За последнее десятилетие использование искусственных нейронных сетей (ИНС) значительно возросло. Люди использовали ANNs в медицинской диагностике , для прогнозирования цен на биткойны и для создания поддельных видео Обамы ! Неужели вы не хотели всегда создавать такой для себя? В этом уроке мы создадим модель для распознавания рукописных цифр.
Мы используем библиотеку keras для обучения модели в этом уроке. Keras — это библиотека высокого уровня на Python, которая является оболочкой для TensorFlow , CNTK и Theano . По умолчанию Keras использует бэкэнд TensorFlow по умолчанию, и мы будем использовать его для обучения нашей модели.
Искусственные нейронные сети
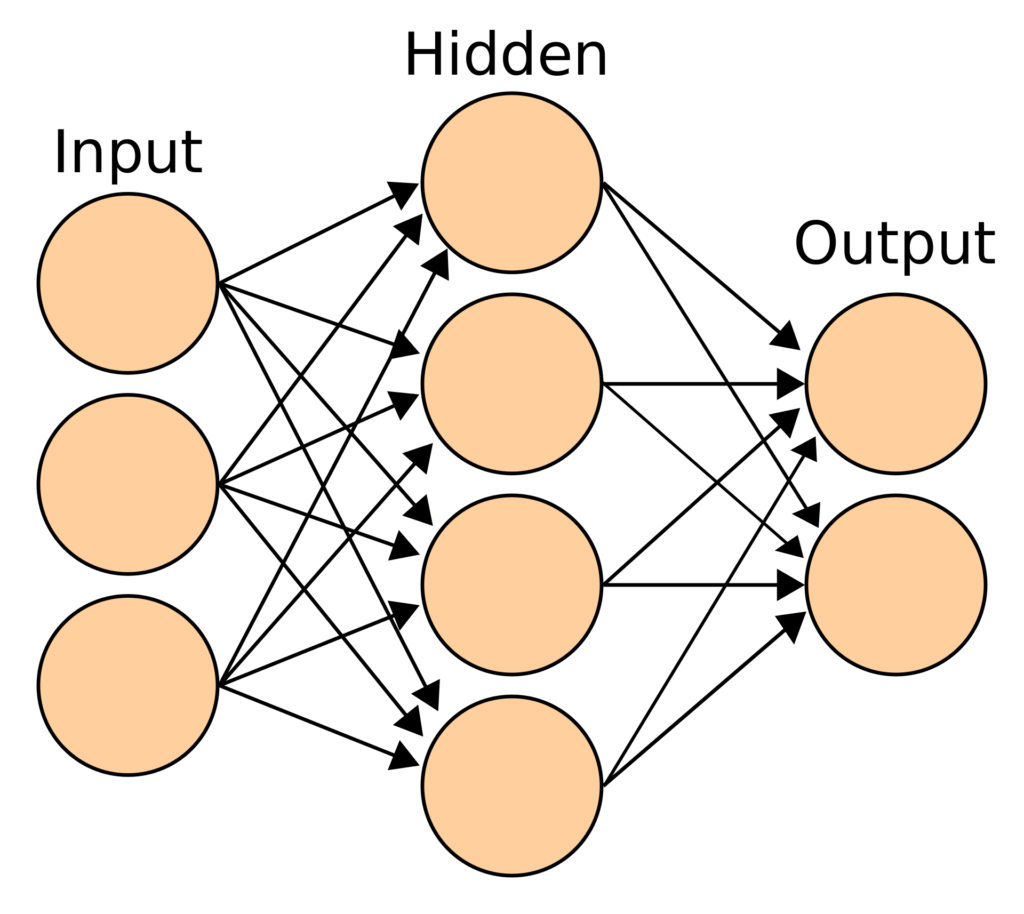
Искусственная нейронная сеть — это математическая модель, которая преобразует набор входных данных в набор выходных данных через ряд скрытых слоев. ИНС работает со скрытыми слоями, каждый из которых является переходной формой, связанной с вероятностью. В типичной нейронной сети каждый узел слоя принимает в качестве входных данных все узлы предыдущего уровня. Модель может иметь один или несколько скрытых слоев.
ANN получают входной слой, чтобы преобразовать его через скрытые слои. ANN инициализируется путем назначения случайных весов и смещений каждому узлу скрытых слоев. Поскольку данные обучения вводятся в модель, она изменяет эти веса и смещения, используя ошибки, генерируемые на каждом шаге. Следовательно, наша модель «изучает» шаблон при прохождении данных обучения.
