Проблема C10K — это термин, обозначающий десять тысяч одновременно обрабатывающих соединений. Чтобы добиться этого, нам часто нужно вносить изменения в настройки созданных сетевых сокетов и настройки по умолчанию ядра Linux, отслеживать использование буферов и очередей отправки / получения TCP и, в частности, настраивать наше приложение, чтобы оно было хорошим кандидатом. для решения этой проблемы.
В сегодняшней статье я собираюсь обсудить общие принципы, которым необходимо следовать, если мы хотим создать масштабируемое приложение, которое может обрабатывать тысячи соединений. Я буду ссылаться на Netty Framework, TCP и внутренние компоненты Socket и некоторые полезные инструменты, если вы хотите получить представление о вашем приложении и базовой системе.
Вам также может понравиться:
Модели программирования для серверов на Java
Отказ от ответственности : я буду немного педантичен с точки зрения памяти, потому что если мы хотим умножить наш поток обработки на количество соединений (10 000>), то каждый килобайт в одном конвейере обработки соединений становится очень дорогим ?
Принцип 1. Сделайте ваше приложение подходящим для проблемы C10K
Как мы упоминали выше, когда нам нужно максимально использовать процессор с минимальным переключением контекста и нехваткой памяти, вам нужно поддерживать подсчет потоков в вашем процессе очень близким к числу процессоров, выделенных для данной задачи. применение.
Помня об этом, единственно возможное решение состоит в том, чтобы подобрать неблокирующую бизнес-логику или бизнес-логику с очень высоким отношением времени обработки ЦП / В (но это уже становится рискованным).
Иногда не очень легко определить это поведение в вашем стеке приложений. Иногда вам нужно будет переупорядочить свои приложения / код, добавить дополнительную внешнюю очередь (RabbitMQ) или тему (Kafka), чтобы изменить распределенную систему, чтобы иметь возможность буферизовать задачи и разделять неблокирующий код от код, который не может быть легко переопределен с использованием неблокирующих методов (например, использование драйвера JDBC, в настоящее время нет официального неблокирующего драйвера для реляционных баз данных — насколько я знаю, работа над ADBC - API асинхронного доступа к базам данных — уже была остановлен).
Однако, по моему опыту, стоит переписать мой код и сделать его более неблокирующим по следующим причинам:
-
Я разделил свое приложение на два разных приложения, которые, скорее всего, не используют одни и те же стратегии развертывания и разработки, даже если они совместно используют один и тот же «домен» (например, одна часть приложения является конечной точкой REST, которая может быть реализована с использованием потокового пула). HTTP-сервер на основе и вторая часть является потребителем из очереди / темы, которая записывает что-то в БД с использованием неблокирующего драйвера).
-
Я могу по-разному масштабировать количество экземпляров этих двух частей, потому что очень вероятно, что нагрузка / процессор / память абсолютно разные.
Что может означать, что мы используем надлежащие инструменты для такого рода приложений:
-
Мы сохраняем количество потоков как можно ниже. Не забудьте проверить не только потоки вашего сервера, но и другие части вашего приложения: потребитель очереди / темы, настройки драйвера БД, настройки ведения журнала (с асинхронным микропакетированием). Всегда делайте дамп потока, чтобы увидеть, какие потоки созданы в вашем приложении и сколько (не забудьте сделать это под нагрузкой, иначе ваши пулы потоков не будут полностью инициализированы, многие из них создают ленивые потоки). Я всегда называю свои собственные потоки из пула потоков (гораздо проще найти жертву и отладить ваш код).
-
Помните о блокировке вызовов HTTP / DB для других служб, мы можем использовать реактивные клиенты, которые автоматически регистрируют обратный вызов для входящего ответа. Подумайте об использовании протокола, который больше подходит для связи сервис-2, например, RSocket.
-
Проверьте, содержит ли ваше приложение постоянно небольшое количество потоков. Это относится к тому, имеет ли ваше приложение ограниченные пулы потоков и может ли оно выдерживать заданную нагрузку.
Если ваше приложение имеет несколько потоков обработки, всегда проверяйте, какие из них блокируют, а какие — не блокируют. Если количество потоков блокирования является значительным, то вам нужно, чтобы почти каждый запрос (по крайней мере, часть потока обработки, где используется вызов блокировки) обрабатывался в другом потоке (из предопределенного пула потоков), чтобы освободить поток цикла событий для следующее соединение (более подробная информация в следующей главе).
В этом случае рассмотрите возможность использования HTTP-сервера на основе пула потоков с рабочими, где все запросы помещаются в поток, отличный от очень огромного пула потоков, для увеличения пропускной способности — другого пути, если мы не сможем избавиться от блокировки, нет. звонки .
