Этот блог является частью серии статей, в которых подробно рассматриваются Envoy Proxy и Istio.io, а также рассказывается о том, как он обеспечивает более элегантный способ подключения и управления микросервисами. Следуйте за мной @christianposta, чтобы не отставать от этих выпусков поста в блоге. Я думаю, что поток, о котором я расскажу в следующих сериях, будет примерно таким:
- Что такое Envoy Proxy , как он работает?
- Как реализовать некоторые из базовых шаблонов с Envoy Proxy ?
- Как Istio Mesh вписывается в эту картину
- Как работает Istio Mesh и как он обеспечивает функциональность высшего порядка в кластерах с Envoy
- Как работает Istio Mesh auth
Вот идея для следующих нескольких частей (обновим ссылки по мере их публикации):
- Автоматические выключатели (часть I)
- Повторные попытки / Тайм-ауты (Часть II)
- Распределенная трассировка (часть III)
- Коллекция метрик с Прометеем (Часть IV)
- Следующие части будут касаться большей части функциональности на стороне клиента (Обнаружение служб, Request Shadowing, TLS и т. Д.), Просто не уверен, какие части будут, какие еще 🙂
Часть I — Разрыв цепи с доверенным лицом посланника
Это первое сообщение в блоге знакомит вас с реализацией функции прерывания цепи Envoy Proxy. Эти демонстрационные примеры преднамеренно просты, так что я могу проиллюстрировать шаблоны и использование по отдельности. Пожалуйста, загрузите исходный код для этой демонстрации и следуйте инструкциям!
Эта демонстрация состоит из клиента и сервиса. Клиент — это Java-приложение http, которое имитирует выполнение http-вызовов к «восходящему» сервису (обратите внимание, мы используем терминологию Envoys здесь и выполняем это репо ). Клиент упакован в образ Docker с именем docker.io/ceposta/http-envoy-client:latest . Наряду с http-клиентом Java-приложение является экземпляром Envoy Proxy . В этой модели развертывания Envoy разворачивается как сопутствующая служба вместе со службой (в данном случае клиентом http). Когда http-клиент совершает исходящие звонки (в «восходящий» сервис), все звонки проходят через коляску Envoy Proxy.
