Как только вы начнете копаться в New Relic, вы начнете понимать, сколько интересных функций имеет сервис, помогающий отслеживать производительность и работоспособность вашего приложения. Было действительно трудно выбрать только пять вещей для обсуждения, поэтому вместо того, чтобы сосредоточиться на очевидных функциях, давайте рассмотрим некоторые из менее раскрученных функций, которые предоставляет New Relic, и то, как мы можем использовать их интересными, а иногда и неортодоксальными способами.
Когда мы покидали вас в последний раз , у нас было простое приложение Rails «Hello World» (называемое New Relic_rails1 , проживающее в ~/project/tmp/New Relic ). Мы продолжим использовать это приложение, расширим его и посмотрим, сможем ли мы использовать его для демонстрации функций New Relic, которые мы рассмотрим.
Это содержание было заказано New Relic и было написано и / или отредактировано командой Tuts +. Наша цель в отношении спонсируемого контента состоит в том, чтобы публиковать соответствующие и объективные учебные пособия, тематические исследования и вдохновляющие интервью, которые предлагают реальную образовательную ценность нашим читателям и позволяют нам финансировать создание более полезного контента.
Мониторинг доступности
Это одна из функций New Relic, которая обычно не попадает на первую страницу маркетингового материала. В этом нет ничего особенного, но если подумать, что важнее, чтобы убедиться, что ваше приложение действительно запущено и доступно для ваших пользователей?
Во-первых, когда вы настраиваете мониторинг доступности, ваше приложение получает красивую звездочку на главной панели приложений:

Это хорошее визуальное напоминание, так что вы можете видеть, какие приложения все еще нуждаются в мониторинге доступности.
Давайте теперь посмотрим, как мы можем настроить мониторинг доступности и что мы можем из него получить. Во-первых, вам нужно перейти в свое приложение, а затем перейти в Настройки-> Мониторинг доступности . Вы увидите что-то вроде этого:
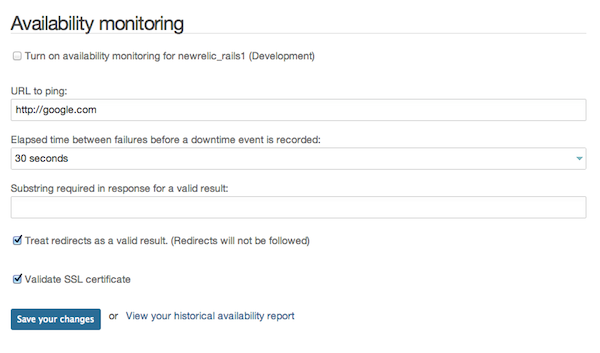
Вам нужно указать URL, который вы хотите, чтобы New Relic отправил эхо-запросы, поставьте галочку, сохраните изменения и все готово. Новая реликвия начнет попадать на ваш URL каждые 30 секунд. Но веселье на этом не заканчивается. New Relic будет проверять ваш URL через запрос HTTP HEAD (и будет считать, что все в порядке, если он получает код ответа 200), но вы можете указать строку ответа, которую вы хотите, чтобы New Relic искал, в этом случае он выполнит запрос GET и проверьте ответ для строки, которую вы предоставили. Это может быть очень удобно, если у вас есть пользовательская страница «Проверка здоровья», на которую вы хотите попасть.
Вы также можете настроить уведомление по электронной почте в случае простоя:
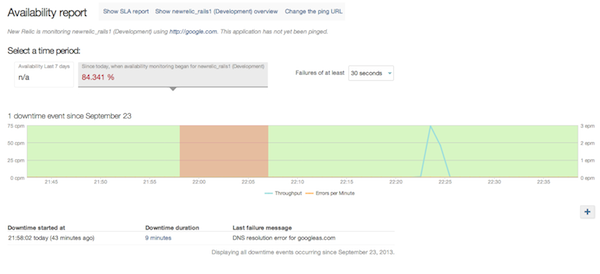
Теперь, когда вы отслеживаете доступность, у вас будет доступ к хорошему отчету, который наглядно покажет вам, когда произошли простои:
Фактически, многие из ваших диаграмм (например, обзор приложения) будут иметь такую визуальную индикацию:
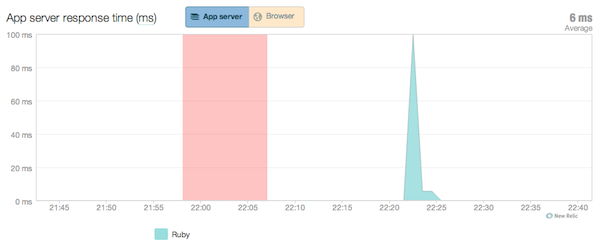
Вы должны признать, что это довольно приятный функционал для такого небольшого усилия.
