R — Обзор
R — это язык программирования и программная среда для статистического анализа, графического представления и отчетности. R был создан Россом Ихакой и Робертом Джентльменом в университете Окленда, Новая Зеландия, и в настоящее время разрабатывается основной группой разработчиков R.
Ядром R является интерпретируемый компьютерный язык, который позволяет выполнять ветвления и циклы, а также модульное программирование с использованием функций. R обеспечивает эффективность интеграции с процедурами, написанными на языках C, C ++, .Net, Python или FORTRAN.
R находится в свободном доступе под GNU General Public License, и предварительно скомпилированные двоичные версии предоставляются для различных операционных систем, таких как Linux, Windows и Mac.
R — это бесплатное программное обеспечение, распространяемое под левой копией в стиле GNU, и официальная часть проекта GNU под названием GNU S.
Эволюция R
Первоначально R был написан Россом Ихакой и Робертом Джентльменом на факультете статистики Оклендского университета в Окленде, Новая Зеландия. R сделал свое первое появление в 1993 году.
-
Большая группа людей внесла свой вклад в R, отправив код и отчеты об ошибках.
-
С середины 1997 года существует основная группа («R Core Team»), которая может изменять архив исходного кода R.
Большая группа людей внесла свой вклад в R, отправив код и отчеты об ошибках.
С середины 1997 года существует основная группа («R Core Team»), которая может изменять архив исходного кода R.
Особенности R
Как указывалось ранее, R является языком программирования и программной средой для статистического анализа, графического представления и отчетности. Ниже приведены важные особенности R —
-
R — это хорошо разработанный, простой и эффективный язык программирования, который включает в себя условные выражения, циклы, пользовательские рекурсивные функции и средства ввода и вывода.
-
R имеет эффективные средства обработки и хранения данных,
-
R предоставляет набор операторов для вычислений над массивами, списками, векторами и матрицами.
-
R предоставляет большой, согласованный и интегрированный набор инструментов для анализа данных.
-
R предоставляет графические средства для анализа данных и отображения либо непосредственно на компьютере, либо для печати на бумаге.
R — это хорошо разработанный, простой и эффективный язык программирования, который включает в себя условные выражения, циклы, пользовательские рекурсивные функции и средства ввода и вывода.
R имеет эффективные средства обработки и хранения данных,
R предоставляет набор операторов для вычислений над массивами, списками, векторами и матрицами.
R предоставляет большой, согласованный и интегрированный набор инструментов для анализа данных.
R предоставляет графические средства для анализа данных и отображения либо непосредственно на компьютере, либо для печати на бумаге.
В заключение следует отметить, что R — самый широко используемый в мире язык программирования для статистики. Это # 1 выбор исследователей данных и поддерживается энергичным и талантливым сообществом участников. R преподается в университетах и используется в критически важных бизнес-приложениях. Этот урок научит вас программированию на R вместе с подходящими примерами в простых и простых шагах.
R — Настройка среды
Настройка локальной среды
Если вы все еще хотите настроить свою среду для R, вы можете выполнить следующие шаги.
Установка Windows
Вы можете загрузить версию R установщика Windows из R-3.2.2 для Windows (32/64 бит) и сохранить ее в локальном каталоге.
Так как это установщик Windows (.exe) с именем «R-version-win.exe». Вы можете просто дважды щелкнуть и запустить установщик, принимая настройки по умолчанию. Если у вас 32-битная версия Windows, она устанавливает 32-битную версию. Но если у вас 64-битная версия Windows, она устанавливает как 32-битную, так и 64-битную версии.
После установки вы можете найти значок для запуска Программы в структуре каталогов «R \ R3.2.2 \ bin \ i386 \ Rgui.exe» в разделе «Файлы программ Windows». Нажатие на этот значок вызывает R-GUI, который является консолью R для программирования R.
Установка Linux
R доступен в виде двоичного файла для многих версий Linux в папке R Binaries .
Инструкция по установке Linux варьируется от аромата к аромату. Эти шаги упомянуты для каждого типа версии Linux в указанной ссылке. Однако, если вы спешите, вы можете использовать команду yum для установки R следующим образом:
$ yum install R
Вышеуказанная команда установит основные функции программирования R вместе со стандартными пакетами, но вам потребуется дополнительный пакет, затем вы можете запустить приглашение R следующим образом:
$ R R version 3.2.0 (2015-04-16) -- "Full of Ingredients" Copyright (C) 2015 The R Foundation for Statistical Computing Platform: x86_64-redhat-linux-gnu (64-bit) R is free software and comes with ABSOLUTELY NO WARRANTY. You are welcome to redistribute it under certain conditions. Type 'license()' or 'licence()' for distribution details. R is a collaborative project with many contributors. Type 'contributors()' for more information and 'citation()' on how to cite R or R packages in publications. Type 'demo()' for some demos, 'help()' for on-line help, or 'help.start()' for an HTML browser interface to help. Type 'q()' to quit R. >
Теперь вы можете использовать команду install в приглашении R для установки необходимого пакета. Например, следующая команда установит пакет plotrix , необходимый для трехмерных диаграмм.
> install.packages("plotrix")
R — основной синтаксис
Как правило, мы начнем изучать программирование на R, написав «Hello, World!» программа. В зависимости от потребностей вы можете запрограммировать либо в командной строке R, либо вы можете использовать файл сценария R для написания вашей программы. Давайте проверим оба по одному.
Командная строка R
После настройки среды R легко запустить командную строку R, просто набрав в командной строке следующую команду:
$ R
Это запустит интерпретатор R и вы получите приглашение>, где вы можете начать печатать вашу программу следующим образом —
> myString <- "Hello, World!" > print ( myString) [1] "Hello, World!"
Здесь первый оператор определяет строковую переменную myString, где мы присваиваем строку «Hello, World!» и затем следующая инструкция print () используется для вывода значения, хранящегося в переменной myString.
R Script File
Обычно вы выполняете программирование, записывая свои программы в файлах сценариев, а затем выполняете эти сценарии в командной строке с помощью интерпретатора R, называемого Rscript . Итак, давайте начнем с написания следующего кода в текстовом файле с именем test.R, как показано ниже:
# My first program in R Programming myString <- "Hello, World!" print ( myString)
Сохраните приведенный выше код в файле test.R и выполните его в командной строке Linux, как указано ниже. Даже если вы используете Windows или другую систему, синтаксис останется прежним.
$ Rscript test.R
Когда мы запускаем вышеуказанную программу, она дает следующий результат.
[1] "Hello, World!"
Комментарии
Комментарии подобны тексту помощи в вашей R-программе, и они игнорируются интерпретатором при выполнении вашей реальной программы. Одиночный комментарий пишется с использованием # в начале утверждения следующим образом:
# My first program in R Programming
R не поддерживает многострочные комментарии, но вы можете выполнить трюк, который выглядит следующим образом:
if(FALSE) { "This is a demo for multi-line comments and it should be put inside either a single OR double quote" } myString <- "Hello, World!" print ( myString)
[1] "Hello, World!"
Хотя приведенные выше комментарии будут выполняться интерпретатором R, они не будут мешать вашей реальной программе. Вы должны поместить такие комментарии внутри, или одинарные или двойные кавычки.
R — Типы данных
Как правило, при программировании на любом языке программирования вам необходимо использовать различные переменные для хранения различной информации. Переменные — это не что иное, как зарезервированные области памяти для хранения значений. Это означает, что при создании переменной вы резервируете некоторое пространство в памяти.
Вы можете хранить информацию различных типов данных, таких как символ, широкий символ, целое число, число с плавающей запятой, двойное число с плавающей запятой, логическое значение и т. Д. В зависимости от типа данных переменной операционная система выделяет память и решает, что можно сохранить в зарезервированная память
В отличие от других языков программирования, таких как C и java в R, переменные не объявляются как некоторый тип данных. Переменным присваиваются R-объекты, а тип данных R-объекта становится типом данных переменной. Существует много типов R-объектов. Часто используемые из них —
- векторы
- Списки
- Матрицы
- Массивы
- факторы
- Фреймы данных
Простейшим из этих объектов является векторный объект, и существует шесть типов данных этих атомных векторов, также называемых шестью классами векторов. Другие R-объекты построены на атомных векторах.
| Тип данных | пример | проверить |
|---|---|---|
| логический | ИСТИНА, ЛОЖЬ | Live Demo
v <- TRUE print(class(v)) это дает следующий результат — [1] "logical" |
| числовой | 12,3, 5, 999 | Live Demo
v <- 23.5 print(class(v)) это дает следующий результат — [1] "numeric" |
| целое число | 2л, 34л, 0л | Live Demo
v <- 2L print(class(v)) это дает следующий результат — [1] "integer" |
| Сложный | 3 + 2i | Live Demo
v <- 2+5i print(class(v)) это дает следующий результат — [1] "complex" |
| символ | «а», «хорошо», «ИСТИНА», «23,4» | Live Demo
v <- "TRUE" print(class(v)) это дает следующий результат — [1] "character" |
| необработанный | «Привет» хранится как 48 65 6c 6c 6f | Live Demo
v <- charToRaw("Hello") print(class(v)) это дает следующий результат — [1] "raw" |
это дает следующий результат —
это дает следующий результат —
это дает следующий результат —
это дает следующий результат —
это дает следующий результат —
это дает следующий результат —
В R-программировании самыми основными типами данных являются R-объекты, называемые векторами, которые содержат элементы разных классов, как показано выше. Обратите внимание, что в R количество классов не ограничивается только указанными выше шестью типами. Например, мы можем использовать множество атомарных векторов и создать массив, класс которого станет массивом.
векторы
Если вы хотите создать вектор с более чем одним элементом, вы должны использовать функцию c (), которая означает объединение элементов в вектор.
# Create a vector. apple <- c('red','green',"yellow") print(apple) # Get the class of the vector. print(class(apple))
Когда мы выполняем приведенный выше код, он дает следующий результат —
[1] "red" "green" "yellow" [1] "character"
Списки
Список — это R-объект, который может содержать в себе множество различных типов элементов, таких как векторы, функции и даже другой список внутри него.
# Create a list. list1 <- list(c(2,5,3),21.3,sin) # Print the list. print(list1)
Когда мы выполняем приведенный выше код, он дает следующий результат —
[[1]]
[1] 2 5 3
[[2]]
[1] 21.3
[[3]]
function (x) .Primitive("sin")
Матрицы
Матрица — это двумерный прямоугольный набор данных. Его можно создать с помощью векторного ввода в матричную функцию.
# Create a matrix. M = matrix( c('a','a','b','c','b','a'), nrow = 2, ncol = 3, byrow = TRUE) print(M)
Когда мы выполняем приведенный выше код, он дает следующий результат —
[,1] [,2] [,3] [1,] "a" "a" "b" [2,] "c" "b" "a"
Массивы
Хотя матрицы ограничены двумя измерениями, массивы могут иметь любое количество измерений. Функция массива принимает атрибут dim, который создает необходимое количество измерений. В приведенном ниже примере мы создаем массив с двумя элементами по 3×3 матрицы каждый.
# Create an array. a <- array(c('green','yellow'),dim = c(3,3,2)) print(a)
Когда мы выполняем приведенный выше код, он дает следующий результат —
, , 1
[,1] [,2] [,3]
[1,] "green" "yellow" "green"
[2,] "yellow" "green" "yellow"
[3,] "green" "yellow" "green"
, , 2
[,1] [,2] [,3]
[1,] "yellow" "green" "yellow"
[2,] "green" "yellow" "green"
[3,] "yellow" "green" "yellow"
факторы
Факторы — это r-объекты, которые создаются с использованием вектора. Он хранит вектор вместе с различными значениями элементов в векторе как метки. Метки всегда символьные, независимо от того, являются ли они числовыми, символьными, логическими и т. Д. Во входном векторе. Они полезны в статистическом моделировании.
Факторы создаются с помощью функции factor () . Функции nlevels дают количество уровней.
# Create a vector. apple_colors <- c('green','green','yellow','red','red','red','green') # Create a factor object. factor_apple <- factor(apple_colors) # Print the factor. print(factor_apple) print(nlevels(factor_apple))
Когда мы выполняем приведенный выше код, он дает следующий результат —
[1] green green yellow red red red green Levels: green red yellow [1] 3
Фреймы данных
Фреймы данных являются табличными объектами данных. В отличие от матрицы во фрейме данных каждый столбец может содержать разные режимы данных. Первый столбец может быть числовым, в то время как второй столбец может быть символьным, а третий столбец может быть логическим. Это список векторов равной длины.
Фреймы данных создаются с использованием функции data.frame () .
# Create the data frame. BMI <- data.frame( gender = c("Male", "Male","Female"), height = c(152, 171.5, 165), weight = c(81,93, 78), Age = c(42,38,26) ) print(BMI)
Когда мы выполняем приведенный выше код, он дает следующий результат —
gender height weight Age 1 Male 152.0 81 42 2 Male 171.5 93 38 3 Female 165.0 78 26
R — переменные
Переменная предоставляет нам именованное хранилище, которым наши программы могут манипулировать. Переменная в R может хранить атомный вектор, группу атомных векторов или комбинацию множества роботов. Допустимое имя переменной состоит из букв, цифр и символов точки или подчеркивания. Имя переменной начинается с буквы или точки, за которой не следует число.
| Имя переменной | Период действия | причина |
|---|---|---|
| var_name2. | действительный | Имеет буквы, цифры, точку и подчеркивание |
| var_name% | Недействительным | Имеет символ «%». Допускается только точка (.) И подчеркивание. |
| 2var_name | недействительным | Начинается с числа |
|
.var_name, var.name |
действительный | Может начинаться с точки (.), Но за точкой (.) Не должно следовать число. |
| .2var_name | недействительным | За начальной точкой следует число, делающее его недействительным. |
| _var_name | недействительным | Начинается с _, что недопустимо |
.var_name,
var.name
Назначение переменной
Переменным можно присваивать значения, используя левую, правую и равные оператору. Значения переменных могут быть напечатаны с использованием функции print () или cat () . Функция cat () объединяет несколько элементов в непрерывный вывод на печать.
# Assignment using equal operator. var.1 = c(0,1,2,3) # Assignment using leftward operator. var.2 <- c("learn","R") # Assignment using rightward operator. c(TRUE,1) -> var.3 print(var.1) cat ("var.1 is ", var.1 ,"\n") cat ("var.2 is ", var.2 ,"\n") cat ("var.3 is ", var.3 ,"\n")
Когда мы выполняем приведенный выше код, он дает следующий результат —
[1] 0 1 2 3 var.1 is 0 1 2 3 var.2 is learn R var.3 is 1 1
Примечание . Вектор c (TRUE, 1) имеет сочетание логического и числового классов. Таким образом, логический класс приведен к числовому классу, делающему TRUE в 1.
Тип данных переменной
В R сама переменная не объявляется ни для какого типа данных, скорее она получает тип данных назначенного ей R-объекта. Таким образом, R называется динамически типизированным языком, что означает, что мы можем снова и снова изменять тип данных переменной для той же переменной при использовании его в программе.
var_x <- "Hello" cat("The class of var_x is ",class(var_x),"\n") var_x <- 34.5 cat(" Now the class of var_x is ",class(var_x),"\n") var_x <- 27L cat(" Next the class of var_x becomes ",class(var_x),"\n")
Когда мы выполняем приведенный выше код, он дает следующий результат —
The class of var_x is character
Now the class of var_x is numeric
Next the class of var_x becomes integer
Поиск переменных
Чтобы узнать все переменные, доступные в данный момент в рабочей области, мы используем функцию ls () . Также функция ls () может использовать шаблоны для сопоставления имен переменных.
print(ls())
Когда мы выполняем приведенный выше код, он дает следующий результат —
[1] "my var" "my_new_var" "my_var" "var.1" [5] "var.2" "var.3" "var.name" "var_name2." [9] "var_x" "varname"
Примечание. Это пример вывода в зависимости от того, какие переменные объявлены в вашей среде.
Функция ls () может использовать шаблоны для сопоставления имен переменных.
# List the variables starting with the pattern "var". print(ls(pattern = "var"))
Когда мы выполняем приведенный выше код, он дает следующий результат —
[1] "my var" "my_new_var" "my_var" "var.1" [5] "var.2" "var.3" "var.name" "var_name2." [9] "var_x" "varname"
Переменные, начинающиеся с точки (.) , Скрыты, их можно перечислить с помощью аргумента «all.names = TRUE» функции ls ().
print(ls(all.name = TRUE))
Когда мы выполняем приведенный выше код, он дает следующий результат —
[1] ".cars" ".Random.seed" ".var_name" ".varname" ".varname2" [6] "my var" "my_new_var" "my_var" "var.1" "var.2" [11]"var.3" "var.name" "var_name2." "var_x"
Удаление переменных
Переменные могут быть удалены с помощью функции rm () . Ниже мы удаляем переменную var.3. При печати значение переменной выдается.
rm(var.3) print(var.3)
Когда мы выполняем приведенный выше код, он дает следующий результат —
[1] "var.3" Error in print(var.3) : object 'var.3' not found
Все переменные могут быть удалены с помощью функции rm () и ls () вместе.
rm(list = ls()) print(ls())
Когда мы выполняем приведенный выше код, он дает следующий результат —
character(0)
R — Операторы
Оператор — это символ, который указывает компилятору выполнять определенные математические или логические манипуляции. Язык R богат встроенными операторами и предоставляет следующие типы операторов.
Типы операторов
У нас есть следующие типы операторов в R программировании —
- Арифметические Операторы
- Операторы отношений
- Логические Операторы
- Операторы присваивания
- Разные операторы
Арифметические Операторы
В следующей таблице приведены арифметические операторы, поддерживаемые языком R. Операторы действуют на каждый элемент вектора.
| оператор | Описание | пример |
|---|---|---|
| + | Добавляет два вектора | Live Demo
v <- c( 2,5.5,6) t <- c(8, 3, 4) print(v+t) это дает следующий результат — [1] 10.0 8.5 10.0 |
| — | Вычитает второй вектор из первого | Live Demo
v <- c( 2,5.5,6) t <- c(8, 3, 4) print(v-t) это дает следующий результат — [1] -6.0 2.5 2.0 |
| * | Умножает оба вектора | Live Demo
v <- c( 2,5.5,6) t <- c(8, 3, 4) print(v*t) это дает следующий результат — [1] 16.0 16.5 24.0 |
| / | Разделите первый вектор на второй | Live Demo
v <- c( 2,5.5,6) t <- c(8, 3, 4) print(v/t) Когда мы выполняем приведенный выше код, он дает следующий результат — [1] 0.250000 1.833333 1.500000 |
| %% | Дайте остаток от первого вектора со вторым | Live Demo
v <- c( 2,5.5,6) t <- c(8, 3, 4) print(v%%t) это дает следующий результат — [1] 2.0 2.5 2.0 |
| % /% | Результат деления первого вектора на второй (частное) | Live Demo
v <- c( 2,5.5,6) t <- c(8, 3, 4) print(v%/%t) это дает следующий результат — [1] 0 1 1 |
| ^ | Первый вектор возведен в степень второго вектора | Live Demo
v <- c( 2,5.5,6) t <- c(8, 3, 4) print(v^t) это дает следующий результат — [1] 256.000 166.375 1296.000 |
это дает следующий результат —
это дает следующий результат —
это дает следующий результат —
Когда мы выполняем приведенный выше код, он дает следующий результат —
это дает следующий результат —
это дает следующий результат —
это дает следующий результат —
Операторы отношений
Следующая таблица показывает реляционные операторы, поддерживаемые языком R. Каждый элемент первого вектора сравнивается с соответствующим элементом второго вектора. Результатом сравнения является логическое значение.
| оператор | Описание | пример |
|---|---|---|
| > | Проверяет, больше ли каждый элемент первого вектора, чем соответствующий элемент второго вектора. | Live Demo
v <- c(2,5.5,6,9) t <- c(8,2.5,14,9) print(v>t) это дает следующий результат — [1] FALSE TRUE FALSE FALSE |
| < | Проверяет, меньше ли каждый элемент первого вектора, чем соответствующий элемент второго вектора. | Live Demo
v <- c(2,5.5,6,9) t <- c(8,2.5,14,9) print(v < t) это дает следующий результат — [1] TRUE FALSE TRUE FALSE |
| == | Проверяет, равен ли каждый элемент первого вектора соответствующему элементу второго вектора. | Live Demo
v <- c(2,5.5,6,9) t <- c(8,2.5,14,9) print(v == t) это дает следующий результат — [1] FALSE FALSE FALSE TRUE |
| <= | Проверяет, является ли каждый элемент первого вектора меньшим или равным соответствующему элементу второго вектора. | Live Demo
v <- c(2,5.5,6,9) t <- c(8,2.5,14,9) print(v<=t) это дает следующий результат — [1] TRUE FALSE TRUE TRUE |
| > = | Проверяет, является ли каждый элемент первого вектора большим или равным соответствующему элементу второго вектора. | Live Demo
v <- c(2,5.5,6,9) t <- c(8,2.5,14,9) print(v>=t) это дает следующий результат — [1] FALSE TRUE FALSE TRUE |
| знак равно | Проверяет, не равен ли каждый элемент первого вектора соответствующему элементу второго вектора. | Live Demo
v <- c(2,5.5,6,9) t <- c(8,2.5,14,9) print(v!=t) это дает следующий результат — [1] TRUE TRUE TRUE FALSE |
это дает следующий результат —
это дает следующий результат —
это дает следующий результат —
это дает следующий результат —
это дает следующий результат —
это дает следующий результат —
Логические Операторы
В следующей таблице приведены логические операторы, поддерживаемые языком R. Он применим только к векторам типа логический, числовой или комплексный. Все числа больше 1 считаются логическим значением ИСТИНА.
