Работающее приложение — это не просто набор кода, он также должен где-то выполняться. Я говорю о ваших производственных серверах. Не менее важно убедиться, что ваши производственные блоки работают сами, так и убедиться, что код вашего приложения работает. Вы можете настроить такие системы, как Nagios, чтобы помочь вам в этом, но они могут быть чрезвычайно сложными для работы, требовать значительной собственной инфраструктуры и могут быть полностью излишними (если ваши потребности в инфраструктуре не слишком сложны). New Relic предоставляет менее полнофункциональную, но очень простую альтернативу, когда дело доходит до мониторинга инфраструктуры.
Если вы читали некоторые из наших предыдущих статей о New Relic , вы должны быть в курсе того, как работают информационные панели New Relic . Панели мониторинга сервера используют те же понятия. Если вы уже используете New Relic, вы можете очень быстро начать получать данные о производительности вашего сервера. Даже если вы ранее не настраивали New Relic, возможно, стоит использовать его только для мониторинга сервера. Шесть или около того панелей, которые предоставляет New Relic, могут значительно отсрочить (или даже полностью удалить) необходимость в более полнофункциональном решении для мониторинга инфраструктуры.
Зачем мне нужен сервис для мониторинга ящиков вообще?
В зависимости от потребностей вашего приложения, у вас может быть веб-компонент, база данных, кеш, поиск, балансировщик нагрузки и т. Д. Некоторые из них могут использовать один и тот же блок. Но как только ваше приложение достигнет определенного размера, вы начнете помещать некоторые из них в свои собственные ящики. Когда у вас только один рабочий сервер, все просто. Вы вводите SSH в это поле , запускаете несколько команд оболочки и получаете довольно хорошее представление о состоянии этого сервера. По мере роста количества коробок это может стать чем-то вроде рутины. Было бы удобно, если бы у вас был способ узнать о здоровье всех ваших коробок одновременно. Именно эту проблему решают информационные панели сервера New Relic. Вы получаете снимок состояния всех ваших производственных серверов одновременно.
Конечно, ручная проверка работоспособности всех ваших серверов — не самая эффективная вещь. Когда что-то идет не так, вы хотите узнать, как только это произойдет, а не в следующий раз, когда вы решите проверить. В большинстве систем мониторинга инфраструктуры есть способ отправлять оповещения, когда определенные части отслеживаемых серверов выходят из строя (например, заполнение диска, использование слишком большого объема ОЗУ и т. Д.). Новая реликвия ничем не отличается. Вы можете использовать очень гибкую инфраструктуру политики предупреждений для отправки уведомлений о сбоях любым удобным для вас способом, таким как электронная почта, веб-перехватчики и т. Д.
Наконец, проблемы инфраструктуры часто не появляются внезапно, важен исторический контекст. ОЗУ будет медленно израсходована в течение нескольких часов, прежде чем коробка начнет выходить из строя, диск заполнится за несколько дней до того, как что-то достигнет цели. Выборочная проверка ваших серверов не дает вам исторического контекста, необходимого для предотвращения возникновения проблем. Если вам случится проверить использование диска, когда он немного заполнится, вы можете что-то с этим сделать. Если нет, вы узнаете о проблеме только тогда, когда ваши коробки умирают. Новая Relic постоянно собирает данные и отправляет их обратно на свои серверы, поэтому все панели мониторинга имеют исторический контекст. Это позволяет легко упреждать определенные классы проблем.
Это работает в реальной жизни
Позвольте мне рассказать вам пару историй. Мы используем New Relic в Tuts + как для мониторинга производительности приложений, так и для мониторинга серверов. Несколько месяцев назад я был на связи, когда наши ящики начали плохо себя вести каждые несколько минут. Они не совсем падали, но приложение работало очень плохо в течение коротких периодов времени. Я вошел в коробках и обнаружил, что использование памяти было очень высоким. Поэтому я перезагружал серверы один за другим, и некоторое время казалось, что все в порядке. Но через несколько часов все это начало происходить снова. Это пахло как утечка памяти.
