Структуры данных и алгоритмы — обзор
Структура данных — это систематический способ организации данных для их эффективного использования. Следующие термины являются базовыми терминами структуры данных.
-
Интерфейс — каждая структура данных имеет интерфейс. Интерфейс представляет собой набор операций, которые поддерживает структура данных. Интерфейс предоставляет только список поддерживаемых операций, тип параметров, которые они могут принять, и возвращает тип этих операций.
-
Реализация — Реализация обеспечивает внутреннее представление структуры данных. Реализация также обеспечивает определение алгоритмов, используемых в операциях структуры данных.
Интерфейс — каждая структура данных имеет интерфейс. Интерфейс представляет собой набор операций, которые поддерживает структура данных. Интерфейс предоставляет только список поддерживаемых операций, тип параметров, которые они могут принять, и возвращает тип этих операций.
Реализация — Реализация обеспечивает внутреннее представление структуры данных. Реализация также обеспечивает определение алгоритмов, используемых в операциях структуры данных.
Характеристики структуры данных
-
Корректность — реализация структуры данных должна правильно реализовывать свой интерфейс.
-
Сложность времени — время выполнения или время выполнения операций структуры данных должно быть как можно меньше.
-
Сложность пространства — использование памяти операцией структуры данных должно быть как можно меньше.
Корректность — реализация структуры данных должна правильно реализовывать свой интерфейс.
Сложность времени — время выполнения или время выполнения операций структуры данных должно быть как можно меньше.
Сложность пространства — использование памяти операцией структуры данных должно быть как можно меньше.
Потребность в структуре данных
Поскольку приложения становятся сложными и богатыми данными, есть три общие проблемы, с которыми приложения сталкиваются в настоящее время.
-
Поиск данных — Рассмотрите инвентарь 1 миллиона (10 6 ) предметов магазина. Если приложение должно искать элемент, оно должно искать элемент в 1 миллионе (10 6 ) элементов каждый раз, замедляя поиск. По мере роста данных поиск будет замедляться.
-
Скорость процессора. Скорость процессора, хотя и очень высокая, ограничивается, если объем данных увеличивается до миллиарда записей.
-
Многократные запросы. Поскольку тысячи пользователей могут одновременно выполнять поиск данных на веб-сервере, даже быстрый сервер дает сбой при поиске данных.
Поиск данных — Рассмотрите инвентарь 1 миллиона (10 6 ) предметов магазина. Если приложение должно искать элемент, оно должно искать элемент в 1 миллионе (10 6 ) элементов каждый раз, замедляя поиск. По мере роста данных поиск будет замедляться.
Скорость процессора. Скорость процессора, хотя и очень высокая, ограничивается, если объем данных увеличивается до миллиарда записей.
Многократные запросы. Поскольку тысячи пользователей могут одновременно выполнять поиск данных на веб-сервере, даже быстрый сервер дает сбой при поиске данных.
Чтобы решить вышеупомянутые проблемы, структуры данных приходят на помощь. Данные могут быть организованы в структуру данных таким образом, что может не потребоваться поиск всех элементов, а требуемые данные можно искать практически мгновенно.
Случаи выполнения
Есть три случая, которые обычно используются для сравнительного сравнения времени выполнения различной структуры данных.
-
В худшем случае — это сценарий, в котором конкретная операция со структурой данных занимает максимальное время, которое она может занять. Если время наихудшего случая операции равно ƒ (n), то эта операция не займет больше времени, чем ƒ (n), где ƒ (n) представляет функцию от n.
-
Средний случай — это сценарий, отображающий среднее время выполнения операции структуры данных. Если на выполнение операции уходит ƒ (n) времени, то m операций займет время mƒ (n).
-
Наилучший случай — это сценарий, отображающий наименьшее возможное время выполнения операции структуры данных. Если на выполнение операции уходит ƒ (n) времени, то для фактической операции может потребоваться время как случайное число, которое будет максимальным как ƒ (n).
В худшем случае — это сценарий, в котором конкретная операция со структурой данных занимает максимальное время, которое она может занять. Если время наихудшего случая операции равно ƒ (n), то эта операция не займет больше времени, чем ƒ (n), где ƒ (n) представляет функцию от n.
Средний случай — это сценарий, отображающий среднее время выполнения операции структуры данных. Если на выполнение операции уходит ƒ (n) времени, то m операций займет время mƒ (n).
Наилучший случай — это сценарий, отображающий наименьшее возможное время выполнения операции структуры данных. Если на выполнение операции уходит ƒ (n) времени, то для фактической операции может потребоваться время как случайное число, которое будет максимальным как ƒ (n).
Основная терминология
-
Данные — данные являются значениями или набором значений.
-
Элемент данных — элемент данных относится к одной единице значений.
-
Элементы группы — элементы данных, которые разделены на подэлементы, называются элементами группы.
-
Элементарные элементы — элементы данных, которые нельзя разделить, называются элементарными элементами.
-
Атрибут и объект. Объект — это объект, который содержит определенные атрибуты или свойства, которым могут быть назначены значения.
-
Entity Set — Объекты с похожими атрибутами образуют набор объектов .
-
Поле — Поле — это единая элементарная единица информации, представляющая атрибут объекта.
-
Запись — Запись — это коллекция значений полей данного объекта.
-
Файл — Файл представляет собой набор записей сущностей в данном наборе сущностей.
Данные — данные являются значениями или набором значений.
Элемент данных — элемент данных относится к одной единице значений.
Элементы группы — элементы данных, которые разделены на подэлементы, называются элементами группы.
Элементарные элементы — элементы данных, которые нельзя разделить, называются элементарными элементами.
Атрибут и объект. Объект — это объект, который содержит определенные атрибуты или свойства, которым могут быть назначены значения.
Entity Set — Объекты с похожими атрибутами образуют набор объектов .
Поле — Поле — это единая элементарная единица информации, представляющая атрибут объекта.
Запись — Запись — это коллекция значений полей данного объекта.
Файл — Файл представляет собой набор записей сущностей в данном наборе сущностей.
Структуры данных — настройка среды
Попробуйте вариант онлайн
Вам действительно не нужно настраивать собственную среду, чтобы начать изучать язык программирования C. Причина очень проста: мы уже настроили среду программирования на С в режиме онлайн, так что вы можете скомпилировать и выполнить все доступные примеры в режиме онлайн одновременно с работой над теорией. Это дает вам уверенность в том, что вы читаете, и проверить результат с различными вариантами. Не стесняйтесь изменять любой пример и выполнять его онлайн.
Попробуйте следующий пример, используя опцию Try it, доступную в верхнем правом углу поля примера кода.
#include <stdio.h>
int main(){
/* My first program in C */
printf("Hello, World! \n");
return 0;
}
Для большинства примеров, приведенных в этом руководстве, вы найдете опцию Try it, так что просто используйте ее и наслаждайтесь обучением.
Настройка локальной среды
Если вы все еще хотите настроить свою среду для языка программирования C, вам потребуются следующие два инструмента, доступные на вашем компьютере: (a) текстовый редактор и (b) компилятор C.
Текстовый редактор
Это будет использоваться для ввода вашей программы. Примерами немногих редакторов являются Блокнот Windows, команда редактирования ОС, Brief, Epsilon, EMACS и vim или vi.
Имя и версия текстового редактора могут различаться в разных операционных системах. Например, Блокнот будет использоваться в Windows, а vim или vi могут использоваться в Windows, а также в Linux или UNIX.
Файлы, которые вы создаете в редакторе, называются исходными файлами и содержат исходный код программы. Исходные файлы для программ на C обычно называются с расширением » .c «.
Перед началом программирования убедитесь, что у вас есть один текстовый редактор, и у вас достаточно опыта, чтобы написать компьютерную программу, сохранить ее в файле, скомпилировать и, наконец, выполнить.
Компилятор C
Исходный код, написанный в исходном файле, является удобочитаемым исходным кодом для вашей программы. Его нужно «скомпилировать», чтобы он превратился в машинный язык, чтобы ваш процессор мог фактически выполнить программу в соответствии с данными инструкциями.
Этот компилятор языка программирования C будет использоваться для компиляции вашего исходного кода в конечную исполняемую программу. Мы предполагаем, что у вас есть базовые знания о компиляторе языка программирования.
Наиболее часто используемым и бесплатным доступным компилятором является компилятор GNU C / C ++. В противном случае вы можете иметь компиляторы из HP или Solaris, если у вас есть соответствующие операционные системы (ОС).
В следующем разделе рассказывается, как установить компилятор GNU C / C ++ в различных ОС. Мы упоминаем C / C ++ вместе, потому что компилятор GNU GCC работает для языков программирования C и C ++.
Установка в UNIX / Linux
Если вы используете Linux или UNIX , проверьте, установлен ли GCC в вашей системе, введя следующую команду из командной строки:
$ gcc -v
Если на вашем компьютере установлен компилятор GNU, он должен напечатать следующее сообщение:
Using built-in specs. Target: i386-redhat-linux Configured with: ../configure --prefix = /usr ....... Thread model: posix gcc version 4.1.2 20080704 (Red Hat 4.1.2-46)
Если GCC не установлен, вам придется установить его самостоятельно, используя подробные инструкции, доступные по адресу https://gcc.gnu.org/install/.
Это руководство было написано на основе Linux, и все приведенные примеры были скомпилированы на основе Cent OS системы Linux.
Установка в Mac OS
Если вы используете Mac OS X, самый простой способ получить GCC — это загрузить среду разработки Xcode с веб-сайта Apple и следовать простым инструкциям по установке. После настройки Xcode вы сможете использовать компилятор GNU для C / C ++.
Xcode в настоящее время доступен по адресу developer.apple.com/technologies/tools/
Установка на Windows
Чтобы установить GCC в Windows, вам необходимо установить MinGW. Чтобы установить MinGW, перейдите на домашнюю страницу MinGW www.mingw.org и перейдите по ссылке на страницу загрузки MinGW. Загрузите последнюю версию программы установки MinGW, которая должна называться MinGW- <версия> .exe.
При установке MinWG, как минимум, вы должны установить gcc-core, gcc-g ++, binutils и среду выполнения MinGW, но вы можете установить больше.
Добавьте подкаталог bin вашей установки MinGW в переменную среды PATH , чтобы вы могли указывать эти инструменты в командной строке по их простым именам.
После завершения установки вы сможете запустить gcc, g ++, ar, ranlib, dlltool и несколько других инструментов GNU из командной строки Windows.
Структуры данных — Основы алгоритмов
Алгоритм представляет собой пошаговую процедуру, которая определяет набор инструкций, которые должны быть выполнены в определенном порядке, чтобы получить желаемый результат. Алгоритмы, как правило, создаются независимо от базовых языков, то есть алгоритм может быть реализован на нескольких языках программирования.
С точки зрения структуры данных, ниже приведены некоторые важные категории алгоритмов —
-
Поиск — алгоритм поиска элемента в структуре данных.
-
Сортировка — алгоритм сортировки элементов в определенном порядке.
-
Вставить — Алгоритм вставки элемента в структуру данных.
-
Обновить — алгоритм обновления существующего элемента в структуре данных.
-
Удалить — алгоритм удаления существующего элемента из структуры данных.
Поиск — алгоритм поиска элемента в структуре данных.
Сортировка — алгоритм сортировки элементов в определенном порядке.
Вставить — Алгоритм вставки элемента в структуру данных.
Обновить — алгоритм обновления существующего элемента в структуре данных.
Удалить — алгоритм удаления существующего элемента из структуры данных.
Характеристики алгоритма
Не все процедуры можно назвать алгоритмом. Алгоритм должен иметь следующие характеристики —
-
Однозначный — алгоритм должен быть понятным и однозначным. Каждый из его этапов (или фаз) и их входы / выходы должны быть четкими и должны приводить только к одному значению.
-
Входные данные — алгоритм должен иметь 0 или более четко определенных входных данных.
-
Выходные данные — алгоритм должен иметь 1 или более четко определенных выходных данных и должен соответствовать желаемым выходным данным.
-
Конечность — Алгоритмы должны завершаться после конечного числа шагов.
-
Осуществимость — должно быть осуществимо с доступными ресурсами.
-
Независимо — алгоритм должен иметь пошаговые инструкции, которые не должны зависеть от программного кода.
Однозначный — алгоритм должен быть понятным и однозначным. Каждый из его этапов (или фаз) и их входы / выходы должны быть четкими и должны приводить только к одному значению.
Входные данные — алгоритм должен иметь 0 или более четко определенных входных данных.
Выходные данные — алгоритм должен иметь 1 или более четко определенных выходных данных и должен соответствовать желаемым выходным данным.
Конечность — Алгоритмы должны завершаться после конечного числа шагов.
Осуществимость — должно быть осуществимо с доступными ресурсами.
Независимо — алгоритм должен иметь пошаговые инструкции, которые не должны зависеть от программного кода.
Как написать алгоритм?
Нет четко определенных стандартов для написания алгоритмов. Скорее, это проблема и ресурсозависимый. Алгоритмы никогда не пишутся для поддержки определенного программного кода.
Поскольку мы знаем, что все языки программирования имеют общие базовые конструкции кода, такие как циклы (do, for, while), управление потоком (if-else) и т. Д. Эти общие конструкции могут использоваться для написания алгоритма.
Мы пишем алгоритмы пошагово, но это не всегда так. Написание алгоритма — это процесс, который выполняется после того, как проблемная область четко определена. То есть мы должны знать проблемную область, для которой мы разрабатываем решение.
пример
Давайте попробуем научиться писать алгоритмы на примере.
Проблема — Разработайте алгоритм для добавления двух чисел и отображения результата.
Step 1 − START Step 2 − declare three integers a , b & c Step 3 − define values of a & b Step 4 − add values of a & b Step 5 − store output of step 4 to c Step 6 − print c Step 7 − STOP
Алгоритмы говорят программистам, как кодировать программу. Альтернативно, алгоритм может быть записан как —
Step 1 − START ADD Step 2 − get values of a & b Step 3 − c ← a + b Step 4 − display c Step 5 − STOP
При разработке и анализе алгоритмов обычно для описания алгоритма используется второй метод. Это позволяет аналитику легко анализировать алгоритм, игнорируя все нежелательные определения. Он может наблюдать, какие операции используются и как протекает процесс.
Написание номера шагов , необязательно.
Мы разрабатываем алгоритм, чтобы получить решение данной проблемы. Проблема может быть решена несколькими способами.
Следовательно, многие алгоритмы решения могут быть получены для данной проблемы. Следующим шагом является анализ этих предложенных алгоритмов решения и реализация наиболее подходящего решения.
Алгоритм анализа
Эффективность алгоритма может быть проанализирована на двух разных этапах, до реализации и после реализации. Они следующие —
-
Априорный анализ — это теоретический анализ алгоритма. Эффективность алгоритма измеряется в предположении, что все другие факторы, например скорость процессора, являются постоянными и не влияют на реализацию.
-
Апостериорный анализ — это эмпирический анализ алгоритма. Выбранный алгоритм реализован с использованием языка программирования. Затем выполняется на целевом компьютере. В этом анализе собраны фактические статистические данные, такие как время выполнения и требуемое пространство.
Априорный анализ — это теоретический анализ алгоритма. Эффективность алгоритма измеряется в предположении, что все другие факторы, например скорость процессора, являются постоянными и не влияют на реализацию.
Апостериорный анализ — это эмпирический анализ алгоритма. Выбранный алгоритм реализован с использованием языка программирования. Затем выполняется на целевом компьютере. В этом анализе собраны фактические статистические данные, такие как время выполнения и требуемое пространство.
Мы узнаем об априорном алгоритме анализа. Анализ алгоритма имеет дело с выполнением или временем выполнения различных задействованных операций. Время выполнения операции может быть определено как количество компьютерных инструкций, выполненных за операцию.
Сложность алгоритма
Предположим, что X является алгоритмом, а n является размером входных данных, время и пространство, используемое алгоритмом X, являются двумя основными факторами, которые определяют эффективность X.
-
Фактор времени — Время измеряется путем подсчета количества ключевых операций, таких как сравнения, в алгоритме сортировки.
-
Коэффициент пространства — пространство измеряется путем подсчета максимального объема памяти, требуемого алгоритмом.
Фактор времени — Время измеряется путем подсчета количества ключевых операций, таких как сравнения, в алгоритме сортировки.
Коэффициент пространства — пространство измеряется путем подсчета максимального объема памяти, требуемого алгоритмом.
Сложность алгоритма f (n) дает время выполнения и / или объем памяти, требуемый алгоритмом, в терминах n в качестве размера входных данных.
Космическая сложность
Пространственная сложность алгоритма представляет собой объем памяти, необходимый алгоритму в его жизненном цикле. Пространство, требуемое алгоритмом, равно сумме следующих двух компонентов:
-
Фиксированная часть, представляющая собой пространство, необходимое для хранения определенных данных и переменных, которые не зависят от размера проблемы. Например, используемые простые переменные и константы, размер программы и т. Д.
-
Переменная часть — это пространство, необходимое для переменных, размер которых зависит от размера задачи. Например, динамическое выделение памяти, пространство стека рекурсии и т. Д.
Фиксированная часть, представляющая собой пространство, необходимое для хранения определенных данных и переменных, которые не зависят от размера проблемы. Например, используемые простые переменные и константы, размер программы и т. Д.
Переменная часть — это пространство, необходимое для переменных, размер которых зависит от размера задачи. Например, динамическое выделение памяти, пространство стека рекурсии и т. Д.
Пространственная сложность S (P) любого алгоритма P равна S (P) = C + SP (I), где C — фиксированная часть, а S (I) — переменная часть алгоритма, которая зависит от характеристики экземпляра I. простой пример, который пытается объяснить концепцию —
Algorithm: SUM(A, B) Step 1 - START Step 2 - C ← A + B + 10 Step 3 - Stop
Здесь у нас есть три переменные A, B и C и одна константа. Следовательно, S (P) = 1 + 3. Теперь пространство зависит от типов данных заданных переменных и типов констант, и оно будет соответственно умножено.
Сложность времени
Временная сложность алгоритма представляет собой количество времени, которое требуется алгоритму для выполнения до завершения. Требования ко времени могут быть определены как числовая функция T (n), где T (n) может быть измерено как количество шагов, при условии, что каждый шаг потребляет постоянное время.
Например, сложение двух n-битных целых чисел занимает n шагов. Следовательно, общее время вычислений равно T (n) = c ∗ n, где c — время, необходимое для сложения двух битов. Здесь мы видим, что T (n) растет линейно с увеличением размера ввода.
Структуры данных — асимптотический анализ
Асимптотический анализ алгоритма относится к определению математического ограничения / формирования его производительности во время выполнения. Используя асимптотический анализ, мы можем очень хорошо заключить наилучший, средний и худший сценарии алгоритма.
Асимптотический анализ связан с входными данными, т. Е. Если нет входных данных для алгоритма, считается, что он работает в постоянное время. Кроме «входных» все остальные факторы считаются постоянными.
Асимптотический анализ относится к вычислению времени выполнения любой операции в математических единицах вычисления. Например, время выполнения одной операции вычисляется как f (n) и может быть для другой операции оно вычисляется как g (n 2 ). Это означает, что время выполнения первой операции будет линейно увеличиваться с увеличением n, а время выполнения второй операции будет увеличиваться экспоненциально при увеличении n . Точно так же время выполнения обеих операций будет почти одинаковым, если n значительно мало.
Обычно время, требуемое алгоритмом, подразделяется на три типа:
-
Лучший вариант — минимальное время, необходимое для выполнения программы.
-
Средний случай — среднее время, необходимое для выполнения программы.
-
В худшем случае — максимальное время, необходимое для выполнения программы.
Лучший вариант — минимальное время, необходимое для выполнения программы.
Средний случай — среднее время, необходимое для выполнения программы.
В худшем случае — максимальное время, необходимое для выполнения программы.
Асимптотические обозначения
Ниже приведены часто используемые асимптотические обозначения для вычисления сложности алгоритма во время выполнения.
- Ο Обозначение
- Обозначение
- θ нотация
Большая О Нотация, Ο
Обозначение Ο (n) является формальным способом выражения верхней границы времени выполнения алгоритма. Он измеряет сложность времени наихудшего случая или наибольшее время, которое алгоритм может занять для завершения.
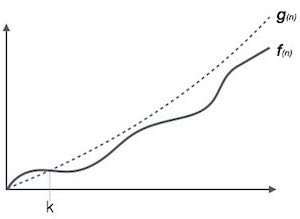
Например, для функции f (n)
Ο( f (n)) = { g (n) : there exists c > 0 and n 0 such that f (n) ≤ c. g (n) for all n > n 0 . }
Нотация Омега, Ом
Обозначение Ω (n) является формальным способом выражения нижней границы времени работы алгоритма. Он измеряет наилучшую временную сложность или лучшее время, которое алгоритм может занять для завершения.
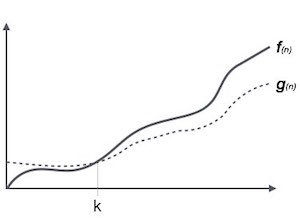
Например, для функции f (n)
Ω( f (n)) ≥ { g (n) : there exists c > 0 and n 0 such that g (n) ≤ c. f (n) for all n > n 0 . }
Тета-нотация, θ
Обозначение θ (n) является формальным способом выражения как нижней, так и верхней границы времени выполнения алгоритма. Это представляется следующим образом —
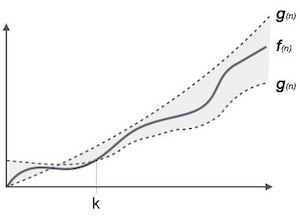
θ( f (n)) = { g (n) if and only if g (n) = Ο( f (n)) and g (n) = Ω( f (n)) for all n > n 0 . }
Распространенные асимптотические обозначения
Ниже приведен список некоторых распространенных асимптотических обозначений —
| постоянная | — | Ο (1) |
| логарифмический | — | Log (журнал n) |
| линейный | — | Ο (п) |
| n log n | — | N (n log n) |
| квадратный | — | Ο (n 2 ) |
| кубический | — | Ο (n 3 ) |
| многочлен | — | n Ο (1) |
| экспоненциальный | — | 2 Ο (н) |
Структуры данных — жадные алгоритмы
Алгоритм предназначен для достижения оптимального решения данной проблемы. При подходе жадного алгоритма решения принимаются из данной области решения. Будучи жадным, выбрано самое близкое решение, которое, кажется, обеспечивает оптимальное решение.
Жадные алгоритмы пытаются найти локализованное оптимальное решение, которое в конечном итоге может привести к глобально оптимизированным решениям. Однако, как правило, жадные алгоритмы не обеспечивают глобально оптимизированных решений.
Подсчет монет
Эта проблема состоит в том, чтобы подсчитать желаемое значение, выбрав как можно меньше монет, и жадный подход заставляет алгоритм выбирать максимально возможную монету. Если нам будут предоставлены монеты ₹ 1, 2, 5 и 10, и нас попросят сосчитать ₹ 18, тогда жадная процедура будет:
-
1 — Выберите одну монету ₹ 10, оставшееся количество — 8
-
2 — Затем выберите одну монету ₹ 5, оставшееся количество составляет 3
-
3 — Затем выберите одну монету ₹ 2, оставшееся количество — 1
-
4 — И наконец, выбор одной монеты ₹ 1 решает проблему
1 — Выберите одну монету ₹ 10, оставшееся количество — 8
2 — Затем выберите одну монету ₹ 5, оставшееся количество составляет 3
3 — Затем выберите одну монету ₹ 2, оставшееся количество — 1
4 — И наконец, выбор одной монеты ₹ 1 решает проблему
Хотя, похоже, все работает нормально, для этого счета нам нужно выбрать всего 4 монеты. Но если мы немного изменим проблему, то тот же подход не сможет дать такой же оптимальный результат.
Для валютной системы, где у нас есть монеты достоинством 1, 7, 10, подсчет монет для значения 18 будет абсолютно оптимальным, но для подсчета, например, 15, он может использовать больше монет, чем необходимо. Например, жадный подход будет использовать 10 + 1 + 1 + 1 + 1 + 1, всего 6 монет. Тогда как ту же проблему можно решить, используя всего 3 монеты (7 + 7 + 1)
Следовательно, мы можем заключить, что жадный подход выбирает немедленное оптимизированное решение и может потерпеть неудачу, когда глобальная оптимизация является главной задачей.
Примеры
Большинство сетевых алгоритмов используют жадный подход. Вот список немногих из них —
- Задача коммивояжера
- Алгоритм минимального связующего дерева Прима
- Алгоритм минимального связующего дерева Крускала
- Алгоритм минимального связующего дерева Дейкстры
- График — раскраска карты
- Graph — Vertex Cover
- Рюкзак Проблема
- Проблема планирования работы
Есть много подобных проблем, которые используют жадный подход, чтобы найти оптимальное решение.
Структуры данных — разделяй и властвуй
При подходе «разделяй и властвуй» имеющаяся проблема разбивается на более мелкие подзадачи, а затем каждая проблема решается независимо. Когда мы продолжаем делить подзадачи на еще более мелкие подзадачи, мы можем в конечном итоге достичь стадии, когда больше деление невозможно. Эти «атомарные» наименьшие возможные подзадачи (дроби) решены. Решение всех подзадач в конечном итоге объединяется, чтобы получить решение исходной задачи.
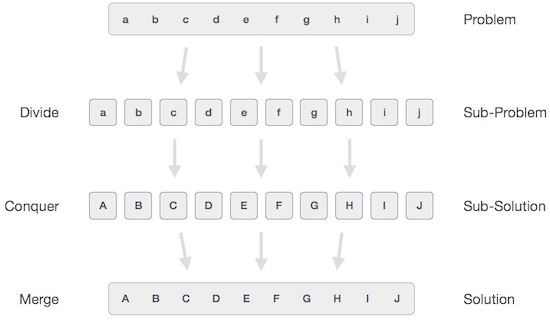
В целом, мы можем понять подход « разделяй и властвуй» в трехэтапном процессе.
Разделить / Перерыв
Этот шаг включает разбиение проблемы на более мелкие подзадачи. Подзадачи должны представлять часть первоначальной проблемы. Этот шаг обычно использует рекурсивный подход для разделения проблемы до тех пор, пока никакая подзадача не станет более делимой. На этом этапе подзадачи приобретают атомарный характер, но все же представляют некоторую часть актуальной проблемы.
Покори / Решить
Этот шаг получает множество мелких подзадач, которые необходимо решить. Как правило, на этом уровне проблемы считаются «решенными» сами по себе.
Слияние / комбинирование
Когда меньшие подзадачи решены, этот этап рекурсивно объединяет их, пока они не сформулируют решение исходной задачи. Этот алгоритмический подход работает рекурсивно, а этапы завоевания и объединения работают так близко, что они выглядят как единое целое.
Примеры
Следующие компьютерные алгоритмы основаны на подходе « разделяй и властвуй» —
- Сортировка слиянием
- Быстрая сортировка
- Бинарный поиск
- Матричное умножение Штрассена
- Ближайшая пара (очки)
Существуют различные способы решения любой компьютерной проблемы, но упомянутые являются хорошим примером подхода «разделяй и властвуй».
Структуры данных — динамическое программирование
Подход динамического программирования аналогичен принципу «разделяй и властвуй», разбивая проблему на более мелкие и все же меньшие возможные подзадачи. Но в отличие, разделяй и властвуй, эти подзадачи не решаются независимо. Скорее, результаты этих меньших подзадач запоминаются и используются для аналогичных или перекрывающихся подзадач.
Динамическое программирование используется там, где у нас есть проблемы, которые можно разделить на аналогичные подзадачи, чтобы их результаты можно было использовать повторно. В основном, эти алгоритмы используются для оптимизации. Прежде чем решить подзадачу, находящуюся в руках, динамический алгоритм попытается изучить результаты ранее решенных подзадач. Решения подзадач объединяются для достижения наилучшего решения.
Таким образом, мы можем сказать, что —
-
Проблему можно разделить на меньшую перекрывающуюся подзадачу.
-
Оптимальное решение может быть достигнуто путем использования оптимального решения небольших подзадач.
-
Динамические алгоритмы используют Memoization.
Проблему можно разделить на меньшую перекрывающуюся подзадачу.
Оптимальное решение может быть достигнуто путем использования оптимального решения небольших подзадач.
Динамические алгоритмы используют Memoization.
сравнение
В отличие от жадных алгоритмов, где применяется локальная оптимизация, динамические алгоритмы мотивированы для общей оптимизации проблемы.
В отличие от алгоритмов «разделяй и властвуй», где решения объединяются для достижения общего решения, динамические алгоритмы используют выходные данные меньшей подзадачи, а затем пытаются оптимизировать большую подзадачу. Динамические алгоритмы используют Memoization для запоминания результатов уже решенных подзадач.
пример
Следующие проблемы с компьютером могут быть решены с использованием подхода динамического программирования —
- Числовой ряд Фибоначчи
- Проблема с рюкзаком
- Ханойская башня
- Все пары кратчайшего пути по Флойд-Варшалл
- Кратчайший путь Дейкстры
- Планирование проекта
Динамическое программирование может использоваться как сверху вниз, так и снизу вверх. И, конечно же, в большинстве случаев обращение к выходным данным предыдущего решения обходится дешевле, чем пересчет с точки зрения циклов ЦП.
Структуры данных и основные понятия алгоритма
В этой главе объясняются основные термины, связанные со структурой данных.
Определение данных
Определение данных определяет конкретные данные со следующими характеристиками.
-
Атомное — определение должно определять единую концепцию.
-
Traceable — определение должно быть в состоянии отображаться на некоторый элемент данных.
-
Точное — определение должно быть однозначным.
-
Ясно и сжато — определение должно быть понятным.
Атомное — определение должно определять единую концепцию.
Traceable — определение должно быть в состоянии отображаться на некоторый элемент данных.
Точное — определение должно быть однозначным.
Ясно и сжато — определение должно быть понятным.
Объект данных
Объект данных представляет объект, имеющий данные.
Тип данных
Тип данных — это способ классификации различных типов данных, таких как целочисленные, строковые и т. Д., Который определяет значения, которые можно использовать с данными соответствующего типа, тип операций, которые можно выполнять с данными соответствующего типа. Есть два типа данных —
- Встроенный тип данных
- Тип производных данных
Встроенный тип данных
Те типы данных, для которых язык имеет встроенную поддержку, называются встроенными типами данных. Например, большинство языков предоставляют следующие встроенные типы данных.
- Целые
- Логическое (верно, неверно)
- Плавающая (десятичные числа)
- Персонаж и Струны
Тип производных данных
Те типы данных, которые не зависят от реализации, поскольку они могут быть реализованы тем или иным способом, называются производными типами данных. Эти типы данных обычно создаются путем сочетания основных или встроенных типов данных и связанных с ними операций. Например —
- Список
- массив
- стек
- Очередь
Основные операции
Данные в структурах данных обрабатываются определенными операциями. Конкретная выбранная структура данных в значительной степени зависит от частоты операции, которая должна быть выполнена над структурой данных.
- Пересекая
- поиск
- вставка
- делеция
- Сортировка
- сращивание
Структуры данных и алгоритмы — массивы
Массив — это контейнер, который может содержать фиксированное количество элементов, и эти элементы должны быть одного типа. Большинство структур данных используют массивы для реализации своих алгоритмов. Ниже приведены важные термины для понимания концепции массива.
-
Элемент — каждый элемент, хранящийся в массиве, называется элементом.
-
Индекс — каждое местоположение элемента в массиве имеет числовой индекс, который используется для идентификации элемента.
Элемент — каждый элемент, хранящийся в массиве, называется элементом.
Индекс — каждое местоположение элемента в массиве имеет числовой индекс, который используется для идентификации элемента.
Представление массива
Массивы могут быть объявлены различными способами на разных языках. Для иллюстрации возьмем объявление массива Си.