Каждый элемент первого вектора сравнивается с соответствующим элементом второго вектора. Результатом сравнения является логическое значение.
| оператор | Описание | пример |
|---|---|---|
| & | Это называется поэлементным логическим оператором И. Он объединяет каждый элемент первого вектора с соответствующим элементом второго вектора и выдает выходной TRUE, если оба элемента имеют значение TRUE. | Live Demo
v <- c(3,1,TRUE,2+3i) t <- c(4,1,FALSE,2+3i) print(v&t) это дает следующий результат — [1] TRUE TRUE FALSE TRUE |
| | | Это называется поэлементным логическим оператором ИЛИ. Он объединяет каждый элемент первого вектора с соответствующим элементом второго вектора и выдает выходной ИСТИНА, если один из элементов равен ИСТИНА. | Live Demo
v <- c(3,0,TRUE,2+2i) t <- c(4,0,FALSE,2+3i) print(v|t) это дает следующий результат — [1] TRUE FALSE TRUE TRUE |
| ! | Это называется логическим оператором NOT. Берет каждый элемент вектора и дает противоположное логическое значение. | Live Demo
v <- c(3,0,TRUE,2+2i) print(!v) это дает следующий результат — [1] FALSE TRUE FALSE FALSE |
это дает следующий результат —
это дает следующий результат —
это дает следующий результат —
Логический оператор && и || рассматривает только первый элемент векторов и выдает вектор одного элемента в качестве выходных данных.
| оператор | Описание | пример |
|---|---|---|
| && | Называется логический оператор И. Принимает первый элемент обоих векторов и дает ИСТИНА, только если оба ИСТИНА. | Live Demo
v <- c(3,0,TRUE,2+2i) t <- c(1,3,TRUE,2+3i) print(v&&t) это дает следующий результат — [1] TRUE |
| || | Вызывается оператором логического ИЛИ. Принимает первый элемент обоих векторов и дает ИСТИНА, если один из них ИСТИНА. | Live Demo
v <- c(0,0,TRUE,2+2i) t <- c(0,3,TRUE,2+3i) print(v||t) это дает следующий результат — [1] FALSE |
это дает следующий результат —
это дает следующий результат —
Операторы присваивания
Эти операторы используются для присвоения значений векторам.
| оператор | Описание | пример |
|---|---|---|
|
<- или же знак равно или же << — |
Вызывается Левое назначение | Live Demo
v1 <- c(3,1,TRUE,2+3i) v2 <<- c(3,1,TRUE,2+3i) v3 = c(3,1,TRUE,2+3i) print(v1) print(v2) print(v3) это дает следующий результат — [1] 3+0i 1+0i 1+0i 2+3i [1] 3+0i 1+0i 1+0i 2+3i [1] 3+0i 1+0i 1+0i 2+3i |
|
-> или же — >> |
Называется право назначения | Live Demo
c(3,1,TRUE,2+3i) -> v1 c(3,1,TRUE,2+3i) ->> v2 print(v1) print(v2) это дает следующий результат — [1] 3+0i 1+0i 1+0i 2+3i [1] 3+0i 1+0i 1+0i 2+3i |
<-
или же
знак равно
или же
<< —
это дает следующий результат —
->
или же
— >>
это дает следующий результат —
Разные операторы
Эти операторы используются для специальных целей, а не для общих математических или логических вычислений.
| оператор | Описание | пример |
|---|---|---|
| : | Оператор двоеточия. Создает последовательность чисел в последовательности для вектора. | Live Demo
v <- 2:8 print(v) это дает следующий результат — [1] 2 3 4 5 6 7 8 |
| %в% | Этот оператор используется для определения, принадлежит ли элемент вектору. | Live Demo
v1 <- 8 v2 <- 12 t <- 1:10 print(v1 %in% t) print(v2 %in% t) это дает следующий результат — [1] TRUE [1] FALSE |
| % *% | Этот оператор используется для умножения матрицы на ее транспонирование. | Live Demo
M = matrix( c(2,6,5,1,10,4), nrow = 2,ncol = 3,byrow = TRUE) t = M %*% t(M) print(t) это дает следующий результат — [,1] [,2] [1,] 65 82 [2,] 82 117 |
это дает следующий результат —
это дает следующий результат —
это дает следующий результат —
R — принятие решений
Структуры принятия решений требуют, чтобы программист указал одно или несколько условий, которые должны быть оценены или протестированы программой, вместе с оператором или инструкциями, которые должны быть выполнены, если условие определено как истинное , и, необязательно, другие операторы, которые должны быть выполнены, если условие определяется как ложный .
Ниже приводится общая форма типичной структуры принятия решений, встречающейся в большинстве языков программирования.
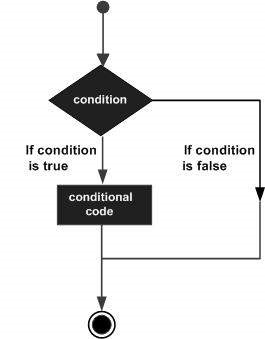
R предоставляет следующие типы заявлений о принятии решений. Нажмите на следующие ссылки, чтобы проверить их детали.
| Sr.No. | Заявление и описание |
|---|---|
| 1 | если заявление
Оператор if состоит из логического выражения, за которым следует один или несколько операторов. |
| 2 | если … еще заявление
За оператором if может следовать необязательный оператор else , который выполняется, когда логическое выражение имеет значение false. |
| 3 | заявление о переключении
Оператор switch позволяет проверять переменную на соответствие списку значений. |
Оператор if состоит из логического выражения, за которым следует один или несколько операторов.
За оператором if может следовать необязательный оператор else , который выполняется, когда логическое выражение имеет значение false.
Оператор switch позволяет проверять переменную на соответствие списку значений.
R — Петли
Может возникнуть ситуация, когда вам нужно выполнить блок кода несколько раз. Как правило, операторы выполняются последовательно. Первый оператор в функции выполняется первым, затем следует второй и так далее.
Языки программирования предоставляют различные управляющие структуры, которые допускают более сложные пути выполнения.
Оператор цикла позволяет нам выполнять оператор или группу операторов несколько раз, и ниже приводится общая форма оператора цикла в большинстве языков программирования:
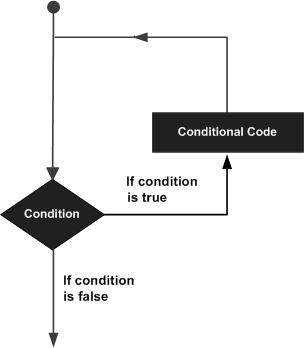
Язык программирования R предоставляет следующие виды циклов для обработки требований циклов. Нажмите на следующие ссылки, чтобы проверить их детали.
| Sr.No. | Тип и описание петли |
|---|---|
| 1 | повторить цикл
Выполняет последовательность операторов несколько раз и сокращает код, который управляет переменной цикла. |
| 2 | в то время как цикл
Повторяет оператор или группу операторов, пока данное условие выполняется. Он проверяет условие перед выполнением тела цикла. |
| 3 | для цикла
Как оператор while, за исключением того, что он проверяет условие в конце тела цикла. |
Выполняет последовательность операторов несколько раз и сокращает код, который управляет переменной цикла.
Повторяет оператор или группу операторов, пока данное условие выполняется. Он проверяет условие перед выполнением тела цикла.
Как оператор while, за исключением того, что он проверяет условие в конце тела цикла.
Заявления о контроле цикла
Операторы управления циклом изменяют выполнение от его нормальной последовательности. Когда выполнение покидает область действия, все автоматические объекты, созданные в этой области, уничтожаются.
R поддерживает следующие операторы управления. Нажмите на следующие ссылки, чтобы проверить их детали.
| Sr.No. | Контрольное заявление и описание |
|---|---|
| 1 | заявление о нарушении
Завершает оператор цикла и передает выполнение в оператор, следующий сразу за циклом. |
| 2 | Следующее утверждение
Следующее утверждение имитирует поведение переключателя R. |
Завершает оператор цикла и передает выполнение в оператор, следующий сразу за циклом.
Следующее утверждение имитирует поведение переключателя R.
R — Функции
Функция — это набор операторов, организованных вместе для выполнения определенной задачи. R имеет большое количество встроенных функций, и пользователь может создавать свои собственные функции.
В R функция — это объект, поэтому интерпретатор R может передать управление функции вместе с аргументами, которые могут понадобиться функции для выполнения действий.
Функция, в свою очередь, выполняет свою задачу и возвращает управление интерпретатору, а также любой результат, который может быть сохранен в других объектах.
Определение функции
Функция R создается с помощью ключевой функции . Основной синтаксис определения функции R следующий:
function_name <- function(arg_1, arg_2, ...) {
Function body
}
Компоненты функций
Различные части функции —
-
Имя функции — это фактическое имя функции. Он хранится в среде R как объект с таким именем.
-
Аргументы — Аргумент является заполнителем. Когда вызывается функция, вы передаете значение аргументу. Аргументы необязательны; то есть функция может не содержать аргументов. Также аргументы могут иметь значения по умолчанию.
-
Тело функции — Тело функции содержит набор операторов, которые определяют, что делает функция.
-
Возвращаемое значение — возвращаемое значение функции является последним выражением в теле функции, которое будет оценено.
Имя функции — это фактическое имя функции. Он хранится в среде R как объект с таким именем.
Аргументы — Аргумент является заполнителем. Когда вызывается функция, вы передаете значение аргументу. Аргументы необязательны; то есть функция может не содержать аргументов. Также аргументы могут иметь значения по умолчанию.
Тело функции — Тело функции содержит набор операторов, которые определяют, что делает функция.
Возвращаемое значение — возвращаемое значение функции является последним выражением в теле функции, которое будет оценено.
В R много встроенных функций, которые можно напрямую вызывать в программе, не определяя их в первую очередь. Мы также можем создавать и использовать наши собственные функции, называемые пользовательскими функциями.
Встроенная функция
Простыми примерами встроенных функций являются seq () , mean () , max () , sum (x) и paste (…) и т. Д. Они напрямую вызываются пользовательскими программами. Вы можете ссылаться на наиболее широко используемые функции R.
# Create a sequence of numbers from 32 to 44. print(seq(32,44)) # Find mean of numbers from 25 to 82. print(mean(25:82)) # Find sum of numbers frm 41 to 68. print(sum(41:68))
Когда мы выполняем приведенный выше код, он дает следующий результат —
[1] 32 33 34 35 36 37 38 39 40 41 42 43 44 [1] 53.5 [1] 1526
Пользовательская функция
Мы можем создавать пользовательские функции в R. Они специфичны для того, что хочет пользователь, и после их создания они могут использоваться как встроенные функции. Ниже приведен пример того, как функция создается и используется.
# Create a function to print squares of numbers in sequence. new.function <- function(a) { for(i in 1:a) { b <- i^2 print(b) } }
Вызов функции
# Create a function to print squares of numbers in sequence. new.function <- function(a) { for(i in 1:a) { b <- i^2 print(b) } } # Call the function new.function supplying 6 as an argument. new.function(6)
Когда мы выполняем приведенный выше код, он дает следующий результат —
[1] 1 [1] 4 [1] 9 [1] 16 [1] 25 [1] 36
Вызов функции без аргумента
# Create a function without an argument. new.function <- function() { for(i in 1:5) { print(i^2) } } # Call the function without supplying an argument. new.function()
Когда мы выполняем приведенный выше код, он дает следующий результат —
[1] 1 [1] 4 [1] 9 [1] 16 [1] 25
Вызов функции со значениями аргумента (по позиции и по имени)
Аргументы для вызова функции могут быть предоставлены в той же последовательности, как определено в функции, или они могут быть предоставлены в другой последовательности, но назначены именам аргументов.
# Create a function with arguments. new.function <- function(a,b,c) { result <- a * b + c print(result) } # Call the function by position of arguments. new.function(5,3,11) # Call the function by names of the arguments. new.function(a = 11, b = 5, c = 3)
Когда мы выполняем приведенный выше код, он дает следующий результат —
[1] 26 [1] 58
Вызов функции с аргументом по умолчанию
Мы можем определить значение аргументов в определении функции и вызвать функцию без указания аргумента, чтобы получить результат по умолчанию. Но мы также можем вызывать такие функции, предоставляя новые значения аргумента и получая результат не по умолчанию.
# Create a function with arguments. new.function <- function(a = 3, b = 6) { result <- a * b print(result) } # Call the function without giving any argument. new.function() # Call the function with giving new values of the argument. new.function(9,5)
Когда мы выполняем приведенный выше код, он дает следующий результат —
[1] 18 [1] 45
Ленивая оценка функции
Аргументы функций оцениваются лениво, что означает, что они оцениваются только тогда, когда это необходимо для тела функции.
# Create a function with arguments. new.function <- function(a, b) { print(a^2) print(a) print(b) } # Evaluate the function without supplying one of the arguments. new.function(6)
Когда мы выполняем приведенный выше код, он дает следующий результат —
[1] 36 [1] 6 Error in print(b) : argument "b" is missing, with no default
R — Струны
Любое значение, записанное в паре одинарных или двойных кавычек в R, рассматривается как строка. Внутри R каждая строка хранится в двойных кавычках, даже если вы создаете их в одинарных кавычках.
Правила, применяемые в строках строк
-
Кавычки в начале и конце строки должны быть как двойными, так и одинарными. Они не могут быть смешаны.
-
Двойные кавычки могут быть вставлены в строку, начинающуюся и заканчивающуюся одинарной кавычкой.
-
Одиночная кавычка может быть вставлена в строку, начинающуюся и заканчивающуюся двойными кавычками.
-
Двойные кавычки не могут быть вставлены в строку, начинающуюся и заканчивающуюся двойными кавычками.
-
Одиночная кавычка не может быть вставлена в строку, начинающуюся и заканчивающуюся одинарной кавычкой.
Кавычки в начале и конце строки должны быть как двойными, так и одинарными. Они не могут быть смешаны.
Двойные кавычки могут быть вставлены в строку, начинающуюся и заканчивающуюся одинарной кавычкой.
Одиночная кавычка может быть вставлена в строку, начинающуюся и заканчивающуюся двойными кавычками.
Двойные кавычки не могут быть вставлены в строку, начинающуюся и заканчивающуюся двойными кавычками.
Одиночная кавычка не может быть вставлена в строку, начинающуюся и заканчивающуюся одинарной кавычкой.
Примеры допустимых строк
Следующие примеры поясняют правила создания строки в R.
a <- 'Start and end with single quote' print(a) b <- "Start and end with double quotes" print(b) c <- "single quote ' in between double quotes" print(c) d <- 'Double quotes " in between single quote' print(d)
Когда приведенный выше код выполняется, мы получаем следующий вывод:
[1] "Start and end with single quote" [1] "Start and end with double quotes" [1] "single quote ' in between double quote" [1] "Double quote \" in between single quote"
Примеры неверных строк
e <- 'Mixed quotes" print(e) f <- 'Single quote ' inside single quote' print(f) g <- "Double quotes " inside double quotes" print(g)
Когда мы запускаем скрипт, он не дает результатов ниже.
Error: unexpected symbol in: "print(e) f <- 'Single" Execution halted
Манипуляция строк
Конкатенация строк — функция вставки ()
Многие строки в R объединяются с использованием функции paste () . Может потребоваться любое количество аргументов для объединения.
Синтаксис
Основной синтаксис для функции вставки —
paste(..., sep = " ", collapse = NULL)
Ниже приведено описание используемых параметров:
-
… представляет любое количество аргументов для объединения.
-
sep представляет любой разделитель между аргументами. Это необязательно.
-
Свернуть используется для устранения пробела между двумя строками. Но не пробел в двух словах одной строки.
… представляет любое количество аргументов для объединения.
sep представляет любой разделитель между аргументами. Это необязательно.
Свернуть используется для устранения пробела между двумя строками. Но не пробел в двух словах одной строки.
пример
a <- "Hello" b <- 'How' c <- "are you? " print(paste(a,b,c)) print(paste(a,b,c, sep = "-")) print(paste(a,b,c, sep = "", collapse = ""))
Когда мы выполняем приведенный выше код, он дает следующий результат —
[1] "Hello How are you? " [1] "Hello-How-are you? " [1] "HelloHoware you? "
Форматирование чисел и строк — функция format ()
Числа и строки могут быть отформатированы в определенный стиль с помощью функции format () .
Синтаксис
Основной синтаксис для функции форматирования —
format(x, digits, nsmall, scientific, width, justify = c("left", "right", "centre", "none"))
Ниже приведено описание используемых параметров:
-
х является векторным входом.
-
цифры — это общее количество отображаемых цифр.
-
nsmall — это минимальное количество цифр справа от десятичной точки.
-
Scientific установлен в TRUE для отображения научной записи.
-
ширина указывает минимальную ширину, которая должна отображаться при добавлении пробелов в начале.
-
justify — отображение строки слева, справа или по центру.
х является векторным входом.
цифры — это общее количество отображаемых цифр.
nsmall — это минимальное количество цифр справа от десятичной точки.
Scientific установлен в TRUE для отображения научной записи.
ширина указывает минимальную ширину, которая должна отображаться при добавлении пробелов в начале.
justify — отображение строки слева, справа или по центру.
пример
# Total number of digits displayed. Last digit rounded off. result <- format(23.123456789, digits = 9) print(result) # Display numbers in scientific notation. result <- format(c(6, 13.14521), scientific = TRUE) print(result) # The minimum number of digits to the right of the decimal point. result <- format(23.47, nsmall = 5) print(result) # Format treats everything as a string. result <- format(6) print(result) # Numbers are padded with blank in the beginning for width. result <- format(13.7, width = 6) print(result) # Left justify strings. result <- format("Hello", width = 8, justify = "l") print(result) # Justfy string with center. result <- format("Hello", width = 8, justify = "c") print(result)
Когда мы выполняем приведенный выше код, он дает следующий результат —
[1] "23.1234568" [1] "6.000000e+00" "1.314521e+01" [1] "23.47000" [1] "6" [1] " 13.7" [1] "Hello " [1] " Hello "
Подсчет количества символов в строке — функция nchar ()
Эта функция считает количество символов, включая пробелы в строке.
Синтаксис
Основной синтаксис для функции nchar () —
nchar(x)
Ниже приведено описание используемых параметров:
-
х является векторным входом.
х является векторным входом.
пример
result <- nchar("Count the number of characters") print(result)
Когда мы выполняем приведенный выше код, он дает следующий результат —
[1] 30
Изменение регистра — функции toupper () и tolower ()
Эти функции изменяют регистр символов строки.
Синтаксис
Основной синтаксис функции toupper () и tolower () —
toupper(x) tolower(x)
Ниже приведено описание используемых параметров:
-
х является векторным входом.
х является векторным входом.
пример
# Changing to Upper case. result <- toupper("Changing To Upper") print(result) # Changing to lower case. result <- tolower("Changing To Lower") print(result)
Когда мы выполняем приведенный выше код, он дает следующий результат —
[1] "CHANGING TO UPPER" [1] "changing to lower"
Извлечение частей строки — функция substring ()
Эта функция извлекает части строки.
Синтаксис
Основной синтаксис для функции substring () —
substring(x,first,last)
Ниже приведено описание используемых параметров:
-
х — символьный вектор ввода.
-
first — позиция первого символа для извлечения.
-
last — позиция последнего извлекаемого символа
х — символьный вектор ввода.
first — позиция первого символа для извлечения.
last — позиция последнего извлекаемого символа
пример
# Extract characters from 5th to 7th position. result <- substring("Extract", 5, 7) print(result)
Когда мы выполняем приведенный выше код, он дает следующий результат —
[1] "act"
R — Векторы
Векторы являются наиболее основными объектами данных R, и существует шесть типов атомных векторов. Они являются логическими, целыми, двойными, сложными, символьными и необработанными.
Создание вектора
Единственный элемент вектора
Даже когда вы записываете только одно значение в R, оно становится вектором длины 1 и относится к одному из указанных выше типов векторов.
# Atomic vector of type character. print("abc"); # Atomic vector of type double. print(12.5) # Atomic vector of type integer. print(63L) # Atomic vector of type logical. print(TRUE) # Atomic vector of type complex. print(2+3i) # Atomic vector of type raw. print(charToRaw('hello'))
Когда мы выполняем приведенный выше код, он дает следующий результат —
[1] "abc" [1] 12.5 [1] 63 [1] TRUE [1] 2+3i [1] 68 65 6c 6c 6f
Несколько элементов вектора
Использование оператора двоеточия с числовыми данными
# Creating a sequence from 5 to 13. v <- 5:13 print(v) # Creating a sequence from 6.6 to 12.6. v <- 6.6:12.6 print(v) # If the final element specified does not belong to the sequence then it is discarded. v <- 3.8:11.4 print(v)
Когда мы выполняем приведенный выше код, он дает следующий результат —
[1] 5 6 7 8 9 10 11 12 13 [1] 6.6 7.6 8.6 9.6 10.6 11.6 12.6 [1] 3.8 4.8 5.8 6.8 7.8 8.8 9.8 10.8
Использование оператора последовательности (Seq.)
# Create vector with elements from 5 to 9 incrementing by 0.4. print(seq(5, 9, by = 0.4))
Когда мы выполняем приведенный выше код, он дает следующий результат —
[1] 5.0 5.4 5.8 6.2 6.6 7.0 7.4 7.8 8.2 8.6 9.0
Использование функции c ()
Не символьные значения приводятся к типу символа, если один из элементов является символом.
# The logical and numeric values are converted to characters. s <- c('apple','red',5,TRUE) print(s)
Когда мы выполняем приведенный выше код, он дает следующий результат —
[1] "apple" "red" "5" "TRUE"
Доступ к элементам вектора
Элементы вектора доступны с помощью индексации. Скобки [] используются для индексации. Индексирование начинается с позиции 1. Если задано отрицательное значение в индексе, этот элемент удаляется из результата. TRUE , FALSE или 0 и 1 также могут использоваться для индексации.
# Accessing vector elements using position. t <- c("Sun","Mon","Tue","Wed","Thurs","Fri","Sat") u <- t[c(2,3,6)] print(u) # Accessing vector elements using logical indexing. v <- t[c(TRUE,FALSE,FALSE,FALSE,FALSE,TRUE,FALSE)] print(v) # Accessing vector elements using negative indexing. x <- t[c(-2,-5)] print(x) # Accessing vector elements using 0/1 indexing. y <- t[c(0,0,0,0,0,0,1)] print(y)
Когда мы выполняем приведенный выше код, он дает следующий результат —
[1] "Mon" "Tue" "Fri" [1] "Sun" "Fri" [1] "Sun" "Tue" "Wed" "Fri" "Sat" [1] "Sun"
Вектор манипуляции
Векторная арифметика
Два вектора одинаковой длины могут быть добавлены, вычтены, умножены или разделены, давая результат в виде векторного вывода.
# Create two vectors. v1 <- c(3,8,4,5,0,11) v2 <- c(4,11,0,8,1,2) # Vector addition. add.result <- v1+v2 print(add.result) # Vector subtraction. sub.result <- v1-v2 print(sub.result) # Vector multiplication. multi.result <- v1*v2 print(multi.result) # Vector division. divi.result <- v1/v2 print(divi.result)
Когда мы выполняем приведенный выше код, он дает следующий результат —
[1] 7 19 4 13 1 13 [1] -1 -3 4 -3 -1 9 [1] 12 88 0 40 0 22 [1] 0.7500000 0.7272727 Inf 0.6250000 0.0000000 5.5000000
Переработка векторных элементов
Если мы применяем арифметические операции к двум векторам неравной длины, то элементы более короткого вектора повторно используются для завершения операций.
v1 <- c(3,8,4,5,0,11) v2 <- c(4,11) # V2 becomes c(4,11,4,11,4,11) add.result <- v1+v2 print(add.result) sub.result <- v1-v2 print(sub.result)
Когда мы выполняем приведенный выше код, он дает следующий результат —
[1] 7 19 8 16 4 22 [1] -1 -3 0 -6 -4 0
Сортировка векторных элементов
Элементы в векторе можно отсортировать с помощью функции sort () .
v <- c(3,8,4,5,0,11, -9, 304) # Sort the elements of the vector. sort.result <- sort(v) print(sort.result) # Sort the elements in the reverse order. revsort.result <- sort(v, decreasing = TRUE) print(revsort.result) # Sorting character vectors. v <- c("Red","Blue","yellow","violet") sort.result <- sort(v) print(sort.result) # Sorting character vectors in reverse order. revsort.result <- sort(v, decreasing = TRUE) print(revsort.result)
Когда мы выполняем приведенный выше код, он дает следующий результат —
[1] -9 0 3 4 5 8 11 304 [1] 304 11 8 5 4 3 0 -9 [1] "Blue" "Red" "violet" "yellow" [1] "yellow" "violet" "Red" "Blue"
R — Списки
Списки — это объекты R, которые содержат элементы различных типов, такие как числа, строки, векторы и другой список внутри него. Список также может содержать матрицу или функцию в качестве своих элементов. Список создается с помощью функции list () .
Создание списка
Ниже приведен пример создания списка, содержащего строки, числа, векторы и логические значения.
