В этом руководстве мы шаг за шагом проведем вас по установке Apache Hadoop на Linux-систему (Ubuntu). Это 2 части процесса
Есть 2 предпосылки
- У вас должна быть установлена и запущена Ubuntu
- У вас должна быть установлена Java.
Часть 1) Скачать и установить Hadoop
Шаг 1) Добавьте пользователя системы Hadoop с помощью команды ниже
sudo addgroup hadoop_

sudo adduser --ingroup hadoop_ hduser_
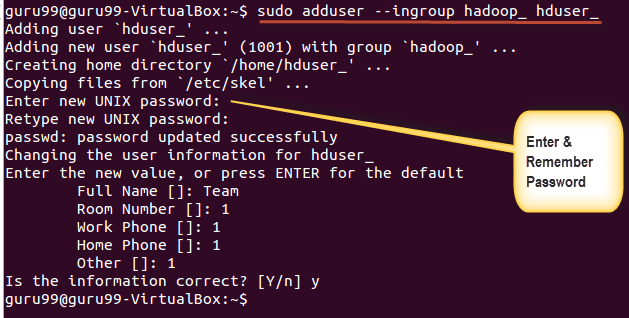
Введите свой пароль, имя и другие данные.
ПРИМЕЧАНИЕ. Существует вероятность возникновения нижеуказанной ошибки в процессе установки и настройки.
«hduser отсутствует в файле sudoers. Об этом инциденте будет сообщено».

Эта ошибка может быть решена при входе в систему как пользователь root

Выполнить команду
sudo adduser hduser_ sudo

Re-login as hduser_

Шаг 2) Настройте SSH
Для управления узлами в кластере Hadoop требуется доступ по SSH
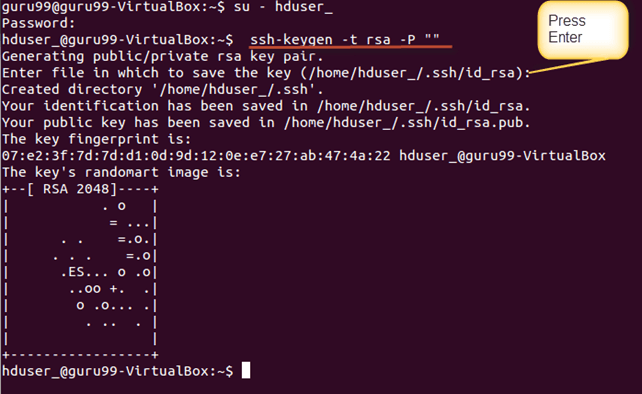
Сначала переключите пользователя, введите следующую команду
su - hduser_

Эта команда создаст новый ключ.
ssh-keygen -t rsa -P ""
Включите SSH доступ к локальной машине, используя этот ключ.
cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys

Теперь проверьте настройку SSH, подключившись к localhost как пользователь ‘hduser’.
ssh localhost
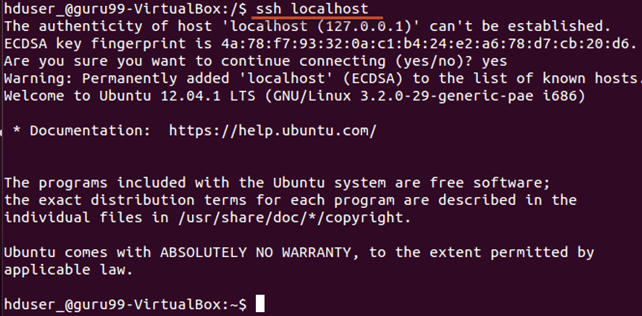
Примечание. Обратите внимание: если вы видите ниже ошибку в ответ на ‘ssh localhost’, есть вероятность, что SSH не доступен в этой системе.