Извилистые нейронные сети
В этом уроке мы собираемся идентифицировать цифры — это простая версия классификации изображений. Изображение, по сути, представляет собой набор точек или пикселей. Пиксель можно идентифицировать по цветам его компонентов (RGB). Следовательно, входные данные изображения представляют собой двумерный массив пикселей, каждый из которых представляет цвет.
Если бы мы обучали обычную нейронную сеть на основе данных изображений, нам пришлось бы предоставить длинный список входов, каждый из которых был бы подключен к следующему скрытому слою. Это затрудняет процесс расширения.

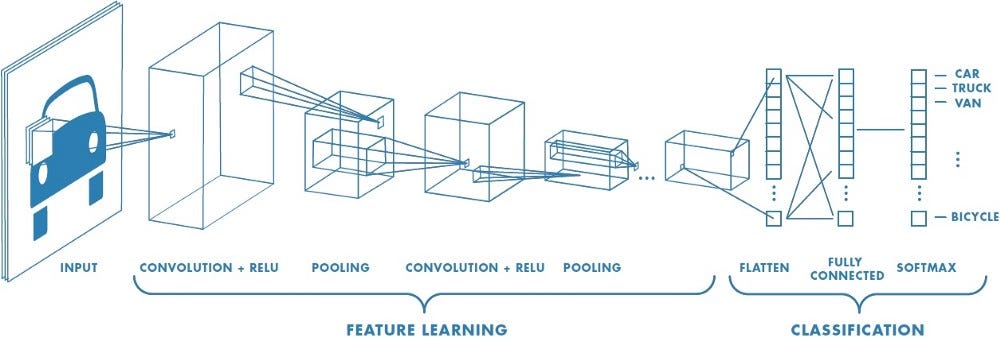
В извилистой нейронной сети (CNN) слои расположены в виде трехмерного массива (координата оси X, координата оси Y и цвет). Следовательно, узел скрытого слоя будет связан только с небольшой областью в окрестности соответствующего входного слоя, что делает процесс намного более эффективным, чем традиционная нейронная сеть. Поэтому CNN очень популярны, когда дело доходит до работы с изображениями и видео.

{kind=link}
{kind=link}
Различные типы слоев в CNN являются следующими:
- сверточные слои : они выполняют ввод через определенные фильтры, которые идентифицируют элементы изображения
- объединяющие слои : они объединяют сверточные элементы, помогая уменьшить их количество
- сглаживать слои : они преобразуют N-мерный слой в 1D слой
- слой классификации : последний слой, который сообщает нам конечный результат.
Давайте теперь исследуем данные.
Изучите набор данных MNIST
Как вы, возможно, уже поняли, нам нужны помеченные данные для обучения любой модели. В этом уроке мы будем использовать набор данных MNIST из рукописных цифр. Этот набор данных является частью пакета Keras. Он содержит обучающий набор из 60000 примеров и тестовый набор из 10000 примеров. Мы будем обучать данные на тренировочном наборе и проверять результаты на основе данных испытаний. Кроме того, мы создадим собственное изображение, чтобы проверить, может ли модель правильно его предсказать.
Во-первых, давайте импортируем набор данных MNIST из Keras. Метод .load_data() возвращает наборы данных обучения и тестирования:
from keras.datasets import mnist (x_train, y_train), (x_test, y_test) = mnist.load_data()
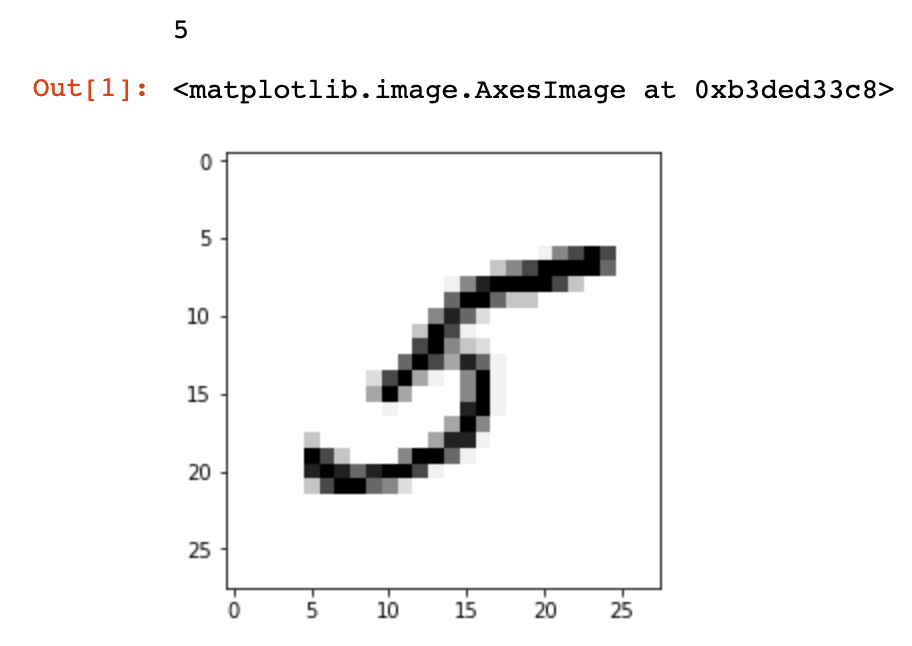
Давайте попробуем визуализировать цифры в наборе данных. Если вы используете ноутбуки Jupyter, используйте следующую магическую функцию для отображения встроенных графиков Matplotlib :
%matplotlib inline
Затем импортируйте модуль pyplot из matplotlib и используйте метод .imshow() для отображения изображения:
import matplotlib.pyplot as plt image_index = 35 print(y_train[image_index]) plt.imshow(x_train[image_index], cmap='Greys') plt.show()
Ярлык изображения печатается, а затем изображение отображается.
Давайте проверим размеры обучающих и тестовых наборов данных:
print(x_train.shape) print(x_test.shape)
Обратите внимание, что каждое изображение имеет размеры 28 х 28:
(60000, 28, 28) (10000, 28, 28)