Сервис «upstream» для этих примеров — httpbin.org . httpbin.org позволяет нам легко моделировать поведение службы HTTP. Это круто, так что проверь, если ты не видел.
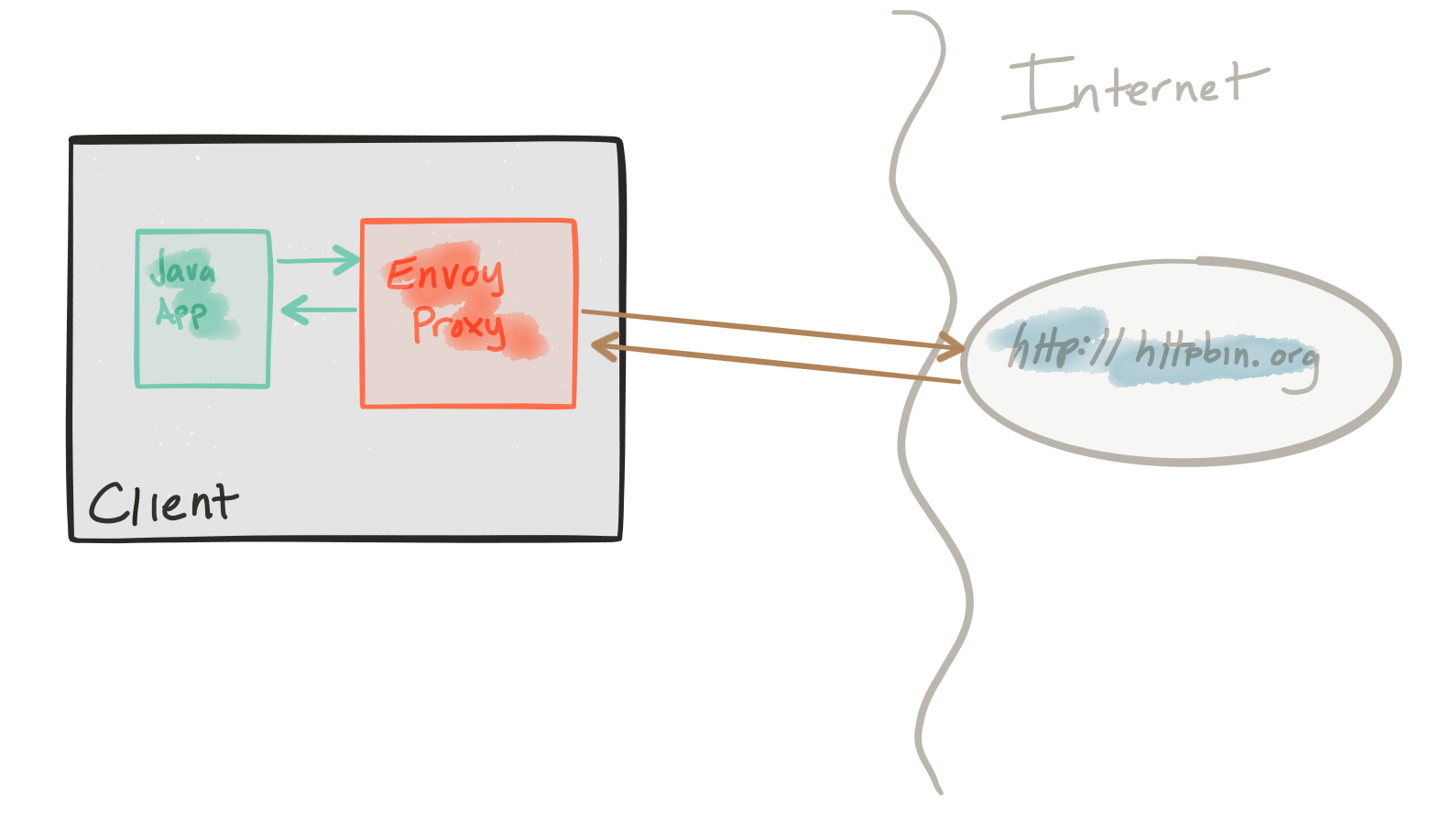
Демонстрация выключателя имеет собственный envoy.json конфигурации envoy.json . Я определенно рекомендую взглянуть на справочную документацию для каждого раздела файла конфигурации, чтобы помочь понять полную конфигурацию. Хорошие люди из datawire.io также собрали хорошее введение в Envoy и его конфигурацию, которую вы также должны проверить.
Запуск демоверсии выключателя
Для запуска демонстрации circuit-breaker ознакомьтесь с демо-фреймворком и запустите:
|
1
|
./docker-run.sh -d circuit-breaker |
Конфигурация посланника для автоматических выключателей выглядит следующим образом (см. Полную конфигурацию здесь ):
|
1
2
3
4
5
6
7
|
"circuit_breakers": { "default": { "max_connections": 1, "max_pending_requests": 1, "max_retries": 3 }} |
Эта конфигурация позволяет нам:
- ограничить количество HTTP / 1-соединений, которые мы установим с вышестоящими кластерами, закорачивая их, если мы перейдем
- ограничить число запросов, которые будут поставлены в очередь / ожидающих подключения, закорачивая их, если мы переходим
- ограничить количество одновременных повторных попыток в любой момент времени (при условии применения политики повторных попыток), эффективно установив квоту повторных попыток
Давайте посмотрим на каждую конфигурацию. Мы проигнорируем настройки максимального повтора прямо сейчас по двум причинам
- Наши настройки не имеют особого смысла; у нас не может быть 3 одновременных повторных попыток, поскольку у нас разрешено только 1 HTTP-соединение с 1 запросом в очереди
- На самом деле у нас нет никакой политики повторов для этой демонстрации; мы можем увидеть повторы в действии в демонстрации
retries
В любом случае настройка повторных попыток позволяет нам избежать больших повторных штормов, которые в большинстве случаев могут усугубить проблемы, связанные с подключением ко всем экземплярам в кластере. Это важный параметр, к которому мы вернемся с демонстрацией retries .
