Этот пост посвящен использованию Apache Hive для запроса данных о кликах поиска, хранящихся в Hadoop. Мы возьмем примеры для генерации поискового запроса и статистики по количеству просмотров.
В продолжение предыдущих постов на
- Аналитические клики по продуктам поиска клиентов с использованием больших данных ,
- Flume: сбор данных о покупках по продуктам клиентов с использованием Apache Flume ,
у нас уже есть данные о кликах, полученных с помощью Flume в Hadoop HDFS.
Здесь будет проведен дальнейший анализ использования Hive для запроса сохраненных данных в Hadoop.
улей
Hive позволяет нам запрашивать большие данные, используя SQL-подобный язык HiveQL.
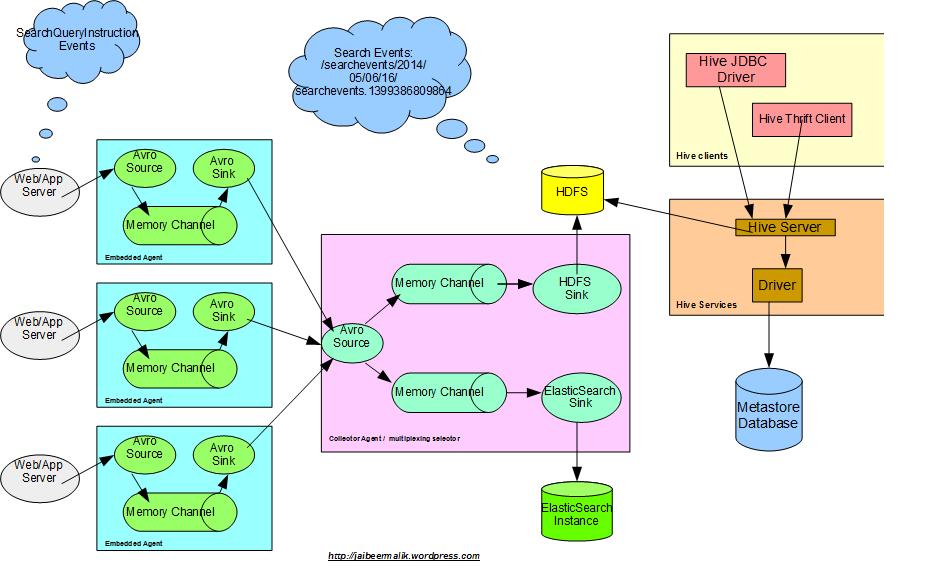
Данные Hadoop
Как сообщалось в последнем сообщении, у нас есть данные по поисковым кликам, хранящиеся в hadoop в следующем формате «/ searchevents / 2014/05/15/16 /». Данные хранятся в отдельном каталоге, созданном за час.
Файлы создаются как:
|
1
|
hdfs://localhost.localdomain:54321/searchevents/2014/05/06/16/searchevents.1399386809864 |
Данные хранятся как DataSteam:
|
1
2
|
{"eventid":"e8470a00-c869-4a90-89f2-f550522f8f52-1399386809212-72","hostedmachinename":"192.168.182.1334","pageurl":"http://jaibigdata.com/0","customerid":72,"sessionid":"7871a55c-a950-4394-bf5f-d2179a553575","querystring":null,"sortorder":"desc","pagenumber":0,"totalhits":8,"hitsshown":44,"createdtimestampinmillis":1399386809212,"clickeddocid":"23","favourite":null,"eventidsuffix":"e8470a00-c869-4a90-89f2-f550522f8f52","filters":[{"code":"searchfacettype_brand_level_2","value":"Apple"},{"code":"searchfacettype_color_level_2","value":"Blue"}]}{"eventid":"2a4c1e1b-d2c9-4fe2-b38d-9b7d32feb4e0-1399386809743-61","hostedmachinename":"192.168.182.1330","pageurl":"http://jaibigdata.com/0","customerid":61,"sessionid":"78286f6d-cc1e-489c-85ce-a7de8419d628","querystring":"queryString59","sortorder":"asc","pagenumber":3,"totalhits":32,"hitsshown":9,"createdtimestampinmillis":1399386809743,"clickeddocid":null,"favourite":null,"eventidsuffix":"2a4c1e1b-d2c9-4fe2-b38d-9b7d32feb4e0","filters":[{"code":"searchfacettype_age_level_2","value":"0-12 years"}]} |
Spring Data
Мы будем использовать Spring для Apache Hadoop, чтобы запускать задания кустов с помощью Spring. Чтобы настроить среду куста в вашем приложении, используйте следующие конфигурации:
|
01
02
03
04
05
06
07
08
09
10
11
|
<hdp:configuration id="hadoopConfiguration" resources="core-site.xml"> fs.default.name=hdfs://localhost.localdomain:54321 mapred.job.tracker=localhost.localdomain:54310</hdp:configuration><hdp:hive-server auto-startup="true" port="10234" min-threads="3" id="hiveServer" configuration-ref="hadoopConfiguration"></hdp:hive-server><hdp:hive-client-factory id="hiveClientFactory" host="localhost" port="10234"></hdp:hive-client-factory><hdp:hive-runner id="hiveRunner" run-at-startup="false" hive-client-factory-ref="hiveClientFactory"></hdp:hive-runner> |
Проверьте файл контекста весны applicationContext -asticsearch.xml для получения дополнительной информации. Мы будем использовать hiveRunner для запуска скриптов улья.
