Что такое Join в Mapreduce?
Операция MAPREDUCE JOIN используется для объединения двух больших наборов данных. Однако этот процесс включает в себя написание большого количества кода для выполнения фактической операции соединения. Объединение двух наборов данных начинается со сравнения размера каждого набора данных. Если один набор данных меньше по сравнению с другим набором данных, то меньший набор данных распределяется по каждому узлу данных в кластере.
Как только он распределен, Mapper или Reducer использует меньший набор данных, чтобы выполнить поиск соответствующих записей из большого набора данных, а затем объединить эти записи для формирования выходных записей.
В этом уроке вы узнаете
- Что такое объединение в MapReduce?
- Типы Присоединения
- Как объединить два набора данных: пример MapReduce
- Что такое счетчик в MapReduce?
- Типы счетчиков MapReduce
- Пример счетчиков
Типы Присоединения
В зависимости от места, где выполняется фактическое соединение, это соединение классифицируется как
1. Соединение на стороне карты — когда соединение выполняется картографом, оно называется соединением на стороне карты. В этом типе соединение выполняется до того, как данные фактически будут использованы функцией карты. Обязательно, чтобы входные данные для каждой карты были в форме раздела и были в отсортированном порядке. Также должно быть одинаковое количество разделов, и оно должно быть отсортировано по ключу соединения.
2. Соединение со стороны уменьшения — Когда соединение выполняется редуктором, оно называется соединением со стороны уменьшения. В этом соединении нет необходимости иметь набор данных в структурированной форме (или разделенной).
Здесь обработка на стороне карты выдает ключ соединения и соответствующие кортежи обеих таблиц. В результате этой обработки все кортежи с одним и тем же ключом соединения попадают в один и тот же редуктор, который затем соединяет записи с одним и тем же ключом соединения.
Общий ход процесса изображен на диаграмме ниже.
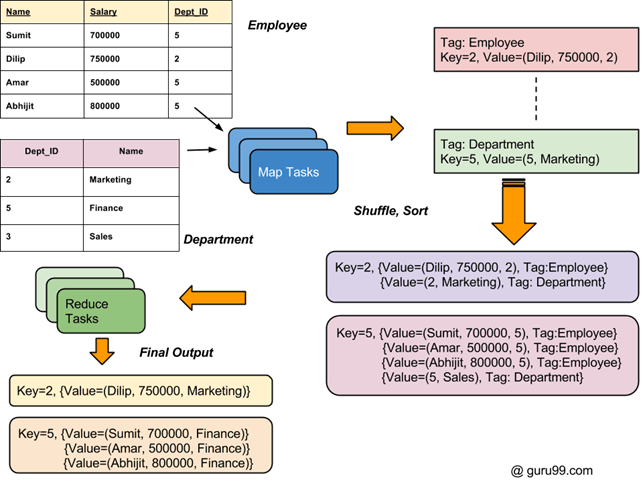
Как объединить два набора данных: пример MapReduce
Есть два набора данных в двух разных файлах (показано ниже). Ключ Dept_ID является общим в обоих файлах. Цель состоит в том, чтобы использовать MapReduce Join для объединения этих файлов.
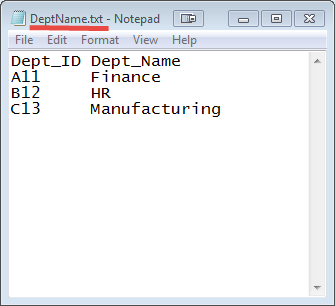
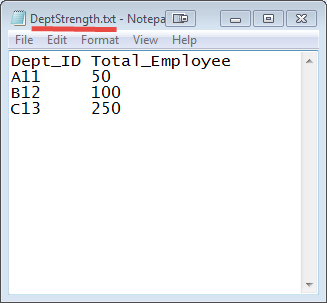
Входные данные: набор входных данных представляет собой текстовый файл, DeptName.txt & DepStrength.txt
Убедитесь, что у вас установлен Hadoop. Прежде чем начать с самого процесса, измените пользователя на «hduser» (идентификатор, используемый при настройке Hadoop, вы можете переключиться на идентификатор пользователя, использованный при настройке Hadoop).
su - hduser_

