За последние несколько лет базы данных NoSQL значительно выросли благодаря их менее ограниченной структуре, масштабируемой схеме и быстрому доступу по сравнению с традиционными реляционными базами данных (RDBMS / SQL). MongoDB — это документально-ориентированная база данных NoSQL с открытым исходным кодом, в которой хранятся данные в виде JSON-подобных объектов. Он стал одной из ведущих баз данных благодаря своей динамической схеме, высокой масштабируемости, оптимальной производительности запросов, более быстрой индексации и активному сообществу пользователей.
Если вы исходите из опыта работы с RDBMS / SQL, понимание концепций NoSQL и MongoDB может быть немного сложным при запуске, поскольку обе технологии имеют очень разный способ представления данных. Эта статья поможет вам понять, как домен RDBMS / SQL, его функциональные возможности, термины и язык запросов сопоставляются с базой данных MongoDB. Под отображением я подразумеваю, что если у нас есть концепция в RDBMS / SQL, мы увидим ее эквивалентную концепцию в MongoDB.
Мы начнем с отображения основных реляционных концепций, таких как таблица, строка, столбец и т. Д., И перейдем к обсуждению индексации и объединений. Затем мы рассмотрим запросы SQL и обсудим соответствующие запросы к базе данных MongoDB. В статье предполагается, что вы знакомы с основными понятиями реляционных баз данных и SQL, потому что на протяжении всей статьи будет сделан упор на понимание того, как эти понятия отображаются в MongoDB. Давайте начнем.
Таблицы сопоставления, строки и столбцы
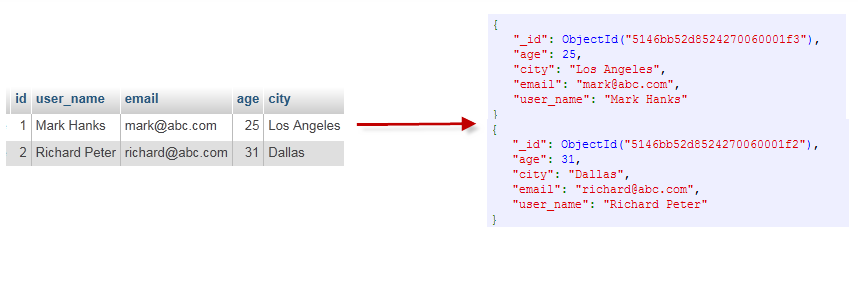
Каждая база данных в MongoDB состоит из коллекций, которые эквивалентны базе данных RDBMS, состоящей из таблиц SQL. Каждая коллекция хранит данные в форме документов, что эквивалентно таблицам, хранящим данные в строках. В то время как строка хранит данные в своем наборе столбцов, документ имеет JSON-подобную структуру (известную как BSON в MongoDB). Наконец, то, как у нас есть строки в строке SQL, у нас есть поля в MongoDB. Ниже приведен пример документа (строка чтения), в котором есть несколько полей (столбцы чтения), в которых хранятся пользовательские данные:
|
1
2
3
4
5
6
7
|
{
«_id»: ObjectId(«5146bb52d8524270060001f3»),
«age»: 25,
«city»: «Los Angeles»,
«email»: «mark@abc.com»,
«user_name»: «Mark Hanks»
}
|
Этот документ эквивалентен одной строке в RDBMS. Коллекция состоит из множества таких документов, так же как таблица состоит из множества строк. Обратите внимание, что каждый документ в коллекции имеет уникальное поле _id , которое представляет собой 12-байтовое поле, которое служит первичным ключом для документов. Поле создается автоматически при создании документа и используется для уникальной идентификации каждого документа.
Чтобы лучше понять сопоставления, давайте рассмотрим пример users таблицы SQL и соответствующей структуры в MongoDB. Как показано на рисунке 1, каждая строка в таблице SQL преобразуется в документ, а каждый столбец — в поле в MongoDB.
