Что такое свинья?
Pig — это язык программирования высокого уровня, полезный для анализа больших наборов данных. Свинья была результатом усилий по разработке в Yahoo!
В рамках MapReduce программы должны быть переведены в ряд этапов Map и Reduce. Однако это не та модель программирования, с которой знакомы аналитики данных. Итак, чтобы преодолеть этот пробел, на Hadoop была построена абстракция под названием Pig.
Apache Pig позволяет людям больше сосредоточиться на анализе больших массивов данных и тратить меньше времени на написание программ Map-Reduce. Подобно Pigs, которые едят что угодно, язык программирования Pig разработан для работы с любыми данными. Вот почему имя, Свинья!

В этом уроке для начинающих с большими данными вы узнаете
Свинья Архитектура
Свинья состоит из двух компонентов:
-
Свинья латынь, которая является языком
-
Среда выполнения, для запуска программ PigLatin.
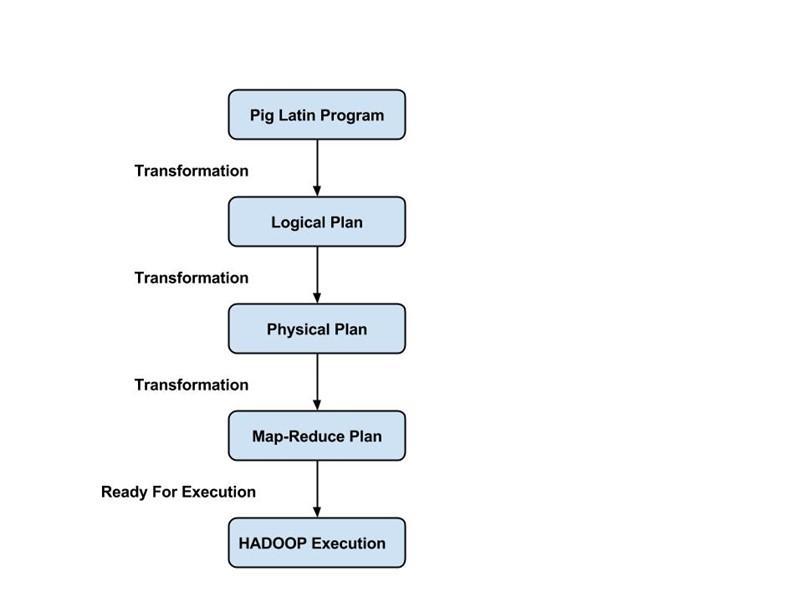
Программа Pig Latin состоит из серии операций или преобразований, которые применяются к входным данным для получения выходных данных. Эти операции описывают поток данных, который преобразуется в исполняемое представление средой выполнения Pig. Ниже приведены результаты этих преобразований — серии заданий MapReduce, о которых программист не знает. Таким образом, Pig позволяет программисту сосредоточиться на данных, а не на характере выполнения.
PigLatin является относительно жестким языком, который использует знакомые ключевые слова из обработки данных, например, Join, Group и Filter.
Режимы исполнения:
Свинья имеет два режима исполнения:
-
Локальный режим: в этом режиме Pig работает в одной JVM и использует локальную файловую систему. Этот режим подходит только для анализа небольших наборов данных с использованием Pig
-
Режим уменьшения карты: в этом режиме запросы, написанные на языке Pig Latin, переводятся в задания MapReduce и выполняются в кластере Hadoop (кластер может быть псевдо или полностью распределенным). Режим MapReduce с полностью распределенным кластером полезен для запуска Pig на больших наборах данных.
Как скачать и установить свинью
Прежде чем мы начнем с самого процесса, убедитесь, что у вас установлен Hadoop. Измените пользователя на ‘hduser’ (идентификатор, используемый при настройке Hadoop, вы можете переключиться на идентификатор пользователя, использованный при настройке Hadoop)

