Что такое FLUME в Hadoop?
Apache Flume — это система, предназначенная для перемещения больших объемов потоковых данных в HDFS. Сбор данных журнала, присутствующих в файлах журналов с веб-серверов, и агрегирование их в HDFS для анализа — один из распространенных примеров использования Flume.
Flume поддерживает несколько источников, таких как —
- ‘tail’ (который передает данные из локального файла и записывает их в HDFS через Flume, аналогично команде Unix ‘tail’)
- Системные журналы
- Apache log4j (позволяет приложениям Java записывать события в файлы в HDFS через Flume).
В этом уроке вы узнаете
- Что такое FLUME в Hadoop?
- Flume Architecture
- Некоторые важные особенности FLUME
- Настройка Flume, библиотеки и исходного кода
- Загрузка данных из Twitter с помощью Flume
- Создание приложения Twitter
- Изменить файл ‘flume.conf’
- Пример: потоковая передача данных Twitter с использованием Flume
Flume Architecture
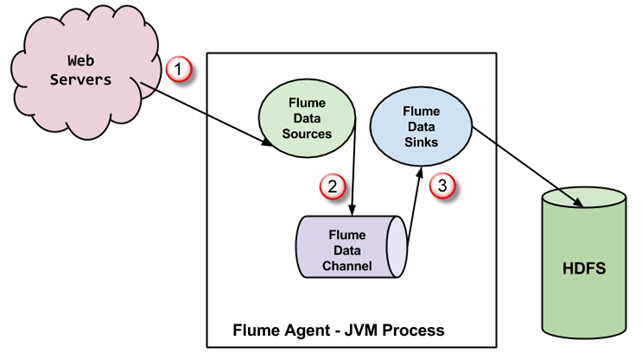
Флюм агент является виртуальной машины Java процесс , который имеет 3 компонента — Флюм Источник, Флюм Channel и Флюм Раковина — через которые распространяются события после того, как инициируется на внешнем источнике.
-
На приведенной выше диаграмме события, генерируемые внешним источником (WebServer), используются источником данных Flume. Внешний источник отправляет события в источник Flume в формате, который распознается целевым источником.
-
Flume Source получает событие и сохраняет его в одном или нескольких каналах. Канал действует как хранилище, которое сохраняет событие, пока оно не будет поглощено приемником потока. Этот канал может использовать локальную файловую систему для хранения этих событий.
-
Приемник потока удаляет событие из канала и сохраняет его во внешнем хранилище, например, HDFS. Там может быть несколько агентов, в этом случае приемник направляет событие в источник следующего агента в потоке.
Некоторые важные особенности FLUME
-
Flume имеет гибкий дизайн, основанный на потоковых данных. Это отказоустойчиво и надежно с несколькими отказоустойчивыми устройствами и механизмами восстановления. Flume предлагает различные уровни надежности, которые включают в себя «доставку с максимальными усилиями» и «сквозную доставку» . Доставка с максимальным усилием не допускает никаких сбоев узла Flume, тогда как режим сквозной доставки гарантирует доставку даже в случае нескольких сбоев узла.
-
Flume передает данные между источниками и приемниками. Этот сбор данных может быть запланированным или управляемым событиями. Flume имеет собственный механизм обработки запросов, который позволяет легко преобразовывать каждый новый пакет данных перед его перемещением в предполагаемый приемник.
-
Возможные приемники Flume включают HDFS и HBase . Flume также может использоваться для передачи данных о событиях, включая, помимо прочего, данные сетевого трафика, данные, генерируемые веб-сайтами социальных сетей, и сообщения электронной почты.
Настройка Flume, библиотеки и исходного кода
Прежде чем мы начнем с самого процесса, убедитесь, что у вас установлен Hadoop. Измените пользователя на ‘hduser’ (идентификатор, используемый при настройке Hadoop, вы можете переключиться на идентификатор пользователя, использованный при настройке Hadoop)

Шаг 1) Создайте новый каталог с именем «FlumeTutorial»
sudo mkdir FlumeTutorial
- Дайте разрешения на чтение, запись и выполнение
sudo chmod -R 777 FlumeTutorial
- Скопируйте файлы MyTwitterSource.java и MyTwitterSourceForFlume.java в этот каталог.
Проверьте права доступа к файлам для всех этих файлов, и если отсутствуют права на «чтение», предоставьте