Массивы могут быть объявлены различными способами на разных языках. Для иллюстрации возьмем объявление массива Си.

Согласно приведенной выше иллюстрации, ниже приведены важные моменты, которые необходимо учитывать.
-
Индекс начинается с 0.
-
Длина массива равна 10, что означает, что он может хранить 10 элементов.
-
Каждый элемент может быть доступен через его индекс. Например, мы можем получить элемент с индексом 6 как 9.
Индекс начинается с 0.
Длина массива равна 10, что означает, что он может хранить 10 элементов.
Каждый элемент может быть доступен через его индекс. Например, мы можем получить элемент с индексом 6 как 9.
Основные операции
Ниже приведены основные операции, поддерживаемые массивом.
-
Traverse — печатать все элементы массива один за другим.
-
Вставка — добавляет элемент по указанному индексу.
-
Удаление — удаляет элемент по указанному индексу.
-
Поиск — поиск элемента по заданному индексу или по значению.
-
Обновить — обновляет элемент по указанному индексу.
Traverse — печатать все элементы массива один за другим.
Вставка — добавляет элемент по указанному индексу.
Удаление — удаляет элемент по указанному индексу.
Поиск — поиск элемента по заданному индексу или по значению.
Обновить — обновляет элемент по указанному индексу.
В C, когда массив инициализируется с размером, он присваивает значения по умолчанию своим элементам в следующем порядке.
| Тип данных | Значение по умолчанию |
|---|---|
| BOOL | ложный |
| голец | 0 |
| ИНТ | 0 |
| поплавок | 0.0 |
| двойной | 0.0f |
| недействительным | |
| wchar_t | 0 |
Операция вставки
Операция вставки заключается в вставке одного или нескольких элементов данных в массив. В зависимости от требования, новый элемент может быть добавлен в начале, конце или любом заданном индексе массива.
Здесь мы видим практическую реализацию операции вставки, где мы добавляем данные в конец массива —
Алгоритм
Пусть Array будет линейным неупорядоченным массивом элементов MAX .
пример
Результат
Пусть LA — линейный массив (неупорядоченный) с N элементами, а K — натуральное число, такое что K <= N. Ниже приведен алгоритм, в котором пункт вставляется в K- ю позицию LA —
1. Start 2. Set J = N 3. Set N = N+1 4. Repeat steps 5 and 6 while J >= K 5. Set LA[J+1] = LA[J] 6. Set J = J-1 7. Set LA[K] = ITEM 8. Stop
пример
Ниже приведена реализация вышеуказанного алгоритма —
#include <stdio.h> main() { int LA[] = {1,3,5,7,8}; int item = 10, k = 3, n = 5; int i = 0, j = n; printf("The original array elements are :\n"); for(i = 0; i<n; i++) { printf("LA[%d] = %d \n", i, LA[i]); } n = n + 1; while( j >= k) { LA[j+1] = LA[j]; j = j - 1; } LA[k] = item; printf("The array elements after insertion :\n"); for(i = 0; i<n; i++) { printf("LA[%d] = %d \n", i, LA[i]); } }
Когда мы компилируем и выполняем вышеуказанную программу, она дает следующий результат:
Выход
The original array elements are : LA[0] = 1 LA[1] = 3 LA[2] = 5 LA[3] = 7 LA[4] = 8 The array elements after insertion : LA[0] = 1 LA[1] = 3 LA[2] = 5 LA[3] = 10 LA[4] = 7 LA[5] = 8
Для других вариантов операции вставки массива нажмите здесь
Операция удаления
Удаление относится к удалению существующего элемента из массива и реорганизации всех элементов массива.
Алгоритм
Рассмотрим LA — линейный массив с N элементами, а K — натуральное число, такое, что K <= N. Ниже приведен алгоритм удаления элемента, доступного в K- й позиции LA.
1. Start 2. Set J = K 3. Repeat steps 4 and 5 while J < N 4. Set LA[J] = LA[J + 1] 5. Set J = J+1 6. Set N = N-1 7. Stop
пример
Ниже приведена реализация вышеуказанного алгоритма —
#include <stdio.h> void main() { int LA[] = {1,3,5,7,8}; int k = 3, n = 5; int i, j; printf("The original array elements are :\n"); for(i = 0; i<n; i++) { printf("LA[%d] = %d \n", i, LA[i]); } j = k; while( j < n) { LA[j-1] = LA[j]; j = j + 1; } n = n -1; printf("The array elements after deletion :\n"); for(i = 0; i<n; i++) { printf("LA[%d] = %d \n", i, LA[i]); } }
Когда мы компилируем и выполняем вышеуказанную программу, она дает следующий результат:
Выход
The original array elements are : LA[0] = 1 LA[1] = 3 LA[2] = 5 LA[3] = 7 LA[4] = 8 The array elements after deletion : LA[0] = 1 LA[1] = 3 LA[2] = 7 LA[3] = 8
Операция поиска
Вы можете выполнить поиск элемента массива по его значению или индексу.
Алгоритм
Рассмотрим LA — линейный массив с N элементами, а K — натуральное число, такое, что K <= N. Ниже приведен алгоритм поиска элемента со значением ITEM с использованием последовательного поиска.
1. Start 2. Set J = 0 3. Repeat steps 4 and 5 while J < N 4. IF LA[J] is equal ITEM THEN GOTO STEP 6 5. Set J = J +1 6. PRINT J, ITEM 7. Stop
пример
Ниже приведена реализация вышеуказанного алгоритма —
#include <stdio.h> void main() { int LA[] = {1,3,5,7,8}; int item = 5, n = 5; int i = 0, j = 0; printf("The original array elements are :\n"); for(i = 0; i<n; i++) { printf("LA[%d] = %d \n", i, LA[i]); } while( j < n){ if( LA[j] == item ) { break; } j = j + 1; } printf("Found element %d at position %d\n", item, j+1); }
Когда мы компилируем и выполняем вышеуказанную программу, она дает следующий результат:
Выход
The original array elements are : LA[0] = 1 LA[1] = 3 LA[2] = 5 LA[3] = 7 LA[4] = 8 Found element 5 at position 3
Операция обновления
Операция обновления относится к обновлению существующего элемента из массива по заданному индексу.
Алгоритм
Рассмотрим LA — линейный массив с N элементами, а K — натуральное число, такое, что K <= N. Ниже приведен алгоритм обновления элемента, доступного в K- й позиции LA.
1. Start 2. Set LA[K-1] = ITEM 3. Stop
пример
Ниже приведена реализация вышеуказанного алгоритма —
#include <stdio.h> void main() { int LA[] = {1,3,5,7,8}; int k = 3, n = 5, item = 10; int i, j; printf("The original array elements are :\n"); for(i = 0; i<n; i++) { printf("LA[%d] = %d \n", i, LA[i]); } LA[k-1] = item; printf("The array elements after updation :\n"); for(i = 0; i<n; i++) { printf("LA[%d] = %d \n", i, LA[i]); } }
Когда мы компилируем и выполняем вышеуказанную программу, она дает следующий результат:
Выход
The original array elements are : LA[0] = 1 LA[1] = 3 LA[2] = 5 LA[3] = 7 LA[4] = 8 The array elements after updation : LA[0] = 1 LA[1] = 3 LA[2] = 10 LA[3] = 7 LA[4] = 8
Структура данных и алгоритмы — связанный список
Связанный список — это последовательность структур данных, которые связаны между собой ссылками.
Связанный список — это последовательность ссылок, которая содержит элементы. Каждая ссылка содержит ссылку на другую ссылку. Связанный список является второй наиболее используемой структурой данных после массива. Ниже приведены важные термины для понимания концепции связанного списка.
-
Ссылка — каждая ссылка в связанном списке может хранить данные, называемые элементом.
-
Далее — каждая ссылка в связанном списке содержит ссылку на следующую ссылку с именем Далее.
-
LinkedList — Linked List содержит ссылку на соединение с первой ссылкой, которая называется First.
Ссылка — каждая ссылка в связанном списке может хранить данные, называемые элементом.
Далее — каждая ссылка в связанном списке содержит ссылку на следующую ссылку с именем Далее.
LinkedList — Linked List содержит ссылку на соединение с первой ссылкой, которая называется First.
Представление связанного списка
Связанный список можно представить в виде цепочки узлов, где каждый узел указывает на следующий узел.