# Create a list containing strings, numbers, vectors and a logical # values. list_data <- list("Red", "Green", c(21,32,11), TRUE, 51.23, 119.1) print(list_data)
Когда мы выполняем приведенный выше код, он дает следующий результат —
[[1]] [1] "Red" [[2]] [1] "Green" [[3]] [1] 21 32 11 [[4]] [1] TRUE [[5]] [1] 51.23 [[6]] [1] 119.1
Элементы списка имен
Элементам списка могут быть присвоены имена, и к ним можно получить доступ, используя эти имена.
# Create a list containing a vector, a matrix and a list. list_data <- list(c("Jan","Feb","Mar"), matrix(c(3,9,5,1,-2,8), nrow = 2), list("green",12.3)) # Give names to the elements in the list. names(list_data) <- c("1st Quarter", "A_Matrix", "A Inner list") # Show the list. print(list_data)
Когда мы выполняем приведенный выше код, он дает следующий результат —
$`1st_Quarter`
[1] "Jan" "Feb" "Mar"
$A_Matrix
[,1] [,2] [,3]
[1,] 3 5 -2
[2,] 9 1 8
$A_Inner_list
$A_Inner_list[[1]]
[1] "green"
$A_Inner_list[[2]]
[1] 12.3
Доступ к элементам списка
Элементы списка могут быть доступны по индексу элемента в списке. В случае именованных списков к нему также можно получить доступ, используя имена.
Мы продолжаем использовать список в приведенном выше примере —
# Create a list containing a vector, a matrix and a list. list_data <- list(c("Jan","Feb","Mar"), matrix(c(3,9,5,1,-2,8), nrow = 2), list("green",12.3)) # Give names to the elements in the list. names(list_data) <- c("1st Quarter", "A_Matrix", "A Inner list") # Access the first element of the list. print(list_data[1]) # Access the thrid element. As it is also a list, all its elements will be printed. print(list_data[3]) # Access the list element using the name of the element. print(list_data$A_Matrix)
Когда мы выполняем приведенный выше код, он дает следующий результат —
$`1st_Quarter`
[1] "Jan" "Feb" "Mar"
$A_Inner_list
$A_Inner_list[[1]]
[1] "green"
$A_Inner_list[[2]]
[1] 12.3
[,1] [,2] [,3]
[1,] 3 5 -2
[2,] 9 1 8
Управление элементами списка
Мы можем добавлять, удалять и обновлять элементы списка, как показано ниже. Мы можем добавлять и удалять элементы только в конце списка. Но мы можем обновить любой элемент.
# Create a list containing a vector, a matrix and a list. list_data <- list(c("Jan","Feb","Mar"), matrix(c(3,9,5,1,-2,8), nrow = 2), list("green",12.3)) # Give names to the elements in the list. names(list_data) <- c("1st Quarter", "A_Matrix", "A Inner list") # Add element at the end of the list. list_data[4] <- "New element" print(list_data[4]) # Remove the last element. list_data[4] <- NULL # Print the 4th Element. print(list_data[4]) # Update the 3rd Element. list_data[3] <- "updated element" print(list_data[3])
Когда мы выполняем приведенный выше код, он дает следующий результат —
[[1]] [1] "New element" $<NA> NULL $`A Inner list` [1] "updated element"
Слияние списков
Вы можете объединить несколько списков в один список, поместив все списки в одну функцию list ().
# Create two lists. list1 <- list(1,2,3) list2 <- list("Sun","Mon","Tue") # Merge the two lists. merged.list <- c(list1,list2) # Print the merged list. print(merged.list)
Когда мы выполняем приведенный выше код, он дает следующий результат —
[[1]] [1] 1 [[2]] [1] 2 [[3]] [1] 3 [[4]] [1] "Sun" [[5]] [1] "Mon" [[6]] [1] "Tue"
Преобразование списка в вектор
Список может быть преобразован в вектор, чтобы элементы вектора можно было использовать для дальнейшей манипуляции. Все арифметические операции над векторами могут применяться после преобразования списка в векторы. Чтобы сделать это преобразование, мы используем функцию unlist () . Он принимает список в качестве входных данных и создает вектор.
# Create lists. list1 <- list(1:5) print(list1) list2 <-list(10:14) print(list2) # Convert the lists to vectors. v1 <- unlist(list1) v2 <- unlist(list2) print(v1) print(v2) # Now add the vectors result <- v1+v2 print(result)
Когда мы выполняем приведенный выше код, он дает следующий результат —
[[1]] [1] 1 2 3 4 5 [[1]] [1] 10 11 12 13 14 [1] 1 2 3 4 5 [1] 10 11 12 13 14 [1] 11 13 15 17 19
R — Матрицы
Матрицы — это объекты R, в которых элементы расположены в двухмерном прямоугольном макете. Они содержат элементы одного и того же атомного типа. Хотя мы можем создать матрицу, содержащую только символы или только логические значения, они не очень полезны. Мы используем матрицы, содержащие числовые элементы, которые будут использоваться в математических вычислениях.
Матрица создается с использованием функции matrix () .
Синтаксис
Основной синтаксис для создания матрицы в R —
matrix(data, nrow, ncol, byrow, dimnames)
Ниже приведено описание используемых параметров:
-
Данные — это входной вектор, который становится элементами данных матрицы.
-
nrow — количество строк, которые будут созданы.
-
ncol — количество создаваемых столбцов.
-
Byrow — логическая подсказка. Если TRUE, то входные векторные элементы упорядочены по строкам.
-
dimname — это имена, присвоенные строкам и столбцам.
Данные — это входной вектор, который становится элементами данных матрицы.
nrow — количество строк, которые будут созданы.
ncol — количество создаваемых столбцов.
Byrow — логическая подсказка. Если TRUE, то входные векторные элементы упорядочены по строкам.
dimname — это имена, присвоенные строкам и столбцам.
пример
Создайте матрицу, используя вектор чисел в качестве входных данных.
# Elements are arranged sequentially by row. M <- matrix(c(3:14), nrow = 4, byrow = TRUE) print(M) # Elements are arranged sequentially by column. N <- matrix(c(3:14), nrow = 4, byrow = FALSE) print(N) # Define the column and row names. rownames = c("row1", "row2", "row3", "row4") colnames = c("col1", "col2", "col3") P <- matrix(c(3:14), nrow = 4, byrow = TRUE, dimnames = list(rownames, colnames)) print(P)
Когда мы выполняем приведенный выше код, он дает следующий результат —
[,1] [,2] [,3]
[1,] 3 4 5
[2,] 6 7 8
[3,] 9 10 11
[4,] 12 13 14
[,1] [,2] [,3]
[1,] 3 7 11
[2,] 4 8 12
[3,] 5 9 13
[4,] 6 10 14
col1 col2 col3
row1 3 4 5
row2 6 7 8
row3 9 10 11
row4 12 13 14
Доступ к элементам матрицы
Доступ к элементам матрицы можно получить с помощью индекса столбца и строки элемента. Мы рассмотрим матрицу P выше, чтобы найти конкретные элементы ниже.
# Define the column and row names. rownames = c("row1", "row2", "row3", "row4") colnames = c("col1", "col2", "col3") # Create the matrix. P <- matrix(c(3:14), nrow = 4, byrow = TRUE, dimnames = list(rownames, colnames)) # Access the element at 3rd column and 1st row. print(P[1,3]) # Access the element at 2nd column and 4th row. print(P[4,2]) # Access only the 2nd row. print(P[2,]) # Access only the 3rd column. print(P[,3])
Когда мы выполняем приведенный выше код, он дает следующий результат —
[1] 5 [1] 13 col1 col2 col3 6 7 8 row1 row2 row3 row4 5 8 11 14
Матричные вычисления
Различные математические операции выполняются над матрицами с использованием операторов R. Результатом операции также является матрица.
Размеры (количество строк и столбцов) должны быть одинаковыми для матриц, участвующих в операции.
Матрица сложение и вычитание
# Create two 2x3 matrices. matrix1 <- matrix(c(3, 9, -1, 4, 2, 6), nrow = 2) print(matrix1) matrix2 <- matrix(c(5, 2, 0, 9, 3, 4), nrow = 2) print(matrix2) # Add the matrices. result <- matrix1 + matrix2 cat("Result of addition","\n") print(result) # Subtract the matrices result <- matrix1 - matrix2 cat("Result of subtraction","\n") print(result)
Когда мы выполняем приведенный выше код, он дает следующий результат —
[,1] [,2] [,3]
[1,] 3 -1 2
[2,] 9 4 6
[,1] [,2] [,3]
[1,] 5 0 3
[2,] 2 9 4
Result of addition
[,1] [,2] [,3]
[1,] 8 -1 5
[2,] 11 13 10
Result of subtraction
[,1] [,2] [,3]
[1,] -2 -1 -1
[2,] 7 -5 2
Умножение матриц и деление
# Create two 2x3 matrices. matrix1 <- matrix(c(3, 9, -1, 4, 2, 6), nrow = 2) print(matrix1) matrix2 <- matrix(c(5, 2, 0, 9, 3, 4), nrow = 2) print(matrix2) # Multiply the matrices. result <- matrix1 * matrix2 cat("Result of multiplication","\n") print(result) # Divide the matrices result <- matrix1 / matrix2 cat("Result of division","\n") print(result)
Когда мы выполняем приведенный выше код, он дает следующий результат —
[,1] [,2] [,3]
[1,] 3 -1 2
[2,] 9 4 6
[,1] [,2] [,3]
[1,] 5 0 3
[2,] 2 9 4
Result of multiplication
[,1] [,2] [,3]
[1,] 15 0 6
[2,] 18 36 24
Result of division
[,1] [,2] [,3]
[1,] 0.6 -Inf 0.6666667
[2,] 4.5 0.4444444 1.5000000
R — массивы
Массивы — это объекты данных R, которые могут хранить данные в более чем двух измерениях. Например, если мы создадим массив измерений (2, 3, 4), он создаст 4 прямоугольные матрицы, каждая из которых содержит 2 строки и 3 столбца. Массивы могут хранить только тип данных.
Массив создается с помощью функции array () . Он принимает векторы в качестве входных данных и использует значения в параметре dim для создания массива.
пример
В следующем примере создается массив из двух матриц 3×3, каждая из которых содержит 3 строки и 3 столбца.
# Create two vectors of different lengths. vector1 <- c(5,9,3) vector2 <- c(10,11,12,13,14,15) # Take these vectors as input to the array. result <- array(c(vector1,vector2),dim = c(3,3,2)) print(result)
Когда мы выполняем приведенный выше код, он дает следующий результат —
, , 1
[,1] [,2] [,3]
[1,] 5 10 13
[2,] 9 11 14
[3,] 3 12 15
, , 2
[,1] [,2] [,3]
[1,] 5 10 13
[2,] 9 11 14
[3,] 3 12 15
Именование столбцов и строк
Мы можем дать имена строкам, столбцам и матрицам в массиве, используя параметр dimnames .
# Create two vectors of different lengths. vector1 <- c(5,9,3) vector2 <- c(10,11,12,13,14,15) column.names <- c("COL1","COL2","COL3") row.names <- c("ROW1","ROW2","ROW3") matrix.names <- c("Matrix1","Matrix2") # Take these vectors as input to the array. result <- array(c(vector1,vector2),dim = c(3,3,2),dimnames = list(row.names,column.names, matrix.names)) print(result)
Когда мы выполняем приведенный выше код, он дает следующий результат —
, , Matrix1
COL1 COL2 COL3
ROW1 5 10 13
ROW2 9 11 14
ROW3 3 12 15
, , Matrix2
COL1 COL2 COL3
ROW1 5 10 13
ROW2 9 11 14
ROW3 3 12 15
Доступ к элементам массива
# Create two vectors of different lengths. vector1 <- c(5,9,3) vector2 <- c(10,11,12,13,14,15) column.names <- c("COL1","COL2","COL3") row.names <- c("ROW1","ROW2","ROW3") matrix.names <- c("Matrix1","Matrix2") # Take these vectors as input to the array. result <- array(c(vector1,vector2),dim = c(3,3,2),dimnames = list(row.names, column.names, matrix.names)) # Print the third row of the second matrix of the array. print(result[3,,2]) # Print the element in the 1st row and 3rd column of the 1st matrix. print(result[1,3,1]) # Print the 2nd Matrix. print(result[,,2])
Когда мы выполняем приведенный выше код, он дает следующий результат —
COL1 COL2 COL3
3 12 15
[1] 13
COL1 COL2 COL3
ROW1 5 10 13
ROW2 9 11 14
ROW3 3 12 15
Манипулирование элементами массива
Поскольку массив состоит из матриц в нескольких измерениях, операции над элементами массива выполняются путем доступа к элементам матриц.
# Create two vectors of different lengths. vector1 <- c(5,9,3) vector2 <- c(10,11,12,13,14,15) # Take these vectors as input to the array. array1 <- array(c(vector1,vector2),dim = c(3,3,2)) # Create two vectors of different lengths. vector3 <- c(9,1,0) vector4 <- c(6,0,11,3,14,1,2,6,9) array2 <- array(c(vector1,vector2),dim = c(3,3,2)) # create matrices from these arrays. matrix1 <- array1[,,2] matrix2 <- array2[,,2] # Add the matrices. result <- matrix1+matrix2 print(result)
Когда мы выполняем приведенный выше код, он дает следующий результат —
[,1] [,2] [,3] [1,] 10 20 26 [2,] 18 22 28 [3,] 6 24 30
Расчеты по элементам массива
Мы можем выполнять вычисления для элементов в массиве, используя функцию apply () .
Синтаксис
apply(x, margin, fun)
Ниже приведено описание используемых параметров:
-
х это массив.
-
margin — это имя используемого набора данных.
-
fun — это функция, применяемая к элементам массива.
х это массив.
margin — это имя используемого набора данных.
fun — это функция, применяемая к элементам массива.
пример
Мы используем функцию apply () ниже, чтобы вычислить сумму элементов в строках массива по всем матрицам.
# Create two vectors of different lengths. vector1 <- c(5,9,3) vector2 <- c(10,11,12,13,14,15) # Take these vectors as input to the array. new.array <- array(c(vector1,vector2),dim = c(3,3,2)) print(new.array) # Use apply to calculate the sum of the rows across all the matrices. result <- apply(new.array, c(1), sum) print(result)
Когда мы выполняем приведенный выше код, он дает следующий результат —
, , 1
[,1] [,2] [,3]
[1,] 5 10 13
[2,] 9 11 14
[3,] 3 12 15
, , 2
[,1] [,2] [,3]
[1,] 5 10 13
[2,] 9 11 14
[3,] 3 12 15
[1] 56 68 60
R — Факторы
Факторы — это объекты данных, которые используются для классификации данных и их хранения в виде уровней. Они могут хранить как строки, так и целые числа. Они полезны в столбцах с ограниченным числом уникальных значений. Как «Мужской», «Женский» и «Правда», «Ложь» и т. Д. Они полезны при анализе данных для статистического моделирования.
Факторы создаются с помощью функции factor () , принимая вектор в качестве входных данных.
пример
# Create a vector as input. data <- c("East","West","East","North","North","East","West","West","West","East","North") print(data) print(is.factor(data)) # Apply the factor function. factor_data <- factor(data) print(factor_data) print(is.factor(factor_data))
Когда мы выполняем приведенный выше код, он дает следующий результат —
[1] "East" "West" "East" "North" "North" "East" "West" "West" "West" "East" "North" [1] FALSE [1] East West East North North East West West West East North Levels: East North West [1] TRUE
Факторы в фрейме данных
При создании любого фрейма данных со столбцом текстовых данных R рассматривает текстовый столбец как категориальные данные и создает факторы на них.
# Create the vectors for data frame. height <- c(132,151,162,139,166,147,122) weight <- c(48,49,66,53,67,52,40) gender <- c("male","male","female","female","male","female","male") # Create the data frame. input_data <- data.frame(height,weight,gender) print(input_data) # Test if the gender column is a factor. print(is.factor(input_data$gender)) # Print the gender column so see the levels. print(input_data$gender)
Когда мы выполняем приведенный выше код, он дает следующий результат —
height weight gender 1 132 48 male 2 151 49 male 3 162 66 female 4 139 53 female 5 166 67 male 6 147 52 female 7 122 40 male [1] TRUE [1] male male female female male female male Levels: female male
Изменение порядка уровней
Порядок уровней в факторе можно изменить, снова применив фактор-функцию с новым порядком уровней.
data <- c("East","West","East","North","North","East","West", "West","West","East","North") # Create the factors factor_data <- factor(data) print(factor_data) # Apply the factor function with required order of the level. new_order_data <- factor(factor_data,levels = c("East","West","North")) print(new_order_data)
Когда мы выполняем приведенный выше код, он дает следующий результат —
[1] East West East North North East West West West East North Levels: East North West [1] East West East North North East West West West East North Levels: East West North
Генерация уровней факторов
Мы можем генерировать факторные уровни с помощью функции gl () . В качестве входных данных используются два целых числа, которые указывают, сколько уровней и сколько раз на каждом уровне.
Синтаксис
gl(n, k, labels)
Ниже приведено описание используемых параметров:
-
n является целым числом, указывающим количество уровней.
-
k представляет собой целое число, дающее количество повторений.
-
метки — это вектор меток для результирующих уровней факторов.
n является целым числом, указывающим количество уровней.
k представляет собой целое число, дающее количество повторений.
метки — это вектор меток для результирующих уровней факторов.
пример
v <- gl(3, 4, labels = c("Tampa", "Seattle","Boston")) print(v)
Когда мы выполняем приведенный выше код, он дает следующий результат —
Tampa Tampa Tampa Tampa Seattle Seattle Seattle Seattle Boston [10] Boston Boston Boston Levels: Tampa Seattle Boston
R — Фреймы данных
Кадр данных представляет собой таблицу или двумерную массивоподобную структуру, в которой каждый столбец содержит значения одной переменной, а каждая строка содержит один набор значений из каждого столбца.
Ниже приведены характеристики фрейма данных.
- Имена столбцов должны быть непустыми.
- Имена строк должны быть уникальными.
- Данные, хранящиеся во фрейме данных, могут быть числовыми, факторными или символьными.
- Каждый столбец должен содержать одинаковое количество элементов данных.
Создать фрейм данных
# Create the data frame. emp.data <- data.frame( emp_id = c (1:5), emp_name = c("Rick","Dan","Michelle","Ryan","Gary"), salary = c(623.3,515.2,611.0,729.0,843.25), start_date = as.Date(c("2012-01-01", "2013-09-23", "2014-11-15", "2014-05-11", "2015-03-27")), stringsAsFactors = FALSE ) # Print the data frame. print(emp.data)
Когда мы выполняем приведенный выше код, он дает следующий результат —
emp_id emp_name salary start_date 1 1 Rick 623.30 2012-01-01 2 2 Dan 515.20 2013-09-23 3 3 Michelle 611.00 2014-11-15 4 4 Ryan 729.00 2014-05-11 5 5 Gary 843.25 2015-03-27
Получить структуру фрейма данных
Структуру фрейма данных можно увидеть с помощью функции str () .
# Create the data frame. emp.data <- data.frame( emp_id = c (1:5), emp_name = c("Rick","Dan","Michelle","Ryan","Gary"), salary = c(623.3,515.2,611.0,729.0,843.25), start_date = as.Date(c("2012-01-01", "2013-09-23", "2014-11-15", "2014-05-11", "2015-03-27")), stringsAsFactors = FALSE ) # Get the structure of the data frame. str(emp.data)
Когда мы выполняем приведенный выше код, он дает следующий результат —
'data.frame': 5 obs. of 4 variables: $ emp_id : int 1 2 3 4 5 $ emp_name : chr "Rick" "Dan" "Michelle" "Ryan" ... $ salary : num 623 515 611 729 843 $ start_date: Date, format: "2012-01-01" "2013-09-23" "2014-11-15" "2014-05-11" ...
Сводка данных в фрейме данных
Статистическая сводка и характер данных могут быть получены с помощью функции summary () .
# Create the data frame. emp.data <- data.frame( emp_id = c (1:5), emp_name = c("Rick","Dan","Michelle","Ryan","Gary"), salary = c(623.3,515.2,611.0,729.0,843.25), start_date = as.Date(c("2012-01-01", "2013-09-23", "2014-11-15", "2014-05-11", "2015-03-27")), stringsAsFactors = FALSE ) # Print the summary. print(summary(emp.data))
Когда мы выполняем приведенный выше код, он дает следующий результат —
emp_id emp_name salary start_date Min. :1 Length:5 Min. :515.2 Min. :2012-01-01 1st Qu.:2 Class :character 1st Qu.:611.0 1st Qu.:2013-09-23 Median :3 Mode :character Median :623.3 Median :2014-05-11 Mean :3 Mean :664.4 Mean :2014-01-14 3rd Qu.:4 3rd Qu.:729.0 3rd Qu.:2014-11-15 Max. :5 Max. :843.2 Max. :2015-03-27
Извлечение данных из фрейма данных
Извлечение определенного столбца из фрейма данных с использованием имени столбца.
# Create the data frame. emp.data <- data.frame( emp_id = c (1:5), emp_name = c("Rick","Dan","Michelle","Ryan","Gary"), salary = c(623.3,515.2,611.0,729.0,843.25), start_date = as.Date(c("2012-01-01","2013-09-23","2014-11-15","2014-05-11", "2015-03-27")), stringsAsFactors = FALSE ) # Extract Specific columns. result <- data.frame(emp.data$emp_name,emp.data$salary) print(result)
Когда мы выполняем приведенный выше код, он дает следующий результат —
emp.data.emp_name emp.data.salary 1 Rick 623.30 2 Dan 515.20 3 Michelle 611.00 4 Ryan 729.00 5 Gary 843.25
Извлеките первые две строки, а затем все столбцы
# Create the data frame. emp.data <- data.frame( emp_id = c (1:5), emp_name = c("Rick","Dan","Michelle","Ryan","Gary"), salary = c(623.3,515.2,611.0,729.0,843.25), start_date = as.Date(c("2012-01-01", "2013-09-23", "2014-11-15", "2014-05-11", "2015-03-27")), stringsAsFactors = FALSE ) # Extract first two rows. result <- emp.data[1:2,] print(result)
Когда мы выполняем приведенный выше код, он дает следующий результат —
emp_id emp_name salary start_date 1 1 Rick 623.3 2012-01-01 2 2 Dan 515.2 2013-09-23
Извлечь 3- й и 5- й ряд со 2- м и 4- м столбцом
# Create the data frame. emp.data <- data.frame( emp_id = c (1:5), emp_name = c("Rick","Dan","Michelle","Ryan","Gary"), salary = c(623.3,515.2,611.0,729.0,843.25), start_date = as.Date(c("2012-01-01", "2013-09-23", "2014-11-15", "2014-05-11", "2015-03-27")), stringsAsFactors = FALSE ) # Extract 3rd and 5th row with 2nd and 4th column. result <- emp.data[c(3,5),c(2,4)] print(result)
Когда мы выполняем приведенный выше код, он дает следующий результат —
emp_name start_date 3 Michelle 2014-11-15 5 Gary 2015-03-27
Развернуть фрейм данных
Фрейм данных можно расширить, добавив столбцы и строки.
Добавить столбец
Просто добавьте вектор столбца, используя новое имя столбца.