Шаг 2) Загрузите Apache Flume с сайта — https://flume.apache.org/download.html.
Apache Flume 1.4.0 был использован в этом руководстве.
Следующий клик
Шаг 3) Скопируйте загруженный архив в выбранный вами каталог и извлеките содержимое с помощью следующей команды
sudo tar -xvf apache-flume-1.4.0-bin.tar.gz

Эта команда создаст новый каталог с именем apache-flume-1.4.0-bin и извлечет в него файлы. Этот каталог будет называться <Установочный каталог Flume> в остальной части статьи.
Шаг 4) Настройка библиотеки Flume
Скопируйте twitter4j-core-4.0.1.jar, flume-ng-configuration-1.4.0.jar, flume-ng-core-1.4.0.jar, flume-ng-sdk-1.4.0.jar в
<Каталог установки Flume> / lib /
Возможно, что один или весь скопированный JAR-файл должен будет иметь разрешение на выполнение. Это может вызвать проблемы с компиляцией кода. Итак, отмените разрешение на выполнение для такого JAR.
В моем случае, twitter4j-core-4.0.1.jar должен был выполнить разрешение. Я отменил это как ниже-
sudo chmod -x twitter4j-core-4.0.1.jar
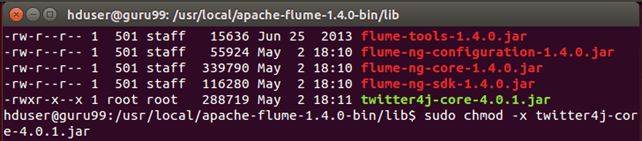
После этого команда дает всем права на чтение в twitter4j-core-4.0.1.jar .
sudo chmod +rrr /usr/local/apache-flume-1.4.0-bin/lib/twitter4j-core-4.0.1.jar
Обратите внимание, что я скачал
— twitter4j-core-4.0.1.jar от https://mvnrepository.com/artifact/org.twitter4j/twitter4j-core
— Все пламени JAR, т.е. flume-ng — * — 1.4.0.jar с http://mvnrepository.com/artifact/org.apache.flume
Загрузка данных из Twitter с помощью Flume
Шаг 1) Перейдите в каталог с файлами исходного кода.
Шаг 2) Установите CLASSPATH, чтобы он содержал <Каталог установки Flume> / lib / * и ~ / FlumeTutorial / flume / mytwittersource / *
export CLASSPATH="/usr/local/apache-flume-1.4.0-bin/lib/*:~/FlumeTutorial/flume/mytwittersource/*"

Шаг 3) Скомпилируйте исходный код, используя команду
javac -d . MyTwitterSourceForFlume.java MyTwitterSource.java

Шаг 4) Создайте банку
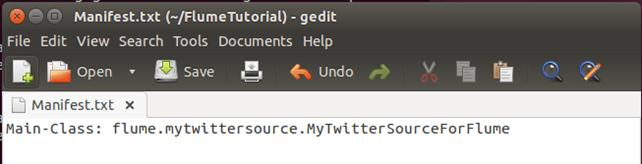
Сначала создайте файл Manifest.txt, используя выбранный вами текстовый редактор, и добавьте в него строку ниже:
Main-Class: flume.mytwittersource.MyTwitterSourceForFlume
.. здесь flume.mytwittersource.MyTwitterSourceForFlume — это имя основного класса. Обратите внимание, что вы должны нажать клавишу ввода в конце этой строки.
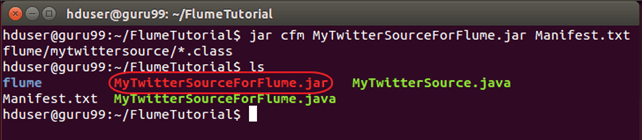
Теперь создайте JAR ‘ MyTwitterSourceForFlume.jar’ как
jar cfm MyTwitterSourceForFlume.jar Manifest.txt flume/mytwittersource/*.class
Шаг 5) Скопируйте этот jar- файл в <каталог установки Flume> / lib /
sudo cp MyTwitterSourceForFlume.jar <Flume Installation Directory>/lib/