Поэтому я вошел в New Relic, чтобы взглянуть на графики. Конечно, одно из развертываний, которое мы делали ранее, внесло утечку памяти в приложение. Приложению потребовалось бы несколько часов, чтобы приложение заняло всю память, после чего оно впало бы в отчаянное безумие при сборке мусора , вызывая всевозможные забавные проблемы. Глядя на графики памяти на всех коробках, сразу видно, что происходит. В то время у нас не было настроено никаких предупреждений (мы делаем сейчас), поэтому мы не узнали о проблеме, пока она не вызвала другие проблемы. Но, имея возможность сравнивать все блоки друг с другом, а также иметь исторический контекст, я позволил мне легко диагностировать проблему, выкрутить исправление и вовремя заснуть в ту ночь.
Вот еще один. Недавно произошел сбой в центре обработки данных AWS, где размещается Tuts +. Когда все окончательно успокоилось, мы перезагрузили все ящики, чтобы убедиться, что проблем не было. Но когда ящики возвращались, приложение периодически возвращало 500 ответов или работало очень редко. Вероятно, это была проблема с одним или несколькими серверами, что очень раздражает для диагностики, когда у вас много ящиков. Еще раз, просмотр New Relic позволил нам очень быстро осветить проблему. Один из наших блоков вернулся с мошенническим процессом, который потреблял много ресурсов процессора, из-за чего приложение на этом блоке работало плохо. На другой блок повлиял какой-то сбой AWS, из-за которого использование дискового ввода-вывода для этого блока составило 100%. Мы вынули эту коробку из нашего балансировщика нагрузки , избавились от мошеннического процесса на другой, и приложение снова начало нормально работать.
Графики, которые предоставляет New Relic, действительно полезны, и я бы не хотел обходиться без них, поэтому позвольте мне показать, как настроить и запустить мониторинг сервера.
Установка нового агента мониторинга сервера Relic
По сути, все сводится к тому, чтобы войти на сервер и установить демон мониторинга сервера New Relic ( nrsysmond ). Если вы читали статью New Relic for PHP , процедура практически идентична. Как обычно, давайте предположим, что мы на Ubuntu.
Первое, что нужно сделать, это импортировать ключ репозитория New Relic:
|
1
|
wget -O — https://download.newrelic.com/548C16BF.gpg |
|
Теперь добавим в систему сам репозиторий New Relic:
|
1
|
sudo sh -c ‘echo «deb http://apt.newrelic.com/debian/ newrelic non-free» > /etc/apt/sources.list.d/newrelic.list’
|
Теперь мы просто используем apt :
|
1
2
|
sudo apt-get update
sudo apt-get install newrelic-sysmond
|
После завершения установки вы получите хорошее сообщение, подобное этому:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
|
*********************************************************************
*********************************************************************
***
*** Can not start the New Relic Server Monitor until you insert a
*** valid license key in the following file:
***
*** /etc/newrelic/nrsysmond.cfg
***
*** You can do this by running the following command as root:
***
*** nrsysmond-config —set license_key=<your_license_key_here>
***
*** No data will be reported until the server monitor can start.
*** You can get your New Relic key from the ‘Configuration’ section
*** of the ‘Support’ menu of your New Relic account (accessible at
*** https://rpm.newrelic.com).
***
*********************************************************************
*********************************************************************
|
Давайте делать то, что он говорит. Во-первых, давайте перейдем к настройкам нашей новой учетной записи Relic, чтобы найти наш лицензионный ключ (он будет справа):
Теперь давайте запустим команду:
|
1
|
nrsysmond-config —set license_key=<your_license_key_here>
|
Если вы проверите файл конфигурации сейчас: /etc/newrelic/nrsysmond.cfg . Вы увидите свой лицензионный ключ там. Мы готовы запустить агента:
|
1
|
/etc/init.d/newrelic-sysmond start
|
Теперь вы можете проверить список процессов, чтобы убедиться, что он запущен:
|
1
2
3
4
|
ps -ef |
newrelic 10087 1 0 09:25 ?
newrelic 10089 10087 0 09:25 ?
ubuntu 10100 9734 0 09:25 pts/1 00:00:00 grep —color=auto nrsys
|
Согласно агенту PHP, есть два процесса. Один — это процесс мониторинга, а второй — рабочий. Рабочий фактически выполняет работу по связи с серверами New Relic, процесс мониторинга просто наблюдает за рабочим, и если работник по какой-либо причине умирает, он порождает новый.