Чтобы решить это —
Очистить SSH с помощью,
sudo apt-get purge openssh-server
Рекомендуется производить чистку перед началом установки

Установите SSH с помощью команды
sudo apt-get install openssh-server

Шаг 3) Следующим шагом является загрузка Hadoop
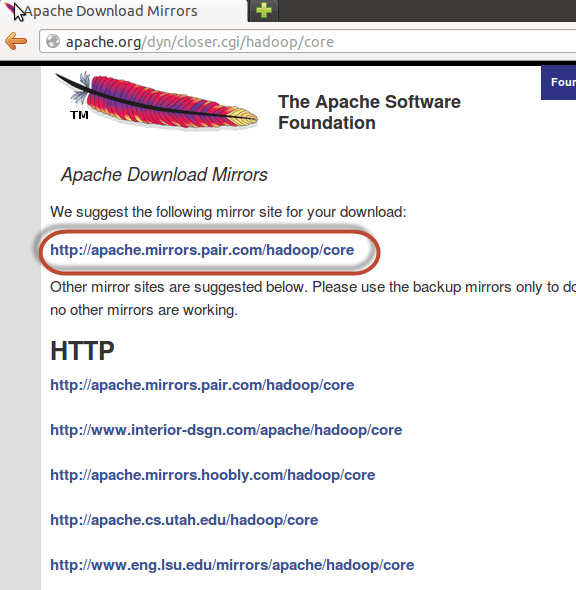
Выберите Стабильный
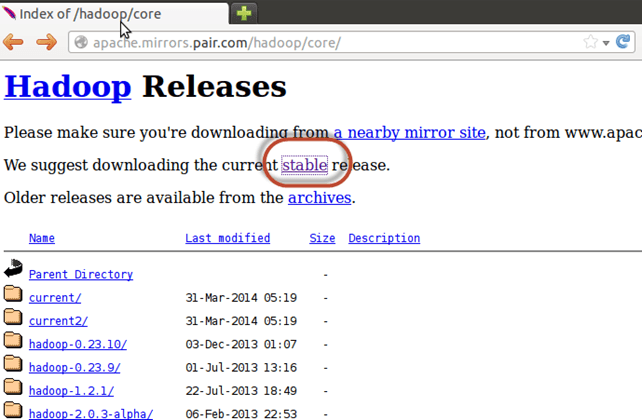
Выберите файл tar.gz (не файл с src)
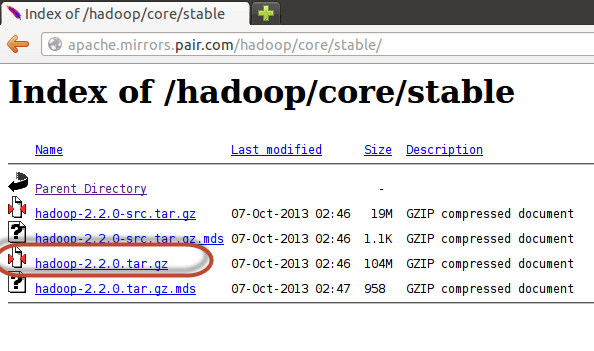
После завершения загрузки перейдите в каталог, содержащий файл tar
Войти,
sudo tar xzf hadoop-2.2.0.tar.gz

