Эта статья посвящена использованию Apache Flume для сбора кликов по продуктам клиентов и для хранения информации с использованием приемников hadoop иasticsearch. Данные могут состоять из различных событий поиска товаров, таких как фильтрация на основе различных аспектов, информация о сортировке, информация о нумерации страниц и другие просматриваемые товары, а также некоторые товары, отмеченные покупателями как избранные. В последующих публикациях мы будем анализировать данные, чтобы использовать их для отображения и анализа.
Функция поиска продукта
Любая платформа электронной коммерции предлагает клиентам различные продукты, и одной из основ этого является функциональность поиска. Предоставление пользователю возможности управляемой навигации с использованием различных фасетов / фильтров или свободного текстового поиска контента является тривиальным из любой из существующих функций поиска.
SearchQueryInstruction
Рассмотрим аналогичный сценарий, когда клиент может искать продукт и позволяет нам фиксировать поведение поиска продукта со следующей информацией,
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
public class SearchQueryInstruction implements Serializable { @JsonIgnore private final String _eventIdSuffix; private String eventId; private String hostedMachineName; private String pageUrl; private Long customerId; private String sessionId; private String queryString; private String sortOrder; private Long pageNumber; private Long totalHits; private Long hitsShown; private final Long createdTimeStampInMillis; private String clickedDocId; private Boolean favourite; @JsonIgnore private Map<String, Set<String>> filters; @JsonProperty(value = "filters") private List<FacetFilter> _filters; public SearchQueryInstruction() { _eventIdSuffix = UUID.randomUUID().toString(); createdTimeStampInMillis = new Date().getTime(); } ... ... private static class FacetFilter implements Serializable { private String code; private String value; public FacetFilter(String code, String value) { this.code = code; this.value = value; } ... ... }} |
Дополнительная информация об источнике доступна на SearchQueryInstruction . Данные сериализуются в формате JSON, чтобы иметь возможность непосредственного использования с ElasticSearch для дальнейшего отображения.
Пример данных, как выглядит информация о кликах на основе кликов пользователей. Данные преобразуются в формат json перед отправкой во встроенный агент Flume.
|
1
2
3
4
|
{"eventid":"629e9b5f-ff4a-4168-8664-6c8df8214aa7-1399386809805-24","hostedmachinename":"192.168.182.1330","pageurl":"http://jaibigdata.com/5","customerid":24,"sessionid":"648a011d-570e-48ef-bccc-84129c9fa400","querystring":null,"sortorder":"desc","pagenumber":3,"totalhits":28,"hitsshown":7,"createdtimestampinmillis":1399386809805,"clickeddocid":"41","favourite":null,"eventidsuffix":"629e9b5f-ff4a-4168-8664-6c8df8214aa7","filters":[{"code":"searchfacettype_color_level_2","value":"Blue"},{"code":"searchfacettype_age_level_2","value":"12-18 