Все скрипты куста в приложении находятся в папке ресурсов куста .
Сервис для запуска всех скриптов кустов можно найти по адресу HiveSearchClicksServiceImpl.java
Настройка базы данных
Давайте настроим базу данных для запроса данных в первую очередь.
|
1
2
|
DROP DATABASE IF EXISTS search CASCADE;CREATE DATABASE search; |
Запросить события поиска с использованием внешней таблицы
Мы создадим Внешнюю таблицу search_clicks для чтения данных поисковых событий, хранящихся в hadoop.
|
1
2
|
USE search;CREATE EXTERNAL TABLE IF NOT EXISTS search_clicks (eventid String, customerid BIGINT, hostedmachinename STRING, pageurl STRING, totalhits INT, querystring STRING, sessionid STRING, sortorder STRING, pagenumber INT, hitsshown INT, clickeddocid STRING, filters ARRAY<STRUCT<code:STRING, value:STRING>>, createdtimestampinmillis BIGINT) PARTITIONED BY (year STRING, month STRING, day STRING, hour STRING) ROW FORMAT SERDE 'org.jai.hive.serde.JSONSerDe' LOCATION 'hdfs:///searchevents/'; |
JSONSerDe
Пользовательский SerDe «org.jai.hive.serde.JSONSerDe» используется для сопоставления данных JSON. Проверьте более подробную информацию о том же JSONSerDe.java
Если вы выполняете запросы из самого Eclipse, зависимости будут автоматически разрешены. Если вы работаете с консоли куста, убедитесь, что для создания класса jar-файла добавьте соответствующую зависимость к консоли улья, прежде чем выполнять запросы куста.
|
1
2
3
4
5
6
7
8
9
|
#create hive json serde jarjar cf jaihivejsonserde-1.0.jar org/jai/hive/serde/JSONSerDe.class# run on hive console to add jaradd jar /opt/hive/lib/jaihivejsonserde-1.0.jar;# Or add jar path to hive-site.xml file permanently<property> <name>hive.aux.jars.path</name> <value>/opt/hive/lib/jaihivejsonserde-1.0.jar</value></property> |
Создать раздел улья
Мы будем использовать стратегию разделов кустов для чтения данных, хранящихся в hadoop в иерархических положениях. Исходя из указанного выше местоположения «/ searchevents / 2014/05/06/16 /», мы передадим следующие значения параметров (DBNAME = search, TBNAME = search_clicks, YEAR = 2014, MONTH = 05, DAY = 06, HOUR = 16).
|
1
2
|
USE ${hiveconf:DBNAME};ALTER TABLE ${hiveconf:TBNAME} ADD IF NOT EXISTS PARTITION(year='${hiveconf:YEAR}', month='${hiveconf:MONTH}', day='${hiveconf:DAY}', hour='${hiveconf:HOUR}') LOCATION "hdfs:///searchevents/${hiveconf:YEAR}/${hiveconf:MONTH}/${hiveconf:DAY}/${hiveconf:HOUR}/"; |
Чтобы запустить скрипт,
|
01
02
03
04
05
06
07
08
09
10
11
12
|
Collection<HiveScript> scripts = new ArrayList<>(); Map<String, String> args = new HashMap<>(); args.put("DBNAME", dbName); args.put("TBNAME", tbName); args.put("YEAR", year); args.put("MONTH", month); args.put("DAY", day); args.put("HOUR", hour); HiveScript script = new HiveScript(new ClassPathResource("hive/add_partition_searchevents.q"), args); scripts.add(script); hiveRunner.setScripts(scripts); hiveRunner.call(); |
В следующем посте мы расскажем, как использовать задание координатора Oozie для автоматического создания разделов улья для почасовых данных.