Согласно приведенной выше иллюстрации, ниже приведены важные моменты, которые необходимо учитывать.
-
Связанный список содержит элемент ссылки, который называется первым.
-
Каждая ссылка содержит поле (и) данных и поле ссылки, называемое следующим.
-
Каждая ссылка связана со своей следующей ссылкой, используя свою следующую ссылку.
-
Последняя ссылка содержит нулевую ссылку для обозначения конца списка.
Связанный список содержит элемент ссылки, который называется первым.
Каждая ссылка содержит поле (и) данных и поле ссылки, называемое следующим.
Каждая ссылка связана со своей следующей ссылкой, используя свою следующую ссылку.
Последняя ссылка содержит нулевую ссылку для обозначения конца списка.
Типы связанного списка
Ниже приведены различные типы связанных списков.
-
Простой связанный список — элемент навигации только вперед.
-
Двусвязный список — элементы можно перемещаться вперед и назад.
-
Круговой связанный список — последний элемент содержит ссылку первого элемента как следующий, а первый элемент имеет ссылку на последний элемент как предыдущий.
Простой связанный список — элемент навигации только вперед.
Двусвязный список — элементы можно перемещаться вперед и назад.
Круговой связанный список — последний элемент содержит ссылку первого элемента как следующий, а первый элемент имеет ссылку на последний элемент как предыдущий.
Основные операции
Ниже приведены основные операции, поддерживаемые списком.
-
Вставка — добавляет элемент в начало списка.
-
Удаление — удаляет элемент в начале списка.
-
Дисплей — отображает полный список.
-
Поиск — поиск элемента по заданному ключу.
-
Удалить — удаляет элемент, используя заданный ключ.
Вставка — добавляет элемент в начало списка.
Удаление — удаляет элемент в начале списка.
Дисплей — отображает полный список.
Поиск — поиск элемента по заданному ключу.
Удалить — удаляет элемент, используя заданный ключ.
Операция вставки
Добавление нового узла в связанный список — это более чем одно действие. Мы узнаем это на диаграммах здесь. Сначала создайте узел, используя ту же структуру, и найдите место, куда он должен быть вставлен.
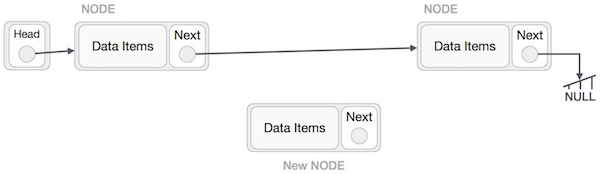
Представьте, что мы вставляем узел B (NewNode) между A (LeftNode) и C (RightNode). Затем укажите B. следующий к C —
NewNode.next −> RightNode;
Это должно выглядеть так —
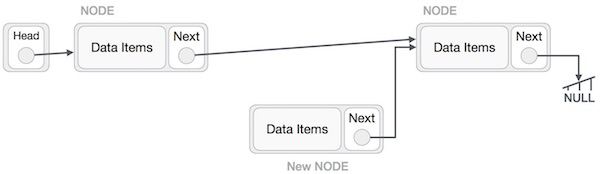
Теперь следующий узел слева должен указывать на новый узел.
LeftNode.next −> NewNode;
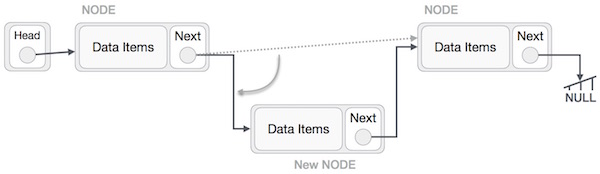
Это поместит новый узел в середину двух. Новый список должен выглядеть так —

Аналогичные шаги следует предпринять, если узел вставляется в начало списка. Вставляя его в конец, второй последний узел списка должен указывать на новый узел, а новый узел будет указывать на NULL.
Операция удаления
Удаление также является более чем одним этапом процесса. Мы будем учиться с графическим изображением. Сначала найдите целевой узел, который нужно удалить, используя алгоритмы поиска.

Левый (предыдущий) узел целевого узла теперь должен указывать на следующий узел целевого узла —
LeftNode.next −> TargetNode.next;

Это удалит ссылку, которая указывала на целевой узел. Теперь, используя следующий код, мы удалим то, на что указывает целевой узел.
TargetNode.next −> NULL;

Нам нужно использовать удаленный узел. Мы можем сохранить это в памяти, иначе мы можем просто освободить память и полностью стереть целевой узел.
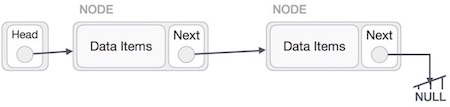
Обратная операция
Эта операция тщательная. Нам нужно сделать последний узел, который будет указан головным узлом, и обратить весь связанный список.
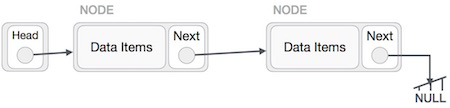
Сначала мы переходим к концу списка. Это должно указывать на NULL. Теперь мы будем указывать на его предыдущий узел —
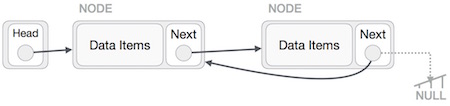
Мы должны убедиться, что последний узел не является потерянным узлом. Таким образом, у нас будет некоторый временный узел, который выглядит как головной узел, указывающий на последний узел. Теперь мы сделаем так, чтобы все левые боковые узлы указывали на их предыдущие узлы один за другим.
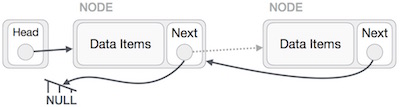
За исключением узла (первого узла), указанного головным узлом, все узлы должны указывать на своего предшественника, что делает их новым преемником. Первый узел будет указывать на NULL.
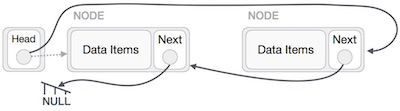
Мы заставим головной узел указывать на новый первый узел, используя временный узел.
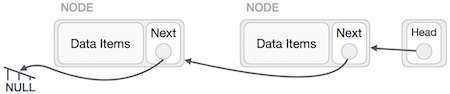
Связанный список теперь перевернут. Чтобы увидеть реализацию связанного списка на языке программирования C, нажмите здесь .
Структура данных — двусвязный список
Двойной связанный список представляет собой разновидность связанного списка, в котором навигация возможна обоими способами, как в прямом, так и в обратном направлении, по сравнению с одиночным связанным списком. Ниже приведены важные термины для понимания концепции двусвязного списка.
-
Ссылка — каждая ссылка в связанном списке может хранить данные, называемые элементом.
-
Далее — каждая ссылка в связанном списке содержит ссылку на следующую ссылку с именем Далее.
-
Пред. Каждая ссылка в связанном списке содержит ссылку на предыдущую ссылку под названием Пред.
-
LinkedList — связанный список содержит ссылку на соединение с первой ссылкой с именем First и с последней ссылкой с именем Last.
Ссылка — каждая ссылка в связанном списке может хранить данные, называемые элементом.
Далее — каждая ссылка в связанном списке содержит ссылку на следующую ссылку с именем Далее.
Пред. Каждая ссылка в связанном списке содержит ссылку на предыдущую ссылку под названием Пред.
LinkedList — связанный список содержит ссылку на соединение с первой ссылкой с именем First и с последней ссылкой с именем Last.
Представление с двойными связями
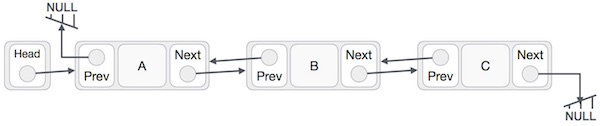
Согласно приведенной выше иллюстрации, ниже приведены важные моменты, которые необходимо учитывать.
-
Вдвойне связанный список содержит элемент ссылки, который называется первым и последним.
-
Каждая ссылка содержит поле (и) данных и два поля ссылки, которые называются next и prev.
-
Каждая ссылка связана со своей следующей ссылкой, используя свою следующую ссылку.
-
Каждая ссылка связана со своей предыдущей ссылкой, используя свою предыдущую ссылку.
-
Последняя ссылка содержит нулевую ссылку для обозначения конца списка.
Вдвойне связанный список содержит элемент ссылки, который называется первым и последним.
Каждая ссылка содержит поле (и) данных и два поля ссылки, которые называются next и prev.
Каждая ссылка связана со своей следующей ссылкой, используя свою следующую ссылку.
Каждая ссылка связана со своей предыдущей ссылкой, используя свою предыдущую ссылку.
Последняя ссылка содержит нулевую ссылку для обозначения конца списка.
Основные операции
Ниже приведены основные операции, поддерживаемые списком.
-
Вставка — добавляет элемент в начало списка.
-
Удаление — удаляет элемент в начале списка.
-
Вставить последний — добавляет элемент в конец списка.
-
Удалить последний — удаляет элемент из конца списка.
-
Вставить после — добавляет элемент после элемента списка.
-
Удалить — удаляет элемент из списка с помощью клавиши.
-
Отображать вперед — отображает полный список в прямом направлении.
-
Отобразить назад — отображает полный список в обратном порядке.
Вставка — добавляет элемент в начало списка.
Удаление — удаляет элемент в начале списка.
Вставить последний — добавляет элемент в конец списка.
Удалить последний — удаляет элемент из конца списка.
Вставить после — добавляет элемент после элемента списка.
Удалить — удаляет элемент из списка с помощью клавиши.
Отображать вперед — отображает полный список в прямом направлении.
Отобразить назад — отображает полный список в обратном порядке.
Операция вставки
Следующий код демонстрирует операцию вставки в начале двусвязного списка.
пример
//insert link at the first location void insertFirst(int key, int data) { //create a link struct node *link = (struct node*) malloc(sizeof(struct node)); link->key = key; link->data = data; if(isEmpty()) { //make it the last link last = link; } else { //update first prev link head->prev = link; } //point it to old first link link->next = head; //point first to new first link head = link; }
Операция удаления
Следующий код демонстрирует операцию удаления в начале двусвязного списка.
пример
//delete first item struct node* deleteFirst() { //save reference to first link struct node *tempLink = head; //if only one link if(head->next == NULL) { last = NULL; } else { head->next->prev = NULL; } head = head->next; //return the deleted link return tempLink; }
Вставка в конце операции
Следующий код демонстрирует операцию вставки в последнюю позицию двусвязного списка.
пример
//insert link at the last location void insertLast(int key, int data) { //create a link struct node *link = (struct node*) malloc(sizeof(struct node)); link->key = key; link->data = data; if(isEmpty()) { //make it the last link last = link; } else { //make link a new last link last->next = link; //mark old last node as prev of new link link->prev = last; } //point last to new last node last = link; }
Чтобы увидеть реализацию на языке программирования C, пожалуйста, нажмите здесь .
Структура данных — круговой связанный список
Круговой связанный список — это вариант связанного списка, в котором первый элемент указывает на последний элемент, а последний элемент указывает на первый элемент. Как односвязный список, так и двусвязный список можно превратить в круговой связанный список.
Единственный связанный список как круговой
В односвязном списке следующий указатель последнего узла указывает на первый узел.

Двойной связанный список как циркулярный
В двусвязном списке следующий указатель последнего узла указывает на первый узел, а предыдущий указатель первого узла указывает на последний узел, делающий круговую в обоих направлениях.

Согласно приведенной выше иллюстрации, ниже приведены важные моменты, которые необходимо учитывать.
-
Следующая ссылка последней ссылки указывает на первую ссылку списка в обоих случаях как одиночного, так и двусвязного списка.
-
Первая ссылка указывает на последний список в случае двусвязного списка.
Следующая ссылка последней ссылки указывает на первую ссылку списка в обоих случаях как одиночного, так и двусвязного списка.
Первая ссылка указывает на последний список в случае двусвязного списка.
Основные операции
Ниже приведены важные операции, поддерживаемые циклическим списком.
-
insert — вставляет элемент в начало списка.
-
удалить — удаляет элемент из начала списка.
-
display — отображает список
insert — вставляет элемент в начало списка.
удалить — удаляет элемент из начала списка.
display — отображает список
Операция вставки
Следующий код демонстрирует операцию вставки в круговой связанный список на основе одного связанного списка.
пример
//insert link at the first location void insertFirst(int key, int data) { //create a link struct node *link = (struct node*) malloc(sizeof(struct node)); link->key = key; link->data= data; if (isEmpty()) { head = link; head->next = head; } else { //point it to old first node link->next = head; //point first to new first node head = link; } }
Операция удаления
Следующий код демонстрирует операцию удаления в круговом связанном списке на основе одного связанного списка.
//delete first item struct node * deleteFirst() { //save reference to first link struct node *tempLink = head; if(head->next == head) { head = NULL; return tempLink; } //mark next to first link as first head = head->next; //return the deleted link return tempLink; }
Операция отображения списка
Следующий код демонстрирует операцию отображения списка в виде круглого связанного списка.
//display the list void printList() { struct node *ptr = head; printf("\n[ "); //start from the beginning if(head != NULL) { while(ptr->next != ptr) { printf("(%d,%d) ",ptr->key,ptr->data); ptr = ptr->next; } } printf(" ]"); }
Чтобы узнать о его реализации на языке программирования C, пожалуйста, нажмите здесь .
Структура данных и алгоритмы — стек
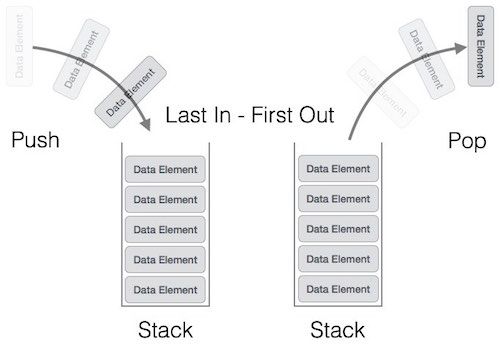
Стек — это абстрактный тип данных (ADT), обычно используемый в большинстве языков программирования. Он называется стеком, так как он ведет себя как реальный стек, например, колода карт или куча тарелок и т. Д.

Реальный стек допускает операции только с одного конца. Например, мы можем поместить или удалить карту или пластину только из верхней части стопки. Аналогично, Stack ADT разрешает все операции с данными только на одном конце. В любой момент времени мы можем получить доступ только к верхнему элементу стека.
Эта особенность делает его структурой данных LIFO. LIFO означает «Последний пришел первым». Здесь элемент, который помещен (вставлен или добавлен) последним, доступен первым. В терминологии стека операция вставки называется операцией PUSH, а операция удаления — операцией POP .
Представление стека
Следующая диаграмма изображает стек и его операции —
Стек может быть реализован с помощью Array, Structure, Pointer и Linked List. Стек может быть фиксированного размера или иметь динамическое изменение размера. Здесь мы собираемся реализовать стек с использованием массивов, что делает его реализацией стека фиксированного размера.
Основные операции
Операции со стеком могут включать инициализацию стека, его использование и затем деинициализацию. Помимо этих основных вещей, стек используется для следующих двух основных операций:
-
push () — Push ( сохранение) элемента в стеке.
-
pop () — Удаление (доступ) элемента из стека.
push () — Push ( сохранение) элемента в стеке.
pop () — Удаление (доступ) элемента из стека.
Когда данные помещаются в стек.
Для эффективного использования стека нам также необходимо проверить состояние стека. Для этой же цели в стеки добавлены следующие функции:
-
peek () — получить верхний элемент данных стека, не удаляя его.
-
isFull () — проверить, заполнен ли стек.
-
isEmpty () — проверить, пуст ли стек.
peek () — получить верхний элемент данных стека, не удаляя его.
isFull () — проверить, заполнен ли стек.
isEmpty () — проверить, пуст ли стек.
Мы всегда поддерживаем указатель на последние данные PUSHed в стеке. Поскольку этот указатель всегда представляет вершину стека, отсюда и название top . Верхний указатель предоставляет верхнее значение стека, фактически не удаляя его.
Сначала мы должны узнать о процедурах для поддержки функций стека —
PEEK ()
Алгоритм функции peek () —
begin procedure peek return stack[top] end procedure
Реализация функции peek () на языке программирования C —
пример
int peek() { return stack[top]; }
полный()
Алгоритм функции isfull () —
begin procedure isfull if top equals to MAXSIZE return true else return false endif end procedure
Реализация функции isfull () на языке программирования C —
пример
bool isfull() { if(top == MAXSIZE) return true; else return false; }
пустой()
Алгоритм функции isempty () —
begin procedure isempty if top less than 1 return true else return false endif end procedure
Реализация функции isempty () в языке программирования C немного отличается. Мы инициализируем вершину в -1, так как индекс в массиве начинается с 0. Поэтому мы проверяем, находится ли вершина ниже нуля или -1, чтобы определить, является ли стек пустым. Вот код —
пример
bool isempty() { if(top == -1) return true; else return false; }
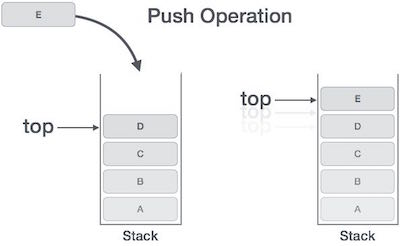
Push Operation
Процесс помещения нового элемента данных в стек известен как операция Push. Push-операция включает в себя ряд шагов —
-
Шаг 1 — Проверяет, заполнен ли стек.
-
Шаг 2 — Если стек заполнен, выдает ошибку и завершается.
-
Шаг 3 — Если стек не заполнен, увеличивается сверху вниз, чтобы указать следующий пустой пробел.
-
Шаг 4 — Добавляет элемент данных в расположение стека, куда указывает верх.
-
Шаг 5 — Возвращает успех.
Шаг 1 — Проверяет, заполнен ли стек.
Шаг 2 — Если стек заполнен, выдает ошибку и завершается.
Шаг 3 — Если стек не заполнен, увеличивается сверху вниз, чтобы указать следующий пустой пробел.
Шаг 4 — Добавляет элемент данных в расположение стека, куда указывает верх.
Шаг 5 — Возвращает успех.
Если связанный список используется для реализации стека, то на шаге 3 нам нужно динамически распределять пространство.
Алгоритм работы PUSH
Простой алгоритм операции Push может быть получен следующим образом:
begin procedure push: stack, data if stack is full return null endif top ← top + 1 stack[top] ← data end procedure
Реализация этого алгоритма на C очень проста. Смотрите следующий код —
пример
void push(int data) { if(!isFull()) { top = top + 1; stack[top] = data; } else { printf("Could not insert data, Stack is full.\n"); } }
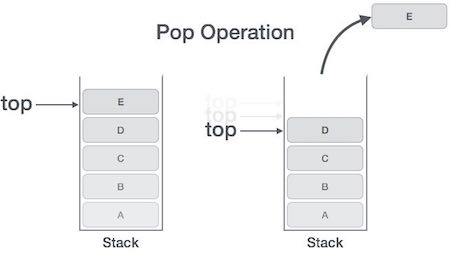
Поп Операция
Доступ к контенту при удалении его из стека известен как операция Pop. В реализации массива операции pop () элемент данных фактически не удаляется, вместо этого верхняя часть уменьшается в нижнюю позицию в стеке, чтобы указывать на следующее значение. Но в реализации связанного списка pop () фактически удаляет элемент данных и освобождает пространство памяти.
Операция Pop может включать следующие шаги:
-
Шаг 1 — Проверяет, пуст ли стек.
-
Шаг 2 — Если стек пуст, выдает ошибку и завершается.
-
Шаг 3 — Если стек не пуст, обращается к элементу данных, на который указывает вершина .
-
Шаг 4 — Уменьшает значение вершины на 1.
-
Шаг 5 — Возвращает успех.
Шаг 1 — Проверяет, пуст ли стек.
Шаг 2 — Если стек пуст, выдает ошибку и завершается.
Шаг 3 — Если стек не пуст, обращается к элементу данных, на который указывает вершина .
Шаг 4 — Уменьшает значение вершины на 1.
Шаг 5 — Возвращает успех.
Алгоритм для поп-операции
Простой алгоритм операции Pop может быть получен следующим образом:
begin procedure pop: stack if stack is empty return null endif data ← stack[top] top ← top - 1 return data end procedure
Реализация этого алгоритма в C, заключается в следующем —
пример
int pop(int data) { if(!isempty()) { data = stack[top]; top = top - 1; return data; } else { printf("Could not retrieve data, Stack is empty.\n"); } }
Для полной программы стека на языке программирования C, пожалуйста, нажмите здесь .
Структура данных — синтаксический анализ выражений
Способ написания арифметического выражения известен как нотация . Арифметическое выражение может быть записано в трех разных, но эквивалентных обозначениях, т. Е. Без изменения сущности или вывода выражения. Эти обозначения —
- Инфиксная нотация
- Префикс (польский)
- Postfix (обратная польская) нотация
Эти обозначения называются как они используют оператор в выражении. Мы узнаем то же самое здесь, в этой главе.
Инфиксная нотация
Мы пишем выражение в инфиксной нотации, например, a — b + c, где операторы используются в- между операндами. Нам, людям, легко читать, писать и говорить в инфиксной записи, но то же самое не подходит для вычислительных устройств. Алгоритм обработки инфиксной записи может быть сложным и дорогостоящим с точки зрения затрат времени и пространства.
Префиксная нотация
В этой записи оператор перед префиксом операнда, т. Е. Оператор записывается перед операндами. Например, + ab . Это эквивалентно его инфиксной записи a + b . Префиксная нотация также известна как польская нотация .
Постфиксная запись
Этот стиль обозначения известен как обратная польская запись. В этом стиле обозначений оператор добавляется после операнда, т. Е. Оператор записывается после операнда. Например, ab & plus; , Это эквивалентно его инфиксной записи a + b .
Следующая таблица кратко пытается показать разницу во всех трех обозначениях —
| Sr.No. | Инфиксная нотация | Префиксная нотация | Постфиксная запись |
|---|---|---|---|
| 1 | а + б | + ab | ab + |
| 2 | (a + b) ∗ c | ∗ + abc | ab + c ∗ |
| 3 | a ∗ (b + c) | ∗ a + bc | abc + ∗ |
| 4 | а / б + ц / д | + / ab / cd | ab / cd / + |
| 5 | (a + b) ∗ (c + d) | ∗ + ab + cd | ab + cd + ∗ |
| 6 | ((a + b) ∗ c) — d | — ∗ + abcd | ab + c ∗ d — |
Разбор выражений
Как мы уже говорили, это не очень эффективный способ разработки алгоритма или программы для анализа инфиксных нотаций. Вместо этого эти инфиксные записи сначала преобразуются в постфиксные или префиксные, а затем вычисляются.
Чтобы разобрать любое арифметическое выражение, нам нужно также позаботиться о приоритете оператора и ассоциативности.
старшинство
Когда операнд находится между двумя разными операторами, какой оператор возьмет операнд первым, определяется приоритетом оператора над другими. Например —