Далее, мы также можем изучить зависимую переменную, хранящуюся в y_train . Давайте будем печатать все этикетки до тех цифр, которые мы визуализировали выше:
print(y_train[:image_index + 1])
[5 0 4 1 9 2 1 3 1 4 3 5 3 6 1 7 2 8 6 9 4 0 9 1 1 2 4 3 2 7 3 8 6 9 0 5]
Очистка данных
Теперь, когда мы увидели структуру данных, давайте продолжим работать с ними, прежде чем создавать модель.
Для работы с API Keras нам необходимо изменить каждое изображение в формат (M x N x 1). Мы будем использовать метод .reshape() для выполнения этого действия. Наконец, нормализуйте данные изображения, разделив значение каждого пикселя на 255 (поскольку значение RGB может варьироваться от 0 до 255):
# save input image dimensions img_rows, img_cols = 28, 28 x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1) x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1) x_train /= 255 x_test /= 255
Далее нам нужно преобразовать зависимую переменную в виде целых чисел в матрицу двоичного класса. Это может быть достигнуто с помощью функции to_categorical() :
from keras.utils import to_categorical num_classes = 10 y_train = to_categorical(y_train, num_classes) y_test = to_categorical(y_test, num_classes)
Теперь мы готовы создать модель и обучить ее!
Дизайн модели
Процесс проектирования модели является наиболее сложным фактором, оказывающим непосредственное влияние на производительность модели. Для этого урока мы будем использовать этот дизайн из документации Keras .
Чтобы создать модель, мы сначала инициализируем последовательную модель. Создает пустой объект модели. Первый шаг — добавить сверточный слой, который принимает входное изображение:
from keras.models import Sequential from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D model = Sequential() model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=(img_rows, img_cols, 1)))
Активация «relu» означает «выпрямленные линейные единицы», которая принимает максимум значения или ноль. Затем мы добавляем еще один сверточный слой, а затем слой объединения:
model.add(Conv2D(64, (3, 3), activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2)))
Далее мы добавляем «выпадающий» слой. В то время как нейронные сети обучаются на огромных наборах данных, может возникнуть проблема переобучения. Чтобы избежать этой проблемы, мы случайным образом отбрасываем юниты и их соединения в процессе обучения. В этом случае мы отбросим 25% единиц:
model.add(Dropout(0.25))
Затем мы добавляем выравнивающий слой, чтобы преобразовать предыдущий скрытый слой в одномерный массив:
model.add(Flatten())
Как только мы сгладим данные в одномерный массив, мы можем добавить плотный скрытый слой, который является нормальным для традиционной нейронной сети. Затем добавьте еще один выпадающий слой перед добавлением окончательного плотного слоя, который классифицирует данные:
model.add(Dense(128, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(num_classes, activation='softmax'))
Активация «softmax» используется, когда мы хотим классифицировать данные в несколько заранее определенных классов.
