В этом уроке вы научитесь использовать Hadoop и MapReduce с примером. Используемые входные данные — SalesJan2009.csv . Он содержит информацию о продажах, такую как название продукта, цена, способ оплаты, город, страна клиента и т. Д. Цель состоит в том, чтобы узнать количество продуктов, проданных в каждой стране.
В этом уроке вы узнаете
- Первая программа Hadoop MapReduce
- Объяснение класса SalesMapper
- Объяснение класса SalesCountryReducer
- Объяснение класса SalesCountryDriver
Первая программа Hadoop MapReduce
Убедитесь, что у вас установлен Hadoop. Прежде чем начать с самого процесса, измените пользователя на «hduser» (идентификатор, используемый при настройке Hadoop, вы можете переключиться на идентификатор пользователя, использованный при настройке Hadoop).
su - hduser_

Шаг 1)
Создайте новый каталог с именем MapReduceTutorial
sudo mkdir MapReduceTutorial

Дать разрешения
sudo chmod -R 777 MapReduceTutorial
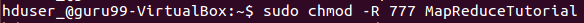
SalesMapper.java
package SalesCountry;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.*;
public class SalesMapper extends MapReduceBase implements Mapper <LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
public void map(LongWritable key, Text value, OutputCollector <Text, IntWritable> output, Reporter reporter) throws IOException {
String valueString = value.toString();
String[] SingleCountryData = valueString.split(",");
output.collect(new Text(SingleCountryData[7]), one);
}
}
SalesCountryReducer.java
package SalesCountry;
import java.io.IOException;
import java.util.*;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.*;
public class SalesCountryReducer extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text t_key, Iterator<IntWritable> values, OutputCollector<Text,IntWritable> output, Reporter reporter) throws IOException {
Text key = t_key;
int frequencyForCountry = 0;
while (values.hasNext()) {
// replace type of value with the actual type of our value
IntWritable value = (IntWritable) values.next();
frequencyForCountry += value.get();
}
output.collect(key, new IntWritable(frequencyForCountry));
}
}
SalesCountryDriver.java
package SalesCountry;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapred.*;
public class SalesCountryDriver {
public static void main(String[] args) {
JobClient my_client = new JobClient();
// Create a configuration object for the job
JobConf job_conf = new JobConf(SalesCountryDriver.class);
// Set a name of the Job
job_conf.setJobName("SalePerCountry");
// Specify data type of output key and value
job_conf.setOutputKeyClass(Text.class);
job_conf.setOutputValueClass(IntWritable.class);
// Specify names of Mapper and Reducer Class
job_conf.setMapperClass(SalesCountry.SalesMapper.class);
job_conf.setReducerClass(SalesCountry.SalesCountryReducer.class);
// Specify formats of the data type of Input and output
job_conf.setInputFormat(TextInputFormat.class);
job_conf.setOutputFormat(TextOutputFormat.class);
// Set input and output directories using command line arguments,
//arg[0] = name of input directory on HDFS, and arg[1] = name of output directory to be created to store the output file.
FileInputFormat.setInputPaths(job_conf, new Path(args[0]));
FileOutputFormat.setOutputPath(job_conf, new Path(args[1]));
my_client.setConf(job_conf);
try {
// Run the job
JobClient.runJob(job_conf);
} catch (Exception e) {
e.printStackTrace();
}
}
}
Проверьте права доступа ко всем этим файлам
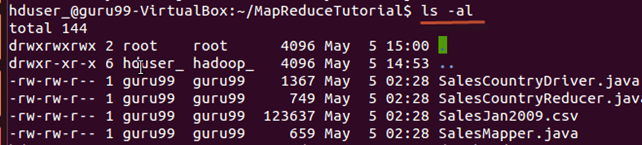
и если разрешения на «чтение» отсутствуют, предоставьте

Шаг 2)
Экспорт classpath
export CLASSPATH="$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.2.0.jar:$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-common-2.2.0.jar:$HADOOP_HOME/share/hadoop/common/hadoop-common-2.2.0.jar:~/MapReduceTutorial/SalesCountry/*:$HADOOP_HOME/lib/*"

Шаг 3)
Компилировать файлы Java (эти файлы присутствуют в каталоге Final-MapReduceHandsOn ). Его файлы классов будут помещены в каталог пакета
javac -d . SalesMapper.java SalesCountryReducer.java SalesCountryDriver.java

Это предупреждение можно смело игнорировать.
Эта компиляция создаст каталог в текущем каталоге с именем пакета, указанным в исходном файле java (т.е. в нашем случае SalesCountry ) и поместит в него все скомпилированные файлы классов.
Шаг 4)
Создать новый файл Manifest.txt
sudo gedit Manifest.txt
добавить следующие строки к нему,
Main-Class: SalesCountry.SalesCountryDriver

