Когда мы создаем сервисную архитектуру (сервис-ориентированную архитектуру, микросервисы, следующее воплощение и т. Д.), Мы в конечном итоге совершаем гораздо больше вызовов по сети. Сеть опасна . Мы стараемся встраивать избыточность в наши услуги, чтобы мы могли испытывать сбои в нашей системе и все еще двигаться вперед и обрабатывать запросы клиентов. Важной частью этой головоломки создания избыточных, отказоустойчивых систем является разумная балансировка нагрузки с учетом приложений. Мэтт Кляйн недавно написал потрясающую статью о современной балансировке нагрузки, которую вы, вероятно, должны остановиться и начать читать прямо сейчас.
Схема автоматического выключателя была важным шаблоном для построения больших, устойчивых распределенных систем, особенно тех, которые предназначены для работы в «облаке» как «микросервисы». При реализации автоматического выключателя мы пытаемся «замкнуть» сетевые вызовы на системы, которые, по-видимому, испытывают повторяющиеся сбои. Разрыв цепи — это особенность интеллектуальной балансировки нагрузки с учетом приложений. Вы либо явно распределяете нагрузку, либо это происходит неявно. Давайте рассмотрим некоторые подходы к разрыву цепей с помощью Netflix Hystrix и их сравнение с подходом Envoy Proxy .
Обрыв цепи
Мы используем функцию прерывания цепи для защиты от частичных или полных каскадных сбоев. Мы хотим контролировать / уменьшать / исключать трафик на нездоровые системы, чтобы не продолжать их перегрузку и препятствовать их восстановлению. Например, если ваша служба поиска вызывает службу рекомендаций для персонализированных результатов поиска, а служба рекомендаций возвращает ошибки для многих различных вызовов, может быть, нам следует прекратить вызывать ее в течение определенного периода времени? Может быть, чем больше мы повторяем, и чем больше стресса мы прикладываем к этой системе, тем больше она ухудшается? В течение некоторого времени мы можем решить просто «быстро потерпеть неудачу» и не разрешать звонки в службу рекомендаций. Этот подход по духу похож на работу автоматического выключателя в вашей электрической системе в вашем доме. Если мы сталкиваемся с ошибками, мы должны открыть цепь, чтобы защитить остальную часть системы. Схема автоматического выключателя заставляет наше приложение учитывать тот факт, что наши сетевые вызовы могут и действительно давать сбой, и помогают защитить систему в целом от каскадных сбоев. Это связано с восприятием работоспособности компонентов системы и с тем, следует ли нам направлять трафик на них .
Netflix OSS Hystrix
Netflix OSS выпустила реализацию автоматического выключателя в 2012 году под названием Netflix OSS Hystrix . Hystrix — это клиентская библиотека Java для получения прерывистого поведения. Hystrix обеспечивает следующее поведение .
Из раздела «Повышение устойчивости API Netflix »:
- Настраиваемый запасной вариант — в некоторых случаях клиентская библиотека службы предоставляет метод отката, который мы можем вызвать, или в других случаях мы можем использовать локально доступные данные на сервере API (например, файл cookie или локальный кеш JVM), чтобы сгенерировать запасной ответ
- Fail silent — в этом случае резервный метод просто возвращает нулевое значение, что полезно, если данные, предоставляемые вызываемой службой, являются необязательными для ответа, который будет отправлен обратно запрашивающему клиенту.
- Быстро завершиться неудачей — используется в тех случаях, когда требуются данные или нет хорошего запасного варианта, и в результате клиент получает ответ 5xx. Это может отрицательно повлиять на UX устройства, что не идеально, но поддерживает работоспособность серверов API и позволяет системе быстро восстанавливаться, когда сбойная служба снова становится доступной.
Функциональность прерывания цепи может быть запущена несколькими различными способами .
