cURL — это инструмент для передачи файлов и данных с синтаксисом URL, поддерживающий многие протоколы, включая HTTP, FTP, TELNET и другие. Изначально cURL был разработан как инструмент командной строки. К счастью для нас, библиотека cURL также поддерживается PHP . В этой статье мы рассмотрим некоторые из расширенных возможностей cURL и то, как мы можем использовать их в наших сценариях PHP.
Почему CURL?
Это правда, что есть и другие способы получения содержимого веб-страницы. Много раз, в основном из-за лени, я просто использовал простые функции PHP вместо cURL:
|
1
2
3
4
5
6
7
8
9
|
$content = file_get_contents(«http://www.nettuts.com»);
// or
$lines = file(«http://www.nettuts.com»);
// or
readfile(«http://www.nettuts.com»);
|
Однако они практически не обладают гибкостью и не имеют достаточной обработки ошибок. Кроме того, есть определенные задачи, которые вы просто не можете выполнить, например, работа с файлами cookie, проверка подлинности, отправка сообщений, загрузка файлов и т. Д.
cURL — это мощная библиотека, которая поддерживает множество различных протоколов, опций и предоставляет подробную информацию о запросах URL.
Базовая структура
Прежде чем перейти к более сложным примерам, давайте рассмотрим базовую структуру запроса cURL в PHP. Есть четыре основных шага:
- Initialize
- Установить параметры
- Выполнить и получить результат
- Освободите ручку cURL
|
01
02
03
04
05
06
07
08
09
10
11
12
13
|
// 1. initialize
$ch = curl_init();
// 2. set the options, including the url
curl_setopt($ch, CURLOPT_URL, «http://www.nettuts.com»);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_HEADER, 0);
// 3. execute and fetch the resulting HTML output
$output = curl_exec($ch);
// 4. free up the curl handle
curl_close($ch);
|
Шаг № 2 (т.е. вызовы curl_setopt ()) станет большой частью этой статьи, потому что именно здесь происходит вся магия. Существует длинный список опций cURL , которые можно настроить, чтобы детально настроить URL-запрос. Может быть трудно пройти весь список и переварить все сразу. Поэтому сегодня мы просто собираемся использовать некоторые из наиболее распространенных и полезных опций в различных примерах кода.
Проверка на ошибки
При желании вы также можете добавить проверку ошибок:
|
01
02
03
04
05
06
07
08
09
10
11
|
// …
$output = curl_exec($ch);
if ($output === FALSE) {
echo «cURL Error: » .
}
// …
|
Обратите внимание, что для сравнения нам нужно использовать «=== ЛОЖЬ» вместо «== ЛОЖЬ». Потому что мы должны различать пустой вывод и логическое значение FALSE, которое указывает на ошибку.
Получение информации
Другим необязательным шагом является получение информации о запросе cURL после его выполнения.
|
1
2
3
4
5
6
7
8
9
|
// …
curl_exec($ch);
$info = curl_getinfo($ch);
echo ‘Took ‘ .
// …
|
Следующая информация включена в возвращаемый массив:
- «URL»
- «Тип содержимого»
- «HTTP_CODE»
- «Header_size»
- «Request_size»
- «FILETIME»
- «Ssl_verify_result»
- «Redirect_count»
- «общее время»
- «Namelookup_time»
- «Connect_time»
- «Pretransfer_time»
- «Size_upload»
- «Size_download»
- «Speed_download»
- «Speed_upload»
- «Download_content_length»
- «Upload_content_length»
- «Starttransfer_time»
- «Redirect_time»
Обнаружение перенаправления на основе браузера
В этом первом примере мы напишем скрипт, который может обнаруживать перенаправления URL-адресов на основе различных настроек браузера. Например, некоторые сайты перенаправляют браузеры мобильных телефонов или даже серферов из разных стран.