Теперь переименуйте hadoop-2.2.0 в hadoop
sudo mv hadoop-2.2.0 hadoop

sudo chown -R hduser_:hadoop_ hadoop

Часть 2) Настройка Hadoop
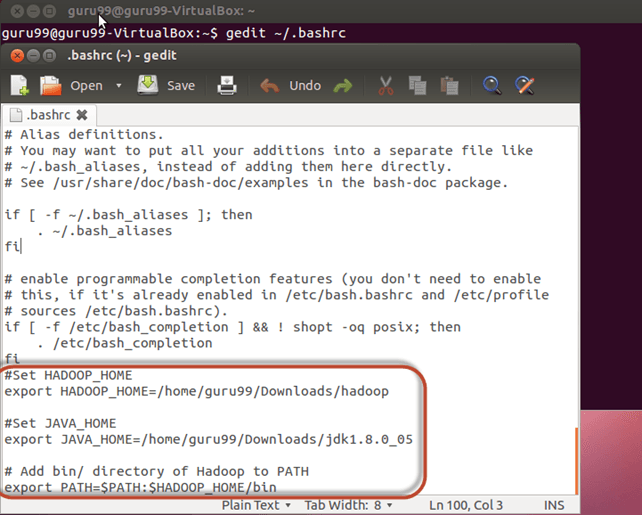
Шаг 1) Изменить файл ~ / .bashrc
Добавьте следующие строки в конец файла ~ / .bashrc
#Set HADOOP_HOME export HADOOP_HOME=<Installation Directory of Hadoop> #Set JAVA_HOME export JAVA_HOME=<Installation Directory of Java> # Add bin/ directory of Hadoop to PATH export PATH=$PATH:$HADOOP_HOME/bin
Теперь создайте эту конфигурацию среды с помощью команды ниже
. ~/.bashrc
Шаг 2) Конфигурации, связанные с HDFS
Установите JAVA_HOME внутри файла $ HADOOP_HOME / etc / hadoop / hadoop-env.sh
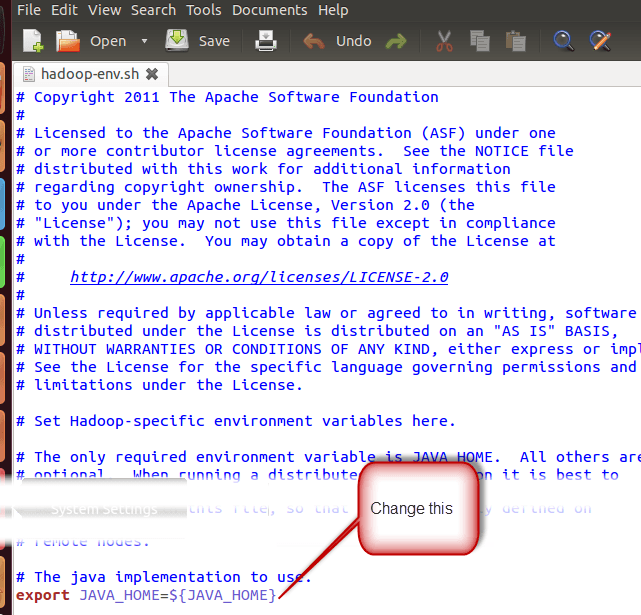
С

В $ HADOOP_HOME / etc / hadoop / core-site.xml есть два параметра, которые нужно установить:
1. ‘hadoop.tmp.dir’ — Used to specify a directory which will be used by Hadoop to store its data files.
2. ‘fs.default.name’ — This specifies the default file system.
To set these parameters, open core-site.xml
sudo gedit $HADOOP_HOME/etc/hadoop/core-site.xml

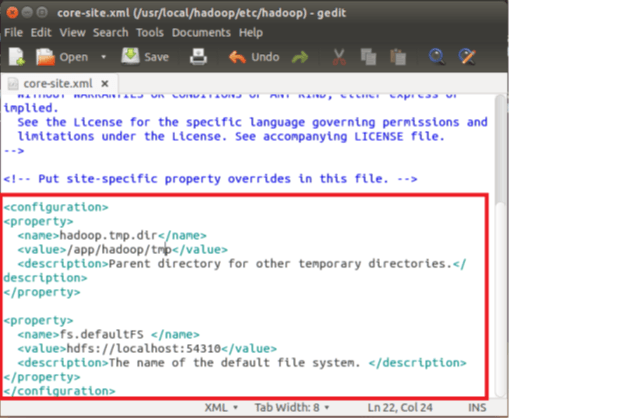
Copy below line in between tags <configuration></configuration>
<property> <name>hadoop.tmp.dir</name> <value>/app/hadoop/tmp</value> <description>Parent directory for other temporary directories.</description> </property> <property> <name>fs.defaultFS </name> <value>hdfs://localhost:54310</value> <description>The name of the default file system. </description> </property>
Перейдите в каталог $ HADOOP_HOME / etc / Hadoop