Компилировать и обучать модель
В процессе проектирования модели мы создали пустую модель без целевой функции. Нам нужно скомпилировать модель и указать функцию потерь, функцию оптимизатора и метрику для оценки производительности модели.
Нам нужно использовать sparse_categorical_crossentropy потери sparse_categorical_crossentropy в случае, если у нас есть целочисленная переменная. Для зависимой переменной на основе вектора, такой как массив из десяти размеров, в качестве выходных данных каждого теста, используйте categorical_crossentropy . В этом примере мы будем использовать оптимизатор adam . Метрика является основой для оценки производительности нашей модели, хотя об этом мы можем судить и не используем на этапе обучения:
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
Теперь мы готовы обучать модель с использованием .fit() . При обучении модели необходимо указать эпоху и размер партии. Эпоха — это один проход вперед и один проход назад всех примеров обучения. Размер партии — это количество обучающих примеров за один проход вперед или назад.
Наконец, сохраните модель после завершения обучения, чтобы использовать ее результаты на более позднем этапе:
batch_size = 128 epochs = 10 model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(x_test, y_test)) score = model.evaluate(x_test, y_test, verbose=0) print('Test loss:', score[0]) print('Test accuracy:', score[1]) model.save("test_model.h5")
Когда мы запустим приведенный выше код, при выводе модели будет показан следующий вывод. Это займет около десяти минут в ноутбуках MacBook Air 2018 с ноутбуками Jupyter:
Train on 60000 samples, validate on 10000 samples Epoch 1/10 60000/60000 [==============================] - 144s 2ms/step - loss: 0.2827 - acc: 0.9131 - val_loss: 0.0612 - val_acc: 0.9809 Epoch 2/10 60000/60000 [==============================] - 206s 3ms/step - loss: 0.0922 - acc: 0.9720 - val_loss: 0.0427 - val_acc: 0.9857 ... Epoch 9/10 60000/60000 [==============================] - 142s 2ms/step - loss: 0.0329 - acc: 0.9895 - val_loss: 0.0276 - val_acc: 0.9919 Epoch 10/10 60000/60000 [==============================] - 141s 2ms/step - loss: 0.0301 - acc: 0.9901 - val_loss: 0.0261 - val_acc: 0.9919 Test loss: 0.026140549496188395 Test accuracy: 0.9919
В конце последней эпохи точность тестового набора данных составляет 99,19%. Трудно комментировать, насколько высокой должна быть точность. Для пробного запуска точность свыше 99% очень хорошая. Тем не менее, есть много возможностей для улучшения путем настройки параметров модели. Вот представление от конкурса распознавания цифр на Kaggle, который достиг точности 99,7%.
Тест с рукописными цифрами
Теперь, когда модель готова, давайте используем собственное изображение для оценки производительности модели. Я разместил пользовательскую цифру 28 × 28 на Imgur . Сначала давайте прочитаем изображение с imageio библиотеки imageio и рассмотрим, как выглядят входные данные:
import imageio import numpy as np from matplotlib import pyplot as plt im = imageio.imread("https://i.imgur.com/a3Rql9C.png")
Затем преобразуйте значения RGB в оттенки серого . Затем мы можем использовать метод .imshow() как описано выше, для отображения изображения:
gray = np.dot(im[...,:3], [0.299, 0.587, 0.114]) plt.imshow(gray, cmap = plt.get_cmap('gray')) plt.show()

Затем измените изображение и нормализуйте значения, чтобы подготовить его к использованию в только что созданной модели:
# reshape the image gray = gray.reshape(1, img_rows, img_cols, 1) # normalize image gray /= 255
Загрузите модель из сохраненного файла с помощью функции load_model() и прогнозируйте цифру с помощью .predict() :
# load the model from keras.models import load_model model = load_model("test_model.h5") # predict digit prediction = model.predict(gray) print(prediction.argmax())
Модель правильно предсказывает цифру, показанную на рисунке:
5
Последние мысли
В этом уроке мы создали нейронную сеть с Keras, используя бэкэнд TensorFlow для классификации рукописных цифр. Хотя мы достигли точности 99%, все еще есть возможности для улучшения. Мы также узнали, как классифицировать пользовательские рукописные цифры, которые не были частью тестового набора данных. Этот урок, однако, только что поцарапал область искусственных нейронных сетей. Есть бесконечное использование нейронных сетей, которые ограничены только нашим воображением.
Можете ли вы улучшить точность модели? Какие еще техники вы можете использовать? Дайте мне знать в Твиттере .