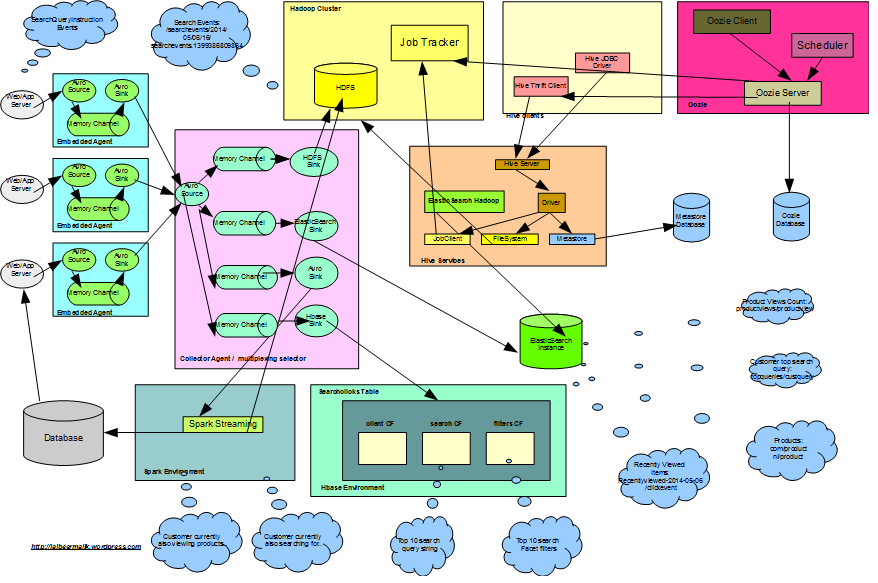
В этом посте мы рассмотрим HBase для хранения данных о событиях кликов при поиске клиентов и их использования для получения информации о поведении клиентов на основе кликов по строке поисковых запросов и щелчков по фасетному фильтру. Мы рассмотрим использование MiniHBaseCluster, разработку схемы HBase, интеграцию с Flume с использованием HBaseSink для хранения данных JSON.
В продолжение предыдущих постов,
- При поиске по продукту клиента кликает аналитика с использованием больших данных ,
- Flume: сбор данных о покупках по продуктам клиентов с использованием Apache Flume ,
- Hive. Запросите самый популярный поисковый запрос клиента и количество просмотров продукта с помощью Apache Hive ,
- ElasticSearch-Hadoop: индексирование количества просмотров продукта и поискового запроса клиентов от Hadoop до ElasticSearch ,
- Oozie: Координатор планирования / Bundle заданий для разделения Hive и индексации ElasticSearch ,
- Spark: аналитика в реальном времени для больших данных по популярным поисковым запросам и популярным продуктам
Мы исследовали, как хранить данные о событиях поисковых кликов в Hadoop и запрашивать их, используя разные технологии. Здесь мы будем использовать HBase для достижения того же:
- Настройка мини-кластера HBase
- Шаблон HBase с использованием Spring Data
- HBase Schema Design
- Интеграция Flume с использованием HBaseSink
- HBaseJsonSerializer для сериализации данных JSON
- Query Top 10 поисковых запросов за последний час
- Query Top 10 фильтр поиска фасетов за последний час
- Получить последнюю строку поискового запроса для клиента за последние 30 дней
HBase
HBase «это база данных Hadoop, распределенное, масштабируемое, хранилище больших данных».
HBaseMiniCluster / MiniZookeperCluster
Чтобы настроить и запустить мини-кластер, проверьте HBaseServiceImpl.java
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
|
... miniZooKeeperCluster = new MiniZooKeeperCluster(); miniZooKeeperCluster.setDefaultClientPort(10235); miniZooKeeperCluster.startup(new File("taget/zookeper/dfscluster_" + UUID.randomUUID().toString()).getAbsoluteFile()); ... Configuration config = HBaseConfiguration.create(); config.set("hbase.tmp.dir", new File("target/hbasetom").getAbsolutePath()); config.set("hbase.master.port", "44335"); config.set("hbase.master.info.port", "44345"); config.set("hbase.regionserver.port", "44435"); config.set("hbase.regionserver.info.port", "44445"); config.set("hbase.master.distributed.log.replay", "false"); config.set("hbase.cluster.distributed", "false"); config.set("hbase.master.distributed.log.splitting", "false"); config.set("hbase.zookeeper.property.clientPort", "10235"); config.set("zookeeper.znode.parent", "/hbase"); miniHBaseCluster = new MiniHBaseCluster(config, 1); miniHBaseCluster.startMaster(); ... |
MiniZookeeprCluster запускается на клиентском порту 10235, все клиентские подключения будут на этом порту. Убедитесь, что порт hbase-сервера не конфликтует с другим локальным сервером hbase. Здесь мы запускаем только один сервер региона hbase в тестовом примере.