Принцип 2: Кэшированные соединения, а не потоки
Этот принцип тесно связан с темой Модели программирования для HTTP-сервера . Основная идея состоит не в том, чтобы связать соединение с одним потоком, а в использовании некоторых библиотек, которые поддерживают немного сложный, но гораздо более эффективный подход чтения из TCP.
Это не значит, что TCP-соединение абсолютно бесплатно. Наиболее важной частью является TCP рукопожатие . Поэтому вы всегда должны использовать постоянное соединение ( keep-alive ). Если бы мы использовали одно TCP-соединение только для отправки одного сообщения, мы заплатили бы за 8 сегментов TCP (соединение и закрытие соединения = 7 сегментов).
Принятие нового соединения TCP
Если мы находимся в ситуации, когда мы не можем использовать постоянное соединение, то, скорее всего, мы получим множество созданных соединений за очень короткий период времени. Эти созданные соединения должны быть поставлены в очередь и ожидают принятия нашей заявки.
На картинке выше мы видим, что резервы SYN и LISTEN . В журнале SYN Backlog мы можем найти соединения, которые просто ожидают подтверждения с помощью TCP Handshake . Однако в LISTEN Backlog у нас уже есть полностью инициализированные соединения, даже с буферами отправки и получения TCP , которые только и ждут, чтобы быть принятыми нашим приложением.
Прочитайте SYN Flood DDoS Attack, если вы хотите узнать больше, почему нам на самом деле нужны две резервные копии.
На самом деле есть одна проблема, если мы находимся под нагрузкой и имеем много входящих соединений, потоки наших приложений, которые отвечают за принятие соединений, могут быть заняты, выполняя какую-то другую работу — выполнение ввода-вывода для уже подключенных клиентов.
Джава
xxxxxxxxxx
1
var bossEventLoopGroup = new EpollEventLoopGroup ( 1 );
2
var workerEventLoopGroup = new EpollEventLoopGroup ();
3
новый ServerBootstrap ()
5
, канал ( EpollServerSocketChannel . класс )
6
, группа ( bossEventLoopGroup , workerEventLoopGroup )
7
, localAddress ( 8080 )
8
, childOption ( ChannelOption . SO_SNDBUF , 1024 * 1024 )
9
, childOption ( ChannelOption . SO_RCVBUF , 32 * тысяча двадцать четыре )
10
, childHandler ( новый CustomChannelInitializer ());
11
bossEventLoopGroup
и
workerEventLoopGroup
. Хотя
workerEventLoopGroup по умолчанию создается с
числом процессоров * 2 потока / цикла обработки событий для выполнения операций ввода-вывода,
bossEventLoopGroup
содержит один поток для принятия новых подключений. Netty позволяет иметь только одну группу для обоих действий, но в этом случае принятие новых соединений может привести к истощению из-за выполнения операций ввода-вывода или более длительных операций в
ChannelHandlers.
Если мы столкнемся с проблемой полного LISTEN Backlog, то сможем увеличить количество потоков в bossEventLoopGroup. Мы можем очень легко проверить, способен ли наш процесс выдерживать нагрузку входящих соединений. Я изменил наше тестовое приложение Websocket-Broadcaster для подключения 20 000 клиентов и несколько раз выполнил эту команду:
$ ss -plnt sport = :8081|cat
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 42 128 *:8081 *:* users:(("java",pid=7418,fd=86))
$ ss -plnt sport = :8081|cat
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 *:8081 *:* users:(("java",pid=7418,fd=86))
$ ss -plnt sport = :8081|cat
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 20 128 *:8081 *:* users:(("java",pid=7418,fd=86))
$ ss -plnt sport = :8081|cat
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 63 128 *:8081 *:* users:(("java",pid=7418,fd=86))
$ ss -plnt sport = :8081|cat
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 *:8081 *:* users:(("java",pid=7418,fd=86))-
Send-Q : общий размер LISTEN Backlog
-
Recv-Q : текущее количество соединений в LISTEN Backlog
Джава
xxxxxxxxxx
1
# Текущий размер по умолчанию LISTEN Backlog
2
# Feel бесплатно , чтобы изменить его и тест SS команду еще раз
3
cat / proc / sys / net / core / somaxconn
4
128
TCP отправлять / получать буферы
Однако, когда ваше соединение готово, наиболее жадными частями являются буферы отправки / получения TCP , которые используются для передачи байтов, записанных вашим приложением, в базовый сетевой стек. Размер этих буферов можно установить через приложение:
Джава
xxxxxxxxxx
1
новый ServerBootstrap ()
2
, канал ( EpollServerSocketChannel . класс )
3
, группа ( bossEventLoopGroup , workerEventLoopGroup )
4
, localAddress ( 8080 )
5
, childOption ( ChannelOption . SO_SNDBUF , 1024 * 1024 )
6
, childOption ( ChannelOption . SO_RCVBUF , 32 * тысяча двадцать четыре )
7
, childHandler ( новый CustomChannelInitializer ());
8
Прочитайте TCP Buffer Sizing перед любой пользовательской настройкой. Большие буферы могут привести к потере памяти, с другой стороны, меньшие буферы могут задушить приложение читателя или писателя, потому что не будет места для передачи байтов в / из сетевого стека.
