Чтобы понять «большие данные», вам сначала нужно знать
Что такое данные?
Количества, символы или символы, над которыми выполняются операции с помощью компьютера, которые могут храниться и передаваться в форме электрических сигналов и записываться на магнитные, оптические или механические носители записи.
Что такое большие данные?
Большие данные — это тоже данные, но огромного размера . Большие данные — это термин, используемый для описания огромного объема данных, который растет со временем в геометрической прогрессии. Короче говоря, такие данные настолько велики и сложны, что ни один из традиционных инструментов управления данными не может их хранить или эффективно обрабатывать.
В этом уроке вы узнаете,
- Примеры больших данных
- Типы больших данных
- Характеристики больших данных
- Преимущества обработки больших данных

Примеры больших данных
Ниже приведены некоторые примеры больших данных.
Нью — Йоркская фондовая биржа генерирует около одного терабайта новых торговых данных в день.

Социальные сети
Статистика показывает, что более 500 терабайт новых данных попадают в базы данных социальной сети Facebook каждый день. Эти данные в основном генерируются с точки зрения загрузки фото и видео, обмена сообщениями, размещения комментариев и т. Д.

Один реактивный двигатель может генерировать 10 + терабайт данных за 30 минут полета. При многих тысячах рейсов в день генерация данных достигает многих петабайт.