# Create the data frame. emp.data <- data.frame( emp_id = c (1:5), emp_name = c("Rick","Dan","Michelle","Ryan","Gary"), salary = c(623.3,515.2,611.0,729.0,843.25), start_date = as.Date(c("2012-01-01", "2013-09-23", "2014-11-15", "2014-05-11", "2015-03-27")), stringsAsFactors = FALSE ) # Add the "dept" coulmn. emp.data$dept <- c("IT","Operations","IT","HR","Finance") v <- emp.data print(v)
Когда мы выполняем приведенный выше код, он дает следующий результат —
emp_id emp_name salary start_date dept 1 1 Rick 623.30 2012-01-01 IT 2 2 Dan 515.20 2013-09-23 Operations 3 3 Michelle 611.00 2014-11-15 IT 4 4 Ryan 729.00 2014-05-11 HR 5 5 Gary 843.25 2015-03-27 Finance
Добавить ряд
Чтобы постоянно добавлять больше строк в существующий фрейм данных, нам нужно ввести новые строки в той же структуре, что и существующий фрейм данных, и использовать функцию rbind () .
В приведенном ниже примере мы создаем фрейм данных с новыми строками и объединяем его с существующим фреймом данных, чтобы создать окончательный фрейм данных.
# Create the first data frame. emp.data <- data.frame( emp_id = c (1:5), emp_name = c("Rick","Dan","Michelle","Ryan","Gary"), salary = c(623.3,515.2,611.0,729.0,843.25), start_date = as.Date(c("2012-01-01", "2013-09-23", "2014-11-15", "2014-05-11", "2015-03-27")), dept = c("IT","Operations","IT","HR","Finance"), stringsAsFactors = FALSE ) # Create the second data frame emp.newdata <- data.frame( emp_id = c (6:8), emp_name = c("Rasmi","Pranab","Tusar"), salary = c(578.0,722.5,632.8), start_date = as.Date(c("2013-05-21","2013-07-30","2014-06-17")), dept = c("IT","Operations","Fianance"), stringsAsFactors = FALSE ) # Bind the two data frames. emp.finaldata <- rbind(emp.data,emp.newdata) print(emp.finaldata)
Когда мы выполняем приведенный выше код, он дает следующий результат —
emp_id emp_name salary start_date dept 1 1 Rick 623.30 2012-01-01 IT 2 2 Dan 515.20 2013-09-23 Operations 3 3 Michelle 611.00 2014-11-15 IT 4 4 Ryan 729.00 2014-05-11 HR 5 5 Gary 843.25 2015-03-27 Finance 6 6 Rasmi 578.00 2013-05-21 IT 7 7 Pranab 722.50 2013-07-30 Operations 8 8 Tusar 632.80 2014-06-17 Fianance
R — Пакеты
Пакеты R представляют собой набор функций R, соблюдаемый код и примеры данных. Они хранятся в каталоге под названием «библиотека» в среде R. По умолчанию R устанавливает набор пакетов во время установки. Дополнительные пакеты добавляются позже, когда они необходимы для какой-то конкретной цели. Когда мы запускаем консоль R, по умолчанию доступны только пакеты по умолчанию. Другие пакеты, которые уже установлены, должны быть явно загружены для использования программой R, которая будет их использовать.
Все пакеты, доступные на языке R, перечислены в R Packages.
Ниже приведен список команд, которые будут использоваться для проверки, проверки и использования пакетов R.
Проверьте доступные пакеты R
Получить местоположения библиотеки, содержащие пакеты R
.libPaths()
Когда мы выполняем приведенный выше код, он дает следующий результат. Это может варьироваться в зависимости от локальных настроек вашего компьютера.
[2] "C:/Program Files/R/R-3.2.2/library"
Получить список всех установленных пакетов
library()
Когда мы выполняем приведенный выше код, он дает следующий результат. Это может варьироваться в зависимости от локальных настроек вашего компьютера.
Packages in library ‘C:/Program Files/R/R-3.2.2/library’:
base The R Base Package
boot Bootstrap Functions (Originally by Angelo Canty
for S)
class Functions for Classification
cluster "Finding Groups in Data": Cluster Analysis
Extended Rousseeuw et al.
codetools Code Analysis Tools for R
compiler The R Compiler Package
datasets The R Datasets Package
foreign Read Data Stored by 'Minitab', 'S', 'SAS',
'SPSS', 'Stata', 'Systat', 'Weka', 'dBase', ...
graphics The R Graphics Package
grDevices The R Graphics Devices and Support for Colours
and Fonts
grid The Grid Graphics Package
KernSmooth Functions for Kernel Smoothing Supporting Wand
& Jones (1995)
lattice Trellis Graphics for R
MASS Support Functions and Datasets for Venables and
Ripley's MASS
Matrix Sparse and Dense Matrix Classes and Methods
methods Formal Methods and Classes
mgcv Mixed GAM Computation Vehicle with GCV/AIC/REML
Smoothness Estimation
nlme Linear and Nonlinear Mixed Effects Models
nnet Feed-Forward Neural Networks and Multinomial
Log-Linear Models
parallel Support for Parallel computation in R
rpart Recursive Partitioning and Regression Trees
spatial Functions for Kriging and Point Pattern
Analysis
splines Regression Spline Functions and Classes
stats The R Stats Package
stats4 Statistical Functions using S4 Classes
survival Survival Analysis
tcltk Tcl/Tk Interface
tools Tools for Package Development
utils The R Utils Package
Получить все пакеты, загруженные в настоящее время в среде R
search()
Когда мы выполняем приведенный выше код, он дает следующий результат. Это может варьироваться в зависимости от локальных настроек вашего компьютера.
[1] ".GlobalEnv" "package:stats" "package:graphics" [4] "package:grDevices" "package:utils" "package:datasets" [7] "package:methods" "Autoloads" "package:base"
Установить новый пакет
Есть два способа добавить новые пакеты R. Один устанавливает непосредственно из каталога CRAN, а другой загружает пакет в вашу локальную систему и устанавливает его вручную.
Установить прямо из CRAN
Следующая команда получает пакеты непосредственно с веб-страницы CRAN и устанавливает пакет в среде R. Вам может быть предложено выбрать ближайшее зеркало. Выберите тот, который соответствует вашему местоположению.
install.packages("Package Name")
# Install the package named "XML".
install.packages("XML")
Установить пакет вручную
Перейдите по ссылке R Packages, чтобы загрузить необходимый пакет. Сохраните пакет в виде файла .zip в подходящем месте в локальной системе.
Теперь вы можете запустить следующую команду, чтобы установить этот пакет в среде R.
install.packages(file_name_with_path, repos = NULL, type = "source") # Install the package named "XML" install.packages("E:/XML_3.98-1.3.zip", repos = NULL, type = "source")
Загрузить пакет в библиотеку
Прежде чем пакет можно будет использовать в коде, он должен быть загружен в текущую среду R. Вам также необходимо загрузить пакет, который уже установлен ранее, но недоступен в текущей среде.
Пакет загружается с помощью следующей команды —
library("package Name", lib.loc = "path to library")
# Load the package named "XML"
install.packages("E:/XML_3.98-1.3.zip", repos = NULL, type = "source")
R — изменение формы данных
Изменение формы данных в R — это изменение способа организации данных в строки и столбцы. Большая часть времени обработки данных в R выполняется путем принятия входных данных в качестве кадра данных. Легко извлечь данные из строк и столбцов фрейма данных, но бывают ситуации, когда нам нужен фрейм данных в формате, отличном от формата, в котором мы его получили. В R имеется много функций для разделения, объединения и изменения строк в столбцы и наоборот во фрейме данных.
Соединение столбцов и строк в фрейме данных
Мы можем объединить несколько векторов для создания фрейма данных с помощью функции cbind () . Также мы можем объединить два фрейма данных с помощью функции rbind () .
# Create vector objects. city <- c("Tampa","Seattle","Hartford","Denver") state <- c("FL","WA","CT","CO") zipcode <- c(33602,98104,06161,80294) # Combine above three vectors into one data frame. addresses <- cbind(city,state,zipcode) # Print a header. cat("# # # # The First data frame\n") # Print the data frame. print(addresses) # Create another data frame with similar columns new.address <- data.frame( city = c("Lowry","Charlotte"), state = c("CO","FL"), zipcode = c("80230","33949"), stringsAsFactors = FALSE ) # Print a header. cat("# # # The Second data frame\n") # Print the data frame. print(new.address) # Combine rows form both the data frames. all.addresses <- rbind(addresses,new.address) # Print a header. cat("# # # The combined data frame\n") # Print the result. print(all.addresses)
Когда мы выполняем приведенный выше код, он дает следующий результат —
# # # # The First data frame
city state zipcode
[1,] "Tampa" "FL" "33602"
[2,] "Seattle" "WA" "98104"
[3,] "Hartford" "CT" "6161"
[4,] "Denver" "CO" "80294"
# # # The Second data frame
city state zipcode
1 Lowry CO 80230
2 Charlotte FL 33949
# # # The combined data frame
city state zipcode
1 Tampa FL 33602
2 Seattle WA 98104
3 Hartford CT 6161
4 Denver CO 80294
5 Lowry CO 80230
6 Charlotte FL 33949
Объединение фреймов данных
Мы можем объединить два фрейма данных с помощью функции merge () . Кадры данных должны иметь одинаковые имена столбцов, в которых происходит слияние.
В приведенном ниже примере мы рассматриваем наборы данных о диабете у индийских женщин Пима, доступные в библиотеках с именами «MASS». мы объединяем два набора данных на основе значений артериального давления («bp») и индекса массы тела («bmi»). При выборе этих двух столбцов для слияния записи, в которых значения этих двух переменных совпадают в обоих наборах данных, объединяются в один фрейм данных.
library(MASS) merged.Pima <- merge(x = Pima.te, y = Pima.tr, by.x = c("bp", "bmi"), by.y = c("bp", "bmi") ) print(merged.Pima) nrow(merged.Pima)
Когда мы выполняем приведенный выше код, он дает следующий результат —
bp bmi npreg.x glu.x skin.x ped.x age.x type.x npreg.y glu.y skin.y ped.y 1 60 33.8 1 117 23 0.466 27 No 2 125 20 0.088 2 64 29.7 2 75 24 0.370 33 No 2 100 23 0.368 3 64 31.2 5 189 33 0.583 29 Yes 3 158 13 0.295 4 64 33.2 4 117 27 0.230 24 No 1 96 27 0.289 5 66 38.1 3 115 39 0.150 28 No 1 114 36 0.289 6 68 38.5 2 100 25 0.324 26 No 7 129 49 0.439 7 70 27.4 1 116 28 0.204 21 No 0 124 20 0.254 8 70 33.1 4 91 32 0.446 22 No 9 123 44 0.374 9 70 35.4 9 124 33 0.282 34 No 6 134 23 0.542 10 72 25.6 1 157 21 0.123 24 No 4 99 17 0.294 11 72 37.7 5 95 33 0.370 27 No 6 103 32 0.324 12 74 25.9 9 134 33 0.460 81 No 8 126 38 0.162 13 74 25.9 1 95 21 0.673 36 No 8 126 38 0.162 14 78 27.6 5 88 30 0.258 37 No 6 125 31 0.565 15 78 27.6 10 122 31 0.512 45 No 6 125 31 0.565 16 78 39.4 2 112 50 0.175 24 No 4 112 40 0.236 17 88 34.5 1 117 24 0.403 40 Yes 4 127 11 0.598 age.y type.y 1 31 No 2 21 No 3 24 No 4 21 No 5 21 No 6 43 Yes 7 36 Yes 8 40 No 9 29 Yes 10 28 No 11 55 No 12 39 No 13 39 No 14 49 Yes 15 49 Yes 16 38 No 17 28 No [1] 17
Плавки и литья
Один из наиболее интересных аспектов R-программирования — это изменение формы данных в несколько этапов для получения желаемой формы. Используемые для этого функции называются melt () и cast () .
Мы рассматриваем набор данных под названием корабли, присутствующий в библиотеке под названием «МАССА».
library(MASS) print(ships)
Когда мы выполняем приведенный выше код, он дает следующий результат —
type year period service incidents 1 A 60 60 127 0 2 A 60 75 63 0 3 A 65 60 1095 3 4 A 65 75 1095 4 5 A 70 60 1512 6 ............. ............. 8 A 75 75 2244 11 9 B 60 60 44882 39 10 B 60 75 17176 29 11 B 65 60 28609 58 ............ ............ 17 C 60 60 1179 1 18 C 60 75 552 1 19 C 65 60 781 0 ............ ............
Расплавить данные
Теперь мы объединяем данные, чтобы организовать их, преобразовывая все столбцы, кроме типа и года, в несколько строк.
molten.ships <- melt(ships, id = c("type","year")) print(molten.ships)
Когда мы выполняем приведенный выше код, он дает следующий результат —
type year variable value 1 A 60 period 60 2 A 60 period 75 3 A 65 period 60 4 A 65 period 75 ............ ............ 9 B 60 period 60 10 B 60 period 75 11 B 65 period 60 12 B 65 period 75 13 B 70 period 60 ........... ........... 41 A 60 service 127 42 A 60 service 63 43 A 65 service 1095 ........... ........... 70 D 70 service 1208 71 D 75 service 0 72 D 75 service 2051 73 E 60 service 45 74 E 60 service 0 75 E 65 service 789 ........... ........... 101 C 70 incidents 6 102 C 70 incidents 2 103 C 75 incidents 0 104 C 75 incidents 1 105 D 60 incidents 0 106 D 60 incidents 0 ........... ...........
В ролях расплавленных данных
Мы можем преобразовать расплавленные данные в новую форму, в которой создается совокупность кораблей каждого типа за каждый год. Это делается с помощью функции cast () .
recasted.ship <- cast(molten.ships, type+year~variable,sum) print(recasted.ship)
Когда мы выполняем приведенный выше код, он дает следующий результат —
type year period service incidents 1 A 60 135 190 0 2 A 65 135 2190 7 3 A 70 135 4865 24 4 A 75 135 2244 11 5 B 60 135 62058 68 6 B 65 135 48979 111 7 B 70 135 20163 56 8 B 75 135 7117 18 9 C 60 135 1731 2 10 C 65 135 1457 1 11 C 70 135 2731 8 12 C 75 135 274 1 13 D 60 135 356 0 14 D 65 135 480 0 15 D 70 135 1557 13 16 D 75 135 2051 4 17 E 60 135 45 0 18 E 65 135 1226 14 19 E 70 135 3318 17 20 E 75 135 542 1
R — CSV файлы
В R мы можем читать данные из файлов, хранящихся вне среды R. Мы также можем записывать данные в файлы, которые будут храниться и доступны операционной системе. R может читать и записывать в различные форматы файлов, такие как CSV, Excel, XML и т. Д.
В этой главе мы научимся читать данные из файла CSV, а затем записывать данные в файл CSV. Файл должен присутствовать в текущем рабочем каталоге, чтобы R мог его прочитать. Конечно, мы также можем установить наш собственный каталог и читать файлы оттуда.
Получение и настройка рабочего каталога
Вы можете проверить, на какой каталог указывает рабочее пространство R, используя функцию getwd () . Вы также можете установить новый рабочий каталог, используя функцию setwd () .
# Get and print current working directory. print(getwd()) # Set current working directory. setwd("/web/com") # Get and print current working directory. print(getwd())
Когда мы выполняем приведенный выше код, он дает следующий результат —
[1] "/web/com/1441086124_2016" [1] "/web/com"
Этот результат зависит от вашей ОС и вашего текущего каталога, в котором вы работаете.
Ввод как файл CSV
Файл CSV представляет собой текстовый файл, в котором значения в столбцах разделены запятой. Давайте рассмотрим следующие данные, присутствующие в файле с именем input.csv .
Вы можете создать этот файл с помощью блокнота Windows, скопировав и вставив эти данные. Сохраните файл как input.csv, используя параметр «Сохранить как все файлы (*. *)» В блокноте.
id,name,salary,start_date,dept 1,Rick,623.3,2012-01-01,IT 2,Dan,515.2,2013-09-23,Operations 3,Michelle,611,2014-11-15,IT 4,Ryan,729,2014-05-11,HR 5,Gary,843.25,2015-03-27,Finance 6,Nina,578,2013-05-21,IT 7,Simon,632.8,2013-07-30,Operations 8,Guru,722.5,2014-06-17,Finance
Чтение файла CSV
Ниже приведен простой пример функции read.csv () для чтения файла CSV, доступного в вашем текущем рабочем каталоге:
data <- read.csv("input.csv") print(data)
Когда мы выполняем приведенный выше код, он дает следующий результат —
id, name, salary, start_date, dept 1 1 Rick 623.30 2012-01-01 IT 2 2 Dan 515.20 2013-09-23 Operations 3 3 Michelle 611.00 2014-11-15 IT 4 4 Ryan 729.00 2014-05-11 HR 5 NA Gary 843.25 2015-03-27 Finance 6 6 Nina 578.00 2013-05-21 IT 7 7 Simon 632.80 2013-07-30 Operations 8 8 Guru 722.50 2014-06-17 Finance
Анализ файла CSV
По умолчанию функция read.csv () выдает выходные данные в виде фрейма данных. Это можно легко проверить следующим образом. Также мы можем проверить количество столбцов и строк.
data <- read.csv("input.csv") print(is.data.frame(data)) print(ncol(data)) print(nrow(data))
Когда мы выполняем приведенный выше код, он дает следующий результат —
[1] TRUE [1] 5 [1] 8
Как только мы прочитаем данные во фрейме данных, мы сможем применить все функции, применимые к фреймам данных, как объяснено в следующем разделе.
Получи максимальную зарплату
# Create a data frame. data <- read.csv("input.csv") # Get the max salary from data frame. sal <- max(data$salary) print(sal)
Когда мы выполняем приведенный выше код, он дает следующий результат —
[1] 843.25
Получить информацию о человеке с максимальной зарплатой
Мы можем получить строки, соответствующие определенным критериям фильтра, аналогичным предложению SQL where.
# Create a data frame. data <- read.csv("input.csv") # Get the max salary from data frame. sal <- max(data$salary) # Get the person detail having max salary. retval <- subset(data, salary == max(salary)) print(retval)
Когда мы выполняем приведенный выше код, он дает следующий результат —
id name salary start_date dept 5 NA Gary 843.25 2015-03-27 Finance
Получить всех людей, работающих в отделе ИТ
# Create a data frame. data <- read.csv("input.csv") retval <- subset( data, dept == "IT") print(retval)
Когда мы выполняем приведенный выше код, он дает следующий результат —
id name salary start_date dept 1 1 Rick 623.3 2012-01-01 IT 3 3 Michelle 611.0 2014-11-15 IT 6 6 Nina 578.0 2013-05-21 IT
Получить людей в отдел ИТ, чья зарплата превышает 600
# Create a data frame. data <- read.csv("input.csv") info <- subset(data, salary > 600 & dept == "IT") print(info)
Когда мы выполняем приведенный выше код, он дает следующий результат —
id name salary start_date dept 1 1 Rick 623.3 2012-01-01 IT 3 3 Michelle 611.0 2014-11-15 IT
Получите людей, которые присоединились к или после 2014
# Create a data frame. data <- read.csv("input.csv") retval <- subset(data, as.Date(start_date) > as.Date("2014-01-01")) print(retval)
Когда мы выполняем приведенный выше код, он дает следующий результат —
id name salary start_date dept 3 3 Michelle 611.00 2014-11-15 IT 4 4 Ryan 729.00 2014-05-11 HR 5 NA Gary 843.25 2015-03-27 Finance 8 8 Guru 722.50 2014-06-17 Finance
Запись в файл CSV
R может создать CSV-файл из существующего фрейма данных. Функция write.csv () используется для создания файла csv. Этот файл создается в рабочем каталоге.
# Create a data frame. data <- read.csv("input.csv") retval <- subset(data, as.Date(start_date) > as.Date("2014-01-01")) # Write filtered data into a new file. write.csv(retval,"output.csv") newdata <- read.csv("output.csv") print(newdata)
Когда мы выполняем приведенный выше код, он дает следующий результат —
X id name salary start_date dept 1 3 3 Michelle 611.00 2014-11-15 IT 2 4 4 Ryan 729.00 2014-05-11 HR 3 5 NA Gary 843.25 2015-03-27 Finance 4 8 8 Guru 722.50 2014-06-17 Finance
Здесь столбец X взят из набора данных newper. Это можно удалить, используя дополнительные параметры при записи файла.
# Create a data frame. data <- read.csv("input.csv") retval <- subset(data, as.Date(start_date) > as.Date("2014-01-01")) # Write filtered data into a new file. write.csv(retval,"output.csv", row.names = FALSE) newdata <- read.csv("output.csv") print(newdata)
Когда мы выполняем приведенный выше код, он дает следующий результат —
id name salary start_date dept 1 3 Michelle 611.00 2014-11-15 IT 2 4 Ryan 729.00 2014-05-11 HR 3 NA Gary 843.25 2015-03-27 Finance 4 8 Guru 722.50 2014-06-17 Finance
R — файл Excel
Microsoft Excel является наиболее широко используемой программой для работы с электронными таблицами, которая хранит данные в формате .xls или .xlsx. R может читать напрямую из этих файлов, используя некоторые специальные пакеты Excel. Мало таких пакетов — XLConnect, xlsx, gdata и т. Д. Мы будем использовать пакет xlsx. R также может записать в файл Excel, используя этот пакет.
Установить пакет xlsx
Вы можете использовать следующую команду в консоли R для установки пакета «xlsx». Может потребоваться установить некоторые дополнительные пакеты, от которых зависит этот пакет. Для установки дополнительных пакетов выполните ту же команду с требуемым именем пакета.
install.packages("xlsx")
Проверьте и загрузите пакет «xlsx»
Используйте следующую команду для проверки и загрузки пакета «xlsx».
# Verify the package is installed. any(grepl("xlsx",installed.packages())) # Load the library into R workspace. library("xlsx")
Когда скрипт запускается, мы получаем следующий вывод.
[1] TRUE Loading required package: rJava Loading required package: methods Loading required package: xlsxjars
Ввод как файл xlsx
Откройте Microsoft Excel. Скопируйте и вставьте следующие данные в рабочий лист с именем sheet1.
id name salary start_date dept 1 Rick 623.3 1/1/2012 IT 2 Dan 515.2 9/23/2013 Operations 3 Michelle 611 11/15/2014 IT 4 Ryan 729 5/11/2014 HR 5 Gary 43.25 3/27/2015 Finance 6 Nina 578 5/21/2013 IT 7 Simon 632.8 7/30/2013 Operations 8 Guru 722.5 6/17/2014 Finance
Также скопируйте и вставьте следующие данные в другой лист и переименуйте этот лист в «город».
name city Rick Seattle Dan Tampa Michelle Chicago Ryan Seattle Gary Houston Nina Boston Simon Mumbai Guru Dallas
Сохраните файл Excel как «input.xlsx». Вы должны сохранить его в текущем рабочем каталоге рабочей области R.
Чтение файла Excel
Input.xlsx читается с использованием функции read.xlsx (), как показано ниже. Результат сохраняется в виде фрейма данных в среде R.
# Read the first worksheet in the file input.xlsx. data <- read.xlsx("input.xlsx", sheetIndex = 1) print(data)
Когда мы выполняем приведенный выше код, он дает следующий результат —
id, name, salary, start_date, dept 1 1 Rick 623.30 2012-01-01 IT 2 2 Dan 515.20 2013-09-23 Operations 3 3 Michelle 611.00 2014-11-15 IT 4 4 Ryan 729.00 2014-05-11 HR 5 NA Gary 843.25 2015-03-27 Finance 6 6 Nina 578.00 2013-05-21 IT 7 7 Simon 632.80 2013-07-30 Operations 8 8 Guru 722.50 2014-06-17 Finance
R — двоичные файлы
Бинарный файл — это файл, который содержит информацию, хранящуюся только в виде битов и байтов (0 и 1). Они не читаются человеком, поскольку байты в нем переводятся в символы и символы, которые содержат много других непечатных символов. Попытка чтения двоичного файла с помощью любого текстового редактора покажет символы, такие как Ø и ð.