Почему кеширование Thread - плохая идея?
Сколько памяти требуется нашему «микро» сервису для обработки тысяч соединений, если мы используем стратегию « соединение на поток» или большие пулы потоков для обработки бизнес-логики блокировки.
Java Thread - довольно дорогой объект, потому что он отображается один в один с потоком ядра (надеюсь, проект Loom рано придет, чтобы спасти нас). В Java мы можем ограничить размер стека потока, используя опцию -Xss, которая по умолчанию имеет значение 1 МБ . Это означает, что один поток занимает 1 МБ виртуальной памяти, но не зарезервированную память.
Реальный RSS (Resident Set Size) равен текущему размеру стека; память не полностью выделяется и отображается в физической памяти в самом начале (это очень часто неправильно понимается, как показано в этом посте: сколько памяти занимает поток Java? ). Обычно (согласно моему опыту) размер потока составляет сотни килобайт (200-300 кБ), если мы действительно не используем жадные фреймворки или рекурсию. Этот вид памяти принадлежит родной памяти; мы можем отследить это в Native Memory Tracking .
xxxxxxxxxx
1
$ java - XX : + UnlockDiagnosticVMOptions - XX : NativeMemoryTracking = summary /
2
- XX : + РаспечататьNMTStatistics - версия
3
openjdk версия "11.0.2" 2019 - 01 - 15
4
Среда выполнения OpenJDK AdoptOpenJDK ( сборка 11.0 . 2 + 9 )
5
OpenJDK 64 - битный сервер VM AdoptOpenJDK ( сборка 11.0 . 2 + 9 , смешанный режим )
6
Native Memory Tracking :
7
Итого : зарезервировано = 6643041 КБ , зафиксировано = 397465 КБ
8
- Java Heap ( зарезервировано = 5079040 КБ , зафиксировано = 317440 КБ )
9
( mmap : зарезервировано = 5079040 КБ , зафиксировано = 317440 КБ )
10
- Класс ( зарезервировано = 1056864 КБ , зафиксировано = 4576 КБ )
11
( занятия № 426 )
12
( экземпляры классов # 364 , массивы классов # 62 )
13
( malloc = 96 КБ № 455 )
14
( mmap : зарезервировано = 1056768 КБ , зафиксировано = 4480 КБ )
15
( Метаданные 🙂
16
( зарезервировано = 8192 КБ , зафиксировано = 4096 КБ )
17
( используется = 2849 КБ )
18
( бесплатно = 1247 КБ )
19
( отходы = 0 кБ = 0 , 00 % )
20
( Классное пространство 🙂
21
( зарезервировано = 1048576 КБ , зафиксировано = 384 КБ )
22
( используется = 270 КБ )
23
( бесплатно = 114 КБ )
24
( отходы = 0 кБ = 0 , 00 % )
25
- Тема ( зарезервировано = 15461 КБ , зафиксировано = 613 КБ )
26
( тема № 15 )
27
( стек : зарезервировано = 15392 КБ , зафиксировано = 544 КБ )
28
( malloc = 52 КБ № 84 )
29
( арена = 18 КБ № 28 )
Другая проблема с большим количеством потоков - это огромный Root Set . Например, у нас есть 4 процессора и 200 потоков. В этом случае мы все еще можем запускать только 4 потока в данный момент времени, но если все 200 потоков уже заняты обработкой какого-либо запроса, мы платим невероятно большую цену за объекты, которые уже размещены в Java Heap, но не могут создать прогресс, потому что данный поток ожидает процессорного времени. Все объекты, которые уже были выделены и все еще используются, являются частью Live Set (достижимые объекты, которые необходимо пройти во время цикла сбора мусора и которые нельзя собрать).
Почему Root Set так важен?