Из раздела «Повышение устойчивости API Netflix »:
- Время ожидания запроса к удаленному сервису
- Пул потоков и ограниченная очередь задач, используемые для взаимодействия с сервисной зависимостью, заполнены на 100%
- Клиентская библиотека, используемая для взаимодействия с сервисной зависимостью, выдает исключение
Блок-схема разрыва цепи Hystrix можно увидеть здесь :
{kind=link}
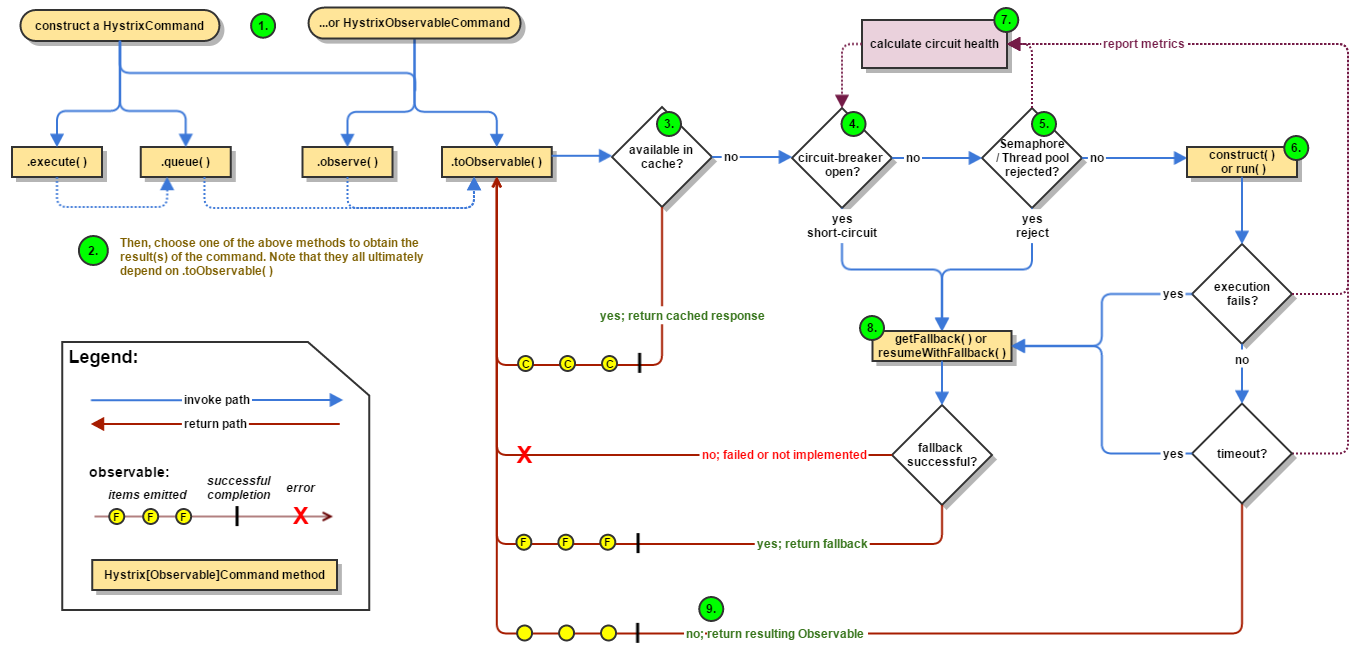
Netflix Hystrix позволяет очень тонко контролировать сетевое взаимодействие . Hystrix позволяет нам обрабатывать «восходящий» кластер, с которым мы взаимодействуем, с очень точными конфигурациями в зависимости от типа вызова, который мы делаем. Например, если мы вызываем механизм рекомендаций, мы, вероятно, делаем много запросов, которые не изменяют данные (операции без записи). Если мы делаем запросы, читаем справочные данные и т. Д., То эти отключающие конфигурации могут быть более расслабленными, чем вызовы, которые изменяют / записывают данные.
Другое важное соображение заключается в том, что Hystrix делает совершенно очевидным, что он обрабатывает сбои / таймауты не иначе, как в целях разрыва цепи, где произошел сбой. То есть это могло произойти в транспорте или в самом коде клиента. Hystrix обнаруживает пороги отключения цепи независимо от того, где произошел сбой.
И наконец, как я уже упоминал ранее: разрыв цепи — это всего лишь специализированная функция разумной балансировки нагрузки с учетом приложений. В этом случае «приложение-осведомленная» часть является буквальной: это библиотека в вашем приложении. В экосистеме Netflix OSS вы также можете связать Hystrix с чем-то вроде ленты Netflix OSS, которая является еще одной библиотекой приложений для балансировки нагрузки на стороне клиента.
Эволюция сервисной сетки
По мере того как архитектура ваших служб становится более разнородной, вам будет сложно (или нецелесообразно) ограничивать реализацию служб конкретными библиотеками, средами или даже языками. С развитием сервисной сетки мы видим некоторые из этих шаблонов устойчивости, такие как разрыв цепи, реализованные как независимые от языка / инфраструктуры решения в инфраструктуре. Сетка обслуживания может быть определена как:
|
1
2
3
|
A decentralized application-networking infrastructure between your services that provides security, resiliency, observability, and routing control. |
Сетка сервиса может полагаться на разные прокси L7 (уровня приложения) в своей «плоскости данных» для реализации функций отказоустойчивости, таких как повторные попытки, тайм-ауты, прерыватели цепи и т. Д. В этом сообщении в блоге мы рассмотрим подход Envoy Proxy разрыв цепи Envoy Proxy является стандартным прокси-сервером по умолчанию для Istio Service Mesh, поэтому описанное здесь поведение применимо и к Istio .