Шаг 1) Скопируйте ZIP-файл в папку по вашему выбору

Шаг 2) Распакуйте Zip-файл
sudo tar -xvf MapReduceJoin.tar.gz
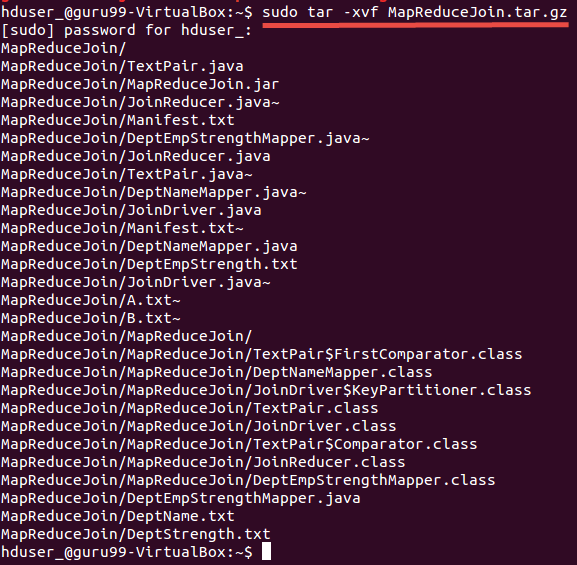
Шаг 3) Перейти в каталог MapReduceJoin /
cd MapReduceJoin/

Шаг 4) Запустите Hadoop
$HADOOP_HOME/sbin/start-dfs.sh
$HADOOP_HOME/sbin/start-yarn.sh

Шаг 5) DeptStrength.txt и DeptName.txt — входные файлы, используемые для этой программы.
Эти файлы необходимо скопировать в HDFS, используя следующую команду:
$HADOOP_HOME/bin/hdfs dfs -copyFromLocal DeptStrength.txt DeptName.txt /

Шаг 6) Запустите программу, используя следующую команду:
$HADOOP_HOME/bin/hadoop jar MapReduceJoin.jar MapReduceJoin/JoinDriver/DeptStrength.txt /DeptName.txt /output_mapreducejoin


Шаг 7) После выполнения выходной файл (с именем ‘part-00000’) будет сохранен в каталоге / output_mapreducejoin на HDFS
Результаты можно увидеть с помощью интерфейса командной строки
$HADOOP_HOME/bin/hdfs dfs -cat /output_mapreducejoin/part-00000

Результаты также можно увидеть через веб-интерфейс, как
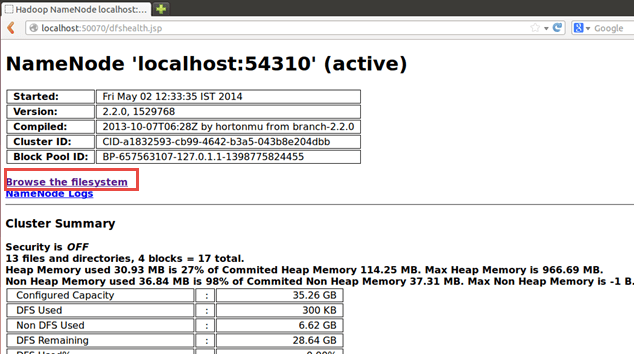
Теперь выберите «Обзор файловой системы» и перейдите к / выходной_mapreducejoin
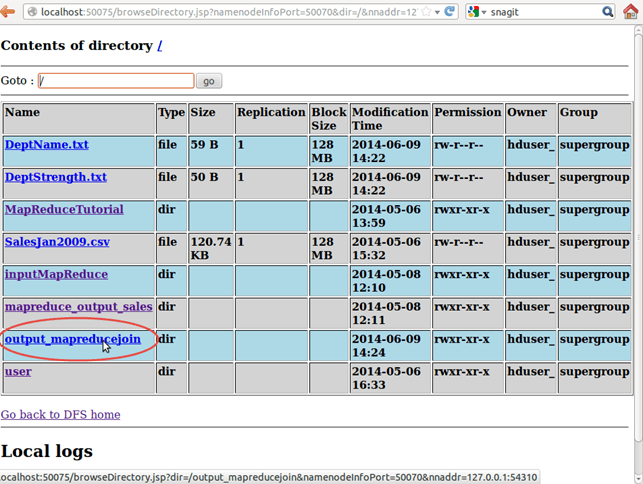
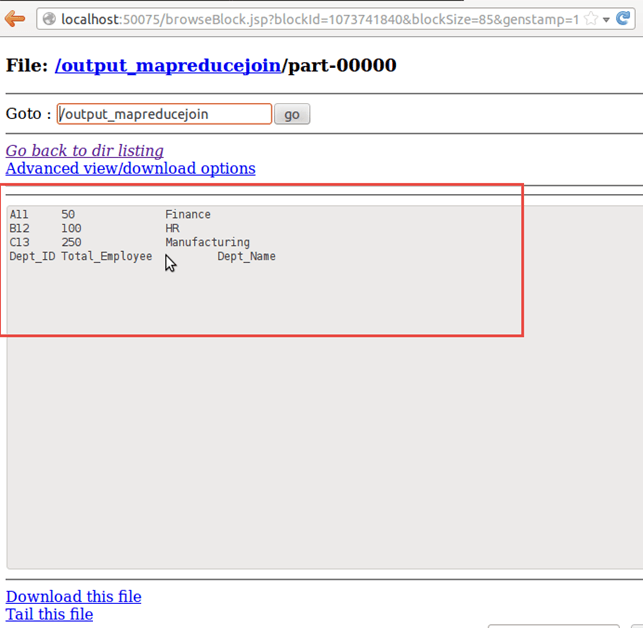
Открытая часть-r-00000