Теперь создайте каталог, упомянутый в core-site.xml
sudo mkdir -p <Path of Directory used in above setting>

Предоставить разрешения на каталог
sudo chown -R hduser_:Hadoop_ <Path of Directory created in above step>

sudo chmod 750 <Path of Directory created in above step>

Шаг 3) Карта Уменьшить конфигурацию
Прежде чем начать с этими конфигурациями, давайте установим путь HADOOP_HOME
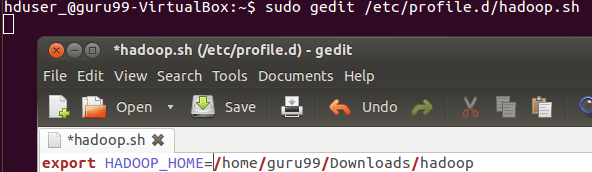
sudo gedit /etc/profile.d/hadoop.sh
И введите
export HADOOP_HOME=/home/guru99/Downloads/Hadoop
Далее введите
sudo chmod +x /etc/profile.d/hadoop.sh

Выйдите из терминала и перезапустите снова
Введите echo $ HADOOP_HOME. Чтобы проверить путь

Теперь скопируйте файлы
sudo cp $HADOOP_HOME/etc/hadoop/mapred-site.xml.template $HADOOP_HOME/etc/hadoop/mapred-site.xml

Откройте файл mapred-site.xml
sudo gedit $HADOOP_HOME/etc/hadoop/mapred-site.xml
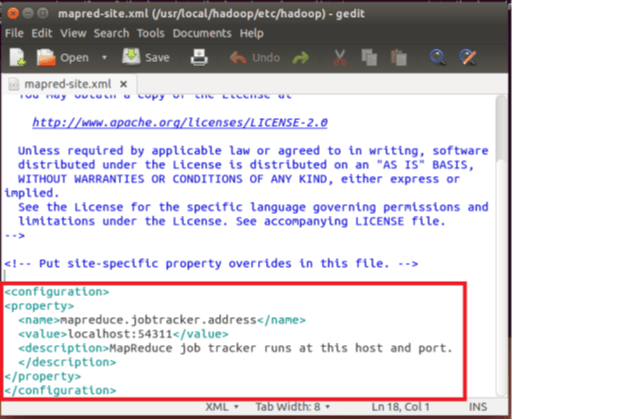
Добавьте ниже строки настройки между тегами <configuration> и </ configuration>
<property> <name>mapreduce.jobtracker.address</name> <value>localhost:54311</value> <description>MapReduce job tracker runs at this host and port. </description> </property>
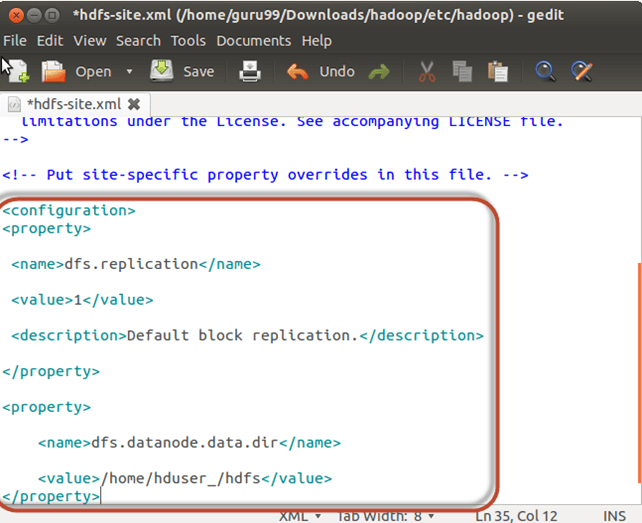
Откройте файл $ HADOOP_HOME / etc / hadoop / hdfs-site.xml, как показано ниже,
sudo gedit $HADOOP_HOME/etc/hadoop/hdfs-site.xml

