В моей предыдущей статье мы рассмотрели некоторые основы HTTP, такие как схема URL, коды состояния и заголовки запроса / ответа. Основываясь на этом, мы рассмотрим более тонкие аспекты HTTP, такие как обработка соединений, аутентификация и HTTP-кэширование. Эти темы довольно обширны, но мы рассмотрим самые важные моменты.
HTTP соединения
Между клиентом и сервером должно быть установлено соединение, прежде чем они смогут взаимодействовать друг с другом, и HTTP использует надежный транспортный протокол TCP для создания этого соединения. По умолчанию веб-трафик использует TCP-порт 80. Поток TCP разбивается на IP-пакеты, и это гарантирует, что эти пакеты всегда поступают в правильном порядке в обязательном порядке. HTTP — это протокол прикладного уровня по TCP, который по IP.
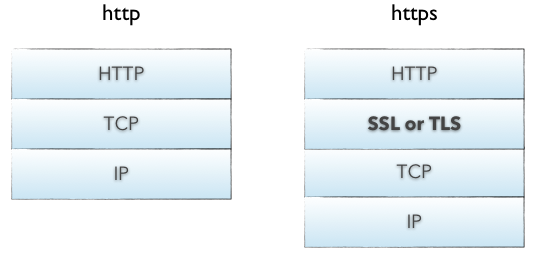
HTTPS — это защищенная версия HTTP, вставляющая дополнительный уровень между HTTP и TCP, который называется TLS или SSL (соответственно, уровень транспортного уровня или уровень защищенных сокетов). HTTPS связывается через порт 443 по умолчанию, и мы рассмотрим HTTPS позже в этой статье.
HTTP-соединение идентифицируется <source-IP, source-port> и <destination-IP, destination-port> . На клиенте приложение HTTP идентифицируется кортежем <IP, port> . Установление соединения между двумя конечными точками является многоэтапным процессом и включает в себя следующее:
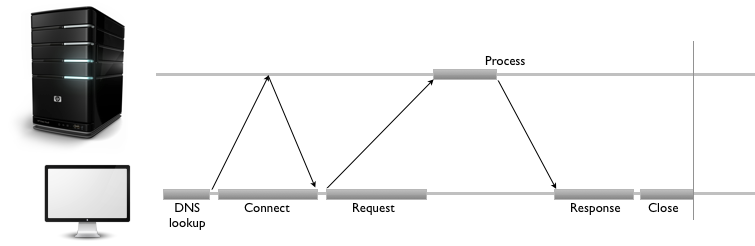
- разрешить IP-адрес от имени хоста через DNS
- установить соединение с сервером
- Отправить запрос
- ждать ответа
- тесная связь
Сервер отвечает за то, что всегда отвечает правильными заголовками и ответами.
В HTTP / 1.0 все соединения были закрыты после одной транзакции. Таким образом, если клиент хотел запросить три отдельных изображения с одного и того же сервера, он сделал три отдельных подключения к удаленному хосту. Как видно из приведенной выше диаграммы, это может привести к большим задержкам в сети, что приведет к неоптимальному восприятию пользователя.
Чтобы уменьшить задержки при установлении соединения, HTTP / 1.1 ввел постоянные соединения , долгоживущие соединения, которые остаются открытыми, пока клиент не закроет их. Постоянные соединения используются по умолчанию в HTTP / 1.1, а для установления соединения с одной транзакцией требуется, чтобы клиент установил заголовок запроса Connection: close . Это говорит серверу закрыть соединение после отправки ответа.
В дополнение к постоянным соединениям браузеры / клиенты также используют метод, называемый параллельными соединениями , чтобы минимизировать задержки в сети. Вековая концепция параллельных соединений включает создание пула соединений (обычно ограничена шестью соединениями). Если клиенту необходимо загрузить шесть ресурсов с веб-сайта, клиент выполняет шесть параллельных подключений для загрузки этих активов, что приводит к более быстрому циклу обработки. Это огромное улучшение по сравнению с последовательными соединениями, когда клиент загружает актив только после завершения загрузки предыдущего актива.