Мы собираемся использовать опцию CURLOPT_HTTPHEADER для установки наших исходящих заголовков HTTP, включая строку агента пользователя и принятые языки. Наконец, мы проверим, пытаются ли эти сайты перенаправить нас на разные URL-адреса.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
|
// test URLs
$urls = array(
«http://www.cnn.com»,
«http://www.mozilla.com»,
«http://www.facebook.com»
);
// test browsers
$browsers = array(
«standard» => array (
«user_agent» => «Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6 (.NET CLR 3.5.30729)»,
«language» => «en-us,en;q=0.5»
),
«iphone» => array (
«user_agent» => «Mozilla/5.0 (iPhone; U; CPU like Mac OS X; en) AppleWebKit/420+ (KHTML, like Gecko) Version/3.0 Mobile/1A537a Safari/419.3»,
«language» => «en»
),
«french» => array (
«user_agent» => «Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; GTB6; .NET CLR 2.0.50727)»,
«language» => «fr,fr-FR;q=0.5»
)
);
foreach ($urls as $url) {
echo «URL: $url\n»;
foreach ($browsers as $test_name => $browser) {
$ch = curl_init();
// set url
curl_setopt($ch, CURLOPT_URL, $url);
// set browser specific headers
curl_setopt($ch, CURLOPT_HTTPHEADER, array(
«User-Agent: {$browser[‘user_agent’]}»,
«Accept-Language: {$browser[‘language’]}»
));
// we don’t want the page contents
curl_setopt($ch, CURLOPT_NOBODY, 1);
// we need the HTTP Header returned
curl_setopt($ch, CURLOPT_HEADER, 1);
// return the results instead of outputting it
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$output = curl_exec($ch);
curl_close($ch);
// was there a redirection HTTP header?
if (preg_match(«!Location: (.*)!», $output, $matches)) {
echo «$test_name: redirects to $matches[1]\n»;
} else {
echo «$test_name: no redirection\n»;
}
}
echo «\n\n»;
}
|
Сначала у нас есть набор URL-адресов для проверки, а затем набор настроек браузера для проверки каждого из этих URL-адресов. Затем мы перебираем эти контрольные примеры и делаем запрос cURL для каждого из них.
Из-за способа настройки параметров cURL возвращаемый вывод будет содержать только заголовки HTTP (сохраненные в $ output). С помощью простого регулярного выражения мы можем видеть, был ли включен заголовок «Location:».
Когда вы запустите этот скрипт, вы должны получить такой вывод:

Размещение на URL
По запросу GET данные могут быть отправлены на URL через «строку запроса». Например, когда вы выполняете поиск в Google, поисковый термин находится в части строки запроса URL:
|
1
|
http://www.google.com/search?q=nettuts
|
Возможно, вам не понадобится cURL для имитации этого в веб-скрипте. Вы можете просто лениться и нажать на этот URL с помощью file_get_contents (), чтобы получить результаты.
Но некоторые HTML-формы установлены для метода POST. Когда эти формы отправляются через браузер, данные отправляются через тело HTTP-запроса, а не строку запроса. Например, если вы выполняете поиск на форумах CodeIgniter , вы будете отправлять свой поисковый запрос в:
|
1
|
http://codeigniter.com/forums/do_search/
|
Мы можем написать скрипт PHP для имитации такого типа запроса URL. Сначала давайте создадим простой файл для принятия и отображения данных POST. Давайте назовем это post_output.php:
|
1
|
print_r($_POST);
|
Далее мы создаем скрипт PHP для выполнения запроса cURL:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
$url = «http://localhost/post_output.php»;
$post_data = array (
«foo» => «bar»,
«query» => «Nettuts»,
«action» => «Submit»
);
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
// we are doing a POST request
curl_setopt($ch, CURLOPT_POST, 1);
// adding the post variables to the request
curl_setopt($ch, CURLOPT_POSTFIELDS, $post_data);
$output = curl_exec($ch);
curl_close($ch);
echo $output;
|
Когда вы запустите этот скрипт, вы должны получить такой вывод:

Он отправил POST скрипту post_output.php, который сбросил переменную $ _POST, и мы записали этот вывод через cURL.
Файл загружен
Загрузка файлов работает очень похоже на предыдущий пример POST, поскольку все формы загрузки файлов имеют метод POST.