Динамическая Схема
Здесь интересно обратить внимание на то, что разные документы в коллекции могут иметь разные схемы. Таким образом, в MongoDB возможно, чтобы один документ имел пять полей, а другой — семь полей. Поля могут быть легко добавлены, удалены и изменены в любое время. Также нет ограничений на типы данных полей. Таким образом, в одном случае поле может содержать данные типа int а в следующем случае оно может содержать array .
Эти понятия должны показаться очень разными для читателей, происходящих из предыстории СУБД, где предварительно определены структуры таблиц, их столбцы, типы данных и отношения. Эта функциональность для использования динамической схемы позволяет нам генерировать динамические документы во время выполнения.
Например, рассмотрим следующие два документа внутри одной коллекции, но имеющие разные схемы (рис. 2):

Первый документ содержит поля address и dob которых нет во втором документе, в то время как второй документ содержит поля gender и gender occupation которых нет в первом. Представьте себе, если бы мы разработали эту вещь в SQL, мы бы сохранили четыре дополнительных столбца для address , dob , gender и gender occupation , некоторые из которых содержали бы пустые (или нулевые) значения и, следовательно, занимали бы ненужное пространство.
Эта модель динамической схемы является причиной, по которой базы данных NosSQL хорошо масштабируются с точки зрения дизайна. Различные сложные схемы (иерархические, древовидные и т. Д.), Для которых требуется количество таблиц СУБД, могут быть эффективно разработаны с использованием таких документов. Типичным примером является хранение сообщений пользователей, их лайков, комментариев и другой связанной информации в виде документов. Реализация SQL для этого в идеале должна иметь отдельные таблицы для хранения сообщений, комментариев и лайков, в то время как документ MongoDB может хранить всю эту информацию в одном документе.
Сопоставление карт и отношений
Отношения в RDBMS достигаются с помощью отношений первичного и внешнего ключей и опроса тех, кто использует соединения. В MongoDB нет такого простого отображения, но здесь отношения разработаны с использованием встроенных и связывающих документов.
Рассмотрим пример, в котором нам нужно хранить информацию о пользователе и соответствующую контактную информацию. В идеальном проекте SQL было бы две таблицы, например user_information и contact_information , с первичными ключами id и contact_id как показано на рис. 3. Таблица contact_information также будет содержать столбец user_id который будет внешним ключом, связывающим поле id с таблицей user_information ,

Теперь мы увидим, как мы будем проектировать такие отношения в MongoDB, используя подходы связывания документов и встроенных документов. Обратите внимание, что в схеме SQL мы обычно добавляем столбец (например, id и contact_id в нашем случае), который выступает в качестве основного столбца для этой таблицы. Однако в MongoDB мы обычно используем автоматически сгенерированное поле _id в качестве первичного ключа для уникальной идентификации документов.
Связывание документов
Этот подход будет использовать две коллекции, user_information и contact_information каждая из которых имеет свои уникальные поля contact_information . У нас будет поле user_id в документе contact_information которое относится к полю user_information документа user_information показывающее, какому пользователю соответствует контакт. (См. Рис. 4). Обратите внимание, что в MongoDB отношения и соответствующие им операции должны обрабатываться вручную (например, с помощью кода), поскольку ограничения и правила внешнего ключа не применяются.
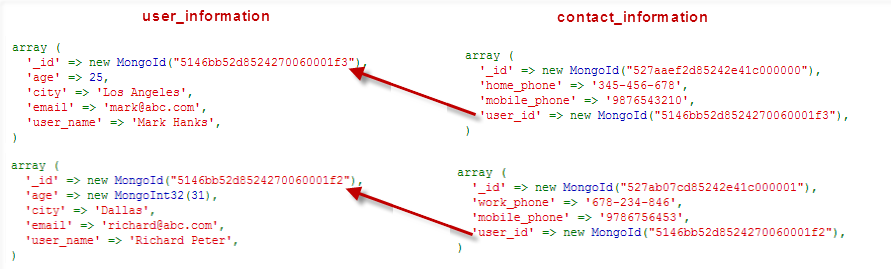
Поле user_id в нашем документе — это просто поле, содержащее некоторые данные, и вся логика, связанная с ним, должна быть реализована нами. Например, даже если вы вставите некоторый user_id в документ contact_information , который не существует в коллекции user_information , MongoDB не собирается user_id какую-либо ошибку, говоря, что соответствующий user_id не был найден в коллекции user_information (в отличие от SQL, где это будет недопустимое ограничение внешнего ключа).