Поскольку операция умножения имеет приоритет перед сложением, b * c будет оцениваться первым. Таблица приоритетов операторов будет предоставлена позже.
Ассоциативность
Ассоциативность описывает правило, в котором операторы с одинаковым приоритетом появляются в выражении. Например, в выражении a + b — c оба + и — имеют одинаковый приоритет, тогда какая часть выражения будет оценена первой, определяется ассоциативностью этих операторов. Здесь и + и — ассоциативно слева, поэтому выражение будет оцениваться как (a + b) — c .
Приоритетность и ассоциативность определяют порядок оценки выражения. Ниже приведена таблица приоритетов операторов и ассоциативности (от высшего к низшему) —
| Sr.No. | оператор | старшинство | Ассоциативность |
|---|---|---|---|
| 1 | Экспонирование | Наибольший | Право Ассоциация |
| 2 | Умножение (∗) и деление (/) | Второй по величине | Левая Ассоциация |
| 3 | Сложение (+) и вычитание (-) | низший | Левая Ассоциация |
В приведенной выше таблице показано поведение операторов по умолчанию. В любой момент времени при вычислении выражения порядок можно изменить с помощью скобок. Например —
В a + b * c часть выражения b * c будет оцениваться первой, с умножением как приоритет над сложением. Здесь мы используем скобки для a + b, которые будут оцениваться первыми, например (a + b) * c .
Постфиксный алгоритм оценки
Теперь мы рассмотрим алгоритм вычисления постфиксной нотации —
Step 1 − scan the expression from left to right Step 2 − if it is an operand push it to stack Step 3 − if it is an operator pull operand from stack and perform operation Step 4 − store the output of step 3, back to stack Step 5 − scan the expression until all operands are consumed Step 6 − pop the stack and perform operation
Чтобы увидеть реализацию на языке программирования C, пожалуйста, нажмите здесь .
Структура данных и алгоритмы — очередь
Очередь — это абстрактная структура данных, несколько похожая на стеки. В отличие от стеков, очередь открыта с обоих концов. Один конец всегда используется для вставки данных (постановка в очередь), а другой — для удаления данных (снятие очереди). Очередь следует методологии «первым пришел — первым обслужен», то есть элемент данных, сохраненный первым, будет доступен первым.
Реальным примером очереди может быть дорога с односторонним движением с односторонним движением, на которой транспортное средство въезжает первым, выезжает первым. Более реальные примеры можно увидеть в виде очередей в кассах и автобусных остановках.
Представление очереди
Как мы теперь понимаем, в очереди мы получаем доступ к обоим концам по разным причинам. Следующая диаграмма, приведенная ниже, пытается объяснить представление очереди как структуру данных —

Как и в стеках, очередь также может быть реализована с использованием массивов, связанных списков, указателей и структур. Для простоты мы будем реализовывать очереди, используя одномерный массив.
Основные операции
Операции с очередями могут включать в себя инициализацию или определение очереди, ее использование, а затем полное удаление из памяти. Здесь мы попытаемся понять основные операции, связанные с очередями —
-
enqueue () — добавить (сохранить) элемент в очередь.
-
dequeue () — удалить (получить доступ) элемент из очереди.
enqueue () — добавить (сохранить) элемент в очередь.
dequeue () — удалить (получить доступ) элемент из очереди.
Еще несколько функций требуется, чтобы сделать вышеупомянутую работу очереди эффективной. Это —
-
peek () — получает элемент в начале очереди, не удаляя его.
-
isfull () — Проверяет, заполнена ли очередь.
-
isempty () — Проверяет, пуста ли очередь.
peek () — получает элемент в начале очереди, не удаляя его.
isfull () — Проверяет, заполнена ли очередь.
isempty () — Проверяет, пуста ли очередь.
В очереди мы всегда удаляем (или обращаемся) к данным, указанным передним указателем, и, помещая в очередь (или сохраняя) данные в очереди, мы обращаемся к заднему указателю.
Давайте сначала узнаем о вспомогательных функциях очереди —
PEEK ()
Эта функция помогает видеть данные в начале очереди. Алгоритм функции peek () выглядит следующим образом:
Алгоритм
begin procedure peek return queue[front] end procedure
Реализация функции peek () на языке программирования C —
пример
int peek() { return queue[front]; }
полный()
Поскольку мы используем массив одного измерения для реализации очереди, мы просто проверяем, чтобы задний указатель достиг MAXSIZE, чтобы определить, что очередь заполнена. Если мы будем поддерживать очередь в круговом связанном списке, алгоритм будет отличаться. Алгоритм функции isfull () —
Алгоритм
begin procedure isfull if rear equals to MAXSIZE return true else return false endif end procedure
Реализация функции isfull () на языке программирования C —
пример
bool isfull() { if(rear == MAXSIZE - 1) return true; else return false; }
пустой()
Алгоритм функции isempty () —
Алгоритм
begin procedure isempty if front is less than MIN OR front is greater than rear return true else return false endif end procedure
Если значение front меньше MIN или 0, это говорит о том, что очередь еще не инициализирована и, следовательно, пуста.
Вот программный код на C —
пример
bool isempty() { if(front < 0 || front > rear) return true; else return false; }
Операция постановки в очередь
Очереди поддерживают два указателя данных, спереди и сзади . Поэтому его операции сравнительно сложны для реализации, чем операции со стеками.
Для постановки (вставки) данных в очередь необходимо предпринять следующие шаги:
-
Шаг 1 — Проверьте, заполнена ли очередь.
-
Шаг 2 — Если очередь заполнена, выведите ошибку переполнения и выйдите.
-
Шаг 3 — Если очередь не заполнена, увеличьте задний указатель, чтобы указать следующий пустой пробел.
-
Шаг 4 — Добавьте элемент данных в расположение очереди, куда указывает указатель.
-
Шаг 5 — верните успех.
Шаг 1 — Проверьте, заполнена ли очередь.
Шаг 2 — Если очередь заполнена, выведите ошибку переполнения и выйдите.
Шаг 3 — Если очередь не заполнена, увеличьте задний указатель, чтобы указать следующий пустой пробел.
Шаг 4 — Добавьте элемент данных в расположение очереди, куда указывает указатель.
Шаг 5 — верните успех.
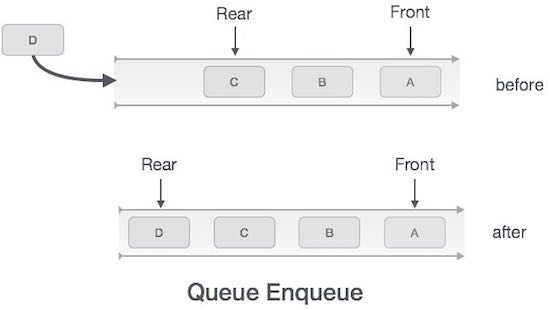
Иногда мы также проверяем, инициализирована или нет очередь, для обработки непредвиденных ситуаций.
Алгоритм постановки в очередь
procedure enqueue(data) if queue is full return overflow endif rear ← rear + 1 queue[rear] ← data return true end procedure
Реализация enqueue () на языке программирования C —
пример
int enqueue(int data) if(isfull()) return 0; rear = rear + 1; queue[rear] = data; return 1; end procedure
Операция Dequeue
Доступ к данным из очереди представляет собой процесс двух задач — получить доступ к данным, куда указывает фронт, и удалить данные после доступа. Для выполнения операции удаления очереди предпринимаются следующие шаги:
-
Шаг 1 — Проверьте, если очередь пуста.
-
Шаг 2 — Если очередь пуста, выдайте ошибку недостаточного значения и выйдите.
-
Шаг 3 — Если очередь не пуста, получите доступ к данным, куда указывает фронт .
-
Шаг 4 — Увеличьте передний указатель, чтобы он указывал на следующий доступный элемент данных.
-
Шаг 5 — Верните успех.
Шаг 1 — Проверьте, если очередь пуста.
Шаг 2 — Если очередь пуста, выдайте ошибку недостаточного значения и выйдите.
Шаг 3 — Если очередь не пуста, получите доступ к данным, куда указывает фронт .
Шаг 4 — Увеличьте передний указатель, чтобы он указывал на следующий доступный элемент данных.
Шаг 5 — Верните успех.
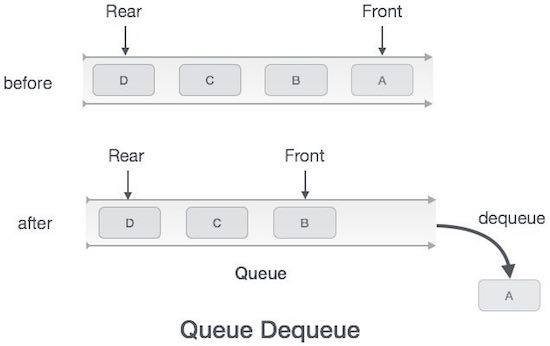
Алгоритм работы с дежурной
procedure dequeue if queue is empty return underflow end if data = queue[front] front ← front + 1 return true end procedure
Реализация dequeue () на языке программирования C —
пример
int dequeue() { if(isempty()) return 0; int data = queue[front]; front = front + 1; return data; }
Для полной программы Queue на языке программирования C, пожалуйста, нажмите здесь .
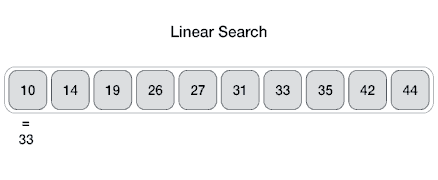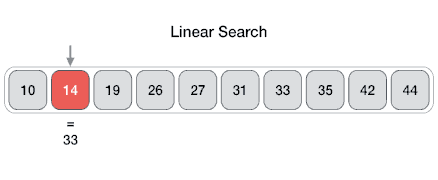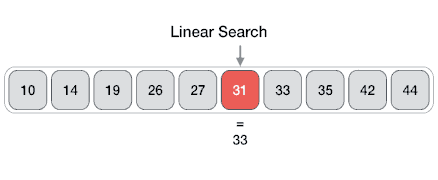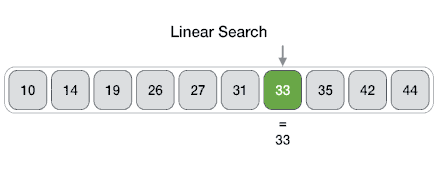
Структура данных и алгоритмы линейного поиска
Линейный поиск — очень простой алгоритм поиска. В этом типе поиска последовательный поиск выполняется по всем элементам один за другим. Каждый элемент проверяется, и если совпадение найдено, то этот конкретный элемент возвращается, в противном случае поиск продолжается до конца сбора данных.
Алгоритм
Linear Search ( Array A, Value x) Step 1: Set i to 1 Step 2: if i > n then go to step 7 Step 3: if A[i] = x then go to step 6 Step 4: Set i to i + 1 Step 5: Go to Step 2 Step 6: Print Element x Found at index i and go to step 8 Step 7: Print element not found Step 8: Exit
ПСЕВДОКОД
procedure linear_search (list, value) for each item in the list if match item == value return the item's location end if end for end procedure
Чтобы узнать о реализации линейного поиска на языке программирования C, нажмите здесь .
Структура данных и алгоритмы бинарного поиска
Бинарный поиск — это быстрый алгоритм поиска со сложностью во время выполнения Ο (log n). Этот алгоритм поиска работает по принципу «разделяй и властвуй». Для правильной работы этого алгоритма сбор данных должен быть в отсортированной форме.
Бинарный поиск ищет определенный элемент, сравнивая самый средний элемент коллекции. Если совпадение происходит, то возвращается индекс элемента. Если средний элемент больше, чем элемент, то этот элемент ищется во вложенном массиве слева от среднего элемента. В противном случае, элемент ищется во вложенном массиве справа от среднего элемента. Этот процесс продолжается и для подмассива, пока размер подмассива не уменьшится до нуля.
Как работает бинарный поиск?
Чтобы бинарный поиск работал, необходимо отсортировать целевой массив. Мы изучим процесс бинарного поиска на наглядном примере. Ниже представлен наш отсортированный массив, и давайте предположим, что нам нужно найти местоположение значения 31 с помощью бинарного поиска.

Во-первых, мы определим половину массива, используя эту формулу —
mid = low + (high - low) / 2
Вот оно, 0 + (9 — 0) / 2 = 4 (целое значение 4,5). Итак, 4 — середина массива.
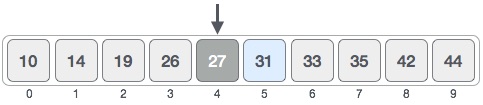
Теперь мы сравниваем значение, хранящееся в местоположении 4, с искомым значением, то есть 31. Мы находим, что значение в местоположении 4 равно 27, что не совпадает. Поскольку значение больше 27, и у нас есть отсортированный массив, мы также знаем, что целевое значение должно находиться в верхней части массива.

Мы меняем наш низкий уровень на средний + 1 и снова находим новое среднее значение.
low = mid + 1 mid = low + (high - low) / 2
Нашей новой середине сейчас 7. Мы сравниваем значение, хранящееся в местоположении 7, с нашим целевым значением 31.
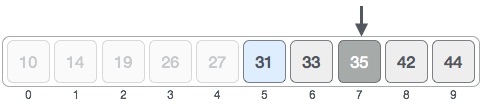
Значение, хранящееся в местоположении 7, не совпадает, а больше, чем мы ищем. Таким образом, значение должно быть в нижней части от этого места.

Следовательно, мы снова вычисляем середину. На этот раз это 5.
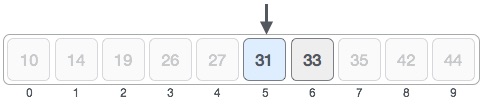
Мы сравниваем значение, хранящееся в местоположении 5, с нашим целевым значением. Мы находим, что это совпадение.

Мы заключаем, что целевое значение 31 хранится в местоположении 5.
Бинарный поиск делит пополам элементы поиска на два и, таким образом, уменьшает количество сравнений до очень меньшего числа.
ПСЕВДОКОД
Псевдокод алгоритмов двоичного поиска должен выглядеть так:
Procedure binary_search A ← sorted array n ← size of array x ← value to be searched Set lowerBound = 1 Set upperBound = n while x not found if upperBound < lowerBound EXIT: x does not exists. set midPoint = lowerBound + ( upperBound - lowerBound ) / 2 if A[midPoint] < x set lowerBound = midPoint + 1 if A[midPoint] > x set upperBound = midPoint - 1 if A[midPoint] = x EXIT: x found at location midPoint end while end procedure
Чтобы узнать о реализации бинарного поиска с использованием массива на языке программирования C, пожалуйста, нажмите здесь .
Структура данных — интерполяционный поиск
Интерполяционный поиск — улучшенный вариант бинарного поиска. Этот алгоритм поиска работает на месте измерения требуемого значения. Для правильной работы этого алгоритма сбор данных должен быть отсортированным и равномерно распределенным.
Бинарный поиск имеет огромное преимущество по временной сложности по сравнению с линейным поиском. Линейный поиск имеет сложность наихудшего случая Ο (n), тогда как бинарный поиск имеет Ο (log n).
Есть случаи, когда местоположение целевых данных может быть известно заранее. Например, в случае телефонного справочника, если мы хотим найти номер телефона Морфия. Здесь линейный поиск и даже бинарный поиск будут казаться медленными, поскольку мы можем напрямую перейти в область памяти, где хранятся имена, начинающиеся с «M».
Позиционирование в бинарном поиске
В бинарном поиске, если требуемые данные не найдены, остальная часть списка делится на две части, нижнюю и верхнюю. Поиск осуществляется в любом из них.




Даже когда данные сортируются, бинарный поиск не использует преимущества для определения положения нужных данных.
Зондирование позиции в интерполяционном поиске
Интерполяционный поиск находит конкретный элемент путем вычисления положения зонда. Первоначально позиция зонда — это позиция самого среднего элемента коллекции.