Добавьте ниже строки настройки между тегами <configuration> и </ configuration>
<property> <name>dfs.replication</name> <value>1</value> <description>Default block replication.</description> </property> <property> <name>dfs.datanode.data.dir</name> <value>/home/hduser_/hdfs</value> </property>
Создайте каталог, указанный в настройках
sudo mkdir -p <Path of Directory used in above setting>
sudo mkdir -p /home/hduser_/hdfs

sudo chown -R hduser_:hadoop_ <Path of Directory created in above step>
sudo chown -R hduser_:hadoop_ /home/hduser_/hdfs

sudo chmod 750 <Path of Directory created in above step>
sudo chmod 750 /home/hduser_/hdfs
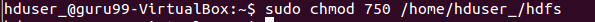
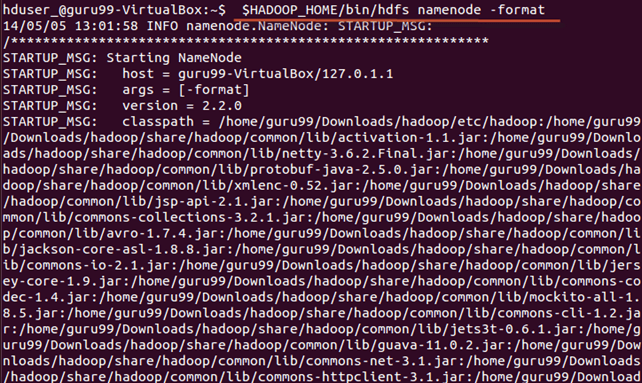
Шаг 4) Перед первым запуском Hadoop отформатируйте HDFS с помощью команды ниже
$HADOOP_HOME/bin/hdfs namenode -format
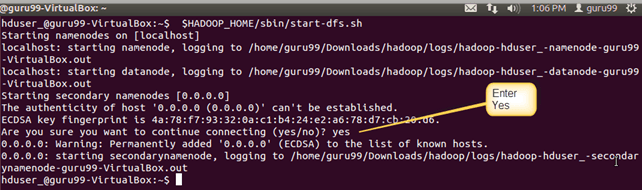
Шаг 5) Запустите кластер Hadoop с одним узлом, используя следующую команду
$HADOOP_HOME/sbin/start-dfs.sh
Вывод вышеуказанной команды
$HADOOP_HOME/sbin/start-yarn.sh

Используя инструмент / команду jps , убедитесь, что все процессы, связанные с Hadoop, запущены или нет.
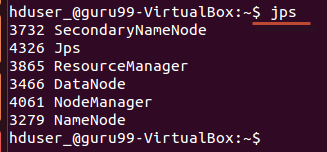
Если Hadoop запущен успешно, то в выводе jps должны отображаться NameNode, NodeManager, ResourceManager, SecondaryNameNode, DataNode.
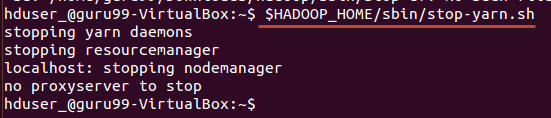
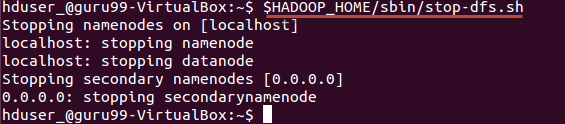
Шаг 6) Остановка Hadoop
$HADOOP_HOME/sbin/stop-dfs.sh
$HADOOP_HOME/sbin/stop-yarn.sh