Что такое SQOOP в Hadoop?
Apache Sqoop ( SQL-to-Hadoop ) предназначен для поддержки массового импорта данных в HDFS из структурных хранилищ данных, таких как реляционные базы данных, хранилища корпоративных данных и системы NoSQL. Sqoop основан на архитектуре коннекторов, которая поддерживает плагины для обеспечения подключения к новым внешним системам.
Примером использования Sqoop является предприятие, которое запускает ночной импорт Sqoop для загрузки данных дня из производственной транзакционной СУБД в хранилище данных Hive для дальнейшего анализа.
Sqoop Architecture
Все существующие системы управления базами данных разработаны с учетом стандарта SQL . Однако каждая СУБД в некоторой степени отличается по диалекту. Таким образом, это различие создает проблемы, когда речь идет о передаче данных между системами. Sqoop Connectors — это компоненты, которые помогают преодолеть эти трудности.
Передача данных между Sqoop и внешней системой хранения возможна с помощью разъемов Sqoop.
Sqoop имеет коннекторы для работы с рядом популярных реляционных баз данных, включая MySQL, PostgreSQL, Oracle, SQL Server и DB2. Каждый из этих соединителей знает, как взаимодействовать со связанной с ним СУБД. Существует также универсальный JDBC-коннектор для подключения к любой базе данных, поддерживающей протокол JDBC Java. Кроме того, Sqoop предоставляет оптимизированные коннекторы MySQL и PostgreSQL, которые используют специфичные для базы данных API-интерфейсы для эффективного выполнения массовых передач.
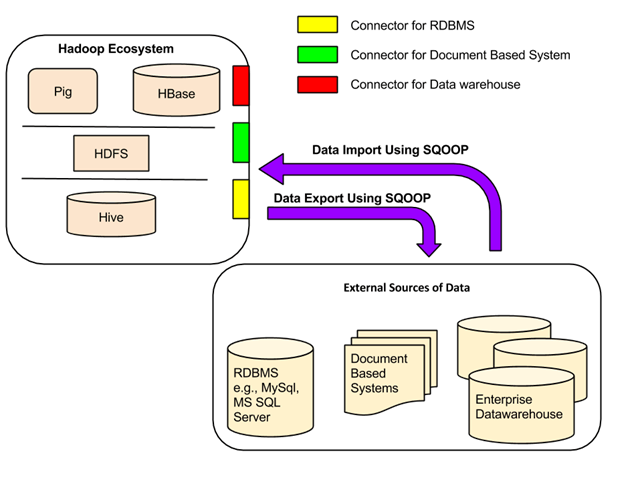
В дополнение к этому, Sqoop имеет различные сторонние разъемы для хранения данных,
от хранилищ данных предприятия (включая Netezza, Teradata и Oracle) до хранилищ NoSQL (таких как Couchbase). Однако эти разъемы не входят в комплект Sqoop; они должны быть загружены отдельно и могут быть легко добавлены к существующей установке Sqoop.
Зачем нам нужен Sqoop?
Аналитическая обработка с использованием Hadoop требует загрузки огромных объемов данных из различных источников в кластеры Hadoop. Этот процесс массовой загрузки данных в Hadoop из разнородных источников и последующей их обработки сопряжен с определенным набором проблем. Поддержание и обеспечение согласованности данных и обеспечение эффективного использования ресурсов — вот некоторые факторы, которые необходимо учитывать перед выбором правильного подхода к загрузке данных.
Главные проблемы:
1. Загрузка данных с использованием скриптов
Традиционный подход использования скриптов для загрузки данных не подходит для массовой загрузки данных в Hadoop; этот подход неэффективен и требует много времени.
2. Прямой доступ к внешним данным через приложение Map-Reduce
Предоставление прямого доступа к данным, находящимся во внешних системах (без загрузки в Hadoop) для приложений сокращения карт, усложняет эти приложения. Таким образом, этот подход неосуществим.
3. Помимо возможности работать с огромными данными, Hadoop может работать с данными в нескольких различных формах. Таким образом, для загрузки таких разнородных данных в Hadoop были разработаны различные инструменты. Sqoop и Flume — два таких инструмента загрузки данных.
Sqoop против Flume против HDFS в Hadoop
| Sqoop | акведук | HDFS |
| Sqoop используется для импорта данных из структурированных источников данных, таких как RDBMS. | Flume используется для перемещения потоковых данных в HDFS. | HDFS — это распределенная файловая система, используемая экосистемой Hadoop для хранения данных. |
| Sqoop имеет архитектуру на основе коннекторов. Соединители знают, как подключиться к соответствующему источнику данных и получить данные. | Flume имеет агентную архитектуру. Здесь написан код (который называется «агент»), который заботится о получении данных. | HDFS имеет распределенную архитектуру, в которой данные распределяются по нескольким узлам данных. |
| HDFS — это место для импорта данных с использованием Sqoop. | Данные передаются в HDFS через ноль или более каналов. | HDFS — это идеальное место для хранения данных. |
| Загрузка данных Sqoop не определяется событиями. | Загрузка данных Flume может быть вызвана событием. | HDFS просто хранит данные, предоставленные ему каким бы то ни было образом. |
| Чтобы импортировать данные из структурированных источников данных, нужно использовать только Sqoop, поскольку его коннекторы знают, как взаимодействовать со структурированными источниками данных и получать из них данные. | Для загрузки потоковых данных, таких как твиты, сгенерированные в Twitter или файлы журналов веб-сервера, следует использовать Flume. Flume-агенты созданы для получения потоковых данных. | HDFS имеет свои собственные встроенные команды оболочки для хранения данных в нем. HDFS не может импортировать потоковые данные |