Сначала давайте создадим файл для получения запроса и назовем его upload_output.php:
|
1
|
print_r($_FILES);
|
А вот фактический скрипт, выполняющий загрузку файла:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
$url = «http://localhost/upload_output.php»;
$post_data = array (
«foo» => «bar»,
// file to be uploaded
«upload» => «@C:/wamp/www/test.zip»
);
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $post_data);
$output = curl_exec($ch);
curl_close($ch);
echo $output;
|
Если вы хотите загрузить файл, все, что вам нужно сделать, это передать его путь к файлу, как переменную post, и поставить символ @ перед ним. Теперь, когда вы запустите этот скрипт, вы должны получить такой вывод:
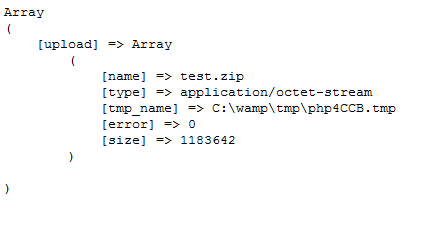
Multi CURL
Одной из более продвинутых функций cURL является возможность создания «мульти» дескриптора cURL. Это позволяет открывать подключения к нескольким URL-адресам одновременно и асинхронно.
При обычном запросе cURL выполнение сценария останавливается и ожидает завершения URL-запроса, прежде чем он может продолжиться. Если вы намереваетесь использовать несколько URL-адресов, это может занять много времени, поскольку вы можете запросить только один URL-адрес за один раз. Мы можем преодолеть это ограничение с помощью мульти ручки.
Давайте посмотрим на этот пример кода с php.net :
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
// create both cURL resources
$ch1 = curl_init();
$ch2 = curl_init();
// set URL and other appropriate options
curl_setopt($ch1, CURLOPT_URL, «http://lxr.php.net/»);
curl_setopt($ch1, CURLOPT_HEADER, 0);
curl_setopt($ch2, CURLOPT_URL, «http://www.php.net/»);
curl_setopt($ch2, CURLOPT_HEADER, 0);
//create the multiple cURL handle
$mh = curl_multi_init();
//add the two handles
curl_multi_add_handle($mh,$ch1);
curl_multi_add_handle($mh,$ch2);
$active = null;
//execute the handles
do {
$mrc = curl_multi_exec($mh, $active);
} while ($mrc == CURLM_CALL_MULTI_PERFORM);
while ($active && $mrc == CURLM_OK) {
if (curl_multi_select($mh) != -1) {
do {
$mrc = curl_multi_exec($mh, $active);
} while ($mrc == CURLM_CALL_MULTI_PERFORM);
}
}
//close the handles
curl_multi_remove_handle($mh, $ch1);
curl_multi_remove_handle($mh, $ch2);
curl_multi_close($mh);
|
Идея состоит в том, что вы можете открыть несколько дескрипторов cURL и назначить их для одного дескриптора multi. Затем вы можете подождать, пока они завершат выполнение в цикле.
В этом примере есть два основных цикла. Первый цикл do-while многократно вызывает curl_multi_exec (). Эта функция неблокирующая. Он выполняется как можно меньше и возвращает значение состояния. Поскольку возвращаемое значение является константой «CURLM_CALL_MULTI_PERFORM», это означает, что есть еще более непосредственная работа (например, отправка http-заголовков на URL-адреса.) Поэтому мы продолжаем вызывать его, пока возвращаемое значение не станет чем-то другим.
В следующем цикле while мы продолжаем, пока переменная $ active равна ‘true’. Это было передано в качестве второго аргумента в вызов curl_multi_exec (). Он установлен в значение «истина», если есть активные соединения с мульти-дескриптором. Следующее, что мы делаем, это вызываем curl_multi_select (). Эта функция «блокирует» до тех пор, пока не возникнет какая-либо активность соединения, например, получение ответа. Когда это происходит, мы переходим в еще один цикл do-while, чтобы продолжить выполнение.
Давайте посмотрим, сможем ли мы сами создать рабочий пример, у которого есть практическая цель.
WordPress Link Checker
Представьте себе блог с множеством постов, содержащих ссылки на внешние сайты. Некоторые из этих ссылок могут закончиться через некоторое время по разным причинам. Возможно, страница там длиннее или весь сайт пропал.