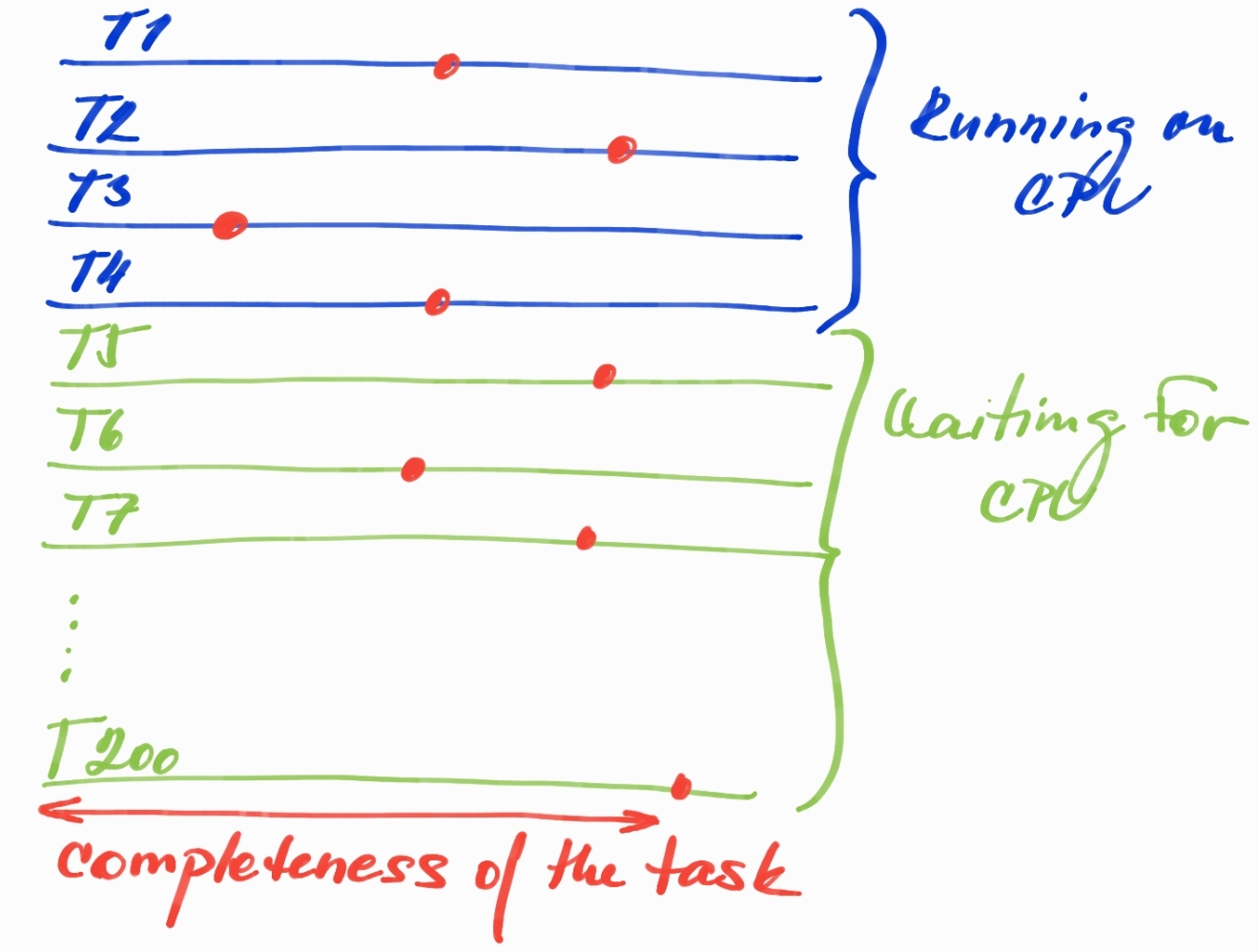
Красные точки могут обозначать любой момент времени, когда только 4 потока в данный момент работают на CPU, а остальные просто ждут в очереди выполнения CPU . Завершенность задачи не означает, что все объекты, выделенные до сих пор, все еще живы и являются частью Live Set , их уже можно превратить в мусор, ожидая удаления следующего цикла GC. Что такого плохого в этой ситуации?
-
Слишком большой живой набор : каждый поток сохраняет выделенные живые объекты в куче Java, которые просто ждут, пока ЦП достигнет определенного прогресса. Нам нужно помнить об этом, когда мы измеряем кучу, где таким образом будет использоваться много памяти - очень неэффективно - особенно если мы хотим разработать небольшие сервисы, обрабатывающие большое количество запросов.
-
Большие паузы GC из-за большего набора корней : Большой набор корней означает сложную работу для нашего сборщика мусора. Современные GC начинаются с идентификации Root Set (также называемого Snapshot-at-the-the-begin или initial-mark , в основном это живые потоки, сохраняющие выделенные достижимые объекты вне кучи - но не только потоки), а затем одновременно проходят по графу объектов / ссылки, чтобы найти текущий Live Set . Чем больше корневой набор, тем больше работы GC по его идентификации и прохождению, более того, начальная отметка обычно является фазой, известной как « остановка мира». фаза. Одновременное прохождение по огромному графу объектов также может привести к большим задержкам и ухудшению предсказуемости самого GC (GC должен запустить параллельную фазу раньше, чтобы завершить ее до заполнения кучи, также в зависимости от скорости выделения).