Встраивание документов
Второй подход заключается в том, чтобы встроить документ user_information документ user_information следующим образом (рис. 5):
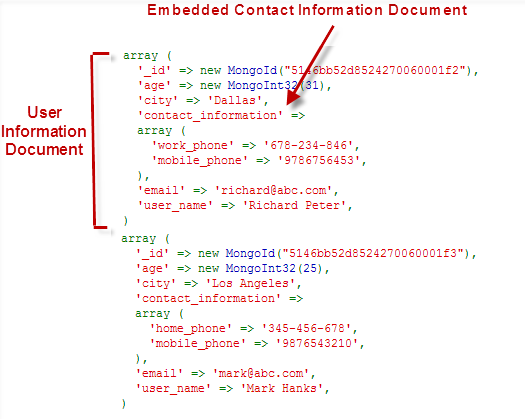
В приведенном выше примере мы встроили небольшой документ с контактной информацией в информацию о пользователе. Подобным образом, большие сложные документы и иерархические данные могут быть встроены таким образом, чтобы связать сущности.
Кроме того, какой подход использовать среди связывания и встроенного подхода зависит от конкретного сценария. Если ожидается, что объем встраиваемых данных будет увеличиваться в размере, лучше использовать подход связывания, а не встроенный, чтобы избежать слишком большого размера документа. Встроенный подход обычно используется в тех случаях, когда необходимо внедрить ограниченный объем информации (например, адрес в нашем примере).
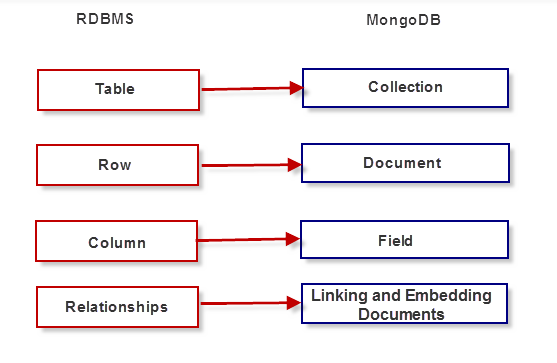
Картографическая Диаграмма
Подводя итог, можно сказать, что следующая диаграмма (Рис. 6) представляет общие взаимосвязи, которые мы обсудили:
Сопоставление SQL с запросами MongoDB
Теперь, когда мы освоились с основными отображениями между RDBMS и MongoDB, мы обсудим, как между ними различается язык запросов, используемый для взаимодействия с базой данных.
Для запросов MongoDB, давайте предположим, что коллекция users со структурой документа выглядит следующим образом:
|
1
2
3
4
5
6
7
|
{
«_id»: ObjectId(«5146bb52d8524270060001f3»),
«post_text»:»This is a sample post» ,
«user_name»: «mark»,
«post_privacy»: «public»,
«post_likes_count»: 0
}
|
Для запросов SQL мы предполагаем, что users таблицы имеют пять столбцов со следующей структурой:

Мы обсудим вопросы, связанные с созданием и изменением коллекций (или таблиц), вставкой, чтением, обновлением и удалением документов (или строк). Есть два запроса для каждой точки, один для SQL и другой для MongoDB. Я буду объяснять запросы MongoDB только потому, что мы хорошо знакомы с запросами SQL. Представленные здесь запросы MongoDB записываются в оболочке Mongo JavaScript, а запросы SQL — в MySQL.