Мы собираемся создать скрипт, который анализирует все ссылки и находит не загружаемые веб-сайты и 404 страницы и возвращает нам отчет.
Обратите внимание, что это не будет настоящий плагин WordPress. Это всего лишь автономный служебный скрипт, и он только для демонстрационных целей.
Итак, начнем. Сначала нам нужно получить ссылки из базы данных:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
|
// CONFIG
$db_host = ‘localhost’;
$db_user = ‘root’;
$db_pass = »;
$db_name = ‘wordpress’;
$excluded_domains = array(
‘localhost’, ‘www.mydomain.com’);
$max_connections = 10;
// initialize some variables
$url_list = array();
$working_urls = array();
$dead_urls = array();
$not_found_urls = array();
$active = null;
// connect to MySQL
if (!mysql_connect($db_host, $db_user, $db_pass)) {
die(‘Could not connect: ‘ . mysql_error());
}
if (!mysql_select_db($db_name)) {
die(‘Could not select db: ‘ . mysql_error());
}
// get all published posts that have links
$q = «SELECT post_content FROM wp_posts
WHERE post_content LIKE ‘%href=%’
AND post_status = ‘publish’
AND post_type = ‘post'»;
$r = mysql_query($q) or die(mysql_error());
while ($d = mysql_fetch_assoc($r)) {
// get all links via regex
if (preg_match_all(«!href=\»(.*?)\»!», $d[‘post_content’], $matches)) {
foreach ($matches[1] as $url) {
// exclude some domains
$tmp = parse_url($url);
if (in_array($tmp[‘host’], $excluded_domains)) {
continue;
}
// store the url
$url_list []= $url;
}
}
}
// remove duplicates
$url_list = array_values(array_unique($url_list));
if (!$url_list) {
die(‘No URL to check’);
}
|
Сначала у нас есть некоторая конфигурация базы данных, за которой следует массив доменных имен, которые мы будем игнорировать ($ exclusive_domains). Также мы устанавливаем число для максимальных одновременных соединений, которые мы будем использовать позже ($ max_connections). Затем мы подключаемся к базе данных, выбираем посты, содержащие ссылки, и собираем их в массив ($ url_list).
Следующий код может быть немного сложным, поэтому я постараюсь объяснить его небольшими шагами.
|
001
002
003
004
005
006
007
008
009
010
011
012
013
014
015
016
017
018
019
020
021
022
023
024
025
026
027
028
029
030
031
032
033
034
035
036
037
038
039
040
041
042
043
044
045
046
047
048
049
050
051
052
053
054
055
056
057
058
059
060
061
062
063
064
065
066
067
068
069
070
071
072
073
074
075
076
077
078
079
080
081
082
083
084
085
086
087
088
089
090
091
092
093
094
095
096
097
098
099
100
101
102
103
104
|
// 1. multi handle
$mh = curl_multi_init();
// 2. add multiple URLs to the multi handle
for ($i = 0; $i < $max_connections; $i++) {
add_url_to_multi_handle($mh, $url_list);
}
// 3. initial execution
do {
$mrc = curl_multi_exec($mh, $active);
} while ($mrc == CURLM_CALL_MULTI_PERFORM);
// 4. main loop
while ($active && $mrc == CURLM_OK) {
// 5. there is activity
if (curl_multi_select($mh) != -1) {
// 6. do work
do {
$mrc = curl_multi_exec($mh, $active);
} while ($mrc == CURLM_CALL_MULTI_PERFORM);
// 7. is there info?
if ($mhinfo = curl_multi_info_read($mh)) {
// this means one of the requests were finished
// 8. get the info on the curl handle
$chinfo = curl_getinfo($mhinfo[‘handle’]);
// 9. dead link?
if (!$chinfo[‘http_code’]) {
$dead_urls []= $chinfo[‘url’];
// 10. 404?