Шаблон HBase с использованием Spring Data
Мы будем использовать шаблон Spring hbase для подключения к кластеру HBase:
|
1
2
3
|
<hdp:hbase-configuration id="hbaseConfiguration" configuration-ref="hadoopConfiguration" stop-proxy="false" delete-connection="false" zk-quorum="localhost" zk-port="10235"> </hdp:hbase-configuration> <bean id="hbaseTemplate" class="org.springframework.data.hadoop.hbase.HBaseTemplate" p:configuration-ref="hbaseConfiguration" /> |
HBase Table Schema Design
У нас есть данные JSON события щелчка для поиска в следующем формате,
|
1
|
{"eventid":"24-1399386809805-629e9b5f-ff4a-4168-8664-6c8df8214aa7","hostedmachinename":"192.168.182.1330","pageurl":"<a href="http://blahblah:/5"" rel="nofollow">http://blahblah:/5"</a>;,"customerid":24,"sessionid":"648a011d-570e-48ef-bccc-84129c9fa400","querystring":null,"sortorder":"desc","pagenumber":3,"totalhits":28,"hitsshown":7,"createdtimestampinmillis":1399386809805,"clickeddocid":"41","favourite":null,"eventidsuffix":"629e9b5f-ff4a-4168-8664-6c8df8214aa7","filters":[{"code":"searchfacettype_color_level_2","value":"Blue"},{"code":"searchfacettype_age_level_2","value":"12-18 years"}]} |
Одним из способов обработки данных является непосредственное хранение их в одном семействе столбцов и столбце json. Таким способом будет нелегко и легко сканировать данные JSON. Другой вариант может заключаться в том, чтобы хранить его в одном семействе столбцов, но иметь разные столбцы. Но хранить данные фильтров в одном столбце будет сложно для сканирования. Приведенный ниже гибридный подход заключается в разделении его на несколько семейств столбцов и динамическом создании столбцов для фильтрации данных.
Преобразованная схема:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
|
{"client:eventid" => "24-1399386809805-629e9b5f-ff4a-4168-8664-6c8df8214aa7","client:eventidsuffix" => "629e9b5f-ff4a-4168-8664-6c8df8214aa7","client:hostedmachinename" => "192.168.182.1330","client:createdtimestampinmillis" => 1399386809805,"client:cutomerid" => 24,"client:sessionid" => "648a011d-570e-48ef-bccc-84129c9fa400","search:querystring" => null,"search:sortorder" => desc,"search:pagenumber" => 3,"search:totalhits" => 28,"search:hitsshown" => 7,"search:clickeddocid" => "41","search:favourite" => null,"filters:searchfacettype_color_level_2" => "Blue","filters:searchfacettype_age_level_2" => "12-18 years"} |
Создаются следующие три семейства столбцов:
- client : для хранения данных клиента и конкретной информации о событии.
- search : здесь хранится информация о поиске, относящаяся к строке запроса и пагинации.
- фильтры: для поддержки дополнительных фасетов в будущем и т. д. и более гибкого сканирования данных имена столбцов динамически создаются на основе имени / кода фасета, а значение столбца сохраняется в качестве значения фильтра фасетов.