Получить все Поиск Нажмите События
Получить поисковые события, хранящиеся во внешней таблице search_clicks. Передайте следующие значения параметров (DBNAME = search, TBNAME = search_clicks, YEAR = 2014, MONTH = 05, DAY = 06, HOUR = 16).
|
1
2
|
USE ${hiveconf:DBNAME};select eventid, customerid, querystring, filters from ${hiveconf:TBNAME} where year='${hiveconf:YEAR}' and month='${hiveconf:MONTH}' and day='${hiveconf:DAY}' and hour='${hiveconf:HOUR}'; |
Это вернет вам все данные в указанном месте, а также поможет вам проверить ваш пользовательский SerDe.
Найти виды товаров за последние 30 дней
Сколько раз продукт был просмотрен / кликнул за последние n дней.
|
1
2
3
4
5
|
Use search;DROP TABLE IF EXISTS search_productviews;CREATE TABLE search_productviews(id STRING, productid BIGINT, viewcount INT);-- product views count in the last 30 days.INSERT INTO TABLE search_productviews select clickeddocid as id, clickeddocid as productid, count(*) as viewcount from search_clicks where clickeddocid is not null and createdTimeStampInMillis > ((unix_timestamp() * 1000) - 2592000000) group by clickeddocid order by productid; |
Чтобы запустить скрипт,
|
1
2
3
4
5
|
Collection<HiveScript> scripts = new ArrayList<>(); HiveScript script = new HiveScript(new ClassPathResource("hive/load-search_productviews-table.q")); scripts.add(script); hiveRunner.setScripts(scripts); hiveRunner.call(); |
Пример данных, выберите данные из таблицы «search_productviews».
|
1
2
3
4
5
|
# id, productid, viewcount61, 61, 1548, 48, 816, 16, 4085, 85, 7 |
Найти самые популярные запросы Cutomer за последние 30 дней
|
1
2
3
4
5
|
Use search;DROP TABLE IF EXISTS search_customerquery;CREATE TABLE search_customerquery(id String, customerid BIGINT, querystring String, querycount INT);-- customer top query string in the last 30 daysINSERT INTO TABLE search_customerquery select concat(customerid,"_",queryString), customerid, querystring, count(*) as querycount from search_clicks where querystring is not null and customerid is not null and createdTimeStampInMillis > ((unix_timestamp() * 1000) - 2592000000) group by customerid, querystring order by customerid; |
Пример данных, выберите данные из таблицы «search_customerquery».
|
1
2
3
4
5
|
# id, querystring, count, customerid61_queryString59, queryString59, 5, 61298_queryString48, queryString48, 3, 298440_queryString16, queryString16, 1, 44047_queryString85, queryString85, 1, 47 |
Анализ граней / фильтров для управляемой навигации
Вы можете дополнительно расширить запросы Hive, чтобы сгенерировать статистику поведения конечных клиентов в течение определенного периода времени, используя фасет / фильтры для поиска соответствующего продукта.
|
1
2
3
4
5
6
7
|
USE search;-- How many times a particular filter has been clicked.select count(*) from search_clicks where array_contains(filters, struct("searchfacettype_color_level_2", "Blue"));-- how many distinct customer clicked the filterselect DISTINCT customerid from search_clicks where array_contains(filters, struct("searchfacettype_color_level_2", "Blue"));-- top query filters by a customerselect customerid, filters.code, filters.value, count(*) as filtercount from search_clicks group by customerid, filters.code, filters.value order by filtercount DESC limit 100; |
Запросы Hive для извлечения данных могут планироваться на еженедельной / почасовой основе в зависимости от требований и могут выполняться с использованием планировщика заданий, такого как Oozie. Данные могут в дальнейшем использоваться для аналитики BI или улучшения качества обслуживания клиентов.
В последующих постах мы рассмотрим, чтобы проанализировать полученные данные дальше,
- Использование ElasticSearch Hadoop для индексации самых популярных запросов клиентов и данных о продуктах
- Использование Oozie для планирования согласованных заданий для раздела куста и связывания заданий для индексации данных в ElasticSearch.
- Использование Свиньи для подсчета общего количества уникальных клиентов и т. Д.
| Ссылка: | Hive. Запросите самый популярный поисковый запрос клиента и количество просмотров продукта с помощью Apache Hive от нашего партнера по JCG Яибира Малика из блога Jai . |