years"}]}{"eventid":"648b5cf7-7ca9-4664-915d-23b0d45facc4-1399386809782-298","hostedmachinename":"192.168.182.1333","pageurl":"http://jaibigdata.com/4","customerid":298,"sessionid":"7bf042ea-526a-4633-84cd-55e0984ea2cb","querystring":"queryString48","sortorder":"desc","pagenumber":0,"totalhits":29,"hitsshown":19,"createdtimestampinmillis":1399386809782,"clickeddocid":"9","favourite":null,"eventidsuffix":"648b5cf7-7ca9-4664-915d-23b0d45facc4","filters":[{"code":"searchfacettype_color_level_2","value":"Green"}]}{"eventid":"74bb7cfe-5f8c-4996-9700-0c387249a134-1399386809799-440","hostedmachinename":"192.168.182.1330","pageurl":"http://jaibigdata.com/1","customerid":440,"sessionid":"940c9a0f-a9b2-4f1d-b114-511ac11bf2bb","querystring":"queryString16","sortorder":"asc","pagenumber":3,"totalhits":5,"hitsshown":32,"createdtimestampinmillis":1399386809799,"clickeddocid":null,"favourite":null,"eventidsuffix":"74bb7cfe-5f8c-4996-9700-0c387249a134","filters":[{"code":"searchfacettype_brand_level_2","value":"Apple"}]}{"eventid":"9da05913-84b1-4a74-89ed-5b6ec6389cce-1399386809828-143","hostedmachinename":"192.168.182.1332","pageurl":"http://jaibigdata.com/1","customerid":143,"sessionid":"08a4a36f-2535-4b0e-b86a-cf180202829b","querystring":null,"sortorder":"desc","pagenumber":0,"totalhits":21,"hitsshown":34,"createdtimestampinmillis":1399386809828,"clickeddocid":"38","favourite":true,"eventidsuffix":"9da05913-84b1-4a74-89ed-5b6ec6389cce","filters":[{"code":"searchfacettype_color_level_2","value":"Blue"},{"code":"product_price_range","value":"10.0 - 20.0"}]} |
Apache Flume
Apache Flume используется для сбора и агрегирования данных. Здесь встроенный агент Flume используется для захвата событий инструкции Поискового запроса. В реальном сценарии, основанном на использовании,
- Либо вы можете использовать встроенный агент для сбора данных
- Или через остальные API для передачи данных со страницы в серверный сервис API, предназначенный для сбора событий
- Или вы можете использовать функцию регистрации приложений, чтобы регистрировать все события поиска и настраивать файл журнала для сбора данных.
Рассмотрим сценарий, зависящий от приложения, когда несколько веб-серверов / серверов приложений отправляют данные о событиях агенту сбора данных. Как показано на диаграмме ниже, события щелчков при поиске собираются с нескольких серверов веб / приложений и агента сборщика / консолидатора для сбора данных от всех агентов. Данные дополнительно делятся на основе селектора, использующего стратегию мультиплексирования для хранения в Hadoop HDFS, а также направления соответствующих данных в ElasticSearch, например. Недавно Рассмотренные пункты.
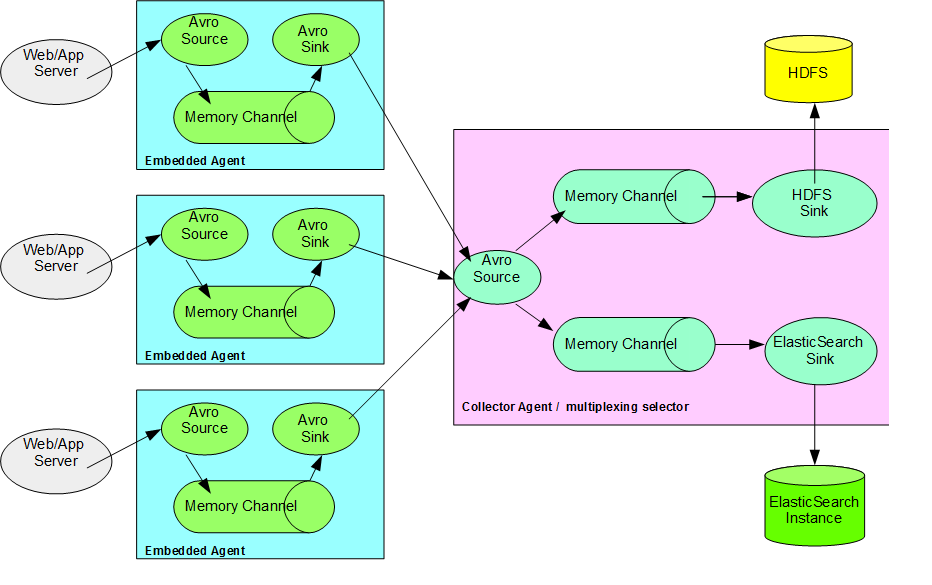
Встроенный агент Flume
Встроенный агент Flume позволяет нам включать агент Flume в само приложение и позволяет нам собирать данные и отправлять их агенту сбора.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
|
private static EmbeddedAgent agent; private void createAgent() { final Map<String, String> properties = new HashMap<String, String>(); properties.put("channel.type", "memory"); properties.put("channel.capacity", "100000"); properties.put("channel.transactionCapacity", "1000"); properties.put("sinks", "sink1"); properties.put("sink1.type", "avro"); properties.put("sink1.hostname", "localhost"); properties.put("sink1.port", "44444"); properties.put("processor.type", "default"); try { agent = new EmbeddedAgent("searchqueryagent"); agent.configure(properties); agent.start(); } catch (final Exception ex) { LOG.error("Error creating agent!", ex); } } |
Данные поиска событий магазина
Flume предоставляет возможность нескольких приемников для хранения данных для последующего анализа. Как показано на диаграмме, мы возьмем сценарий для хранения данных в Apache Hadoop, а также в ElasticSearch для недавно просмотренных элементов.