Шаг 1) Загрузите последнюю стабильную версию Pig с любого из зеркал, доступных на
http://pig.apache.org/releases.html
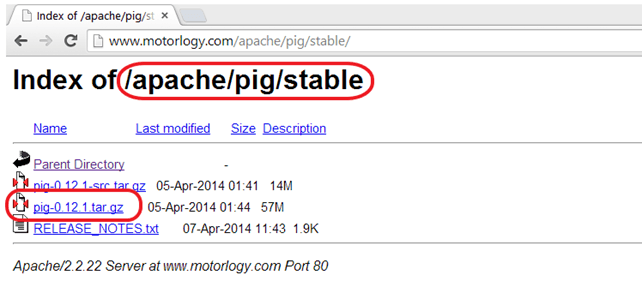
Выберите файл tar.gz (а не src.tar.gz) для загрузки.
Шаг 2) После завершения загрузки перейдите в каталог, содержащий загруженный tar-файл, и переместите tar в то место, где вы хотите установить Pig. В этом случае мы переместимся в / usr / local

Перейти в каталог, содержащий файлы Pig
cd /usr/local
Извлеките содержимое файла tar, как показано ниже
sudo tar -xvf pig-0.12.1.tar.gz

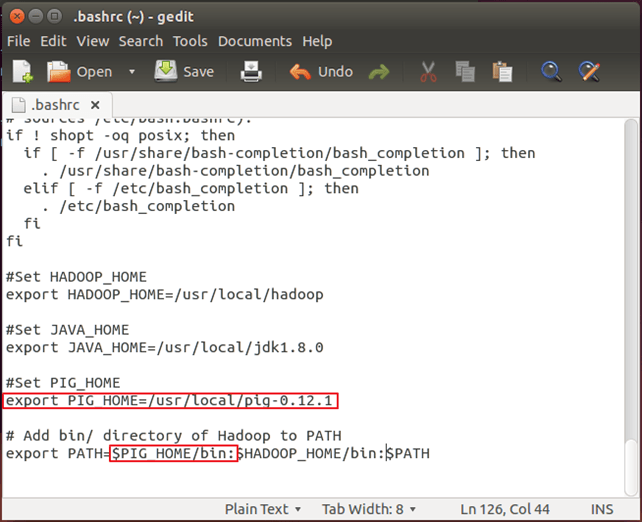
Шаг 3). Измените ~ / .bashrc, чтобы добавить связанные с Pig переменные среды
Откройте файл ~ / .bashrc в любом текстовом редакторе по вашему выбору и внесите следующие изменения:
export PIG_HOME=<Installation directory of Pig> export PATH=$PIG_HOME/bin:$HADOOP_HOME/bin:$PATH
Шаг 4) Теперь создайте эту конфигурацию среды с помощью команды ниже
. ~/.bashrc

Шаг 5) Нам нужно перекомпилировать PIG для поддержки Hadoop 2.2.0
Вот шаги, чтобы сделать это
Перейти в домашний каталог PIG
cd $PIG_HOME
Установить муравей
sudo apt-get install ant
 Примечание: загрузка начнется и будет занимать время в соответствии с вашей скоростью интернета.
Примечание: загрузка начнется и будет занимать время в соответствии с вашей скоростью интернета.
Перекомпилировать PIG
sudo ant clean jar-all -Dhadoopversion=23