Чтобы создать таблицу hbase,
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
|
... TableName name = TableName.valueOf("searchclicks"); HTableDescriptor desc = new HTableDescriptor(name); desc.addFamily(new HColumnDescriptor(HBaseJsonEventSerializer.COLUMFAMILY_CLIENT_BYTES)); desc.addFamily(new HColumnDescriptor(HBaseJsonEventSerializer.COLUMFAMILY_SEARCH_BYTES)); desc.addFamily(new HColumnDescriptor(HBaseJsonEventSerializer.COLUMFAMILY_FILTERS_BYTES)); try { HBaseAdmin hBaseAdmin = new HBaseAdmin(miniHBaseCluster.getConf()); hBaseAdmin.createTable(desc); hBaseAdmin.close(); } catch (IOException e) { throw new RuntimeException(e); } ... |
При создании таблицы добавлено соответствующее семейство столбцов для поддержки новой структуры данных. Как правило, рекомендуется поддерживать минимальное количество семейств столбцов, помните, как вы структурируете свои данные в зависимости от использования. На основе приведенных выше примеров мы сохранили сценарий сканирования, например:
- Сканирование семейства клиентов на тот случай, если вы хотите получить информацию о клиенте или клиенте на основе общей информации о трафике на сайте.
- отсканируйте поисковую информацию, чтобы увидеть, какой свободный текстовый поиск ищут конечные клиенты, которые не встречаются при навигационном поиске. Посмотрите, на какой странице был выбран соответствующий продукт. Нужно ли повысить, чтобы подать заявку, чтобы продвинуть продукт высоко.
- Сканирование фильтров семейства, чтобы увидеть, как навигационный поиск работает для вас. Дает ли конечным потребителям продукт, который они ищут. Посмотрите, какие фильтры фасетов нажимаются больше, и вам нужно немного подняться в заказе, чтобы он был легко доступен для клиента.
- следует избегать сканирования между семействами и использовать конструкцию ключей строк для получения конкретной информации о клиентах.
Информация о конструкции строки ключа
В нашем случае дизайн ключа строки основан на customerId-timestamp -randomuuid . Поскольку ключ строки одинаков для всех семейств столбцов, мы можем использовать фильтр префиксов для фильтрации строк, относящихся только к конкретному клиенту.
|
1
2
3
4
5
|
final String eventId = customerId + "-" + searchQueryInstruction.getCreatedTimeStampInMillis() + "-" + searchQueryInstruction.getEventIdSuffix();...byte[] rowKey = searchQueryInstruction.getEventId().getBytes(CHARSET_DEFAULT);...# 24-1399386809805-629e9b5f-ff4a-4168-8664-6c8df8214aa7 |
Каждое семейство столбцов здесь будет иметь один и тот же ключ строки, и вы можете использовать префиксный фильтр для сканирования строк только для конкретного клиента.
Flume Integration
HBaseSink используется для хранения данных событий поиска непосредственно в HBase. Проверьте детали, FlumeHBaseSinkServiceImpl.java
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
... channel = new MemoryChannel(); Map<String, String> channelParamters = new HashMap<>(); channelParamters.put("capacity", "100000"); channelParamters.put("transactionCapacity", "1000"); Context channelContext = new Context(channelParamters); Configurables.configure(channel, channelContext); channel.setName("HBaseSinkChannel-" + UUID.randomUUID()); sink = new HBaseSink(); sink.setName("HBaseSink-" + UUID.randomUUID()); Map<String, String> paramters = new HashMap<>(); paramters.put(HBaseSinkConfigurationConstants.CONFIG_TABLE, "searchclicks"); paramters.put(HBaseSinkConfigurationConstants.CONFIG_COLUMN_FAMILY, new String(HBaseJsonEventSerializer.COLUMFAMILY_CLIENT_BYTES)); paramters.put(HBaseSinkConfigurationConstants.CONFIG_BATCHSIZE, "1000"); paramters.put(HBaseSinkConfigurationConstants.CONFIG_SERIALIZER, HBaseJsonEventSerializer.class.getName()); Context sinkContext = new Context(paramters); sink.configure(sinkContext); sink.setChannel(channel); sink.start(); channel.start(); ... |
Семейство столбцов клиента используется только для проверки HBaseSink.