Если совпадение происходит, то возвращается индекс элемента. Чтобы разбить список на две части, мы используем следующий метод —
mid = Lo + ((Hi - Lo) / (A[Hi] - A[Lo])) * (X - A[Lo]) where − A = list Lo = Lowest index of the list Hi = Highest index of the list A[n] = Value stored at index n in the list
Если средний элемент больше, чем элемент, то позиция зонда снова вычисляется в подмассиве справа от среднего элемента. В противном случае элемент ищется в подмассиве слева от среднего элемента. Этот процесс продолжается и для подмассива, пока размер подмассива не уменьшится до нуля.
Во время выполнения сложность алгоритма интерполяционного поиска составляет Ο (log (log n)) по сравнению с Ο (log n) BST в благоприятных ситуациях.
Алгоритм
Поскольку это импровизация существующего алгоритма BST, мы упоминаем шаги для поиска «целевого» индекса значения данных, используя определение положения —
Step 1 − Start searching data from middle of the list. Step 2 − If it is a match, return the index of the item, and exit. Step 3 − If it is not a match, probe position. Step 4 − Divide the list using probing formula and find the new midle. Step 5 − If data is greater than middle, search in higher sub-list. Step 6 − If data is smaller than middle, search in lower sub-list. Step 7 − Repeat until match.
ПСЕВДОКОД
A → Array list N → Size of A X → Target Value Procedure Interpolation_Search() Set Lo → 0 Set Mid → -1 Set Hi → N-1 While X does not match if Lo equals to Hi OR A[Lo] equals to A[Hi] EXIT: Failure, Target not found end if Set Mid = Lo + ((Hi - Lo) / (A[Hi] - A[Lo])) * (X - A[Lo]) if A[Mid] = X EXIT: Success, Target found at Mid else if A[Mid] < X Set Lo to Mid+1 else if A[Mid] > X Set Hi to Mid-1 end if end if End While End Procedure
Чтобы узнать о реализации интерполяционного поиска на языке программирования C, нажмите здесь .
Структура данных и алгоритмы — хэш-таблица
Хеш-таблица — это структура данных, в которой данные хранятся ассоциативно. В хеш-таблице данные хранятся в формате массива, где каждое значение данных имеет свое уникальное значение индекса. Доступ к данным становится очень быстрым, если мы знаем индекс нужных данных.
Таким образом, он становится структурой данных, в которой операции вставки и поиска выполняются очень быстро независимо от размера данных. Хеш-таблица использует массив в качестве носителя данных и использует технику хеширования для генерации индекса, в который элемент должен быть вставлен или должен быть расположен.
хеширования
Хеширование — это метод для преобразования диапазона значений ключа в диапазон индексов массива. Мы собираемся использовать оператор по модулю, чтобы получить диапазон значений ключа. Рассмотрим пример хеш-таблицы размером 20, и следующие элементы должны быть сохранены. Элемент в формате (ключ, значение).
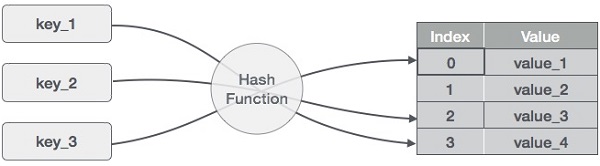
- (1,20)
- (2,70)
- (42,80)
- (4,25)
- (12,44)
- (14,32)
- (17,11)
- (13,78)
- (37,98)
| Sr.No. | ключ | гашиш | Индекс массива |
|---|---|---|---|
| 1 | 1 | 1% 20 = 1 | 1 |
| 2 | 2 | 2% 20 = 2 | 2 |
| 3 | 42 | 42% 20 = 2 | 2 |
| 4 | 4 | 4% 20 = 4 | 4 |
| 5 | 12 | 12% 20 = 12 | 12 |
| 6 | 14 | 14% 20 = 14 | 14 |
| 7 | 17 | 17% 20 = 17 | 17 |
| 8 | 13 | 13% 20 = 13 | 13 |
| 9 | 37 | 37% 20 = 17 | 17 |
Линейное зондирование
Как мы видим, может случиться так, что техника хеширования используется для создания уже используемого индекса массива. В таком случае мы можем искать следующее пустое место в массиве, просматривая следующую ячейку, пока не найдем пустую ячейку. Эта техника называется линейным зондированием.
| Sr.No. | ключ | гашиш | Индекс массива | После линейного зондирования, индекс массива |
|---|---|---|---|---|
| 1 | 1 | 1% 20 = 1 | 1 | 1 |
| 2 | 2 | 2% 20 = 2 | 2 | 2 |
| 3 | 42 | 42% 20 = 2 | 2 | 3 |
| 4 | 4 | 4% 20 = 4 | 4 | 4 |
| 5 | 12 | 12% 20 = 12 | 12 | 12 |
| 6 | 14 | 14% 20 = 14 | 14 | 14 |
| 7 | 17 | 17% 20 = 17 | 17 | 17 |
| 8 | 13 | 13% 20 = 13 | 13 | 13 |
| 9 | 37 | 37% 20 = 17 | 17 | 18 |
Основные операции
Ниже приведены основные основные операции хэш-таблицы.
-
Поиск — поиск элемента в хеш-таблице.
-
Вставить — вставляет элемент в хеш-таблицу.
-
delete — удаляет элемент из хеш-таблицы
Поиск — поиск элемента в хеш-таблице.
Вставить — вставляет элемент в хеш-таблицу.
delete — удаляет элемент из хеш-таблицы
DataItem
Определите элемент данных, имеющий некоторые данные и ключ, на основании которого поиск должен быть выполнен в хеш-таблице.
struct DataItem {
int data;
int key;
};
Метод хеширования
Определите метод хеширования для вычисления хеш-кода ключа элемента данных.
int hashCode(int key){ return key % SIZE; }
Операция поиска
Всякий раз, когда необходимо выполнить поиск элемента, вычислите хеш-код переданного ключа и найдите элемент, используя этот хеш-код в качестве индекса в массиве. Используйте линейное зондирование, чтобы получить элемент вперед, если элемент не найден в вычисленном хэш-коде.
пример
struct DataItem *search(int key) { //get the hash int hashIndex = hashCode(key); //move in array until an empty while(hashArray[hashIndex] != NULL) { if(hashArray[hashIndex]->key == key) return hashArray[hashIndex]; //go to next cell ++hashIndex; //wrap around the table hashIndex %= SIZE; } return NULL; }
Операция вставки
Всякий раз, когда элемент должен быть вставлен, вычислите хеш-код переданного ключа и найдите индекс, используя этот хеш-код в качестве индекса в массиве. Используйте линейное зондирование для пустого местоположения, если элемент найден в вычисленном хэш-коде.
пример
void insert(int key,int data) { struct DataItem *item = (struct DataItem*) malloc(sizeof(struct DataItem)); item->data = data; item->key = key; //get the hash int hashIndex = hashCode(key); //move in array until an empty or deleted cell while(hashArray[hashIndex] != NULL && hashArray[hashIndex]->key != -1) { //go to next cell ++hashIndex; //wrap around the table hashIndex %= SIZE; } hashArray[hashIndex] = item; }
Удалить операцию
Всякий раз, когда элемент должен быть удален, вычислите хеш-код переданного ключа и найдите индекс, используя этот хеш-код в качестве индекса в массиве. Используйте линейное зондирование, чтобы получить элемент вперед, если элемент не найден в вычисленном хэш-коде. Когда найден, храните фиктивный элемент там, чтобы сохранить производительность хэш-таблицы без изменений.
пример
struct DataItem* delete(struct DataItem* item) { int key = item->key; //get the hash int hashIndex = hashCode(key); //move in array until an empty while(hashArray[hashIndex] !=NULL) { if(hashArray[hashIndex]->key == key) { struct DataItem* temp = hashArray[hashIndex]; //assign a dummy item at deleted position hashArray[hashIndex] = dummyItem; return temp; } //go to next cell ++hashIndex; //wrap around the table hashIndex %= SIZE; } return NULL; }
Чтобы узнать о реализации хеша на языке программирования C, пожалуйста, нажмите здесь .
Структура данных — методы сортировки
Сортировка относится к упорядочению данных в определенном формате. Алгоритм сортировки определяет способ упорядочения данных в определенном порядке. Наиболее распространенные заказы в числовом или лексикографическом порядке.
Важность сортировки заключается в том, что поиск данных может быть оптимизирован до очень высокого уровня, если данные хранятся в отсортированном виде. Сортировка также используется для представления данных в более удобочитаемых форматах. Ниже приведены некоторые примеры сортировки в реальных сценариях:
-
Телефонный справочник. В телефонном справочнике хранятся телефонные номера людей, отсортированные по их именам, чтобы их можно было легко найти.
-
Словарь — словарь хранит слова в алфавитном порядке, так что поиск любого слова становится легким.
Телефонный справочник. В телефонном справочнике хранятся телефонные номера людей, отсортированные по их именам, чтобы их можно было легко найти.
Словарь — словарь хранит слова в алфавитном порядке, так что поиск любого слова становится легким.
Сортировка на месте и сортировка на месте
Алгоритмы сортировки могут потребовать дополнительного пространства для сравнения и временного хранения нескольких элементов данных. Эти алгоритмы не требуют дополнительного пространства, и говорят, что сортировка происходит на месте или, например, внутри самого массива. Это называется сортировкой на месте . Пузырьковая сортировка является примером сортировки на месте.
Однако в некоторых алгоритмах сортировки программе требуется пространство, которое больше или равно сортируемым элементам. Сортировка, которая использует одинаковое или большее пространство, называется сортировкой не на месте . Сортировка слиянием является примером сортировки по месту.
Стабильная и не стабильная сортировка
Если алгоритм сортировки после сортировки содержимого не изменяет последовательность аналогичного содержимого, в котором они появляются, это называется стабильной сортировкой .
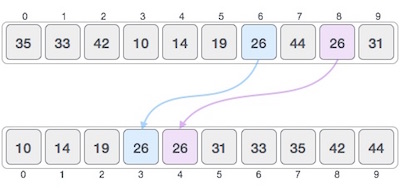
Если алгоритм сортировки после сортировки содержимого изменяет последовательность аналогичного содержимого, в котором они появляются, это называется нестабильной сортировкой .
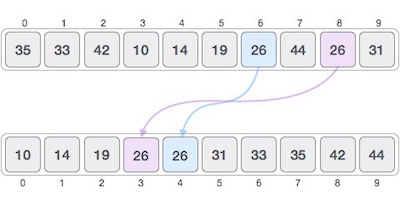
Стабильность алгоритма имеет значение, когда мы хотим сохранить последовательность исходных элементов, например, в кортеже.
Адаптивный и неадаптивный алгоритм сортировки
Алгоритм сортировки называется адаптивным, если он использует преимущества уже «отсортированных» элементов в списке, который должен быть отсортирован. То есть при сортировке, если в исходном списке уже есть какой-то элемент, адаптивные алгоритмы примут это во внимание и постараются не переупорядочивать их.
Неадаптивный алгоритм — это алгоритм, который не учитывает элементы, которые уже отсортированы. Они пытаются принудительно переупорядочить каждый элемент, чтобы подтвердить их сортировку.
Важные условия
Некоторые термины, как правило, придуманы при обсуждении методов сортировки, вот краткое введение к ним —
Увеличение заказа
Считается, что последовательность значений находится в возрастающем порядке , если последующий элемент больше предыдущего. Например, 1, 3, 4, 6, 8, 9 расположены в порядке возрастания, поскольку каждый следующий элемент больше, чем предыдущий элемент.
Уменьшение заказа
Последовательность значений называется в порядке убывания , если последующий элемент меньше текущего. Например, 9, 8, 6, 4, 3, 1 расположены в порядке убывания, так как каждый следующий элемент меньше, чем предыдущий элемент.
Неупорядоченный заказ
Считается, что последовательность значений находится в не возрастающем порядке , если последующий элемент меньше или равен своему предыдущему элементу в последовательности. Этот порядок происходит, когда последовательность содержит повторяющиеся значения. Например, 9, 8, 6, 3, 3, 1 расположены в не возрастающем порядке, поскольку каждый следующий элемент меньше или равен (в случае 3), но не больше, чем любой предыдущий элемент.
Неубывающий Заказ
Считается, что последовательность значений находится в неубывающем порядке , если последующий элемент больше или равен своему предыдущему элементу в последовательности. Этот порядок происходит, когда последовательность содержит повторяющиеся значения. Например, 1, 3, 3, 6, 8, 9 расположены в неубывающем порядке, так как каждый следующий элемент больше или равен (в случае 3), но не меньше, чем предыдущий.
Структура данных — алгоритм пузырьковой сортировки
Пузырьковая сортировка — это простой алгоритм сортировки. Этот алгоритм сортировки является алгоритмом на основе сравнения, в котором сравнивается каждая пара смежных элементов, и элементы меняются местами, если они не в порядке. Этот алгоритм не подходит для больших наборов данных, поскольку его средняя и наихудшая сложность имеют значение Ο (n 2 ), где n — количество элементов.
Как работает Bubble Sort?
Мы берем несортированный массив для нашего примера. Сортировка пузырьков занимает Ο (n 2 ) времени, поэтому мы держим его коротким и точным.

Bubble sort начинается с самых первых двух элементов, сравнивая их, чтобы определить, какой из них больше.

В этом случае значение 33 больше 14, поэтому оно уже находится в отсортированных местоположениях. Далее мы сравниваем 33 с 27.

Мы находим, что 27 меньше 33, и эти два значения необходимо поменять местами.
Новый массив должен выглядеть так —

Далее мы сравниваем 33 и 35. Мы находим, что оба находятся в уже отсортированных позициях.

Затем мы переходим к следующим двум значениям, 35 и 10.

Тогда мы знаем, что 10 меньше 35. Следовательно, они не отсортированы.

Мы поменяем эти значения. Мы находим, что достигли конца массива. После одной итерации массив должен выглядеть так:

Чтобы быть точным, мы сейчас показываем, как должен выглядеть массив после каждой итерации. После второй итерации все должно выглядеть так:

Обратите внимание, что после каждой итерации в конце перемещается как минимум одно значение.
И когда нет необходимости подкачки, пузырьковые сортировки узнают, что массив полностью отсортирован.
Теперь мы должны рассмотреть некоторые практические аспекты пузырьковой сортировки.
Алгоритм
Мы предполагаем, что список — это массив из n элементов. Далее мы предполагаем, что функция swap меняет значения заданных элементов массива.
begin BubbleSort(list) for all elements of list if list[i] > list[i+1] swap(list[i], list[i+1]) end if end for return list end BubbleSort
ПСЕВДОКОД
В алгоритме мы наблюдаем, что Bubble Sort сравнивает каждую пару элементов массива, если весь массив полностью не отсортирован в порядке возрастания. Это может вызвать некоторые проблемы со сложностью, например, что если массив больше не нужно менять, так как все элементы уже восходящие.
Чтобы облегчить проблему, мы используем одну переменную flag swapped, которая поможет нам увидеть, произошел ли какой-либо обмен или нет. Если обмен не произошел, т. Е. Массив не требует дополнительной обработки для сортировки, он выйдет из цикла.
Псевдокод алгоритма BubbleSort можно записать следующим образом:
procedure bubbleSort( list : array of items ) loop = list.count; for i = 0 to loop-1 do: swapped = false for j = 0 to loop-1 do: /* compare the adjacent elements */ if list[j] > list[j+1] then /* swap them */ swap( list[j], list[j+1] ) swapped = true end if end for /*if no number was swapped that means array is sorted now, break the loop.*/ if(not swapped) then break end if end for end procedure return list
Реализация
Еще одна проблема, которую мы не рассмотрели в нашем оригинальном алгоритме и его импровизированном псевдокоде, заключается в том, что после каждой итерации самые высокие значения располагаются в конце массива. Следовательно, следующая итерация не должна включать уже отсортированные элементы. Для этой цели в нашей реализации мы ограничиваем внутренний цикл, чтобы избежать уже отсортированных значений.
Чтобы узнать о реализации пузырьковой сортировки на языке программирования C, пожалуйста, нажмите здесь .
Сортировка структуры данных и алгоритмов
Это алгоритм сортировки на основе сравнения на месте. Здесь поддерживается подсписок, который всегда сортируется. Например, нижняя часть массива поддерживается для сортировки. Элемент, который должен быть «вставлен» в этот отсортированный подсписок, должен найти свое подходящее место, а затем его нужно вставить туда. Отсюда и название, вставка сортировки .
Массив ищется последовательно, а несортированные элементы перемещаются и вставляются в отсортированный подсписок (в том же массиве). Этот алгоритм не подходит для больших наборов данных, поскольку его средняя и наихудшая сложность имеют значение Ο (n 2 ), где n — количество элементов.
Как работает сортировка вставками?
Мы берем несортированный массив для нашего примера.

Сортировка вставки сравнивает первые два элемента.

Он находит, что и 14 и 33 уже в порядке возрастания. На данный момент 14 находится в отсортированном подсписке.

Сортировка вставок продвигается вперед и сравнивает 33 с 27.

И обнаруживает, что 33 не в правильном положении.

Он заменяет 33 на 27. Он также проверяет все элементы отсортированного подсписка. Здесь мы видим, что отсортированный подсписок имеет только один элемент 14, а 27 больше 14. Следовательно, отсортированный подсписок остается отсортированным после замены.

К настоящему времени у нас есть 14 и 27 в отсортированном подсписке. Далее он сравнивает 33 с 10.

Эти значения не в отсортированном порядке.

Таким образом, мы меняем их.

Однако при обмене получается 27 и 10 несортированных.

Следовательно, мы поменяем их тоже.

Снова мы находим 14 и 10 в несортированном порядке.

Мы меняем их снова. К концу третьей итерации у нас есть отсортированный подсписок из 4 элементов.

Этот процесс продолжается до тех пор, пока все несортированные значения не будут включены в отсортированный подсписок. Теперь мы увидим некоторые программные аспекты сортировки вставкой.
Алгоритм
Теперь у нас есть более полное представление о том, как работает этот метод сортировки, поэтому мы можем вывести простые шаги, с помощью которых мы можем добиться сортировки вставками.
Step 1 − If it is the first element, it is already sorted. return 1;
Step 2 − Pick next element
Step 3 − Compare with all elements in the sorted sub-list
Step 4 − Shift all the elements in the sorted sub-list that is greater than the
value to be sorted
Step 5 − Insert the value
Step 6 − Repeat until list is sorted
ПСЕВДОКОД
procedure insertionSort( A : array of items ) int holePosition int valueToInsert for i = 1 to length(A) inclusive do: /* select value to be inserted */ valueToInsert = A[i] holePosition = i /*locate hole position for the element to be inserted */ while holePosition > 0 and A[holePosition-1] > valueToInsert do: A[holePosition] = A[holePosition-1] holePosition = holePosition -1 end while /* insert the number at hole position */ A[holePosition] = valueToInsert end for end procedure
Чтобы узнать о реализации сортировки вставкой на языке программирования C, пожалуйста, нажмите здесь .
Сортировка структуры данных и алгоритмов
Сортировка выбора — это простой алгоритм сортировки. Этот алгоритм сортировки представляет собой алгоритм сравнения на месте, в котором список делится на две части: отсортированная часть на левом конце и несортированная часть на правом конце. Изначально отсортированная часть пуста, а несортированная часть — весь список.
Наименьший элемент выбирается из несортированного массива и заменяется на крайний левый элемент, и этот элемент становится частью отсортированного массива. Этот процесс продолжает перемещать несортированную границу массива на один элемент вправо.
Этот алгоритм не подходит для больших наборов данных, поскольку его средняя и наихудшая сложности имеют значение of (n 2 ), где n — количество элементов.
Как работает сортировка выбора?
Рассмотрим следующий изображенный массив в качестве примера.

Для первой позиции в отсортированном списке весь список сканируется последовательно. Первая позиция, где в настоящее время хранится 14, мы ищем по всему списку и находим, что 10 является самым низким значением.

Таким образом, мы заменяем 14 на 10. После одной итерации 10, которая оказывается минимальным значением в списке, появляется в первой позиции отсортированного списка.

Для второй позиции, где находится 33, мы начинаем сканировать остальную часть списка линейным способом.

Мы находим, что 14 является вторым самым низким значением в списке, и оно должно появиться на втором месте. Мы поменяем эти значения.

После двух итераций два наименьших значения располагаются в начале отсортированным образом.