Параллельные соединения в сочетании с постоянными соединениями являются сегодняшним ответом на минимизацию сетевых задержек и налаживание работы клиента. Подробное описание HTTP-соединений приведено в разделе « Соединения» спецификации HTTP.
Обработка соединений на стороне сервера
Сервер в основном прослушивает входящие соединения и обрабатывает их при получении запроса. Операции включают в себя:
- установление сокета для начала прослушивания порта 80 (или другого порта)
- получение запроса и разбор сообщения
- обработка ответа
- установка заголовков ответа
- отправив ответ клиенту
- закрыть соединение, если найден заголовок запроса
Connection: close
Конечно, это не исчерпывающий список операций. Большинству приложений / веб-сайтов необходимо знать, кто делает запрос, чтобы создавать более персонализированные ответы. Это сфера идентификации и аутентификации .
Идентификация и Аутентификация
HTTP — это протокол прикладного уровня по TCP, который по IP.
Практически обязательно знать, кто подключается к серверу для отслеживания использования приложения или сайта и общих шаблонов взаимодействия пользователей. Предпосылка идентификации состоит в том, чтобы адаптировать ответ, чтобы обеспечить персонализированный опыт; естественно, сервер должен знать, кто является пользователем, чтобы обеспечить эту функциональность.
Существует несколько различных способов сбора этой информации сервером, и большинство веб-сайтов используют гибрид этих подходов:
- Заголовки запроса :
From,Referer,User-Agent— Мы видели эти заголовки в части 1 . - Client-IP — IP-адрес клиента
- Fat Urls — сохранение состояния текущего пользователя путем изменения URL и перенаправления на другой URL при каждом клике; каждый щелчок по существу накапливает состояние.
- Куки — самый популярный и ненавязчивый подход.
Файлы cookie позволяют серверу прикреплять произвольную информацию для исходящих ответов через заголовок ответа Set-Cookie . Файл cookie устанавливается с одной или несколькими парами имя = значение, разделенными точкой с запятой ( ; ), как в Set-Cookie: session-id=12345ABC; username=nettuts Set-Cookie: session-id=12345ABC; username=nettuts .
Сервер также может ограничить использование cookie-файлов определенным domain и path и может сделать их постоянными со значением expires . Файлы cookie автоматически отправляются браузером для каждого запроса на сервер, и браузер гарантирует, что в запросе будут отправляться только файлы cookie, domain к domain и path . Заголовок запроса Cookie: name=value [; name2=value2] Cookie: name=value [; name2=value2] используется для отправки этих куки на сервер.
Лучший способ идентифицировать пользователя — это потребовать от него регистрации и входа, но реализация этой функции требует определенных усилий как от разработчика, так и от пользователя.
Такие методы, как OAuth, упрощают этот тип функций, но для правильной работы все еще требуется согласие пользователя. Аутентификация играет здесь большую роль, и это, вероятно, единственный способ идентифицировать и проверить пользователя.
Аутентификация
HTTP поддерживает элементарную форму аутентификации, называемую базовой аутентификацией , а также более безопасную дайджест-аутентификацию .
При базовой аутентификации сервер первоначально отклоняет запрос клиента с заголовком ответа WWW-Authenticate и 401 Unauthorized кодом 401 Unauthorized статуса. Увидев этот заголовок, браузер отображает диалог входа в систему, запрашивая имя пользователя и пароль. Эта информация отправляется в формате base-64 в заголовке запроса Authentication . Теперь сервер может проверить запрос и разрешить доступ, если учетные данные верны. Некоторые серверы могут также отправлять заголовок Authentication-Info содержащий дополнительные данные аутентификации.