Посланник Proxy / Istio Service Mesh
Envoy рассматривает свою функцию прерывания цепи как подмножество балансировки нагрузки и проверки работоспособности. Envoy отделяет свои проблемы «маршрутизации» (выбирая, с каким кластером следует общаться) от связи с реальными внутренними кластерами. Это важное соображение, и именно это позволяет Envoy выйти за пределы грубых конфигураций устойчивости, которые можно найти в других реализациях балансировки нагрузки. У посланника может быть много разных «маршрутов», которые пытаются сопоставить трафик с соответствующими бэкэндами. Эти бэкэнды описываются как «кластеры», и каждый кластер может иметь свою собственную кластерную конфигурацию для распределения нагрузки. Каждый кластер также может иметь свою собственную конфигурацию для пассивной проверки работоспособности (обнаружения выбросов). На самом деле, существует несколько конфигураций посланников, которые совместно обеспечивают функциональные возможности прерывания цепи, как описано во вводном параграфе. Давайте посмотрим на каждый из них.
Мы можем определить исходящий кластер следующим образом:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
|
"clusters": [ { "name": "httpbin_service", "connect_timeout_ms": 5000, "type": "static", "lb_type": "round_robin", "hosts": [ { "url": "tcp://172.17.0.2:8080" },{ "url": "tcp://172.17.0.3:8080" } ], |
В этом примере мы видим, что у нас есть кластер с именем httpbin_service , мы собираемся использовать round_robin нагрузки round_robin и мы будем балансировать между двумя хостами. Давайте добавим конфигурацию выключателя Envoy
Выключатель
|
1
2
3
4
5
6
|
"circuit_breakers": { "default": { "max_connections": 1, "max_pending_requests": 1, "max_retries": 3 } |
Здесь мы нацелены на рабочие нагрузки HTTP 1.x. Мы ограничиваем количество исходящих подключений до 1 а максимальное количество ожидающих запросов — до 1 . Мы также определили максимальное количество повторов. В некоторых случаях такое поведение ограничения пула соединений и количества запросов аналогично переборке, которую может обеспечить Netflix Hystrix . Если наше приложение открывает больше соединений, чем эти параметры (на практике есть некоторая свобода действий — это не жесткие ограничения), мы увидим, как Envoy откроет канал для этих вызовов и сообщит об этих событиях в своей статистике отчетов. Смотрите этот пост в блоге, который идет в деталях
Обнаружение выбросов
До сих пор мы видим, что то, что Envoy называет «разрывом цепи», на самом деле является чем-то ближе к переборкам в пуле соединений . Чтобы получить поведение «разомкнутой цепи», Envoy делает то, что называется обнаружением выбросов . Envoy хранит статистику о работе различных конечных точек в своем пуле балансировки нагрузки для конкретного кластера. Если он обнаруживает ненормальное поведение, он может извлечь эту конечную точку из пула балансировки нагрузки. Давайте рассмотрим пример конфигурации для обнаружения выбросов :
|
1
2
3
4
5
6
|
"outlier_detection" : { "consecutive_5xx": 1, "max_ejection_percent": 100, "interval_ms": 1000, "base_ejection_time_ms": 60000 } |
Эта конфигурация говорит об ошибке «если у нас есть 1 5xx» в нашем взаимодействии с вышестоящим хостом, мы должны пометить его как нездоровый и временно удалить его из нашего пула балансировки нагрузки для этого кластера. Мы также настроили max_ejection_percent на 100 означает, что мы готовы max_ejection_percent все хосты, которые испытывают эти сбои. Этот параметр зависит от конкретной среды, и вы захотите настроить его. В идеале мы хотим сделать все возможное для маршрутизации на хост, чтобы не вводить частичные или каскадные сбои. Посланник по умолчанию установит max_ejection_percent 10 .
Мы также устанавливаем базовый период выброса на 6000 мс. Фактическое время, когда хост будет извлечен из пула балансировки нагрузки, — это «базовый» параметр, умноженный на количество раз, когда он был извлечен. Это позволяет нам более жестко наказывать хосты, которые кажутся неизменно менее надежными.