Раковина Hadoop
Позволяет постоянно хранить данные в HDFS, чтобы иметь возможность впоследствии анализировать их для аналитики.
На основании данных о входящих событиях, скажем, мы хотим хранить их на почасовой основе. Каталог «/ searchevents / 2014/05/15/16 ″ будет хранить все входящие события в течение часа 16
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
private HDFSEventSink sink; sink = new HDFSEventSink(); sink.setName("HDFSEventSink-" + UUID.randomUUID()); channel = new MemoryChannel(); Map<String, String> channelParamters = new HashMap<>(); channelParamters.put("capacity", "100000"); channelParamters.put("transactionCapacity", "1000"); Context channelContext = new Context(channelParamters); Configurables.configure(channel, channelContext); channel.setName("HDFSEventSinkChannel-" + UUID.randomUUID()); Map<String, String> paramters = new HashMap<>(); paramters.put("hdfs.type", "hdfs"); String hdfsBasePath = hadoopClusterService.getHDFSUri() + "/searchevents"; paramters.put("hdfs.path", hdfsBasePath + "/%Y/%m/%d/%H"); paramters.put("hdfs.filePrefix", "searchevents"); paramters.put("hdfs.fileType", "DataStream"); paramters.put("hdfs.rollInterval", "0"); paramters.put("hdfs.rollSize", "0"); paramters.put("hdfs.idleTimeout", "1"); paramters.put("hdfs.rollCount", "0"); paramters.put("hdfs.batchSize", "1000"); paramters.put("hdfs.useLocalTimeStamp", "true"); Context sinkContext = new Context(paramters); sink.configure(sinkContext); sink.setChannel(channel); sink.start(); channel.start(); |
Проверьте FlumeHDFSSinkServiceImpl.java для подробного запуска / остановки приемника hdfs.
Пример данных ниже, хранится в Hadoop, как,
|
1
2
3
|
Check:hdfs://localhost.localdomain:54321/searchevents/2014/05/06/16/searchevents.1399386809864body is:{"eventid":"e8470a00-c869-4a90-89f2-f550522f8f52-1399386809212-72","hostedmachinename":"192.168.182.1334","pageurl":"http://jaibigdata.com/0","customerid":72,"sessionid":"7871a55c-a950-4394-bf5f-d2179a553575","querystring":null,"sortorder":"desc","pagenumber":0,"totalhits":8,"hitsshown":44,"createdtimestampinmillis":1399386809212,"clickeddocid":"23","favourite":null,"eventidsuffix":"e8470a00-c869-4a90-89f2-f550522f8f52","filters":[{"code":"searchfacettype_brand_level_2","value":"Apple"},{"code":"searchfacettype_color_level_2","value":"Blue"}]}body is:{"eventid":"2a4c1e1b-d2c9-4fe2-b38d-9b7d32feb4e0-1399386809743-61","hostedmachinename":"192.168.182.1330","pageurl":"http://jaibigdata.com/0","customerid":61,"sessionid":"78286f6d-cc1e-489c-85ce-a7de8419d628","querystring":"queryString59","sortorder":"asc","pagenumber":3,"totalhits":32,"hitsshown":9,"createdtimestampinmillis":1399386809743,"clickeddocid":null,"favourite":null,"eventidsuffix":"2a4c1e1b-d2c9-4fe2-b38d-9b7d32feb4e0","filters":[{"code":"searchfacettype_age_level_2","value":"0-12 years"}]} |
ElasticSearch Sink
Для просмотра цели, чтобы отобразить недавно просмотренные элементы для конечного пользователя. Мойка ElasticSearch позволяет автоматически создавать ежедневно просматриваемые элементы. Функциональность может быть использована для отображения клиентом недавно просмотренных элементов.