Тот же процесс применяется к остальным элементам в массиве.
Ниже приведено графическое изображение всего процесса сортировки —
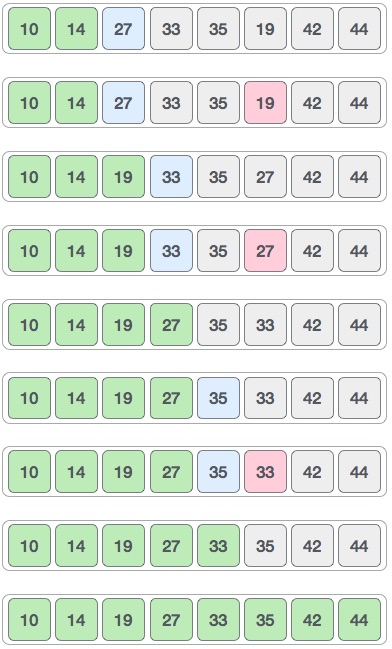
Теперь давайте изучим некоторые программные аспекты сортировки.
Алгоритм
Step 1 − Set MIN to location 0 Step 2 − Search the minimum element in the list Step 3 − Swap with value at location MIN Step 4 − Increment MIN to point to next element Step 5 − Repeat until list is sorted
ПСЕВДОКОД
procedure selection sort list : array of items n : size of list for i = 1 to n - 1 /* set current element as minimum*/ min = i /* check the element to be minimum */ for j = i+1 to n if list[j] < list[min] then min = j; end if end for /* swap the minimum element with the current element*/ if indexMin != i then swap list[min] and list[i] end if end for end procedure
Чтобы узнать о реализации сортировки выбора на языке программирования C, пожалуйста, нажмите здесь .
Структуры данных — алгоритм сортировки слиянием
Сортировка слиянием — это метод сортировки, основанный на технике «разделяй и властвуй». Учитывая сложность времени в худшем случае Ο (n log n), это один из наиболее уважаемых алгоритмов.
Сортировка слиянием сначала делит массив на равные половины, а затем объединяет их отсортированным образом.
Как работает сортировка слиянием?
Чтобы понять сортировку слиянием, мы берем несортированный массив следующим образом:

Мы знаем, что сортировка слиянием сначала делит весь массив итеративно на равные половины, если не достигнуты атомарные значения. Здесь мы видим, что массив из 8 элементов делится на два массива размером 4.

Это не меняет последовательности появления предметов в оригинале. Теперь мы разделим эти два массива пополам.

Далее мы делим эти массивы и получаем атомную ценность, которую больше нельзя разделить.

Теперь мы объединяем их точно так же, как они были разбиты. Обратите внимание на коды цветов, приведенные в этих списках.
Сначала мы сравниваем элемент для каждого списка, а затем сортируем их в другой список. Мы видим, что 14 и 33 находятся в отсортированных позициях. Мы сравниваем 27 и 10 и в целевом списке из 2 значений сначала ставим 10, а затем 27. Мы меняем порядок 19 и 35, тогда как 42 и 44 располагаются последовательно.

На следующей итерации фазы объединения мы сравниваем списки двух значений данных и объединяем их в список найденных значений данных, размещая все в отсортированном порядке.

После окончательного объединения список должен выглядеть так:

Теперь мы должны изучить некоторые программные аспекты сортировки слиянием.
Алгоритм
Сортировка слиянием продолжает делить список на равные половины, пока он больше не может быть разделен. По определению, если это только один элемент в списке, он сортируется. Затем сортировка слиянием объединяет отсортированные списки меньшего размера, сохраняя сортировку нового списка.
Step 1 − if it is only one element in the list it is already sorted, return. Step 2 − divide the list recursively into two halves until it can no more be divided. Step 3 − merge the smaller lists into new list in sorted order.
ПСЕВДОКОД
Теперь мы увидим псевдокоды для функций сортировки слиянием. Поскольку наши алгоритмы указывают на две основные функции — разделяй и объединяй.
Сортировка слиянием работает с рекурсией, и мы увидим нашу реализацию таким же образом.
procedure mergesort( var a as array ) if ( n == 1 ) return a var l1 as array = a[0] ... a[n/2] var l2 as array = a[n/2+1] ... a[n] l1 = mergesort( l1 ) l2 = mergesort( l2 ) return merge( l1, l2 ) end procedure procedure merge( var a as array, var b as array ) var c as array while ( a and b have elements ) if ( a[0] > b[0] ) add b[0] to the end of c remove b[0] from b else add a[0] to the end of c remove a[0] from a end if end while while ( a has elements ) add a[0] to the end of c remove a[0] from a end while while ( b has elements ) add b[0] to the end of c remove b[0] from b end while return c end procedure
Чтобы узнать о реализации сортировки слиянием на языке программирования C, пожалуйста, нажмите здесь .
Сортировка оболочки является высокоэффективным алгоритмом сортировки и основана на алгоритме сортировки вставкой. Этот алгоритм позволяет избежать больших сдвигов, как в случае сортировки вставкой, если меньшее значение находится в крайнем правом положении и должно быть перемещено в крайнее левое положение.
Этот алгоритм использует сортировку вставки для широко распространенных элементов, сначала сортируя их, а затем сортирует менее широко расположенные элементы. Этот интервал называется интервалом . Этот интервал рассчитывается на основе формулы Кнута как —
Формула Кнута
h = h * 3 + 1 where − h is interval with initial value 1
Этот алгоритм достаточно эффективен для наборов данных среднего размера, поскольку его средняя и наихудшая сложность имеют значение Ο (n), где n — количество элементов.
Как работает Shell Sort?
Давайте рассмотрим следующий пример, чтобы понять, как работает сортировка оболочки. Мы берем тот же массив, который мы использовали в наших предыдущих примерах. Для нашего примера и простоты понимания мы берем интервал 4. Составьте виртуальный подсписок всех значений, расположенных с интервалом в 4 позиции. Вот эти значения: {35, 14}, {33, 19}, {42, 27} и {10, 44}
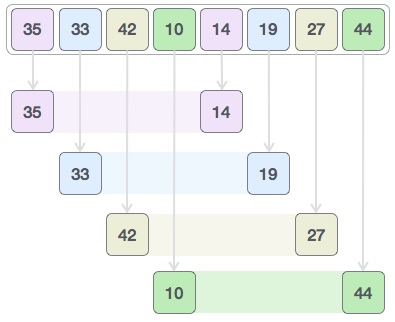
Мы сравниваем значения в каждом подсписке и меняем их (при необходимости) в исходном массиве. После этого шага новый массив должен выглядеть так:

Затем мы берем интервал 2, и этот разрыв создает два подсписка — {14, 27, 35, 42}, {19, 10, 33, 44}
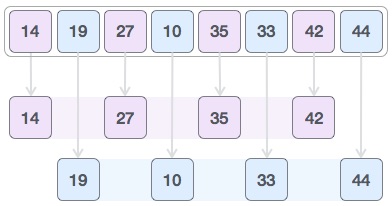
Мы сравниваем и меняем значения, если необходимо, в исходном массиве. После этого шага массив должен выглядеть так:

Наконец, мы сортируем остальную часть массива, используя интервал значения 1. Сортировка оболочки использует сортировку вставкой для сортировки массива.
Ниже приводится пошаговое описание —
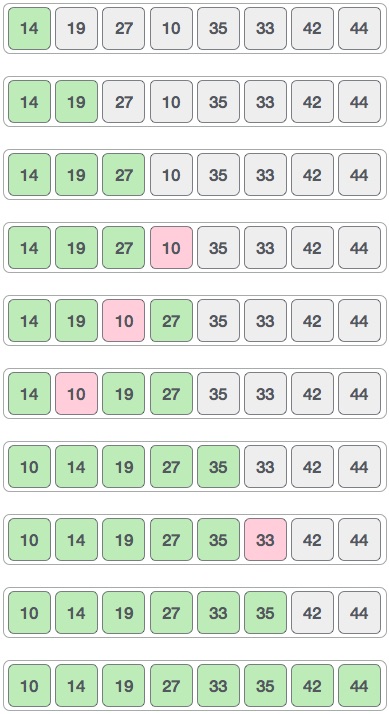
Мы видим, что для сортировки остальной части массива потребовалось всего четыре перестановки.
Алгоритм
Ниже приведен алгоритм сортировки оболочки.
Step 1 − Initialize the value of h Step 2 − Divide the list into smaller sub-list of equal interval h Step 3 − Sort these sub-lists using insertion sort Step 3 − Repeat until complete list is sorted
ПСЕВДОКОД
Ниже приведен псевдокод для сортировки оболочки.
procedure shellSort() A : array of items /* calculate interval*/ while interval < A.length /3 do: interval = interval * 3 + 1 end while while interval > 0 do: for outer = interval; outer < A.length; outer ++ do: /* select value to be inserted */ valueToInsert = A[outer] inner = outer; /*shift element towards right*/ while inner > interval -1 && A[inner - interval] >= valueToInsert do: A[inner] = A[inner - interval] inner = inner - interval end while /* insert the number at hole position */ A[inner] = valueToInsert end for /* calculate interval*/ interval = (interval -1) /3; end while end procedure
Чтобы узнать о реализации сортировки оболочки на языке программирования C, пожалуйста, нажмите здесь .
Структура данных и алгоритмы — Shell Sort
Сортировка оболочки является высокоэффективным алгоритмом сортировки и основана на алгоритме сортировки вставкой. Этот алгоритм позволяет избежать больших сдвигов, как в случае сортировки вставкой, если меньшее значение находится в крайнем правом положении и должно быть перемещено в крайнее левое положение.
Этот алгоритм использует сортировку вставки для широко распространенных элементов, сначала сортируя их, а затем сортирует менее широко расположенные элементы. Этот интервал называется интервалом . Этот интервал рассчитывается на основе формулы Кнута как —
Формула Кнута
h = h * 3 + 1 where − h is interval with initial value 1
Этот алгоритм достаточно эффективен для наборов данных среднего размера, поскольку его средняя и наихудшая сложности этого алгоритма зависят от последовательности промежутков, наиболее известной из которых является Ο (n), где n — количество элементов. И в худшем случае сложность пространства O (n).
Как работает Shell Sort?
Давайте рассмотрим следующий пример, чтобы понять, как работает сортировка оболочки. Мы берем тот же массив, который мы использовали в наших предыдущих примерах. Для нашего примера и простоты понимания мы берем интервал 4. Составьте виртуальный подсписок всех значений, расположенных с интервалом в 4 позиции. Вот эти значения: {35, 14}, {33, 19}, {42, 27} и {10, 44}
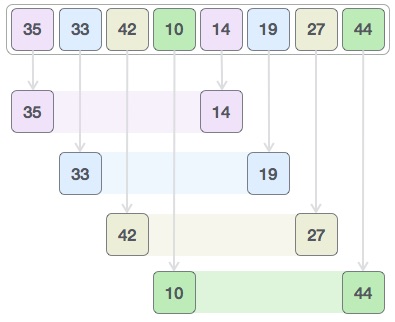
Мы сравниваем значения в каждом подсписке и меняем их (при необходимости) в исходном массиве. После этого шага новый массив должен выглядеть так:

Затем мы берем интервал 1, и этот разрыв генерирует два подсписка — {14, 27, 35, 42}, {19, 10, 33, 44}
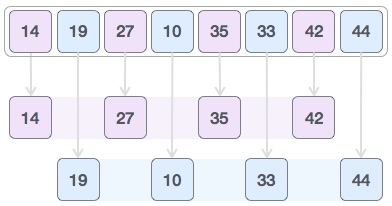
Мы сравниваем и меняем значения, если необходимо, в исходном массиве. После этого шага массив должен выглядеть так:

Наконец, мы сортируем остальную часть массива, используя интервал значения 1. Сортировка оболочки использует сортировку вставкой для сортировки массива.
Ниже приводится пошаговое описание —
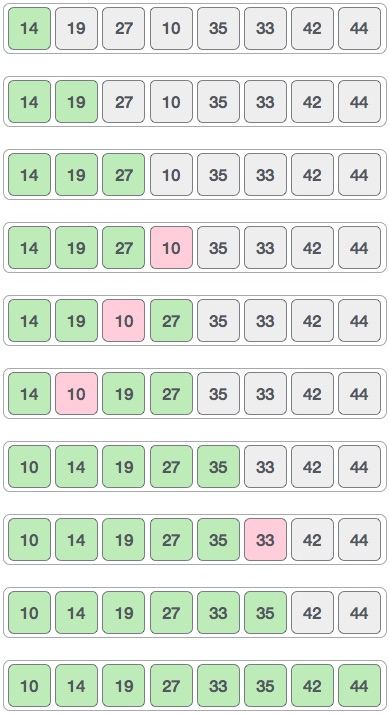
Мы видим, что для сортировки остальной части массива потребовалось всего четыре перестановки.
Алгоритм
Ниже приведен алгоритм сортировки оболочки.
Step 1 − Initialize the value of h Step 2 − Divide the list into smaller sub-list of equal interval h Step 3 − Sort these sub-lists using insertion sort Step 3 − Repeat until complete list is sorted
ПСЕВДОКОД
Ниже приведен псевдокод для сортировки оболочки.
procedure shellSort() A : array of items /* calculate interval*/ while interval < A.length /3 do: interval = interval * 3 + 1 end while while interval > 0 do: for outer = interval; outer < A.length; outer ++ do: /* select value to be inserted */ valueToInsert = A[outer] inner = outer; /*shift element towards right*/ while inner > interval -1 && A[inner - interval] >= valueToInsert do: A[inner] = A[inner - interval] inner = inner - interval end while /* insert the number at hole position */ A[inner] = valueToInsert end for /* calculate interval*/ interval = (interval -1) /3; end while end procedure
Чтобы узнать о реализации сортировки оболочки на языке программирования C, пожалуйста, нажмите здесь .
Структура данных и алгоритмы — Быстрая сортировка
Быстрая сортировка является высокоэффективным алгоритмом сортировки и основана на разбиении массива данных на меньшие массивы. Большой массив разделен на два массива, один из которых содержит значения, меньшие, чем заданное значение, скажем, pivot, на основе которого создано разделение, а другой массив содержит значения, превышающие значение pivot.
Быстрая сортировка разделяет массив, а затем дважды вызывает себя рекурсивно для сортировки двух результирующих подмассивов. Этот алгоритм достаточно эффективен для наборов данных большого размера, поскольку его средняя и наихудшая сложность составляют Ο (n 2 ), где n — количество элементов.
Раздел в быстрой сортировке
Следующее анимированное представление объясняет, как найти значение pivot в массиве.
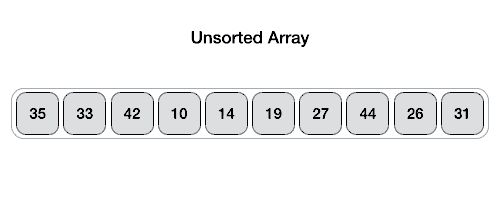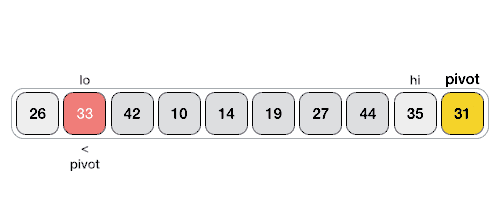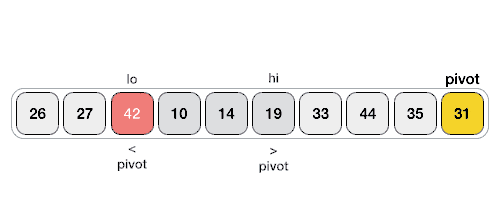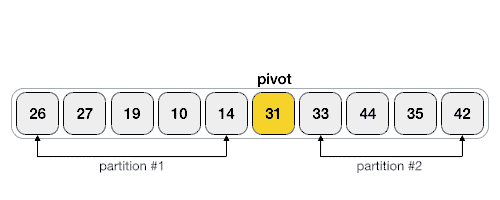
Сводное значение делит список на две части. И рекурсивно мы находим стержень для каждого подсписка, пока все списки не содержат только один элемент.
Алгоритм быстрой сортировки Pivot
Основываясь на нашем понимании разбиения в быстрой сортировке, мы теперь попытаемся написать алгоритм для него, который заключается в следующем.
Step 1 − Choose the highest index value has pivot Step 2 − Take two variables to point left and right of the list excluding pivot Step 3 − left points to the low index Step 4 − right points to the high Step 5 − while value at left is less than pivot move right Step 6 − while value at right is greater than pivot move left Step 7 − if both step 5 and step 6 does not match swap left and right Step 8 − if left ≥ right, the point where they met is new pivot
Quick Sort Pivot Pseudocode
Псевдокод для вышеуказанного алгоритма может быть получен как —
function partitionFunc(left, right, pivot) leftPointer = left rightPointer = right - 1 while True do while A[++leftPointer] < pivot do //do-nothing end while while rightPointer > 0 && A[--rightPointer] > pivot do //do-nothing end while if leftPointer >= rightPointer break else swap leftPointer,rightPointer end if end while swap leftPointer,right return leftPointer end function
Алгоритм быстрой сортировки
Используя рекурсивный алгоритм pivot, мы получаем меньшие возможные разделы. Каждый раздел затем обрабатывается для быстрой сортировки. Определим рекурсивный алгоритм быстрой сортировки следующим образом:
Step 1 − Make the right-most index value pivot Step 2 − partition the array using pivot value Step 3 − quicksort left partition recursively Step 4 − quicksort right partition recursively
Быстрая сортировка псевдокода
Чтобы получить больше, давайте посмотрим псевдокод для алгоритма быстрой сортировки —
procedure quickSort(left, right) if right-left <= 0 return else pivot = A[right] partition = partitionFunc(left, right, pivot) quickSort(left,partition-1) quickSort(partition+1,right) end if end procedure
Чтобы узнать о быстрой реализации сортировки на языке программирования C, пожалуйста, нажмите здесь .
Структура данных — структура данных графика
Граф представляет собой графическое представление набора объектов, где некоторые пары объектов связаны ссылками. Взаимосвязанные объекты представлены точками, называемыми вершинами , а связи, соединяющие вершины, называются ребрами .
Формально граф представляет собой пару множеств (V, E) , где V — множество вершин, а E — множество ребер, соединяющих пары вершин. Посмотрите на следующий график —
На приведенном выше графике
V = {a, b, c, d, e}
E = {ab, ac, bd, cd, de}
Структура данных графика
Математические графики могут быть представлены в структуре данных. Мы можем представить граф, используя массив вершин и двумерный массив ребер. Прежде чем мы продолжим, давайте ознакомимся с некоторыми важными терминами —
-
Вершина — каждый узел графа представлен как вершина. В следующем примере помеченный кружок представляет вершины. Таким образом, от A до G являются вершинами. Мы можем представить их, используя массив, как показано на следующем рисунке. Здесь A можно идентифицировать по индексу 0. B можно идентифицировать по индексу 1 и так далее.
-
Край — Край представляет собой путь между двумя вершинами или линию между двумя вершинами. В следующем примере линии от A до B, B до C и т. Д. Представляют ребра. Мы можем использовать двумерный массив для представления массива, как показано на следующем рисунке. Здесь AB можно представить как 1 в строке 0, столбце 1, BC как 1 в строке 1, столбце 2 и т. Д., Оставив другие комбинации равными 0.
-
Смежность — два узла или вершины являются смежными, если они соединены друг с другом через ребро. В следующем примере B смежен с A, C смежен с B и так далее.
-
Путь — Путь представляет собой последовательность ребер между двумя вершинами. В следующем примере ABCD представляет путь от A до D.
Вершина — каждый узел графа представлен как вершина. В следующем примере помеченный кружок представляет вершины. Таким образом, от A до G являются вершинами. Мы можем представить их, используя массив, как показано на следующем рисунке. Здесь A можно идентифицировать по индексу 0. B можно идентифицировать по индексу 1 и так далее.
Край — Край представляет собой путь между двумя вершинами или линию между двумя вершинами. В следующем примере линии от A до B, B до C и т. Д. Представляют ребра. Мы можем использовать двумерный массив для представления массива, как показано на следующем рисунке. Здесь AB можно представить как 1 в строке 0, столбце 1, BC как 1 в строке 1, столбце 2 и т. Д., Оставив другие комбинации равными 0.
Смежность — два узла или вершины являются смежными, если они соединены друг с другом через ребро. В следующем примере B смежен с A, C смежен с B и так далее.
Путь — Путь представляет собой последовательность ребер между двумя вершинами. В следующем примере ABCD представляет путь от A до D.
Основные операции
Ниже приведены основные основные операции графа —
-
Добавить вершину — добавляет вершину на график.
-
Добавить ребро — добавляет ребро между двумя вершинами графа.
-
Отображать вершину — отображает вершину графика.
Добавить вершину — добавляет вершину на график.
Добавить ребро — добавляет ребро между двумя вершинами графа.
Отображать вершину — отображает вершину графика.
Чтобы узнать больше о графике, пожалуйста, прочитайте учебник теории графов . Мы узнаем о прохождении графа в следующих главах.
Структура данных — первый проход по глубине
Алгоритм поиска в глубину (DFS) пересекает график при движении вглубь и использует стек для запоминания, чтобы получить следующую вершину для начала поиска, когда тупик возникает на любой итерации.
Как и в приведенном выше примере, алгоритм DFS переходит сначала от S к A, от D к G, от E к B, затем к F и, наконец, к C. В нем применяются следующие правила.
-
Правило 1 — Посетите соседнюю не посещенную вершину. Отметить как посещенный Покажите это. Толкните его в стопку.
-
Правило 2 — Если соседняя вершина не найдена, вытащите вершину из стека. (Появятся все вершины из стека, у которых нет смежных вершин.)
-
Правило 3 — Повторяйте Правило 1 и Правило 2, пока стек не опустеет.
Правило 1 — Посетите соседнюю не посещенную вершину. Отметить как посещенный Покажите это. Толкните его в стопку.
Правило 2 — Если соседняя вершина не найдена, вытащите вершину из стека. (Появятся все вершины из стека, у которых нет смежных вершин.)
Правило 3 — Повторяйте Правило 1 и Правило 2, пока стек не опустеет.
| шаг | пересечение | Описание |
|---|---|---|
| 1 |  |
Инициализировать стек. |
| 2 | 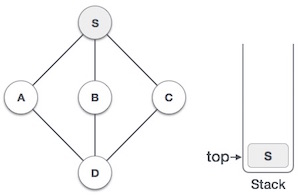 |
Отметьте S как посещенный и поместите его в стек. Исследуйте любой не посещенный соседний узел из S. У нас есть три узла, и мы можем выбрать любой из них. Для этого примера мы возьмем узел в алфавитном порядке. |
| 3 | 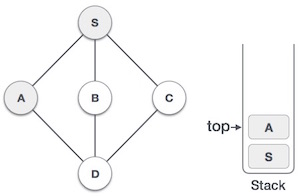 |
Отметьте A как посещенный и поместите его в стек. Исследуйте любой не посещенный соседний узел из A. И S, и D смежны с A, но нас интересуют только не посещенные узлы. |
| 4 | 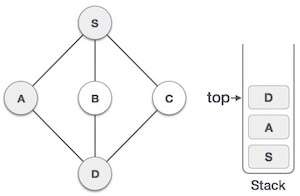 |
Посетите D и отметьте его как посещенный и положите в стек. Здесь у нас есть узлы B и C , которые соседствуют с D и оба не посещаются. Однако мы снова будем выбирать в алфавитном порядке. |
| 5 | 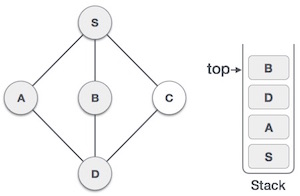 |
Мы выбираем B , отмечаем его как посещенный и помещаем в стек. Здесь B не имеет ни одного не посещенного соседнего узла. Итак, мы выталкиваем B из стека. |
| 6 | 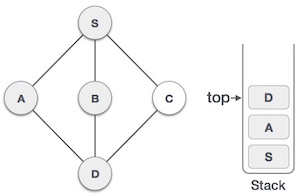 |
Мы проверяем вершину стека на предмет возврата к предыдущему узлу и проверяем, есть ли у него какие-либо не посещенные узлы Здесь мы находим D на вершине стека. |
| 7 | 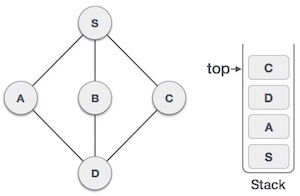 |
Единственный не посещенный соседний узел от D теперь C. Поэтому мы посещаем C , помечаем его как посещенный и помещаем в стек. |
Поскольку C не имеет ни одного не посещенного смежного узла, мы продолжаем выталкивать стек до тех пор, пока не найдем узел, который имеет не посещенный соседний узел. В этом случае их нет, и мы продолжаем появляться, пока стек не опустеет.
Чтобы узнать о реализации этого алгоритма на языке программирования C, нажмите здесь .
Структура данных — первый обход ширины
Алгоритм поиска в ширину (BFS) перебирает график в движении по ширине и использует очередь для запоминания, чтобы получить следующую вершину для начала поиска, когда тупик возникает на любой итерации.
Как и в примере, приведенном выше, алгоритм BFS переходит сначала от A к B, к E к F, затем к C и G, наконец, к D. Он использует следующие правила.
-
Правило 1 — Посетите соседнюю не посещенную вершину. Отметить как посещенный Покажите это. Вставьте его в очередь.
-
Правило 2 — Если соседняя вершина не найдена, удалите первую вершину из очереди.
-
Правило 3 — Повторяйте Правило 1 и Правило 2, пока очередь не станет пустой.
Правило 1 — Посетите соседнюю не посещенную вершину. Отметить как посещенный Покажите это. Вставьте его в очередь.
Правило 2 — Если соседняя вершина не найдена, удалите первую вершину из очереди.
Правило 3 — Повторяйте Правило 1 и Правило 2, пока очередь не станет пустой.
| шаг | пересечение | Описание |
|---|---|---|
| 1 |  |
Инициализируйте очередь. |
| 2 |  |
Мы начинаем с посещения S (начальный узел) и помечаем его как посещенный. |
| 3 | 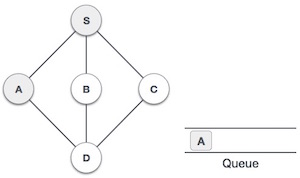 |
Затем мы видим не посещенный соседний узел из S. В этом примере у нас есть три узла, но в алфавитном порядке мы выбираем A , помечаем его как посещенный и ставим в очередь. |
| 4 | 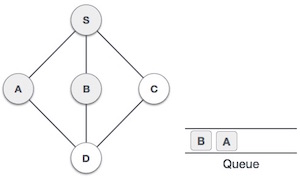 |
Далее, непосещенный соседний узел из S — это B. Мы помечаем его как посещенный и ставим в очередь. |
| 5 | 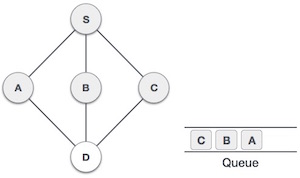 |
Далее, непосещенный соседний узел из S является C. Мы помечаем его как посещенный и ставим в очередь. |
| 6 | 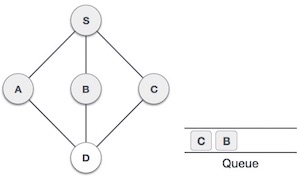 |
Теперь S осталось без невидимых соседних узлов. Итак, мы снимаем с очереди и находим A. |
| 7 | 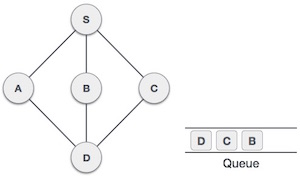 |
Из A мы имеем D как не посещаемый соседний узел. Мы помечаем его как посещенный и ставим в очередь. |
На этом этапе у нас не осталось немаркированных (не посещенных) узлов. Но в соответствии с алгоритмом мы продолжаем отключение, чтобы получить все не посещенные узлы. Когда очередь очищается, программа заканчивается.
Реализацию этого алгоритма на языке C можно увидеть здесь .
Структура данных и алгоритмы — Дерево
Дерево представляет собой узлы, соединенные ребрами. Мы обсудим двоичное дерево или двоичное дерево поиска конкретно.
Двоичное дерево — это специальная структура данных, используемая для хранения данных. Бинарное дерево имеет специальное условие, что каждый узел может иметь максимум двух дочерних элементов. Двоичное дерево имеет преимущества как упорядоченного массива, так и связанного списка, поскольку поиск выполняется так же быстро, как в отсортированном массиве, а операции вставки или удаления выполняются так же быстро, как и в связанном списке.
Важные условия
Ниже приведены важные термины относительно дерева.
-
Путь — путь относится к последовательности узлов по краям дерева.
-
Корень — узел в верхней части дерева называется корнем. Существует только один корень на дерево и один путь от корневого узла к любому узлу.
-
Родитель — Любой узел, кроме корневого, имеет один край вверх к узлу, называемому родительским.
-
Дочерний — узел ниже заданного узла, соединенного его ребром вниз, называется его дочерним узлом.
-
Лист — узел, у которого нет дочернего узла, называется листовым узлом.
-
Поддерево — Поддерево представляет потомков узла.
-
Посещение — Посещение относится к проверке значения узла, когда управление находится на узле.
-
Обход — Обход означает прохождение через узлы в определенном порядке.
-
Уровни — Уровень узла представляет генерацию узла. Если корневой узел находится на уровне 0, то его следующий дочерний узел находится на уровне 1, его внук — на уровне 2 и т. Д.
-
keys — Key представляет значение узла, на основе которого должна выполняться операция поиска для узла.
Путь — путь относится к последовательности узлов по краям дерева.
Корень — узел в верхней части дерева называется корнем. Существует только один корень на дерево и один путь от корневого узла к любому узлу.
Родитель — Любой узел, кроме корневого, имеет один край вверх к узлу, называемому родительским.
Дочерний — узел ниже заданного узла, соединенного его ребром вниз, называется его дочерним узлом.
Лист — узел, у которого нет дочернего узла, называется листовым узлом.
Поддерево — Поддерево представляет потомков узла.
Посещение — Посещение относится к проверке значения узла, когда управление находится на узле.
Обход — Обход означает прохождение через узлы в определенном порядке.
Уровни — Уровень узла представляет генерацию узла. Если корневой узел находится на уровне 0, то его следующий дочерний узел находится на уровне 1, его внук — на уровне 2 и т. Д.
keys — Key представляет значение узла, на основе которого должна выполняться операция поиска для узла.
Представление дерева двоичного поиска
Дерево бинарного поиска обладает особым поведением. Левый потомок узла должен иметь значение меньше значения его родителя, а правый потомок узла должен иметь значение больше, чем значение его родителя.
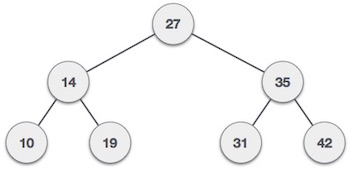
Мы собираемся реализовать дерево, используя объект узла и соединяя их через ссылки.
Узел дерева
Код для написания узла дерева будет похож на приведенный ниже. Он имеет часть данных и ссылки на его левый и правый дочерние узлы.
struct node { int data; struct node *leftChild; struct node *rightChild; };
В дереве все узлы имеют общую конструкцию.
BST Основные операции
Основные операции, которые могут быть выполнены над структурой данных бинарного дерева поиска, следующие:
-
Вставить — вставляет элемент в дерево / создает дерево.
-
Поиск — поиск элемента в дереве.
-
Preorder Traversal — обход дерева по предзаказу.
-
Inorder Traversal — обход дерева по порядку.
-
Postorder Traversal — обход дерева по порядку заказа.
Вставить — вставляет элемент в дерево / создает дерево.
Поиск — поиск элемента в дереве.
Preorder Traversal — обход дерева по предзаказу.
Inorder Traversal — обход дерева по порядку.
Postorder Traversal — обход дерева по порядку заказа.
Мы научимся создавать (вставлять в) древовидную структуру и искать элемент данных в дереве в этой главе. Мы узнаем о методах обхода дерева в следующей главе.
Операция вставки
Самая первая вставка создает дерево. После этого всякий раз, когда необходимо вставить элемент, сначала найдите его правильное местоположение. Начните поиск с корневого узла, затем, если данные меньше значения ключа, найдите пустое место в левом поддереве и вставьте данные. В противном случае найдите пустое место в правом поддереве и вставьте данные.
Алгоритм
If root is NULL then create root node return If root exists then compare the data with node.data while until insertion position is located If data is greater than node.data goto right subtree else goto left subtree endwhile insert data end If
Реализация
Реализация функции вставки должна выглядеть так:
void insert(int data) { struct node *tempNode = (struct node*) malloc(sizeof(struct node)); struct node *current; struct node *parent; tempNode->data = data; tempNode->leftChild = NULL; tempNode->rightChild = NULL; //if tree is empty, create root node if(root == NULL) { root = tempNode; } else { current = root; parent = NULL; while(1) { parent = current; //go to left of the tree if(data < parent->data) { current = current->leftChild; //insert to the left if(current == NULL) { parent->leftChild = tempNode; return; } } //go to right of the tree else { current = current->rightChild; //insert to the right if(current == NULL) { parent->rightChild = tempNode; return; } } } } }
Операция поиска
Всякий раз, когда необходимо выполнить поиск элемента, начинайте поиск с корневого узла, затем, если данные меньше значения ключа, ищите элемент в левом поддереве. В противном случае ищите элемент в правом поддереве. Следуйте тому же алгоритму для каждого узла.
Алгоритм
If root.data is equal to search.data return root else while data not found If data is greater than node.data goto right subtree else goto left subtree If data found return node endwhile return data not found end if
Реализация этого алгоритма должна выглядеть следующим образом.
struct node* search(int data) { struct node *current = root; printf("Visiting elements: "); while(current->data != data) { if(current != NULL) printf("%d ",current->data); //go to left tree if(current->data > data) { current = current->leftChild; } //else go to right tree else { current = current->rightChild; } //not found if(current == NULL) { return NULL; } return current; } }
Чтобы узнать о реализации структуры данных бинарного дерева поиска, нажмите здесь .
Структура данных и алгоритмы — обход дерева
Обход — это процесс, который посещает все узлы дерева и может также печатать их значения. Поскольку все узлы связаны через ребра (ссылки), мы всегда начинаем с корневого (головного) узла. То есть мы не можем получить произвольный доступ к узлу в дереве. Есть три способа прохождения дерева:
- Порядок обхода
- Предварительный заказ обхода
- Обход после заказа
Как правило, мы пересекаем дерево, чтобы найти или найти данный элемент или ключ в дереве или распечатать все содержащиеся в нем значения.
Порядок обхода
В этом методе обхода сначала посещается левое поддерево, затем корень, а затем правое поддерево. Мы всегда должны помнить, что каждый узел может представлять само поддерево.
Если двоичное дерево просматривается по порядку , выходные данные будут генерировать отсортированные значения ключа в порядке возрастания.
Мы начинаем с A и, следуя по порядку, переходим к его левому поддереву B. B также пройден по порядку. Процесс продолжается до тех пор, пока не будут посещены все узлы. Вывод обхода этого дерева по порядку будет —
D → B → E → A → F → C → G
Алгоритм
Until all nodes are traversed − Step 1 − Recursively traverse left subtree. Step 2 − Visit root node. Step 3 − Recursively traverse right subtree.
Предварительный заказ обхода
В этом методе обхода сначала посещается корневой узел, затем левое поддерево и, наконец, правое поддерево.
Мы начинаем с A и, следуя предварительному заказу, сначала посещаем саму A , а затем перемещаемся в его левое поддерево B. B также пройден предварительный заказ. Процесс продолжается до тех пор, пока не будут посещены все узлы. Вывод обхода предзаказа этого дерева будет —
A → B → D → E → C → F → G
Алгоритм
Until all nodes are traversed − Step 1 − Visit root node. Step 2 − Recursively traverse left subtree. Step 3 − Recursively traverse right subtree.
Обход после заказа
В этом методе обхода корневой узел посещается последним, отсюда и имя. Сначала мы пересекаем левое поддерево, затем правое поддерево и, наконец, корневой узел.
Мы начинаем с A , и после прохождения Post-order мы сначала посещаем левое поддерево B. B также пройден после заказа. Процесс продолжается до тех пор, пока не будут посещены все узлы. Результат пост-обхода этого дерева будет —
D → E → B → F → G → C → A
Алгоритм
Until all nodes are traversed − Step 1 − Recursively traverse left subtree. Step 2 − Recursively traverse right subtree. Step 3 − Visit root node.
Чтобы проверить реализацию обхода дерева в C, нажмите здесь .
Структура данных — двоичное дерево поиска
Двоичное дерево поиска (BST) — это дерево, в котором все узлы следуют указанным ниже свойствам:
-
Левое поддерево узла имеет ключ, меньший или равный ключу его родительского узла.
-
Правое поддерево узла имеет ключ больше, чем ключ его родительского узла.
Левое поддерево узла имеет ключ, меньший или равный ключу его родительского узла.
Правое поддерево узла имеет ключ больше, чем ключ его родительского узла.
Таким образом, BST делит все свои поддеревья на два сегмента; левое поддерево и правое поддерево и может быть определено как —
left_subtree (keys) ≤ node (key) ≤ right_subtree (keys)
Представление
BST — это набор узлов, расположенных таким образом, что они поддерживают свойства BST. Каждый узел имеет ключ и соответствующее значение. При поиске нужный ключ сравнивается с ключами в BST, и, если он найден, извлекается соответствующее значение.
Ниже приведено графическое представление BST —
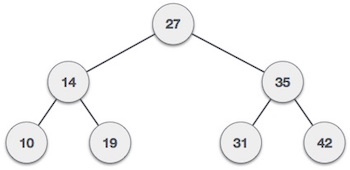
Мы видим, что ключ корневого узла (27) имеет все менее значимые ключи в левом поддереве и более значимые ключи в правом поддереве.
Основные операции
Ниже приведены основные операции дерева —
-
Поиск — поиск элемента в дереве.
-
Вставить — вставляет элемент в дерево.
-
Предзаказ обхода — обход дерева по предзаказу.
-
Порядок обхода — обход дерева по порядку.
-
Post-order Traversal — обход дерева по порядку.
Поиск — поиск элемента в дереве.
Вставить — вставляет элемент в дерево.
Предзаказ обхода — обход дерева по предзаказу.
Порядок обхода — обход дерева по порядку.
Post-order Traversal — обход дерева по порядку.
Узел
Определите узел, имеющий некоторые данные, ссылки на его левый и правый дочерние узлы.
struct node { int data; struct node *leftChild; struct node *rightChild; };
Операция поиска
Всякий раз, когда необходимо выполнить поиск элемента, начинайте поиск с корневого узла. Затем, если данные меньше значения ключа, найдите элемент в левом поддереве. В противном случае ищите элемент в правом поддереве. Следуйте тому же алгоритму для каждого узла.
Алгоритм
struct node* search(int data){ struct node *current = root; printf("Visiting elements: "); while(current->data != data){ if(current != NULL) { printf("%d ",current->data); //go to left tree if(current->data > data){ current = current->leftChild; } //else go to right tree else { current = current->rightChild; } //not found if(current == NULL){ return NULL; } } } return current; }
Операция вставки
Всякий раз, когда элемент должен быть вставлен, сначала найдите его правильное местоположение. Начните поиск с корневого узла, затем, если данные меньше значения ключа, найдите пустое место в левом поддереве и вставьте данные. В противном случае найдите пустое место в правом поддереве и вставьте данные.
Алгоритм
void insert(int data) { struct node *tempNode = (struct node*) malloc(sizeof(struct node)); struct node *current; struct node *parent; tempNode->data = data; tempNode->leftChild = NULL; tempNode->rightChild = NULL; //if tree is empty if(root == NULL) { root = tempNode; } else { current = root; parent = NULL; while(1) { parent = current; //go to left of the tree if(data < parent->data) { current = current->leftChild; //insert to the left if(current == NULL) { parent->leftChild = tempNode; return; } } //go to right of the tree else { current = current->rightChild; //insert to the right if(current == NULL) { parent->rightChild = tempNode; return; } } } } }
Структура данных и алгоритмы — деревья AVL
Что если вход в двоичное дерево поиска поступает отсортированным (по возрастанию или по убыванию) образом? Тогда это будет выглядеть так —
Замечено, что производительность BST в худшем случае наиболее близка к алгоритмам линейного поиска, то есть Ο (n). В данных в реальном времени мы не можем предсказать структуру данных и их частоту. Таким образом, возникает необходимость сбалансировать существующий BST.
Названные в честь их изобретателя Adelson , Velski & Landis , деревья AVL представляют собой бинарное дерево поиска с балансировкой высоты. Дерево AVL проверяет высоту левого и правого поддеревьев и гарантирует, что разница не превышает 1. Эта разница называется коэффициентом баланса .
Здесь мы видим, что первое дерево сбалансировано, а следующие два дерева не сбалансированы —
Во втором дереве левое поддерево C имеет высоту 2, а правое поддерево имеет высоту 0, поэтому разница составляет 2. В третьем дереве правое поддерево A имеет высоту 2, а левое отсутствует, поэтому оно равно 0 и снова разница 2. Дерево AVL допускает разницу (коэффициент баланса) только в 1.
BalanceFactor = height(left-sutree) − height(right-sutree)
Если разница в высоте левого и правого поддеревьев превышает 1, дерево уравновешивается с использованием некоторых методов поворота.
AVL Rotations
Чтобы сбалансировать себя, дерево AVL может выполнять следующие четыре вида вращений:
- Левый поворот
- Правое вращение
- Вращение влево-вправо
- Вращение вправо-влево
Первые два вращения — это одиночные вращения, а следующие два вращения — двойные вращения. Чтобы иметь несбалансированное дерево, нам нужно, по крайней мере, дерево высоты 2. С этим простым деревом, давайте разберемся с ними один за другим.
Левый поворот
Если дерево становится неуравновешенным, когда узел вставляется в правое поддерево правого поддерева, мы выполняем одиночное вращение влево —
В нашем примере узел A стал неуравновешенным, поскольку узел вставлен в правое поддерево правого поддерева A. Мы выполняем вращение влево, делая A левым поддеревом B.
Правое вращение
Дерево AVL может стать несбалансированным, если узел вставлен в левое поддерево левого поддерева. Дерево тогда нуждается в правильном вращении.
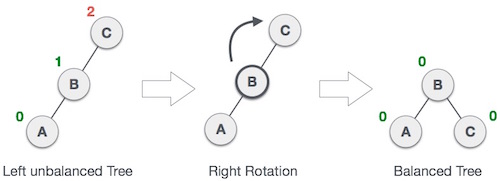
Как изображено, несбалансированный узел становится правым потомком своего левого потомка, выполняя правое вращение.
Вращение вправо-влево
Двойные повороты — немного сложная версия уже объясненных версий поворотов. Чтобы понять их лучше, мы должны принять к сведению каждое действие, выполненное во время вращения. Давайте сначала проверим, как выполнить вращение влево-вправо. Поворот влево-вправо — это комбинация вращения влево, за которым следует поворот вправо.
| государственный | действие |
|---|---|
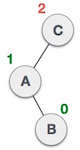 |
Узел был вставлен в правое поддерево левого поддерева. Это делает C несбалансированным узлом. Эти сценарии заставляют дерево AVL выполнять вращение влево-вправо. |
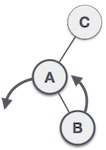 |
Сначала мы выполняем левый поворот на левом поддереве C. Это делает A , левое поддерево B. |
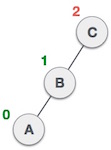 |
Узел C все еще не сбалансирован, однако теперь это происходит из-за левого поддерева левого поддерева. |
 |
Теперь мы повернем дерево вправо, сделав B новым корневым узлом этого поддерева. C теперь становится правым поддеревом своего собственного левого поддерева. |
 |
Дерево теперь сбалансировано. |
Вращение вправо-влево
Второй тип двойного вращения — вращение вправо-влево. Это комбинация правого вращения с последующим левым вращением.
| государственный | действие |
|---|---|
 |
Узел был вставлен в левое поддерево правого поддерева. Это делает A несбалансированным узлом с коэффициентом баланса 2. |
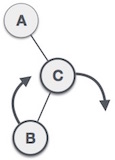 |
Сначала мы выполняем правое вращение вдоль узла C , делая C правым поддеревом своего собственного левого поддерева B. Теперь B становится правильным поддеревом A. |
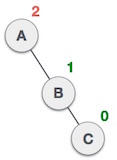 |
Узел A все еще не сбалансирован из-за правого поддерева своего правого поддерева и требует левого поворота. |
 |
Поворот влево выполняется путем создания B новым корневым узлом поддерева. A становится левым поддеревом своего правого поддерева B. |
 |
Дерево теперь сбалансировано. |
Структура данных и алгоритмы — связующее дерево
Покрывающее дерево — это подмножество графа G, в котором все вершины покрыты минимально возможным числом ребер. Следовательно, связующее дерево не имеет циклов и не может быть отключено.
По этому определению можно сделать вывод, что у каждого связного и ненаправленного графа G есть хотя бы одно остовное дерево. Несвязанный граф не имеет никакого остовного дерева, так как он не может быть разбит на все его вершины.
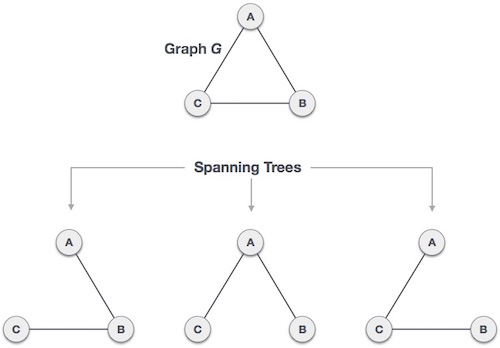
Мы нашли три остовных дерева на одном полном графе. Полный неориентированный граф может иметь максимальное количество n -2 связующих деревьев, где n — количество узлов. В приведенном выше примере n равно 3, поэтому возможны 3 3-2 = 3 остовных дерева.
Общие свойства связующего дерева
Теперь мы понимаем, что один граф может иметь более одного связующего дерева. Ниже приведены несколько свойств связующего дерева, связанного с графом G:
-
Связный граф G может иметь более одного связующего дерева.
-
Все возможные остовные деревья графа G имеют одинаковое количество ребер и вершин.
-
В связующем дереве нет циклов (циклов).
-
Удаление одного ребра из связующего дерева приведет к отключению графа, то есть связующее дерево будет минимально связным .
-
Добавление одного ребра в связующее дерево создаст схему или петлю, то есть связующее дерево будет максимально ациклическим .
Связный граф G может иметь более одного связующего дерева.
Все возможные остовные деревья графа G имеют одинаковое количество ребер и вершин.
В связующем дереве нет циклов (циклов).
Удаление одного ребра из связующего дерева приведет к отключению графа, то есть связующее дерево будет минимально связным .
Добавление одного ребра в связующее дерево создаст схему или петлю, то есть связующее дерево будет максимально ациклическим .
Математические свойства связующего дерева
-
Остовное дерево имеет n-1 ребер, где n — количество узлов (вершин).
-
Из полного графа, удалив максимум e — n + 1 ребер, мы можем построить остовное дерево.
-
Полный граф может иметь максимальное количество n-2 связующих деревьев.
Остовное дерево имеет n-1 ребер, где n — количество узлов (вершин).
Из полного графа, удалив максимум e — n + 1 ребер, мы можем построить остовное дерево.
Полный граф может иметь максимальное количество n-2 связующих деревьев.
Таким образом, можно сделать вывод, что остовные деревья являются подмножеством связного графа G, а несвязные графы не имеют остовного дерева.
Применение связующего дерева
Связующее дерево в основном используется, чтобы найти минимальный путь для соединения всех узлов в графе. Обычное применение связующих деревьев —
-
Планирование гражданской сети
-
Протокол маршрутизации компьютерной сети
-
Кластерный анализ
Планирование гражданской сети
Протокол маршрутизации компьютерной сети
Кластерный анализ
Позвольте нам понять это на небольшом примере. Рассмотрим городскую сеть как огромный график и теперь планируем развернуть телефонные линии таким образом, чтобы в минимальных линиях мы могли подключаться ко всем городским узлам. Это где связующее дерево входит в картину.
Минимальное связующее дерево (MST)
В взвешенном графе минимальное остовное дерево — это остовное дерево, которое имеет минимальный вес, чем все остальные остовные деревья того же графа. В реальных ситуациях этот вес может быть измерен как расстояние, затор, транспортная нагрузка или любое произвольное значение, обозначенное по краям.
Минимальный алгоритм связующего дерева
Мы узнаем о двух наиболее важных алгоритмах связующего дерева здесь —
Оба являются жадными алгоритмами.
Структуры данных кучи
Куча — это особый случай сбалансированной структуры данных бинарного дерева, где ключ корневого узла сравнивается с его дочерними элементами и распределяется соответствующим образом. Если α имеет дочерний узел β, то —
ключ (α) ≥ ключ (β)
Поскольку значение parent больше значения child, это свойство генерирует Max Heap . Исходя из этого критерия, куча может быть двух типов:
For Input → 35 33 42 10 14 19 27 44 26 31
Min-Heap — где значение корневого узла меньше или равно одному из его дочерних элементов.
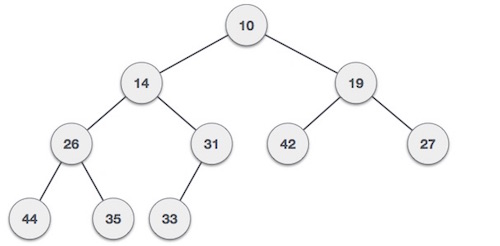
Max-Heap — где значение корневого узла больше или равно одному из его дочерних узлов.
Оба дерева построены с использованием одинакового ввода и порядка прибытия.
Алгоритм построения Max Heap
Мы будем использовать тот же пример, чтобы продемонстрировать, как создается Max Heap. Процедура создания Min Heap похожа, но мы используем минимальные значения вместо максимальных.
Мы собираемся вывести алгоритм для максимальной кучи, вставляя по одному элементу за раз. В любой момент времени куча должна сохранять свою собственность. При вставке мы также предполагаем, что мы вставляем узел в уже кучи дерева.
Step 1 − Create a new node at the end of heap. Step 2 − Assign new value to the node. Step 3 − Compare the value of this child node with its parent. Step 4 − If value of parent is less than child, then swap them. Step 5 − Repeat step 3 & 4 until Heap property holds.
Примечание. В алгоритме построения Min Heap мы ожидаем, что значение родительского узла будет меньше значения дочернего узла.
Давайте разберемся с конструкцией Max Heap по анимированной иллюстрации. Мы рассматриваем ту же исходную выборку, которую использовали ранее.