-
Продвижение к старому поколению : Большой Live Set также будет влиять на время, в течение которого данный объект будет рассматриваться как живой объект. Это увеличивает вероятность того, что объект будет переведен в старое поколение (или, по крайней мере, в пространство выживания ), даже если поток, поддерживающий этот объект, провел большую часть своего времени вне ЦП.
Принцип 3: прекратить генерировать мусор
Если вы действительно хотите написать приложение, которое будет находиться под большой нагрузкой, вам нужно подумать о распределении всех объектов и не позволять JVM тратить ни одного байта. Это приводит нас ByteBuffers и ByteBuf нетти. Это очень продвинутый, поэтому просто очень кратко.
ByteBuffers являются держателями байтов JDK. Там два варианта HeapByteBuffer (байтовые массивы, выделенные на куче) и DirectByteBuffer(память вне кучи). Основная причина в том, что они DirectByteBuffersмогут быть напрямую переданы функциям собственной ОС для выполнения ввода-вывода - другими словами, когда вы выполняете ввод-вывод в Java, вы передаете ссылку DirectByteBuffer (со смещением и длиной).
Это может помочь во многих случаях использования. Представьте, у вас есть 10 тыс. Соединений и вы хотите передать всем им одинаковое строковое значение. Нет причин передавать строку и вызывать сопоставление одной и той же строки с байтами в 10 000 раз (или, что еще хуже, генерировать новый строковый объект для каждого клиентского соединения и загрязнять кучу тем же массивом байтов), и надеяться, что Механизм дедупликации строки будет действовать быстро). Вместо этого мы можем сгенерировать свое собственное DirectByteBuffer и предоставить его всем соединениям и позволить им просто передавать его через JVM в ОС.
Однако есть одна проблема. DirectByteBuffer очень дорого выделять. Поэтому в JDK каждый поток, выполняющий ввод-вывод (и не потребляющий DirectByteBuffers генерацию из логики нашего приложения), кэширует один DirectByteBuffer для этого внутреннего использования. Пожалуйста, прочитайте Устранение утечки памяти собственного байта Java в ByteBuffer, чтобы получить некоторую информацию о потенциальной проблеме этого решения.
Но зачем нам, HeapByteBuffer если нам все еще нужно преобразовать его во DirectByteBuffer внутреннюю, чтобы иметь возможность записать его в ОС? Это правда, но HeapByteBuffer намного дешевле с точки зрения распределения. Если мы примем во внимание приведенный выше пример, мы могли бы, по крайней мере, исключить первый шаг - кодирование строки в массив байтов (а не делать это 10 раз), а затем мы можем рассчитывать на механизм автоматического кэширования DirectByteBuffer для каждого поток внутри JDK и не нужно платить цену за выделение нового DirectByteBuffer для каждого нового строкового сообщения, иначе нам нужно будет разработать наш собственный механизм кэширования в нашем бизнес-коде.
Какой вариант лучше? Когда мы хотим использовать DirectByteBuffer без кэширования, а когда лучше использовать HeapByteBuffer и рассчитывать на механизм автоматического кэширования? Нам нужно экспериментировать и измерять.
Я упомянул ByteBuf механизм для Netty. Это на самом деле концепция как ByteBuffer; тем не менее, мы можем пользоваться удобным API, основанным на 2 индексах (один для чтения, другой для записи). Другое различие заключается в восстановлении памяти. DirectByteBuffer основан на классе JDK Cleaner .
Это означает, что нам нужно запустить GC, в противном случае у нас заканчивается собственная память. Это может быть проблемой для приложений, которые очень оптимизированы и не размещают в куче, что означает, что они не запускают GC. Тогда нам нужно рассчитывать на то, что явный GC ( System#gc()) придет на помощь и освободит достаточно памяти для следующих собственных выделений.
Netty ByteBuf можно создавать в двух версиях: в пуле и в пуле , а освобождение собственной памяти (или помещение буфера обратно в пул) основано на механизме подсчета ссылок. Это какая-то дополнительная ручная работа. Нам нужно писать, когда мы хотим уменьшить счетчик ссылок, но это решает проблему, упомянутую выше.
Если вы хотите прочитать о буфере:
Устранение неполадок с собственной (вне кучи) памяти в приложениях Java
Bytebuf против DirectByteBuffer
Принцип 4: Измерьте, какую нагрузку вы генерируете в часы пик
Если вы хотите получить представление об уровне TCP, я настоятельно рекомендую:
Используя bpftrace, мы можем написать простую программу и получить быстрый результат и иметь возможность исследовать проблему. Это пример socketio-pid.bt, показывающий, сколько байтов было передано на основе гранулярности PID.