HBaseJsonEventSerializer
Пользовательский сериализатор создан для хранения данных JSON:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
|
public class HBaseJsonEventSerializer implements HBaseEventSerializer { public static final byte[] COLUMFAMILY_CLIENT_BYTES = "client".getBytes(); public static final byte[] COLUMFAMILY_SEARCH_BYTES = "search".getBytes(); public static final byte[] COLUMFAMILY_FILTERS_BYTES = "filters".getBytes(); ... byte[] rowKey = searchQueryInstruction.getEventId().getBytes(CHARSET_DEFAULT); Put put = new Put(rowKey); // Client Infor put.add(COLUMFAMILY_CLIENT_BYTES, "eventid".getBytes(), searchQueryInstruction.getEventId().getBytes()); ... if (searchQueryInstruction.getFacetFilters() != null) { for (SearchQueryInstruction.FacetFilter filter : searchQueryInstruction.getFacetFilters()) { put.add(COLUMFAMILY_FILTERS_BYTES, filter.getCode().getBytes(),filter.getValue().getBytes()); } } ... |
Проверьте дополнительную информацию, HBaseJsonEventSerializer.java
Тело событий преобразуется в Java-бин из Json, а затем данные обрабатываются для сериализации в соответствующие семейства столбцов.
Query Raw Cell data
Чтобы запросить необработанные данные ячейки:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
... Scan scan = new Scan(); scan.addFamily(HBaseJsonEventSerializer.COLUMFAMILY_CLIENT_BYTES); scan.addFamily(HBaseJsonEventSerializer.COLUMFAMILY_SEARCH_BYTES); scan.addFamily(HBaseJsonEventSerializer.COLUMFAMILY_FILTERS_BYTES); List<String> rows = hbaseTemplate.find("searchclicks", scan, new RowMapper<String>() { @Override public String mapRow(Result result, int rowNum) throws Exception { return Arrays.toString(result.rawCells()); } }); for (String row : rows) { LOG.debug("searchclicks table content, Table returned row: {}", row); } |
Проверьте HBaseServiceImpl.java для деталей.
Данные хранятся в hbase в следующем формате:
|
1
|
searchclicks table content, Table returned row: [84-1404832902498-7965306a-d256-4ddb-b7a8-fd19cdb99923/client:createdtimestampinmillis/1404832918166/Put/vlen=13/mvcc=0, 84-1404832902498-7965306a-d256-4ddb-b7a8-fd19cdb99923/client:customerid/1404832918166/Put/vlen=2/mvcc=0, 84-1404832902498-7965306a-d256-4ddb-b7a8-fd19cdb99923/client:eventid/1404832918166/Put/vlen=53/mvcc=0, 84-1404832902498-7965306a-d256-4ddb-b7a8-fd19cdb99923/client:hostedmachinename/1404832918166/Put/vlen=16/mvcc=0, 84-1404832902498-7965306a-d256-4ddb-b7a8-fd19cdb99923/client:pageurl/1404832918166/Put/vlen=19/mvcc=0, 84-1404832902498-7965306a-d256-4ddb-b7a8-fd19cdb99923/client:sessionid/1404832918166/Put/vlen=36/mvcc=0, 84-1404832902498-7965306a-d256-4ddb-b7a8-fd19cdb99923/filters:searchfacettype_product_type_level_2/1404832918166/Put/vlen=7/mvcc=0, 84-1404832902498-7965306a-d256-4ddb-b7a8-fd19cdb99923/search:hitsshown/1404832918166/Put/vlen=2/mvcc=0, 84-1404832902498-7965306a-d256-4ddb-b7a8-fd19cdb99923/search:pagenumber/1404832918166/Put/vlen=1/mvcc=0, 84-1404832902498-7965306a-d256-4ddb-b7a8-fd19cdb99923/search:querystring/1404832918166/Put/vlen=13/mvcc=0, 84-1404832902498-7965306a-d256-4ddb-b7a8-fd19cdb99923/search:sortorder/1404832918166/Put/vlen=3/mvcc=0, 84-1404832902498-7965306a-d256-4ddb-b7a8-fd19cdb99923/search:totalhits/1404832918166/Put/vlen=2/mvcc=0] |
Query Top 10 поисковых запросов за последний час
Чтобы запросить только строку поиска, нам нужно только семейство столбцов поиска. Чтобы сканировать в пределах временного диапазона, мы можем использовать колонку созданного семейства столбцов клиента timetimestampinmillis, но это будет расширенное сканирование.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
... Scan scan = new Scan(); scan.addColumn(HBaseJsonEventSerializer.COLUMFAMILY_CLIENT_BYTES, Bytes.toBytes("createdtimestampinmillis")); scan.addColumn(HBaseJsonEventSerializer.COLUMFAMILY_SEARCH_BYTES, Bytes.toBytes("querystring")); List<String> rows = hbaseTemplate.find("searchclicks", scan, new RowMapper<String>() { @Override public String mapRow(Result result, int rowNum) throws Exception { String createdtimestampinmillis = new String(result.getValue(HBaseJsonEventSerializer.COLUMFAMILY_CLIENT_BYTES, Bytes.toBytes("createdtimestampinmillis"))); byte[] value = result.getValue(HBaseJsonEventSerializer.COLUMFAMILY_SEARCH_BYTES, Bytes.toBytes("querystring")); String querystring = null; if (value != null) { querystring = new String(value); } if (new DateTime(Long.valueOf(createdtimestampinmillis)).plusHours(1).compareTo(new DateTime()) == 1 && querystring != null) { return querystring; } return null; } }); ... //sort the keys, based on counts collection of the query strings. List<String> sortedKeys = Ordering.natural().onResultOf(Functions.forMap(counts)).immutableSortedCopy(counts.keySet()); ... |
Query Top 10 фильтр поиска фасетов за последний час
Основываясь на динамическом создании столбцов, вы можете сканировать данные, чтобы получить фильтры фасетов, которые были нажаты сверху.