Конечно, вы можете отключить и снова включить мониторинг (с помощью нового Relic REST API ) при выполнении развертываний, чтобы убедиться, что вы не получаете ложных событий простоя.
Другим интересным побочным эффектом этого является то, что если вы развертываете свой проект питомца в Heroku на одном динамометрическом стенде , вы можете использовать эту функцию ping, чтобы предотвратить спящий режим вашего динамо , что может сделать ваш сайт раздражающе медленным, если у вас нет напряженная ситуация на дороге.
Пользовательская запись ошибок
Если в вашем приложении возникают непредвиденные ошибки, New Relic запишет их для вас и предоставит вам хороший график. Наше маленькое приложение «Hello World» на данный момент работает превосходно, поэтому нам нечего видеть в этом плане. Но мы можем намеренно сломать наше приложение и посмотреть, что нам дает New Relic.
Давайте изменим наш HelloController чтобы случайным образом вызывать ошибку примерно в 50% случаев:
|
1
2
3
4
5
6
7
|
class HelloController < ApplicationController
def index
if rand(2) == 0
raise ‘Random error’
end
end
end
|
Теперь мы сделаем несколько сотен звонков в наше приложение и посмотрим, что произойдет:
|
1
|
ab -n 300 -c 10 http://127.0.0.1:3000/
|
Наш график ошибок New Relic теперь выглядит намного интереснее:
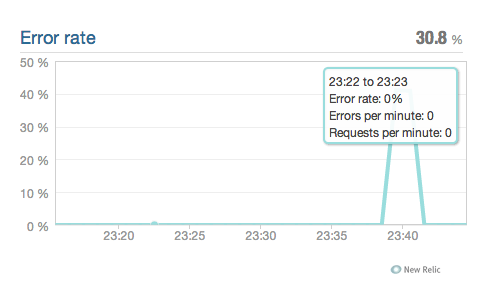
И мы можем перейти к деталям:
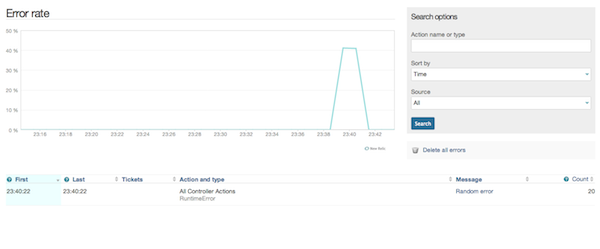
Как вы можете видеть, мы можем сортировать наши ошибки и фильтровать их, а также отдельно рассматривать ошибки из веб-запросов и фоновых задач. Это невероятно мощный инструмент, который поможет вам диагностировать и устранять проблемы с вашим приложением. Конечно, вы также можете увидеть трассировку стека для каждой ошибки:
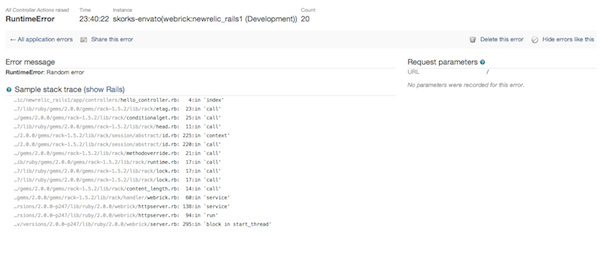
Существуют службы, специально предназначенные для регистрации ошибок в вашем приложении, некоторые из наиболее известных — Airbrake и Bugsnag . Это платные сервисы, используемые многими приложениями, но функциональность, которую обеспечивает New Relic, делает эти сервисы избыточными. Фактически, если бы мы могли отправлять пользовательские ошибки в New Relic (вместо того, чтобы позволять ей регистрировать ошибки, которые мы не спасли), мы могли бы сделать веские аргументы в пользу того, чтобы не использовать отдельную службу сбора ошибок (и сэкономить немного денег и избавиться от дополнительных жемчужина в процессе).