Джава
xxxxxxxxxx
1
# ! / snap / bin / bpftrace
2
#include < linux / fs . h >
4
НАЧАТЬ
6
{
7
printf ( «Socket READS / WRITES и переданные байты, PID:% u \ n» , $ 1 );
8
}
9
kprobe : sock_read_iter ,
11
kprobe : sock_write_iter
12
/ $ 1 == 0 || ( $ 1 ! = 0 && pid == $ 1 ) /
13
{
14
[ tid ] = arg0 ;
15
}
16
kretprobe : sock_read_iter
18
/ [ tid ] && ( $ 1 == 0 || ( $ 1 ! = 0 && pid == $ 1 )) /
19
{
20
$ file = (( struct kiocb * ) [ tid ]) -> ki_filp ;
21
$ name = $ file -> f_path . Дентри -> имя_Д . имя ;
22
[ comm , pid , "read" , str ( $ name )] = count ();
23
[ comm , pid , "read" , str ( $ name )] = sum ( retval > 0 ? retval : 0 );
24
удалить ( [ tid ]);
25
}
26
kretprobe : sock_write_iter
28
/ [ tid ] && ( $ 1 == 0 || ( $ 1 ! = 0 && pid == $ 1 )) /
29
{
30
$ file = (( struct kiocb * ) [ tid ]) -> ki_filp ;
31
$ name = $ file -> f_path . Дентри -> имя_Д . имя ;
32
[ comm , pid , "write" , str ( $ name )] = count ();
33
[ comm , pid , "write" , str ( $ name )] = sum ( retval > 0 ? retval : 0 );
34
удалить ( [ tid ]);
35
}
36
КОНЕЦ
38
{
39
ясно ( );
40
}
Я вижу пять потоков Netty, называемых server-io-x, и каждый поток обозначает один цикл обработки событий . Каждый цикл обработки событий имеет одного подключенного клиента, и приложение передает случайно сгенерированное строковое сообщение всем подключенным клиентам, используя протокол Websocket.
-
@bytes - сумма прочитанных / записанных байтов
-
@io - общее количество операций чтения / записи (1 сообщение чтения означает рукопожатие Websocket)
Джава
xxxxxxxxxx
1
, / socketio - pid . Bt 27069
2
Присоединение 6 зондов ...
3
Разъем ЧИТАЕТ / Пишет и переданные байты , PID : 27069
4
^ C
5
[ сервер - io - 3 , 27069 , чтение , TCPv6 ]: 292
7
[ сервер - io - 4 , 27069 , чтение , TCPv6 ]: 292
8
[ сервер - io - 0 , 27069 , чтение , TCPv6 ]: 292
9
[ сервер - io - 2 , 27069 , чтение , TCPv6 ]: 292
10
[ сервер - io - 1 , 27069 , чтение , TCPv6 ]: 292
11
[ сервер - io - 3 , 27069 , запись , TCPv6 ]: 1252746
12
[ сервер - io - 1 , 27069 , запись , TCPv6 ]: 1252746
13
[ сервер - io - 0 , 27069 , запись , TCPv6 ]: 1252746
14
[ сервер - io - 4 , 27069 , запись , TCPv6 ]: 1252746
15
[ сервер - io - 2 , 27069 , запись , TCPv6 ]: 1252746
16
[ сервер - io - 3 , 27069 , чтение , TCPv6 ]: 1
18
[ сервер - io - 4 , 27069 , чтение , TCPv6 ]: 1
19
[ сервер - io - 0 , 27069 , чтение , TCPv6 ]: 1
20
[ сервер - io - 2 , 27069 , чтение , TCPv6 ]: 1
21
[ сервер - io - 1 , 27069 , чтение , TCPv6 ]: 1
22
[ сервер - io - 3 , 27069 , запись , TCPv6 ]: 1371
23
[ сервер - io - 1 , 27069 , запись , TCPv6 ]: 1371
24
[ сервер - io - 0 , 27069 , запись , TCPv6 ]: 1371
25
[ сервер - io - 4 , 27069 , запись , TCPv6 ]: 1371
26
[ сервер - io - 2 , 27069 , запись , TCPv6 ]: 1371
Принцип 5: баланс между пропускной способностью и задержкой
Если вы думаете о производительности приложений, вы, скорее всего, получите компромисс между пропускной способностью и задержкой. Этот компромисс затрагивает все области программирования, хорошо известным примером в области JVM является сборщик мусора: хотите ли вы сосредоточиться на пропускной способности с ParallelGC в некоторых пакетных приложениях или вам нужна низко-латентная в основном параллельная сборка мусора, такая как ShenandoahGC или ZGC?