Мы также можем проверить журналы, чтобы убедиться в отсутствии ошибок при запуске:
|
1
2
3
|
cat /var/log/newrelic/nrsysmond.log
2014-05-25 09:25:02 [10089/main] always: New Relic Server Monitor version 1.4.0.471/C+IA started — pid=10089 background=true SSL=true ca_bundle=<none> ca_path=<none> host=ip-10-196-10-195
2014-05-25 09:25:03 [10089/main] info: RPM redirect: collector-102.newrelic.com(50.31.164.202) port 0 (0 means default port)
|
Все выглядит хорошо, и теперь вы должны начать видеть данные в интерфейсе New Relic.
Настройка агента мониторинга сервера
В большинстве случаев вам не нужно настраивать что-либо еще, кроме лицензионного ключа, но если вам нужно повысить уровень журнала или настроить прокси-сервер, это определенно возможно. Все это находится в /etc/newrelic/nrsysmond.cfg . Файл очень хорошо прокомментирован и довольно понятен. Если вы что-то изменили, не забудьте перезапустить демон:
|
1
|
/etc/init.d/newrelic-sysmond restart
|
Есть только одна тонкая вещь, когда речь идет о настройке мониторинга сервера, и это имя сервера, как это будет видно на сводных панелях New Relic. По умолчанию New Relic будет принимать имя хоста блока и указывать имя сервера в сводных панелях (т.е. вывод команды hostname ). Я рекомендую вам оставить это так. Если вы также используете New Relic для мониторинга приложений, сохраняя имя хоста как вывод команды hostname в качестве имени сервера, вы гарантируете, что New Relic сможет правильно определить, какие приложения работают на каких блоках и правильно связать все. в пользовательском интерфейсе.
Если вам действительно нужно, вы можете изменить имя сервера, как оно будет отображаться в пользовательском интерфейсе, установив параметр hostname= в файле конфигурации: /etc/newrelic/nrsysmond.cfg . Вам нужно будет перезапустить демон, чтобы это вступило в силу. Вы также можете изменить имя сервера непосредственно в пользовательском интерфейсе, что не повлияет на работу демона.
Использование панелей мониторинга сервера
Первое, что вы видите, когда нажимаете на ссылку « Серверы» слева, это снимок всех ваших серверов и ключевые показатели для всех из них (ЦП, диск, память, ввод-вывод).
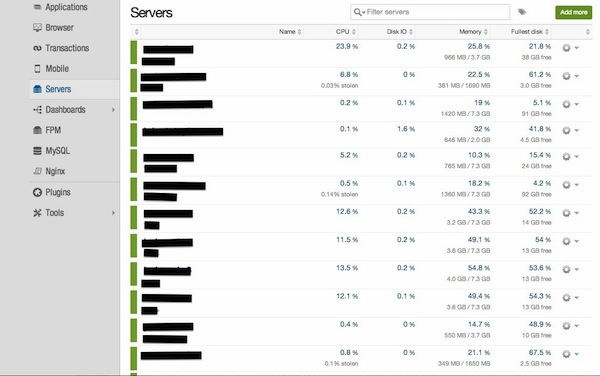
На этой странице вы можете увидеть, не работает ли один или несколько ваших ящиков. Здесь вы также можете переименовать сервер или добавить теги к нему, если это необходимо.
Если мы нажмем на один из серверов, мы перейдем к главной панели сервера:
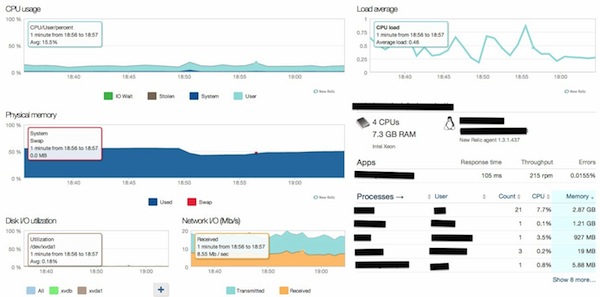
Здесь есть шесть основных показателей:
- использование процессора
- Использование памяти
- Использование дискового ввода-вывода
- Сетевой ввод-вывод
- Средняя нагрузка
- Список процессов
Это даст вам быстрый обзор конкретного сервера. Вы можете углубиться в каждый из графиков, чтобы получить больше информации. Например, вы можете углубиться в график CPU, чтобы увидеть, какие процессы используют CPU:
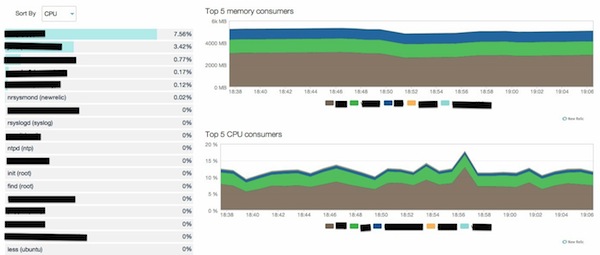
Или вы можете углубиться в график диска, чтобы увидеть свою скорость ввода-вывода, разбивку операций чтения и записи, а также получить оценку того, сколько времени пройдет до того, как ваш диск заполнится.
