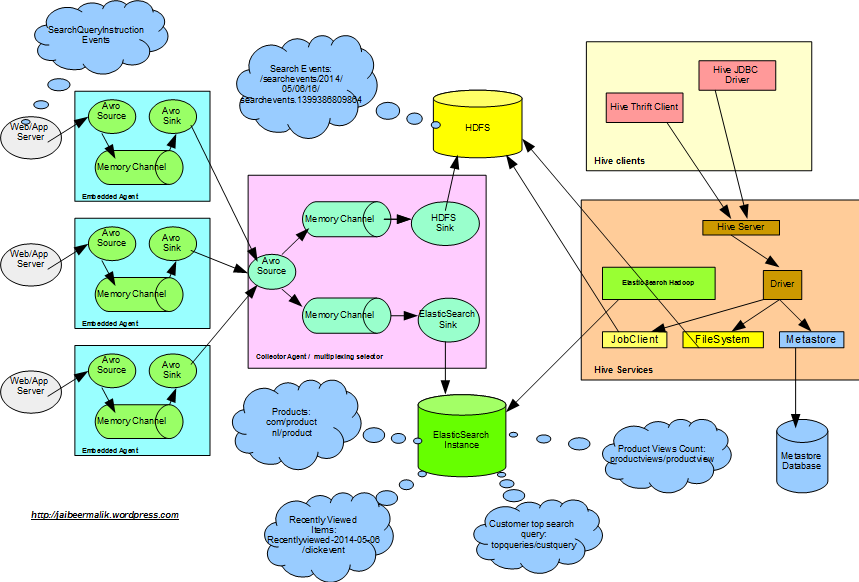
Этот пост посвящен использованию ElasticSearch-Hadoop для чтения данных из системы Hadoop и индексации их в ElasticSearch. Функциональность, которую он охватывает, заключается в том, чтобы индексировать количество просмотров продукта и самый популярный поисковый запрос на одного клиента за последние n дней. Проанализированные данные могут в дальнейшем использоваться на веб-сайте для отображения количества недавно просмотренных клиентов, количества просмотров продукта и верхней строки поискового запроса.
В продолжение предыдущих постов на
- При поиске по продукту клиента кликает аналитика с использованием больших данных ,
- Flume: сбор данных о покупках по продуктам клиентов с использованием Apache Flume ,
- Hive. Запросите самый популярный поисковый запрос клиента и количество просмотров продукта с помощью Apache Hive .
У нас уже есть данные о кликах по запросу клиентов, собранные с помощью Flume и сохраненные в Hadoop HDFS и ElasticSearch, а также о том, как анализировать те же данные с помощью Hive и генерировать статистические данные. Здесь мы еще увидим, как использовать проанализированные данные для повышения качества обслуживания клиентов на веб-сайте и сделать их актуальными для конечных клиентов.
Недавно Рассмотренные пункты
В первой части мы уже рассмотрели, как мы можем использовать приемник Flume ElasticSearch для индексации недавно просмотренного каталога элементов в экземпляре ElasticSearch, и эти данные можно использовать для отображения элементов, щелкаемых в реальном времени, для клиента.
ElasticSearch-Hadoop
Elasticsearch для Apache Hadoop позволяет заданиям Hadoop взаимодействовать с ElasticSearch с небольшой библиотекой и простой настройкой .
Elasticsearch-hadoop-hive, позволяет получить доступ к ElasticSearch с помощью Hive. Как сообщалось в предыдущем посте, у нас есть счетчик просмотров продукта, а также данные самых популярных поисковых запросов клиентов, извлеченные из таблиц Hive. Мы будем читать и индексировать те же данные в ElasticSearch, чтобы их можно было использовать для отображения на веб-сайте.
Функциональность подсчета просмотров товаров
Возьмите сценарий, чтобы отобразить общее количество просмотров каждого продукта по клиенту за последние n дней. Для лучшего пользовательского опыта вы можете использовать ту же функциональность, чтобы показать конечному покупателю, как другие покупатели воспринимают тот же продукт.
Данные Hive для просмотра продуктов
Выберите пример данных из таблицы улья:
|
1
2
3
4
5
|
# search.search_productviews : id, productid, viewcount61, 61, 1548, 48, 816, 16, 4085, 85, 7 |
Индекс количества просмотров товаров
Создайте внешнюю таблицу Hive «search_productviews_to_es» для индексации данных в экземпляре ElasticSearch.
|
1
2
3
4
|
Use search;DROP TABLE IF EXISTS search_productviews_to_es;CREATE EXTERNAL TABLE search_productviews_to_es (id STRING, productid BIGINT, viewcount INT) STORED BY 'org.elasticsearch.hadoop.hive.EsStorageHandler' TBLPROPERTIES('es.resource' = 'productviews/productview', 'es.nodes' = 'localhost', 'es.port' = '9210', 'es.input.json' = 'false', 'es.write.operation' = 'index', 'es.mapping.id' = 'id', 'es.index.auto.create' = 'yes');INSERT OVERWRITE TABLE search_productviews_to_es SELECT qcust.id, qcust.productid, qcust.viewcount FROM search_productviews qcust; |
- Внешняя таблица search_productviews_to_es создана указывает на экземпляр ES
- Конфигурация экземпляра ElasticSearch используется localhost: 9210
- Индекс «productviews» и тип документа «productviews» будут использоваться для индексации данных.
- Index и mappins будут созданы автоматически, если он не существует
- Перезапись при вставке переопределит данные, если они уже существуют на основе поля id.
- Вставка данных осуществляется путем выбора данных из другой таблицы кустов «search_productviews», в которой хранятся аналитические / статистические данные.
