Что такое Hadoop?
Apache Hadoop — это программная среда с открытым исходным кодом, используемая для разработки приложений обработки данных, которые выполняются в распределенной вычислительной среде.
Приложения, созданные с использованием HADOOP, запускаются на больших наборах данных, распределенных по кластерам обычных компьютеров. Товарные компьютеры дешевы и широко доступны. Они в основном полезны для достижения большей вычислительной мощности при низких затратах.
Подобно данным, хранящимся в локальной файловой системе персональной компьютерной системы, в Hadoop данные хранятся в распределенной файловой системе, которая называется распределенной файловой системой Hadoop . Модель обработки основана на концепции « локальности данных», в которой вычислительная логика отправляется на узлы кластера (сервер), содержащие данные. Эта вычислительная логика — ничто иное, как скомпилированная версия программы, написанная на языке высокого уровня, таком как Java. Такая программа обрабатывает данные, хранящиеся в Hadoop HDFS.
Ты знаешь? Компьютерный кластер состоит из набора нескольких процессоров (диск + процессор), которые связаны друг с другом и действуют как единая система.
В этом уроке вы узнаете,
Экосистема Hadoop и компоненты
На диаграмме ниже показаны различные компоненты в экосистеме Hadoop.
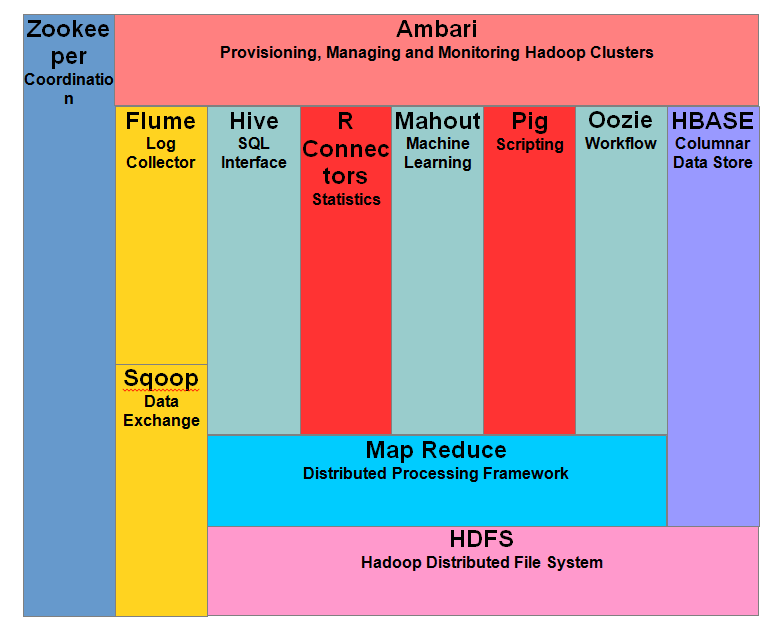
Apache Hadoop состоит из двух подпроектов —
-
Hadoop MapReduce: MapReduce — это вычислительная модель и программная среда для написания приложений, работающих на Hadoop. Эти программы MapReduce способны обрабатывать огромные данные параллельно на больших кластерах вычислительных узлов.
-
HDFS ( распределенная файловая система Hadoop ): HDFS заботится о хранилище приложений Hadoop. Приложения MapReduce используют данные из HDFS. HDFS создает несколько копий блоков данных и распределяет их по вычислительным узлам в кластере. Это распределение обеспечивает надежные и чрезвычайно быстрые вычисления.
Хотя Hadoop наиболее известен за MapReduce и его распределенную файловую систему — HDFS, этот термин также используется для семейства смежных проектов, которые попадают под эгиду распределенных вычислений и крупномасштабной обработки данных. Другие связанные с Hadoop проекты в Apache включают Hive, HBase, Mahout, Sqoop, Flume и ZooKeeper.
Hadoop Architecture

Hadoop имеет архитектуру Master-Slave для хранения и распределенной обработки данных с использованием методов MapReduce и HDFS.
NameNode:
NameNode представляет все файлы и каталоги, которые используются в пространстве имен
DataNode:
DataNode помогает вам управлять состоянием узла HDFS и позволяет вам взаимодействовать с блоками
MasterNode:
Главный узел позволяет проводить параллельную обработку данных с использованием Hadoop MapReduce.
Ведомый узел:
Подчиненные узлы — это дополнительные машины в кластере Hadoop, которые позволяют хранить данные для проведения сложных вычислений. Более того, весь подчиненный узел поставляется с Task Tracker и DataNode. Это позволяет вам синхронизировать процессы с NameNode и Job Tracker соответственно.
В Hadoop ведущую или подчиненную систему можно настроить в облаке или локально
Особенности Hadoop
• Подходит для анализа больших данных
Поскольку большие данные имеют тенденцию быть распределенными и неструктурированными по природе, кластеры HADOOP лучше всего подходят для анализа больших данных. Поскольку логика обработки (а не фактические данные) передается на вычислительные узлы, потребляется меньшая пропускная способность сети. Эта концепция называется концепцией локальности данных, которая помогает повысить эффективность приложений на основе Hadoop.
• Масштабируемость
Кластеры HADOOP можно легко масштабировать до любой степени, добавляя дополнительные узлы кластера, что позволяет увеличить объем больших данных. Кроме того, масштабирование не требует изменений в логике приложения.
• Отказоустойчивость
В экосистеме HADOOP предусмотрена возможность репликации входных данных на другие узлы кластера. Таким образом, в случае сбоя узла кластера обработка данных может продолжаться с использованием данных, хранящихся на другом узле кластера.
Топология сети в Hadoop
Топология (организация) сети влияет на производительность кластера Hadoop при увеличении размера кластера Hadoop. Помимо производительности, необходимо также заботиться о высокой доступности и обработке сбоев. Для достижения этого Hadoop при формировании кластера используется топология сети.

Как правило, пропускная способность сети является важным фактором, который необходимо учитывать при формировании любой сети. Однако, поскольку измерение пропускной способности может быть затруднено, в Hadoop сеть представляется в виде дерева, а расстояние между узлами этого дерева (количество прыжков) рассматривается как важный фактор формирования кластера Hadoop. Здесь расстояние между двумя узлами равно сумме их расстояния до ближайшего общего предка.
Кластер Hadoop состоит из центра обработки данных, стойки и узла, который фактически выполняет задания. Здесь дата-центр состоит из стоек, а стойка состоит из узлов. Пропускная способность сети, доступная для процессов, варьируется в зависимости от местоположения процессов. То есть доступная полоса пропускания становится меньше по мере удаления от
- Процессы на одном узле
- Разные узлы на одной стойке
- Узлы на разных стойках одного и того же датацентра
- Узлы в разных датацентрах