В то время как New Relic не документирует какой-либо способ сделать это, мы всегда можем обратиться к источнику, чтобы увидеть, трудно ли то, что мы хотим сделать. Мне кажется, что отправка пользовательских ошибок в New Relic должна быть довольно простой задачей, поэтому давайте попробуем. Мы снова изменим действие нашего контроллера, чтобы спасти все ошибки и отправить новую ошибку в New Relic:
|
1
2
3
4
5
6
7
8
9
|
class HelloController < ApplicationController
def index
if rand(2) == 0
raise ‘Random error’
end
rescue
New Relic::Agent.notice_error(StandardError.new(«I caught and reraised an error»))
end
end
|
После того, как мы сделаем еще несколько звонков и дождемся поступления данных, мы увидим следующее:
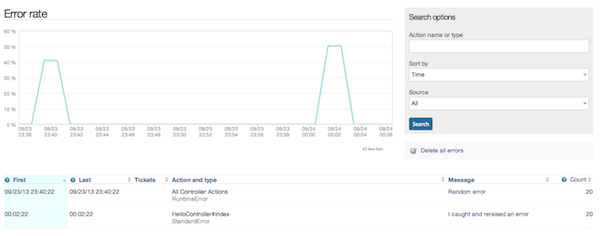
Это сработало, наша пользовательская ошибка приходит! New Relic может определенно выступать в качестве нашей службы сбора ошибок. Мы, конечно, используем здесь закрытый интерфейс, который не очень хорош, но мы можем поместить вызов notice_error за фасадом, что немного облегчит нам ситуацию, если интерфейс изменится.
Еще лучший подход может заключаться в том, чтобы вообще не обрабатывать пользовательские ошибки как обычные ошибки, а вместо этого создавать настраиваемый показатель для отслеживания, а затем создавать настраиваемую панель мониторинга для визуализации. Таким образом, мы не используем недокументированную функциональность и все равно получили бы все преимущества — блестящие!
Отслеживание ключевых транзакций
New Relic обычно будет отслеживать ваши транзакции для вас:
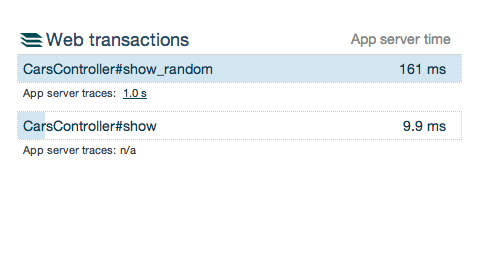
Вы сможете увидеть, где ваше приложение проводит большую часть своего времени (например, в контроллере, модели, базе данных и т. Д.). Однако New Relic не будет захватывать детальную трассировку, если транзакция не займет больше времени, чем Appdex * 4 секунды. Обычно это нормально, но иногда у вас есть транзакции, которые гораздо важнее для вашего приложения или для вашего бизнеса. Возможно, эти транзакции имеют чрезвычайно большой объем или связаны с такими важными событиями, как платежи. Достаточно сказать, что вы должны убедиться, что этот тип транзакции всегда работает очень хорошо.
Дело в том, что когда транзакция настолько важна, она, вероятно, уже получила от вас достаточно любви и может показаться довольно хорошей. Допустим, у вас есть транзакция с чрезвычайно высокой пропускной способностью (происходит много раз в минуту). Если эта транзакция работает оптимально, то все в порядке, но если производительность немного снизится, из-за объема трафика это может оказать непропорционально пагубное влияние на ваше приложение. То, что вы хотите, это что-то вроде:
- отдельное значение Apdex T только для этой транзакции
- возможность получать оповещения, когда производительность этой транзакции ухудшается
- подробный след каждый раз, когда эта транзакция выполняется даже немного неоптимально
Это именно то, что дают вам ключевые транзакции!