Обратите внимание, что в процессе перекомпиляции загружаются несколько компонентов. Таким образом, система должна быть подключена к Интернету.
Кроме того, если этот процесс где-то застрял, и вы не видите никакого движения в командной строке более 20 минут, нажмите Ctrl + c и повторите эту же команду.
В нашем случае это занимает 20 минут
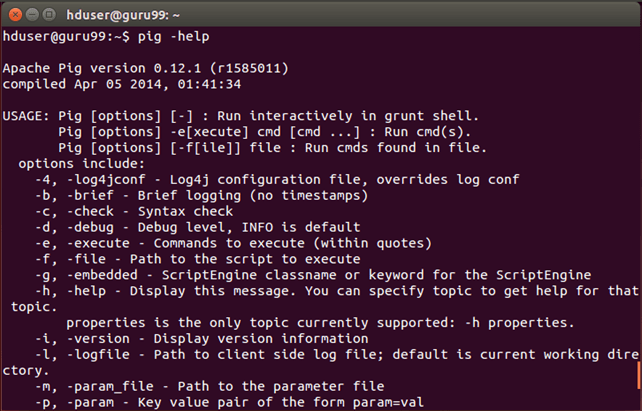
Шаг 6) Проверьте установку Pig с помощью команды
pig -help
Пример Pig Script
Мы будем использовать PIG для определения количества проданных товаров в каждой стране.
Входные данные: Наш входной набор данных представляет собой файл CSV, SalesJan2009.csv
Шаг 1) Запустите Hadoop
$HADOOP_HOME/sbin/start-dfs.sh
$HADOOP_HOME/sbin/start-yarn.sh
Шаг 2) Свинья берет файл из HDFS в режиме MapReduce и сохраняет результаты обратно в HDFS.
Скопируйте файл SalesJan2009.csv (хранящийся в локальной файловой системе ~ / input / SalesJan2009.csv ) в домашнюю директорию HDFS (распределенная файловая система Hadoop).
Здесь файл находится в папке ввода. Если файл хранится в другом месте, дайте это имя
$HADOOP_HOME/bin/hdfs dfs -copyFromLocal ~/input/SalesJan2009.csv /

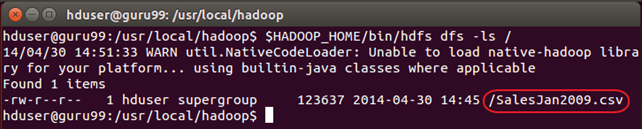
Проверьте, действительно ли файл скопирован или нет.
$HADOOP_HOME/bin/hdfs dfs -ls /
Шаг 3) Конфигурация Свиньи
Сначала перейдите к $ PIG_HOME / conf
cd $PIG_HOME/conf
sudo cp pig.properties pig.properties.original

Откройте pig.properties в любом текстовом редакторе и укажите путь к файлу журнала, используя pig.logfile.
sudo gedit pig.properties

Loger будет использовать этот файл для регистрации ошибок.
Шаг 4) Запустите команду ‘pig’, которая запустит командную строку Pig, представляющую собой интерактивную оболочку Pig-запросов.
pig

Шаг 5) В командной строке Grunt для Pig выполните приведенные ниже команды Pig по порядку.
— A. Загрузить файл, содержащий данные.
salesTable = LOAD '/SalesJan2009.csv' USING PigStorage(',') AS (Transaction_date:chararray,Product:chararray,Price:chararray,Payment_Type:chararray,Name:chararray,City:chararray,State:chararray,Country:chararray,Account_Created:chararray,Last_Login:chararray,Latitude:chararray,Longitude:chararray);
Нажмите Enter после этой команды.

— B. Группировать данные по полю Страна
GroupByCountry = GROUP salesTable BY Country;

— C. Для каждого кортежа в «GroupByCountry» сгенерируйте результирующую строку в форме-> Название страны: Количество проданных продуктов
CountByCountry = FOREACH GroupByCountry GENERATE CONCAT((chararray)$0,CONCAT(':',(chararray)COUNT($1)));
Нажмите Enter после этой команды.