Однако в этой части я собираюсь сосредоточиться на другом типе компромисса, который может быть обусловлен нашим приложением или инфраструктурой на основе Netty. Предположим, у нас есть WebSocket Server, который отправляет сообщения подключенным клиентам. Нам действительно нужно отправить конкретное сообщение как можно скорее? Или можно подождать немного дольше и позволить создать пакет из пяти сообщений и отправить их вместе?
Netty на самом деле поддерживает механизм сброса, который идеально подходит для этого варианта использования. Допустим, мы решили использовать пакетную обработку, чтобы амортизировать системные вызовы до 20 процентов и пожертвовать задержкой в пользу общей пропускной способности.
Пожалуйста, ознакомьтесь с моим примером JFR Netty Socket , внесите следующие изменения:
Простой текст
1
пбуда . JFR . розетки . Нетти . сервер . SlowConsumerDisconnectHandler :
2
- мы нужны , чтобы комментировать из смыва из каждого сообщения и использовать простую запись вместо
3
- написать метод делает не автоматически записи данных в в гнездо , она ждет для более скрытого контекста . writeAndFlush ( obj ) -> контекст . написать ( объект )
Простой текст
xxxxxxxxxx
1
пбуда . JFR . розетки . Нетти . Начало # основной
2
- раскоментируйте участок в в конце части к методу `Flush в основную часть из 5 messages`
Если вы установите Java 14, которая включает в себя функцию потоковой передачи Java Flight Recorder, вы сможете увидеть, что на самом деле делает Netty в этом случае.
Простой текст
xxxxxxxxxx
1
Broadcaster - Server 2020 - 01 - 14 22 : 12 : 00 , 937 [ client - nioEventLoopGroup - 0 ] ИНФОРМАЦИЯ с . Дж . с . п . с . WebSocketClientHandler - Полученное сообщение : my - message ( 10 байтов )
2
Broadcaster - Server 2020 - 01 - 14 22 : 12 : 00 , 937 [ client - nioEventLoopGroup - 0 ] ИНФОРМАЦИЯ с . Дж . с . п . с . WebSocketClientHandler - Полученное сообщение : my - message ( 10 байтов )
3
Broadcaster - Server 2020 - 01 - 14 22 : 12 : 00 , 938 [ client - nioEventLoopGroup - 0 ] ИНФОРМАЦИЯ с . Дж . с . п . с . WebSocketClientHandler - Полученное сообщение : my - message ( 10 байтов )
4
Broadcaster - Server 2020 - 01 - 14 22 : 12 : 00 , 938 [ client - nioEventLoopGroup - 0 ] ИНФОРМАЦИЯ с . Дж . с . п . с . WebSocketClientHandler - Полученное сообщение : my - message ( 10 байтов )
5
Broadcaster - Server 2020 - 01 - 14 22 : 12 : 00 , 939 [ клиент - nioEventLoopGroup - 0 ] ИНФОРМАЦИЯ с . Дж . с . п . с . WebSocketClientHandler - Полученное сообщение : my - message ( 10 байтов )
6
JDK . SocketWrite {
8
startTime = 22 : 12 : 01.603
9
длительность = 2,23 мс
10
хост = ""
11
адрес = "127.0.0.1"
12
порт = 42556
13
bytesWritten = 60 байтов
14
eventThread = "server-nioEventLoopGroup-1" ( javaThreadId = 27 )
15
stackTrace = [
16
солнце . Nio . ч . SocketChannelImpl . напишите ( ByteBuffer [], int , int ) строка : 167
17
-й . Нетти . канал . сокет . Nio . NioSocketChannel . doWrite ( ChannelOutboundBuffer ) линии : 420
18
-й . Нетти . канал . AbstractChannel $ AbstractUnsafe . flush0 () строка : 931
19
-й . Нетти . канал . Nio . AbstractNioChannel $ AbstractNioUnsafe . flush0 () строка : 354
20
-й . Нетти . канал . AbstractChannel $ AbstractUnsafe . строка flush () : 898
21
...
22
]
23
}
24
JDK . SocketRead {
26
startTime = 22 : 12 : 01.605
27
длительность = 0,0757 мс
28
хост = ""
29
адрес = "127.0.0.1"
30
порт = 8080
31
тайм-аут = 0 с
32
bytesRead = 60 байт
33
endOfStream = false
34
eventThread = "client-nioEventLoopGroup-0" ( javaThreadId = 26 )
35
stackTrace = [
36
солнце . Nio . ч . SocketChannelImpl . читать ( ByteBuffer ) строку : 73
37
-й . Нетти . буфер . PooledByteBuf . setBytes ( int , ScatteringByteChannel , int ) строка : 247
38
-й . Нетти . буфер . AbstractByteBuf . writeBytes ( ScatteringByteChannel , int ) строка : 1147
39
-й . Нетти . канал . сокет . Nio . NioSocketChannel . doReadBytes ( ByteBuf ) линии : 347
40
-й . Нетти . канал . Nio . AbstractNioByteChannel $ NioByteUnsafe . читать () строка : 148
41
...