Допустим, у вас уже есть экземпляр ES, работающий на localhost / 9310.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
private ElasticSearchSink sink; sink = new ElasticSearchSink(); sink.setName("ElasticSearchSink-" + UUID.randomUUID()); channel = new MemoryChannel(); Map<String, String> channelParamters = new HashMap<>(); channelParamters.put("capacity", "100000"); channelParamters.put("transactionCapacity", "1000"); Context channelContext = new Context(channelParamters); Configurables.configure(channel, channelContext); channel.setName("ElasticSearchSinkChannel-" + UUID.randomUUID()); Map<String, String> paramters = new HashMap<>(); paramters.put(ElasticSearchSinkConstants.HOSTNAMES, "127.0.0.1:9310"); String indexNamePrefix = "recentlyviewed"; paramters.put(ElasticSearchSinkConstants.INDEX_NAME, indexNamePrefix); paramters.put(ElasticSearchSinkConstants.INDEX_TYPE, "clickevent"); paramters.put(ElasticSearchSinkConstants.CLUSTER_NAME, "jai-testclusterName"); paramters.put(ElasticSearchSinkConstants.BATCH_SIZE, "10"); paramters.put(ElasticSearchSinkConstants.SERIALIZER, ElasticSearchJsonBodyEventSerializer.class.getName()); Context sinkContext = new Context(paramters); sink.configure(sinkContext); sink.setChannel(channel); sink.start(); channel.start(); |
Проверьте FlumeESSinkServiceImpl.java для деталей, чтобы запустить / остановить приемник ElasticSearch.
Данные выборки вasticsearch хранятся как,
|
1
2
3
|
{timestamp=1399386809743, body={pageurl=http://jaibigdata.com/0, querystring=queryString59, pagenumber=3, hitsshown=9, hostedmachinename=192.168.182.1330, createdtimestampinmillis=1399386809743, sessionid=78286f6d-cc1e-489c-85ce-a7de8419d628, eventid=2a4c1e1b-d2c9-4fe2-b38d-9b7d32feb4e0-1399386809743-61, totalhits=32, clickeddocid=null, customerid=61, sortorder=asc, favourite=null, eventidsuffix=2a4c1e1b-d2c9-4fe2-b38d-9b7d32feb4e0, filters=[{value=0-12 years, code=searchfacettype_age_level_2}]}, eventId=2a4c1e1b-d2c9-4fe2-b38d-9b7d32feb4e0}{timestamp=1399386809757, body={pageurl=http://jaibigdata.com/1, querystring=null, pagenumber=1, hitsshown=34, hostedmachinename=192.168.182.1330, createdtimestampinmillis=1399386809757, sessionid=e6a3fd51-fe07-4e21-8574-ce5ab8bfbd68, eventid=fe5279b7-0bce-4e2b-ad15-8b94107aa792-1399386809757-134, totalhits=9, clickeddocid=22, customerid=134, sortorder=desc, favourite=null, eventidsuffix=fe5279b7-0bce-4e2b-ad15-8b94107aa792, filters=[{value=Blue, code=searchfacettype_color_level_2}]}, State=VIEWED, eventId=fe5279b7-0bce-4e2b-ad15-8b94107aa792}{timestamp=1399386809765, body={pageurl=http://jaibigdata.com/0, querystring=null, pagenumber=4, hitsshown=2, hostedmachinename=192.168.182.1331, createdtimestampinmillis=1399386809765, sessionid=29864de8-5708-40ab-a78b-4fae55698b01, eventid=886e9a28-4c8c-4e8c-a866-e86f685ecc54-1399386809765-317, totalhits=2, clickeddocid=null, customerid=317, sortorder=asc, favourite=null, eventidsuffix=886e9a28-4c8c-4e8c-a866-e86f685ecc54, filters=[{value=0-12 years, code=searchfacettype_age_level_2}, {value=0.0 - 10.0, code=product_price_range}]}, eventId=886e9a28-4c8c-4e8c-a866-e86f685ecc54} |
ElasticSearchJsonBodyEventSerializer
Чтобы контролировать, как данные будут проиндексированы в ElasticSearch. Обновите средство поиска событий согласно вашей стратегии, чтобы увидеть, как данные должны быть проиндексированы.