Макс. Алгоритм удаления кучи
Давайте выведем алгоритм удаления из максимальной кучи. Удаление в Max (или Min) Heap всегда происходит в корне, чтобы удалить максимальное (или минимальное) значение.
Step 1 − Remove root node. Step 2 − Move the last element of last level to root. Step 3 − Compare the value of this child node with its parent. Step 4 − If value of parent is less than child, then swap them. Step 5 − Repeat step 3 & 4 until Heap property holds.

Структура данных — Основы рекурсии
Некоторые языки программирования позволяют самому себе вызывать модуль или функцию. Этот метод известен как рекурсия. В рекурсии функция α либо вызывает себя напрямую, либо вызывает функцию β, которая, в свою очередь, вызывает исходную функцию α . Функция α называется рекурсивной функцией.
Пример — функция, вызывающая себя сама.
int function(int value) { if(value < 1) return; function(value - 1); printf("%d ",value); }
Пример — функция, которая вызывает другую функцию, которая, в свою очередь, вызывает ее снова.
int function1(int value1) { if(value1 < 1) return; function2(value1 - 1); printf("%d ",value1); } int function2(int value2) { function1(value2); }
свойства
Рекурсивная функция может идти бесконечно, как цикл. Чтобы избежать бесконечного запуска рекурсивной функции, есть два свойства, которые должна иметь рекурсивная функция:
-
Базовые критерии — должен быть хотя бы один базовый критерий или условие, чтобы при выполнении этого условия функция перестала вызывать себя рекурсивно.
-
Прогрессивный подход — рекурсивные вызовы должны развиваться таким образом, чтобы каждый раз, когда выполняется рекурсивный вызов, он приближался к базовым критериям.
Базовые критерии — должен быть хотя бы один базовый критерий или условие, чтобы при выполнении этого условия функция перестала вызывать себя рекурсивно.
Прогрессивный подход — рекурсивные вызовы должны развиваться таким образом, чтобы каждый раз, когда выполняется рекурсивный вызов, он приближался к базовым критериям.
Реализация
Многие языки программирования реализуют рекурсию с помощью стеков . Как правило, всякий раз, когда функция ( вызывающая сторона ) вызывает другую функцию ( вызываемую ) или себя в качестве вызываемой, вызывающая функция передает управление выполнением вызываемой стороне. Этот процесс передачи может также включать в себя некоторые данные, которые будут переданы от вызывающего к вызываемому.
Это подразумевает, что вызывающая функция должна временно приостановить свое выполнение и возобновить работу позже, когда управление выполнением вернется из функции вызываемого. Здесь функция вызывающей стороны должна начинаться именно с точки выполнения, где она удерживает себя. Ему также нужны те же значения данных, с которыми он работал. Для этого для функции вызывающей стороны создается запись активации (или кадр стека).
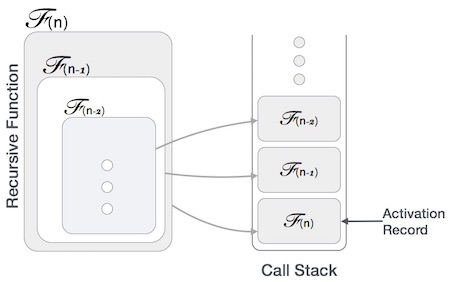
Эта запись активации содержит информацию о локальных переменных, формальных параметрах, адресе возврата и всю информацию, передаваемую функции вызывающей стороны.
Анализ рекурсии
Кто-то может поспорить, зачем использовать рекурсию, поскольку ту же задачу можно выполнить итерацией. Первая причина в том, что рекурсия делает программу более читабельной, а благодаря новейшим улучшенным системам ЦП рекурсия более эффективна, чем итерации.
Сложность времени
В случае итераций мы берем количество итераций для подсчета сложности времени. Аналогично, в случае рекурсии, предполагая, что все постоянно, мы пытаемся выяснить, сколько раз выполняется рекурсивный вызов. Вызов функции — это Ο (1), следовательно, (n) количество повторных вызовов делает рекурсивную функцию Ο (n).
Космическая сложность
Сложность пространства считается как количество дополнительного пространства, необходимого для выполнения модуля. В случае итераций компилятору едва ли требуется дополнительное пространство. Компилятор продолжает обновлять значения переменных, используемых в итерациях. Но в случае рекурсии система должна сохранять запись активации каждый раз, когда выполняется рекурсивный вызов. Следовательно, считается, что пространственная сложность рекурсивной функции может быть выше, чем у функции с итерацией.
Структура данных и алгоритмы — Ханойская башня
Ханойская башня, это математическая головоломка, которая состоит из трех башен (колышков) и более одного кольца, как изображено —
Эти кольца имеют разные размеры и сложены в порядке возрастания, то есть меньшее помещается над большим. Существуют и другие варианты головоломки, в которых количество дисков увеличивается, но количество башен остается неизменным.
правила
Миссия состоит в том, чтобы переместить все диски в какую-то другую башню, не нарушая последовательность расположения. Вот несколько правил, которым нужно следовать для Ханойской башни:
- Только один диск может быть перемещен среди башен в любой момент времени.
- Только «верхний» диск может быть удален.
- Ни один большой диск не может сидеть над маленьким диском.
Ниже приводится анимационное изображение решения головоломки Ханойской башни с тремя дисками.
Загадка Ханойской башни с n дисками может быть решена минимум за 2 n −1 шагов. Эта презентация показывает, что головоломка с 3 дисками прошла 2 3 — 1 = 7 шагов.
Алгоритм
Чтобы написать алгоритм для Ханойской башни, сначала нам нужно научиться решать эту проблему с меньшим количеством дисков, скажем, → 1 или 2. Мы помечаем три башни с именем, источником , местом назначения и вспомогательным (только для перемещения дисков. ). Если у нас есть только один диск, он может быть легко перемещен из исходной точки в точку привязки.
Если у нас есть 2 диска —
- Во-первых, мы перемещаем меньший (верхний) диск в aug peg.
- Затем мы перемещаем больший (нижний) диск в целевой колышек.
- И, наконец, мы перемещаем меньший диск из вспомогательной в конечную привязку.
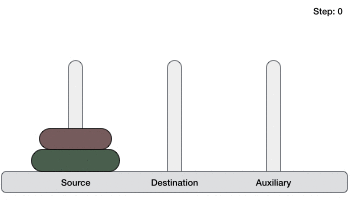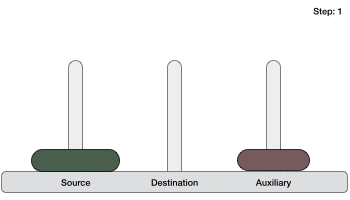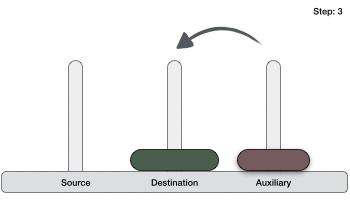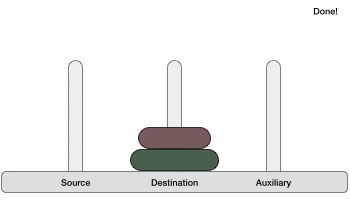
Итак, теперь мы можем разработать алгоритм для Ханойской башни с более чем двумя дисками. Разобьем стек дисков на две части. Самый большой диск (n- й диск) находится в одной части, а все остальные (n-1) — во второй части.
Наша конечная цель — переместить диск n из источника в место назначения, а затем поместить на него все остальные (n1) диски. Мы можем представить, чтобы применить это же рекурсивное решение для всего данного набора дисков.
Следующие шаги —
Step 1 − Move n-1 disks fromsourcetoauxStep 2 − Move n th disk fromsourcetodestStep 3 − Move n-1 disks fromauxtodest
Рекурсивный алгоритм для Ханойской башни может быть реализован следующим образом:
START Procedure Hanoi(disk, source, dest, aux) IF disk == 1, THEN move disk from source to dest ELSE Hanoi(disk - 1, source, aux, dest) // Step 1 move disk from source to dest // Step 2 Hanoi(disk - 1, aux, dest, source) // Step 3 END IF END Procedure STOP
Чтобы проверить реализацию в C-программировании, нажмите здесь .
Структура данных и алгоритмы Фибоначчи
Ряд Фибоначчи генерирует последующее число, добавляя два предыдущих числа. Ряд Фибоначчи начинается с двух чисел — F 0 и F 1 . Начальные значения F 0 и F 1 могут быть приняты 0, 1 или 1, 1 соответственно.
Ряд Фибоначчи удовлетворяет следующим условиям —
F n = F n-1 + F n-2
Следовательно, ряд Фибоначчи может выглядеть так —
F 8 = 0 1 1 2 3 5 8 13
или это —
F 8 = 1 1 2 3 5 8 13 21
В целях иллюстрации Фибоначчи F 8 отображается как —

Итерационный алгоритм Фибоначчи
Сначала мы попытаемся составить итерационный алгоритм для ряда Фибоначчи.
Procedure Fibonacci(n) declare f 0 , f 1 , fib, loop set f 0 to 0 set f 1 to 1 display f 0 , f 1 for loop ← 1 to n fib ← f 0 + f 1 f 0 ← f 1 f 1 ← fib display fib end for end procedure
Чтобы узнать о реализации вышеупомянутого алгоритма на языке программирования C, нажмите здесь .
Рекурсивный алгоритм Фибоначчи
Давайте узнаем, как создать рекурсивный алгоритм ряда Фибоначчи. Базовые критерии рекурсии.
START Procedure Fibonacci(n) declare f 0 , f 1 , fib, loop set f 0 to 0 set f 1 to 1 display f 0 , f 1 for loop ← 1 to n fib ← f 0 + f 1 f 0 ← f 1 f 1 ← fib display fib end for END
Чтобы увидеть реализацию вышеуказанного алгоритма на языке программирования C, нажмите здесь .