Динамические столбцы будут основаны на ваших кодах фасетов, которые могут быть следующими:
|
1
2
3
4
5
6
7
|
#searchfacettype_age_level_1 #searchfacettype_color_level_2 #searchfacettype_brand_level_2 #searchfacettype_age_level_2 for (String facetField : SearchFacetName.categoryFacetFields) { scan.addColumn(HBaseJsonEventSerializer.COLUMFAMILY_FILTERS_BYTES, Bytes.toBytes(facetField)); } |
Чтобы получить:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
|
... hbaseTemplate.find("searchclicks", scan, new RowMapper<String>() { @Override public String mapRow(Result result, int rowNum) throws Exception { for (String facetField : SearchFacetName.categoryFacetFields) { byte[] value = result.getValue(HBaseJsonEventSerializer.COLUMFAMILY_FILTERS_BYTES, Bytes.toBytes(facetField)); if (value != null) { String facetValue = new String(value); List<String> list = columnData.get(facetField); if (list == null) { list = new ArrayList<>(); list.add(facetValue); columnData.put(facetField, list); } else { list.add(facetValue); } } } return null; } }); ... |
Вы получите полный список всех аспектов, вы можете обработать данные дальше, чтобы посчитать верхние аспекты и упорядочить их. Для полной проверки деталей, HBaseServiceImpl.findTopTenSearchFiltersForLastAnHour
Получить последнюю строку поискового запроса для клиента
Если нам нужно проверить, что ищет клиент в настоящее время, мы можем создать сканирование между двумя семействами столбцов между «клиентом» и «поиском». Или другой способ — спроектировать ключ строки таким образом, чтобы предоставить вам соответствующую информацию. В нашем случае дизайн ключа строки основан на CustomerId_timestamp _randomuuid. Поскольку ключ строки одинаков для всех семейств столбцов, мы можем использовать фильтр префиксов для фильтрации строк, относящихся только к конкретному клиенту.
|
1
2
3
4
5
|
final String eventId = customerId + "-" + searchQueryInstruction.getCreatedTimeStampInMillis() + "-" + searchQueryInstruction.getEventIdSuffix();...byte[] rowKey = searchQueryInstruction.getEventId().getBytes(CHARSET_DEFAULT);...# 84-1404832902498-7965306a-d256-4ddb-b7a8-fd19cdb99923 |
Чтобы сканировать данные для конкретного клиента,
|
1
2
3
4
5
6
|
... Scan scan = new Scan(); scan.addColumn(HBaseJsonEventSerializer.COLUMFAMILY_SEARCH_BYTES, Bytes.toBytes("customerid")); Filter filter = new PrefixFilter(Bytes.toBytes(customerId + "-")); scan.setFilter(filter); ... |
Для получения дополнительной информации проверьте HBaseServiceImpl.getAllSearchQueryStringsByCustomerInLastOneMonth
Надеюсь, что это поможет вам разобраться в дизайне схемы HBase и обработке данных.
| Ссылка: | HBase: создание статистики событий поисковых кликов для поведения клиентов от нашего партнера JCG Jaibeer Malik в блоге Jai на блоге. |