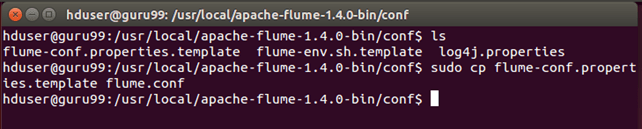
Шаг 6) Перейдите в каталог конфигурации Flume, <Каталог установки Flume> / conf
Если файл flume.conf не существует, скопируйте файл flume-conf.properties.template и переименуйте его в flume.conf.
sudo cp flume-conf.properties.template flume.conf
Если файл flume-env.sh не существует, скопируйте файл flume-env.sh.template и переименуйте его в flume-env.sh
sudo cp flume-env.sh.template flume-env.sh

Создание приложения Twitter
Шаг 1) Создайте приложение для Twitter, войдя в https://developer.twitter.com/
Шаг 2) Перейдите в «Мои приложения» (эта опция выпадает при нажатии кнопки «Яйцо» в правом верхнем углу)
Шаг 3) Создайте новое приложение, нажав «Создать новое приложение»
Шаг 4) Заполните данные приложения, указав название приложения, описание и веб-сайт. Вы можете обратиться к примечаниям, приведенным под каждым полем ввода.

Шаг 5) Прокрутите страницу вниз и примите условия, отметив «Да, я согласен» и нажмите кнопку «Создать приложение в Твиттере».