max_connections
Давайте посмотрим, что делает посланник, когда слишком много потоков в приложении пытаются создать слишком много одновременных соединений с вышестоящим кластером.
Напомним, что наши настройки прерывания цепи для нашего восходящего кластера httbin выглядят так (см. Полную конфигурацию здесь ):
|
1
2
3
4
5
6
7
|
"circuit_breakers": { "default": { "max_connections": 1, "max_pending_requests": 1, "max_retries": 3 }} |
Если мы посмотрим на ./circuit-breaker/http-client.env настроек ./circuit-breaker/http-client.env , то увидим, что изначально мы начнем с запуска одного потока, который создает единственное соединение, выполняет пять вызовов и завершает работу:
|
1
2
3
4
5
|
NUM_THREADS=1DELAY_BETWEEN_CALLS=0NUM_CALLS_PER_CLIENT=5URL_UNDER_TEST=http://localhost:15001/getMIX_RESPONSE_TIMES=false |
Давайте проверим это. Запустите демо:
|
1
|
./docker-run.sh -d circuit-breaker |
Это устанавливает приложение с его клиентскими библиотеками, а также настраивает Envoy Proxy. Мы будем отправлять трафик напрямую в Envoy Proxy, чтобы обработать для нас разрыв цепи. Позвоним в наш сервис:
|
1
|
docker exec -it client bash -c 'java -jar http-client.jar' |
Мы должны увидеть результат примерно так:
|
1
2
3
|
using num threads: 1Starting pool-1-thread-1 with numCalls=5 delayBetweenCalls=0 url=http://localhost:15001/get mixedRespTimes=falsepool-1-thread-1: successes=[5], failures=[0], duration=[545ms] |
Мы видим, что все пять наших звонков были успешными!
Давайте посмотрим на некоторые показатели, собранные Envoy Proxy:
|
1
|
./get-envoy-stats.sh |
ВОТ ЭТО ДА! Это множество метрик треков для нас! Давайте разберемся с этим:
|
1
|
./get-envoy-stats.sh | grep cluster.httpbin_service |
Это покажет метрики для нашего настроенного восходящего кластера с именем httpbin_service . Бегло рассмотрите некоторые из этих статистических данных и посмотрите их значение в документации посланника . Важные из них следует отметить здесь:
|
1
2
3
4
5
6
|
cluster.httpbin_service.upstream_cx_http1_total: 1cluster.httpbin_service.upstream_rq_total: 5cluster.httpbin_service.upstream_rq_200: 5cluster.httpbin_service.upstream_rq_2xx: 5cluster.httpbin_service.upstream_rq_pending_overflow: 0cluster.httpbin_service.upstream_rq_retry: 0 |
Это говорит нам о том, что у нас было 1 соединение http / 1 с 5 запросами (всего) и 5 из них закончились HTTP 2xx (и даже 200 ). Большой! Но что произойдет, если мы попытаемся использовать два одновременных соединения?