SalesCountry.SalesCountryDriver — это имя основного класса. Обратите внимание, что вы должны нажать клавишу ввода в конце этой строки.
Шаг 5)
Создать файл Jar
jar cfm ProductSalePerCountry.jar Manifest.txt SalesCountry/*.class

Убедитесь, что файл JAR создан

Шаг 6)
Запустите Hadoop
$HADOOP_HOME/sbin/start-dfs.sh
$HADOOP_HOME/sbin/start-yarn.sh
Шаг 7)
Скопируйте файл SalesJan2009.csv в ~ / inputMapReduce
Теперь используйте команду ниже, чтобы скопировать ~ / inputMapReduce в HDFS.
$HADOOP_HOME/bin/hdfs dfs -copyFromLocal ~/inputMapReduce /

Мы можем смело игнорировать это предупреждение.
Проверьте, действительно ли файл скопирован или нет.
$HADOOP_HOME/bin/hdfs dfs -ls /inputMapReduce

Шаг 8)
Запустить задание MapReduce
$HADOOP_HOME/bin/hadoop jar ProductSalePerCountry.jar /inputMapReduce /mapreduce_output_sales

Это создаст выходной каталог с именем mapreduce_output_sales в HDFS. Содержимое этого каталога представляет собой файл, содержащий информацию о продажах товаров в каждой стране.
Шаг 9)
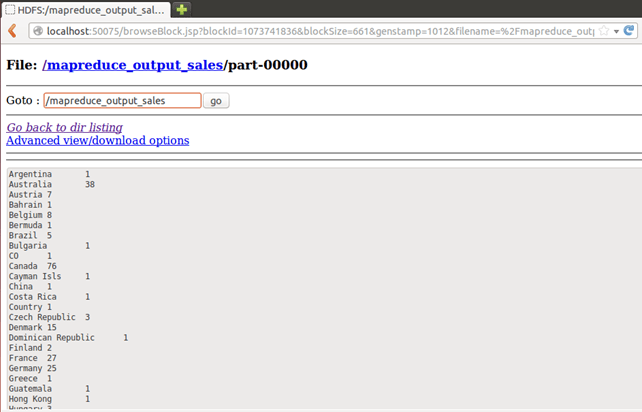
Результат можно увидеть через командный интерфейс как,
$HADOOP_HOME/bin/hdfs dfs -cat /mapreduce_output_sales/part-00000
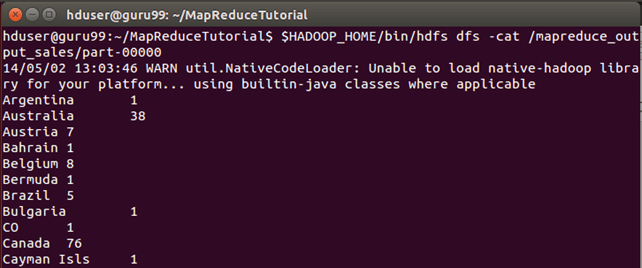
Результаты также можно увидеть через веб-интерфейс, как
Откройте r в веб-браузере.
Теперь выберите «Обзор файловой системы» и перейдите к / mapreduce_output_sales
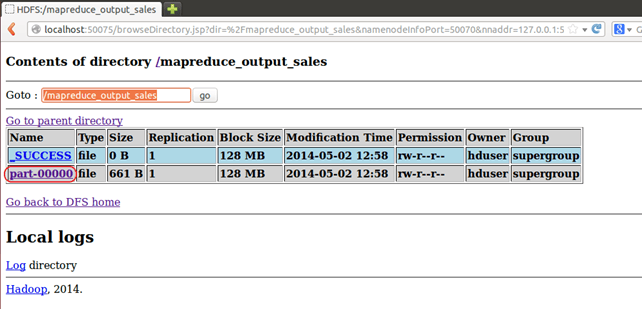
Открытая часть-r-00000
Объяснение класса SalesMapper
В этом разделе мы разберем реализацию класса SalesMapper .
1. Начнем с указания имени пакета для нашего класса. SalesCountry — это название нашего пакета. Обратите внимание, что выходные данные компиляции SalesMapper.class будут помещены в каталог с именем этого пакета: SalesCountry .
Затем мы импортируем библиотечные пакеты.
Ниже моментальных показана реализация SalesMapper class-
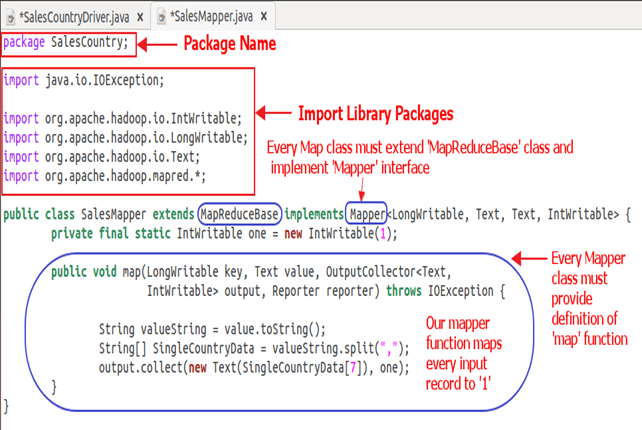
Пример кода Объяснение:
1. Определение класса SalesMapper
Открытый класс SalesMapper расширяет MapReduceBase реализует Mapper <LongWritable, Text, Text, IntWritable> {
Каждый класс mapper должен быть расширен из класса MapReduceBase, и он должен реализовывать интерфейс Mapper .
2. Определение функции «карта»
public void map(LongWritable key,
Text value,
OutputCollector<Text, IntWritable> output,
Reporter reporter) throws IOException
Основная часть класса Mapper — это метод ‘map ()’, который принимает четыре аргумента.
При каждом вызове метода map () передается пара ключ-значение ( «ключ» и «значение» в этом коде).