— D. Сохраните результаты потока данных в каталоге pig_output_sales на HDFS.
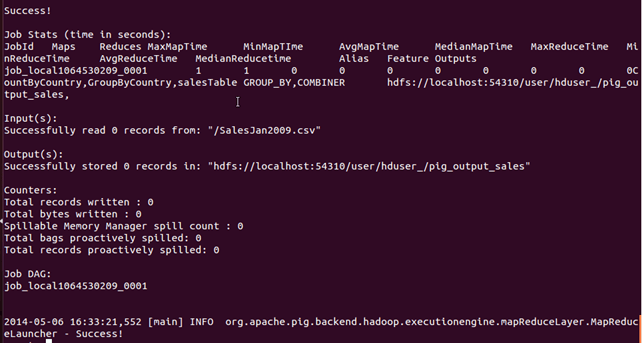
STORE CountByCountry INTO 'pig_output_sales' USING PigStorage('\t');

Выполнение этой команды займет некоторое время. После этого вы должны увидеть следующий экран
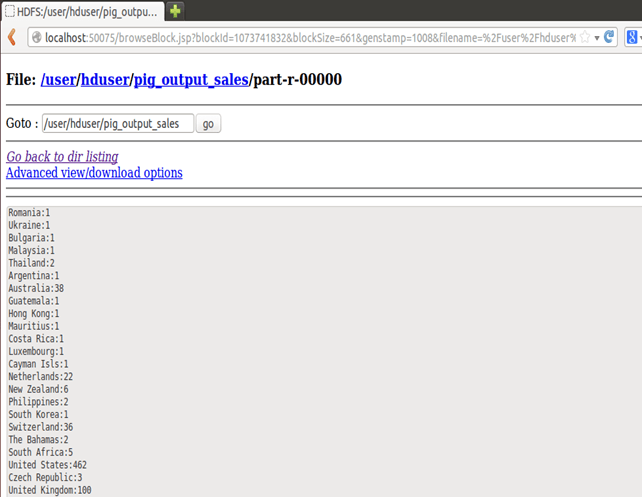
Шаг 6) Результат можно увидеть через командный интерфейс как,
$HADOOP_HOME/bin/hdfs dfs -cat pig_output_sales/part-r-00000
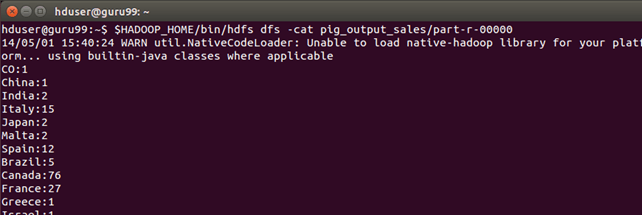
Результаты также можно увидеть через веб-интерфейс, как
Результаты через веб-интерфейс
Откройте http: // localhost: 50070 / в веб-браузере.
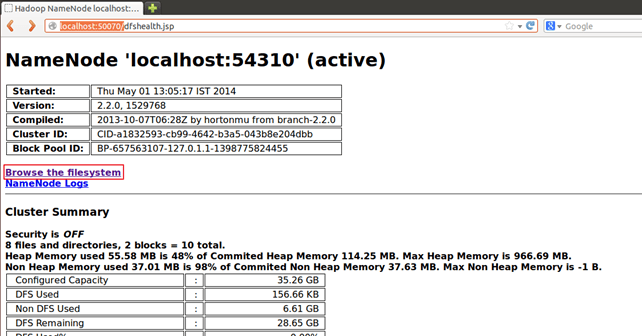
Теперь выберите «Обзор файловой системы» и перейдите в / user / hduser / pig_output_sales
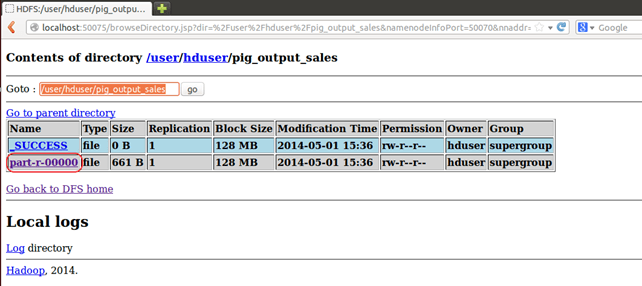
Открытая часть-r-00000