Сначала давайте сбросим статистику:
|
1
2
|
./reset-envoy-stats.shOK |
Давайте вызовем эти вызовы с 2 потоками:
|
1
|
docker exec -it client bash -c 'NUM_THREADS=2; java -jar http-client.jar' |
Мы должны увидеть какой-то вывод:
|
1
2
3
4
5
|
using num threads: 2Starting pool-1-thread-1 with numCalls=5 delayBetweenCalls=0 url=http://localhost:15001/get mixedRespTimes=falseStarting pool-1-thread-2 with numCalls=5 delayBetweenCalls=0 url=http://localhost:15001/get mixedRespTimes=falsepool-1-thread-1: successes=[0], failures=[5], duration=[123ms]pool-1-thread-2: successes=[5], failures=[0], duration=[513ms] |
Вау … У одной из наших тем было 5 успехов, но у одной из них нет! В одном потоке все 5 запросов не были выполнены! Давайте еще раз посмотрим на статистику посланника:
|
1
|
./get-envoy-stats.sh | grep cluster.httpbin_service |
Теперь наша статистика сверху выглядит так:
|
1
2
3
4
5
6
7
8
|
cluster.httpbin_service.upstream_cx_http1_total: 1cluster.httpbin_service.upstream_rq_total: 5cluster.httpbin_service.upstream_rq_200: 5cluster.httpbin_service.upstream_rq_2xx: 5cluster.httpbin_service.upstream_rq_503: 5cluster.httpbin_service.upstream_rq_5xx: 5cluster.httpbin_service.upstream_rq_pending_overflow: 5cluster.httpbin_service.upstream_rq_retry: 0 |
Из этого вывода мы видим, что только одно из наших соединений успешно выполнено! В итоге мы получили 5 запросов, в результате которых был получен HTTP 200 и 5 запросов, которые закончились HTTP 503 . Мы также видим, что upstream_rq_pending_overflow был увеличен до 5 . Это свидетельствует о том, что выключатель сделал свою работу здесь. Он замыкал любые вызовы, которые не соответствовали нашим настройкам конфигурации.
Обратите внимание, что мы установили нашу настройку max_connections на искусственно низкое число, в данном случае 1, чтобы проиллюстрировать функцию прерывания цепи Envoy. Это нереалистичная обстановка, но, надеюсь, служит иллюстрацией этого.
max_pending_requests
Давайте запустим несколько похожих тестов, чтобы max_pending_requests настройку max_pending_requests .
Напомним, что наши настройки прерывания цепи для нашего восходящего кластера httbin выглядят так (см. Полную конфигурацию здесь ):
|
1
2
3
4
5
6
7
|
"circuit_breakers": { "default": { "max_connections": 1, "max_pending_requests": 1, "max_retries": 3 }} |
Мы хотим имитировать несколько одновременных запросов, происходящих в одном HTTP-соединении (поскольку нам разрешено только max_connections из 1). Мы ожидаем, что запросы будут поставлены в очередь, но Envoy должен отклонить поставленные в очередь сообщения, поскольку у нас max_pending_requests установлено в 1. Мы хотим установить верхние пределы для глубины нашей очереди и не допускать повторных штормов, неконтролируемых нисходящих запросов, DoS и ошибок в наша система каскадная.
Продолжая предыдущий раздел, давайте сбросим статистику посланника:
|
1
2
|
./reset-envoy-stats.shOK |
Давайте вызовем клиента с 1 потоком (то есть с 1 HTTP-соединением), но отправим наши запросы параллельно (пакетами по 5 по умолчанию). Мы также хотим рандомизировать задержки, которые мы получаем при отправке, чтобы вещи могли стоять в очереди:
|
1
|
docker exec -it client bash -c 'NUM_THREADS=1 && PARALLEL_SENDS=true && MIX_RESPONSE_TIMES=true; java -jar http-client.jar' |
Мы должны увидеть вывод, похожий на этот:
|
1
2
3
4
5
6
7
8
9
|
using num threads: 1Starting pool-1-thread-1 with numCalls=5 parallelSends=true delayBetweenCalls=0 url=http://localhost:15001/get mixedRespTimes=truepool-2-thread-3: using delay of : 3pool-2-thread-2: using delay of : 0pool-2-thread-1: using delay of : 2pool-2-thread-4: using delay of : 4pool-2-thread-5: using delay of : 0finished batch 0pool-1-thread-1: successes=[1], failures=[4], duration=[4242ms] |
Черт! четыре наших запроса не были выполнены… давайте проверим статистику посланника:
|
1
|
./get-envoy-stats.sh | grep cluster.httpbin_service | grep pending |
Конечно же, мы видим, что 4 из наших запросов были закорочены:
|
1
2
3
4
|
cluster.httpbin_service.upstream_rq_pending_active: 0cluster.httpbin_service.upstream_rq_pending_failure_eject: 0cluster.httpbin_service.upstream_rq_pending_overflow: 4cluster.httpbin_service.upstream_rq_pending_total: 1 |
А как насчет того, когда услуги полностью отключаются?