Создайте
В MongoDB нет необходимости явно создавать структуру коллекции (как мы делаем для таблиц, использующих запрос CREATE TABLE ). Структура документа создается автоматически при первой вставке в коллекцию. Однако вы можете создать пустую коллекцию с createCollection команды createCollection .
|
1
2
3
|
SQL: CREATE TABLE `posts` (`id` int(11) NOT NULL AUTO_INCREMENT,`post_text` varchar(500) NOT NULL,`user_name` varchar(20) NOT NULL,`post_privacy` varchar(10) NOT NULL,`post_likes_count` int(11) NOT NULL,PRIMARY KEY (`id`))
MongoDB: db.createCollection(«posts»)
|
Вставить
Чтобы вставить документ в MongoDB, мы используем метод insert который принимает объект с парами ключ-значение в качестве входных данных. Вставленный документ будет содержать автоматически _id поле _id . Однако вы также можете явно указать 12-байтовое значение как _id вместе с другими полями.
|
1
2
3
|
SQL: INSERT INTO `posts` (`id` ,`post_text` ,`user_name` ,`post_privacy` ,`post_likes_count`)VALUES (NULL , ‘This is a sample post’, ‘mark’, ‘public’, ‘0’);
MongoDB: db.posts.insert({user_name:»mark», post_text:»This is a sample post», post_privacy:»public», post_likes_count:0})
|
В MongoDB нет функции Alter Table для изменения структуры документа. Поскольку документы являются динамическими в схеме, схема изменяется по мере того, как происходит любое обновление документа.
Читать
MongoDB использует метод find который эквивалентен команде SELECT в SQL. Следующие заявления просто прочитайте все документы из коллекции posts .
|
1
2
3
|
SQL: SELECT * FROM `posts`
MongoDB: db.posts.find()
|
Следующий запрос выполняет условный поиск документов, имеющих поле user_name качестве mark . Все критерии получения документов должны быть заключены в первые фигурные скобки {}, разделенные запятыми.
|
1
2
3
|
SQL: SELECT * FROM `posts` WHERE `user_name` = ‘mark’
MongoDB: db.posts.find({user_name:»mark»})
|
Следующий запрос извлекает определенные столбцы post_text и post_likes_count как указано во втором наборе фигурных скобок {}.
|
1
2
3
|
SQL: SELECT `post_text` , `post_likes_count` FROM `posts`
MongoDB: db.posts.find({},{post_text:1,post_likes_count:1})
|
Обратите внимание, что MongoDB по умолчанию возвращает поле _id с каждым оператором find. Если нам не нужно это поле в нашем наборе результатов, мы должны указать ключ _id со значением 0 в списке извлекаемых столбцов. Значение 0 ключа указывает, что мы хотим исключить это поле из набора результатов.
|
1
|
MongoDB: db.posts.find({},{post_text:1,post_likes_count:1,_id:0})
|
Следующий запрос извлекает определенные поля на основе критерия, которым является user_name .
|
1
2
3
|
SQL: SELECT `post_text` , `post_likes_count` FROM `posts` WHERE `user_name` = ‘mark’
MongoDB: db.posts.find({user_name:»mark»},{post_text:1,post_likes_count:1})
|
Теперь мы добавим еще один критерий для получения сообщений с типом конфиденциальности как общедоступных. Поля критериев, указанные с помощью запятых, представляют логическое условие AND . Таким образом, этот оператор будет искать документы, имеющие как user_name как mark и post_privacy как public .
|
1
2
3
|
SQL: SELECT `post_text` , `post_likes_count` FROM `posts` WHERE `user_name` = ‘mark’ AND `post_privacy` = ‘public’
MongoDB: db.posts.find({user_name:»mark»,post_privacy:»public»},{post_text:1,post_likes_count:1})
|
Чтобы использовать логическое OR между критериями в методе find , мы используем оператор $or .
|
1
2
3
|
SQL: SELECT `post_text` , `post_likes_count` FROM `posts` WHERE `user_name` = ‘mark’ OR `post_privacy` = ‘public’
MongoDB: db.posts.find({$or:[{user_name:»mark»},{post_privacy:»public»}]},{post_text:1,post_likes_count:1})
|
Далее мы будем использовать метод sort который сортирует результат в порядке возрастания post_likes_count (указан 1 ).