Выполните скрипт куста в Java, чтобы проиндексировать данные представлений продукта, HiveSearchClicksServiceImpl.java
|
1
2
3
4
5
|
Collection<HiveScript> scripts = new ArrayList<>(); HiveScript script = new HiveScript(new ClassPathResource("hive/load-search_productviews_to_es.q")); scripts.add(script); hiveRunner.setScripts(scripts); hiveRunner.call(); |
пример данных индекса продукта
Пример данных в индексе ElasticSearch хранится, как показано ниже:
|
1
2
3
4
|
{id=48, productid=48, viewcount=10}{id=49, productid=49, viewcount=20}{id=5, productid=5, viewcount=18}{id=6, productid=6, viewcount=9} |
Функциональность строки поискового запроса клиента
Возьмите сценарий, в котором вы можете захотеть отображать строку верхнего поискового запроса одним клиентом или всеми клиентами на веб-сайте. Вы можете использовать то же самое, чтобы отобразить облако самых популярных поисковых запросов на сайте.
Данные Hive для самых популярных поисковых запросов
Выберите пример данных из таблицы улья:
|
1
2
3
4
5
|
# search.search_customerquery : id, querystring, count, customerid61_queryString59, queryString59, 5, 61298_queryString48, queryString48, 3, 298440_queryString16, queryString16, 1, 44047_queryString85, queryString85, 1, 47 |
Индекс самых популярных поисковых запросов
Создайте внешнюю таблицу Hive «search_customerquery_to_es» для индексации данных в экземпляре ElasticSearch.
|
1
2
3
4
|
Use search;DROP TABLE IF EXISTS search_customerquery_to_es;CREATE EXTERNAL TABLE search_customerquery_to_es (id String, customerid BIGINT, querystring String, querycount INT) STORED BY 'org.elasticsearch.hadoop.hive.EsStorageHandler' TBLPROPERTIES('es.resource' = 'topqueries/custquery', 'es.nodes' = 'localhost', 'es.port' = '9210', 'es.input.json' = 'false', 'es.write.operation' = 'index', 'es.mapping.id' = 'id', 'es.index.auto.create' = 'yes');INSERT OVERWRITE TABLE search_customerquery_to_es SELECT qcust.id, qcust.customerid, qcust.queryString, qcust.querycount FROM search_customerquery qcust; |
- Внешняя таблица search_customerquery_to_es создана указывает на экземпляр ES
- Конфигурация экземпляра ElasticSearch используется localhost: 9210
- Индекс «topqueries» и тип документа «custquery» будут использоваться для индексации данных
- Index и mappins будут созданы автоматически, если он не существует
- Перезапись при вставке переопределит данные, если они уже существуют на основе поля id.
- Вставка данных осуществляется путем выбора данных из другой таблицы кустов «search_customerquery», в которой хранятся аналитические / статистические данные.
Выполнить скрипт куста в Java для индексации данных HiveSearchClicksServiceImpl.java
|
1
2
3
4
5
|
Collection<HiveScript> scripts = new ArrayList<>(); HiveScript script = new HiveScript(new ClassPathResource("hive/load-search_customerquery_to_es.q")); scripts.add(script); hiveRunner.setScripts(scripts); hiveRunner.call(); |
Пример данных индекса topqueries
Данные индекса topqueries для экземпляра ElasticSearch показаны ниже:
|
1
2
3
4
5
6
|
{id=474_queryString95, querystring=queryString95, querycount=10, customerid=474}{id=482_queryString43, querystring=queryString43, querycount=5, customerid=482}{id=482_queryString64, querystring=queryString64, querycount=7, customerid=482}{id=483_queryString6, querystring=queryString6, querycount=2, customerid=483}{id=487_queryString86, querystring=queryString86, querycount=111, customerid=487}{id=494_queryString67, querystring=queryString67, querycount=1, customerid=494} |
Функциональность, описанная выше, является лишь примерной функциональностью, и, конечно, ее необходимо расширить для соответствия конкретному бизнес-сценарию. Это может охватывать бизнес-сценарий отображения облака поисковых запросов клиентам на веб-сайте или для дальнейшей аналитики бизнес-аналитики.
Spring Data
Spring ElasticSearch для тестирования также был включен для создания ESRepository для подсчета общего количества записей и удаления всех.
Проверьте сервис для деталей, ElasticSearchRepoServiceImpl.java
Общее количество просмотров продукта:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
@Document(indexName = "productviews", type = "productview", indexStoreType = "fs", shards = 1, replicas = 0, refreshInterval = "-1")public class ProductView { @Id private String id; @Version private Long version; private Long productId; private int viewCount; ... ... }public interface ProductViewElasticsearchRepository extends ElasticsearchCrudRepository<ProductView, String> { }long count = productViewElasticsearchRepository.count(); |
Лучшие поисковые запросы клиентов:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
|
@Document(indexName = "topqueries", type = "custquery", indexStoreType = "fs", shards = 1, replicas = 0, refreshInterval = "-1")public class CustomerTopQuery { @Id private String id; @Version private Long version; private Long customerId; private String queryString; private int count; ... ... }public interface TopQueryElasticsearchRepository extends ElasticsearchCrudRepository<CustomerTopQuery, String> { }long count = topQueryElasticsearchRepository.count(); |
В следующих постах мы рассмотрим анализ данных с использованием запланированных заданий,
- Использование Oozie для планирования скоординированных заданий для раздела куста и связывания заданий для индексации данных в ElasticSearch.
- Использование Свиньи для подсчета общего количества уникальных клиентов и т. Д.
| Ссылка: | ElasticSearch-Hadoop: индексирование количества просмотров продуктов и самых популярных поисковых запросов клиентов от Hadoop до ElasticSearch от нашего партнера JCG Яибира Малика в блоге Jai на блоге. |