Двоичный файл должен быть прочитан определенными программами, чтобы его можно было использовать. Например, двоичный файл программы Microsoft Word может быть прочитан в удобочитаемой форме только программой Word. Это указывает на то, что, помимо читаемого человеком текста, имеется намного больше информации, такой как форматирование символов и номеров страниц и т. Д., Которые также хранятся вместе с буквенно-цифровыми символами. И, наконец, двоичный файл представляет собой непрерывную последовательность байтов. Разрыв строки, который мы видим в текстовом файле, — это символ, соединяющий первую строку со следующей.
Иногда данные, генерируемые другими программами, должны обрабатываться R как двоичный файл. Также R необходим для создания бинарных файлов, которые могут использоваться другими программами.
R имеет две функции WriteBin () и readBin () для создания и чтения двоичных файлов.
Синтаксис
writeBin(object, con) readBin(con, what, n )
Ниже приведено описание используемых параметров:
-
con — это объект подключения для чтения или записи двоичного файла.
-
Объект — это двоичный файл, который нужно записать.
-
что такое режим, как символ, целое число и т. д., представляющие байты для чтения.
-
n — это количество байтов для чтения из двоичного файла.
con — это объект подключения для чтения или записи двоичного файла.
Объект — это двоичный файл, который нужно записать.
что такое режим, как символ, целое число и т. д., представляющие байты для чтения.
n — это количество байтов для чтения из двоичного файла.
пример
Мы считаем встроенные данные R «mtcars». Сначала мы создаем из него CSV-файл, преобразуем его в двоичный файл и сохраняем как файл ОС. Далее мы читаем этот двоичный файл, созданный в R.
Запись двоичного файла
Мы читаем фрейм данных «mtcars» как файл csv, а затем записываем его как двоичный файл в ОС.
# Read the "mtcars" data frame as a csv file and store only the columns "cyl", "am" and "gear". write.table(mtcars, file = "mtcars.csv",row.names = FALSE, na = "", col.names = TRUE, sep = ",") # Store 5 records from the csv file as a new data frame. new.mtcars <- read.table("mtcars.csv",sep = ",",header = TRUE,nrows = 5) # Create a connection object to write the binary file using mode "wb". write.filename = file("/web/com/binmtcars.dat", "wb") # Write the column names of the data frame to the connection object. writeBin(colnames(new.mtcars), write.filename) # Write the records in each of the column to the file. writeBin(c(new.mtcars$cyl,new.mtcars$am,new.mtcars$gear), write.filename) # Close the file for writing so that it can be read by other program. close(write.filename)
Чтение двоичного файла
Созданный выше двоичный файл хранит все данные в виде непрерывных байтов. Поэтому мы будем читать его, выбирая соответствующие значения имен столбцов, а также значений столбцов.
# Create a connection object to read the file in binary mode using "rb". read.filename <- file("/web/com/binmtcars.dat", "rb") # First read the column names. n = 3 as we have 3 columns. column.names <- readBin(read.filename, character(), n = 3) # Next read the column values. n = 18 as we have 3 column names and 15 values. read.filename <- file("/web/com/binmtcars.dat", "rb") bindata <- readBin(read.filename, integer(), n = 18) # Print the data. print(bindata) # Read the values from 4th byte to 8th byte which represents "cyl". cyldata = bindata[4:8] print(cyldata) # Read the values form 9th byte to 13th byte which represents "am". amdata = bindata[9:13] print(amdata) # Read the values form 9th byte to 13th byte which represents "gear". geardata = bindata[14:18] print(geardata) # Combine all the read values to a dat frame. finaldata = cbind(cyldata, amdata, geardata) colnames(finaldata) = column.names print(finaldata)
Когда мы выполняем приведенный выше код, он дает следующий результат и диаграмму —
[1] 7108963 1728081249 7496037 6 6 4
[7] 6 8 1 1 1 0
[13] 0 4 4 4 3 3
[1] 6 6 4 6 8
[1] 1 1 1 0 0
[1] 4 4 4 3 3
cyl am gear
[1,] 6 1 4
[2,] 6 1 4
[3,] 4 1 4
[4,] 6 0 3
[5,] 8 0 3
Как мы видим, мы получили исходные данные, прочитав двоичный файл в R.
R — XML файлы
XML — это формат файла, который совместно использует формат файла и данные во Всемирной паутине, интрасетях и других местах с использованием стандартного текста ASCII. Он расшифровывается как расширяемый язык разметки (XML). Как и в HTML, он содержит теги разметки. Но в отличие от HTML, где тег разметки описывает структуру страницы, в XML теги разметки описывают значение данных, содержащихся в файле.
Вы можете прочитать XML-файл в R, используя пакет «XML». Этот пакет можно установить с помощью следующей команды.
install.packages("XML")
Входные данные
Создайте файл XMl, скопировав приведенные ниже данные в текстовый редактор, например блокнот. Сохраните файл с расширением .xml и выберите тип файла в качестве всех файлов (*. *) .
<RECORDS> <EMPLOYEE> <ID>1</ID> <NAME>Rick</NAME> <SALARY>623.3</SALARY> <STARTDATE>1/1/2012</STARTDATE> <DEPT>IT</DEPT> </EMPLOYEE> <EMPLOYEE> <ID>2</ID> <NAME>Dan</NAME> <SALARY>515.2</SALARY> <STARTDATE>9/23/2013</STARTDATE> <DEPT>Operations</DEPT> </EMPLOYEE> <EMPLOYEE> <ID>3</ID> <NAME>Michelle</NAME> <SALARY>611</SALARY> <STARTDATE>11/15/2014</STARTDATE> <DEPT>IT</DEPT> </EMPLOYEE> <EMPLOYEE> <ID>4</ID> <NAME>Ryan</NAME> <SALARY>729</SALARY> <STARTDATE>5/11/2014</STARTDATE> <DEPT>HR</DEPT> </EMPLOYEE> <EMPLOYEE> <ID>5</ID> <NAME>Gary</NAME> <SALARY>843.25</SALARY> <STARTDATE>3/27/2015</STARTDATE> <DEPT>Finance</DEPT> </EMPLOYEE> <EMPLOYEE> <ID>6</ID> <NAME>Nina</NAME> <SALARY>578</SALARY> <STARTDATE>5/21/2013</STARTDATE> <DEPT>IT</DEPT> </EMPLOYEE> <EMPLOYEE> <ID>7</ID> <NAME>Simon</NAME> <SALARY>632.8</SALARY> <STARTDATE>7/30/2013</STARTDATE> <DEPT>Operations</DEPT> </EMPLOYEE> <EMPLOYEE> <ID>8</ID> <NAME>Guru</NAME> <SALARY>722.5</SALARY> <STARTDATE>6/17/2014</STARTDATE> <DEPT>Finance</DEPT> </EMPLOYEE> </RECORDS>
Чтение XML-файла
XML-файл читается R с помощью функции xmlParse () . Хранится в виде списка в R.
# Load the package required to read XML files.
library("XML")
# Also load the other required package.
library("methods")
# Give the input file name to the function.
result <- xmlParse(file = "input.xml")
# Print the result.
print(result)
Когда мы выполняем приведенный выше код, он дает следующий результат —
1 Rick 623.3 1/1/2012 IT 2 Dan 515.2 9/23/2013 Operations 3 Michelle 611 11/15/2014 IT 4 Ryan 729 5/11/2014 HR 5 Gary 843.25 3/27/2015 Finance 6 Nina 578 5/21/2013 IT 7 Simon 632.8 7/30/2013 Operations 8 Guru 722.5 6/17/2014 Finance
Получить количество узлов, присутствующих в файле XML
# Load the packages required to read XML files.
library("XML")
library("methods")
# Give the input file name to the function.
result <- xmlParse(file = "input.xml")
# Exract the root node form the xml file.
rootnode <- xmlRoot(result)
# Find number of nodes in the root.
rootsize <- xmlSize(rootnode)
# Print the result.
print(rootsize)
Когда мы выполняем приведенный выше код, он дает следующий результат —
output [1] 8
Детали первого узла
Давайте посмотрим на первую запись проанализированного файла. Это даст нам представление о различных элементах, присутствующих в узле верхнего уровня.
# Load the packages required to read XML files.
library("XML")
library("methods")
# Give the input file name to the function.
result <- xmlParse(file = "input.xml")
# Exract the root node form the xml file.
rootnode <- xmlRoot(result)
# Print the result.
print(rootnode[1])
Когда мы выполняем приведенный выше код, он дает следующий результат —
$EMPLOYEE 1 Rick 623.3 1/1/2012 IT attr(,"class") [1] "XMLInternalNodeList" "XMLNodeList"
Получить различные элементы узла
# Load the packages required to read XML files.
library("XML")
library("methods")
# Give the input file name to the function.
result <- xmlParse(file = "input.xml")
# Exract the root node form the xml file.
rootnode <- xmlRoot(result)
# Get the first element of the first node.
print(rootnode[[1]][[1]])
# Get the fifth element of the first node.
print(rootnode[[1]][[5]])
# Get the second element of the third node.
print(rootnode[[3]][[2]])
Когда мы выполняем приведенный выше код, он дает следующий результат —
1 IT Michelle
Фрейм XML в данные
Чтобы эффективно обрабатывать данные в больших файлах, мы читаем данные в файле XML как кадр данных. Затем обработайте фрейм данных для анализа данных.
# Load the packages required to read XML files.
library("XML")
library("methods")
# Convert the input xml file to a data frame.
xmldataframe <- xmlToDataFrame("input.xml")
print(xmldataframe)
Когда мы выполняем приведенный выше код, он дает следующий результат —
ID NAME SALARY STARTDATE DEPT 1 1 Rick 623.30 2012-01-01 IT 2 2 Dan 515.20 2013-09-23 Operations 3 3 Michelle 611.00 2014-11-15 IT 4 4 Ryan 729.00 2014-05-11 HR 5 NA Gary 843.25 2015-03-27 Finance 6 6 Nina 578.00 2013-05-21 IT 7 7 Simon 632.80 2013-07-30 Operations 8 8 Guru 722.50 2014-06-17 Finance
Поскольку данные теперь доступны в виде фрейма данных, мы можем использовать функцию, связанную с фреймом данных, для чтения и манипулирования файлом.
R — JSON Files
Файл JSON хранит данные в виде текста в удобочитаемом формате. Json расшифровывается как JavaScript Object Notation. R может читать файлы JSON с помощью пакета rjson.
Установить пакет rjson
В консоли R вы можете выполнить следующую команду для установки пакета rjson.
install.packages("rjson")
Входные данные
Создайте файл JSON, скопировав приведенные ниже данные в текстовый редактор, например блокнот. Сохраните файл с расширением .json и выберите тип файла в качестве всех файлов (*. *) .
{
"ID":["1","2","3","4","5","6","7","8" ],
"Name":["Rick","Dan","Michelle","Ryan","Gary","Nina","Simon","Guru" ],
"Salary":["623.3","515.2","611","729","843.25","578","632.8","722.5" ],
"StartDate":[ "1/1/2012","9/23/2013","11/15/2014","5/11/2014","3/27/2015","5/21/2013",
"7/30/2013","6/17/2014"],
"Dept":[ "IT","Operations","IT","HR","Finance","IT","Operations","Finance"]
}
Прочитайте файл JSON
Файл JSON читается R с помощью функции из JSON () . Хранится в виде списка в R.
# Load the package required to read JSON files.
library("rjson")
# Give the input file name to the function.
result <- fromJSON(file = "input.json")
# Print the result.
print(result)
Когда мы выполняем приведенный выше код, он дает следующий результат —
$ID [1] "1" "2" "3" "4" "5" "6" "7" "8" $Name [1] "Rick" "Dan" "Michelle" "Ryan" "Gary" "Nina" "Simon" "Guru" $Salary [1] "623.3" "515.2" "611" "729" "843.25" "578" "632.8" "722.5" $StartDate [1] "1/1/2012" "9/23/2013" "11/15/2014" "5/11/2014" "3/27/2015" "5/21/2013" "7/30/2013" "6/17/2014" $Dept [1] "IT" "Operations" "IT" "HR" "Finance" "IT" "Operations" "Finance"
Конвертировать JSON в фрейм данных
Мы можем преобразовать извлеченные данные выше во фрейм данных R для дальнейшего анализа, используя функцию as.data.frame () .
# Load the package required to read JSON files.
library("rjson")
# Give the input file name to the function.
result <- fromJSON(file = "input.json")
# Convert JSON file to a data frame.
json_data_frame <- as.data.frame(result)
print(json_data_frame)
Когда мы выполняем приведенный выше код, он дает следующий результат —
id, name, salary, start_date, dept 1 1 Rick 623.30 2012-01-01 IT 2 2 Dan 515.20 2013-09-23 Operations 3 3 Michelle 611.00 2014-11-15 IT 4 4 Ryan 729.00 2014-05-11 HR 5 NA Gary 843.25 2015-03-27 Finance 6 6 Nina 578.00 2013-05-21 IT 7 7 Simon 632.80 2013-07-30 Operations 8 8 Guru 722.50 2014-06-17 Finance
R — Веб-данные
Многие веб-сайты предоставляют данные для потребления своими пользователями. Например, Всемирная организация здравоохранения (ВОЗ) предоставляет отчеты о медицинской и медицинской информации в виде файлов CSV, txt и XML. Используя программы R, мы можем программно извлекать конкретные данные с таких сайтов. Некоторые пакеты в R, которые используются для сбора данных из Интернета, — «RCurl», XML »и« stringr ». Они используются для подключения к URL-адресам, определения необходимых ссылок для файлов и загрузки их в локальную среду.
Установить пакеты R
Следующие пакеты необходимы для обработки URL-адресов и ссылок на файлы. Если они недоступны в вашей среде R, вы можете установить их с помощью следующих команд.
install.packages("RCurl")
install.packages("XML")
install.packages("stringr")
install.packages("plyr")
Входные данные
Мы посетим данные о погоде в URL и загрузим файлы CSV с использованием R за 2015 год.
пример
Мы будем использовать функцию getHTMLLinks () для сбора URL-адресов файлов. Затем мы будем использовать функцию download.file () для сохранения файлов в локальной системе. Поскольку мы будем применять один и тот же код снова и снова для нескольких файлов, мы создадим функцию, которая будет вызываться несколько раз. Имена файлов передаются в качестве параметров в виде объекта списка R в эту функцию.
# Read the URL.
url <- "http://www.geos.ed.ac.uk/~weather/jcmb_ws/"
# Gather the html links present in the webpage.
links <- getHTMLLinks(url)
# Identify only the links which point to the JCMB 2015 files.
filenames <- links[str_detect(links, "JCMB_2015")]
# Store the file names as a list.
filenames_list <- as.list(filenames)
# Create a function to download the files by passing the URL and filename list.
downloadcsv <- function (mainurl,filename) {
filedetails <- str_c(mainurl,filename)
download.file(filedetails,filename)
}
# Now apply the l_ply function and save the files into the current R working directory.
l_ply(filenames,downloadcsv,mainurl = "http://www.geos.ed.ac.uk/~weather/jcmb_ws/")
Проверить загрузку файла
После запуска приведенного выше кода вы можете найти следующие файлы в текущем рабочем каталоге R.
"JCMB_2015.csv" "JCMB_2015_Apr.csv" "JCMB_2015_Feb.csv" "JCMB_2015_Jan.csv" "JCMB_2015_Mar.csv"
R — Базы данных
Данные реляционных баз данных хранятся в нормализованном формате. Итак, для проведения статистических вычислений нам понадобятся очень сложные и сложные запросы SQL. Но R может легко подключаться ко многим реляционным базам данных, таким как MySql, Oracle, Sql-сервер и т. Д., И извлекать из них записи в виде фрейма данных. Как только данные становятся доступны в среде R, они становятся обычным набором данных R и могут обрабатываться или анализироваться с использованием всех мощных пакетов и функций.
В этом уроке мы будем использовать MySql в качестве справочной базы данных для подключения к R.
Пакет RMySQL
R имеет встроенный пакет с именем «RMySQL», который обеспечивает встроенную связь между базой данных MySql. Вы можете установить этот пакет в среде R, используя следующую команду.
install.packages("RMySQL")
Подключение R к MySql
После установки пакета мы создаем объект подключения в R для подключения к базе данных. Он принимает имя пользователя, пароль, имя базы данных и имя хоста в качестве входных данных.
# Create a connection Object to MySQL database. # We will connect to the sampel database named "sakila" that comes with MySql installation. mysqlconnection = dbConnect(MySQL(), user = 'root', password = '', dbname = 'sakila', host = 'localhost') # List the tables available in this database. dbListTables(mysqlconnection)
Когда мы выполняем приведенный выше код, он дает следующий результат —
[1] "actor" "actor_info" [3] "address" "category" [5] "city" "country" [7] "customer" "customer_list" [9] "film" "film_actor" [11] "film_category" "film_list" [13] "film_text" "inventory" [15] "language" "nicer_but_slower_film_list" [17] "payment" "rental" [19] "sales_by_film_category" "sales_by_store" [21] "staff" "staff_list" [23] "store"
Опрос таблиц
Мы можем запросить таблицы базы данных в MySql, используя функцию dbSendQuery () . Запрос выполняется в MySql, а набор результатов возвращается с помощью функции R fetch () . Наконец, он сохраняется как фрейм данных в R.
# Query the "actor" tables to get all the rows. result = dbSendQuery(mysqlconnection, "select * from actor") # Store the result in a R data frame object. n = 5 is used to fetch first 5 rows. data.frame = fetch(result, n = 5) print(data.fame)
Когда мы выполняем приведенный выше код, он дает следующий результат —
actor_id first_name last_name last_update 1 1 PENELOPE GUINESS 2006-02-15 04:34:33 2 2 NICK WAHLBERG 2006-02-15 04:34:33 3 3 ED CHASE 2006-02-15 04:34:33 4 4 JENNIFER DAVIS 2006-02-15 04:34:33 5 5 JOHNNY LOLLOBRIGIDA 2006-02-15 04:34:33
Запрос с предложением фильтра
Мы можем передать любой действительный запрос на выборку, чтобы получить результат.
result = dbSendQuery(mysqlconnection, "select * from actor where last_name = 'TORN'") # Fetch all the records(with n = -1) and store it as a data frame. data.frame = fetch(result, n = -1) print(data)
Когда мы выполняем приведенный выше код, он дает следующий результат —
actor_id first_name last_name last_update 1 18 DAN TORN 2006-02-15 04:34:33 2 94 KENNETH TORN 2006-02-15 04:34:33 3 102 WALTER TORN 2006-02-15 04:34:33
Обновление строк в таблицах
Мы можем обновить строки в таблице Mysql, передав запрос на обновление в функцию dbSendQuery ().
dbSendQuery(mysqlconnection, "update mtcars set disp = 168.5 where hp = 110")
После выполнения приведенного выше кода мы видим, что таблица обновлена в среде MySql.
Вставка данных в таблицы
dbSendQuery(mysqlconnection,
"insert into mtcars(row_names, mpg, cyl, disp, hp, drat, wt, qsec, vs, am, gear, carb)
values('New Mazda RX4 Wag', 21, 6, 168.5, 110, 3.9, 2.875, 17.02, 0, 1, 4, 4)"
)
После выполнения приведенного выше кода мы видим строку, вставленную в таблицу в среде MySql.
Создание таблиц в MySql
Мы можем создавать таблицы в MySql, используя функцию dbWriteTable () . Он перезаписывает таблицу, если она уже существует, и принимает фрейм данных в качестве входных данных.
# Create the connection object to the database where we want to create the table. mysqlconnection = dbConnect(MySQL(), user = 'root', password = '', dbname = 'sakila', host = 'localhost') # Use the R data frame "mtcars" to create the table in MySql. # All the rows of mtcars are taken inot MySql. dbWriteTable(mysqlconnection, "mtcars", mtcars[, ], overwrite = TRUE)
После выполнения приведенного выше кода мы можем увидеть таблицу, созданную в среде MySql.
Отбрасывание таблиц в MySql
Мы можем отбрасывать таблицы в базе данных MySql, передавая оператор отбрасывания таблиц в dbSendQuery () так же, как мы использовали его для запроса данных из таблиц.
dbSendQuery(mysqlconnection, 'drop table if exists mtcars')
После выполнения приведенного выше кода мы видим, что таблица отброшена в среде MySql.
R — Круговые диаграммы
Язык программирования R имеет множество библиотек для создания диаграмм и графиков. Круговая диаграмма — это представление значений в виде кусочков круга разных цветов. Срезы помечены, и числа, соответствующие каждому срезу, также представлены на диаграмме.
В R круговая диаграмма создается с использованием функции pie (), которая принимает положительные числа в качестве входных данных вектора. Дополнительные параметры используются для управления метками, цветом, заголовком и т. Д.
Синтаксис
Основной синтаксис для создания круговой диаграммы с использованием R —
pie(x, labels, radius, main, col, clockwise)
Ниже приведено описание используемых параметров:
-
x — это вектор, содержащий числовые значения, используемые в круговой диаграмме.
-
метки используются для описания ломтиков.
-
radius указывает радиус круга круговой диаграммы (значение от -1 до +1).
-
main указывает на название графика.
-
col обозначает цветовую палитру.
-
по часовой стрелке — логическое значение, указывающее, нарисованы ли срезы по часовой стрелке или против часовой стрелки.
x — это вектор, содержащий числовые значения, используемые в круговой диаграмме.
метки используются для описания ломтиков.
radius указывает радиус круга круговой диаграммы (значение от -1 до +1).
main указывает на название графика.
col обозначает цветовую палитру.
по часовой стрелке — логическое значение, указывающее, нарисованы ли срезы по часовой стрелке или против часовой стрелки.
пример
Очень простая круговая диаграмма создается с использованием только входного вектора и меток. Приведенный ниже скрипт создаст и сохранит круговую диаграмму в текущем рабочем каталоге R.
# Create data for the graph.
x <- c(21, 62, 10, 53)
labels <- c("London", "New York", "Singapore", "Mumbai")
# Give the chart file a name.
png(file = "city.jpg")
# Plot the chart.
pie(x,labels)
# Save the file.
dev.off()
Когда мы выполняем приведенный выше код, он дает следующий результат —
Название и цвета круговой диаграммы
Мы можем расширить возможности диаграммы, добавив больше параметров в функцию. Мы будем использовать параметр main, чтобы добавить заголовок к диаграмме, а другой параметр — col, который будет использовать палитру цвета радуги при рисовании диаграммы. Длина поддона должна совпадать с количеством значений, которые мы имеем для диаграммы. Следовательно, мы используем длину (х).
пример
Приведенный ниже скрипт создаст и сохранит круговую диаграмму в текущем рабочем каталоге R.
# Create data for the graph.
x <- c(21, 62, 10, 53)
labels <- c("London", "New York", "Singapore", "Mumbai")
# Give the chart file a name.
png(file = "city_title_colours.jpg")
# Plot the chart with title and rainbow color pallet.
pie(x, labels, main = "City pie chart", col = rainbow(length(x)))
# Save the file.
dev.off()
Когда мы выполняем приведенный выше код, он дает следующий результат —
Процент срезов и легенда диаграммы
Мы можем добавить процент срезов и условные обозначения диаграммы, создав дополнительные переменные диаграммы.