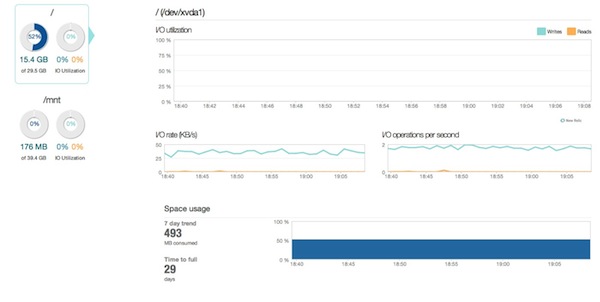
Самое приятное, что вы можете использовать те же операции на всех этих графиках, что и на графиках уровня приложения. Таким образом, вы можете увеличить пятиминутное окно, чтобы более внимательно рассмотреть всплеск загрузки ЦП, или взглянуть на семидневный тренд использования памяти.
Самое приятное то, что графики просты для понимания, вы не перегружены метриками и можете сравнивать похожие блоки друг с другом. Это может помочь вам диагностировать 99% общих проблем, с которыми вы, вероятно, столкнетесь в своей инфраструктуре.
Настройка предупреждений мониторинга сервера
New Relic недавно проделала большую работу по улучшению своих возможностей оповещения. Политики оповещений — это то, что они придумали во всей своей системе (например, существуют политики оповещений приложений для приложений и политики оповещений серверов для ящиков). Поначалу это может немного сбить с толку, но это довольно просто, когда вы освоитесь. Есть две основные концепции: политика и каналы. С точки зрения серверных оповещений, это работает так:
Мы устанавливаем политику и назначаем ей несколько серверов:
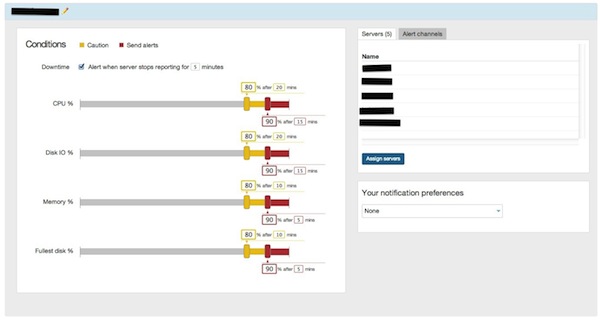
Вы также создаете канал (например, электронная почта, веб-крючок), на который можно отправлять оповещения:

Затем вы назначаете канал для политики. С этого момента, в зависимости от настроек канала (например, первое критическое событие, все критические события, только время простоя). Вы будете получать уведомления на этом канале.
Единственный запутанный момент в политиках оповещений — где их найти. Они живут под Сервис-> Политика оповещения :
Затем вам нужно нажать на Серверы в меню вверху, чтобы найти политики предупреждений сервера.
Вывод
Если вы уже используете решение для мониторинга инфраструктуры, такое как Nagios, и оно хорошо работает для вас, то вы можете не получить слишком много от мониторинга серверов New Relic (хотя графики и исторические тренды довольно хороши). Однако, если вы вообще не контролируете свою инфраструктуру или ваше текущее решение не работает для вас, обязательно попробуйте New Relic. Для меня это стало первым инструментом, к которому я обращаюсь, когда подозреваю, что что-то не так с моими серверами. И достаточно часто, это сообщит мне, что назревает проблема прежде, чем ситуация станет критической. Как разработчики, именно такие инструменты нам нужны в нашем арсенале.