Шаг 6) В окне вновь созданного приложения перейдите на вкладку «Ключи API», прокрутите страницу вниз и нажмите кнопку «Создать мой токен доступа».
Шаг 7) Обновите страницу.
Шаг 8) Нажмите «Проверить OAuth» . Это покажет «OAuth» настройки приложения.
Шаг 9) Измените файл «flume.conf», используя эти настройки OAuth . Шаги для изменения ‘flume.conf’ приведены ниже.
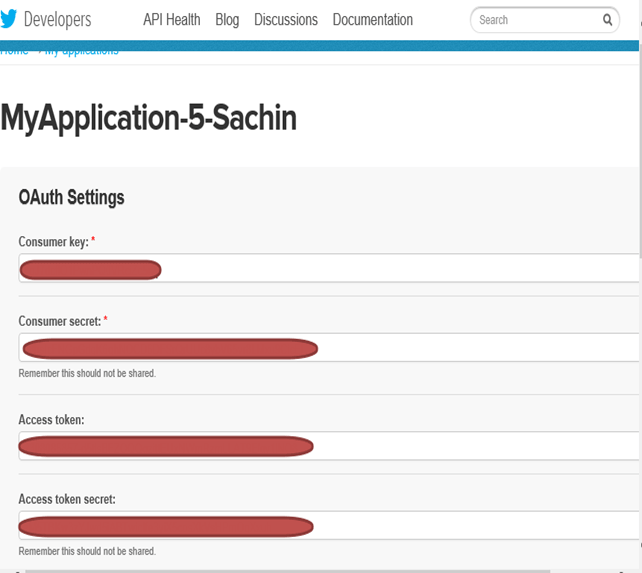
Нам необходимо скопировать ключ Consumer, секрет Consumer, токен Access и секрет токена Access для обновления «flume.conf».
Примечание. Эти значения принадлежат пользователю и, следовательно, являются конфиденциальными, поэтому не должны использоваться совместно.
Изменить файл ‘flume.conf’
Шаг 1) Откройте «flume.conf» в режиме записи и установите значения для следующих параметров:
sudo gedit flume.conf
Скопируйте ниже содержание-
MyTwitAgent.sources = Twitter MyTwitAgent.channels = MemChannel MyTwitAgent.sinks = HDFS MyTwitAgent.sources.Twitter.type = flume.mytwittersource.MyTwitterSourceForFlume MyTwitAgent.sources.Twitter.channels = MemChannel MyTwitAgent.sources.Twitter.consumerKey = <Copy consumer key value from Twitter App> MyTwitAgent.sources.Twitter.consumerSecret = <Copy consumer secret value from Twitter App> MyTwitAgent.sources.Twitter.accessToken = <Copy access token value from Twitter App> MyTwitAgent.sources.Twitter.accessTokenSecret = <Copy access token secret value from Twitter App> MyTwitAgent.sources.Twitter.keywords = guru99 MyTwitAgent.sinks.HDFS.channel = MemChannel MyTwitAgent.sinks.HDFS.type = hdfs MyTwitAgent.sinks.HDFS.hdfs.path = hdfs://localhost:54310/user/hduser/flume/tweets/ MyTwitAgent.sinks.HDFS.hdfs.fileType = DataStream MyTwitAgent.sinks.HDFS.hdfs.writeFormat = Text MyTwitAgent.sinks.HDFS.hdfs.batchSize = 1000 MyTwitAgent.sinks.HDFS.hdfs.rollSize = 0 MyTwitAgent.sinks.HDFS.hdfs.rollCount = 10000 MyTwitAgent.channels.MemChannel.type = memory MyTwitAgent.channels.MemChannel.capacity = 10000 MyTwitAgent.channels.MemChannel.transactionCapacity = 1000
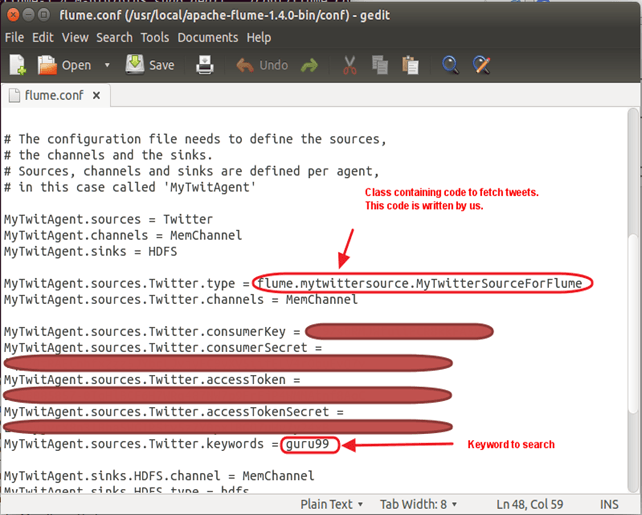
Шаг 2) Также установите TwitterAgent.sinks.HDFS.hdfs.path, как показано ниже,
TwitterAgent.sinks.HDFS.hdfs.path = hdfs: // <имя хоста>: <номер порта> / <домашний каталог HDFS> / flume / tweets /
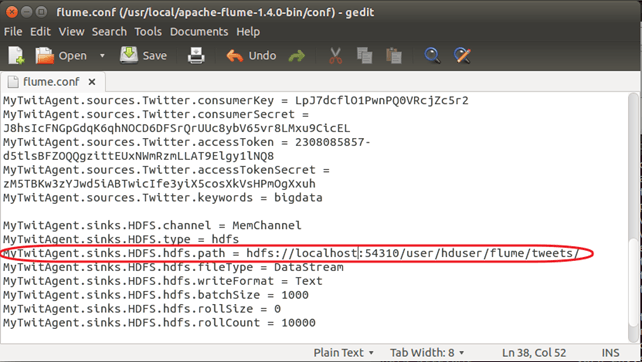
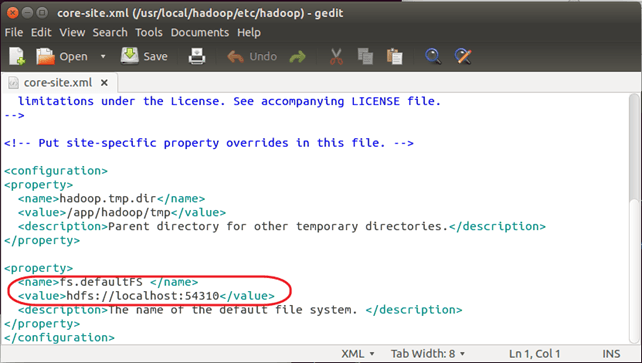
Чтобы узнать <имя хоста> , <номер порта> и <домашний каталог HDFS> , посмотрите значение параметра ‘fs.defaultFS’, установленное в $ HADOOP_HOME / etc / hadoop / core-site.xml
Шаг 3) Чтобы сбросить данные в HDFS, например, когда они появятся, удалите запись ниже, если она существует,
TwitterAgent.sinks.HDFS.hdfs.rollInterval = 600
Пример: потоковая передача данных Twitter с использованием Flume
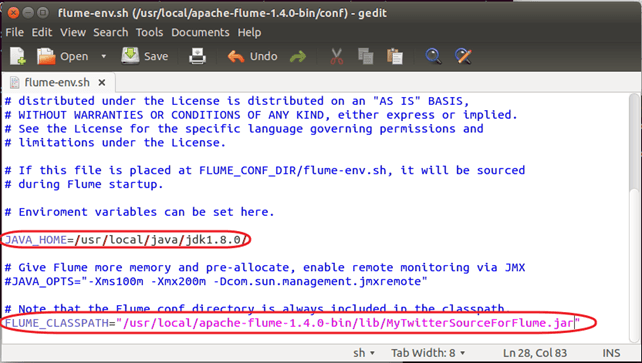
Шаг 1) Откройте «flume-env.sh» в режиме записи и установите значения для следующих параметров,
JAVA_HOME=<Installation directory of Java>
FLUME_CLASSPATH="<Flume Installation Directory>/lib/MyTwitterSourceForFlume.jar"
Шаг 2) Запустите Hadoop
$HADOOP_HOME/sbin/start-dfs.sh
$HADOOP_HOME/sbin/start-yarn.sh
Шаг 3) Два файла JAR из архива Flume не совместимы с Hadoop 2.2.0. Итак, нам нужно выполнить следующие шаги, чтобы сделать Flume совместимым с Hadoop 2.2.0.
а. Переместите protobuf-java-2.4.1.jar из «<Каталог установки Flume> / lib».
Перейдите в «<Каталог установки Flume> / lib»
cd <каталог установки Flume> / lib
sudo mv protobuf-java-2.4.1.jar ~/