} else if ($chinfo[‘http_code’] == 404) {
$not_found_urls []= $chinfo[‘url’];
// 11. working
} else {
$working_urls []= $chinfo[‘url’];
}
// 12. remove the handle
curl_multi_remove_handle($mh, $mhinfo[‘handle’]);
curl_close($mhinfo[‘handle’]);
// 13. add a new url and do work
if (add_url_to_multi_handle($mh, $url_list)) {
do {
$mrc = curl_multi_exec($mh, $active);
} while ($mrc == CURLM_CALL_MULTI_PERFORM);
}
}
}
}
// 14. finished
curl_multi_close($mh);
echo «==Dead URLs==\n»;
echo implode(«\n»,$dead_urls) .
echo «==404 URLs==\n»;
echo implode(«\n»,$not_found_urls) .
echo «==Working URLs==\n»;
echo implode(«\n»,$working_urls);
// 15. adds a url to the multi handle
function add_url_to_multi_handle($mh, $url_list) {
static $index = 0;
// if we have another url to get
if ($url_list[$index]) {
// new curl handle
$ch = curl_init();
// set the url
curl_setopt($ch, CURLOPT_URL, $url_list[$index]);
// to prevent the response from being outputted
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
// follow redirections
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
// do not need the body.
curl_setopt($ch, CURLOPT_NOBODY, 1);
// add it to the multi handle
curl_multi_add_handle($mh, $ch);
// increment so next url is used next time
$index++;
return true;
} else {
// we are done adding new URLs
return false;
}
}
|
А вот объяснение коду выше. Номера в списке соответствуют номерам в комментариях к коду.
- Создана мульти ручка.
- Мы будем создавать функцию add_url_to_multi_handle () позже. Каждый раз, когда он вызывается, он добавляет URL-адрес в дескриптор multi. Первоначально мы добавляем 10 (на основе $ max_connections) URL-адресов к мульти дескриптору
- Мы должны запустить curl_multi_exec () для начальной работы. Пока он возвращает CURLM_CALL_MULTI_PERFORM, есть над чем работать. Это в основном для создания связей. Он не ждет полного ответа URL.
- Этот основной цикл выполняется до тех пор, пока в дескрипторе multi есть активность.
- curl_multi_select () ждет сценария, пока не произойдет какое-либо действие с любым из URL-квестов.
- Опять же, мы должны позволить cURL выполнить некоторую работу, в основном, для получения данных ответов.
- Мы проверяем информацию. Возвращается массив, если запрос URL завершен.
- В возвращаемом массиве есть дескриптор cURL. Мы используем это для получения информации по отдельному запросу cURL.
- Если ссылка устарела или истек срок ее действия, код http не будет.
- Если ссылка была на страницу 404, http-код будет установлен на 404.
- В противном случае мы предполагаем, что это была рабочая ссылка. (Вы можете добавить дополнительные проверки для 500 кодов ошибок и т. Д.)
- Мы удаляем маркер cURL из мульти дескриптора, поскольку он больше не нужен, и закрываем его.
- Теперь мы можем добавить еще один URL к дескриптору multi и снова выполнить начальную работу, прежде чем двигаться дальше.
- Все закончено. Мы можем закрыть мульти-дескриптор и распечатать отчет.
- Это функция, которая добавляет новый URL к мульти дескриптору. Статическая переменная $ index увеличивается каждый раз, когда вызывается эта функция, поэтому мы можем отслеживать, где мы остановились.
Я запустил скрипт в своем блоге (с некоторыми неработающими ссылками, добавленными специально для тестирования), и вот как он выглядел:
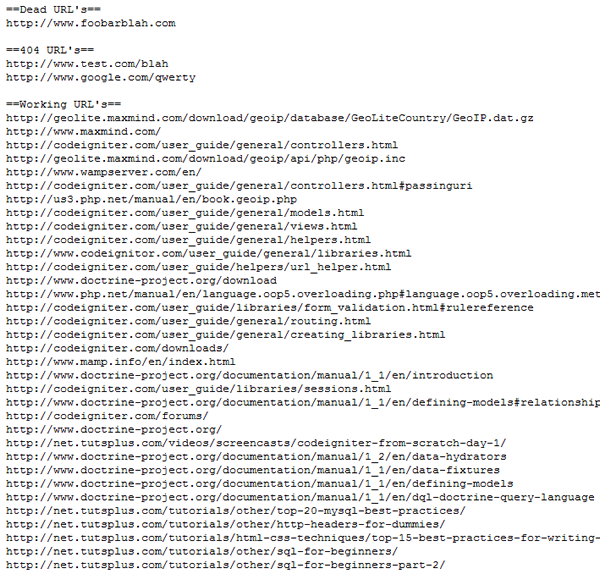
Потребовалось всего менее 2 секунд, чтобы просмотреть около 40 URL-адресов. Повышение производительности является значительным при работе с еще большими наборами URL. Если вы одновременно откроете десять подключений, он может работать в десять раз быстрее. Также вы можете просто использовать неблокирующую природу манипулятора multi curl для выполнения URL-запросов без остановки вашего веб-скрипта.