Прежде чем мы настроим ключевую транзакцию для нашего приложения «Hello World», нам нужно создать более интересную транзакцию, которая обычно будет работать хорошо, но иногда будет работать несколько хуже. Мы создадим возможность смотреть на марки и модели автомобилей и подбирать конкретные марки автомобилей, чтобы замедлить транзакцию. Во-первых, маршрут:
|
1
2
3
4
5
|
New RelicRails1::Application.routes.draw do
get ‘random_car’, to: ‘cars#show_random’
root ‘hello#index’
end
|
Мы хотим иметь возможность получить случайный автомобиль, который будет отображаться в CarsController :
|
1
2
3
4
5
6
7
8
|
class CarsController < ApplicationController
def show_random
@car = Car.offset(rand(Car.count)).first
if @car.make == ‘Ford’
sleep(2)
end
end
end
|
Мы получаем случайный автомобиль из базы данных, и если марка автомобиля — «Форд», у нас будет медленная транзакция. Конечно, нам нужна модель Car :
|
1
2
|
class Car < ActiveRecord::Base
end
|
Нам нужно настроить нашу базу данных для использования MySql в разработке (я сделал это, но вы можете придерживаться sqlite ):
|
01
02
03
04
05
06
07
08
09
10
11
12
|
base: &BASE
adapter: mysql2
encoding: utf8
host: «localhost»
username: «root»
max_connections: 10
timeout: 5000
development: &DEV
<<: *BASE
database: «New Relic_rails1_development»
sql_log_level: debug
|
Нам нужна миграция для создания таблицы cars :
|
1
2
3
4
5
6
7
8
|
class Cars < ActiveRecord::Migration
def change
create_table :cars, force: true do |t|
t.string :make
t.string :model
end
end
end
|
И нам нужны некоторые начальные данные, которые мы поместим в наш файл db/seeds.rb :
|
1
2
3
4
5
|
Car.create(make: ‘Ford’, model: ‘Mondeo’)
Car.create(make: ‘Honda’, model: ‘Accord’)
Car.create(make: ‘Audi’, model: ‘A4’)
Car.create(make: ‘Lamborghini’, model: ‘Murcielago’)
Car.create(make: ‘Toyota’, model: ‘Prius’)
|
Наконец, мы, вероятно, должны иметь представление cars/show_random.html.erb :
|
1
2
|
<h1>Make: <%= @car.make %></h1>
<h2>Model: <%= @car.model %></h2>
|
Вам также необходимо добавить гем Gemfile в Gemfile если вы использовали MySql. После этого нам просто нужно создать и заполнить базу данных, перезапустить наш сервер, и все готово:
|
1
2
3
|
bundle
rake db:create && rake db:migrate && rake db:seed
rails s
|
Вам нужно будет нажать на URL, чтобы убедиться, что New Relic распознает, что эта транзакция существует:
|
1
|
curl localhost:3000/random_car
