Что такое HDFS?
HDFS — это распределенная файловая система для хранения очень больших файлов данных, работающая на кластерах стандартного оборудования. Он отказоустойчив, масштабируем и чрезвычайно прост в расширении. Hadoop поставляется в комплекте с HDFS ( распределенные файловые системы Hadoop ).
Когда данные превышают емкость хранилища на одном физическом компьютере, становится необходимым разделить их на несколько отдельных машин. Файловая система, которая управляет конкретными операциями хранения в сети компьютеров, называется распределенной файловой системой. HDFS является одним из таких программ.
В этом уроке мы узнаем,
- Что такое HDFS?
- Архитектура HDFS
- Операция чтения
- Операция записи
- Доступ к HDFS с использованием JAVA API
- Доступ к HDFS с помощью COMMAND-LINE INTERFACE
Архитектура HDFS
Кластер HDFS в основном состоит из NameNode, который управляет метаданными файловой системы, и DataNode, в котором хранятся фактические данные .
-
NameNode: NameNode может рассматриваться как мастер системы. Он поддерживает дерево файловой системы и метаданные для всех файлов и каталогов, присутствующих в системе. Два файла ‘Namespace image’ и ‘edit log’ используются для хранения метаданных. Namenode знает все датододы, содержащие блоки данных для данного файла, однако он не хранит постоянные местоположения блоков. Эта информация восстанавливается каждый раз из датоданных при запуске системы.
-
DataNode: DataNode — это подчиненные устройства, которые находятся на каждой машине в кластере и предоставляют фактическое хранилище. Он отвечает за обслуживание, чтение и запись запросов для клиентов.
Операции чтения / записи в HDFS работают на уровне блоков. Файлы данных в HDFS разбиты на куски размером с блок, которые хранятся как независимые блоки. Размер блока по умолчанию составляет 64 МБ.
HDFS работает на основе концепции репликации данных, при которой создается несколько реплик блоков данных, которые распределяются по узлам по всему кластеру для обеспечения высокой доступности данных в случае сбоя узла.
Ты знаешь? Файл в HDFS, который меньше, чем один блок, не занимает полное хранилище блока.
Операция чтения в HDFS
Запрос на чтение данных обслуживается HDFS, NameNode и DataNode. Давайте назовем читателя «клиентом». Ниже на диаграмме изображена операция чтения файла в Hadoop.
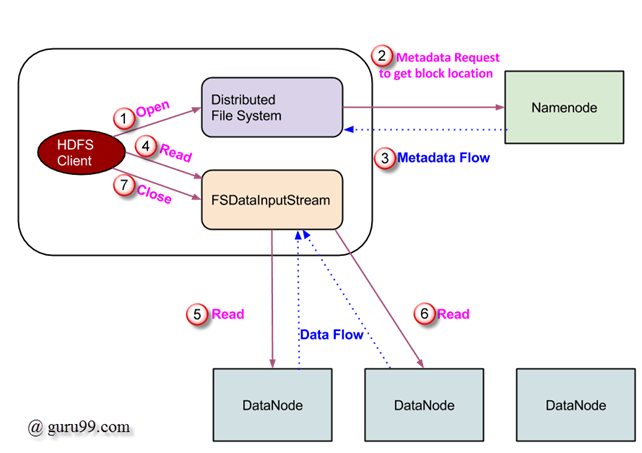
- Клиент инициирует запрос на чтение, вызывая метод open () объекта FileSystem; это объект типа DistributedFileSystem .
- Этот объект подключается к namenode с помощью RPC и получает информацию метаданных, такую как расположение блоков файла. Обратите внимание, что эти адреса являются первыми несколькими блоками файла.
- В ответ на этот запрос метаданных адреса узлов данных, имеющих копию этого блока, возвращаются обратно.
-
После получения адресов узлов данных объект типа FSDataInputStream возвращается клиенту. FSDataInputStream содержит DFSInputStream, который заботится о взаимодействиях с DataNode и NameNode. На шаге 4, показанном на приведенной выше схеме, клиент вызывает метод read (), который заставляет DFSInputStream установить соединение с первым DataNode с первым блоком файла.
-
Данные считываются в виде потоков, в которых клиент повторно вызывает метод read () . Этот процесс операции read () продолжается до достижения конца блока.
- Как только достигнут конец блока, DFSInputStream закрывает соединение и переходит к поиску следующего DataNode для следующего блока
- Как только клиент завершил чтение, он вызывает метод close () .
Операция записи в HDFS
В этом разделе мы поймем, как данные записываются в HDFS через файлы.
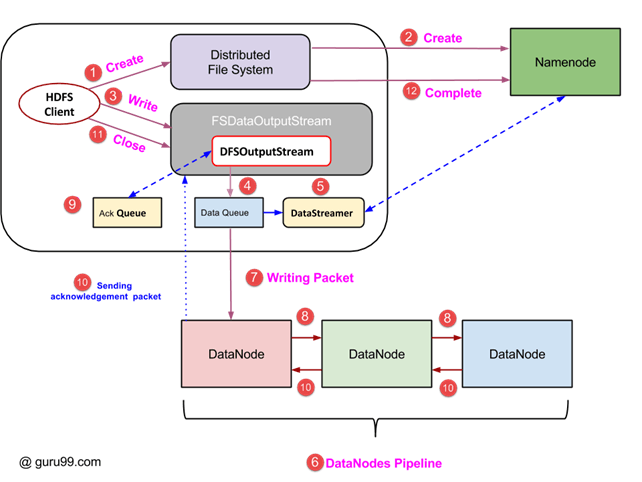
- Клиент инициирует операцию записи, вызывая метод create () объекта DistributedFileSystem, который создает новый файл — Шаг №. 1 на рисунке выше.
- Объект DistributedFileSystem подключается к NameNode с помощью вызова RPC и инициирует создание нового файла. Однако этот файл создает операцию, не связывая никакие блоки с файлом. NameNode отвечает за проверку того, что файл (который создается) еще не существует, и клиент имеет правильные разрешения для создания нового файла. Если файл уже существует или у клиента недостаточно прав для создания нового файла, то IOException выдается клиенту. В противном случае операция завершается успешно, и NameNode создает новую запись для файла.
