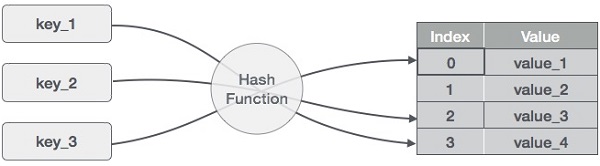
Хеш-таблица — это структура данных, в которой данные хранятся ассоциативно. В хеш-таблице данные хранятся в формате массива, где каждое значение данных имеет свое уникальное значение индекса. Доступ к данным становится очень быстрым, если мы знаем индекс нужных данных.
Таким образом, он становится структурой данных, в которой операции вставки и поиска выполняются очень быстро независимо от размера данных. Хеш-таблица использует массив в качестве носителя данных и использует технику хеширования для генерации индекса, в который элемент должен быть вставлен или должен быть расположен.
хеширования
Хеширование — это метод для преобразования диапазона значений ключа в диапазон индексов массива. Мы собираемся использовать оператор по модулю, чтобы получить диапазон значений ключа. Рассмотрим пример хеш-таблицы размером 20, и следующие элементы должны быть сохранены. Элемент в формате (ключ, значение).
- (1,20)
- (2,70)
- (42,80)
- (4,25)
- (12,44)
- (14,32)
- (17,11)
- (13,78)
- (37,98)
| Sr.No. | ключ | гашиш | Индекс массива |
|---|---|---|---|
| 1 | 1 | 1% 20 = 1 | 1 |
| 2 | 2 | 2% 20 = 2 | 2 |
| 3 | 42 | 42% 20 = 2 | 2 |
| 4 | 4 | 4% 20 = 4 | 4 |
| 5 | 12 | 12% 20 = 12 | 12 |
| 6 | 14 | 14% 20 = 14 | 14 |
| 7 | 17 | 17% 20 = 17 | 17 |
| 8 | 13 | 13% 20 = 13 | 13 |
| 9 | 37 | 37% 20 = 17 | 17 |
Линейное зондирование
Как мы видим, может случиться так, что техника хеширования используется для создания уже используемого индекса массива. В таком случае мы можем искать следующее пустое место в массиве, просматривая следующую ячейку, пока не найдем пустую ячейку. Эта техника называется линейным зондированием.
| Sr.No. | ключ | гашиш | Индекс массива | После линейного зондирования, индекс массива |
|---|---|---|---|---|
| 1 | 1 | 1% 20 = 1 | 1 | 1 |
| 2 | 2 | 2% 20 = 2 | 2 | 2 |
| 3 | 42 | 42% 20 = 2 | 2 | 3 |
| 4 | 4 | 4% 20 = 4 | 4 | 4 |
| 5 | 12 | 12% 20 = 12 | 12 | 12 |
| 6 | 14 | 14% 20 = 14 | 14 | 14 |
| 7 | 17 | 17% 20 = 17 | 17 | 17 |
| 8 | 13 | 13% 20 = 13 | 13 | 13 |
| 9 | 37 | 37% 20 = 17 | 17 | 18 |
Основные операции
Ниже приведены основные основные операции хэш-таблицы.
-
Поиск — поиск элемента в хеш-таблице.
-
Вставить — вставляет элемент в хеш-таблицу.
-
delete — удаляет элемент из хеш-таблицы
Поиск — поиск элемента в хеш-таблице.
Вставить — вставляет элемент в хеш-таблицу.
delete — удаляет элемент из хеш-таблицы
DataItem
Определите элемент данных, имеющий некоторые данные и ключ, на основании которого поиск должен быть выполнен в хеш-таблице.
struct DataItem {
int data;
int key;
};
Метод хеширования
Определите метод хеширования для вычисления хеш-кода ключа элемента данных.
int hashCode(int key){ return key % SIZE; }
Операция поиска
Всякий раз, когда необходимо выполнить поиск элемента, вычислите хеш-код переданного ключа и найдите элемент, используя этот хеш-код в качестве индекса в массиве. Используйте линейное зондирование, чтобы получить элемент вперед, если элемент не найден в вычисленном хэш-коде.
пример
struct DataItem *search(int key) { //get the hash int hashIndex = hashCode(key); //move in array until an empty while(hashArray[hashIndex] != NULL) { if(hashArray[hashIndex]->key == key) return hashArray[hashIndex]; //go to next cell ++hashIndex; //wrap around the table hashIndex %= SIZE; } return NULL; }
Операция вставки
Всякий раз, когда элемент должен быть вставлен, вычислите хеш-код переданного ключа и найдите индекс, используя этот хеш-код в качестве индекса в массиве. Используйте линейное зондирование для пустого местоположения, если элемент найден в вычисленном хэш-коде.
пример
void insert(int key,int data) { struct DataItem *item = (struct DataItem*) malloc(sizeof(struct DataItem)); item->data = data; item->key = key; //get the hash int hashIndex = hashCode(key); //move in array until an empty or deleted cell while(hashArray[hashIndex] != NULL && hashArray[hashIndex]->key != -1) { //go to next cell ++hashIndex; //wrap around the table hashIndex %= SIZE; } hashArray[hashIndex] = item; }
Удалить операцию
Всякий раз, когда элемент должен быть удален, вычислите хеш-код переданного ключа и найдите индекс, используя этот хеш-код в качестве индекса в массиве. Используйте линейное зондирование, чтобы получить элемент вперед, если элемент не найден в вычисленном хэш-коде. Когда найден, храните фиктивный элемент там, чтобы сохранить производительность хэш-таблицы без изменений.
пример
struct DataItem* delete(struct DataItem* item) { int key = item->key; //get the hash int hashIndex = hashCode(key); //move in array until an empty while(hashArray[hashIndex] !=NULL) { if(hashArray[hashIndex]->key == key) { struct DataItem* temp = hashArray[hashIndex]; //assign a dummy item at deleted position hashArray[hashIndex] = dummyItem; return temp; } //go to next cell ++hashIndex; //wrap around the table hashIndex %= SIZE; } return NULL; }
Чтобы узнать о реализации хеша на языке программирования C, пожалуйста, нажмите здесь .