Некоторые другие полезные опции cURL
HTTP-аутентификация
Если для URL-адреса есть HTTP-аутентификация, вы можете использовать это:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
|
$url = «http://www.somesite.com/members/»;
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
// send the username and password
curl_setopt($ch, CURLOPT_USERPWD, «myusername:mypassword»);
// if you allow redirections
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
// this lets cURL keep sending the username and password
// after being redirected
curl_setopt($ch, CURLOPT_UNRESTRICTED_AUTH, 1);
$output = curl_exec($ch);
curl_close($ch);
|
Загрузка по FTP
PHP имеет библиотеку FTP , но вы также можете использовать cURL:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
|
// open a file pointer
$file = fopen(«/path/to/file», «r»);
// the url contains most of the info needed
$url = «ftp://username:password@mydomain.com:21/path/to/new/file»;
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
// upload related options
curl_setopt($ch, CURLOPT_UPLOAD, 1);
curl_setopt($ch, CURLOPT_INFILE, $fp);
curl_setopt($ch, CURLOPT_INFILESIZE, filesize(«/path/to/file»));
// set for ASCII mode (eg text files)
curl_setopt($ch, CURLOPT_FTPASCII, 1);
$output = curl_exec($ch);
curl_close($ch);
|
Использование прокси
Вы можете выполнить свой URL-запрос через прокси:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL,’http://www.example.com’);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
// set the proxy address to use
curl_setopt($ch, CURLOPT_PROXY, ‘11.11.11.11:8080’);
// if the proxy requires a username and password
curl_setopt($ch, CURLOPT_PROXYUSERPWD,’user:pass’);
$output = curl_exec($ch);
curl_close ($ch);
|
Функции обратного вызова
Можно сделать вызов cURL заданными функциями обратного вызова во время запроса URL-адреса до его завершения. Например, по мере загрузки содержимого ответа вы можете начать использовать данные, не дожидаясь завершения всей загрузки.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
|
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL,’http://net.tutsplus.com’);
curl_setopt($ch, CURLOPT_WRITEFUNCTION,»progress_function»);
curl_exec($ch);
curl_close ($ch);
function progress_function($ch,$str) {
echo $str;
return strlen($str);
}
|
Функция обратного вызова ДОЛЖНА возвращать длину строки, которая необходима для правильной работы.
При получении ответа URL каждый раз при получении пакета данных вызывается функция обратного вызова.
Вывод
Сегодня мы изучили возможности и гибкость библиотеки cURL. Я надеюсь, что вы получили удовольствие и узнали из этой статьи. В следующий раз, когда вам нужно будет сделать запрос URL в вашем веб-приложении, рассмотрите возможность использования cURL.
Спасибо Вам и хорошего дня!
Написать Плюс Учебник
Знаете ли вы, что вы можете заработать до 600 долларов за написание учебника PLUS и / или скринкаст для нас? Мы ищем подробные и хорошо написанные учебники по HTML, CSS, PHP и JavaScript. Если у вас есть такая возможность, пожалуйста, свяжитесь с Джеффри по адресу nettuts@tutsplus.com.
Обратите внимание, что фактическая компенсация будет зависеть от качества окончательного урока и скринкаста.

- Подпишитесь на нас в Твиттере или подпишитесь на ленту Nettuts + RSS для получения лучших учебных материалов по веб-разработке.