diabetes.csv" headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(path, names = headernames) array = data.values
Далее мы создадим конвейер с помощью следующего кода —
estimators = [] estimators.append(('standardize', StandardScaler())) estimators.append(('lda', LinearDiscriminantAnalysis())) model = Pipeline(estimators)
Наконец, мы собираемся оценить этот конвейер и вывести его точность следующим образом:
kfold = KFold(n_splits = 20, random_state = 7) results = cross_val_score(model, X, Y, cv = kfold) print(results.mean())
Выход
0.7790148448043184
Приведенный выше вывод представляет собой сводную информацию о точности настройки набора данных.
Моделирование ML Pipeline и извлечение функций
Утечка данных также может произойти на этапе извлечения признаков модели ML. Вот почему процедуры извлечения признаков также должны быть ограничены, чтобы остановить утечку данных в нашем обучающем наборе данных. Как и в случае подготовки данных, используя конвейеры ML, мы также можем предотвратить утечку данных. FeatureUnion, инструмент, предоставляемый конвейерами ML, может быть использован для этой цели.
пример
Ниже приведен пример в Python, который демонстрирует рабочий процесс извлечения функций и оценки модели. Для этой цели мы используем набор данных Pima Indian Diabetes от Sklearn.
Во-первых, 3 функции будут извлечены с помощью PCA (Анализ основных компонентов). Затем 6 объектов будут извлечены с помощью статистического анализа. После извлечения признаков результат нескольких процедур выбора и извлечения будет объединен с помощью
Инструмент FeatureUnion. Наконец, будет создана модель логистической регрессии, и конвейер будет оценен с использованием 10-кратной перекрестной проверки.
Сначала импортируйте необходимые пакеты следующим образом:
from pandas import read_csv from sklearn.model_selection import KFold from sklearn.model_selection import cross_val_score from sklearn.pipeline import Pipeline from sklearn.pipeline import FeatureUnion from sklearn.linear_model import LogisticRegression from sklearn.decomposition import PCA from sklearn.feature_selection import SelectKBest
Теперь нам нужно загрузить набор данных диабета Pima, как это делалось в предыдущих примерах —
path = r"C:\pima-indians-diabetes.csv" headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(path, names = headernames) array = data.values
Далее объединение объектов будет создано следующим образом:
features = [] features.append(('pca', PCA(n_components=3))) features.append(('select_best', SelectKBest(k=6))) feature_union = FeatureUnion(features)
Далее будет создан конвейер с помощью следующих строк скрипта —
estimators = [] estimators.append(('feature_union', feature_union)) estimators.append(('logistic', LogisticRegression())) model = Pipeline(estimators)
Наконец, мы собираемся оценить этот конвейер и вывести его точность следующим образом:
kfold = KFold(n_splits = 20, random_state = 7) results = cross_val_score(model, X, Y, cv = kfold) print(results.mean())
Выход
0.7789811066126855
Приведенный выше вывод представляет собой сводную информацию о точности настройки набора данных.