# Create data for the graph.
x <- c(21, 62, 10,53)
labels <- c("London","New York","Singapore","Mumbai")
piepercent<- round(100*x/sum(x), 1)
# Give the chart file a name.
png(file = "city_percentage_legends.jpg")
# Plot the chart.
pie(x, labels = piepercent, main = "City pie chart",col = rainbow(length(x)))
legend("topright", c("London","New York","Singapore","Mumbai"), cex = 0.8,
fill = rainbow(length(x)))
# Save the file.
dev.off()
Когда мы выполняем приведенный выше код, он дает следующий результат —
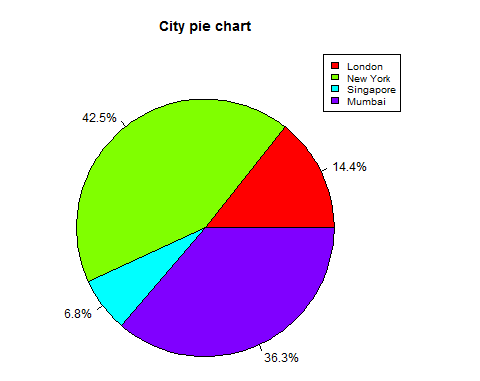
3D круговая диаграмма
Круговую диаграмму с 3 измерениями можно нарисовать с помощью дополнительных пакетов. Пакетная матрица имеет функцию pie3D (), которая используется для этого.
# Get the library.
library(plotrix)
# Create data for the graph.
x <- c(21, 62, 10,53)
lbl <- c("London","New York","Singapore","Mumbai")
# Give the chart file a name.
png(file = "3d_pie_chart.jpg")
# Plot the chart.
pie3D(x,labels = lbl,explode = 0.1, main = "Pie Chart of Countries ")
# Save the file.
dev.off()
Когда мы выполняем приведенный выше код, он дает следующий результат —
R — Гистограммы
Гистограмма представляет данные в прямоугольных столбцах, длина столбца которых пропорциональна значению переменной. R использует функцию barplot () для создания гистограмм. R может рисовать как вертикальные, так и горизонтальные столбцы на гистограмме. В гистограмме каждому из баров могут быть даны разные цвета.
Синтаксис
Основной синтаксис для создания гистограммы в R —
barplot(H,xlab,ylab,main, names.arg,col)
Ниже приведено описание используемых параметров:
- H — вектор или матрица, содержащая числовые значения, используемые в гистограмме.
- xlab — это метка для оси x.
- ylab — метка для оси y.
- Основным является заголовок гистограммы.
- names.arg — это вектор имен, появляющихся под каждой полосой.
- col используется, чтобы дать цвета столбцам на графике.
пример
Простая гистограмма создается с использованием только входного вектора и имени каждого бара.
Приведенный ниже скрипт создаст и сохранит гистограмму в текущем рабочем каталоге R.
# Create the data for the chart H <- c(7,12,28,3,41) # Give the chart file a name png(file = "barchart.png") # Plot the bar chart barplot(H) # Save the file dev.off()
Когда мы выполняем приведенный выше код, он дает следующий результат —
Ярлыки гистограммы, название и цвета
Возможности гистограммы можно расширить, добавив больше параметров. Основной параметр используется для добавления заголовка . Параметр col используется для добавления цветов к столбцам. Args.name — это вектор, имеющий то же количество значений, что и входной вектор, для описания значения каждого столбца.
пример
Приведенный ниже скрипт создаст и сохранит гистограмму в текущем рабочем каталоге R.
# Create the data for the chart
H <- c(7,12,28,3,41)
M <- c("Mar","Apr","May","Jun","Jul")
# Give the chart file a name
png(file = "barchart_months_revenue.png")
# Plot the bar chart
barplot(H,names.arg=M,xlab="Month",ylab="Revenue",col="blue",
main="Revenue chart",border="red")
# Save the file
dev.off()
Когда мы выполняем приведенный выше код, он дает следующий результат —
Гистограмма группы и гистограмма с накоплением
Мы можем создать гистограмму с группами баров и стеков в каждом баре, используя матрицу в качестве входных значений.
Более двух переменных представлены в виде матрицы, которая используется для создания гистограммы группы и гистограммы с накоплением.
# Create the input vectors.
colors = c("green","orange","brown")
months <- c("Mar","Apr","May","Jun","Jul")
regions <- c("East","West","North")
# Create the matrix of the values.
Values <- matrix(c(2,9,3,11,9,4,8,7,3,12,5,2,8,10,11), nrow = 3, ncol = 5, byrow = TRUE)
# Give the chart file a name
png(file = "barchart_stacked.png")
# Create the bar chart
barplot(Values, main = "total revenue", names.arg = months, xlab = "month", ylab = "revenue", col = colors)
# Add the legend to the chart
legend("topleft", regions, cex = 1.3, fill = colors)
# Save the file
dev.off()
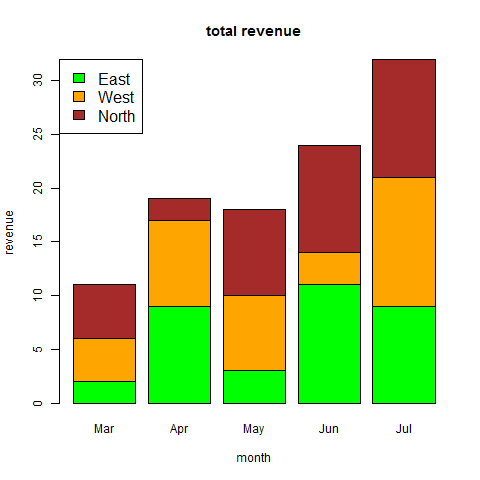
R — Boxplots
Блокпосты представляют собой меру того, насколько хорошо распределены данные в наборе данных. Он делит набор данных на три квартиля. Этот график представляет минимум, максимум, медиану, первый квартиль и третий квартиль в наборе данных. Это также полезно при сравнении распределения данных по наборам данных путем рисования коробочных диаграмм для каждого из них.
Бокплоты создаются в R с помощью функции boxplot () .
Синтаксис
Основной синтаксис для создания боксплота в R —
boxplot(x, data, notch, varwidth, names, main)
Ниже приведено описание используемых параметров:
-
х — это вектор или формула.
-
данные — это фрейм данных.
-
Notch — логическое значение. Установите как TRUE, чтобы нарисовать метку.
-
varwidth является логическим значением. Установите значение true, чтобы нарисовать ширину поля пропорционально размеру выборки.
-
Имена — это групповые ярлыки, которые будут напечатаны под каждым коробочным графиком.
-
main используется, чтобы дать название графику.
х — это вектор или формула.
данные — это фрейм данных.
Notch — логическое значение. Установите как TRUE, чтобы нарисовать метку.
varwidth является логическим значением. Установите значение true, чтобы нарисовать ширину поля пропорционально размеру выборки.
Имена — это групповые ярлыки, которые будут напечатаны под каждым коробочным графиком.
main используется, чтобы дать название графику.
пример
Мы используем набор данных «mtcars», доступный в среде R, чтобы создать базовый блокплот. Давайте посмотрим на столбцы «mpg» и «cyl» в mtcars.
input <- mtcars[,c('mpg','cyl')]
print(head(input))
Когда мы выполняем приведенный выше код, он дает следующий результат —
mpg cyl Mazda RX4 21.0 6 Mazda RX4 Wag 21.0 6 Datsun 710 22.8 4 Hornet 4 Drive 21.4 6 Hornet Sportabout 18.7 8 Valiant 18.1 6
Создание Boxplot
Приведенный ниже скрипт создаст график коробчатого графика для отношения между миль на галлон (миль на галлон) и цил (количество цилиндров).
# Give the chart file a name. png(file = "boxplot.png") # Plot the chart. boxplot(mpg ~ cyl, data = mtcars, xlab = "Number of Cylinders", ylab = "Miles Per Gallon", main = "Mileage Data") # Save the file. dev.off()
Когда мы выполняем приведенный выше код, он дает следующий результат —
Боксплот с надрезом
Мы можем нарисовать прямоугольник с надрезом, чтобы выяснить, как медианы разных групп данных соответствуют друг другу.
Приведенный ниже скрипт создаст график коробчатого графика с надрезом для каждой группы данных.
# Give the chart file a name.
png(file = "boxplot_with_notch.png")
# Plot the chart.
boxplot(mpg ~ cyl, data = mtcars,
xlab = "Number of Cylinders",
ylab = "Miles Per Gallon",
main = "Mileage Data",
notch = TRUE,
varwidth = TRUE,
col = c("green","yellow","purple"),
names = c("High","Medium","Low")
)
# Save the file.
dev.off()
Когда мы выполняем приведенный выше код, он дает следующий результат —
R — гистограммы
Гистограмма представляет частоты значений переменной, сгруппированных в диапазоны. Гистограмма похожа на гистограмму, но разница в том, что она группирует значения в непрерывные диапазоны. Каждый столбец в гистограмме представляет высоту количества значений, присутствующих в этом диапазоне.
R создает гистограмму с помощью функции hist () . Эта функция принимает вектор в качестве входных данных и использует еще несколько параметров для построения гистограмм.
Синтаксис
Основной синтаксис для создания гистограммы с использованием R —
hist(v,main,xlab,xlim,ylim,breaks,col,border)
Ниже приведено описание используемых параметров:
-
v — вектор, содержащий числовые значения, используемые в гистограмме.
-
main указывает на название графика.
-
col используется для установки цвета столбцов.
-
border используется для установки цвета рамки каждого бара.
-
xlab используется для описания оси X.
-
xlim используется для указания диапазона значений по оси X.
-
ylim используется для указания диапазона значений на оси Y.
-
Перерывы используются для указания ширины каждого бара.
v — вектор, содержащий числовые значения, используемые в гистограмме.
main указывает на название графика.
col используется для установки цвета столбцов.
border используется для установки цвета рамки каждого бара.
xlab используется для описания оси X.
xlim используется для указания диапазона значений по оси X.
ylim используется для указания диапазона значений на оси Y.
Перерывы используются для указания ширины каждого бара.
пример
Простая гистограмма создается с использованием входных параметров вектора, метки, столбца и границы.
Сценарий, приведенный ниже, создаст и сохранит гистограмму в текущем рабочем каталоге R.
# Create data for the graph. v <- c(9,13,21,8,36,22,12,41,31,33,19) # Give the chart file a name. png(file = "histogram.png") # Create the histogram. hist(v,xlab = "Weight",col = "yellow",border = "blue") # Save the file. dev.off()
Когда мы выполняем приведенный выше код, он дает следующий результат —
Диапазон значений X и Y
Чтобы указать диапазон значений, разрешенных по осям X и Y, мы можем использовать параметры xlim и ylim.
Ширина каждого бара может быть решена с помощью перерывов.
# Create data for the graph. v <- c(9,13,21,8,36,22,12,41,31,33,19) # Give the chart file a name. png(file = "histogram_lim_breaks.png") # Create the histogram. hist(v,xlab = "Weight",col = "green",border = "red", xlim = c(0,40), ylim = c(0,5), breaks = 5) # Save the file. dev.off()
Когда мы выполняем приведенный выше код, он дает следующий результат —
R — линейные графики
Линейный график — это график, который соединяет ряд точек путем рисования отрезков между ними. Эти точки упорядочены по одной из их координатных (обычно x-координатных) значений. Линейные графики обычно используются для определения тенденций в данных.
Функция plot () в R используется для создания линейного графика.
Синтаксис
Основной синтаксис для создания линейной диаграммы в R —
plot(v,type,col,xlab,ylab)
Ниже приведено описание используемых параметров:
-
v — вектор, содержащий числовые значения.
-
type принимает значение «p» для рисования только точек, «l» для рисования только линий и «o» для рисования как точек, так и линий.
-
xlab — это метка для оси x.
-
ylab — метка для оси y.
-
Основным является заголовок графика.
-
col используется, чтобы дать цвета и точкам и линиям.
v — вектор, содержащий числовые значения.
type принимает значение «p» для рисования только точек, «l» для рисования только линий и «o» для рисования как точек, так и линий.
xlab — это метка для оси x.
ylab — метка для оси y.
Основным является заголовок графика.
col используется, чтобы дать цвета и точкам и линиям.
пример
Простая линейная диаграмма создается с использованием входного вектора и параметра типа как «O». Приведенный ниже скрипт создаст и сохранит линейную диаграмму в текущем рабочем каталоге R.
# Create the data for the chart. v <- c(7,12,28,3,41) # Give the chart file a name. png(file = "line_chart.jpg") # Plot the bar chart. plot(v,type = "o") # Save the file. dev.off()
Когда мы выполняем приведенный выше код, он дает следующий результат —
Название линейной диаграммы, цвет и метки
Особенности линейного графика могут быть расширены с помощью дополнительных параметров. Мы добавляем цвет к точкам и линиям, присваиваем заголовок диаграмме и добавляем метки к осям.
пример
# Create the data for the chart. v <- c(7,12,28,3,41) # Give the chart file a name. png(file = "line_chart_label_colored.jpg") # Plot the bar chart. plot(v,type = "o", col = "red", xlab = "Month", ylab = "Rain fall", main = "Rain fall chart") # Save the file. dev.off()
Когда мы выполняем приведенный выше код, он дает следующий результат —
Несколько линий в линейной диаграмме
С помощью функции lines () можно нарисовать более одной линии на одном графике.
После построения первой линии функция lines () может использовать дополнительный вектор в качестве входных данных для рисования второй линии на графике,
# Create the data for the chart. v <- c(7,12,28,3,41) t <- c(14,7,6,19,3) # Give the chart file a name. png(file = "line_chart_2_lines.jpg") # Plot the bar chart. plot(v,type = "o",col = "red", xlab = "Month", ylab = "Rain fall", main = "Rain fall chart") lines(t, type = "o", col = "blue") # Save the file. dev.off()
Когда мы выполняем приведенный выше код, он дает следующий результат —
R — Scatterplots
Диаграммы рассеяния показывают много точек, нанесенных на декартовой плоскости. Каждая точка представляет значения двух переменных. Одна переменная выбрана на горизонтальной оси, а другая на вертикальной оси.
Простая диаграмма рассеяния создается с помощью функции plot () .
Синтаксис
Основной синтаксис для создания диаграммы рассеяния в R —
plot(x, y, main, xlab, ylab, xlim, ylim, axes)
Ниже приведено описание используемых параметров:
-
х — это набор данных, значения которого являются горизонтальными координатами.
-
y — это набор данных, значения которого являются вертикальными координатами.
-
Основным является плитка графика.
-
xlab — это метка на горизонтальной оси.
-
ylab — это метка на вертикальной оси.
-
xlim — пределы значений x, используемых для построения графика.
-
ylim — пределы значений y, используемых для построения графика.
-
Оси указывает, следует ли рисовать обе оси на графике.
х — это набор данных, значения которого являются горизонтальными координатами.
y — это набор данных, значения которого являются вертикальными координатами.
Основным является плитка графика.
xlab — это метка на горизонтальной оси.
ylab — это метка на вертикальной оси.
xlim — пределы значений x, используемых для построения графика.
ylim — пределы значений y, используемых для построения графика.
Оси указывает, следует ли рисовать обе оси на графике.
пример
Мы используем набор данных «mtcars», доступный в среде R, чтобы создать базовую диаграмму рассеяния. Давайте используем столбцы «wt» и «mpg» в mtcars.
input <- mtcars[,c('wt','mpg')]
print(head(input))
Когда мы выполняем приведенный выше код, он дает следующий результат —
wt mpg Mazda RX4 2.620 21.0 Mazda RX4 Wag 2.875 21.0 Datsun 710 2.320 22.8 Hornet 4 Drive 3.215 21.4 Hornet Sportabout 3.440 18.7 Valiant 3.460 18.1
Создание Scatterplot
Приведенный ниже скрипт создаст график диаграммы рассеяния для соотношения между весом (вес) и милю на галлон (миль на галлон).
# Get the input values.
input <- mtcars[,c('wt','mpg')]
# Give the chart file a name.
png(file = "scatterplot.png")
# Plot the chart for cars with weight between 2.5 to 5 and mileage between 15 and 30.
plot(x = input$wt,y = input$mpg,
xlab = "Weight",
ylab = "Milage",
xlim = c(2.5,5),
ylim = c(15,30),
main = "Weight vs Milage"
)
# Save the file.
dev.off()
Когда мы выполняем приведенный выше код, он дает следующий результат —
Матрицы рассеяния
Когда у нас более двух переменных и мы хотим найти корреляцию между одной переменной и остальными, мы используем матрицу рассеяния. Мы используем функцию pair () для создания матриц рассеяния.
Синтаксис
Основной синтаксис для создания матриц рассеяния в R это —
pairs(formula, data)
Ниже приведено описание используемых параметров:
-
формула представляет ряд переменных, используемых в парах.
-
Данные представляют собой набор данных, из которого будут взяты переменные.
формула представляет ряд переменных, используемых в парах.
Данные представляют собой набор данных, из которого будут взяты переменные.
пример
Каждая переменная связана с каждой из оставшихся переменных. Диаграмма рассеяния строится для каждой пары.
# Give the chart file a name. png(file = "scatterplot_matrices.png") # Plot the matrices between 4 variables giving 12 plots. # One variable with 3 others and total 4 variables. pairs(~wt+mpg+disp+cyl,data = mtcars, main = "Scatterplot Matrix") # Save the file. dev.off()
Когда приведенный выше код выполняется, мы получаем следующий вывод.
R — среднее значение, медиана и мода
Статистический анализ в R выполняется с использованием многих встроенных функций. Большинство из этих функций являются частью базового пакета R. Эти функции принимают вектор R в качестве входных данных вместе с аргументами и дают результат.
Функции, которые мы обсуждаем в этой главе, — это среднее значение, медиана и режим.
Имею в виду
Он рассчитывается путем взятия суммы значений и деления на количество значений в ряду данных.
Функция mean () используется для вычисления этого в R.
Синтаксис
Основной синтаксис для вычисления среднего значения в R —
mean(x, trim = 0, na.rm = FALSE, ...)
Ниже приведено описание используемых параметров:
-
х является входным вектором.
-
Обрезка используется для отбрасывания некоторых наблюдений с обоих концов отсортированного вектора.
-
na.rm используется для удаления пропущенных значений из входного вектора.
х является входным вектором.
Обрезка используется для отбрасывания некоторых наблюдений с обоих концов отсортированного вектора.
na.rm используется для удаления пропущенных значений из входного вектора.
пример
# Create a vector. x <- c(12,7,3,4.2,18,2,54,-21,8,-5) # Find Mean. result.mean <- mean(x) print(result.mean)
Когда мы выполняем приведенный выше код, он дает следующий результат —
[1] 8.22
Применение варианта обрезки
Если указан параметр обрезки, значения в векторе сортируются, а затем необходимое количество наблюдений отбрасывается из расчета среднего значения.
Когда трим = 0,3, 3 значения с каждого конца будут исключены из расчетов, чтобы найти среднее.
В этом случае отсортированный вектор равен (−21, −5, 2, 3, 4.2, 7, 8, 12, 18, 54), а значения, удаленные из вектора для расчета среднего значения, равны (−21, −5,2) слева и (12,18,54) справа.
# Create a vector. x <- c(12,7,3,4.2,18,2,54,-21,8,-5) # Find Mean. result.mean <- mean(x,trim = 0.3) print(result.mean)
Когда мы выполняем приведенный выше код, он дает следующий результат —
[1] 5.55
Применение опции NA
Если пропущенные значения отсутствуют, функция средних значений возвращает NA.
Чтобы удалить пропущенные значения из расчета, используйте na.rm = TRUE. что означает удалить значения NA.
# Create a vector. x <- c(12,7,3,4.2,18,2,54,-21,8,-5,NA) # Find mean. result.mean <- mean(x) print(result.mean) # Find mean dropping NA values. result.mean <- mean(x,na.rm = TRUE) print(result.mean)
Когда мы выполняем приведенный выше код, он дает следующий результат —
[1] NA [1] 8.22
медиана
Среднее значение в ряду данных называется медианой. Функция median () используется в R для вычисления этого значения.
Синтаксис
Основной синтаксис для вычисления медианы в R —
median(x, na.rm = FALSE)
Ниже приведено описание используемых параметров:
-
х является входным вектором.
-
na.rm используется для удаления пропущенных значений из входного вектора.
х является входным вектором.
na.rm используется для удаления пропущенных значений из входного вектора.
пример
# Create the vector. x <- c(12,7,3,4.2,18,2,54,-21,8,-5) # Find the median. median.result <- median(x) print(median.result)
Когда мы выполняем приведенный выше код, он дает следующий результат —
[1] 5.6
Режим
Режим — это значение, которое имеет наибольшее количество вхождений в наборе данных. Unike среднее и среднее, режим может иметь как числовые, так и символьные данные.
R не имеет стандартной встроенной функции для расчета режима. Таким образом, мы создаем пользовательскую функцию для расчета режима набора данных в R. Эта функция принимает вектор в качестве входных данных и дает значение режима в качестве выходных данных.
пример
# Create the function.
getmode <- function(v) {
uniqv <- unique(v)
uniqv[which.max(tabulate(match(v, uniqv)))]
}
# Create the vector with numbers.
v <- c(2,1,2,3,1,2,3,4,1,5,5,3,2,3)
# Calculate the mode using the user function.
result <- getmode(v)
print(result)
# Create the vector with characters.
charv <- c("o","it","the","it","it")
# Calculate the mode using the user function.
result <- getmode(charv)
print(result)
Когда мы выполняем приведенный выше код, он дает следующий результат —
[1] 2 [1] "it"
R — Линейная регрессия
Регрессионный анализ является очень широко используемым статистическим инструментом для установления модели отношений между двумя переменными. Одна из этих переменных называется предикторной переменной, значение которой собирается в ходе экспериментов. Другая переменная называется переменной ответа, значение которой получено из переменной предиктора.
В линейной регрессии эти две переменные связаны через уравнение, где показатель (степень) обеих этих переменных равен 1. Математически линейная зависимость представляет прямую линию, когда она изображена в виде графика. Нелинейное отношение, где показатель степени любой переменной не равен 1, создает кривую.
Общее математическое уравнение для линейной регрессии —
y = ax + b
Ниже приведено описание используемых параметров:
-
у — переменная ответа.
-
х — это предикторная переменная.
-
a и b являются константами, которые называются коэффициентами.
у — переменная ответа.
х — это предикторная переменная.
a и b являются константами, которые называются коэффициентами.
Шаги по созданию регрессии
Простым примером регрессии является прогнозирование веса человека, когда известен его рост. Для этого нам необходимо иметь соотношение между ростом и весом человека.
Шаги для создания отношений —
-
Проводят эксперимент по сбору образца наблюдаемых значений роста и соответствующего веса.
-
Создайте модель отношений, используя функции lm () в R.
-
Найдите коэффициенты из созданной модели и создайте математическое уравнение, используя эти
-
Получите сводную информацию о модели отношений, чтобы узнать среднюю ошибку в прогнозировании. Также называется остатками .
-
Чтобы предсказать вес новых людей, используйте функцию предиката () в R.
Проводят эксперимент по сбору образца наблюдаемых значений роста и соответствующего веса.