- Как только новая запись в NameNode создана, объект типа FSDataOutputStream возвращается клиенту. Клиент использует его для записи данных в HDFS. Метод записи данных вызывается (шаг 3 на диаграмме).
- FSDataOutputStream содержит объект DFSOutputStream, который следит за связью с DataNodes и NameNode. Пока клиент продолжает запись данных, DFSOutputStream продолжает создавать пакеты с этими данными. Эти пакеты помещаются в очередь, которая называется DataQueue .
- Есть еще один компонент, называемый DataStreamer, который использует этот DataQueue . DataStreamer также запрашивает NameNode о выделении новых блоков, тем самым выбирая желаемые узлы DataNode, которые будут использоваться для репликации.
- Теперь процесс репликации начинается с создания конвейера с использованием узлов данных. В нашем случае мы выбрали уровень репликации 3, и поэтому в конвейере есть 3 узла данных.
- DataStreamer помещает пакеты в первый DataNode в конвейере.
- Каждый DataNode в конвейере хранит полученный им пакет и перенаправляет его во второй DataNode в конвейере.
- Другая очередь, «Очередь подтверждения», поддерживается DFSOutputStream для хранения пакетов, ожидающих подтверждения от узлов данных.
- Как только подтверждение для пакета в очереди получено от всех узлов данных в конвейере, оно удаляется из «очереди подтверждения». В случае любого сбоя DataNode пакеты из этой очереди используются для повторного запуска операции.
- После того как клиент завершил запись данных, он вызывает метод close () (шаг 9 на диаграмме). Вызов close () приводит к сбросу оставшихся пакетов данных в конвейер с последующим ожиданием подтверждения.
- Как только окончательное подтверждение получено, связывается с NameNode, чтобы сообщить ему, что операция записи в файл завершена.
Доступ к HDFS с использованием JAVA API
В этом разделе мы попытаемся понять интерфейс Java, используемый для доступа к файловой системе Hadoop.
Для программного взаимодействия с файловой системой Hadoop Hadoop предоставляет несколько классов JAVA. Пакет с именем org.apache.hadoop.fs содержит классы, полезные для манипулирования файлом в файловой системе Hadoop. Эти операции включают, открывать, читать, писать и закрывать. На самом деле, файловый API для Hadoop является общим и может быть расширен для взаимодействия с другими файловыми системами, кроме HDFS.
Чтение файла из HDFS, программно
Объект java.net.URL используется для чтения содержимого файла. Для начала нам нужно заставить Java распознавать схему URL Hadoop hdfs. Это делается путем вызова метода setURLStreamHandlerFactory для объекта URL, и ему передается экземпляр FsUrlStreamHandlerFactory. Этот метод должен выполняться только один раз для JVM, поэтому он заключен в статический блок.
Пример кода
public class URLCat {
static {
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
}
public static void main(String[] args) throws Exception {
InputStream in = null;
try {
in = new URL(args[0]).openStream();
IOUtils.copyBytes(in, System.out, 4096, false);
} finally {
IOUtils.closeStream(in);
}
}
}
Этот код открывает и читает содержимое файла. Путь этого файла в HDFS передается программе в качестве аргумента командной строки.
Доступ к HDFS с помощью COMMAND-LINE INTERFACE
Это один из самых простых способов взаимодействия с HDFS. Интерфейс командной строки поддерживает такие операции файловой системы, как чтение файла, создание каталогов, перемещение файлов, удаление данных и просмотр каталогов.
Мы можем запустить ‘$ HADOOP_HOME / bin / hdfs dfs -help’, чтобы получить подробную справку по каждой команде. Здесь ‘dfs’ — это команда оболочки HDFS, которая поддерживает несколько подкоманд.
Некоторые из широко используемых команд перечислены ниже вместе с некоторыми подробностями каждой из них.
1. Скопируйте файл из локальной файловой системы в HDFS
$HADOOP_HOME/bin/hdfs dfs -copyFromLocal temp.txt /

Эта команда копирует файл temp.txt из локальной файловой системы в HDFS.
2. Мы можем перечислить файлы, присутствующие в каталоге, используя -ls
$HADOOP_HOME/bin/hdfs dfs -ls /

Мы видим файл «temp.txt» (скопированный ранее), который находится в каталоге «/» .
3. Команда для копирования файла в локальную файловую систему из HDFS
$HADOOP_HOME/bin/hdfs dfs -copyToLocal /temp.txt

Мы видим, что temp.txt скопирован в локальную файловую систему.
4. Команда для создания нового каталога
$HADOOP_HOME/bin/hdfs dfs -mkdir /mydirectory

Проверьте, создан ли каталог или нет. Теперь вы должны знать, как это сделать ?