|
Теперь мы готовы отслеживать эту транзакцию как ключевую транзакцию. Сначала перейдите на вкладку транзакции:
Нажмите кнопку «Отслеживание ключевой транзакции», выберите нашу вновь созданную транзакцию:
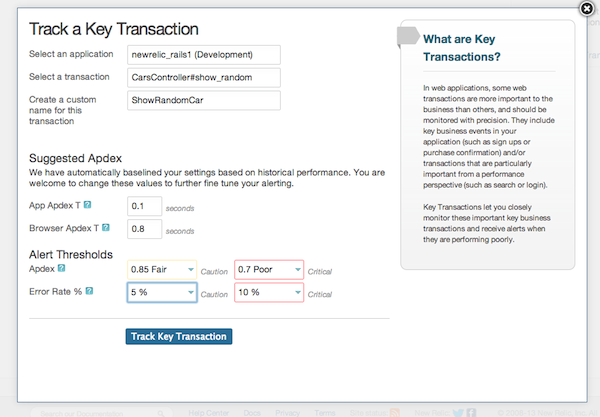
Мы можем дать нашей новой ключевой транзакции имя, выбрать Apdex T, которым мы довольны, а также настроить некоторые оповещения. Когда наша транзакция займет больше времени, чем выбранный нами Apdex, New Relic захватит подробный след, который мы сможем использовать, чтобы выяснить, откуда возникла проблема с производительностью. Давайте сделаем несколько звонков на наш новый URL и посмотрим, какие данные мы получим:
|
1
|
ab -n 300 -c 20 http://127.0.0.1:3000/random_car
|
Хм, кажется, некоторые из наших транзакций расстраивают наших пользователей:
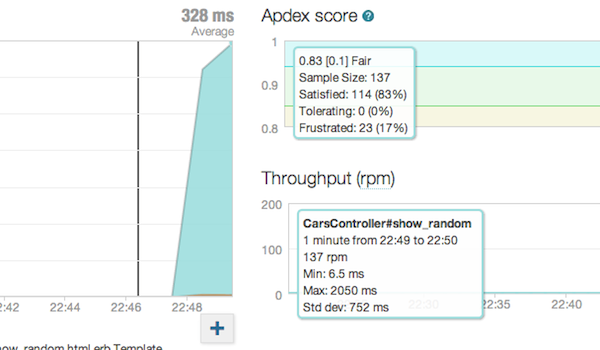
Давайте посмотрим, обнаружил ли New Relic некоторые транзакции для нас:
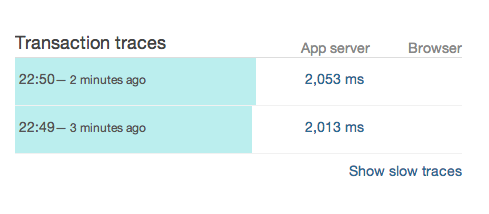
Давайте посмотрим на один из этих следов. Чтобы ответить, потребовалось около 2 секунд, но только 10 миллисекунд использовали процессор:

Все наши операторы SQL были быстрыми, поэтому проблема не в базе данных:
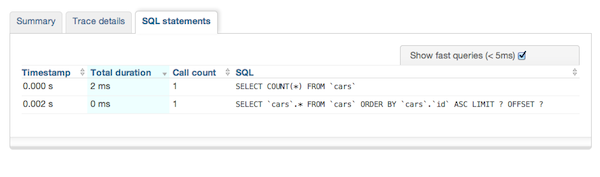
Похоже, что большую часть времени тратится на действия контроллера:
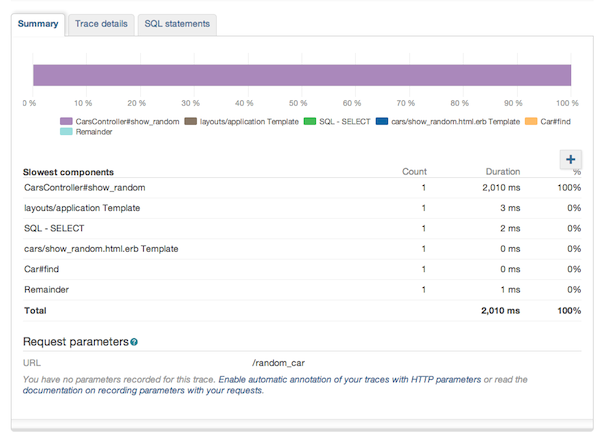
Давайте углубимся в след. Похоже, что SQL SELECT был быстрым, Car.find также был быстрым. Затем мы теряем около 2 секунд, после чего следует очень быстрый рендеринг шаблона:
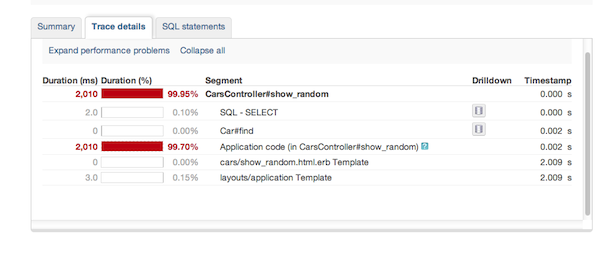
Новый Relic любезно подчеркнул для нас, где мы потеряли эти две секунды. Нам нужно взглянуть на код нашего контроллера после вызова Car.find :
|
1
2
3
4
5
6
7
8
|
class CarsController < ApplicationController
def show_random
@car = Car.offset(rand(Car.count)).first
if @car.make == ‘Ford’
sleep(2)
end
end
end
|
Хм, начальный SELECT должен быть вызовом Car.count , а Car.find должен быть Car.offset вызовом Car.offset . Наша большая задержка сразу после этого, хотя. Ага, посмотрите на это, какой-то глупый человек добавил в наш код 2-секундную задержку, когда марка машины — «Форд». Это объясняет, почему наша задержка в 2 секунды происходит только иногда. Я лучше сделаю git blame в наш репозиторий, чтобы узнать, кто поместил туда этот ужасный код! Если подумать, мне лучше этого не делать, потому что это может сказать, что это был я.