Создайте модель отношений, используя функции lm () в R.
Найдите коэффициенты из созданной модели и создайте математическое уравнение, используя эти
Получите сводную информацию о модели отношений, чтобы узнать среднюю ошибку в прогнозировании. Также называется остатками .
Чтобы предсказать вес новых людей, используйте функцию предиката () в R.
Входные данные
Ниже приведен пример данных, представляющих наблюдения —
# Values of height 151, 174, 138, 186, 128, 136, 179, 163, 152, 131 # Values of weight. 63, 81, 56, 91, 47, 57, 76, 72, 62, 48
Функция lm ()
Эта функция создает модель отношений между предиктором и переменной ответа.
Синтаксис
Основной синтаксис функции lm () в линейной регрессии —
lm(formula,data)
Ниже приведено описание используемых параметров:
-
формула представляет собой символ, представляющий отношения между х и у.
-
Данные — это вектор, к которому будет применена формула.
формула представляет собой символ, представляющий отношения между х и у.
Данные — это вектор, к которому будет применена формула.
Создать модель отношений и получить коэффициенты
x <- c(151, 174, 138, 186, 128, 136, 179, 163, 152, 131) y <- c(63, 81, 56, 91, 47, 57, 76, 72, 62, 48) # Apply the lm() function. relation <- lm(y~x) print(relation)
Когда мы выполняем приведенный выше код, он дает следующий результат —
Call: lm(formula = y ~ x) Coefficients: (Intercept) x -38.4551 0.6746
Получить резюме отношений
x <- c(151, 174, 138, 186, 128, 136, 179, 163, 152, 131) y <- c(63, 81, 56, 91, 47, 57, 76, 72, 62, 48) # Apply the lm() function. relation <- lm(y~x) print(summary(relation))
Когда мы выполняем приведенный выше код, он дает следующий результат —
Call:
lm(formula = y ~ x)
Residuals:
Min 1Q Median 3Q Max
-6.3002 -1.6629 0.0412 1.8944 3.9775
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -38.45509 8.04901 -4.778 0.00139 **
x 0.67461 0.05191 12.997 1.16e-06 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 3.253 on 8 degrees of freedom
Multiple R-squared: 0.9548, Adjusted R-squared: 0.9491
F-statistic: 168.9 on 1 and 8 DF, p-value: 1.164e-06
функция предиката ()
Синтаксис
Основным синтаксисом для Предиката () в линейной регрессии является —
predict(object, newdata)
Ниже приведено описание используемых параметров:
-
Объект — это формула, которая уже создана с помощью функции lm ().
-
newdata — это вектор, содержащий новое значение переменной-предиктора.
Объект — это формула, которая уже создана с помощью функции lm ().
newdata — это вектор, содержащий новое значение переменной-предиктора.
Предсказать вес новых людей
# The predictor vector. x <- c(151, 174, 138, 186, 128, 136, 179, 163, 152, 131) # The resposne vector. y <- c(63, 81, 56, 91, 47, 57, 76, 72, 62, 48) # Apply the lm() function. relation <- lm(y~x) # Find weight of a person with height 170. a <- data.frame(x = 170) result <- predict(relation,a) print(result)
Когда мы выполняем приведенный выше код, он дает следующий результат —
1 76.22869
Визуализируйте регрессию графически
# Create the predictor and response variable. x <- c(151, 174, 138, 186, 128, 136, 179, 163, 152, 131) y <- c(63, 81, 56, 91, 47, 57, 76, 72, 62, 48) relation <- lm(y~x) # Give the chart file a name. png(file = "linearregression.png") # Plot the chart. plot(y,x,col = "blue",main = "Height & Weight Regression", abline(lm(x~y)),cex = 1.3,pch = 16,xlab = "Weight in Kg",ylab = "Height in cm") # Save the file. dev.off()
Когда мы выполняем приведенный выше код, он дает следующий результат —
R — множественная регрессия
Множественная регрессия является продолжением линейной регрессии в связи между более чем двумя переменными. В простом линейном отношении у нас есть один предиктор и одна переменная ответа, но в множественной регрессии мы имеем более одной переменной предиктора и одну переменную ответа.
Общее математическое уравнение множественной регрессии —
y = a + b1x1 + b2x2 +...bnxn
Ниже приведено описание используемых параметров:
-
у — переменная ответа.
-
a, b1, b2 … bn — коэффициенты.
-
x1, x2, … xn — переменные предиктора.
у — переменная ответа.
a, b1, b2 … bn — коэффициенты.
x1, x2, … xn — переменные предиктора.
Мы создаем регрессионную модель, используя функцию lm () в R. Модель определяет значение коэффициентов, используя входные данные. Затем мы можем предсказать значение переменной отклика для данного набора переменных предиктора, используя эти коэффициенты.
Функция lm ()
Эта функция создает модель отношений между предиктором и переменной ответа.
Синтаксис
Основной синтаксис функции lm () в множественной регрессии —
lm(y ~ x1+x2+x3...,data)
Ниже приведено описание используемых параметров:
-
формула — это символ, представляющий связь между переменной ответа и переменными предиктора.
-
Данные — это вектор, к которому будет применена формула.
формула — это символ, представляющий связь между переменной ответа и переменными предиктора.
Данные — это вектор, к которому будет применена формула.
пример
Входные данные
Рассмотрим набор данных «mtcars», доступный в среде R. Это дает сравнение между различными моделями автомобилей с точки зрения пробега на галлон (миль на галлон), рабочего объема цилиндра («disp»), лошадиных сил («л.с.»), веса автомобиля («wt») и некоторых других параметров.
Цель модели — установить связь между «mpg» в качестве переменной отклика с «disp», «hp» и «wt» в качестве переменных-предикторов. Для этого мы создаем подмножество этих переменных из набора данных mtcars.
input <- mtcars[,c("mpg","disp","hp","wt")]
print(head(input))
Когда мы выполняем приведенный выше код, он дает следующий результат —
mpg disp hp wt Mazda RX4 21.0 160 110 2.620 Mazda RX4 Wag 21.0 160 110 2.875 Datsun 710 22.8 108 93 2.320 Hornet 4 Drive 21.4 258 110 3.215 Hornet Sportabout 18.7 360 175 3.440 Valiant 18.1 225 105 3.460
Создать модель отношений и получить коэффициенты
input <- mtcars[,c("mpg","disp","hp","wt")]
# Create the relationship model.
model <- lm(mpg~disp+hp+wt, data = input)
# Show the model.
print(model)
# Get the Intercept and coefficients as vector elements.
cat("# # # # The Coefficient Values # # # ","\n")
a <- coef(model)[1]
print(a)
Xdisp <- coef(model)[2]
Xhp <- coef(model)[3]
Xwt <- coef(model)[4]
print(Xdisp)
print(Xhp)
print(Xwt)
Когда мы выполняем приведенный выше код, он дает следующий результат —
Call:
lm(formula = mpg ~ disp + hp + wt, data = input)
Coefficients:
(Intercept) disp hp wt
37.105505 -0.000937 -0.031157 -3.800891
# # # # The Coefficient Values # # #
(Intercept)
37.10551
disp
-0.0009370091
hp
-0.03115655
wt
-3.800891
Создать уравнение для регрессионной модели
На основе приведенного выше значения перехвата и коэффициента мы создаем математическое уравнение.
Y = a+Xdisp.x1+Xhp.x2+Xwt.x3 or Y = 37.15+(-0.000937)*x1+(-0.0311)*x2+(-3.8008)*x3
Применить уравнение для прогнозирования новых значений
Мы можем использовать уравнение регрессии, созданное выше, для прогнозирования пробега, когда предоставляется новый набор значений для смещения, лошадиных сил и веса.
Для автомобиля с disp = 221, hp = 102 и wt = 2,91 прогнозируемый пробег составляет —
Y = 37.15+(-0.000937)*221+(-0.0311)*102+(-3.8008)*2.91 = 22.7104
R — Логистическая регрессия
Логистическая регрессия — это модель регрессии, в которой переменная ответа (зависимая переменная) имеет категориальные значения, такие как True / False или 0/1. Фактически он измеряет вероятность двоичного отклика как значение переменной отклика на основе математического уравнения, связывающего его с переменными предиктора.
Общее математическое уравнение для логистической регрессии —
y = 1/(1+e^-(a+b1x1+b2x2+b3x3+...))
Ниже приведено описание используемых параметров:
-
у — переменная ответа.
-
х — это предикторная переменная.
-
a и b — коэффициенты, которые являются числовыми константами.
у — переменная ответа.
х — это предикторная переменная.
a и b — коэффициенты, которые являются числовыми константами.
Функция, используемая для создания регрессионной модели, является функцией glm () .
Синтаксис
Основной синтаксис функции glm () в логистической регрессии —
glm(formula,data,family)
Ниже приведено описание используемых параметров:
-
формула представляет собой символ, представляющий отношения между переменными.
-
Данные — это набор данных, дающий значения этих переменных.
-
Семейство является объектом R для указания деталей модели. Это значение является биномиальным для логистической регрессии.
формула представляет собой символ, представляющий отношения между переменными.
Данные — это набор данных, дающий значения этих переменных.
Семейство является объектом R для указания деталей модели. Это значение является биномиальным для логистической регрессии.
пример
Встроенный набор данных «mtcars» описывает различные модели автомобилей с различными характеристиками двигателя. В наборе данных «mtcars» режим передачи (автоматический или ручной) описывается столбцом am, который является двоичным значением (0 или 1). Мы можем создать модель логистической регрессии между столбцами «am» и 3 другими столбцами — hp, wt и cyl.
# Select some columns form mtcars.
input <- mtcars[,c("am","cyl","hp","wt")]
print(head(input))
Когда мы выполняем приведенный выше код, он дает следующий результат —
am cyl hp wt Mazda RX4 1 6 110 2.620 Mazda RX4 Wag 1 6 110 2.875 Datsun 710 1 4 93 2.320 Hornet 4 Drive 0 6 110 3.215 Hornet Sportabout 0 8 175 3.440 Valiant 0 6 105 3.460
Создать модель регрессии
Мы используем функцию glm () для создания регрессионной модели и получения ее сводки для анализа.
input <- mtcars[,c("am","cyl","hp","wt")]
am.data = glm(formula = am ~ cyl + hp + wt, data = input, family = binomial)
print(summary(am.data))
Когда мы выполняем приведенный выше код, он дает следующий результат —
Call:
glm(formula = am ~ cyl + hp + wt, family = binomial, data = input)
Deviance Residuals:
Min 1Q Median 3Q Max
-2.17272 -0.14907 -0.01464 0.14116 1.27641
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 19.70288 8.11637 2.428 0.0152 *
cyl 0.48760 1.07162 0.455 0.6491
hp 0.03259 0.01886 1.728 0.0840 .
wt -9.14947 4.15332 -2.203 0.0276 *
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 43.2297 on 31 degrees of freedom
Residual deviance: 9.8415 on 28 degrees of freedom
AIC: 17.841
Number of Fisher Scoring iterations: 8
Заключение
В итоге, поскольку значение p в последнем столбце больше, чем 0,05 для переменных «cyl» и «hp», мы считаем, что они несущественны для внесения вклада в значение переменной «am». Только вес (wt) влияет на значение «am» в этой регрессионной модели.
R — нормальное распределение
При случайном сборе данных из независимых источников обычно наблюдается нормальное распределение данных. Это означает, что при построении графика со значением переменной на горизонтальной оси и количеством значений на вертикальной оси мы получаем кривую в форме колокола. Центр кривой представляет среднее значение набора данных. На графике пятьдесят процентов значений лежат слева от среднего значения, а остальные пятьдесят процентов лежат справа от графика. Это называется нормальным распределением в статистике.
R имеет четыре встроенных функции для генерации нормального распределения. Они описаны ниже.
dnorm(x, mean, sd) pnorm(x, mean, sd) qnorm(p, mean, sd) rnorm(n, mean, sd)
Ниже приведено описание параметров, используемых в вышеуказанных функциях:
-
х вектор чисел.
-
р — вектор вероятностей.
-
n — количество наблюдений (размер выборки).
-
среднее значение — это среднее значение данных выборки. Это значение по умолчанию равно нулю.
-
SD — стандартное отклонение. Это значение по умолчанию равно 1.
х вектор чисел.
р — вектор вероятностей.
n — количество наблюдений (размер выборки).
среднее значение — это среднее значение данных выборки. Это значение по умолчанию равно нулю.
SD — стандартное отклонение. Это значение по умолчанию равно 1.
dnorm ()
Эта функция дает высоту распределения вероятностей в каждой точке для данного среднего значения и стандартного отклонения.
# Create a sequence of numbers between -10 and 10 incrementing by 0.1. x <- seq(-10, 10, by = .1) # Choose the mean as 2.5 and standard deviation as 0.5. y <- dnorm(x, mean = 2.5, sd = 0.5) # Give the chart file a name. png(file = "dnorm.png") plot(x,y) # Save the file. dev.off()
Когда мы выполняем приведенный выше код, он дает следующий результат —
pnorm ()
Эта функция дает вероятность того, что обычно распределенное случайное число меньше значения данного числа. Это также называется «кумулятивная функция распределения».
# Create a sequence of numbers between -10 and 10 incrementing by 0.2. x <- seq(-10,10,by = .2) # Choose the mean as 2.5 and standard deviation as 2. y <- pnorm(x, mean = 2.5, sd = 2) # Give the chart file a name. png(file = "pnorm.png") # Plot the graph. plot(x,y) # Save the file. dev.off()
Когда мы выполняем приведенный выше код, он дает следующий результат —
qnorm ()
Эта функция принимает значение вероятности и дает число, совокупное значение которого соответствует значению вероятности.
# Create a sequence of probability values incrementing by 0.02. x <- seq(0, 1, by = 0.02) # Choose the mean as 2 and standard deviation as 3. y <- qnorm(x, mean = 2, sd = 1) # Give the chart file a name. png(file = "qnorm.png") # Plot the graph. plot(x,y) # Save the file. dev.off()
Когда мы выполняем приведенный выше код, он дает следующий результат —
RNorm ()
Эта функция используется для генерации случайных чисел с нормальным распределением. Он принимает размер выборки в качестве входных данных и генерирует столько случайных чисел. Мы рисуем гистограмму, чтобы показать распределение сгенерированных чисел.
# Create a sample of 50 numbers which are normally distributed. y <- rnorm(50) # Give the chart file a name. png(file = "rnorm.png") # Plot the histogram for this sample. hist(y, main = "Normal DIstribution") # Save the file. dev.off()
Когда мы выполняем приведенный выше код, он дает следующий результат —
R — биномиальное распределение
Модель биномиального распределения имеет дело с нахождением вероятности успеха события, которое имеет только два возможных результата в серии экспериментов. Например, бросание монеты всегда дает голову или хвост. Вероятность найти ровно 3 головы при повторном подбрасывании монеты 10 раз оценивается во время биномиального распределения.
R имеет четыре встроенных функции для генерации биномиального распределения. Они описаны ниже.
dbinom(x, size, prob) pbinom(x, size, prob) qbinom(p, size, prob) rbinom(n, size, prob)
Ниже приведено описание используемых параметров:
-
х вектор чисел.
-
р — вектор вероятностей.
-
n — количество наблюдений.
-
Размер — это количество испытаний.
-
prob — вероятность успеха каждого испытания.
х вектор чисел.
р — вектор вероятностей.
n — количество наблюдений.
Размер — это количество испытаний.
prob — вероятность успеха каждого испытания.
dbinom ()
Эта функция дает распределение плотности вероятности в каждой точке.
# Create a sample of 50 numbers which are incremented by 1. x <- seq(0,50,by = 1) # Create the binomial distribution. y <- dbinom(x,50,0.5) # Give the chart file a name. png(file = "dbinom.png") # Plot the graph for this sample. plot(x,y) # Save the file. dev.off()
Когда мы выполняем приведенный выше код, он дает следующий результат —
pbinom ()
Эта функция дает совокупную вероятность события. Это одно значение, представляющее вероятность.
# Probability of getting 26 or less heads from a 51 tosses of a coin. x <- pbinom(26,51,0.5) print(x)
Когда мы выполняем приведенный выше код, он дает следующий результат —
[1] 0.610116
qbinom ()
Эта функция принимает значение вероятности и дает число, совокупное значение которого соответствует значению вероятности.
# How many heads will have a probability of 0.25 will come out when a coin # is tossed 51 times. x <- qbinom(0.25,51,1/2) print(x)
Когда мы выполняем приведенный выше код, он дает следующий результат —
[1] 23
rbinom ()
Эта функция генерирует необходимое количество случайных значений заданной вероятности из заданной выборки.
# Find 8 random values from a sample of 150 with probability of 0.4. x <- rbinom(8,150,.4) print(x)
Когда мы выполняем приведенный выше код, он дает следующий результат —
[1] 58 61 59 66 55 60 61 67
R — Пуассоновская регрессия
Регрессия Пуассона включает в себя регрессионные модели, в которых переменная ответа представлена в виде числа, а не дробных чисел. Например, подсчет количества рождений или количества побед в серии футбольных матчей. Также значения переменных отклика следуют распределению Пуассона.
Общее математическое уравнение для пуассоновской регрессии —
log(y) = a + b1x1 + b2x2 + bnxn.....
Ниже приведено описание используемых параметров:
-
у — переменная ответа.
-
а и б — числовые коэффициенты.
-
х — это предикторная переменная.
у — переменная ответа.
а и б — числовые коэффициенты.
х — это предикторная переменная.
Функция, используемая для создания модели регрессии Пуассона, является функцией glm () .
Синтаксис
Основной синтаксис функции glm () в регрессии Пуассона —
glm(formula,data,family)
Ниже приведено описание параметров, используемых в вышеуказанных функциях:
-
формула представляет собой символ, представляющий отношения между переменными.
-
Данные — это набор данных, дающий значения этих переменных.
-
Семейство является объектом R для указания деталей модели. Это значение «Пуассона» для логистической регрессии.
формула представляет собой символ, представляющий отношения между переменными.
Данные — это набор данных, дающий значения этих переменных.
Семейство является объектом R для указания деталей модели. Это значение «Пуассона» для логистической регрессии.
пример
У нас есть встроенный набор данных «деформации основы», который описывает влияние типа шерсти (А или В) и натяжения (низкого, среднего или высокого) на количество разрывов основы на ткацкий станок. Рассмотрим «разрывы» как переменную ответа, которая является подсчетом количества разрывов. «Тип» шерсти и «натяжение» принимаются в качестве переменных предикторов.
Входные данные
input <- warpbreaks print(head(input))
Когда мы выполняем приведенный выше код, он дает следующий результат —
breaks wool tension 1 26 A L 2 30 A L 3 54 A L 4 25 A L 5 70 A L 6 52 A L
Создать модель регрессии
output <-glm(formula = breaks ~ wool+tension, data = warpbreaks, family = poisson) print(summary(output))
Когда мы выполняем приведенный выше код, он дает следующий результат —
Call:
glm(formula = breaks ~ wool + tension, family = poisson, data = warpbreaks)
Deviance Residuals:
Min 1Q Median 3Q Max
-3.6871 -1.6503 -0.4269 1.1902 4.2616
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 3.69196 0.04541 81.302 < 2e-16 ***
woolB -0.20599 0.05157 -3.994 6.49e-05 ***
tensionM -0.32132 0.06027 -5.332 9.73e-08 ***
tensionH -0.51849 0.06396 -8.107 5.21e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for poisson family taken to be 1)
Null deviance: 297.37 on 53 degrees of freedom
Residual deviance: 210.39 on 50 degrees of freedom
AIC: 493.06
Number of Fisher Scoring iterations: 4
В сводке мы ищем значение p в последнем столбце меньше 0,05, чтобы учесть влияние переменной предиктора на переменную ответа. Как видно, тип шерсти B, имеющий тип натяжения M и H, влияет на количество разрывов.
R — Анализ Ковариации
Мы используем регрессионный анализ для создания моделей, которые описывают влияние изменения переменных предиктора на переменную ответа. Иногда, если у нас есть категориальная переменная со значениями, такими как Да / Нет или Мужской / Женский и т. Д. Простой регрессионный анализ дает несколько результатов для каждого значения категориальной переменной. В таком сценарии мы можем изучить влияние категориальной переменной, используя ее вместе с переменной-предиктором и сравнивая линии регрессии для каждого уровня категориальной переменной. Такой анализ называется анализ ковариантности, также называемый ANCOVA .
пример
Рассмотрим встроенный в R набор данных mtcars. В нем мы наблюдаем, что поле «am» представляет тип трансмиссии (автоматический или ручной). Это категориальная переменная со значениями 0 и 1. От нее может зависеть и количество миль на галлон (миль на галлон) автомобиля, помимо значения лошадиных сил («л.с.»).
Мы изучаем влияние значения «am» на регрессию между «mpg» и «hp». Это делается с помощью функции aov (), за которой следует функция anova () для сравнения множественных регрессий.
Входные данные
Создайте фрейм данных, содержащий поля «mpg», «hp» и «am» из набора данных mtcars. Здесь мы берем «mpg» как переменную ответа, «hp» как переменную предиктора и «am» как категориальную переменную.
input <- mtcars[,c("am","mpg","hp")]
print(head(input))
Когда мы выполняем приведенный выше код, он дает следующий результат —
am mpg hp Mazda RX4 1 21.0 110 Mazda RX4 Wag 1 21.0 110 Datsun 710 1 22.8 93 Hornet 4 Drive 0 21.4 110 Hornet Sportabout 0 18.7 175 Valiant 0 18.1 105
ANCOVA Анализ
Мы создаем регрессионную модель, в которой в качестве переменной-предиктора используется «hp», а в качестве ответной переменной — «mpg» с учетом взаимодействия между «am» и «hp».
Модель с взаимодействием между категориальной переменной и переменной предиктора
# Get the dataset. input <- mtcars # Create the regression model. result <- aov(mpg~hp*am,data = input) print(summary(result))
Когда мы выполняем приведенный выше код, он дает следующий результат —
Df Sum Sq Mean Sq F value Pr(>F) hp 1 678.4 678.4 77.391 1.50e-09 *** am 1 202.2 202.2 23.072 4.75e-05 *** hp:am 1 0.0 0.0 0.001 0.981 Residuals 28 245.4 8.8 --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Этот результат показывает, что мощность в лошадиных силах и тип трансмиссии оказывают существенное влияние на мили на галлон, поскольку значение p в обоих случаях составляет менее 0,05. Но взаимодействие между этими двумя переменными не является значительным, так как значение р составляет более 0,05.
Модель без взаимодействия между категориальной переменной и предикторной переменной
# Get the dataset. input <- mtcars # Create the regression model. result <- aov(mpg~hp+am,data = input) print(summary(result))
Когда мы выполняем приведенный выше код, он дает следующий результат —
Df Sum Sq Mean Sq F value Pr(>F) hp 1 678.4 678.4 80.15 7.63e-10 *** am 1 202.2 202.2 23.89 3.46e-05 *** Residuals 29 245.4 8.5 --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Этот результат показывает, что мощность в лошадиных силах и тип трансмиссии оказывают существенное влияние на мили на галлон, поскольку значение p в обоих случаях составляет менее 0,05.
Сравнивая две модели
Теперь мы можем сравнить две модели, чтобы сделать вывод, является ли взаимодействие переменных действительно незначительным. Для этого мы используем функцию anova () .