Мы видели, какие возможности Envoy для прерывания цепи используют для короткого замыкания и перегрузки потоков в кластеры, но что, если узлы в кластере полностью разрушаются (или кажутся отключенными)?
Envoy имеет настройки для «обнаружения выбросов», которые могут обнаруживать ненадежные узлы в кластере и могут полностью исключить их из ротации кластера (на определенный период времени). Один интересный феномен, который необходимо понять, заключается в том, что по умолчанию Envoy извлекает хосты из алгоритмов балансировки нагрузки до определенной точки. Алгоритмы балансировки нагрузки Envoy обнаружат порог паники, если слишком много (то есть> 50%) хостов были признаны нездоровыми, и просто вернутся к балансировке нагрузки для всех них. Этот порог паники настраивается, и чтобы получить функцию отключения цепи, которая сбрасывает нагрузку (на период времени) на все хосты во время серьезного сбоя, вы можете настроить параметры обнаружения выбросов. В нашем примере конфигурации выключателя ) envoy.json вы можете увидеть следующее:
|
1
2
3
4
5
|
"outlier_detection" : { "consecutive_5xx": 5, "max_ejection_percent": 100, "interval_ms": 3 } |
Давайте проверим этот случай и посмотрим, что произойдет. Сначала сбросьте статистику:
|
1
2
|
./reset-envoy-stats.shOK |
Далее, давайте позвоним нашему клиенту с URL, который вернет нам результаты HTTP 500 . Мы сделаем 10 звонков, потому что наше обнаружение выброса проверит 5 последовательных ответов 5xx, поэтому мы хотим сделать больше, чем 5 звонков.
|
1
|
docker exec -it client bash -c 'URL_UNDER_TEST=http://localhost:15001/status/500 && NUM_CALLS_PER_CLIENT=10; java -jar http-client.jar' |
Мы должны увидеть ответ, подобный этому, когда все вызовы были неудачными (как мы и ожидали: по крайней мере 5 из них вернули бы HTTP 500):
|
1
2
3
|
using num threads: 1Starting pool-1-thread-1 with numCalls=10 parallelSends=false delayBetweenCalls=0 url=http://localhost:15001/status/500 mixedRespTimes=falsepool-1-thread-1: successes=[0], failures=[10], duration=[929ms] |
Давайте теперь проверим статистику посланника, чтобы увидеть, что именно произошло:
|
1
|
./get-envoy-stats.sh | grep cluster.httpbin_service | grep outlier |
|
1
2
3
4
5
|
cluster.httpbin_service.outlier_detection.ejections_active: 0cluster.httpbin_service.outlier_detection.ejections_consecutive_5xx: 1cluster.httpbin_service.outlier_detection.ejections_overflow: 0cluster.httpbin_service.outlier_detection.ejections_success_rate: 0cluster.httpbin_service.outlier_detection.ejections_total: 1 |
Мы видим, что мы сработали при последовательном обнаружении 5xx! Мы также удалили этот хост из нашей группы балансировки нагрузки.
Серии
Пожалуйста, следите за обновлениями ! Части II и III о таймаутах / повторных попытках / отслеживании должны появиться на следующей неделе!
| Ссылка: | Шаблоны микросервисов с Envoy Sidecar Proxy, часть I: разрыв цепи от нашего партнера JCG Кристиана Поста в блоге |