Запись внешнего сервисного звонка
Всякий раз, когда вы делаете звонки на другие сервисы из вашего приложения (например, HTTP-запрос к API, например, Twitter ), New Relic будет отслеживать их как внешние вызовы. В наши дни серьезное приложение может интегрироваться с рядом внешних API. Часто эти внешние службы могут значительно снизить производительность вашего приложения, особенно если вы выполняете эти вызовы в процессе. Новая Relic может показать, какие из ваших внешних вызовов являются самыми медленными, какие из них вы вызываете чаще всего, а какие отвечают в среднем медленнее. Вы также можете посмотреть на производительность каждой из внешних услуг, которые вы используете в отдельности. Давайте попробуем.
Мы создадим наш собственный внешний сервис, создав небольшое приложение Sinatra . Сначала мы устанавливаем драгоценный камень:
|
1
|
gem install sinatra
|
Создайте новый файл для нашего сервиса:
|
1
|
touch external_service.rb
|
И поместите туда следующий код:
|
1
2
3
4
5
6
7
|
require ‘sinatra’
get ‘/hello’ do
sleep_time = rand(2000)/1000.0
sleep(sleep_time)
«Hello External World #{sleep_time}!»
end
|
Эта служба будет находиться в спящем режиме в течение произвольного времени (от 0 до 2000 миллисекунд), а затем возвращает ответ «Hello» со временем, в течение которого она спала. Теперь все, что нам нужно сделать, это запустить его:
|
1
|
ruby external_service.rb
|
Вернувшись в наше приложение Rails, мы создадим новый контроллер для вызова нашего внешнего сервиса. Мы будем использовать этот маршрут:
|
1
2
3
4
5
|
New RelicRails1::Application.routes.draw do
…
get ‘external_call’, to: ‘external_calls#external_call’
…
end
|
Наш контроллер будет вызывать наш сервис Sinatra через HTTP:
|
01
02
03
04
05
06
07
08
09
10
11
12
|
require ‘net/http’
class ExternalCallsController < ApplicationController
def external_call
url = URI.parse(‘http://localhost:4567/hello’)
external_request = Net::HTTP::Get.new(url.to_s)
external_response = Net::HTTP.start(url.host, url.port) do |http|
http.request(external_request)
end
@result = external_response.body
end
end
|
И нам нужен вид для отображения результатов:
|
1
|
<h1><%= @result %></h1>
|
Все, что нам нужно сделать, это сделать несколько звонков на нашу новую конечную точку:
|
1
|
ab -n 100 -c 10 http://127.0.0.1:3000/external_call
|
Давайте посмотрим, что New Relic произвела для нас.
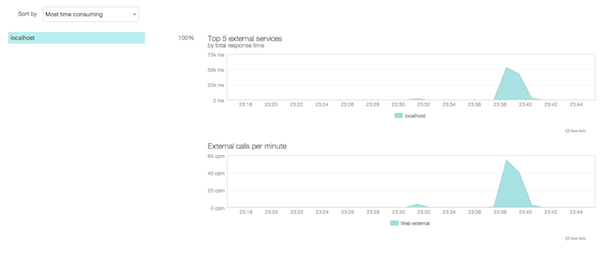
Новая Реликвия действительно приняла наш новый внешний вызов. У нас есть общее количество вызовов в минуту, которые мы делаем на внешнюю конечную точку. И общая сумма, потраченная на ответ внешней службы. Конечно, наш график выглядит немного скудным, поскольку у нас есть только один внешний сервис, что означает, что нам не с чем сравнивать.
Мы также можем получить более подробные данные о конкретном внешнем вызове, а также о том, откуда в нашем приложении делается этот вызов:
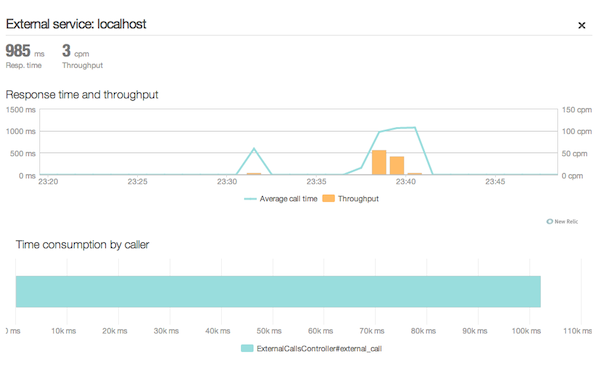
Мы можем видеть, когда были сделаны вызовы, пропускную способность и среднее время ответа. Это может показаться простым, но если у вас есть приложение с большим количеством внешних сервисов, эта функция может дать вам очень хороший обзор того, как работают эти внешние сервисы, а также когда и где они используются. Это может позволить вам принимать решения, касающиеся кэширования определенных ответов внешних служб, если это возможно, или даже отбрасывания определенных внешних служб, если их производительность не до нуля. И вам больше не нужно спорить об этих вещах, основываясь на интуитивных ощущениях и запеченных в домашних условиях показателях, у вас будут точные данные, чтобы доказать свою точку зрения для вас.