Кластерная паника
Одна вещь, которую мы также должны знать о Envoy для обнаружения выбросов и балансировки нагрузки. Если при обнаружении выбросов было выброшено слишком много хостов, мы могли бы перейти в режим «паники» глобального кластера, который означает, что прокси-сервер игнорирует состояние пула балансировки нагрузки и снова начнет маршрутизацию на все хосты. Это невероятно мощная встроенная функция. В распределенных системах вы должны осознавать, что иногда ваше представление о мире в «теории» неверно, и лучше всего перейти на режим, который не поощряет более каскадный сбой. С другой стороны, вы можете контролировать этот процент паники (по умолчанию, если извлекается более 50% пула балансировки нагрузки, Envoy будет паниковать) и увеличивать порог паники (> 50%) или даже полностью отключить (установив его на 0 ) Установка его в 0 делает поведение между функциями прерывания цепи Envoy более похожим на Netflix Hystrix .
Тонкая политика прерывания цепи
Одним из преимуществ библиотечного подхода является то, что мы можем применять тонко настраиваемые политики защиты от взлома приложений. В документации Hystrix используются примеры различных вызовов чтения / запроса / записи для одного вышестоящего кластера. Например, из часто задаваемых вопросов Hystrix :
|
1
2
3
4
5
6
|
Often a single network route via a cluster of loadbalancers will serve many different types of functionality that end up in several different HystrixCommands.Each HystrixCommand needs the ability to set different throughput constraints, timeout values and fallback strategies. |
С Envoy мы можем реализовать ту же политику прерывания работы хирургических систем с помощью сопоставления маршрутов, определяя, с какими именно вызовами кластера мы хотим работать, и с помощью определенных политик кластера .
Мелкозернистое прерывание цепи с Istio
Мы можем использовать высокоуровневую конфигурацию Istio для определения мелкозернистых кластеров и прерывания цепи. В Istio мы используем DestinationPolicies для настройки балансировки нагрузки и политик прерывания цепи. Вот пример политики destiantion, определяющей функциональность прерывания цепи в Istio:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
|
metadata: name: reviews-cb-policy namespace: defaultspec: destination: name: reviews labels: version: v1 circuitBreaker: simpleCb: maxConnections: 100 httpMaxRequests: 1000 httpMaxRequestsPerConnection: 10 httpConsecutiveErrors: 7 sleepWindow: 15m httpDetectionInterval: 5m |
Что делать, если цепь отключена?
Последняя часть головоломки об отключении цепи — это то, что происходит, когда мы достигаем пороговых значений отключения цепи. В Hystrix концепция резервных компонентов встроена в библиотеку и может быть организована библиотекой. В Hystrix мы можем делать такие вещи, как результаты кэширования, откат к значениям по умолчанию или даже выбирать альтернативные пути, вызывая различные сервисы. Мы также можем получить очень подробную информацию о том, что не удалось, и принять решения для конкретного приложения.
С сервисной сеткой, в настоящее время без специализированных библиотек для распространения контекста сбоев, причины сбоев более непрозрачны. Это не означает, что наше приложение не может использовать запасные варианты (как для транспортных, так и для клиентских ошибок). Я бы сказал, что очень важно, чтобы протокол любого приложения, будь то использование библиотечно-ориентированных сред или нет), всегда выполнял обещания, которые он пытается выполнить для своих клиентов. Если он обнаружит, что не может завершить запланированное действие, он должен найти способ изящно ухудшиться. К счастью, вам не нужны специфичные для приложения фреймворки для этого. Большинство языков имеют встроенные функции отслеживания и обработки ошибок и исключений. В этих путях исключения должны быть реализованы запасные варианты.
резюмировать
- Разрыв цепи — это специализированное поведение балансировщиков нагрузки.
- Hystrix выполняет только функции отключения цепи; балансировка нагрузки может быть сопряжена с лентой (или любой клиентской библиотекой балансировки нагрузки)
- Hystrix имеет понятие «запасной вариант» как проблема библиотеки / фреймворка и делает это первым и центральным
- Envoy имеет обрыв цепи и обнаружение выбросов как часть своей реализации балансировки нагрузки
- «Разрыв цепи» посланника больше похож на переборку Hystrix, а «обнаружение выброса» больше похож на выключатель Hystrix
- У Envoy есть множество стандартных и протестированных функций, таких как пороги паники.
- Сетка сервиса не в состоянии предоставить контекст ошибки обратно приложению (пока! Следите за обновлениями
| См. Оригинальную статью здесь: Сравнение посланника и разрыва цепи Istio с Netflix OSS Hystrix
Мнения, высказанные участниками Java Code Geeks, являются их собственными. |