|
1
2
3
|
SQL: SELECT * FROM `posts` WHERE `user_name` = ‘mark’ order by post_likes_count ASC
MongoDB: db.posts.find({user_name:»mark»}).sort({post_likes_count:1})
|
Чтобы отсортировать результаты в порядке убывания, мы указываем -1 в качестве значения поля.
|
1
2
3
|
SQL: SELECT * FROM `posts` WHERE `user_name` = ‘mark’ order by post_likes_count DESC
MongoDB: db.posts.find({user_name:»mark»}).sort({post_likes_count:-1})
|
Чтобы ограничить количество документов, подлежащих возврату, мы используем метод limit указывающий количество документов.
|
1
2
3
|
SQL: SELECT * FROM `posts` LIMIT 10
MongoDB: db.posts.find().limit(10)
|
То, как мы используем offset в SQL, чтобы пропустить некоторое количество записей, мы используем функцию skip в MongoDB. Например, следующий оператор извлечет десять сообщений, пропуская первые пять.
|
1
2
3
|
SQL: SELECT * FROM `posts` LIMIT 10 OFFSET 5
MongoDB: db.posts.find().limit(10).skip(5)
|
Обновить
Первый параметр метода update определяет критерии выбора документов. Второй параметр указывает фактическую операцию обновления, которая должна быть выполнена. Например, следующий запрос выбирает все документы с user_name качестве mark и устанавливает их post_privacy как private .
Одно из отличий заключается в том, что по умолчанию запрос на обновление MongoDB обновляет только один (и первый соответствующий) документ. Чтобы обновить все соответствующие документы, мы должны предоставить третий параметр, указывающий multi как true указывающий, что мы хотим обновить несколько документов.
|
1
2
3
|
SQL: UPDATE posts SET post_privacy = «private» WHERE user_name=’mark’
MongoDB: db.posts.update({user_name:»mark»},{$set:{post_privacy:»private»}},{multi:true})
|
удалять
Удаление документов довольно просто и похоже на SQL.
|
1
2
3
|
SQL: DELETE FROM posts WHERE user_name=’mark’
MongoDB: db.posts.remove({user_name:»mark»})
|
индексирование
MongoDB имеет индекс по умолчанию, созданный в поле _id каждой коллекции. Для создания новых индексов на полях мы используем метод ensureIndex задающий поля и связанный порядок сортировки, обозначенный 1 или -1 (по возрастанию или по убыванию).
|
1
2
3
|
SQL: CREATE INDEX index_posts ON posts(user_name,post_likes_count DESC)
MongoDB: db.posts.ensureIndex({user_name:1,post_likes_count:-1})
|
Чтобы увидеть все индексы, присутствующие в любой коллекции, мы используем метод getIndexes в тех же строках запроса SHOW INDEX для SQL.
|
1
2
3
|
SQL: SHOW INDEX FROM posts
MongoDB: db.posts.getIndexes()
|
Вывод
В этой статье мы поняли, как элементарные понятия и термины RDBMS / SQL связаны с MongoDB. Мы рассмотрели проектирование отношений в MongoDB и узнали, как функционирует отображение базовых запросов SQL в MongoDB.
Начав с этой статьи, вы можете попробовать сложные запросы, включая агрегацию, редукцию карты и запросы с несколькими коллекциями. Вы также можете воспользоваться помощью некоторых онлайн-инструментов для преобразования запросов SQL в запросы MongoDB. Вы можете самостоятельно разработать образец схемы базы данных MongoDB. Один из лучших примеров для этого — база данных для хранения сообщений пользователей, их лайков, комментариев и лайков комментариев. Это даст вам практическое представление о гибкой схеме, которую предлагает MongoDB.
Не стесняйтесь комментировать любые предложения, вопросы или идеи, которые вы хотели бы видеть дальше.