Метод map () начинается с разделения входного текста, полученного в качестве аргумента. Он использует токенизатор, чтобы разбить эти строки на слова.
String valueString = value.toString();
String[] SingleCountryData = valueString.split(",");
Здесь «,» используется в качестве разделителя.
После этого пара формируется с использованием записи с 7-м индексом массива «SingleCountryData» и значением «1» .
output.collect (новый текст (SingleCountryData [7]), один);
Мы выбираем запись с 7-м индексом, потому что нам нужны данные о стране, и она расположена с 7-м индексом в массиве SingleCountryData .
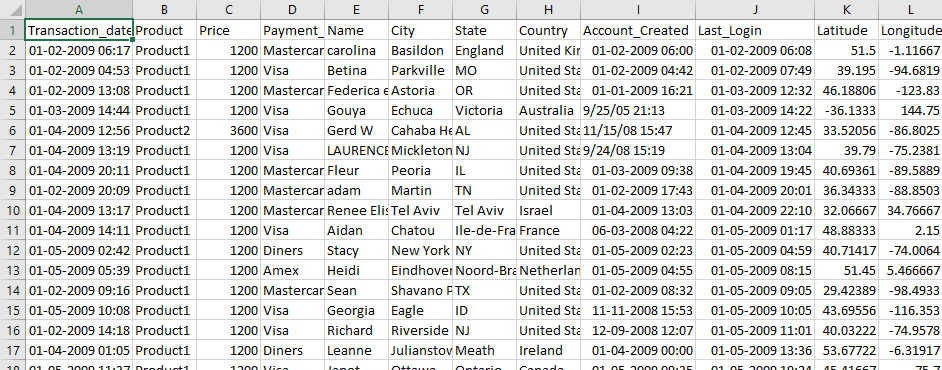
Обратите внимание, что наши входные данные представлены в следующем формате (где Страна находится на 7- м индексе, с 0 в качестве начального индекса) —
Дата транзакции, продукт, цена, тип платежа, имя, город, штат, страна , созданный аккаунт, последний логин, широта, долгота
Выходными данными mapper снова является пара ключ-значение, которая выводится с использованием метода collect () объекта OutputCollector .
Объяснение класса SalesCountryReducer
В этом разделе мы поймем реализацию класса SalesCountryReducer .
1. Начнем с указания имени пакета для нашего класса. SalesCountry — это название нашего пакета. Обратите внимание, что выходные данные компиляции SalesCountryReducer.class будут помещены в каталог с именем этого пакета: SalesCountry .
Затем мы импортируем библиотечные пакеты.
Ниже моментальных показана реализация SalesCountryReducer class-
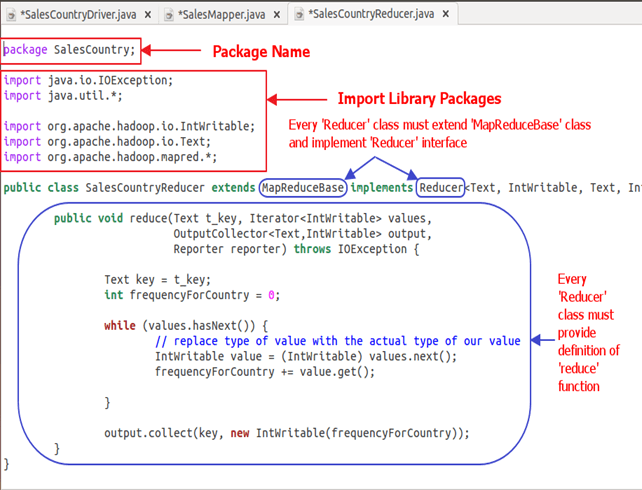
Объяснение кода:
1. Определение класса SalesCountryReducer
открытый класс SalesCountryReducer расширяет MapReduceBase реализует Reducer <Text, IntWritable, Text, IntWritable> {
Здесь первые два типа данных, «Текст» и «IntWritable», являются типом данных ввода значения ключа для редуктора.
Выходные данные маппера представлены в виде <CountryName1, 1>, <CountryName2, 1>. Этот выход преобразователя становится входом для редуктора. Таким образом, чтобы выровнять его тип данных, Text и IntWritable используются здесь как тип данных.
Последние два типа данных, «Текст» и «IntWritable», являются типом данных, сгенерированных редуктором в виде пары ключ-значение.
Каждый класс редуктора должен быть расширен из класса MapReduceBase, и он должен реализовывать интерфейс редуктора .
2. Определение функции уменьшения
public void reduce( Text t_key,
Iterator<IntWritable> values,
OutputCollector<Text,IntWritable> output,
Reporter reporter) throws IOException {
Входные данные для метода redu () — это ключ со списком нескольких значений.
Например, в нашем случае это будет