Типы больших данных
BigData ‘можно найти в трех формах:
-
Структурированные
- неструктурированных
- Полуструктурированный
Структурированные
Любые данные, которые могут быть сохранены, доступны и обработаны в форме фиксированного формата, называются «структурированными» данными. За это время талант в области компьютерных наук достиг больших успехов в разработке методов работы с данными такого типа (где формат хорошо известен заранее), а также извлечении из них пользы. Однако в настоящее время мы предвидим проблемы, когда размер таких данных увеличивается в огромной степени, типичные размеры находятся в ярости нескольких зетабайтов.
Ты знаешь? 10 21 байт, равный 1 зетабайту или одному миллиарду терабайт, образует зетабайт .
Глядя на эти цифры, можно легко понять, почему дается название Big Data, и представить себе проблемы, связанные с их хранением и обработкой.
Ты знаешь? Данные, хранящиеся в системе управления реляционными базами данных, являются одним из примеров «структурированных» данных.
Примеры структурированных данных
Таблица «Сотрудник» в базе данных является примером структурированных данных
| eMPLOYEE_ID | Имя сотрудника | Пол | отдел | Salary_In_lacs |
|---|---|---|---|---|
| 2365 | Раджеш Кулкарни | мужчина | финансов | 650000 |
| 3398 | Пратибха Джоши | женский | Администратор | 650000 |
| 7465 | Шушил Рой | мужчина | Администратор | +500000 |
| 7500 | Шубходжит Дас | мужчина | финансов | +500000 |
| 7699 | Прия Сане | женский | финансов | 550000 |
неструктурированных
Любые данные с неизвестной формой или структурой классифицируются как неструктурированные данные. В дополнение к огромному размеру неструктурированные данные создают множество проблем с точки зрения их обработки для получения ценности из них. Типичным примером неструктурированных данных является гетерогенный источник данных, содержащий комбинацию простых текстовых файлов, изображений, видео и т. Д. Сейчас дневные организации имеют в своем распоряжении множество данных, но, к сожалению, они не знают, как извлечь из них выгоду, поскольку эти данные находятся в необработанном виде или в неструктурированном формате.
Примеры неструктурированных данных
Результат, возвращаемый поиском Google
Полуструктурированный
Полуструктурированные данные могут содержать обе формы данных. Мы можем видеть полуструктурированные данные как структурированные по форме, но на самом деле они не определены, например, с помощью определения таблицы в реляционной СУБД. Примером полуструктурированных данных являются данные, представленные в файле XML.
Примеры полуструктурированных данных
Персональные данные хранятся в файле XML
<rec><name>Prashant Rao</name><sex>Male</sex><age>35</age></rec> <rec><name>Seema R.</name><sex>Female</sex><age>41</age></rec> <rec><name>Satish Mane</name><sex>Male</sex><age>29</age></rec> <rec><name>Subrato Roy</name><sex>Male</sex><age>26</age></rec> <rec><name>Jeremiah J.</name><sex>Male</sex><age>35</age></rec>
Рост данных за последние годы
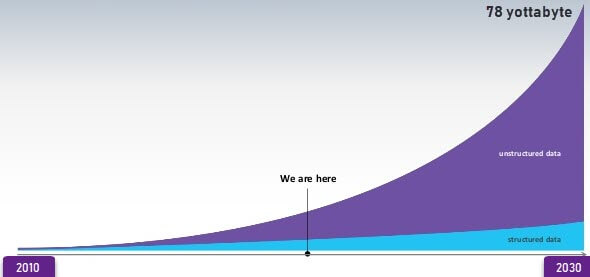
Обратите внимание, что неструктурированные данные веб-приложения состоят из файлов журналов, файлов истории транзакций и т. Д. Системы OLTP созданы для работы со структурированными данными, в которых данные хранятся в отношениях (таблицах).
Характеристики больших данных
(i) Объем — само название «Большие данные» связано с огромным размером. Размер данных играет очень важную роль в определении ценности данных. Кроме того, то, могут ли конкретные данные действительно рассматриваться как большие данные или нет, зависит от объема данных. Следовательно, «объем» — это одна из характеристик, которую необходимо учитывать при работе с большими данными.
(ii) Разнообразие . Следующим аспектом больших данных является их разнообразие .
Разнообразие относится к разнородным источникам и природе данных, как структурированных, так и неструктурированных. В прежние времена электронные таблицы и базы данных были единственными источниками данных, которые рассматривались большинством приложений. В настоящее время в приложениях для анализа также рассматриваются данные в виде электронных писем, фотографий, видео, устройств мониторинга, файлов PDF, аудио и т. Д. Это разнообразие неструктурированных данных создает определенные проблемы для хранения, анализа и анализа данных.
(iii) Скорость — термин «скорость» относится к скорости генерации данных. Скорость, с которой данные генерируются и обрабатываются для удовлетворения потребностей, определяет реальный потенциал данных.
Big Data Velocity имеет дело со скоростью, с которой данные поступают из таких источников, как бизнес-процессы, журналы приложений, сети и сайты социальных сетей, датчики, мобильные устройства и т. Д. Поток данных огромен и непрерывен.
(iv) Изменчивость. Это относится к несоответствиям, которые могут время от времени проявляться данными, что затрудняет процесс эффективной обработки и управления данными.
Преимущества обработки больших данных
Способность обрабатывать большие данные дает множество преимуществ, таких как:
- Предприятия могут использовать внешний интеллект при принятии решений
Доступ к социальным данным из поисковых систем и сайтов, таких как Facebook, Twitter, позволяет организациям отлаживать свои бизнес-стратегии.
- Улучшенное обслуживание клиентов
Традиционные системы обратной связи с клиентами заменяются новыми системами, разработанными с использованием технологий больших данных. В этих новых системах для обработки и оценки ответов потребителей используются технологии обработки больших данных и естественного языка.
- Раннее выявление риска для продукта / услуги, если таковые имеются
- Лучшая операционная эффективность
Технологии больших данных можно использовать для создания промежуточной зоны или зоны посадки для новых данных перед определением того, какие данные следует перенести в хранилище данных. Кроме того, такая интеграция технологий больших данных и хранилища данных помогает организации разгружать редко используемые данные.
Резюме
- Большие данные определяются как данные огромного размера. Bigdata — это термин, используемый для описания огромного размера данных, которые растут в геометрической прогрессии со временем.
- Примеры генерации больших данных включают биржи, сайты социальных сетей, реактивные двигатели и т. Д.
- Большие данные могут быть 1) структурированными, 2) неструктурированными, 3) полуструктурированными
- Объем, разнообразие, скорость и изменчивость — это несколько характеристик Bigdata
- Улучшенное обслуживание клиентов, лучшая операционная эффективность, лучшее принятие решений — вот некоторые преимущества Bigdata