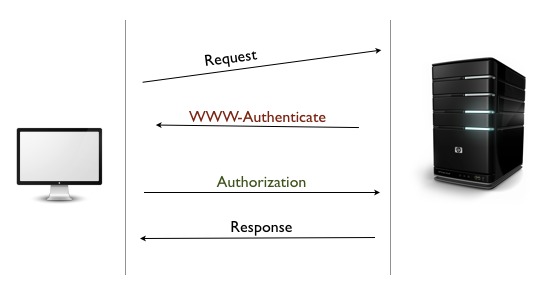
Следствием базовой аутентификации является прокси-аутентификация . Вместо веб-сервера запрос на аутентификацию запрашивается промежуточным прокси-сервером. Прокси-сервер отправляет заголовок Proxy-Authenticate с кодом 407 Unauthorized статуса 407 Unauthorized . В свою очередь, клиент должен отправить учетные данные через заголовок запроса Proxy-Authorization .
Дайджест-аутентификация аналогична базовой и использует ту же технику рукопожатия с заголовками WWW-Authenticate и Authorization , но дайджест использует более безопасную функцию хеширования для шифрования имени пользователя и пароля (обычно с функциями дайджеста MD5 или KD). Хотя дайджест-аутентификация должна быть более безопасной, чем базовая, веб-сайты обычно используют базовую аутентификацию из-за ее простоты. Чтобы уменьшить проблемы безопасности, Basic Auth используется вместе с SSL.
Безопасный HTTP

Протокол HTTPS обеспечивает безопасное соединение в Интернете. Самый простой способ узнать, используете ли вы HTTPS, — это проверить адресную строку браузера. Защищенный компонент HTTP включает в себя вставку слоя шифрования / дешифрования между HTTP и TCP. Это уровень защищенных сокетов (SSL) или улучшенная безопасность транспортного уровня (TLS).
SSL использует мощную форму шифрования с использованием RSA и криптографии с открытым ключом. Поскольку безопасные транзакции так важны в Интернете, в течение довольно долгого времени предпринимались вездесущие стандартизированные инфраструктуры инфраструктуры открытых ключей (PKI).
Существующим клиентам / серверам не нужно менять способ обработки сообщений, поскольку большая часть тяжелой работы происходит на уровне SSL. Таким образом, вы можете разработать свое веб-приложение с использованием базовой аутентификации и автоматически воспользоваться преимуществами SSL, переключившись на протокол https:// . Однако, чтобы веб-приложение работало по протоколу HTTPS, вам необходимо иметь работающий цифровой сертификат, развернутый на сервере.
Сертификаты
Точно так же, как вам нужны удостоверения личности, чтобы показать вашу личность, веб-серверу нужен цифровой сертификат для идентификации себя. Сертификаты (или «сертификаты») выдаются Центром сертификации (CA) и подтверждают вашу личность в Интернете. CA являются хранителями PKI. Наиболее распространенной формой сертификатов является стандарт X.509 v3 , который содержит такую информацию, как:
- эмитент сертификата
- алгоритм, используемый для сертификата
- название субъекта или организации, для которой создан этот сертификат
- информация открытого ключа для субъекта
- Подпись удостоверяющего центра, используя указанный алгоритм подписи
Когда клиент делает запрос через HTTPS, он сначала пытается найти сертификат на сервере. Если сертификат найден, он пытается сравнить его с известным списком CA. Если это не один из перечисленных CA, он может показать диалоговое окно с предупреждением пользователя о сертификате веб-сайта.
Как только сертификат подтвержден, SSL-квитирование завершено и защищенная передача действует.
HTTP-кеширование
Общепринято, что выполнение одной и той же работы дважды является расточительным. Это основополагающий принцип концепции HTTP-кэширования, фундаментальной основы сетевой инфраструктуры HTTP. Поскольку большинство операций выполняются по сети, кэш-память помогает сэкономить время, затраты и пропускную способность, а также обеспечивает улучшенную работу в Интернете.