Результаты показаны
ПРИМЕЧАНИЕ. Обратите внимание, что перед запуском этой программы в следующий раз вам необходимо удалить каталог вывода / output_mapreducejoin
$HADOOP_HOME/bin/hdfs dfs -rm -r /output_mapreducejoin
Альтернативой является использование другого имени для выходного каталога.
Что такое счетчик в MapReduce?
Счетчик в MapReduce — это механизм, используемый для сбора статистической информации о задании MapReduce. Эта информация может быть полезна для диагностики проблемы при обработке задания MapReduce. Счетчики аналогичны помещению сообщения журнала в коде карты или уменьшении.
Как правило, эти счетчики определяются в программе (отображение или уменьшение) и увеличиваются во время выполнения, когда происходит конкретное событие или условие (специфичное для этого счетчика). Очень хорошее применение счетчиков — отслеживать действительные и недействительные записи из входного набора данных.
Типы счетчиков MapReduce
Есть в основном 2 типа счетчиков MapReduce
- Встроенные счетчики Hadoop: для каждого задания существует несколько встроенных счетчиков. Ниже представлены встроенные счетчики
- Счетчики задач MapReduce — собирает специфичную для задачи информацию (например, количество входных записей) во время ее выполнения.
- Счетчики FileSystem — собирает информацию, такую как количество байтов, прочитанных или записанных задачей
- Счетчики FileInputFormat — собирает информацию о количестве байтов, прочитанных через FileInputFormat.
- Счетчики FileOutputFormat — собирает информацию о количестве байтов, записанных через FileOutputFormat.
- Счетчики заданий — эти счетчики используются JobTracker. Собранная ими статистика включает, например, количество задач, запущенных для работы.
В дополнение к встроенным счетчикам пользователь может определять свои собственные счетчики, используя аналогичные функции, предоставляемые языками программирования. Например, в Java ‘enum’ используются для определения пользовательских счетчиков.
Пример счетчиков
Пример MapClass со счетчиками для подсчета количества пропущенных и недопустимых значений. Файл входных данных, используемый в этом учебном курсе. Наш набор входных данных представляет собой файл CSV, SalesJan2009.csv
public static class MapClass
extends MapReduceBase
implements Mapper<LongWritable, Text, Text, Text>
{
static enum SalesCounters { MISSING, INVALID };
public void map ( LongWritable key, Text value,
OutputCollector<Text, Text> output,
Reporter reporter) throws IOException
{
//Input string is split using ',' and stored in 'fields' array
String fields[] = value.toString().split(",", -20);
//Value at 4th index is country. It is stored in 'country' variable
String country = fields[4];
//Value at 8th index is sales data. It is stored in 'sales' variable
String sales = fields[8];
if (country.length() == 0) {
reporter.incrCounter(SalesCounters.MISSING, 1);
} else if (sales.startsWith("\"")) {
reporter.incrCounter(SalesCounters.INVALID, 1);
} else {
output.collect(new Text(country), new Text(sales + ",1"));
}
}
}
Выше фрагмент кода показывает пример реализации счетчиков в Map Reduce.
Здесь SalesCounters — это счетчик, определенный с помощью enum . Используется для подсчета входных записей MISSING и INVALID .
Во фрагменте кода, если поле ‘страна’ имеет нулевую длину, его значение отсутствует, и, следовательно, увеличивается соответствующий счетчик SalesCounters.MISSING .
Далее, если поле «продажи» начинается с « тогда», запись считается недействительной. Об этом свидетельствует увеличение счетчика SalesCounters.INVALID.