|
01
02
03
04
05
06
07
08
09
10
11
|
public class ElasticSearchJsonBodyEventSerializer implements ElasticSearchEventSerializer { @Override public BytesStream getContentBuilder(final Event event) throws IOException { final XContentBuilder builder = jsonBuilder().startObject(); appendBody(builder, event); appendHeaders(builder, event); return builder; } ... ...} |
Проверьте ElasticSearchJsonBodyEventSerializer.java, чтобы настроить сериализатор на индексирование данных.
Давайте возьмем пример Java, чтобы создать источник Flume для обработки приведенной выше SearchQueryInstruction в тестовых примерах и сохранения данных.
Avro Source с переключателем каналов
Для тестирования давайте создадим источник Avro для перенаправления данных в соответствующие приемники на основе функции мультиплексирования потока.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
//Avro source to start at below port and process incoming data. private AvroSource avroSource; final Map<String, String> properties = new HashMap<String, String>(); properties.put("type", "avro"); properties.put("bind", "localhost"); properties.put("port", "44444"); avroSource = new AvroSource(); avroSource.setName("AvroSource-" + UUID.randomUUID()); Context sourceContext = new Context(properties); avroSource.configure(sourceContext); ChannelSelector selector = new MultiplexingChannelSelector(); //Channels from above services Channel ESChannel = flumeESSinkService.getChannel(); Channel HDFSChannel = flumeHDFSSinkService.getChannel(); List<Channel> channels = new ArrayList<>(); channels.add(ESChannel); channels.add(HDFSChannel); selector.setChannels(channels); final Map<String, String> selectorProperties = new HashMap<String, String>(); selectorProperties.put("type", "multiplexing"); selectorProperties.put("header", "State"); selectorProperties.put("mapping.VIEWED", HDFSChannel.getName() + " " + ESChannel.getName()); selectorProperties.put("mapping.FAVOURITE", HDFSChannel.getName() + " " + ESChannel.getName()); selectorProperties.put("default", HDFSChannel.getName()); Context selectorContext = new Context(selectorProperties); selector.configure(selectorContext); ChannelProcessor cp = new ChannelProcessor(selector); avroSource.setChannelProcessor(cp); avroSource.start(); |
Проверьте FlumeAgentServiceImpl.java для непосредственного хранения данных в выше сконфигурированных приемниках или даже для записи всех данных в файл журнала.
Автономная среда Flume / Hadoop / ElasticSearch
Приложение может использоваться для генерации данных SearchQueryInstruction, и вы можете использовать собственную автономную среду для дальнейшей обработки данных. Если у вас уже есть среда Flume / Hadoop / ElasticSearch, используйте следующие настройки для дальнейшей обработки данных.