Анализ масштабируемости и производительности
Для разработчика нет ничего более разочаровывающего, чем падение приложения из-за резкого увеличения трафика. Все шло гладко, пока не появились эти несколько сотен пользователей и ваше приложение взорвалось. У вас было чувство, что это может произойти, но вы не могли быть уверены — выжидательная позиция казалась самым прагматичным подходом. Что касается отчетов о емкости и масштабируемости New Relic, вам больше не нужно «ждать и видеть». Вы можете сразу сказать, насколько хорошо ваше приложение масштабируется, вы можете выполнить нагрузочные тесты и сразу увидеть, сможет ли ваше приложение справиться с нагрузкой. Вы можете наблюдать тенденции времени отклика вашего приложения по мере роста вашей пользовательской базы и прогнозировать, когда вам нужно будет увеличить емкость. Все это действительно замечательные вещи.
Сначала давайте посмотрим на отчеты о емкости:
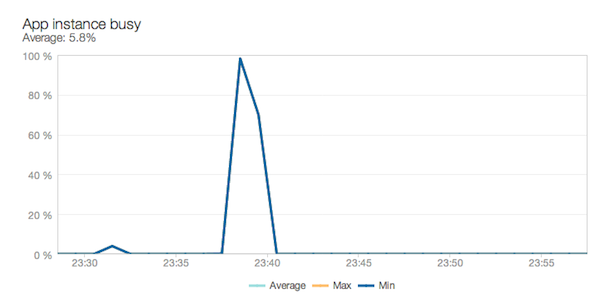
Хм, этот показывает большой всплеск, но в остальном ничего. Ну, мы работаем в режиме разработки, так что это понятно. Этот всплеск предназначен для того, когда мы сделали несколько запросов одновременно, совсем недавно. Как вы можете видеть, когда мы выполняли эти параллельные запросы, мы максимально использовали наш бедный одинокий экземпляр Webrick. Если бы это было производство и эта нагрузка была постоянной, наш экземпляр всегда был бы занят на 100%, что, вероятно, указывало бы на то, что нам нужен другой экземпляр.
Отчет анализа экземпляра немного отличается:
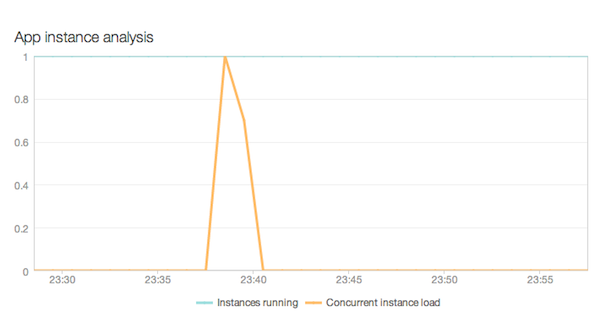
В нашем случае мы мало что получаем от этого, но обычно он показывает нам количество запущенных экземпляров и количество экземпляров, которые нам действительно нужны для обработки нагрузки, если все экземпляры были заняты на 100%. Таким образом, если бы мы запускали 10 экземпляров, а одновременная загрузка экземпляров равнялась 2, мы могли бы легко вдвое (или даже больше, чем вдвое) увеличить количество запущенных экземпляров и вообще не снижать производительность. Для небольшого приложения, которое запускается всего в нескольких экземплярах, это не представляет особой проблемы, но для большого приложения с десятками и сотнями экземпляров это может привести к значительной экономии средств.