б. Найдите для файла JAR ‘guava’ как ниже
find . -name "guava*"

Переместите guava-10.0.1.jar из «<Каталог установки Flume> / lib».
sudo mv guava-10.0.1.jar ~/

с. Загрузите guava-17.0.jar с http://mvnrepository.com/artifact/com.google.guava/guava/17.0
Теперь скопируйте этот скачанный файл jar в «<каталог установки Flume> / lib»
Шаг 4) Перейдите в «<Каталог установки Flume> / bin» и запустите Flume как
./flume-ng agent -n MyTwitAgent -c conf -f <Flume Installation Directory>/conf/flume.conf

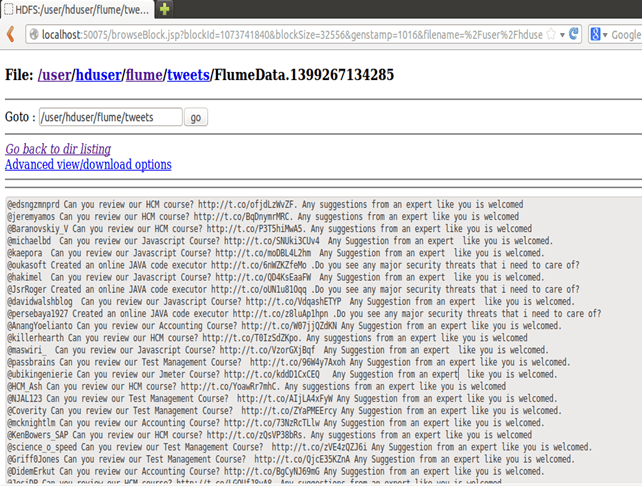
Окно командной строки, в котором происходит извлечение информации.
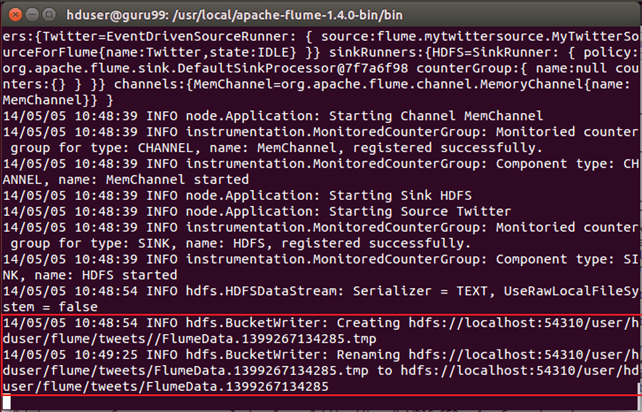
Из сообщения окна команды мы видим, что вывод записывается в каталог / user / hduser / flume / tweets / .
Теперь откройте этот каталог с помощью веб-браузера.
Шаг 5) Чтобы увидеть результат загрузки данных, с помощью браузера откройте http: // localhost: 50070 / и просмотрите файловую систему, затем перейдите в каталог, куда были загружены данные, то есть
<Домашний каталог HDFS> / flume / твиты /