# Get the dataset. input <- mtcars # Create the regression models. result1 <- aov(mpg~hp*am,data = input) result2 <- aov(mpg~hp+am,data = input) # Compare the two models. print(anova(result1,result2))
Когда мы выполняем приведенный выше код, он дает следующий результат —
Model 1: mpg ~ hp * am Model 2: mpg ~ hp + am Res.Df RSS Df Sum of Sq F Pr(>F) 1 28 245.43 2 29 245.44 -1 -0.0052515 6e-04 0.9806
Поскольку значение р больше 0,05, мы заключаем, что взаимодействие между мощностью в лошадиных силах и типом передачи не является значительным. Таким образом, пробег на галлон будет аналогичным образом зависеть от мощности автомобиля как в автоматическом, так и в ручном режиме.
R — Анализ временных рядов
Временной ряд — это ряд точек данных, в которых каждая точка данных связана с временной меткой. Простым примером является цена акции на фондовом рынке в разные моменты времени в данный день. Другим примером является количество осадков в регионе в разные месяцы года. Язык R использует множество функций для создания, манипулирования и отображения данных временных рядов. Данные для временного ряда хранятся в объекте R, который называется объектом временного ряда . Это также объект данных R, такой как вектор или фрейм данных.
Объект временного ряда создается с помощью функции ts () .
Синтаксис
Основной синтаксис функции ts () в анализе временных рядов —
timeseries.object.name <- ts(data, start, end, frequency)
Ниже приведено описание используемых параметров:
-
Данные — это вектор или матрица, содержащая значения, используемые во временных рядах.
-
start указывает время начала первого наблюдения во временных рядах.
-
end указывает время окончания последнего наблюдения во временных рядах.
-
частота указывает количество наблюдений за единицу времени.
Данные — это вектор или матрица, содержащая значения, используемые во временных рядах.
start указывает время начала первого наблюдения во временных рядах.
end указывает время окончания последнего наблюдения во временных рядах.
частота указывает количество наблюдений за единицу времени.
Кроме параметра «данные» все остальные параметры являются необязательными.
пример
Рассмотрим данные о годовом количестве осадков в месте, начиная с января 2012 года. Мы создаем объект временного ряда R на период 12 месяцев и наносим его на график.
# Get the data points in form of a R vector. rainfall <- c(799,1174.8,865.1,1334.6,635.4,918.5,685.5,998.6,784.2,985,882.8,1071) # Convert it to a time series object. rainfall.timeseries <- ts(rainfall,start = c(2012,1),frequency = 12) # Print the timeseries data. print(rainfall.timeseries) # Give the chart file a name. png(file = "rainfall.png") # Plot a graph of the time series. plot(rainfall.timeseries) # Save the file. dev.off()
Когда мы выполняем приведенный выше код, он дает следующий результат и диаграмму —
Jan Feb Mar Apr May Jun Jul Aug Sep
2012 799.0 1174.8 865.1 1334.6 635.4 918.5 685.5 998.6 784.2
Oct Nov Dec
2012 985.0 882.8 1071.0
Диаграмма временного ряда —
Разные интервалы времени
Значение параметра частоты в функции ts () определяет интервалы времени, в которые измеряются точки данных. Значение 12 указывает, что временной ряд составляет 12 месяцев. Другие значения и их значение, как показано ниже —
-
частота = 12 привязок точек данных за каждый месяц года.
-
частота = 4 привязки точек данных за каждый квартал года.
-
частота = 6 привязок точек данных за каждые 10 минут часа.
-
частота = 24 * 6 привязок точек данных для каждых 10 минут дня.
частота = 12 привязок точек данных за каждый месяц года.
частота = 4 привязки точек данных за каждый квартал года.
частота = 6 привязок точек данных за каждые 10 минут часа.
частота = 24 * 6 привязок точек данных для каждых 10 минут дня.
Несколько временных рядов
Мы можем построить несколько временных рядов на одном графике, объединив оба ряда в матрицу.
# Get the data points in form of a R vector.
rainfall1 <- c(799,1174.8,865.1,1334.6,635.4,918.5,685.5,998.6,784.2,985,882.8,1071)
rainfall2 <-
c(655,1306.9,1323.4,1172.2,562.2,824,822.4,1265.5,799.6,1105.6,1106.7,1337.8)
# Convert them to a matrix.
combined.rainfall <- matrix(c(rainfall1,rainfall2),nrow = 12)
# Convert it to a time series object.
rainfall.timeseries <- ts(combined.rainfall,start = c(2012,1),frequency = 12)
# Print the timeseries data.
print(rainfall.timeseries)
# Give the chart file a name.
png(file = "rainfall_combined.png")
# Plot a graph of the time series.
plot(rainfall.timeseries, main = "Multiple Time Series")
# Save the file.
dev.off()
Когда мы выполняем приведенный выше код, он дает следующий результат и диаграмму —
Series 1 Series 2 Jan 2012 799.0 655.0 Feb 2012 1174.8 1306.9 Mar 2012 865.1 1323.4 Apr 2012 1334.6 1172.2 May 2012 635.4 562.2 Jun 2012 918.5 824.0 Jul 2012 685.5 822.4 Aug 2012 998.6 1265.5 Sep 2012 784.2 799.6 Oct 2012 985.0 1105.6 Nov 2012 882.8 1106.7 Dec 2012 1071.0 1337.8
Диаграмма с несколькими временными рядами —
R — нелинейная наименьшая площадь
При моделировании данных реального мира для регрессионного анализа мы наблюдаем, что редко случается, что уравнение модели представляет собой линейное уравнение, дающее линейный график. В большинстве случаев уравнение модели данных реального мира включает в себя математические функции более высокой степени, такие как показатель степени 3 или функция sin. В таком случае график модели дает кривую, а не линию. Целью как линейной, так и нелинейной регрессии является настройка значений параметров модели, чтобы найти линию или кривую, которая ближе всего подходит к вашим данным. Найдя эти значения, мы сможем оценить переменную отклика с хорошей точностью.
В регрессии наименьших квадратов мы устанавливаем регрессионную модель, в которой сумма квадратов вертикальных расстояний различных точек от кривой регрессии минимизируется. Обычно мы начинаем с определенной модели и принимаем некоторые значения для коэффициентов. Затем мы применяем функцию nls () для R, чтобы получить более точные значения вместе с доверительными интервалами.
Синтаксис
Основной синтаксис для создания нелинейного критерия наименьших квадратов в R —
nls(formula, data, start)
Ниже приведено описание используемых параметров:
-
формула — это формула нелинейной модели, включающая переменные и параметры.
-
Данные — это фрейм данных, используемый для оценки переменных в формуле.
-
start — именованный список или именованный числовой вектор начальных оценок.
формула — это формула нелинейной модели, включающая переменные и параметры.
Данные — это фрейм данных, используемый для оценки переменных в формуле.
start — именованный список или именованный числовой вектор начальных оценок.
пример
Рассмотрим нелинейную модель с предположением начальных значений ее коэффициентов. Далее мы увидим, каковы доверительные интервалы этих предполагаемых значений, чтобы мы могли судить, насколько хорошо эти значения попадают в модель.
Итак, давайте рассмотрим приведенное ниже уравнение для этой цели —
a = b1*x^2+b2
Давайте предположим, что начальные коэффициенты равны 1 и 3, и поместим эти значения в функцию nls ().
xvalues <- c(1.6,2.1,2,2.23,3.71,3.25,3.4,3.86,1.19,2.21) yvalues <- c(5.19,7.43,6.94,8.11,18.75,14.88,16.06,19.12,3.21,7.58) # Give the chart file a name. png(file = "nls.png") # Plot these values. plot(xvalues,yvalues) # Take the assumed values and fit into the model. model <- nls(yvalues ~ b1*xvalues^2+b2,start = list(b1 = 1,b2 = 3)) # Plot the chart with new data by fitting it to a prediction from 100 data points. new.data <- data.frame(xvalues = seq(min(xvalues),max(xvalues),len = 100)) lines(new.data$xvalues,predict(model,newdata = new.data)) # Save the file. dev.off() # Get the sum of the squared residuals. print(sum(resid(model)^2)) # Get the confidence intervals on the chosen values of the coefficients. print(confint(model))
Когда мы выполняем приведенный выше код, он дает следующий результат —
[1] 1.081935
Waiting for profiling to be done...
2.5% 97.5%
b1 1.137708 1.253135
b2 1.497364 2.496484
Можно сделать вывод, что значение b1 ближе к 1, а значение b2 ближе к 2, а не к 3.
R — Дерево решений
Дерево решений — это график, представляющий варианты и их результаты в виде дерева. Узлы на графике представляют событие или выбор, а края графика представляют правила или условия принятия решения. В основном используется в приложениях машинного обучения и интеллектуального анализа данных, использующих R.
Примерами использования решения могут быть: прогнозирование электронной почты как спама или не спама, прогнозирование опухоли злокачественного или прогнозирование ссуды как хорошего или плохого кредитного риска на основе факторов в каждом из них. Обычно создается модель с данными наблюдений, также называемыми данными обучения. Затем набор проверочных данных используется для проверки и улучшения модели. R имеет пакеты, которые используются для создания и визуализации деревьев решений. Для нового набора переменных-предикторов мы используем эту модель, чтобы прийти к решению относительно категории (да / нет, спам / не спам) данных.
Пакет R «party» используется для создания деревьев решений.
Установить пакет R
Используйте приведенную ниже команду в консоли R для установки пакета. Вы также должны установить зависимые пакеты, если таковые имеются.
install.packages("party")
Пакет «party» имеет функцию ctree (), которая используется для создания и анализа дерева решений.
Синтаксис
Основной синтаксис для создания дерева решений в R —
ctree(formula, data)
Ниже приведено описание используемых параметров:
-
формула — это формула, описывающая предиктор и переменные ответа.
-
data — имя используемого набора данных.
формула — это формула, описывающая предиктор и переменные ответа.
data — имя используемого набора данных.
Входные данные
Мы будем использовать встроенный набор данных R с именем readingSkills для создания дерева решений. Он описывает оценку чьего-либо навыка чтения, если мы знаем переменные «возраст», «размер обуви», «оценка» и то, является ли человек носителем языка или нет.
Вот пример данных.
# Load the party package. It will automatically load other # dependent packages. library(party) # Print some records from data set readingSkills. print(head(readingSkills))
Когда мы выполняем приведенный выше код, он дает следующий результат и диаграмму —
nativeSpeaker age shoeSize score 1 yes 5 24.83189 32.29385 2 yes 6 25.95238 36.63105 3 no 11 30.42170 49.60593 4 yes 7 28.66450 40.28456 5 yes 11 31.88207 55.46085 6 yes 10 30.07843 52.83124 Loading required package: methods Loading required package: grid ............................... ...............................
пример
Мы будем использовать функцию ctree (), чтобы создать дерево решений и увидеть его график.
# Load the party package. It will automatically load other # dependent packages. library(party) # Create the input data frame. input.dat <- readingSkills[c(1:105),] # Give the chart file a name. png(file = "decision_tree.png") # Create the tree. output.tree <- ctree( nativeSpeaker ~ age + shoeSize + score, data = input.dat) # Plot the tree. plot(output.tree) # Save the file. dev.off()
Когда мы выполняем приведенный выше код, он дает следующий результат —
null device
1
Loading required package: methods
Loading required package: grid
Loading required package: mvtnorm
Loading required package: modeltools
Loading required package: stats4
Loading required package: strucchange
Loading required package: zoo
Attaching package: ‘zoo’
The following objects are masked from ‘package:base’:
as.Date, as.Date.numeric
Loading required package: sandwich
Заключение
Из дерева решений, показанного выше, мы можем сделать вывод, что любой, чей уровень чтения по навыкам чтения менее 38,3, а возраст более 6 лет, не является носителем языка.
R — Случайный Лес
При подходе со случайным лесом создается большое количество деревьев решений. Каждое наблюдение подается в каждое дерево решений. Наиболее общий результат для каждого наблюдения используется в качестве конечного результата. Новое наблюдение подается во все деревья и получает большинство голосов для каждой модели классификации.
Оценка ошибок сделана для случаев, которые не использовались при построении дерева. Это называется оценкой ошибки OOB (Out-of-bag), которая указывается в процентах.
Пакет R «randomForest» используется для создания случайных лесов.
Установить пакет R
Используйте приведенную ниже команду в консоли R для установки пакета. Вы также должны установить зависимые пакеты, если таковые имеются.
install.packages("randomForest)
Пакет randomForest имеет функцию randomForest (), которая используется для создания и анализа случайных лесов.
Синтаксис
Основной синтаксис для создания случайного леса в R —
randomForest(formula, data)
Ниже приведено описание используемых параметров:
-
формула — это формула, описывающая предиктор и переменные ответа.
-
data — имя используемого набора данных.
формула — это формула, описывающая предиктор и переменные ответа.
data — имя используемого набора данных.
Входные данные
Мы будем использовать встроенный набор данных R с именем readingSkills для создания дерева решений. Он описывает оценку чьего-либо навыка чтения, если мы знаем переменные «возраст», «размер обуви», «оценка» и то, является ли человек носителем языка.
Вот пример данных.
# Load the party package. It will automatically load other # required packages. library(party) # Print some records from data set readingSkills. print(head(readingSkills))
Когда мы выполняем приведенный выше код, он дает следующий результат и диаграмму —
nativeSpeaker age shoeSize score 1 yes 5 24.83189 32.29385 2 yes 6 25.95238 36.63105 3 no 11 30.42170 49.60593 4 yes 7 28.66450 40.28456 5 yes 11 31.88207 55.46085 6 yes 10 30.07843 52.83124 Loading required package: methods Loading required package: grid ............................... ...............................
пример
Мы будем использовать функцию randomForest (), чтобы создать дерево решений и увидеть его график.
# Load the party package. It will automatically load other
# required packages.
library(party)
library(randomForest)
# Create the forest.
output.forest <- randomForest(nativeSpeaker ~ age + shoeSize + score,
data = readingSkills)
# View the forest results.
print(output.forest)
# Importance of each predictor.
print(importance(fit,type = 2))
Когда мы выполняем приведенный выше код, он дает следующий результат —
Call:
randomForest(formula = nativeSpeaker ~ age + shoeSize + score,
data = readingSkills)
Type of random forest: classification
Number of trees: 500
No. of variables tried at each split: 1
OOB estimate of error rate: 1%
Confusion matrix:
no yes class.error
no 99 1 0.01
yes 1 99 0.01
MeanDecreaseGini
age 13.95406
shoeSize 18.91006
score 56.73051
Заключение
Из приведенного выше случайного леса мы можем сделать вывод, что размер обуви и оценка являются важными факторами, определяющими, является ли кто-то носителем языка или нет. Также модель имеет только 1% погрешности, что означает, что мы можем прогнозировать с точностью 99%.
R — Анализ выживания
Анализ выживания имеет дело с предсказанием времени, когда определенное событие произойдет. Это также известно как анализ времени отказа или анализ времени до смерти. Например, прогнозирование количества дней, в течение которых человек с раком выживет, или прогнозирование времени, когда механическая система выйдет из строя.
Пакет R под названием « выживание» используется для анализа выживаемости. Этот пакет содержит функцию Surv (), которая принимает входные данные в виде формулы R и создает объект выживания среди выбранных переменных для анализа. Затем мы используем функцию Survfit (), чтобы создать график для анализа.
Установить пакет
install.packages("survival")
Синтаксис
Основной синтаксис для создания анализа выживаемости в R —
Surv(time,event) survfit(formula)
Ниже приведено описание используемых параметров:
-
время — время наблюдения до наступления события.
-
Событие указывает на состояние возникновения ожидаемого события.
-
формула — это отношение между переменными предиктора.
время — время наблюдения до наступления события.
Событие указывает на состояние возникновения ожидаемого события.
формула — это отношение между переменными предиктора.
пример
Мы рассмотрим набор данных с именем «pbc», присутствующий в пакетах выживания, установленных выше. Он описывает данные о выживаемости людей с первичным билиарным циррозом печени. Среди множества столбцов, представленных в наборе данных, мы в первую очередь занимаемся полями «время» и «статус». Время представляет собой количество дней между регистрацией пациента и более ранним событием между пациентом, получающим трансплантацию печени, или смертью пациента.
# Load the library.
library("survival")
# Print first few rows.
print(head(pbc))
Когда мы выполняем приведенный выше код, он дает следующий результат и диаграмму —
id time status trt age sex ascites hepato spiders edema bili chol 1 1 400 2 1 58.76523 f 1 1 1 1.0 14.5 261 2 2 4500 0 1 56.44627 f 0 1 1 0.0 1.1 302 3 3 1012 2 1 70.07255 m 0 0 0 0.5 1.4 176 4 4 1925 2 1 54.74059 f 0 1 1 0.5 1.8 244 5 5 1504 1 2 38.10541 f 0 1 1 0.0 3.4 279 6 6 2503 2 2 66.25873 f 0 1 0 0.0 0.8 248 albumin copper alk.phos ast trig platelet protime stage 1 2.60 156 1718.0 137.95 172 190 12.2 4 2 4.14 54 7394.8 113.52 88 221 10.6 3 3 3.48 210 516.0 96.10 55 151 12.0 4 4 2.54 64 6121.8 60.63 92 183 10.3 4 5 3.53 143 671.0 113.15 72 136 10.9 3 6 3.98 50 944.0 93.00 63 NA 11.0 3
Из приведенных выше данных мы рассматриваем время и статус для нашего анализа.
Применение функций Surv () и Survfit ()
Теперь мы переходим к применению функции Surv () к указанному выше набору данных и создаем график, который покажет тренд.
# Load the library.
library("survival")
# Create the survival object.
survfit(Surv(pbc$time,pbc$status == 2)~1)
# Give the chart file a name.
png(file = "survival.png")
# Plot the graph.
plot(survfit(Surv(pbc$time,pbc$status == 2)~1))
# Save the file.
dev.off()
Когда мы выполняем приведенный выше код, он дает следующий результат и диаграмму —
Call: survfit(formula = Surv(pbc$time, pbc$status == 2) ~ 1)
n events median 0.95LCL 0.95UCL
418 161 3395 3090 3853
Тенденция на приведенном выше графике помогает нам прогнозировать вероятность выживания в конце определенного количества дней.
R — тест хи-квадрат
Критерий хи-квадрат — это статистический метод определения значимой корреляции между двумя категориальными переменными. Обе эти переменные должны быть из одной популяции, и они должны быть категоричными, как — Да / Нет, Мужской / Женский, Красный / Зеленый и т. Д.
Например, мы можем создать набор данных с наблюдениями за покупателями мороженого и попытаться соотнести пол человека с ароматом мороженого, которое они предпочитают. Если корреляция найдена, мы можем планировать соответствующий запас вкусов, зная количество людей, посещающих их.
Синтаксис
Функция, используемая для выполнения теста хи-квадрат: chisq.test () .
Основной синтаксис для создания теста хи-квадрат в R —
chisq.test(data)
Ниже приведено описание используемых параметров:
-
данные — это данные в виде таблицы, содержащей значение счетчика переменных в наблюдении.
данные — это данные в виде таблицы, содержащей значение счетчика переменных в наблюдении.
пример
Мы возьмем данные Cars93 в библиотеке «MASS», которая представляет продажи различных моделей автомобилей в 1993 году.
library("MASS")
print(str(Cars93))
Когда мы выполняем приведенный выше код, он дает следующий результат —
'data.frame': 93 obs. of 27 variables: $ Manufacturer : Factor w/ 32 levels "Acura","Audi",..: 1 1 2 2 3 4 4 4 4 5 ... $ Model : Factor w/ 93 levels "100","190E","240",..: 49 56 9 1 6 24 54 74 73 35 ... $ Type : Factor w/ 6 levels "Compact","Large",..: 4 3 1 3 3 3 2 2 3 2 ... $ Min.Price : num 12.9 29.2 25.9 30.8 23.7 14.2 19.9 22.6 26.3 33 ... $ Price : num 15.9 33.9 29.1 37.7 30 15.7 20.8 23.7 26.3 34.7 ... $ Max.Price : num 18.8 38.7 32.3 44.6 36.2 17.3 21.7 24.9 26.3 36.3 ... $ MPG.city : int 25 18 20 19 22 22 19 16 19 16 ... $ MPG.highway : int 31 25 26 26 30 31 28 25 27 25 ... $ AirBags : Factor w/ 3 levels "Driver & Passenger",..: 3 1 2 1 2 2 2 2 2 2 ... $ DriveTrain : Factor w/ 3 levels "4WD","Front",..: 2 2 2 2 3 2 2 3 2 2 ... $ Cylinders : Factor w/ 6 levels "3","4","5","6",..: 2 4 4 4 2 2 4 4 4 5 ... $ EngineSize : num 1.8 3.2 2.8 2.8 3.5 2.2 3.8 5.7 3.8 4.9 ... $ Horsepower : int 140 200 172 172 208 110 170 180 170 200 ... $ RPM : int 6300 5500 5500 5500 5700 5200 4800 4000 4800 4100 ... $ Rev.per.mile : int 2890 2335 2280 2535 2545 2565 1570 1320 1690 1510 ... $ Man.trans.avail : Factor w/ 2 levels "No","Yes": 2 2 2 2 2 1 1 1 1 1 ... $ Fuel.tank.capacity: num 13.2 18 16.9 21.1 21.1 16.4 18 23 18.8 18 ... $ Passengers : int 5 5 5 6 4 6 6 6 5 6 ... $ Length : int 177 195 180 193 186 189 200 216 198 206 ... $ Wheelbase : int 102 115 102 106 109 105 111 116 108 114 ... $ Width : int 68 71 67 70 69 69 74 78 73 73 ... $ Turn.circle : int 37 38 37 37 39 41 42 45 41 43 ... $ Rear.seat.room : num 26.5 30 28 31 27 28 30.5 30.5 26.5 35 ... $ Luggage.room : int 11 15 14 17 13 16 17 21 14 18 ... $ Weight : int 2705 3560 3375 3405 3640 2880 3470 4105 3495 3620 ... $ Origin : Factor w/ 2 levels "USA","non-USA": 2 2 2 2 2 1 1 1 1 1 ... $ Make : Factor w/ 93 levels "Acura Integra",..: 1 2 4 3 5 6 7 9 8 10 ...
Приведенный выше результат показывает, что набор данных имеет много переменных фактора, которые можно рассматривать как категориальные переменные. Для нашей модели рассмотрим переменные «Подушки безопасности» и «Тип». Здесь мы стремимся выяснить любую существенную корреляцию между типами продаваемого автомобиля и типом подушек безопасности, которые он имеет. Если наблюдается корреляция, мы можем оценить, какие типы автомобилей могут продаваться лучше с какими типами подушек безопасности.
# Load the library.
library("MASS")
# Create a data frame from the main data set.
car.data <- data.frame(Cars93$AirBags, Cars93$Type)
# Create a table with the needed variables.
car.data = table(Cars93$AirBags, Cars93$Type)
print(car.data)
# Perform the Chi-Square test.
print(chisq.test(car.data))
Когда мы выполняем приведенный выше код, он дает следующий результат —
Compact Large Midsize Small Sporty Van
Driver & Passenger 2 4 7 0 3 0
Driver only 9 7 11 5 8 3
None 5 0 4 16 3 6
Pearson's Chi-squared test
data: car.data
X-squared = 33.001, df = 10, p-value = 0.0002723
Warning message:
In chisq.test(car.data) : Chi-squared approximation may be incorrect
Заключение
Результат показывает значение p менее 0,05, что указывает на корреляцию строк.