И затем есть отчеты о масштабируемости. Отчет о времени отклика, пожалуй, самый интересный / важный:
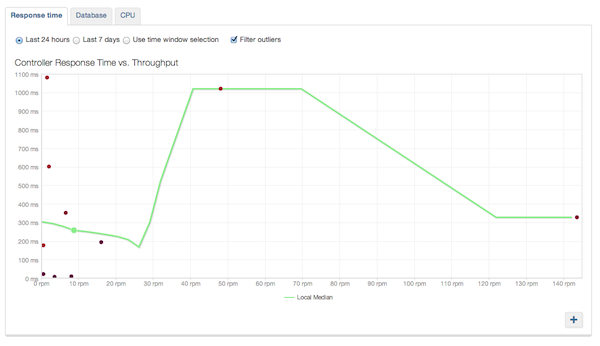
Еще раз, наш график очень искажен, потому что это приложение для разработки, с которым мы играли случайно. Идея этого отчета заключается в том, что по мере увеличения пропускной способности вашего приложения (больше запросов в минуту) время отклика должно оставаться близким к постоянному (т. Е. Производительность не снижается при большем трафике). Это означает, что вы всегда должны видеть что-то похожее на плоскую линию здесь. Если ваша линия значительно наклонена вверх, ваше приложение, вероятно, изо всех сил пытается обработать трафик, и вам может потребоваться увеличить пропускную способность. Где добавить емкость — это совсем другой вопрос (например, емкость базы данных, больше серверов и т. Д.). Два других отчета о масштабируемости помогут вам ответить на него. Есть отчет базы данных:
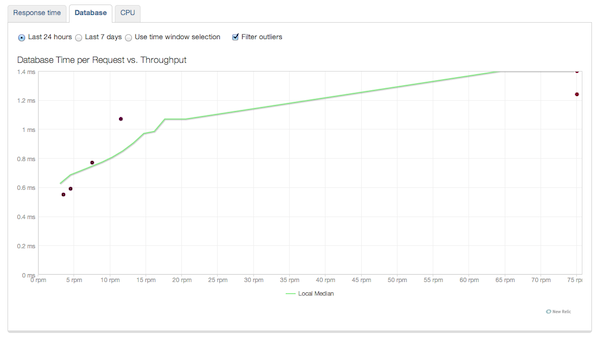
Вы не можете ожидать, что ваша база данных не будет подвержена более высокой нагрузке, поэтому здесь вы должны увидеть линию, которая медленно увеличивается с ростом пропускной способности вашего приложения. Это зависит от вас, когда время отклика базы данных считается неприемлемым (то есть слишком сильно влияет на отклик приложения), но когда вы решаете, что ответы базы данных слишком медленные, вы знаете, что пришло время добавить емкость базы данных. Другой отчет — это процессор:
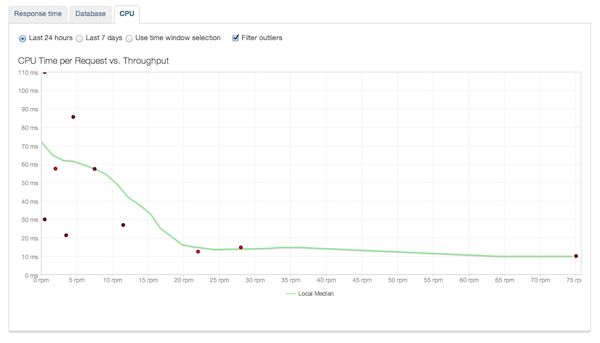
Опять же, вы не можете ожидать, что более высокая пропускная способность не повлияет на загрузку вашего процессора, вы должны увидеть линию, которая постепенно увеличивается с увеличением пропускной способности. Это, вместе с отчетами о пропускной способности, о которых мы говорили ранее, может позволить вам решить, когда добавить больше процессов / серверов Rails, чтобы обеспечить достойную производительность.
Вывод
Если одна или все из этих функций вызвали у вас удивление (или две), хорошая новость заключается в том, что мы только что поцарапали поверхность. Каждая из этих функций более чем заслуживает отдельной статьи. Но у New Relic также есть ряд других функций, которые потенциально могут быть даже более мощными, включая мониторинг реальных пользователей , платформу New Relic , профилировщик потоков , пороговые значения оповещений и уведомления и многие другие. Мы постараемся охватить некоторые или, возможно, даже все из них в следующих уроках.
А пока попробуйте New Relic, разверните агент на своем любимом языке и посмотрите, сможете ли вы найти готовый способ использования некоторых функций, предоставляемых New Relic. И если у вас есть какие-то инновационные способы использования New Relic, обязательно сообщите об этом всем, оставив комментарий.