Кэши используются в нескольких местах сетевой инфраструктуры, от браузера до исходного сервера. В зависимости от того, где он находится, кэш может быть классифицирован как:
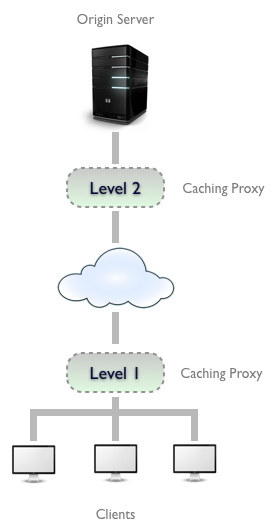
- Частный : в браузере, кэширует имена пользователей, пароли, URL-адреса, историю просмотров и веб-контент. Они, как правило, маленькие и специфичные для пользователя.
- Общедоступный : развернут как кеширующие прокси между сервером и клиентом. Они намного больше, потому что они обслуживают нескольких пользователей. Обычная практика — хранить несколько прокси-серверов для кэширования между клиентом и сервером источника. Это помогает обслуживать часто доступный контент, в то же время позволяя отправлять на сервер нечасто необходимый контент.
Обработка кэша
Независимо от того, где находится кеш, процесс обслуживания кеша очень похож:
- Получите сообщение запроса.
- Разобрать URL и заголовки.
- Поиск локальной копии; в противном случае, получить и хранить локально
- Выполните проверку свежести, чтобы определить возраст содержимого в кэше; сделать запрос на обновление контента только при необходимости.
- Создайте ответ из кэшированного тела и обновленных заголовков.
- Отправьте ответ обратно клиенту.
- При желании, зарегистрируйте транзакцию.
Конечно, сервер всегда отвечает за правильные заголовки и ответы. Если документ не изменился, сервер должен ответить 304 Not Modified . Если срок хранения в кэше истек, он должен сгенерировать новый ответ с обновленными заголовками ответа и вернуть с 200 OK . Если ресурс удален, он должен вернуться с 404 Not Found . Эти ответы помогают настроить кэш и гарантировать, что устаревший контент не будет храниться слишком долго.
Заголовки контроля кэша
Параллельные соединения в сочетании с постоянными соединениями — это сегодняшний ответ на минимизацию сетевых задержек.
Теперь, когда у нас есть представление о том, как работает кэш, пришло время взглянуть на заголовки запросов и ответов, которые включают инфраструктуру кэширования. Поддержание свежести и актуальности контента — одна из основных обязанностей кеша. Чтобы сохранить кэшированную копию в соответствии с сервером, HTTP предоставляет несколько простых механизмов, а именно: истечение срока действия документа и повторную проверку сервера .
Срок действия документа
HTTP позволяет серверу происхождения прикреплять дату истечения срока действия к каждому документу, используя заголовки ответа Cache-Control и Expires . Это помогает клиенту и другим серверам кэша знать, как долго документ является действительным и свежим. Кэш может обслуживать копию до тех пор, пока срок действия документа не истечет. По истечении срока действия документа кэш должен проверить на сервере более новую копию и соответствующим образом обновить свою локальную копию.
Expires — это более старый заголовок ответа HTTP / 1.0, в котором значение указывается как абсолютная дата. Это полезно, только если часы сервера синхронизированы с клиентом, что является ужасным предположением. Этот заголовок менее полезен по сравнению с более новым заголовком Cache-Control: max-age=<s> представленным в HTTP / 1.1. Здесь max-age — это относительный возраст, указанный в секундах с момента создания ответа. Таким образом, если срок действия документа истечет через один день, заголовок срока действия должен быть Cache-Control: max-age=86400 .