Следующая конфигурация (flume.conf) также может быть использована, если у вас уже запущен экземпляр Flume,
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
# Name the components on this agentsearcheventscollectoragent.sources = eventsavrosourcesearcheventscollectoragent.sinks = hdfssink essinksearcheventscollectoragent.channels = hdfschannel eschannel# Bind the source and sink to the channelsearcheventscollectoragent.sources.eventsavrosource.channels = hdfschannel eschannelsearcheventscollectoragent.sinks.hdfssink.channel = hdfschannelsearcheventscollectoragent.sinks.essink.channel = eschannel#Avro source. This is where data will send data to.searcheventscollectoragent.sources.eventsavrosource.type = avrosearcheventscollectoragent.sources.eventsavrosource.bind = 0.0.0.0searcheventscollectoragent.sources.eventsavrosource.port = 44444searcheventscollectoragent.sources.eventsavrosource.selector.type = multiplexingsearcheventscollectoragent.sources.eventsavrosource.selector.header = Statesearcheventscollectoragent.sources.eventsavrosource.selector.mapping.VIEWED = hdfschannel eschannelsearcheventscollectoragent.sources.eventsavrosource.selector.mapping.default = hdfschannel# Use a channel which buffers events in memory. This will keep all incoming stuff in memory. You may change this to file etc. in case of too much data coming and memory an issue.searcheventscollectoragent.channels.hdfschannel.type = memorysearcheventscollectoragent.channels.hdfschannel.capacity = 100000searcheventscollectoragent.channels.hdfschannel.transactionCapacity = 1000searcheventscollectoragent.channels.eschannel.type = memorysearcheventscollectoragent.channels.eschannel.capacity = 100000searcheventscollectoragent.channels.eschannel.transactionCapacity = 1000#HDFS sink. Store events directly to hadoop file system.searcheventscollectoragent.sinks.hdfssink.type = hdfssearcheventscollectoragent.sinks.hdfssink.hdfs.path = hdfs://localhost.localdomain:54321/searchevents/%Y/%m/%d/%Hsearcheventscollectoragent.sinks.hdfssink.hdfs.filePrefix = searcheventssearcheventscollectoragent.sinks.hdfssink.hdfs.fileType = DataStreamsearcheventscollectoragent.sinks.hdfssink.hdfs.rollInterval = 0searcheventscollectoragent.sinks.hdfssink.hdfs.rollSize = 134217728searcheventscollectoragent.sinks.hdfssink.hdfs.idleTimeout = 60searcheventscollectoragent.sinks.hdfssink.hdfs.rollCount = 0searcheventscollectoragent.sinks.hdfssink.hdfs.batchSize = 10searcheventscollectoragent.sinks.hdfssink.hdfs.useLocalTimeStamp = true#Elastic searchsearcheventscollectoragent.sinks.essink.type = elasticsearchsearcheventscollectoragent.sinks.essink.hostNames = 127.0.0.1:9310searcheventscollectoragent.sinks.essink.indexName = recentlyviewedsearcheventscollectoragent.sinks.essink.indexType = clickeventsearcheventscollectoragent.sinks.essink.clusterName = jai-testclusterNamesearcheventscollectoragent.sinks.essink.batchSize = 10searcheventscollectoragent.sinks.essink.ttl = 5searcheventscollectoragent.sinks.essink.serializer = org.jai.flume.sinks.elasticsearch.serializer.ElasticSearchJsonBodyEventSerializer |
Чтобы протестировать приложение, как инструкции поискового запроса ведут себя в существующем экземпляре hadoop, настройте экземпляры hadoop иasticsearch отдельно. Приложение использует Cloudera hadoop 5.0 для тестирования.
В последующем посте мы рассмотрим для дальнейшего анализа сгенерированных данных,
- С помощью Hive запрашивайте данные о самых популярных запросах клиентов и количестве просмотров продукта.
- Использование ElasticSearch Hadoop для индексации самых популярных запросов клиентов и данных о продуктах
- Использование Pig для подсчета общего количества уникальных клиентов
- Использование Oozie для планирования согласованных заданий для раздела куста и связывания заданий для индексации данных в ElasticSearch.
| Ссылка: | Flume. Сбор информации о кликах по продуктам клиентов производится с помощью Apache Flume от нашего партнера по JCG Яибира Малика в блоге Jai . |