42
]
43
}
Подключенный клиент получил пять сообщений, но мы можем видеть только одно чтение-сокет и запись-сокет, и оба содержат все байты для всего пакета сообщений.
Если вы хотите узнать больше о Java Flight Recorder, прочитайте мою статью « Копание в сокеты с Java Flight Recorder» .
Принцип 6: следите за новыми тенденциями и продолжайте экспериментировать
В этой части я хотел бы очень кратко представить две концепции, которые в настоящее время очень обсуждаются и становятся значительными вариантами для обработки большого количества клиентов / запросов, даже если они явно не связаны с решением проблемы C10K, но это определенно может помочь Вы с вашей общей архитектурой одноузлового приложения или группы сервисов, обрабатывающих некоторую большую нагрузку.
GraalVM Native-Image для экономии ресурсов
В настоящее время GraalVM работает над опережающим компилятором, который может запускать исполняемый файл вместе с недавно появившимся SubstrateVM . Одним словом, это означает, что Graal Compiler используется во время сборки для генерации машинного кода без каких-либо данных профилирования. Вы можете спросить: как это может помочь нам справиться с проблемой C10K, если мы, безусловно, генерируем менее эффективный машинный код, чем мы могли бы скомпилировать с помощью компилятора точно в срок? Ответ - нет! Это вам не поможет!
Тем не менее, он будет генерировать автономный минималистичный двоичный файл без каких-либо неиспользуемых классов / методов, внутренних структур, таких как структуры данных JIT, без профилирования, динамического кэширования кода, гораздо более простых GC, а также GC и структур.
Вышеуказанные оптимизации гарантируют, что мы сможем запустить наше приложение с гораздо меньшим объемом, и даже если приложение имеет менее эффективный код, мы можем получить лучшее соотношение между потребляемой памятью и общим количеством обработанных запросов, чем в случае JIT , Это означает, что мы можем развернуть несколько экземпляров этого приложения, и оно может обеспечить еще большую пропускную способность при меньшем количестве ресурсов.
Это всего лишь идея, которую мы всегда должны измерять. Целевые платформы для native-image - это серверные провайдеры, где нам необходимо развертывать небольшие приложения с меньшим объемом и очень малым временем запуска.
Проект Loom приходит, чтобы устранить нашу боль от блокирующих вызовов
Вы, наверное, слышали о волокнах / зеленых нитях / горутинах. Все эти термины обозначают одну концепцию. Они хотят избежать планирования потоков в пространстве ядра и перенести эту ответственность в пространство пользователя, хотя бы частично. Типичным примером этого является то, что у нас много блокирующих вызовов, каждый наш запрос к приложению заканчивается вызовом JDBC / HTTP / .., и нам нужно заблокировать наш текущий поток Java (который отображается один в один на поток ядра) и ждет, пока ответ не вернется.
Эти приложения должны иметь много потоков для масштабирования обработки запросов, и то, как мы уже обсуждали это, вообще неэффективно. Однако вместо этого мы можем использовать Fibers из Project Loom . Это гарантирует, что блокирующий вызов фактически не блокирует поток Java, а только текущее волокно. Таким образом, мы можем запланировать новое волокно в текущей запущенной java, а затем вернуться к исходному волокну, когда вызов блокировки завершен. Результатом этого является то, что мы можем обрабатывать все запросы даже при очень ограниченном количестве потоков Java, потому что излучение волокон «почти» бесплатно (сотни байтов для обработки контекста выполнения и очень быстрая инициализация), по крайней мере по сравнению с настоящая нить Java.
Это все еще продолжается, и Fibers еще не были объединены с mainline, но это невероятно многообещающая функция для исправления унаследованного кода, полного вызова JDBC.
Резюме
Попытка победить проблему C10K в основном связана с эффективностью использования ресурсов. Код, который абсолютно нормален для десятков / сотен параллельных пользователей, может очень сильно потерпеть неудачу, когда мы начнем принимать тысячи одновременных соединений.
Совершенно нормально сказать, что это приложение не предназначено для такого большого количества соединений, и мы можем избежать сложности расширенных функций для сохранения каждого байта в вашей памяти. Но всегда полезно знать об этом и начинать проектировать наше высокопроизводительное приложение с нуля, если нам нужно работать с большим количеством клиентов.
Спасибо за чтение моей статьи и, пожалуйста, оставьте комментарии ниже. Если вы хотите получать уведомления о новых сообщениях, тогда начните подписываться на меня в Twitter !