Повторная проверка сервера
Когда срок действия кэшированного документа истекает, кэш должен пройти повторную проверку на сервере, чтобы проверить, изменился ли документ. Это называется повторной проверкой сервера и служит механизмом запроса на устойчивость документа. Тот факт, что срок хранения кэшированной копии истек, не означает, что на самом деле на сервере имеется более новое содержимое. Повторная проверка — это просто средство обеспечения того, чтобы кэш оставался свежим. Из-за истечения срока действия (как указано в предыдущем ответе сервера), кэш-память не должна проверять сервер для каждого отдельного запроса, что позволяет сэкономить пропускную способность, время и уменьшить сетевой трафик.
Сочетание истечения срока действия документа и повторной проверки сервера является очень эффективным механизмом и позволяет распределенным системам сохранять копии с датой истечения срока действия.
Если известно, что контент часто изменяется, время истечения может быть уменьшено, что позволяет системам выполнять повторную синхронизацию чаще.
Этап повторной проверки может быть выполнен с помощью двух типов заголовков запроса: If-Modified-Since и If-None-Match . Первый предназначен для проверки на основе даты, а второй использует теги сущностей (ETags), хэш содержимого. В этих заголовках используются значения даты или ETag, полученные из предыдущего ответа сервера. В случае If-Modified-Since используется заголовок ответа Last-Modified ; для If-None-Match это ETag ответа ETag .
Управление Кэшируемостью
Срок действия документа должен быть определен сервером, генерирующим документ. Если это веб-сайт газеты, срок действия домашней страницы истекает через день (а иногда даже каждый час!). HTTP предоставляет заголовки ответов Cache-Control и Expires для установки срока действия документов. Как упоминалось ранее, Expires основан на абсолютных датах и не является надежным решением для управления кэшем.
Заголовок Cache-Control гораздо более полезен и имеет несколько различных значений, чтобы ограничить то, как клиенты должны кэшировать ответ:
- Cache-Control: no-cache : клиенту разрешено хранить документ; однако при каждом запросе он должен повторяться с сервером. Существует заголовок совместимости HTTP / 1.0 под названием Pragma: no-cache , который работает так же.
- Cache-Control: no-store : это более сильная директива для клиента вообще не хранить документ.
- Cache-Control: must-revalidate : это говорит клиенту обойти вычисления свежести и всегда выполнять повторную проверку на сервере. Не разрешается обслуживать кэшированный ответ, если сервер недоступен.
- Cache-Control: max-age : устанавливает относительное время истечения (в секундах) с момента генерации ответа.
Кроме того, если сервер не отправляет заголовки Cache-Control , клиент может использовать свой собственный эвристический алгоритм истечения срока действия для определения свежести.
Сдерживая свежесть от клиента
Кешируемость не ограничивается только сервером. Это также может быть указано от клиента. Это позволяет клиенту налагать ограничения на то, что он готов принять. Это возможно через тот же заголовок Cache-Control , хотя и с несколькими различными значениями:
- Cache-Control: min-fresh = <s> : документ должен быть обновлен не менее <s> секунд.
- Cache-Control: max-stale или Cache-Control: max-stale = <s> : документ не может быть доставлен из кэша, если он устарел дольше <s> секунд.
- Cache-Control: max-age = <s> : кэш не может вернуть документ, который был кэширован дольше, чем <s> секунд.
- Cache-Control: no-cache или Pragma: no-cache : клиент не примет кэшированный ресурс, если он не был повторно проверен.
HTTP-кэширование на самом деле очень интересная тема, и есть несколько очень сложных алгоритмов для управления кэшированным контентом. Для более глубокого изучения этой темы обратитесь к разделу «Кэширование» спецификации HTTP.
Резюме
Наш тур по HTTP начался с основания схем URL, кодов состояния и заголовков запросов / ответов. Основываясь на этих концепциях, мы рассмотрели некоторые тонкие области HTTP, такие как обработка соединений, идентификация, аутентификация и кэширование. Я надеюсь, что этот тур дал вам хороший вкус к широте HTTP и достаточное количество указателей для дальнейшего изучения этого протокола.