<Объединенные Арабские Эмираты, 1>, <Объединенные Арабские Эмираты, 1>, <Объединенные Арабские Эмираты, 1>, <Объединенные Арабские Эмираты, 1>, <Объединенные Арабские Эмираты, 1>, <Объединенные Арабские Эмираты, 1>.
Это дается редуктору как <Объединенные Арабские Эмираты, {1,1,1,1,1,1}>
Таким образом, чтобы принять аргументы этой формы, используются первые два типа данных, а именно: Text и Iterator <IntWritable> . Текст — это тип данных ключа, а Iterator <IntWritable> — это тип данных для списка значений для этого ключа.
Следующий аргумент имеет тип OutputCollector <Text, IntWritable>, который собирает выходные данные фазы редуктора.
Метод Redu () начинается с копирования значения ключа и инициализации счетчика частоты до 0.
Текстовый ключ = t_key;
int частотаForCountry = 0;
Затем, используя « а» цикл, мы перебираем список значений , связанных с ключом и рассчитать конечную частоту путем суммирования всех значений.
while (values.hasNext()) {
// replace type of value with the actual type of our value
IntWritable value = (IntWritable) values.next();
frequencyForCountry += value.get();
}
Теперь мы передаем результат на выходной коллектор в виде ключа и полученного подсчета частоты .
Ниже код делает это
output.collect(key, new IntWritable(frequencyForCountry));
Объяснение класса SalesCountryDriver
В этом разделе мы поймем реализацию класса SalesCountryDriver
1. Начнем с указания имени пакета для нашего класса. SalesCountry — это название нашего пакета. Обратите внимание, что выходные данные компиляции SalesCountryDriver.class будут помещены в каталог с именем этого пакета: SalesCountry .
Вот строка, указывающая имя пакета, за которым следует код для импорта библиотечных пакетов.
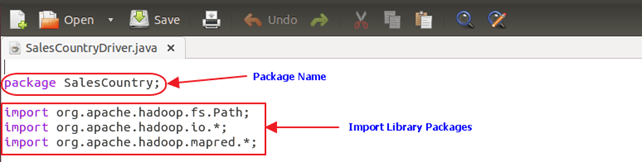
2. Определите класс драйвера, который создаст новое клиентское задание, объект конфигурации и объявит классы Mapper и Reducer.
Класс драйвера отвечает за настройку задания MapReduce для запуска в Hadoop. В этом классе мы указываем имя задания, тип данных ввода / вывода и имена классов мапперов и редукторов .
3. В приведенном ниже фрагменте кода мы устанавливаем входные и выходные каталоги, которые используются для использования входного набора данных и вывода результатов соответственно.
arg [0] и arg [1] являются аргументами командной строки, передаваемыми командой, заданной в MapReduce, т. е.
$ HADOOP_HOME / bin / hadoop jar ProductSalePerCountry.jar / inputMapReduce / mapreduce_output_sales

4. Запустите нашу работу
Ниже кода запускается выполнение задания MapReduce
try {
// Run the job
JobClient.runJob(job_conf);
} catch (Exception e) {
e.printStackTrace();
}